


SQL, hvad kunne være nemmere? Hver af os kan skrive en simpel anmodning - vi skriver Vælg, angiv derefter de påkrævede kolonner fra, tabelnavn, nogle betingelser i hvor og det er alt - nyttige data er i vores lomme, og (næsten) uanset hvilket DBMS der er under motorhjelmen på det tidspunkt (eller måske ). Som et resultat kan arbejde med næsten enhver datakilde (relationel og ikke sådan) overvejes ud fra almindelig kodes synspunkt (med alt hvad det indebærer - versionskontrol, kodegennemgang, statisk analyse, autotest, og det er alt). Og det gælder ikke kun selve dataene, skemaer og migreringer, men generelt hele lagerets levetid. I denne artikel vil vi tale om dagligdags opgaver og problemer med at arbejde med forskellige databaser under linsen "database som kode".
Og lad os starte lige fra . De første kampe af typen "SQL vs ORM" blev bemærket igen .
Objektrelationel kortlægning
ORM-supportere værdsætter traditionelt hastighed og nem udvikling, uafhængighed af DBMS og ren kode. For mange af os er koden til at arbejde med databasen (og ofte selve databasen)
det plejer at se sådan ud...
@Entity
@Table(name = "stock", catalog = "maindb", uniqueConstraints = {
@UniqueConstraint(columnNames = "STOCK_NAME"),
@UniqueConstraint(columnNames = "STOCK_CODE") })
public class Stock implements java.io.Serializable {
@Id
@GeneratedValue(strategy = IDENTITY)
@Column(name = "STOCK_ID", unique = true, nullable = false)
public Integer getStockId() {
return this.stockId;
}
...Modellen er behængt med smarte annoteringer, og et sted bag kulisserne genererer og udfører en tapper ORM tonsvis af noget SQL-kode. Udviklere forsøger i øvrigt deres bedste for at isolere sig fra deres database med kilometervis af abstraktioner, hvilket indikerer nogle .
På den anden side af barrikaderne bemærker tilhængere af ren "håndlavet" SQL evnen til at presse al saften ud af deres DBMS uden yderligere lag og abstraktioner. Som følge heraf opstår der "datacentrerede" projekter, hvor specialuddannede personer er involveret i databasen (de er også "basicister", de er også "basicister", de er også "basdenere" osv.), og udviklerne behøver kun at "trække" de færdige visninger og lagrede procedurer, uden at gå i detaljer.
Hvad hvis vi havde det bedste fra begge verdener? Hvordan dette gøres i et vidunderligt værktøj med et livsbekræftende navn . Jeg vil give et par linjer fra det generelle koncept i min gratis oversættelse, og du kan stifte nærmere bekendtskab med det .
Clojure er et fedt sprog til at skabe DSL'er, men SQL i sig selv er en fed DSL, og vi har ikke brug for en anden. S-udtryk er fantastiske, men de tilføjer ikke noget nyt her. Som følge heraf får vi beslag for beslags skyld. Er ikke enig? Vent derefter på det øjeblik, hvor abstraktionen over databasen begynder at lække, og du begynder at slås med funktionen (raw-sql)
Så hvad skal jeg gøre? Lad os lade SQL være almindelig SQL - én fil pr. anmodning:
-- name: users-by-country
select *
from users
where country_code = :country_code... og læs derefter denne fil, og gør den til en almindelig Clojure-funktion:
(defqueries "some/where/users_by_country.sql"
{:connection db-spec})
;;; A function with the name `users-by-country` has been created.
;;; Let's use it:
(users-by-country {:country_code "GB"})
;=> ({:name "Kris" :country_code "GB" ...} ...)Ved at overholde "SQL af sig selv, Clojure af sig selv"-princippet får du:
- Ingen syntaktiske overraskelser. Din database (som enhver anden) er ikke 100% kompatibel med SQL-standarden - men det betyder ikke noget for Yesql. Du vil aldrig spilde tid på at jage efter funktioner med SQL tilsvarende syntaks. Du behøver aldrig at vende tilbage til en funktion (raw-sql "some('funky'::SYNTAX)")).
- Bedste editor support. Din editor har allerede fremragende SQL-understøttelse. Ved at gemme SQL som SQL kan du blot bruge det.
- Team kompatibilitet. Dine DBA'er kan læse og skrive den SQL, du bruger i dit Clojure-projekt.
- Lettere justering af ydeevne. Har du brug for at lave en plan for en problematisk forespørgsel? Dette er ikke et problem, når din forespørgsel er almindelig SQL.
- Genbrug af forespørgsler. Træk og slip de samme SQL-filer til andre projekter, fordi det bare er almindelig gammel SQL - bare del det.
Idéen er efter min mening meget fed og samtidig meget enkel, takket være projektet har fået mange på en række sprog. Og vi vil derefter forsøge at anvende en lignende filosofi om at adskille SQL-kode fra alt andet langt ud over ORM.
IDE & DB ledere
Lad os starte med en simpel hverdagsopgave. Ofte skal vi søge efter nogle objekter i databasen, for eksempel finde en tabel i skemaet og studere dens struktur (hvilke kolonner, nøgler, indekser, begrænsninger osv. bruges). Og fra enhver grafisk IDE eller en lille DB-manager forventer vi først og fremmest netop disse evner. Så det er hurtigt, og du ikke skal vente en halv time, indtil der er tegnet et vindue med de nødvendige informationer (især med en langsom forbindelse til en fjerndatabase), og samtidig er den modtagne information frisk og relevant, og ikke cachelagret junk. Desuden, jo mere kompleks og større databasen og jo større antallet af dem, jo sværere er det at gøre dette.
Men normalt smider jeg musen og skriver bare kode. Lad os sige, at du skal finde ud af, hvilke tabeller (og med hvilke egenskaber) der er indeholdt i "HR"-skemaet. I de fleste DBMS'er kan det ønskede resultat opnås med denne enkle forespørgsel fra information_schema:
select table_name
, ...
from information_schema.tables
where schema = 'HR'Fra database til database varierer indholdet af sådanne referencetabeller afhængigt af hver enkelt DBMS's muligheder. Og for eksempel, for MySQL, fra den samme opslagsbog kan du få tabelparametre, der er specifikke for dette DBMS:
select table_name
, storage_engine -- Используемый "движок" ("MyISAM", "InnoDB" etc)
, row_format -- Формат строки ("Fixed", "Dynamic" etc)
, ...
from information_schema.tables
where schema = 'HR'Oracle kender ikke information_schema, men det har det , og der opstår ingen store problemer:
select table_name
, pct_free -- Минимум свободного места в блоке данных (%)
, pct_used -- Минимум используемого места в блоке данных (%)
, last_analyzed -- Дата последнего сбора статистики
, ...
from all_tables
where owner = 'HR'ClickHouse er ingen undtagelse:
select name
, engine -- Используемый "движок" ("MergeTree", "Dictionary" etc)
, ...
from system.tables
where database = 'HR'Noget lignende kan gøres i Cassandra (som har kolonnefamilier i stedet for tabeller og nøglerum i stedet for skemaer):
select columnfamily_name
, compaction_strategy_class -- Стратегия сборки мусора
, gc_grace_seconds -- Время жизни мусора
, ...
from system.schema_columnfamilies
where keyspace_name = 'HR'For de fleste andre databaser kan du også komme med lignende forespørgsler (selv Mongo har , som indeholder oplysninger om alle samlinger i systemet).
Selvfølgelig kan du på denne måde få information ikke kun om tabeller, men om ethvert objekt generelt. Fra tid til anden deler venlige mennesker sådan kode til forskellige databaser, som for eksempel i serien af habra-artikler "Funktioner til at dokumentere PostgreSQL-databaser" (, , ). Det er selvfølgelig en fornøjelse at have hele dette bjerg af forespørgsler i mit hoved og konstant skrive dem, så i min yndlings-IDE/editor har jeg et forudforberedt sæt uddrag til ofte brugte forespørgsler, og det eneste, der er tilbage, er at skrive objektnavne i skabelonen.
Som et resultat er denne metode til at navigere og søge efter objekter meget mere fleksibel, sparer meget tid og giver dig mulighed for at få præcis den information i den form, som den nu er nødvendig (som f.eks. beskrevet i indlægget ).
Operationer med objekter
Når vi har fundet og studeret de nødvendige genstande, er det tid til at gøre noget nyttigt med dem. Naturligvis også uden at tage fingrene fra tastaturet.
Det er ingen hemmelighed, at blot at slette en tabel vil se ens ud i næsten alle databaser:
drop table hr.personsMen med skabelsen af bordet bliver det mere interessant. Næsten ethvert DBMS (inklusive mange NoSQL) kan "oprette tabel" i en eller anden form, og hoveddelen af den vil endda afvige lidt (navn, liste over kolonner, datatyper), men andre detaljer kan afvige dramatisk og afhænge af intern enhed og funktioner i et specifikt DBMS. Mit foretrukne eksempel er, at der i Oracle-dokumentationen kun er "nøgne" BNF'er til "opret tabel"-syntaksen . Andre DBMS'er har mere beskedne muligheder, men hver af dem har også mange interessante og unikke funktioner til at oprette tabeller (, , , ). Det er usandsynligt, at nogen grafisk "trollmand" fra en anden IDE (især en universel) fuldt ud vil være i stand til at dække alle disse evner, og selvom den kan, vil det ikke være et skue for sarte sjæle. Samtidig en korrekt og rettidig skriftlig redegørelse oprette tabel vil give dig mulighed for nemt at bruge dem alle, gøre opbevaring og adgang til dine data pålidelig, optimal og så komfortabel som muligt.
Mange DBMS'er har også deres egne specifikke typer objekter, som ikke er tilgængelige i andre DBMS'er. Desuden kan vi udføre operationer ikke kun på databaseobjekter, men også på selve DBMS, for eksempel "dræbe" en proces, frigøre noget hukommelsesområde, aktivere sporing, skifte til "read only"-tilstand og meget mere.
Lad os nu tegne lidt
En af de mest almindelige opgaver er at bygge et diagram med databaseobjekter og se objekterne og forbindelserne mellem dem i et smukt billede. Næsten enhver grafisk IDE, separate "kommandolinje"-værktøjer, specialiserede grafiske værktøjer og modelbyggere kan gøre dette. De vil tegne noget for dig "så godt de kan", og du kan kun påvirke denne proces lidt ved hjælp af nogle få parametre i konfigurationsfilen eller afkrydsningsfelter i grænsefladen.
Men dette problem kan løses meget enklere, mere fleksibelt og elegant, og selvfølgelig ved hjælp af kode. For at skabe diagrammer af enhver kompleksitet har vi flere specialiserede markup-sprog (DOT, GraphML osv.), og for dem en hel spredning af applikationer (GraphViz, PlantUML, Mermaid), der kan læse sådanne instruktioner og visualisere dem i en række forskellige formater . Nå, vi ved allerede, hvordan man får information om objekter og forbindelser mellem dem.
Her er et lille eksempel på, hvordan dette kunne se ud, ved at bruge PlantUML og (til venstre er en SQL-forespørgsel, der genererer den nødvendige instruktion til PlantUML, og til højre er resultatet):
select '@startuml'||chr(10)||'hide methods'||chr(10)||'hide stereotypes' union all
select distinct ccu.table_name || ' --|> ' ||
tc.table_name as val
from table_constraints as tc
join key_column_usage as kcu
on tc.constraint_name = kcu.constraint_name
join constraint_column_usage as ccu
on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and tc.table_name ~ '.*' union all
select '@enduml'Og hvis du prøver lidt, så ud fra du kan få noget, der ligner et rigtigt ER-diagram:
SQL-forespørgslen er lidt mere kompliceret
-- Шапка
select '@startuml
!define Table(name,desc) class name as "desc" << (T,#FFAAAA) >>
!define primary_key(x) <b>x</b>
!define unique(x) <color:green>x</color>
!define not_null(x) <u>x</u>
hide methods
hide stereotypes'
union all
-- Таблицы
select format('Table(%s, "%s n information about %s") {'||chr(10), table_name, table_name, table_name) ||
(select string_agg(column_name || ' ' || upper(udt_name), chr(10))
from information_schema.columns
where table_schema = 'public'
and table_name = t.table_name) || chr(10) || '}'
from information_schema.tables t
where table_schema = 'public'
union all
-- Связи между таблицами
select distinct ccu.table_name || ' "1" --> "0..N" ' || tc.table_name || format(' : "A %s may haven many %s"', ccu.table_name, tc.table_name)
from information_schema.table_constraints as tc
join information_schema.key_column_usage as kcu on tc.constraint_name = kcu.constraint_name
join information_schema.constraint_column_usage as ccu on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and ccu.constraint_schema = 'public'
and tc.table_name ~ '.*'
union all
-- Подвал
select '@enduml'
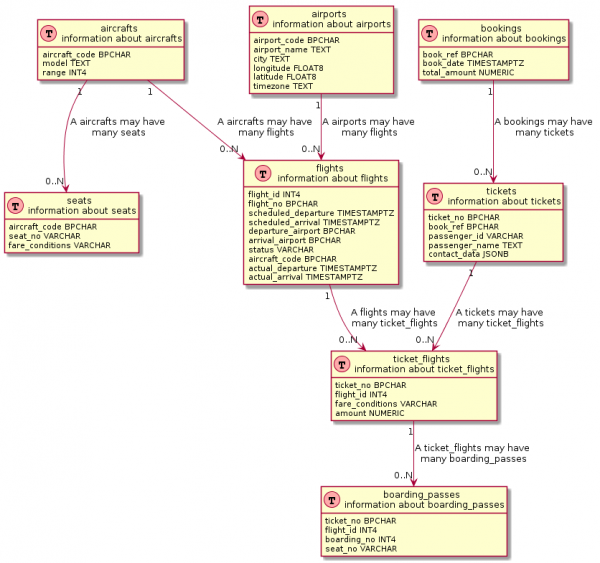
Hvis du ser godt efter, bruger mange visualiseringsværktøjer også lignende forespørgsler under motorhjelmen. Sandt nok er disse anmodninger normalt dybt , for ikke at nævne nogen ændring af dem.
Metrik og overvågning
Lad os gå videre til et traditionelt komplekst emne - overvågning af databaseydelse. Jeg husker en lille sand historie fortalt af "en af mine venner". På et andet projekt boede der en vis magtfuld DBA, og få af udviklerne kendte ham personligt, eller havde nogensinde set ham personligt (på trods af, at han ifølge rygterne arbejdede et sted i den næste bygning). I timen "X", da en stor detailhandlers indsamlingssystem begyndte at "få det dårligt" igen, sendte han lydløst skærmbilleder af grafer fra Oracle Enterprise Manager, hvorpå han omhyggeligt fremhævede kritiske steder med en rød markør for "forståelighed" ( dette hjalp mildt sagt ikke meget). Og ud fra dette "fotokort" skulle jeg behandle. Samtidig havde ingen adgang til den dyrebare (i begge betydninger af ordet) Enterprise Manager, fordi systemet er komplekst og dyrt, pludselig "snubler udviklerne over noget og bryder alt." Derfor fandt udviklerne "empirisk" placeringen og årsagen til bremserne og frigav en patch. Hvis det truende brev fra DBA ikke kom igen i den nærmeste fremtid, så ville alle ånde lettet op og vende tilbage til deres nuværende opgaver (indtil det nye brev).
Men overvågningsprocessen kan se mere sjov og venlig ud, og vigtigst af alt, tilgængelig og gennemsigtig for alle. I det mindste dens grundlæggende del, som en tilføjelse til de vigtigste overvågningssystemer (som bestemt er nyttige og i mange tilfælde uerstattelige). Ethvert DBMS er frit og helt gratis at dele oplysninger om dets aktuelle tilstand og ydeevne. I den samme "blodige" Oracle DB kan næsten enhver information om ydeevne fås fra systemvisninger, lige fra processer og sessioner til buffercachens tilstand (f.eks. , afsnittet "Overvågning"). Postgresql har også en hel masse systemvisninger til , især dem, der er uundværlige i dagligdagen på enhver DBA, som f.eks , , . MySQL har endda et separat skema til dette. . A In Mongo indbygget samler ydeevnedata til en systemsamling .
Bevæbnet med en slags metrik-samler (Telegraf, Metricbeat, Collectd), der kan udføre brugerdefinerede sql-forespørgsler, en lagring af disse metrics (InfluxDB, Elasticsearch, Timescaledb) og en visualizer (Grafana, Kibana), kan du få en ret nem og et fleksibelt overvågningssystem, der vil være tæt integreret med andre systemdækkende metrikker (f.eks. opnået fra applikationsserveren, fra OS osv.). Som f.eks. gøres dette i pgwatch2, som bruger kombinationen InfluxDB + Grafana og et sæt forespørgsler til systemvisninger, som også kan tilgås .
I alt
Og dette er kun en omtrentlig liste over, hvad der kan gøres med vores database ved hjælp af almindelig SQL-kode. Jeg er sikker på du kan finde mange flere anvendelser, skriv i kommentarerne. Og vi vil tale om, hvordan (og vigtigst af alt hvorfor) man automatiserer alt dette og inkluderer det i din CI/CD-pipeline næste gang.
Kilde: www.habr.com
