

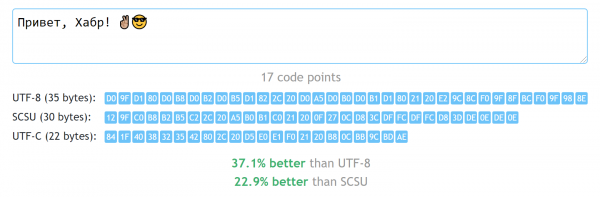
Hvis du er udvikler og står over for opgaven med at vælge en kodning, så vil Unicode næsten altid være den rigtige løsning. Den specifikke repræsentationsmetode afhænger af konteksten, men oftest er der også her et universelt svar - UTF-8. Det gode ved det er, at det giver dig mulighed for at bruge alle Unicode-tegn uden udgifter for meget mange bytes i de fleste tilfælde. Sandt nok, for sprog, der bruger mere end blot det latinske alfabet, er "ikke for meget" i det mindste to bytes pr. tegn. Kan vi gøre det bedre uden at vende tilbage til forhistoriske kodninger, der begrænser os til kun 256 tilgængelige tegn?
Nedenfor foreslår jeg at gøre dig bekendt med mit forsøg på at besvare dette spørgsmål og implementere en relativt simpel algoritme, der giver dig mulighed for at gemme linjer på de fleste sprog i verden uden at tilføje redundansen, der er i UTF-8.
Ansvarsfraskrivelse. Jeg vil straks tage et par vigtige forbehold: den beskrevne løsning tilbydes ikke som en universel erstatning for UTF-8, den er kun egnet i en snæver liste af tilfælde (mere om dem nedenfor), og den bør under ingen omstændigheder bruges til at interagere med tredjeparts API'er (som ikke engang kender til det). Oftest er komprimeringsalgoritmer til generelle formål (f.eks. deflater) egnede til kompakt lagring af store mængder tekstdata. Derudover fandt jeg allerede i færd med at lave min løsning en eksisterende standard i selve Unicode, som løser samme problem - det er noget mere kompliceret (og ofte værre), men alligevel er det en accepteret standard, og ikke bare sat sammen på knæet. Jeg vil også fortælle dig om ham.
Om Unicode og UTF-8
Til at begynde med et par ord om, hvad det er Unicode и UTF-8.
Som du ved, plejede 8-bit-kodninger at være populære. Med dem var alt enkelt: 256 tegn kan nummereres med tal fra 0 til 255, og tal fra 0 til 255 kan naturligvis repræsenteres som én byte. Hvis vi går tilbage til begyndelsen, er ASCII-kodningen fuldstændig begrænset til 7 bit, så den mest signifikante bit i dens byte-repræsentation er nul, og de fleste 8-bit-kodninger er kompatible med den (de adskiller sig kun i den "øvre" del, hvor den væsentligste bit er en ).
Hvordan adskiller Unicode sig fra disse kodninger, og hvorfor er så mange specifikke repræsentationer forbundet med det - UTF-8, UTF-16 (BE og LE), UTF-32? Lad os ordne det i rækkefølge.
Den grundlæggende Unicode-standard beskriver kun korrespondancen mellem tegn (og i nogle tilfælde individuelle komponenter af tegn) og deres numre. Og der er rigtig mange mulige tal i denne standard - fra 0x00 til 0x10FFFF (1 stykker). Hvis vi ville sætte et tal i et sådant område ind i en variabel, ville hverken 114 eller 112 bytes være nok for os. Og da vores processorer ikke er særlig designet til at arbejde med tre-byte-tal, ville vi være tvunget til at bruge så mange som 1 bytes pr. tegn! Dette er UTF-2, men det er netop på grund af denne "ødselhed", at dette format ikke er populært.
Heldigvis er rækkefølgen af tegn i Unicode ikke tilfældig. Hele deres sæt er opdelt i 17"fly", som hver indeholder 65536 (0x10000) «kodepunkter" Konceptet med et "kodepunkt" her er ganske enkelt tegnnummer, tildelt den af Unicode. Men som nævnt ovenfor er ikke kun individuelle tegn nummereret i Unicode, men også deres komponenter og servicemærker (og nogle gange svarer intet overhovedet til nummeret - måske for tiden, men for os er dette ikke så vigtigt), så det er mere korrekt altid tale specifikt om antallet af tal selv, og ikke symboler. Men i det følgende vil jeg for kortheds skyld ofte bruge ordet "symbol", hvilket antyder udtrykket "kodepunkt".
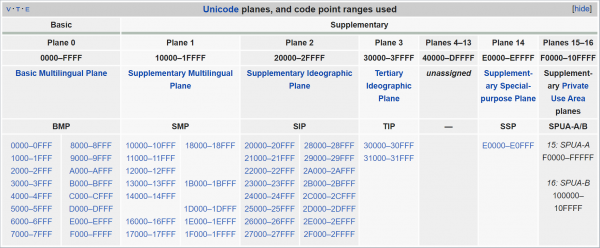
Unicode fly. Som du kan se, er det meste (fly 4 til 13) stadig ubrugt.
Det mest bemærkelsesværdige er, at al den vigtigste "pulp" ligger i nulplanet, det kaldes "Grundlæggende flersproget plan". Hvis en linje indeholder tekst på et af de moderne sprog (inklusive kinesisk), kommer du ikke ud over dette plan. Men du kan heller ikke afskære resten af Unicode - for eksempel er emoji hovedsageligt placeret i slutningen af det næste fly,"Supplerende flersproget plan"(det strækker sig fra 0x10000 til 0x1FFFF). Så UTF-16 gør dette: alle tegn falder indenfor Grundlæggende flersproget plan, er kodet "som de er" med et tilsvarende to-byte nummer. Nogle af tallene i dette interval angiver dog slet ikke specifikke tegn, men indikerer, at vi efter dette par bytes skal overveje endnu et - ved at kombinere værdierne af disse fire bytes sammen, får vi et tal, der dækker hele det gyldige Unicode-interval. Denne idé kaldes "surrogatpar" - du har måske hørt om dem.
Så UTF-16 kræver to eller (i meget sjældne tilfælde) fire bytes pr. "kodepunkt". Dette er bedre end at bruge fire bytes hele tiden, men latin (og andre ASCII-tegn), når de kodes på denne måde, spilder halvdelen af pladsen på nuller. UTF-8 er designet til at rette op på dette: ASCII i den optager, som før, kun én byte; koder fra 0x80 til 0x7FF - to bytes; fra 0x800 til 0xFFFF - tre, og fra 0x10000 til 0x10FFFF - fire. På den ene side er det latinske alfabet blevet godt: kompatibiliteten med ASCII er vendt tilbage, og fordelingen er mere jævnt "spredt ud" fra 1 til 4 bytes. Men andre alfabeter end latin gavner desværre ikke på nogen måde i forhold til UTF-16, og mange kræver nu tre bytes i stedet for to - intervallet dækket af en to-byte post er indsnævret med 32 gange, med 0xFFFF til 0x7FF, og hverken kinesisk eller for eksempel georgisk er med i den. Kyrillisk og fem andre alfabeter - hurra - heldig, 2 bytes pr. tegn.
Hvorfor sker dette? Lad os se, hvordan UTF-8 repræsenterer tegnkoder:

Direkte til at repræsentere tal bruges her bits markeret med symbolet x. Det kan ses, at der i en to-byte-record kun er 11 sådanne bits (ud af 16). De ledende bits har her kun en hjælpefunktion. I tilfælde af en fire-byte-record tildeles 21 ud af 32 bits til kodepunktnummeret - det ser ud til, at tre bytes (som giver i alt 24 bits) ville være nok, men servicemarkører æder for meget.
Er det slemt? Ikke rigtig. På den ene side, hvis vi bekymrer os meget om plads, har vi kompressionsalgoritmer, der nemt kan eliminere al den ekstra entropi og redundans. På den anden side var målet med Unicode at give den mest universelle kodning muligt. For eksempel kan vi overlade en linje kodet i UTF-8 til kode, der tidligere kun fungerede med ASCII, og ikke være bange for, at den vil se et tegn fra ASCII-området, som faktisk ikke er der (trods alt i UTF-8 alt bytes startende med fra nul bit - det er præcis, hvad ASCII er). Og hvis vi pludselig vil skære en lille hale af fra en stor streng uden at afkode den helt fra begyndelsen (eller gendanne en del af informationen efter en beskadiget sektion), er det nemt for os at finde forskydningen, hvor en karakter begynder (det er nok at springe bytes over, der har et bit-præfiks 10).
Hvorfor så opfinde noget nyt?
Samtidig er der nogle gange situationer, hvor komprimeringsalgoritmer som deflate er dårligt anvendelige, men du ønsker at opnå kompakt lagring af strenge. Personligt stødte jeg på dette problem, da jeg tænkte på at bygge for en stor ordbog med ord på vilkårlige sprog. På den ene side er hvert ord meget kort, så det vil være ineffektivt at komprimere det. På den anden side var træimplementeringen, som jeg overvejede, designet således, at hver byte af den lagrede streng genererede et separat træ-vertex, så det var meget nyttigt at minimere deres antal. I mit bibliotek (Som i , som den er baseret på) kan et lignende problem løses ganske enkelt - strenge pakket ind i -ordbog, gemt der i . Men som det er let at forstå, fungerer dette kun godt for et begrænset alfabet - en linje på kinesisk kan ikke tilføjes til en sådan ordbog.
Separat vil jeg gerne bemærke endnu en ubehagelig nuance, der opstår, når man bruger UTF-8 i en sådan datastruktur. Billedet ovenfor viser, at når et tegn skrives som to bytes, kommer de bits, der er relateret til dets nummer, ikke i en række, men er adskilt af et par bits 10 i midten: 110xxxxx 10xxxxxx. På grund af dette, når de nederste 6 bits af den anden byte flyder over i tegnkoden (dvs. der sker en overgang 10111111 → 10000000), så ændres den første byte også. Det viser sig, at bogstavet "p" er angivet med bytes 0xD0 0xBF, og det næste "r" er allerede 0xD1 0x80. I et præfikstræ fører dette til opdelingen af den overordnede node i to - en for præfikset 0xD0, og en anden for 0xD1 (selvom hele det kyrilliske alfabet kun kunne kodes af den anden byte).
Hvad fik jeg
Stillet over for dette problem besluttede jeg mig for at øve mig i at spille spil med bits, og samtidig blive lidt bedre bekendt med strukturen i Unicode som helhed. Resultatet var UTF-C-kodningsformatet ("C" for kompakt), som ikke bruger mere end 3 bytes pr. kodepunkt, og meget ofte tillader dig kun at bruge en ekstra byte for hele den kodede linje. Dette fører til det faktum, at en sådan kodning viser sig at være på mange ikke-ASCII-alfabeter 30-60 % mere kompakt end UTF-8.
Jeg har præsenteret eksempler på implementering af indkodnings- og afkodningsalgoritmer i formularen , kan du frit bruge dem i din kode. Men jeg vil stadig understrege, at dette format i en vis forstand forbliver en "cykel", og jeg anbefaler ikke at bruge det uden at vide hvorfor du har brug for det. Dette er stadig mere et eksperiment end en seriøs "forbedring af UTF-8". Ikke desto mindre er koden der skrevet pænt, kortfattet, med et stort antal kommentarer og testdækning.
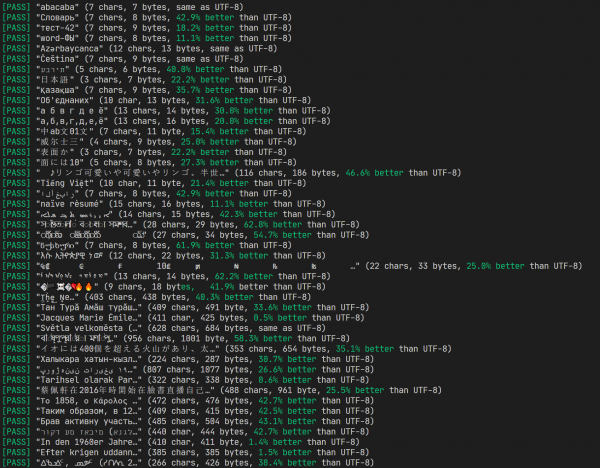
Testresultater og sammenligning med UTF-8
Det gjorde jeg også , hvor du kan evaluere algoritmens ydeevne, og så vil jeg fortælle dig mere om dens principper og udviklingsproces.
Eliminering af overflødige bits
Jeg tog selvfølgelig UTF-8 som grundlag. Den første og mest åbenlyse ting, der kan ændres i den, er at reducere antallet af servicebits i hver byte. For eksempel starter den første byte i UTF-8 altid med enten 0eller med 11 - et præfiks 10 Kun de følgende bytes har det. Lad os erstatte præfikset 11 på 1, og for de næste bytes vil vi fjerne præfikserne fuldstændigt. Hvad vil der ske?
0xxxxxxx - 1 byte
10xxxxxx xxxxxxxx - 2 bytes
110xxxxx xxxxxxxx xxxxxxxx - 3 bytes
Vent, hvor er den fire-byte post? Men det er ikke længere nødvendigt - når der skrives i tre bytes, har vi nu 21 bit til rådighed, og det er tilstrækkeligt til alle tal op til 0x10FFFF.
Hvad har vi ofret her? Det vigtigste er detekteringen af tegngrænser fra en vilkårlig placering i bufferen. Vi kan ikke pege på en vilkårlig byte og finde begyndelsen af det næste tegn fra den. Dette er en begrænsning af vores format, men i praksis er det sjældent nødvendigt. Vi er normalt i stand til at løbe gennem bufferen helt fra begyndelsen (især når det kommer til korte linjer).
Situationen med at dække sprog med 2 bytes er også blevet bedre: nu giver to-byte formatet en rækkevidde på 14 bit, og det er koder op til 0x3FFF. Kineserne er uheldige (deres tegn spænder for det meste fra 0x4E00 til 0x9FFF), men georgiere og mange andre folk har det sjovere - deres sprog passer også ind i 2 bytes pr. tegn.
Indtast encodertilstanden
Lad os nu tænke på egenskaberne af selve linjerne. Ordbogen indeholder oftest ord skrevet med bogstaver af samme alfabet, og det gælder også for mange andre tekster. Det ville være godt at angive dette alfabet én gang og derefter kun angive nummeret på bogstavet i det. Lad os se, om arrangementet af tegn i Unicode-tabellen vil hjælpe os.
Som nævnt ovenfor er Unicode opdelt i fly 65536 koder hver. Men dette er ikke en meget nyttig opdeling (som allerede sagt, oftest er vi i nulplanet). Mere interessant er opdelingen efter blokke. Disse områder har ikke længere en fast længde og er mere meningsfulde - som regel kombinerer hver tegn fra det samme alfabet.
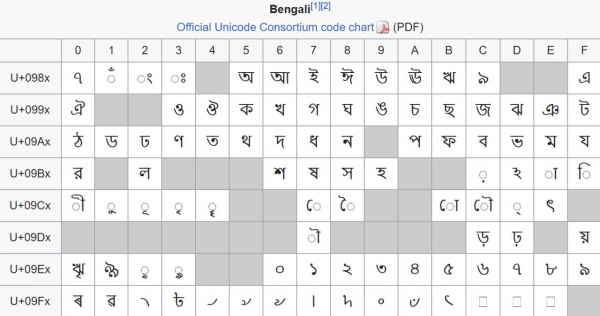
En blok, der indeholder tegn fra det bengalske alfabet. Desværre er dette af historiske årsager et eksempel på ikke særlig tæt emballage - 96 tegn er kaotisk spredt ud over 128 blokkodepunkter.
Begyndelsen af blokke og deres størrelser er altid multipla af 16 - dette gøres simpelthen for nemheds skyld. Derudover begynder og slutter mange blokke på værdier, der er multipla af 128 eller endda 256 - for eksempel fylder det grundlæggende kyrilliske alfabet 256 bytes fra 0x0400 til 0x04FF. Dette er ret praktisk: hvis vi gemmer præfikset én gang 0x04, så kan et hvilket som helst kyrillisk tegn skrives i én byte. Sandt nok, på denne måde mister vi muligheden for at vende tilbage til ASCII (og til andre karakterer generelt). Derfor gør vi dette:
- To bytes
10yyyyyy yxxxxxxxikke kun betegne et symbol med et talyyyyyy yxxxxxxx, men også ændre sig nuværende alfabet påyyyyyy y0000000(dvs. vi husker alle bits undtagen de mindst betydningsfulde 7 bit); - En byte
0xxxxxxxdette er karakteren af det aktuelle alfabet. Det skal bare føjes til forskydningen, som vi huskede i trin 1. Selvom vi ikke ændrede alfabetet, er forskydningen nul, så vi bevarede kompatibiliteten med ASCII.
Ligeledes for koder, der kræver 3 bytes:
- Tre bytes
110yyyyy yxxxxxxx xxxxxxxxangive et symbol med et talyyyyyy yxxxxxxx xxxxxxxx, lave om nuværende alfabet påyyyyyy y0000000 00000000(huskede alt undtagen de yngre 15 bit), og marker det felt, som vi nu er i lang tilstand (når vi ændrer alfabetet tilbage til et dobbeltbyte, nulstiller vi dette flag); - To bytes
0xxxxxxx xxxxxxxxi lang tilstand er det karakteren af det aktuelle alfabet. På samme måde tilføjer vi det med offset fra trin 1. Den eneste forskel er, at nu læser vi to bytes (fordi vi skiftede til denne tilstand).
Lyder godt: Mens vi nu skal indkode tegn fra det samme 7-bit Unicode-område, bruger vi 1 ekstra byte i begyndelsen og i alt en byte pr. tegn.
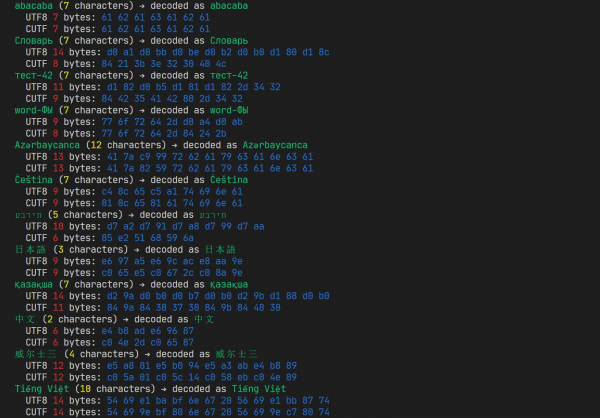
Arbejder fra en af de tidligere versioner. Den slår allerede ofte UTF-8, men der er stadig plads til forbedringer.
Hvad er værre? For det første har vi en betingelse, nemlig nuværende alfabetforskydning og afkrydsningsfelt lang tilstand. Dette begrænser os yderligere: nu kan de samme tegn kodes forskelligt i forskellige sammenhænge. Søgning efter understrenge skal for eksempel ske under hensyntagen til dette, og ikke kun ved at sammenligne bytes. For det andet, så snart vi ændrede alfabetet, blev det dårligt med indkodningen af ASCII-tegn (og dette er ikke kun det latinske alfabet, men også grundlæggende tegnsætning, inklusive mellemrum) - de kræver at ændre alfabetet igen til 0, dvs. igen en ekstra byte (og så endnu en for at komme tilbage til vores hovedpointe).
Et alfabet er godt, to er bedre
Lad os prøve at ændre vores bit-præfikser lidt, og klemme en mere ind til de tre beskrevet ovenfor:
0xxxxxxx — 1 byte i normal tilstand, 2 i lang tilstand
11xxxxxx - 1 byte
100xxxxx xxxxxxxx - 2 bytes
101xxxxx xxxxxxxx xxxxxxxx - 3 bytes
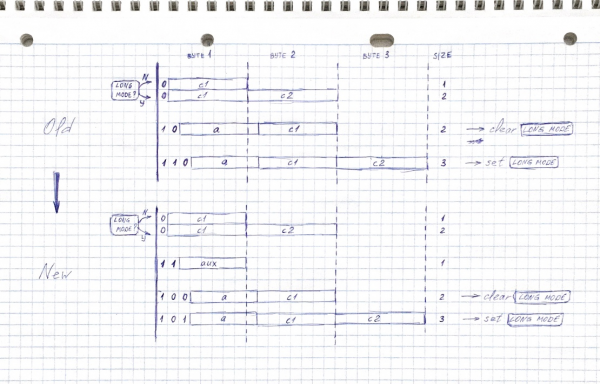
Nu i en to-byte record er der en mindre tilgængelig bit - kodepunkter op til 0x1FFFOg ikke 0x3FFF. Det er dog stadig mærkbart større end i dobbeltbyte UTF-8-koder, de fleste almindelige sprog passer stadig ind, det mest mærkbare tab er faldet ud и , japanerne er kede af det.
Hvad er denne nye kode? 11xxxxxx? Dette er et lille "stash" på 64 tegn i størrelse, det supplerer vores hovedalfabet, så jeg kaldte det hjælpe (hjælpemotor) alfabet. Når vi skifter det nuværende alfabet, bliver et stykke af det gamle alfabet hjælpe. For eksempel skiftede vi fra ASCII til kyrillisk - gemmerne indeholder nu 64 tegn, der indeholder Latinsk alfabet, tal, mellemrum og komma (hyppigste indsættelser i ikke-ASCII-tekster). Skift tilbage til ASCII - og hoveddelen af det kyrilliske alfabet bliver hjælpealfabetet.
Takket være adgang til to alfabeter kan vi håndtere et stort antal tekster med minimale omkostninger til at skifte alfabet (tegnsætning vil oftest føre til en tilbagevenden til ASCII, men herefter vil vi få mange ikke-ASCII-tegn fra det ekstra alfabet, uden skifter igen).
Bonus: præfiks til underalfabetet 11xxxxxx og vælge dens indledende offset til at være 0xC0, får vi delvis kompatibilitet med CP1252. Med andre ord vil mange (men ikke alle) vesteuropæiske tekster kodet i CP1252 se ens ud i UTF-C.
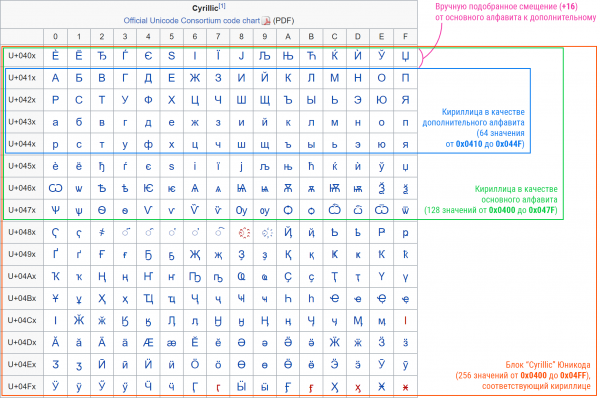
Her opstår der imidlertid en vanskelighed: hvordan får man et hjælpealfabet fra hovedalfabetet? Du kan forlade den samme offset, men - desværre - her spiller Unicode-strukturen allerede mod os. Meget ofte er hoveddelen af alfabetet ikke i begyndelsen af blokken (for eksempel har den russiske hovedstad "A" koden 0x0410, selvom den kyrilliske blok begynder med 0x0400). Efter at have taget de første 64 tegn ind i gemmerne kan vi således miste adgangen til alfabetets haledel.
For at løse dette problem gik jeg manuelt igennem nogle blokke, der svarer til forskellige sprog, og specificerede forskydningen af hjælpealfabetet i det primære alfabet for dem. Det latinske alfabet blev som en undtagelse generelt omorganiseret som base64.
Sidste hånd
Lad os endelig tænke over, hvor vi ellers kan forbedre noget.
Bemærk, at formatet 101xxxxx xxxxxxxx xxxxxxxx giver dig mulighed for at kode tal op til 0x1FFFFF, og Unicode slutter tidligere, kl 0x10FFFF. Med andre ord vil det sidste kodepunkt blive repræsenteret som 10110000 11111111 11111111. Derfor kan vi sige, at hvis den første byte er af formen 1011xxxx (Hvor xxxx større end 0), så betyder det noget andet. For eksempel kan du tilføje yderligere 15 tegn der, som konstant er tilgængelige for kodning i en byte, men jeg besluttede at gøre det anderledes.
Lad os se på de Unicode-blokke, der kræver tre bytes nu. Dybest set, som allerede nævnt, er disse kinesiske tegn - men det er svært at gøre noget med dem, der er 21 tusinde af dem. Men hiragana og katakana fløj der også - og dem er der ikke så mange af længere, mindre end to hundrede. Og siden vi huskede japanerne, er der også emojis (faktisk er de spredt mange steder i Unicode, men hovedblokkene er i rækken 0x1F300 - 0x1FBFF). Hvis du tænker på, at der nu er emojis, der er samlet fra flere kodepunkter på én gang (f.eks. emoji'en består af hele 7 koder!), så bliver det en skam at bruge tre bytes på hver (7×3 = 21 bytes af hensyn til ét ikon, et mareridt).
Derfor udvælger vi nogle få udvalgte områder svarende til emoji, hiragana og katakana, omnummererer dem til en kontinuerlig liste og koder dem som to bytes i stedet for tre:
1011xxxx xxxxxxxx
Fantastisk: den førnævnte emoji, der består af 7 kodepunkter, tager 8 bytes i UTF-25, og vi passer det ind 14 (præcis to bytes for hvert kodepunkt). Habr nægtede i øvrigt at fordøje det (både i den gamle og i den nye editor), så jeg måtte indsætte den med et billede.
Lad os prøve at løse endnu et problem. Som vi husker, er det grundlæggende alfabet i det væsentlige høj 6 bits, som vi husker og limer til koden for hvert næste afkodede symbol. I tilfælde af kinesiske tegn, der er i blokken 0x4E00 - 0x9FFF, dette er enten bit 0 eller 1. Dette er ikke særlig praktisk: vi bliver nødt til konstant at skifte alfabetet mellem disse to værdier (dvs. bruge tre bytes). Men bemærk, at i den lange tilstand, fra selve koden, kan vi trække antallet af tegn, som vi koder ved hjælp af den korte tilstand (efter alle de tricks, der er beskrevet ovenfor, er dette 10240) - så vil rækken af hieroglyffer skifte til 0x2600 - 0x77FF, og i dette tilfælde vil de mest signifikante 6 bits (ud af 21) i hele dette område være lig med 0. Således vil sekvenser af hieroglyffer bruge to bytes pr. hieroglyf (hvilket er optimalt for så stort et område), uden at forårsager alfabetskift.
Alternative løsninger: SCSU, BOCU-1
Unicode-eksperter, som lige har læst artiklens titel, vil højst sandsynligt skynde sig at minde dig om, at der direkte blandt Unicode-standarderne er (SCSU), som beskriver en indkodningsmetode meget lig den, der er beskrevet i artiklen.
Jeg indrømmer ærligt: Jeg lærte om dens eksistens først, efter at jeg var dybt fordybet i at skrive min beslutning. Havde jeg vidst det fra starten, havde jeg nok forsøgt at skrive en implementering i stedet for at komme med min egen tilgang.
Det interessante er, at SCSU bruger ideer, der ligner dem, jeg selv kom med (i stedet for begrebet "alfabeter" bruger de "vinduer", og der er flere af dem tilgængelige, end jeg har). Samtidig har dette format også ulemper: det er lidt tættere på kompressionsalgoritmer end kodningsalgoritmer. Specielt giver standarden mange repræsentationsmetoder, men siger ikke, hvordan man vælger den optimale - til dette skal indkoderen bruge en form for heuristik. En SCSU encoder, der producerer god emballage, vil således være mere kompleks og mere besværlig end min algoritme.
Til sammenligning overførte jeg en relativt simpel implementering af SCSU til JavaScript - med hensyn til kodevolumen viste den sig at være sammenlignelig med min UTF-C, men i nogle tilfælde var resultatet titusindvis af procent dårligere (nogle gange kan det overstige det, men ikke meget). For eksempel blev tekster på hebraisk og græsk kodet af UTF-C 60 % bedre end SCSU (sandsynligvis på grund af deres kompakte alfabeter).
Separat vil jeg tilføje, at der udover SCSU også er en anden måde at kompakt repræsentere Unicode - , men det sigter efter MIME-kompatibilitet (som jeg ikke havde brug for) og tager en lidt anden tilgang til kodning. Jeg har ikke vurderet dets effektivitet, men det forekommer mig, at det er usandsynligt, at det er højere end SCSU.
Mulige forbedringer
Algoritmen, jeg præsenterede, er ikke universel af design (det er nok her, mine mål afviger mest fra Unicode-konsortiets mål). Jeg har allerede nævnt, at den primært blev udviklet til én opgave (lagring af en flersproget ordbog i et præfikstræ), og nogle af dens funktioner er muligvis ikke velegnede til andre opgaver. Men det faktum, at det ikke er en standard, kan være et plus - du kan nemt ændre den, så den passer til dine behov.
For eksempel kan du på den indlysende måde slippe af med tilstedeværelsen af stat, lave statsløs kodning - bare ikke opdatere variabler offs, auxOffs и is21Bit i encoder og dekoder. I dette tilfælde vil det ikke være muligt effektivt at pakke sekvenser af tegn i det samme alfabet, men der vil være en garanti for, at det samme tegn altid er kodet med de samme bytes, uanset konteksten.
Derudover kan du skræddersy koderen til et bestemt sprog ved at ændre standardtilstanden - for eksempel ved at fokusere på russiske tekster, indstille koderen og dekoderen i begyndelsen offs = 0x0400 и auxOffs = 0. Dette giver især mening i tilfælde af statsløs tilstand. Generelt vil dette svare til at bruge den gamle otte-bit-kodning, men uden at fjerne muligheden for at indsætte tegn fra al Unicode efter behov.
En anden ulempe nævnt tidligere er, at der i stor tekst kodet i UTF-C ikke er nogen hurtig måde at finde den tegngrænse, der er tættest på en vilkårlig byte. Hvis du afskærer de sidste f.eks. 100 bytes fra den kodede buffer, risikerer du at få skrald, som du ikke kan gøre noget med. Kodningen er ikke designet til lagring af multi-gigabyte logs, men generelt kan dette rettes. Byte 0xBF må aldrig vises som den første byte (men kan være den anden eller tredje). Derfor kan du, når du koder, indsætte sekvensen 0xBF 0xBF 0xBF hver, f.eks. 10 KB - så, hvis du skal finde en grænse, vil det være nok at scanne det valgte stykke, indtil en lignende markør er fundet. Efter det sidste 0xBF er med garanti begyndelsen på en karakter. (Ved afkodning skal denne sekvens på tre bytes naturligvis ignoreres.)
Opsummering
Hvis du har læst så langt, tillykke! Jeg håber, at du ligesom jeg har lært noget nyt (eller genopfrisket din hukommelse) om Unicodes struktur.
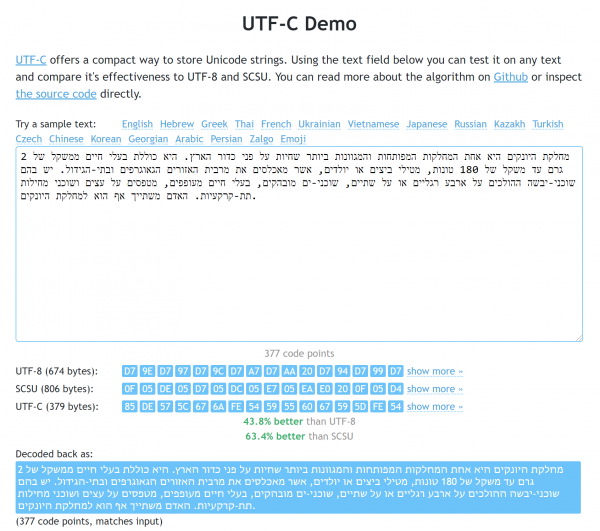
Demo side. Eksemplet med hebraisk viser fordelene i forhold til både UTF-8 og SCSU.
Den ovenfor beskrevne forskning bør ikke betragtes som et indgreb i standarder. Jeg er dog generelt tilfreds med resultaterne af mit arbejde, så jeg er glad for dem : for eksempel vejer et minificeret JS-bibliotek kun 1710 bytes (og har selvfølgelig ingen afhængigheder). Som jeg nævnte ovenfor, kan hendes arbejde findes på (der er også et sæt tekster, hvorpå det kan sammenlignes med UTF-8 og SCSU).
Til sidst vil jeg endnu en gang henlede opmærksomheden på tilfælde, hvor UTF-C bruges ikke det værd:
- Hvis dine linjer er lange nok (fra 100-200 tegn). I dette tilfælde bør du overveje at bruge kompressionsalgoritmer som deflate.
- Hvis du har brug for ASCII gennemsigtighed, det vil sige, at det er vigtigt for dig, at de kodede sekvenser ikke indeholder ASCII-koder, der ikke var i den oprindelige streng. Behovet for dette kan undgås, hvis du, når du interagerer med tredjeparts API'er (f.eks. arbejder med en database), sender kodningsresultatet som et abstrakt sæt af bytes, og ikke som strenge. Ellers risikerer du at få uventede sårbarheder.
- Hvis du vil være i stand til hurtigt at finde tegngrænser ved en vilkårlig offset (f.eks. når en del af en linje er beskadiget). Dette kan gøres, men kun ved at scanne linjen fra begyndelsen (eller anvende ændringen beskrevet i det foregående afsnit).
- Hvis du hurtigt skal udføre operationer på indholdet af strenge (sortér dem, søg efter understrenge i dem, sammenkæd). Dette kræver, at strenge afkodes først, så UTF-C vil være langsommere end UTF-8 i disse tilfælde (men hurtigere end komprimeringsalgoritmer). Da den samme streng altid er kodet på samme måde, er nøjagtig sammenligning af afkodning ikke nødvendig og kan udføres på en byte-for-byte basis.
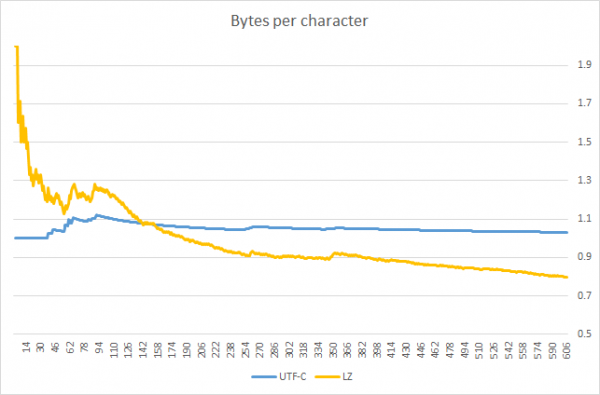
Update: bruger postede en graf, der fremhæver anvendelighedsgrænserne for UTF-C. Det viser, at UTF-C er mere effektiv end en generel komprimeringsalgoritme (en variation af LZW), så længe den pakkede streng er kortere ~140 tegn (Jeg bemærker dog, at sammenligningen blev udført på én tekst; for andre sprog kan resultatet afvige).
Kilde: www.habr.com
