

Vi har med succes designet strukturen af vores PostgreSQL-database til lagring af korrespondance, et år er gået, brugerne udfylder den aktivt, og nu indeholder den millioner af optegnelser, og... noget begyndte at bremse.
- Del 2: sektionering "for profit"

Fakta er, at Efterhånden som tabellens størrelse vokser, vokser "dybden" af indeksene. - dog logaritmisk. Men over tid tvinger dette serveren til at udføre de samme læse-/skriveopgaver behandle mange gange flere sider med dataend i begyndelsen.
Det er her, det kommer til undsætning sektionering.
Lad mig bemærke, at vi ikke taler om sharding, det vil sige at distribuere data mellem forskellige databaser eller servere. Fordi selv opdele dataene i flere servere, vil du ikke slippe af med problemet med at indekser "hæver" over tid. Det er klart, at hvis du har råd til at sætte en ny server i drift hver dag, så vil dine problemer slet ikke længere ligge i en bestemt databases plan.
Vi vil ikke overveje specifikke scripts til implementering af partitionering "i hardware", men selve tilgangen - hvad og hvordan skal "skæres i skiver", og hvad et sådant ønske fører til.
Koncept
Lad os definere vores mål igen: vi vil sikre os, at i dag, i morgen og om et år forbliver mængden af data, der læses af PostgreSQL under enhver læse-/skriveoperation, omtrent den samme.
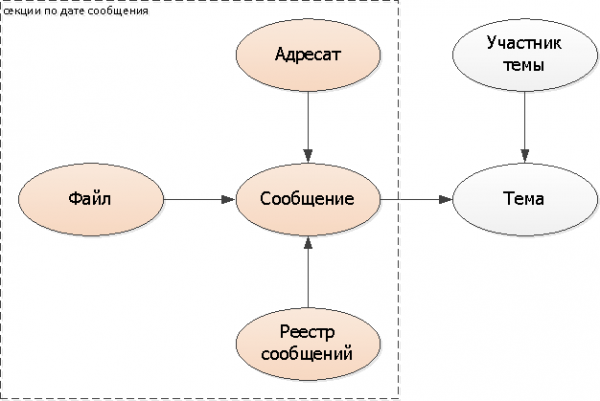
For evt kronologisk akkumulerede data (meddelelser, dokumenter, logfiler, arkiver, ...) det naturlige valg som partitioneringsnøgle er begivenheds dato/tid. I vores tilfælde er en sådan begivenhed øjeblik for afsendelse af beskeden.
Bemærk, at brugere næsten altid kun arbejde med de "nyeste". sådanne data - de læser de seneste beskeder, analyserer de seneste logs,... Nej, selvfølgelig kan de scrolle længere tilbage i tiden, men det gør de meget sjældent.
Ud fra disse begrænsninger er det klart, at den optimale beskedløsning ville være "daglige" sektioner - vores bruger vil trods alt næsten altid læse, hvad der kom til ham "i dag" eller "i går".
Hvis vi næsten kun skriver og læser i ét afsnit i løbet af dagen, så giver dette os også mere effektiv brug af hukommelse og disk - da alle sektionsindekser nemt passer ind i RAM'en, i modsætning til de "store og fede" i hele tabellen.
trin for trin
Generelt lyder alt, der er sagt ovenfor, som én kontinuerlig fortjeneste. Og det er opnåeligt, men for dette bliver vi nødt til at prøve hårdt - fordi beslutningen om at opdele en af enhederne fører til behovet for at "så" den tilknyttede.
Budskab, dets egenskaber og projektioner
Da vi besluttede at skære beskeder efter datoer, giver det mening også at opdele de entitetsegenskaber, der afhænger af dem (vedhæftede filer, liste over modtagere) og også efter meddelelsesdato.
Da en af vores typiske opgaver netop er at se meddelelsesregistre (ulæste, indgående, alle), er det også logisk at "trække dem ind" i opdeling efter meddelelsesdatoer.
Vi tilføjer partitioneringsnøglen (meddelelsesdato) til alle tabeller: modtagere, fil, registre. Du behøver ikke at tilføje den til selve beskeden, men bruge den eksisterende DateTime.
tråde
Da der kun er ét emne for flere beskeder, er der ingen måde at "klippe" det i den samme model; du er nødt til at stole på noget andet. I vores tilfælde er det ideelt dato for første meddelelse i korrespondance - det vil sige skabelsesøjeblikket, i virkeligheden af emnet.
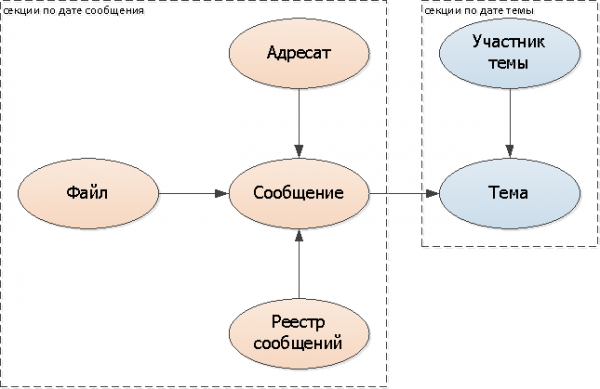
Tilføj partitioneringsnøglen (emnedato) til alle tabeller: emne, deltager.
Men nu har vi to problemer på én gang:
- I hvilket afsnit skal jeg kigge efter beskeder om emnet?
- I hvilket afsnit skal jeg søge efter emnet fra meddelelsen?
Vi kan selvfølgelig fortsætte med at søge i alle sektioner, men dette vil være meget trist og vil ophæve alle vores gevinster. Derfor vil vi, for at vide, hvor vi skal lede, lave logiske links/henvisninger til sektioner:
- vi tilføjer i beskeden emne dato felt
- lad os tilføje til emnet besked dato sat denne korrespondance (kan være en separat tabel eller en række datoer)
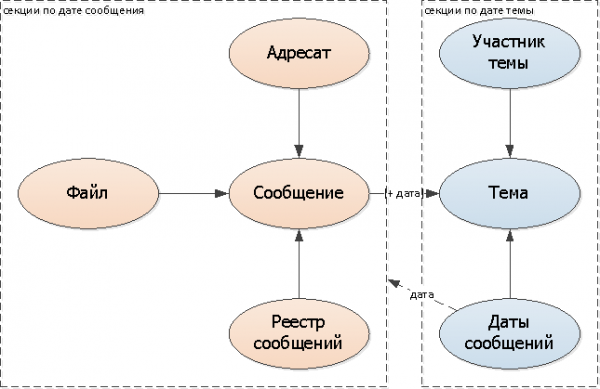
Da der vil være få ændringer i listen over meddelelsesdatoer for hver enkelt korrespondance (næsten alle meddelelser falder trods alt på 1-2 tilstødende dage), vil jeg fokusere på denne mulighed.
I alt tog strukturen af vores database følgende form under hensyntagen til partitionering:
Tabeller: RU, hvis du har en aversion mod det kyrilliske alfabet i navnene på tabeller/felter, er det bedre ikke at kigge
-- секции по дате сообщения
CREATE TABLE "Сообщение_YYYYMMDD"(
"Сообщение"
uuid
PRIMARY KEY
, "Тема"
uuid
, "ДатаТемы"
date
, "Автор"
uuid
, "ДатаВремя" -- используем как дату
timestamp
, "Текст"
text
);
CREATE TABLE "Адресат_YYYYMMDD"(
"ДатаСообщения"
date
, "Сообщение"
uuid
, "Персона"
uuid
, PRIMARY KEY("Сообщение", "Персона")
);
CREATE TABLE "Файл_YYYYMMDD"(
"ДатаСообщения"
date
, "Файл"
uuid
PRIMARY KEY
, "Сообщение"
uuid
, "BLOB"
uuid
, "Имя"
text
);
CREATE TABLE "РеестрСообщений_YYYYMMDD"(
"ДатаСообщения"
date
, "Владелец"
uuid
, "ТипРеестра"
smallint
, "ДатаВремя"
timestamp
, "Сообщение"
uuid
, PRIMARY KEY("Владелец", "ТипРеестра", "Сообщение")
);
CREATE INDEX ON "РеестрСообщений_YYYYMMDD"("Владелец", "ТипРеестра", "ДатаВремя" DESC);
-- секции по дате темы
CREATE TABLE "Тема_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
PRIMARY KEY
, "Документ"
uuid
, "Название"
text
);
CREATE TABLE "УчастникТемы_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
, "Персона"
uuid
, PRIMARY KEY("Тема", "Персона")
);
CREATE TABLE "ДатыСообщенийТемы_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
PRIMARY KEY
, "Дата"
date
);
Spar en pæn krone
Tja, hvad nu hvis vi ikke bruger baseret på fordelingen af feltværdier (gennem triggere og arv eller PARTITION BY), og "manuelt" på applikationsniveau, vil du bemærke, at værdien af partitioneringsnøglen allerede er gemt i navnet på selve tabellen.
Så hvis du er det Er du meget bekymret over mængden af lagrede data?, så kan du slippe af med disse "ekstra" felter og adressere specifikke tabeller. Sandt nok skal alle valg fra flere sektioner i dette tilfælde overføres til applikationssiden.
Kilde: www.habr.com
