


Hej alle sammen! Mit navn er Dmitry Samsonov, og jeg arbejder som ledende systemadministrator hos Odnoklassniki. Vi har over 7 fysiske servere, 11 containere i vores cloud og 200 applikationer, som i forskellige konfigurationer danner 700 forskellige klynger. Langt de fleste servere kører CentOS 7.
Den 14. august 2018 blev oplysninger om FragmentSmack-sårbarheden offentliggjort
() og SegmentSmack (). Det er sårbarheder med en netværksangrebsvektor og en ret høj score (7.5), som truer denial of service (DoS) på grund af ressourceudmattelse (CPU). En kernerettelse til FragmentSmack blev ikke foreslået på det tidspunkt; den udkom desuden meget senere end offentliggørelsen af information om sårbarheden. For at eliminere SegmentSmack blev det foreslået at opdatere kernen. Selve opdateringspakken blev frigivet samme dag, der var kun tilbage at installere den.
Nej, vi er slet ikke imod at opdatere kernen! Men der er nuancer...
Hvordan vi opdaterer kernen ved produktion
Generelt er der ikke noget kompliceret:
- Download pakker;
- Installer dem på en række servere (inklusive servere, der hoster vores sky);
- Sørg for, at intet er i stykker;
- Sørg for, at alle standardkerneindstillinger anvendes uden fejl;
- Vent et par dage;
- Tjek serverens ydeevne;
- Skift udrulning af nye servere til den nye kerne;
- Opdater alle servere efter datacenter (et datacenter ad gangen for at minimere effekten på brugerne i tilfælde af problemer);
- Genstart alle servere.
Gentag for alle grene af de kerner, vi har. I øjeblikket er det:
- Lager CentOS 7 3.10 - for de fleste almindelige servere;
- Vanilla 4.19 - til vores , fordi vi har brug for BFQ, BBR osv.;
- Elrepo kernel-ml 5.2 - til , fordi 4.19 plejede at opføre sig ustabilt, men de samme funktioner er nødvendige.
Som du måske har gættet, tager det længst tid at genstarte tusindvis af servere. Da ikke alle sårbarheder er kritiske for alle servere, genstarter vi kun dem, der er direkte tilgængelige fra internettet. I skyen, for ikke at begrænse fleksibiliteten, binder vi ikke eksternt tilgængelige containere til individuelle servere med en ny kerne, men genstarter alle værter uden undtagelse. Heldigvis er proceduren dér enklere end med almindelige servere. For eksempel kan statsløse containere simpelthen flytte til en anden server under en genstart.
Der er dog stadig meget arbejde, og det kan tage flere uger, og hvis der er problemer med den nye version, op til flere måneder. Angribere forstår dette meget godt, så de har brug for en plan B.
FragmentSmack/SegmentSmack. Løsning
Heldigvis eksisterer en sådan plan B for nogle sårbarheder, og den kaldes Workaround. Oftest er dette en ændring i kerne/applikationsindstillinger, der kan minimere den mulige effekt eller helt eliminere udnyttelsen af sårbarheder.
I tilfælde af FragmentSmack/SegmentSmack Løsning som denne:
«Du kan ændre standardværdierne på 4MB og 3MB i net.ipv4.ipfrag_high_thresh og net.ipv4.ipfrag_low_thresh (og deres modstykker for ipv6 net.ipv6.ipfrag_high_thresh og net.ipv6.ipfrag_low_thresh) til henholdsvis 256 kB eller 192 kB og hhv. nederste. Test viser små til betydelige fald i CPU-brug under et angreb afhængigt af hardware, indstillinger og forhold. Der kan dog være en vis præstationspåvirkning på grund af ipfrag_high_thresh=262144 bytes, da kun to 64K-fragmenter kan passe ind i genmonteringskøen ad gangen. For eksempel er der risiko for, at applikationer, der arbejder med store UDP-pakker, går i stykker'.
Selve parametrene beskrevet som følger:
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.
ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.
Vi har ikke store UDP'er på produktionstjenester. Der er ingen fragmenteret trafik på LAN, der er fragmenteret trafik på WAN, men ikke signifikant. Der er ingen tegn - du kan udrulle Workaround!
FragmentSmack/SegmentSmack. Første blod
Det første problem, vi stødte på, var, at cloud-containere nogle gange kun anvendte de nye indstillinger delvist (kun ipfrag_low_thresh), og nogle gange slet ikke anvendte dem - de gik simpelthen ned i starten. Det var ikke muligt at reproducere problemet stabilt (alle indstillinger blev anvendt manuelt uden problemer). Det er heller ikke så let at forstå, hvorfor containeren går ned i starten: ingen fejl blev fundet. En ting var sikker: at rulle indstillingerne tilbage løser problemet med containernedbrud.
Hvorfor er det ikke nok at anvende Sysctl på værten? Containeren bor i sit eget dedikerede netværk Namespace, så i hvert fald i beholderen kan afvige fra værten.
Hvordan anvendes Sysctl-indstillinger præcist i containeren? Da vores containere er uprivilegerede, vil du ikke være i stand til at ændre nogen Sysctl-indstilling ved at gå ind i selve containeren - du har simpelthen ikke nok rettigheder. Til at køre containere brugte vores sky på det tidspunkt Docker (nu ). Parametrene for den nye container blev sendt til Docker via API'et, inklusive de nødvendige Sysctl-indstillinger.
Mens man søgte gennem versionerne, viste det sig, at Docker API'en ikke returnerede alle fejl (i hvert fald i version 1.10). Da vi forsøgte at starte containeren via "docker run", så vi endelig i det mindste noget:
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.
Parameterværdien er ikke gyldig. Men hvorfor? Og hvorfor er det ikke kun gyldigt nogle gange? Det viste sig, at Docker ikke garanterer den rækkefølge, som Sysctl-parametrene anvendes i (den seneste testede version er 1.13.1), så nogle gange forsøgte ipfrag_high_thresh at blive sat til 256K, når ipfrag_low_thresh stadig var 3M, dvs. den øvre grænse var lavere end den nedre grænse, hvilket førte til fejlen.
På det tidspunkt brugte vi allerede vores egen mekanisme til at omkonfigurere beholderen efter start (frysning af beholderen efter og udføre kommandoer i containerens navneområde via ), og vi tilføjede også skrive Sysctl-parametre til denne del. Problemet blev løst.
FragmentSmack/SegmentSmack. Første blod 2
Før vi nåede at forstå brugen af Workaround i skyen, begyndte de første sjældne klager fra brugere at komme. På det tidspunkt var der gået flere uger siden starten på at bruge Workaround på de første servere. Den indledende undersøgelse viste, at der blev modtaget klager over individuelle tjenester og ikke alle disse tjenesters servere. Problemet er igen blevet ekstremt usikkert.
Først prøvede vi at rulle Sysctl-indstillingerne tilbage, men det havde ingen effekt. Diverse manipulationer af server- og programindstillingerne hjalp heller ikke. En genstart hjalp. Genstart for Linux lige så unaturligt, som det var en normal tilstand at arbejde med Windows I gamle dage. Det virkede dog, og vi afskrev det en "kernel-fejl", når vi anvendte nye Sysctl-indstillinger. Hvor tåbeligt af os...
Tre uger senere opstod problemet igen. Konfigurationen af disse servere var ret enkel: Nginx i proxy/balancer-tilstand. Ikke meget trafik. Ny indledende note: antallet af 504 fejl på klienter stiger hver dag (). Grafen viser antallet af 504 fejl pr. dag for denne tjeneste:
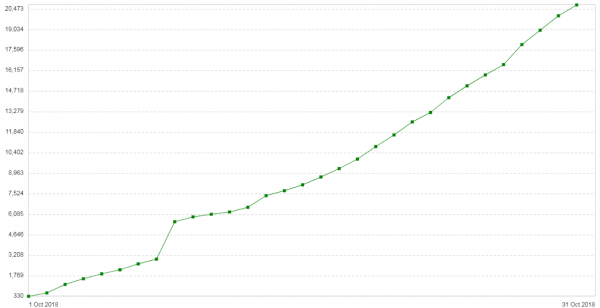
Alle fejlene handler om den samme backend - om den, der er i skyen. Hukommelsesforbrugsgrafen for pakkefragmenter på denne backend så således ud:
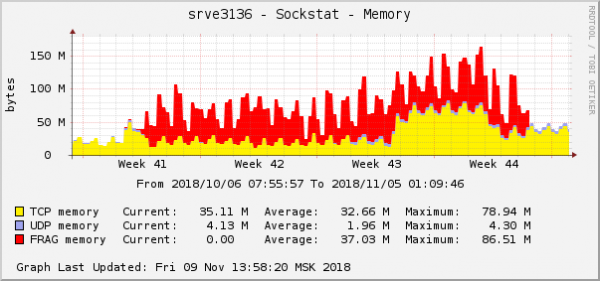
Dette er en af de mest åbenlyse manifestationer af problemet i operativsystemgrafer. I skyen blev et andet netværksproblem med QoS (Traffic Control)-indstillinger rettet. På grafen over hukommelsesforbrug for pakkefragmenter så det nøjagtigt det samme ud:
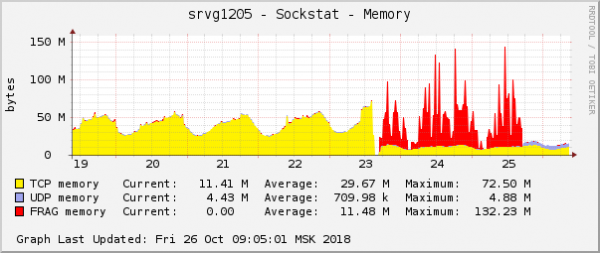
Antagelsen var enkel: Hvis de ser ens ud på graferne, så har de samme grund. Desuden er eventuelle problemer med denne type hukommelse ekstremt sjældne.
Essensen af det løste problem var, at vi brugte fq-pakkeplanlæggeren med standardindstillinger i QoS. Som standard, for én forbindelse, giver det dig mulighed for at tilføje 100 pakker til køen, og nogle forbindelser, i situationer med kanalmangel, begyndte at tilstoppe køen til kapacitet. I dette tilfælde slettes pakker. I tc statistik (tc -s qdisc) kan det ses sådan:
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit
"464545 flows_plimit" er de pakker, der er droppet på grund af overskridelse af køgrænsen for én forbindelse, og "droppede 464545" er summen af alle droppede pakker i denne planlægger. Efter at have øget kølængden til 1 tusind og genstartet containerne, holdt problemet op med at opstå. Du kan læne dig tilbage og drikke en smoothie.
FragmentSmack/SegmentSmack. Sidste Blod
For det første blev der endelig udgivet en rettelse til FragmentSmack flere måneder efter at kernens sårbarheder blev annonceret (husk, at annonceringen i august kun udgav en rettelse til SegmentSmack), hvilket gav os mulighed for at opgive Workaround, som havde forårsaget os en del problemer. Vi havde allerede migreret nogle servere til den nye kerne i løbet af denne tid, og nu måtte vi starte forfra. Hvorfor opdaterede vi kernen uden at vente på FragmentSmack-rettelsen? Faktum er, at processen med at beskytte mod disse sårbarheder faldt sammen (og blev integreret) med processen med at opdatere selve Workaround. CentOS (hvilket tager endnu længere tid end blot at opdatere kernen). Desuden er SegmentSmack en farligere sårbarhed, og en rettelse til den var tilgængelig med det samme, så det gav alligevel mening. Men blot at opdatere kernen CentOS vi kunne ikke på grund af FragmentSmack-sårbarheden, der opstod under CentOS 7.5 blev kun rettet i version 7.6, så vi måtte stoppe opdateringen til 7.5 og starte forfra med opdateringen til 7.6. Dette sker også.
For det andet er sjældne brugerklager over problemer vendt tilbage til os. Nu ved vi allerede med sikkerhed, at de alle er relateret til upload af filer fra klienter til nogle af vores servere. Desuden gik et meget lille antal uploads fra den samlede masse gennem disse servere.
Som vi husker fra historien ovenfor, hjalp det ikke at rulle Sysctl tilbage. Genstart hjalp, men midlertidigt.
Mistanker vedrørende Sysctl blev ikke fjernet, men denne gang var det nødvendigt at indsamle så mange oplysninger som muligt. Der var også en enorm mangel på evne til at gengive uploadproblemet på klienten for at studere mere præcist, hvad der skete.
Analyse af alle tilgængelige statistikker og logfiler bragte os ikke tættere på at forstå, hvad der skete. Der var en akut mangel på evne til at reproducere problemet for at "føle" en specifik sammenhæng. Endelig lykkedes det udviklerne ved hjælp af en speciel version af applikationen at opnå stabil gengivelse af problemer på en testenhed, når de var tilsluttet via Wi-Fi. Dette var et gennembrud i efterforskningen. Klienten tilsluttede sig Nginx, som proxyede til backend, som var vores Java-applikation.
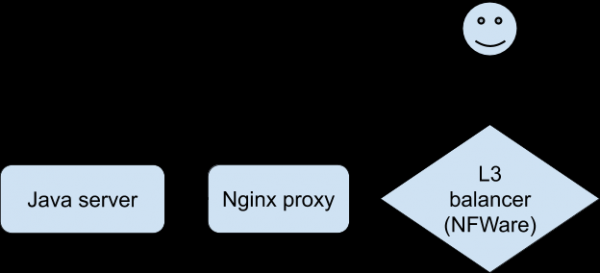
Dialogen for problemer var sådan her (fast på Nginx proxy-siden):
- Klient: anmodning om at modtage information om download af en fil.
- Java-server: svar.
- Klient: POST med fil.
- Java-server: fejl.
Samtidig skriver Java-serveren til loggen, at der blev modtaget 0 bytes data fra klienten, og Nginx-proxyen skriver, at anmodningen tog mere end 30 sekunder (30 sekunder er timeout for klientapplikationen). Hvorfor timeout og hvorfor 0 bytes? Fra et HTTP-perspektiv fungerer alt som det skal, men POST'en med filen ser ud til at forsvinde fra netværket. Desuden forsvinder det mellem klienten og Nginx. Det er tid til at bevæbne dig med Tcpdump! Men først skal du forstå netværkskonfigurationen. Nginx proxy står bag L3 balanceren . Tunneling bruges til at levere pakker fra L3 balanceren til serveren, som tilføjer sine overskrifter til pakkerne:
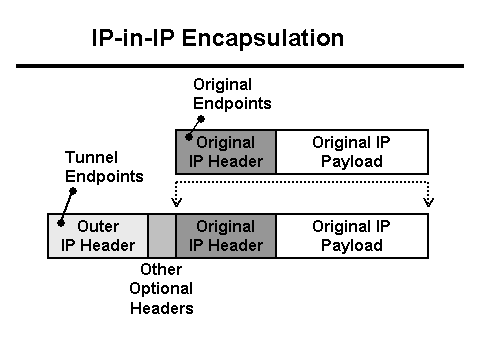
I dette tilfælde kommer netværket til denne server i form af Vlan-tagget trafik, som også tilføjer sine egne felter til pakkerne:
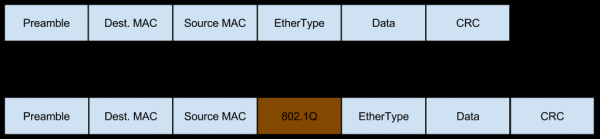
Og denne trafik kan også være fragmenteret (den samme lille procentdel af indgående fragmenteret trafik, som vi talte om, da vi vurderede risiciene fra Workaround), hvilket også ændrer indholdet af overskrifterne:
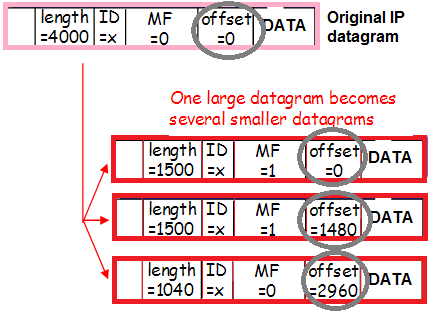
Endnu en gang: pakker er indkapslet med et Vlan-tag, indkapslet med en tunnel, fragmenteret. For bedre at forstå, hvordan dette sker, lad os spore pakkeruten fra klienten til Nginx-proxyen.
- Pakken når L3 balanceren. For korrekt routing i datacentret indkapsles pakken i en tunnel og sendes til netværkskortet.
- Da pakke + tunnel headers ikke passer ind i MTU'en, skæres pakken i fragmenter og sendes til netværket.
- Switchen efter L3 balanceren tilføjer, når den modtager en pakke, et Vlan-tag til den og sender den videre.
- Switchen foran Nginx-proxyen ser (baseret på portindstillingerne), at serveren forventer en Vlan-indkapslet pakke, så den sender den, som den er, uden at fjerne Vlan-tagget.
- Linux modtager fragmenter af individuelle pakker og limer dem sammen til én stor pakke.
- Dernæst når pakken Vlan-grænsefladen, hvor det første lag fjernes fra den - Vlan-indkapsling.
- derefter Linux sender den til tunnelgrænsefladen, hvor et andet lag fjernes fra den - tunnelindkapsling.
Vanskeligheden er at overføre alt dette som parametre til tcpdump.
Lad os starte fra slutningen: Er der rene (uden unødvendige overskrifter) IP-pakker fra klienter, hvor vlan og tunnelindkapsling er fjernet?
tcpdump host <ip клиента>
Nej, der var ingen sådanne pakker på serveren. Så problemet må være der tidligere. Er der nogen pakker med kun Vlan-indkapsling fjernet?
tcpdump ip[32:4]=0xx390x2xx
0xx390x2xx er klientens IP-adresse i hex-format.
32:4 — adresse og længde på det felt, hvori SCR IP er skrevet i tunnelpakken.
Feltadressen skulle vælges med brute force, da de på internettet skriver om 40, 44, 50, 54, men der var ingen IP-adresse der. Du kan også se på en af pakkerne i hex (parameteren -xx eller -XX i tcpdump) og beregne den IP-adresse, du kender.
Er der pakkefragmenter uden Vlan og Tunnel indkapsling fjernet?
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
Denne magi vil vise os alle fragmenterne, inklusive det sidste. Sandsynligvis kan det samme filtreres efter IP, men jeg prøvede ikke, for der er ikke ret mange sådanne pakker, og dem, jeg havde brug for, var let at finde i det generelle flow. Her er de:
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0, flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....jEx
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if..MM.*........
14:02:58.471103 I 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), længde 62: (tos 0x0, ttl 63, id 53652, forskydning 1480, flag [ingen], proto IPIP (4), længde 40)
11.11.11.11 > 22.22.22.22: ip-proto-4
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ..........A....
0x0010: 4500 0028 d194 00b9 3f04 faf6 2x76 385x E..(....?....f8}
0x0020: 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .faE...D-,.!...C
0x0030: x978 e91d x9b0 d608 0000 0000 0000 7c31 .x............|Q
0x0040: 881d c4b6 0000 0000 0000 0000 0000 ............
Disse er to fragmenter af en pakke (samme ID 53652) med et fotografi (ordet Exif er synligt i den første pakke). På grund af det faktum, at der er pakker på dette niveau, men ikke i den sammenlagte form på lossepladserne, er problemet helt klart med monteringen. Endelig er der dokumentation for dette!
Pakkedekoderen afslørede ikke nogen problemer, der ville forhindre opbygningen. Prøvede det her: . Først, når du prøver at fylde noget der, kan dekoderen ikke lide pakkeformatet. Det viste sig, at der var nogle ekstra to oktetter mellem Srcmac og Ethertype (ikke relateret til fragmentinformation). Efter at have fjernet dem, begyndte dekoderen at arbejde. Det viste dog ingen problemer.
Hvad man end måtte sige, fandtes intet andet end de Sysctl. Tilbage var blot at finde en måde at identificere problemservere for at forstå omfanget og beslutte sig for yderligere handlinger. Den nødvendige tæller blev fundet hurtigt nok:
netstat -s | grep "packet reassembles failed”
Det er også i snmpd under OID=1.3.6.1.2.1.4.31.1.1.16.1 ().
"Antallet af fejl registreret af IP-gensamlingsalgoritmen (uanset grund: timeout, fejl osv.)."
Blandt gruppen af servere, hvor problemet blev undersøgt, steg denne tæller hurtigere på to, på to langsommere, og på to mere steg den slet ikke. Sammenligning af dynamikken i denne tæller med dynamikken i HTTP-fejl på Java-serveren afslørede en korrelation. Det vil sige, at måleren kunne overvåges.
Det er meget vigtigt at have en pålidelig indikator for problemer, så du nøjagtigt kan afgøre, om tilbagerulning af Sysctl hjælper, da vi fra den forrige historie ved, at dette ikke umiddelbart kan forstås fra applikationen. Denne indikator ville give os mulighed for at identificere alle problemområder i produktionen, før brugerne opdager det.
Efter tilbagerulning af Sysctl stoppede overvågningsfejlene, dermed blev årsagen til problemerne bevist, samt at tilbagerulningen hjælper.
Vi rullede fragmenteringsindstillingerne tilbage på andre servere, hvor ny overvågning kom i spil, og et eller andet sted tildelte vi endnu mere hukommelse til fragmenter, end det tidligere var standard (dette var UDP-statistikker, hvis delvise tab ikke var mærkbart på den generelle baggrund) .
De vigtigste spørgsmål
Hvorfor er pakker fragmenteret på vores L3 balancer? De fleste af de pakker, der ankommer fra brugere til balancerer, er SYN og ACK. Størrelserne på disse pakker er små. Men da andelen af sådanne pakker er meget stor, bemærkede vi på baggrund af deres baggrund ikke tilstedeværelsen af store pakker, der begyndte at fragmentere.
Årsagen var et ødelagt konfigurationsscript på servere med Vlan-grænseflader (der var meget få servere med tagget trafik i produktion på det tidspunkt). Advmss giver os mulighed for at formidle til klienten informationen om, at pakker i vores retning skal være mindre i størrelse, så de efter at have vedhæftet tunneloverskrifter til dem ikke behøver at blive fragmenteret.
Hvorfor hjalp Sysctl rollback ikke, men genstart gjorde det? Rulle tilbage Sysctl ændrede mængden af tilgængelig hukommelse til at flette pakker. Samtidig førte tilsyneladende selve kendsgerningen med hukommelsesoverløb for fragmenter til opbremsning af forbindelser, hvilket førte til, at fragmenter blev forsinket i lang tid i køen. Det vil sige, at processen gik i cyklusser.
Genstarten ryddede hukommelsen, og alt vendte tilbage til orden.
Var det muligt at undvære Workaround? Ja, men der er en høj risiko for at efterlade brugere uden service i tilfælde af et angreb. Naturligvis resulterede brugen af Workaround i forskellige problemer, herunder opbremsningen af en af tjenesterne for brugerne, men ikke desto mindre mener vi, at handlingerne var berettigede.
Mange tak til Andrey Timofeev () for hjælp til at gennemføre efterforskningen, samt Alexey Krenev () - for det titaniske arbejde med at opdatere Centos og serverkerner. I dette tilfælde måtte processen genstartes flere gange, hvilket resulterede i, at det tog mange måneder.
Kilde: www.habr.com
