

Den næste HighLoad++ konference afholdes den 6. og 7. april 2020 i St. Petersburg. Detaljer og billetter . HighLoad++ Moskva 2018. Hal “Moskva”. 9. november klokken 15. Specialer og .

* Overvågning - online og analyser.
* Grundlæggende begrænsninger for ZABBIX-platformen.
* Løsning til skalering af analyselager.
* Optimering af ZABBIX-serveren.
* UI optimering.
* Oplev at betjene systemet under belastninger på mere end 40k NVPS.
* Korte konklusioner.
Mikhail Makurov (i det følgende – MM): - Hej alle!
Maxim Chernetsov (i det følgende – MCH): - God eftermiddag!
MM: – Lad mig introducere Maxim. Max er en talentfuld ingeniør, den bedste netværksmand, jeg kender. Maxim er involveret i netværk og tjenester, deres udvikling og drift.

MCH: – Og jeg vil gerne fortælle dig om Mikhail. Mikhail er en C-udvikler. Han skrev adskillige højbelastningsløsninger til trafikbehandling til vores virksomhed. Vi bor og arbejder i Ural, i byen med barske mænd i Chelyabinsk, i virksomheden Intersvyaz. Vores virksomhed er en udbyder af internet- og kabel-tv-tjenester til en million mennesker i 16 byer.
MM: - Og det er værd at sige, at Intersvyaz er meget mere end blot en udbyder, det er en it-virksomhed. De fleste af vores løsninger er lavet af vores IT-afdeling.
EN: fra servere, der behandler trafik til et callcenter og mobilapplikation. IT-afdelingen har nu omkring 80 personer med meget, meget forskelligartede kompetencer.
Om Zabbix og dens arkitektur
MCH: – Og nu vil jeg forsøge at sætte en personlig rekord og sige på et minut, hvad Zabbix er (i det følgende benævnt "Zabbix").
Zabbix positionerer sig selv som et out-of-the-box overvågningssystem på virksomhedsniveau. Den har mange funktioner, der gør livet nemmere: avancerede eskaleringsregler, API til integration, gruppering og automatisk registrering af værter og metrics. Zabbix har såkaldte skaleringsværktøjer – proxyer. Zabbix er et open source-system.
Kort om arkitektur. Vi kan sige, at det består af tre komponenter:
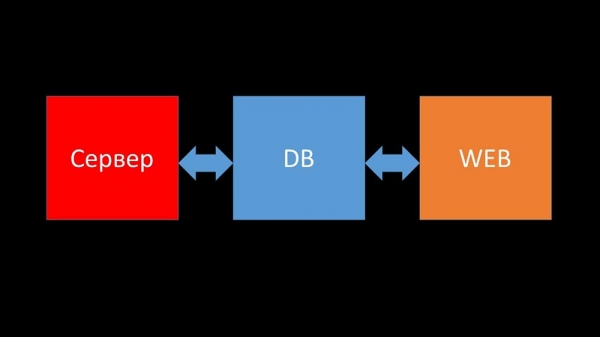
- Server. Skrevet i C. Med ret kompleks bearbejdning og overførsel af information mellem tråde. Al behandling foregår i den: fra modtagelse til lagring i databasen.
- Alle data gemmes i databasen. Zabbix understøtter MySQL, PostreSQL og Oracle.
- Webgrænsefladen er skrevet i PHP. På de fleste systemer kommer den med en Apache-server, men fungerer mere effektivt i kombination med nginx + php.
I dag vil vi gerne fortælle en historie fra vores virksomheds liv relateret til Zabbix...
En historie fra Intersvyaz-virksomhedens liv. Hvad har vi, og hvad har vi brug for?

5 eller 6 måneder siden. En dag efter arbejde...
MCH: - Misha, hej! Jeg er glad for, at det lykkedes mig at fange dig - der er en snak. Vi havde igen problemer med overvågningen. Under en større ulykke gik alt langsomt, og der var ingen oplysninger om netværkets tilstand. Det er desværre ikke første gang, det er sket. Jeg har brug for din hjælp. Lad os få vores overvågning til at fungere under alle omstændigheder!
MM: - Men lad os synkronisere først. Jeg har ikke kigget der i et par år. Så vidt jeg husker, forlod vi Nagios og skiftede til Zabbix for omkring 8 år siden. Og nu ser det ud til, at vi har 6 kraftfulde servere og omkring et dusin proxyer. Forvirrer jeg noget?
MCH: - Næsten. 15 servere, hvoraf nogle er virtuelle maskiner. Det vigtigste er, at det ikke redder os i det øjeblik, hvor vi har allermest brug for det. Som et uheld - serverne sænker farten, og du kan ikke se noget. Vi forsøgte at optimere konfigurationen, men det gav ikke den optimale ydelsesforøgelse.
MM: - Det er klart. Så du på noget, har du allerede gravet noget frem fra diagnostikken?
MCH: – Det første, du skal forholde dig til, er databasen. MySQL indlæses konstant og gemmer nye metrics, og når Zabbix begynder at generere en masse hændelser, går databasen i overdrive i bogstaveligt talt et par timer. Jeg har allerede fortalt dig om optimering af konfigurationen, men bogstaveligt talt i år opdaterede de hardwaren: serverne har mere end hundrede gigabyte hukommelse og diskarrays på SSD RAID'er - der er ingen mening i at vokse det lineært på lang sigt. Hvad gør vi?
MM: - Det er klart. Generelt er MySQL en LTP-database. Det er tilsyneladende ikke længere egnet til at gemme et arkiv af metrikker af vores størrelse. Lad os finde ud af det.
MCH: - Lad os!
Integration af Zabbix og Clickhouse som et resultat af hackathon
Efter nogen tid modtog vi interessante data:

Det meste af pladsen i vores database blev optaget af metrics-arkivet, og mindre end 1% blev brugt til konfiguration, skabeloner og indstillinger. På det tidspunkt havde vi drevet Big data-løsningen baseret på Clickhouse i mere end et år. Bevægelsesretningen var indlysende for os. Ved vores forårs Hackathon skrev jeg integrationen af Zabbix med Clickhouse til serveren og frontend. På det tidspunkt havde Zabbix allerede support til ElasticSearch, og vi besluttede at sammenligne dem.

Sammenligning af Clickhouse og Elasticsearch
MM: – Til sammenligning genererede vi den samme belastning, som Zabbix-serveren leverer, og så på, hvordan systemerne ville opføre sig. Vi skrev data i batches på 1000 linjer ved hjælp af CURL. Vi antog på forhånd, at Clickhouse ville være mere effektiv til den belastningsprofil, som Zabbix gør. Resultaterne oversteg endda vores forventninger:
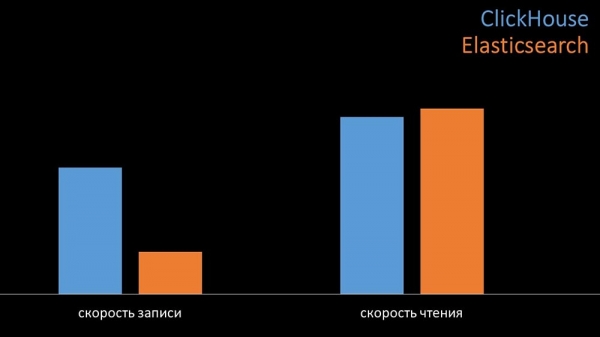
Under de samme testbetingelser skrev Clickhouse tre gange flere data. Samtidig brugte begge systemer meget effektivt (en lille mængde ressourcer), når de læste data. Men elastikker krævede en stor mængde processor ved optagelse:
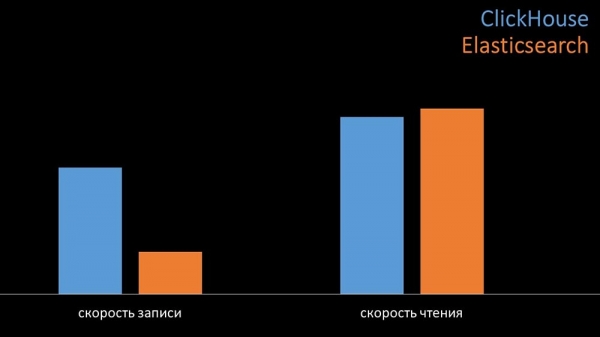
I alt var Clickhouse Elastix væsentligt overlegen med hensyn til processorforbrug og hastighed. På samme tid, på grund af datakomprimering, bruger Clickhouse 11 gange mindre på harddisken og udfører cirka 30 gange færre diskoperationer:
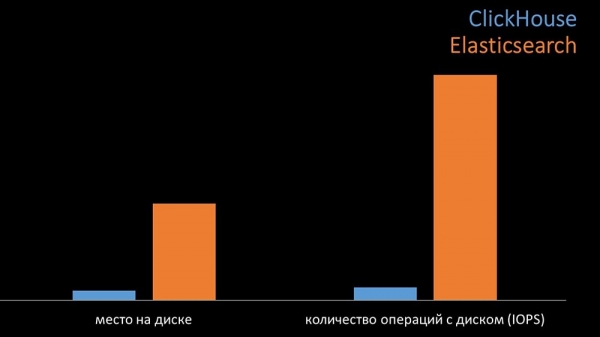
MCH: – Ja, Clickhouses arbejde med diskundersystemet er implementeret meget effektivt. Du kan bruge enorme SATA-diske til databaser og få skrivehastigheder på hundredtusindvis af linjer i sekundet. Out-of-the-box systemet understøtter sharding, replikering og er meget let at konfigurere. Vi er mere end tilfredse med dens brug hele året.
For at optimere ressourcerne kan du installere Clickhouse ved siden af din eksisterende hoveddatabase og derved spare en masse CPU-tid og diskoperationer. Vi har flyttet arkivet af metrics til eksisterende Clickhouse-klynger:
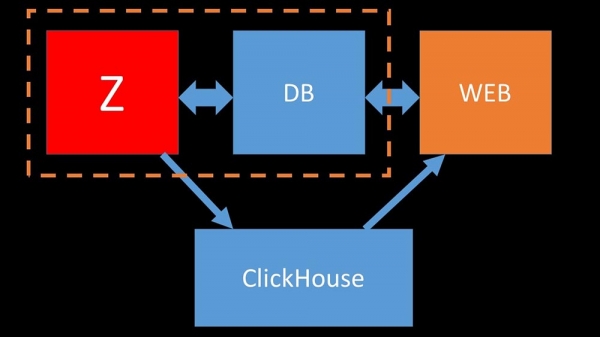
Vi lettede den primære MySQL-database så meget, at vi kunne kombinere den på én maskine med Zabbix-serveren og opgive den dedikerede server til MySQL.
Hvordan fungerer afstemning i Zabbix?
4 måneder siden
MM: – Jamen, kan vi glemme problemerne med basen?
MCH: - Det er sikkert! Et andet problem, vi skal løse, er langsom dataindsamling. Nu er alle vores 15 proxy-servere overbelastet med SNMP og polling-processer. Og der er ingen anden måde end at installere nye og nye servere.
MM: - Store. Men fortæl os først, hvordan afstemning fungerer i Zabbix?
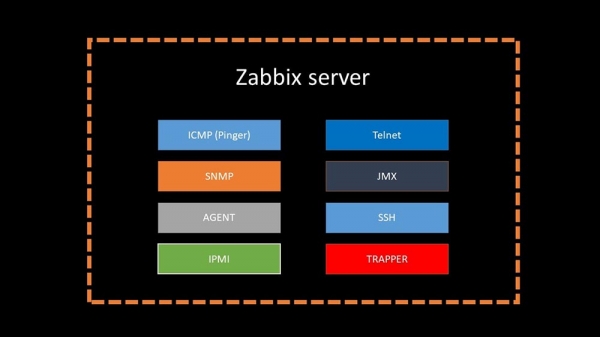
MCH: - Kort sagt, der er 20 typer metrikker og et dusin måder at opnå dem på. Zabbix kan indsamle data enten i "request-response"-tilstanden eller vente på nye data gennem "Trapper Interface".

Det er værd at bemærke, at i den originale Zabbix er denne metode (Trapper) den hurtigste.
Der er proxyservere til belastningsfordeling:
Proxyer kan udføre de samme indsamlingsfunktioner som Zabbix-serveren, modtage opgaver fra den og sende de indsamlede metrics gennem Trapper-grænsefladen. Dette er den officielt anbefalede måde at fordele belastningen på. Proxyer er også nyttige til at overvåge fjerninfrastruktur, der fungerer via NAT eller en langsom kanal:
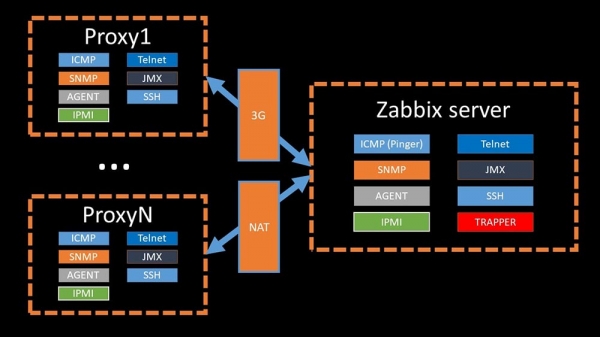
MM: – Alt er klart med arkitektur. Vi skal se på kilderne...
Et par dage senere
Historien om, hvordan nmap fping vandt
MM: "Jeg tror, jeg har gravet noget op."
MCH: - Fortæl mig!
MM: – Jeg opdagede, at når Zabbix tjekker tilgængelighed, tjekker Zabbix maksimalt 128 værter ad gangen. Jeg prøvede at øge dette tal til 500 og fjerne inter-packet intervallet i deres ping (ping) - dette fordoblede ydeevnen. Men jeg vil gerne have større tal.
MCH: – I min praksis er jeg nogle gange nødt til at tjekke tilgængeligheden af tusindvis af værter, og jeg har aldrig set noget hurtigere end nmap til dette. Jeg er sikker på, at dette er den hurtigste måde. Lad os prøve det! Vi er nødt til at øge antallet af værter markant pr. iteration.
MM: – Tjek mere end fem hundrede? 600?
MCH: - Mindst et par tusinde.
MM: - OKAY. Det vigtigste, jeg ville sige, er, at jeg fandt ud af, at de fleste afstemninger i Zabbix foregår synkront. Vi skal helt sikkert ændre det til asynkron tilstand. Så kan vi dramatisk øge antallet af målinger indsamlet af pollers, især hvis vi øger antallet af målinger pr. iteration.
MCH: - Store! Og når?
MM: – Som sædvanlig i går.
MCH: – Vi sammenlignede begge versioner af fping og nmap:
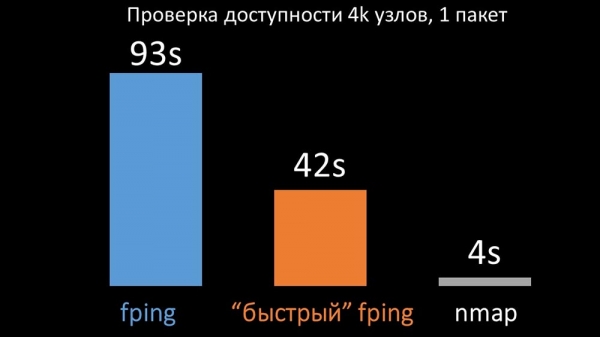
På et stort antal værter forventedes nmap at være op til fem gange mere effektivt. Da nmap kun kontrollerer tilgængelighed og responstid, flyttede vi beregningen af tab til triggere og reducerede intervallerne for tilgængelighedstjek markant. Vi fandt, at det optimale antal værter for nmap var omkring 4 tusinde pr. iteration. Nmap gjorde det muligt for os at reducere CPU-omkostningerne ved tilgængelighedstjek med tre gange og reducere intervallet fra 120 sekunder til 10.
Afstemningsoptimering
MM: »Så begyndte vi at lave pollers. Vi var hovedsageligt interesserede i SNMP-detektion og agenter. I Zabbix foretages afstemning synkront, og der er taget særlige tiltag for at øge effektiviteten af systemet. I synkron tilstand forårsager værtens utilgængelighed betydelig pollingforringelse. Der er et helt system af stater, der er specielle processer - de såkaldte unreachable pollers, som kun arbejder med unreachable værter:

Dette er en kommentar, der demonstrerer tilstandsmatricen, hele kompleksiteten af systemet af overgange, der kræves for at systemet forbliver effektivt. Derudover er selve synkron polling ret langsom:
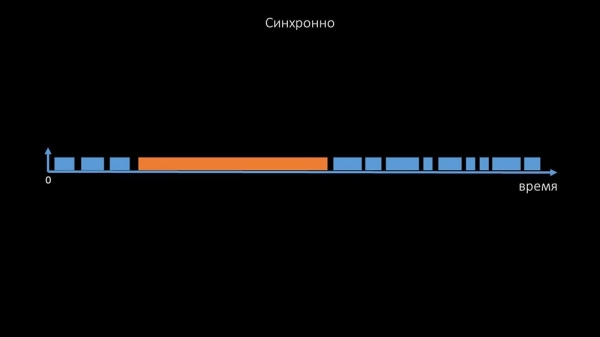
Det er grunden til, at tusindvis af poller-streams på snesevis af proxyer ikke kunne indsamle den nødvendige mængde data for os. Den asynkrone implementering løste ikke kun problemerne med antallet af tråde, men forenklede også betydeligt tilstandssystemet for utilgængelige værter, fordi for et hvilket som helst antal, der blev tjekket i en polling-iteration, var den maksimale ventetid 1 timeout:
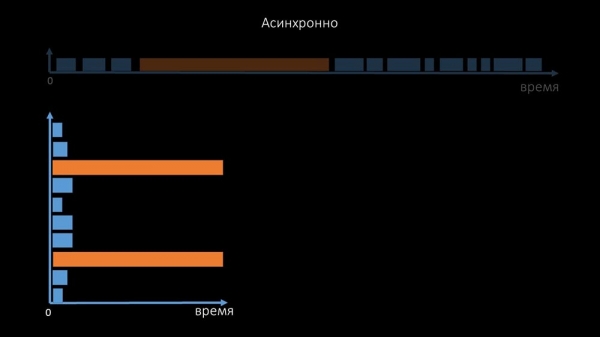
Derudover modificerede og forbedrede vi pollingsystemet for SNMP-anmodninger. Faktum er, at de fleste mennesker ikke kan svare på flere SNMP-anmodninger på samme tid. Derfor lavede vi en hybrid tilstand, når SNMP polling af den samme vært udføres asynkront:
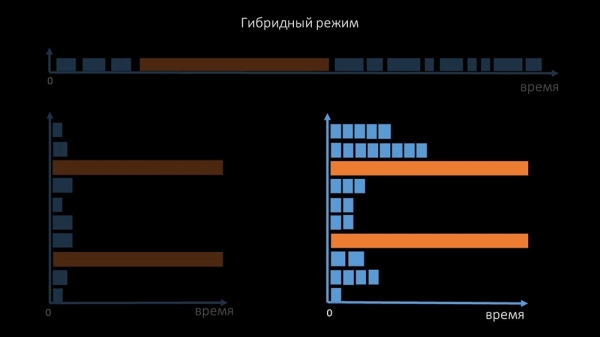
Dette gøres for hele pakken af værter. Denne tilstand er i sidste ende ikke langsommere end en fuldstændig asynkron, da polling af halvandet hundrede SNMP-værdier stadig er meget hurtigere end 1 timeout.
Vores eksperimenter har vist, at det optimale antal anmodninger i én iteration er cirka 8 tusinde med SNMP-afstemning. I alt tillod overgangen til asynkron tilstand os at fremskynde pollingydelsen med 200 gange, flere hundrede gange.
MCH: – De resulterende afstemningsoptimeringer viste, at vi ikke kun kan slippe af med alle fuldmagter, men også reducere intervallerne for mange kontroller, og der vil ikke længere være behov for fuldmagter som en måde at dele belastningen på.
For omkring tre måneder siden
Skift arkitekturen - øg belastningen!
MM: - Nå, Max, er det tid til at blive produktiv? Jeg har brug for en kraftfuld server og en god ingeniør.
MCH: - Okay, lad os planlægge det. Det er på høje tid at bevæge sig fra dødpunktet på 5 tusinde målinger i sekundet.
Morgen efter opgraderingen
MCH: - Misha, vi opdaterede os selv, men om morgenen rullede vi tilbage... Gæt hvilken hastighed vi nåede at opnå?
MM: – Maksimalt 20 tusind.
MCH: - Ja, 25! Desværre er vi lige der, hvor vi startede.
MM: - Hvorfor? Har du kørt nogen diagnose?
MCH: - Ja sikkert! Her er for eksempel en interessant top:
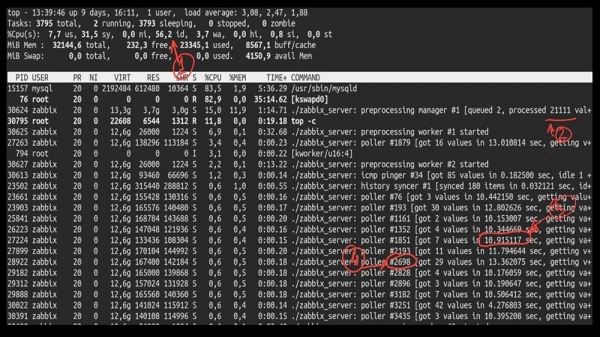
MM: - Lad os se. Jeg kan se, at vi har prøvet et stort antal afstemningstråde:
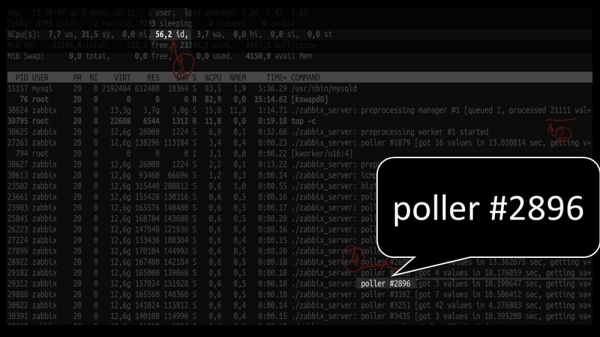
Men samtidig kunne de ikke genbruge systemet engang til det halve:
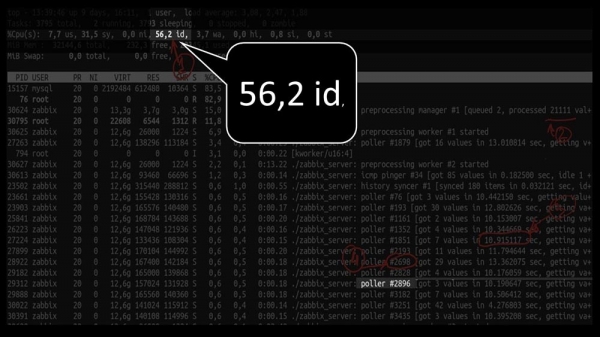
Og den samlede ydeevne er ret lille, omkring 4 tusinde målinger i sekundet:
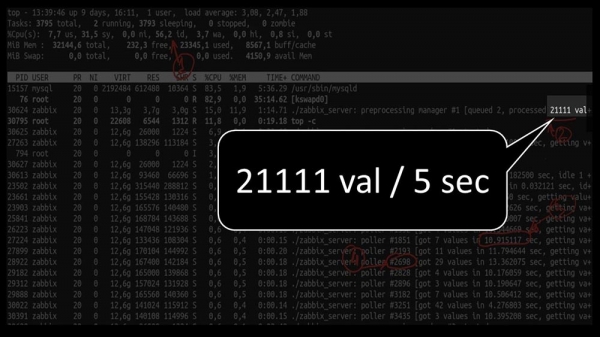
Er der andet?
MCH: – Ja, spor af en af meningsmålerne:
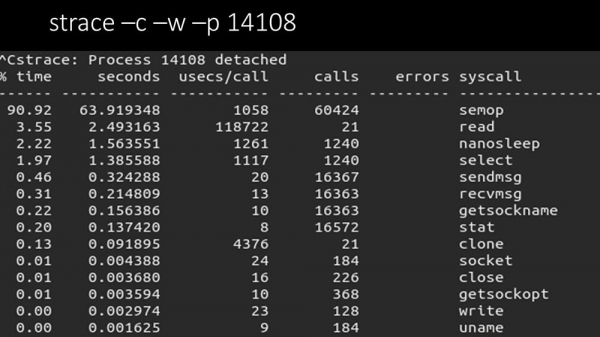
MM: – Her kan man tydeligt se, at afstemningsprocessen venter på "semaforer". Dette er låsene:
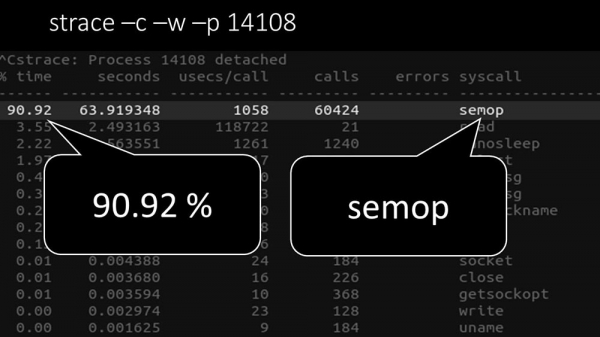
MCH: - Uklart.
MM: – Se, det ligner en situation, hvor en masse tråde forsøger at arbejde med ressourcer, som kun én kan arbejde med ad gangen. Så alt, hvad de kan gøre, er at dele denne ressource over tid:

Og den samlede ydeevne ved at arbejde med en sådan ressource er begrænset af hastigheden af en kerne:
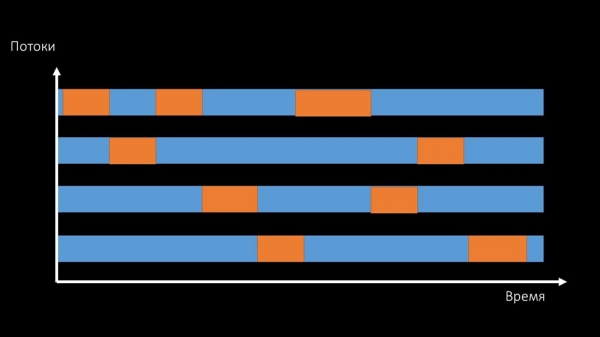
Der er to måder at løse dette problem på.
Opgrader maskinens hardware, skift til hurtigere kerner:
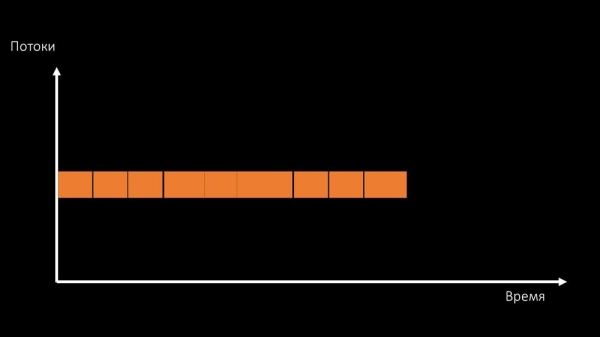
Eller ændre arkitekturen og samtidig ændre belastningen:
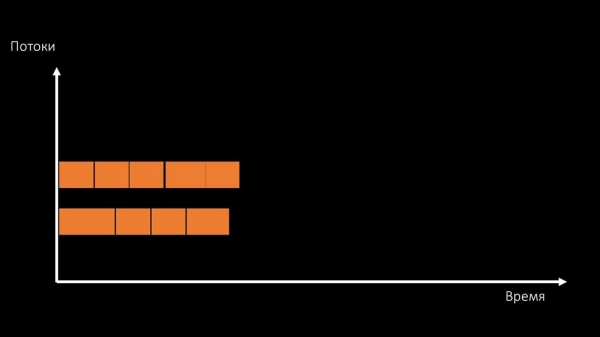
MCH: – Forresten, på testmaskinen vil vi bruge færre kerner end på kamp, men de er 1,5 gange hurtigere i frekvens per kerne!
MM: - Klart? Du skal se på serverkoden.
Datasti i Zabbix server
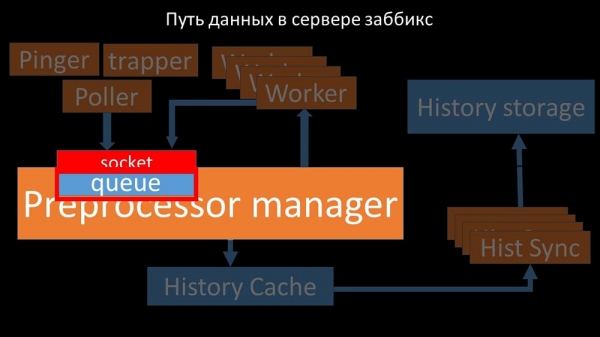
MCH: – For at finde ud af det, begyndte vi at analysere, hvordan data overføres inde i Zabbix-serveren:
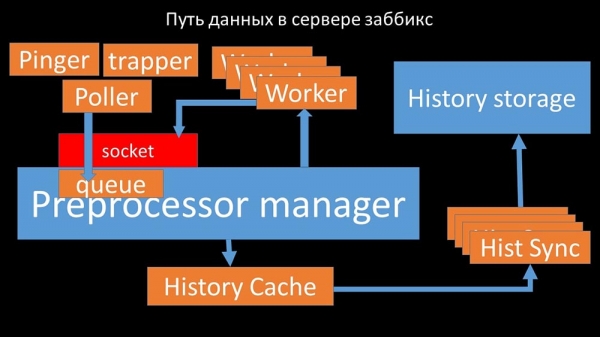
Fedt billede, ikke? Lad os gennemgå det trin for trin for at gøre det mere eller mindre klart. Der er tråde og tjenester, der er ansvarlige for at indsamle data:
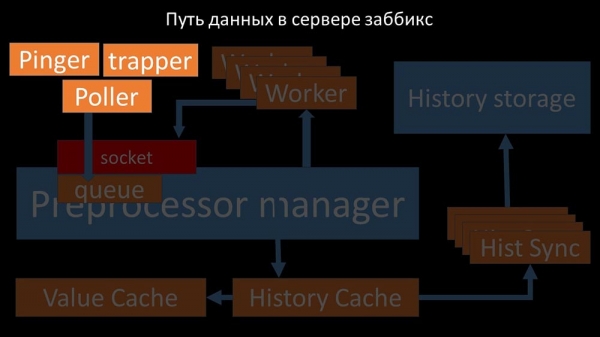
De overfører de indsamlede metrics via en socket til Preprocessor-manageren, hvor de gemmes i en kø:
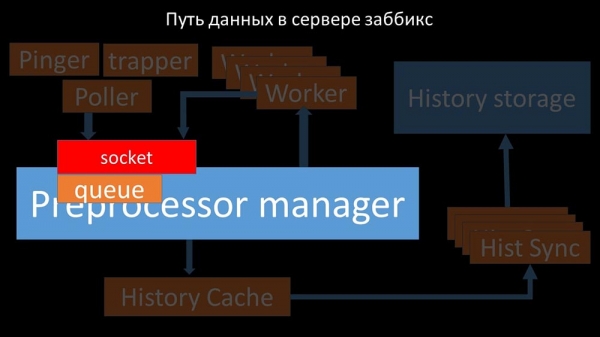
"Preprocessor manager" transmitterer data til sine medarbejdere, som udfører forbehandlingsinstruktioner og returnerer dem tilbage gennem den samme socket:
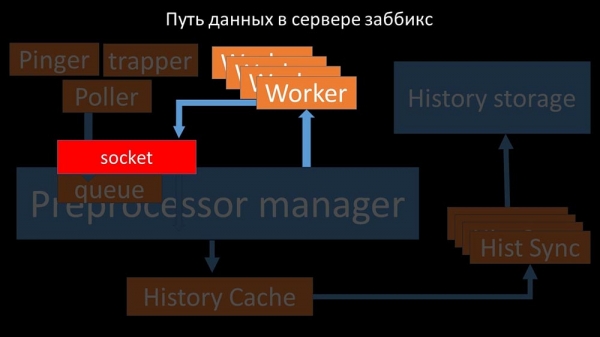
Herefter gemmer præprocessormanageren dem i historiecachen:
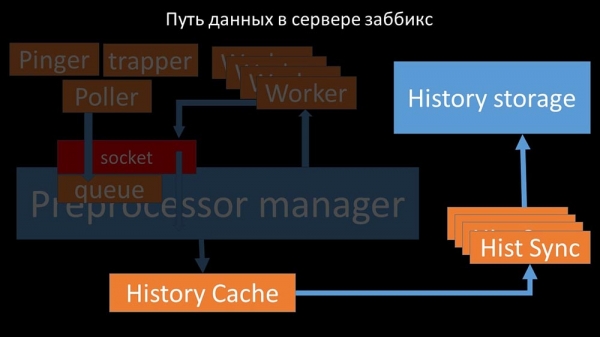
Derfra er de taget af historiesænkere, som udfører en hel del funktioner: for eksempel at beregne triggere, fylde værdicachen og, vigtigst af alt, gemme metrics i historielageret. Generelt er processen kompleks og meget forvirrende.
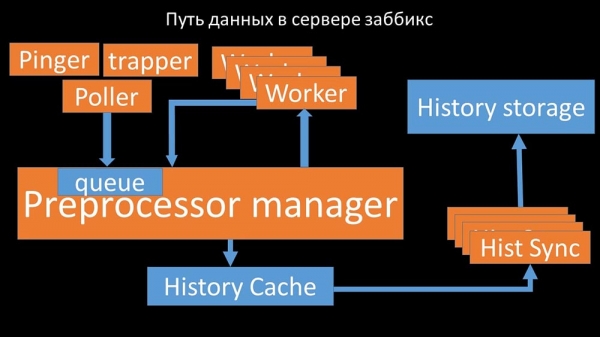
MM: – Det første vi så var, at de fleste tråde konkurrerer om den såkaldte "konfigurationscache" (hukommelsesområdet, hvor alle serverkonfigurationer er gemt). Tråde, der er ansvarlige for at indsamle data, blokerer især meget:
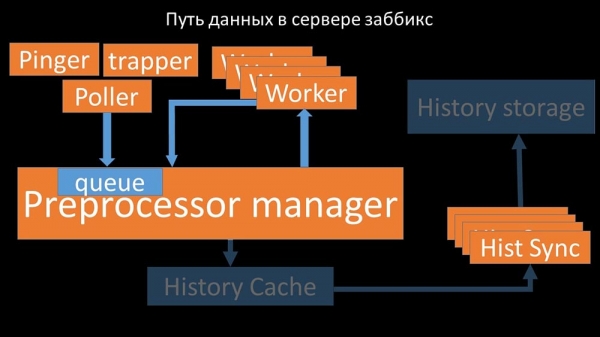
...da konfigurationen ikke kun gemmer metrics med deres parametre, men også køer, hvorfra pollere tager information om, hvad de skal gøre næste gang. Når der er mange pollers, og en blokerer konfigurationen, venter de andre på anmodninger:
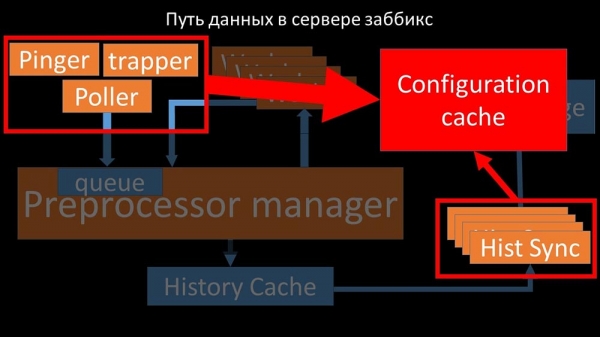
Pollere bør ikke være i konflikt
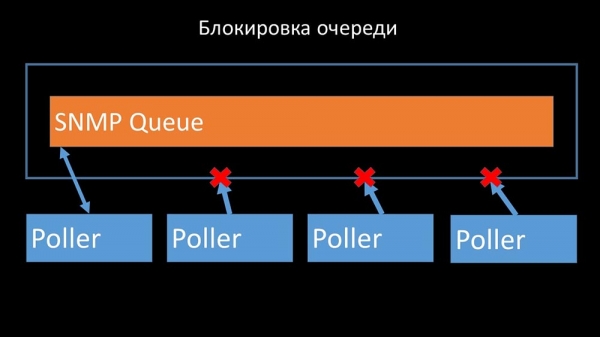
Derfor var det første, vi gjorde, at dele køen i 4 dele og lade pollere blokere disse køer, disse dele på samme tid, under sikre forhold:
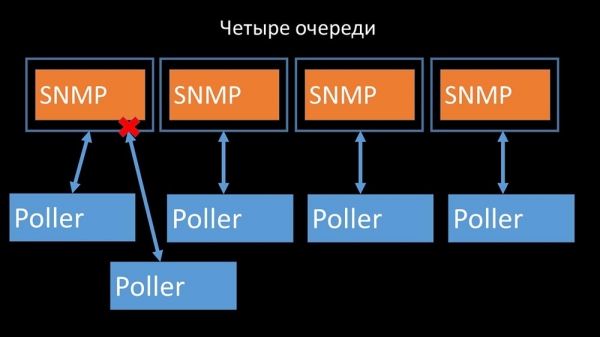
Dette fjernede konkurrencen om konfigurationscachen, og pollers hastighed steg markant. Men så stødte vi på det faktum, at præprocessor-manageren begyndte at akkumulere en kø af job:
Forbehandlerleder skal kunne prioritere
Dette skete i tilfælde, hvor han manglede præstationer. Så kunne han kun akkumulere anmodninger fra dataindsamlingsprocesser og tilføje deres buffer, indtil den opbrugte al hukommelsen og styrtede ned:
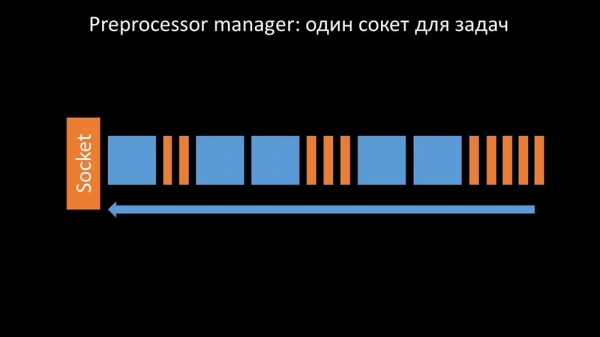
For at løse dette problem tilføjede vi en anden socket, der var dedikeret specifikt til arbejdere:
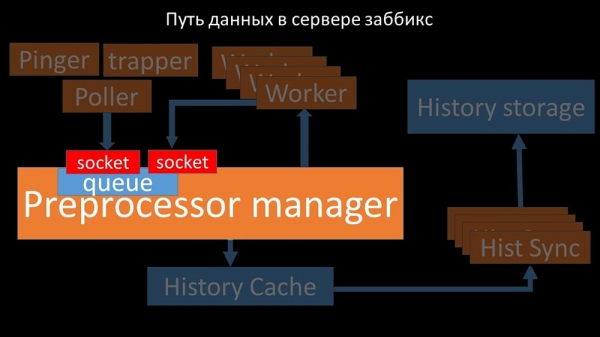
Således havde præprocessorlederen mulighed for at prioritere sit arbejde, og hvis bufferen vokser, er opgaven at bremse fjernelsen, hvilket giver arbejderne mulighed for at tage denne buffer:
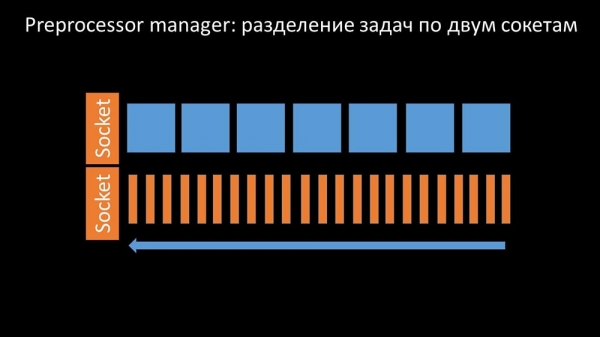
Så opdagede vi, at en af årsagerne til afmatningen var arbejderne selv, da de konkurrerede om en ressource, der var fuldstændig ligegyldig for deres arbejde. Vi dokumenterede dette problem som en fejlrettelse, og det er allerede blevet løst i nye versioner af Zabbix:
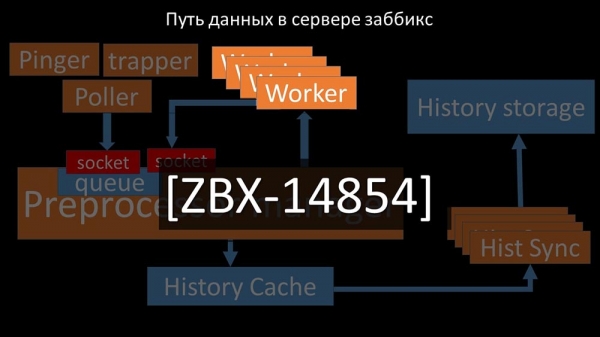
Vi øger antallet af stikkontakter - vi får resultatet
Ydermere blev selve præprocessormanageren en flaskehals, da det er én tråd. Den hvilede på kernehastigheden, hvilket gav en maksimal hastighed på omkring 70 tusinde meter i sekundet:
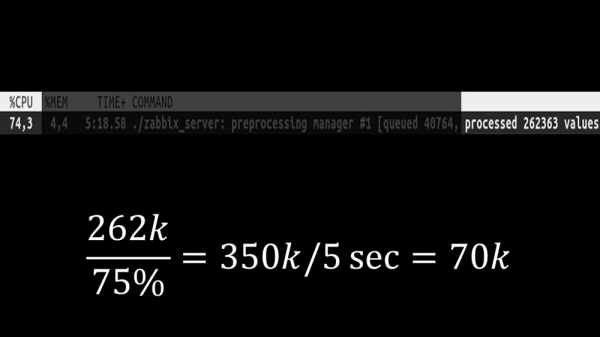
Derfor lavede vi fire, med fire sæt fatninger, arbejdere:
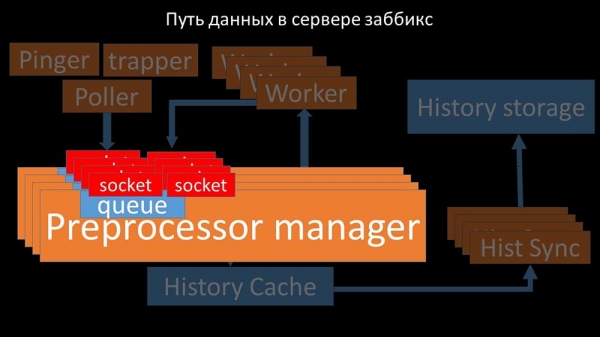
Og dette gjorde det muligt for os at øge hastigheden til cirka 130 tusinde målinger:
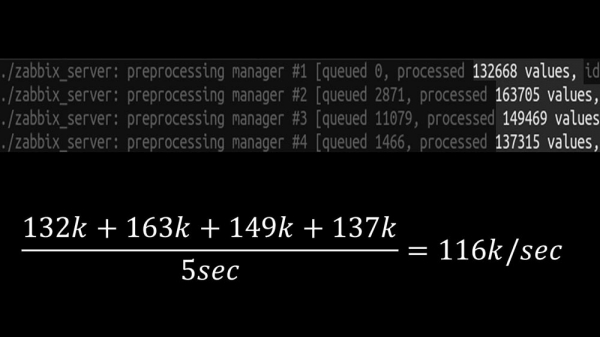
Vækstens ikke-linearitet forklares ved, at der er opstået konkurrence om historiecachen. 4 preprocessor-managere og historiesænkere konkurrerede om det. På dette tidspunkt modtog vi cirka 130 tusinde målinger i sekundet på testmaskinen, og brugte den af cirka 95 % af processoren:
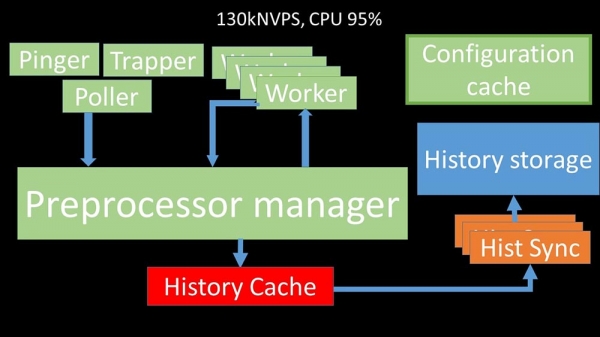
For cirka 2,5 måneder siden
Afvisning fra snmp-community øgede NVP'er med halvanden gange
MM: – Max, jeg skal bruge en ny testbil! Vi passer ikke længere ind i den nuværende.
MCH: - Hvad har du nu?
MM: – Nu – 130 NVP'er og en hyldeklar processor.
MCH: - Wow! Fedt nok! Vent, jeg har to spørgsmål. Ifølge mine beregninger er vores behov omkring 15-20 tusinde målinger i sekundet. Hvorfor har vi brug for mere?
MM: "Jeg vil gøre arbejdet færdigt." Jeg vil gerne se, hvor meget vi kan presse ud af dette system.
MCH: - Men…
MM: "Men det er ubrugeligt for erhvervslivet."
MCH: - Det er klart. Og det andet spørgsmål: kan vi støtte det, vi har nu på egen hånd, uden hjælp fra en udvikler?
MM: - Det tror jeg ikke. Det er et problem at ændre, hvordan konfigurationscachen fungerer. Det påvirker ændringer i de fleste tråde og er ret svært at vedligeholde. Mest sandsynligt vil det være meget svært at vedligeholde det.
MCH: "Så har vi brug for en form for alternativ."
MM: - Der er sådan en mulighed. Vi kan skifte til hurtige kerner, mens vi opgiver det nye låsesystem. Vi vil stadig få en præstation på 60-80 tusinde målinger. Samtidig kan vi lade resten af koden ligge. Clickhouse og asynkron polling vil fungere. Og det vil være nemt at vedligeholde.
MCH: - Fantastiske! Jeg foreslår, at vi stopper her.
Efter at have optimeret serversiden, kunne vi endelig lancere den nye kode i produktion. Vi opgav nogle af ændringerne til fordel for at skifte til en maskine med hurtige kerner og minimere antallet af kodeændringer. Vi har også forenklet konfigurationen og elimineret makroer i dataelementer, hvor det er muligt, da de introducerer yderligere låsning.

For eksempel, at opgive snmp-community-makroen, som ofte findes i dokumentation og eksempler, gjorde det i vores tilfælde muligt at fremskynde NVP'er yderligere med omkring 1,5 gange.
Efter to dage i produktion
Fjernelse af hændelseshistorik pop-ups
MCH: – Misha, vi har brugt systemet i to dage, og alt fungerer. Men kun når alt virker! Vi havde planlagt arbejde med overførsel af et ret stort segment af netværket, og vi tjekkede igen med hænderne, hvad der gik op, og hvad der ikke gik.
MM: - Kan ikke være! Vi tjekkede alt 10 gange. Serveren håndterer selv fuldstændig netværkstilgængelighed øjeblikkeligt.
MCH: - Ja, jeg forstår alt: server, database, top, austat, logs - alt er hurtigt... Men vi ser på webgrænsefladen, og der er en processor "i hylden" på serveren og dette:

MM: - Det er klart. Lad os se på nettet. Vi fandt ud af, at i en situation, hvor der var et stort antal aktive hændelser, begyndte de fleste live-widgets at arbejde meget langsomt:
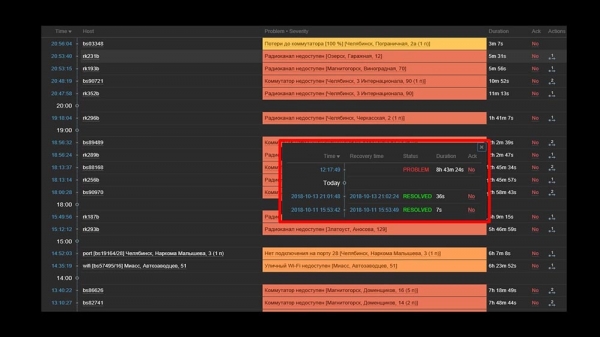
Årsagen til dette var genereringen af hændelseshistorik pop-ups, der genereres for hvert element på listen. Derfor opgav vi genereringen af disse vinduer (kommenterede 5 linjer i koden), og dette løste vores problemer.
Indlæsningstiden for widgets, selv når den er fuldstændig utilgængelig, er reduceret fra flere minutter til de acceptable 10-15 sekunder for os, og historikken kan stadig ses ved at klikke på tiden:
Efter arbejde. 2 måneder siden
MCH: - Misha, tager du afsted? Vi skal snakke.
MM: - Det havde jeg ikke tænkt mig. Noget med Zabbix igen?
MCH: - Nej, slap af! Jeg ville bare sige: alt fungerer, tak! Jeg har fået en øl.
Zabbix er effektiv
Zabbix er et ret universelt og rigt system og funktion. Den kan bruges til små installationer ud af boksen, men efterhånden som behovet vokser, skal den optimeres. For at gemme et stort arkiv af metrics skal du bruge et passende lager:
- du kan bruge indbyggede værktøjer i form af integration med Elasticsearch eller uploade historik til tekstfiler (tilgængelig fra version XNUMX);
- Du kan drage fordel af vores erfaring og integration med Clickhouse.
For dramatisk at øge hastigheden for indsamling af metrikker, indsamle dem ved hjælp af asynkrone metoder og transmittere dem gennem trapper-grænsefladen til Zabbix-serveren; eller du kan bruge en patch til at gøre Zabbix pollers asynkrone.
Zabbix er skrevet i C og er ret effektiv. Løsning af flere arkitektoniske flaskehalse giver dig mulighed for yderligere at øge dens ydeevne og, efter vores erfaring, opnå mere end 100 tusinde målinger på en enkelt-processor maskine.

Det samme Zabbix-plaster
MM: – Jeg vil gerne tilføje et par punkter. Hele den aktuelle rapport, alle test, numre er angivet for den konfiguration, vi bruger. Vi tager nu cirka 20 tusinde målinger i sekundet fra det. Hvis du forsøger at forstå, om dette vil virke for dig, kan du sammenligne. Det, der blev diskuteret i dag, er lagt ud på GitHub i form af en patch:

Patchen indeholder:
- fuld integration med Clickhouse (både Zabbix-server og frontend);
- løse problemer med præprocessormanageren;
- asynkron polling.
Patchen er kompatibel med alle version 4, inklusive lts. Mest sandsynligt, med minimale ændringer vil det fungere på version 3.4.
Tak for din opmærksomhed.
R'RѕRїSЂRѕSЃS <
Spørgsmål fra salen (i det følgende – A): – God eftermiddag! Fortæl mig venligst, har du planer om intensiv interaktion med Zabbix-teamet eller med dem med dig, så dette ikke er et plaster, men normal adfærd hos Zabbix?
MM: – Ja, vi vil helt sikkert begå nogle af ændringerne. Noget vil ske, noget vil forblive i plasteret.
EN: – Mange tak for den fremragende rapport! Fortæl mig venligst, efter at have installeret patchen, vil support fra Zabbix forblive, og hvordan fortsætter man med at opdatere til højere versioner? Vil det være muligt at opdatere Zabbix efter din patch til 4.2, 5.0?
MM: - Jeg kan ikke sige noget om støtte. Hvis jeg var Zabbix teknisk support, ville jeg nok sige nej, fordi dette er en andens kode. Hvad angår 4.2-kodebasen, er vores holdning: "Vi vil bevæge os med tiden, og vi vil opdatere os selv om den næste version." Derfor vil vi i nogen tid poste en patch til opdaterede versioner. Jeg sagde allerede i rapporten: antallet af ændringer med versioner er stadig ret lille. Jeg tror, at overgangen fra 3.4 til 4 tog os omkring 15 minutter. Der ændrede sig noget, men ikke særlig vigtigt.
EN: – Så du planlægger at understøtte din patch, og du kan trygt installere den i produktionen og modtage opdateringer på en eller anden måde i fremtiden?
MM: – Vi anbefaler det stærkt. Dette løser en masse problemer for os.
MCH: - Endnu en gang vil jeg gerne gøre opmærksom på, at de ændringer, der ikke vedrører arkitekturen og ikke vedrører blokering eller køer, er modulære, de er i separate moduler. Selv med mindre ændringer kan du nemt vedligeholde dem.
MM: – Hvis du er interesseret i detaljerne, så bruger “Clickhouse” det såkaldte historiebibliotek. Det er ubundet - det er en kopi af Elastics-understøttelsen, det vil sige, det kan konfigureres. Afstemning ændrer kun meningsmålere. Vi tror på, at dette vil virke i lang tid.
EN: - Mange tak. Fortæl mig, er der dokumentation for ændringerne?

MM: – Dokumentation er en patch. Det er klart, med introduktionen af Clickhouse, med introduktionen af nye typer pollere, opstår der nye konfigurationsmuligheder. Linket fra sidste slide har en kort beskrivelse af, hvordan man bruger det.
Om at erstatte fping med nmap
EN: – Hvordan implementerede du endelig dette? Kan du give specifikke eksempler: har du strappere og et eksternt script? Hvad ender med at tjekke et så stort antal værter så hurtigt? Hvordan miner du disse værter? Skal vi fodre dem for at nmap på en eller anden måde, få dem et sted fra, sætte dem i, køre noget?
MM: - Fedt nok. Et meget korrekt spørgsmål! Pointen er dette. Vi modificerede biblioteket (ICMP ping, en del af Zabbix) til ICMP-tjek, som angiver antallet af pakker - en (1), og koden forsøger at bruge nmap. Det vil sige, at dette er Zabbix' interne arbejde, som er blevet pingerens interne arbejde. Derfor kræves ingen synkronisering eller brug af en fangemaskine. Dette blev gjort med vilje for at forlade systemet intakt og ikke skulle beskæftige sig med synkroniseringen af to databasesystemer: hvad skal man tjekke, uploade gennem polleren, og er vores upload ødelagt?.. Dette er meget enklere.
EN: – Virker det også for fuldmagter?
MM: – Ja, men vi tjekkede ikke. Afstemningskoden er den samme i både Zabbix og serveren. Bør virke. Lad mig understrege endnu en gang: Systemets ydeevne er sådan, at vi ikke har brug for en proxy.
MCH: – Det korrekte svar på spørgsmålet er: "Hvorfor har du brug for en proxy med sådan et system?" Kun på grund af NAT eller overvågning gennem en slags langsom kanal...
EN: – Og du bruger Zabbix som allertor, hvis jeg forstår det rigtigt. Eller har din grafik (hvor arkivlaget er) flyttet til et andet system, såsom Grafana? Eller bruger du ikke denne funktionalitet?
MM: – Jeg vil endnu en gang understrege: Vi har opnået fuldstændig integration. Vi hælder historie ind i Clickhouse, men samtidig har vi ændret php-frontenden. Php-frontenden går til Clickhouse og laver al grafikken derfra. Samtidig har vi, for at være ærlig, en del, der bygger data i andre grafiske displaysystemer fra det samme Clickhouse, ud fra de samme Zabbix-data.
MCH: – Også i "Grafan".
Hvordan blev beslutninger truffet om allokering af ressourcer?
EN: – Del lidt af dit indre køkken. Hvordan blev beslutningen truffet om, at det var nødvendigt at allokere ressourcer til seriøs forarbejdning af produktet? Disse er generelt visse risici. Og fortæl mig venligst, i forbindelse med det faktum, at du vil støtte nye versioner: Hvordan retfærdiggør denne beslutning fra et ledelsesmæssigt synspunkt?
MM: - Vi fortalte åbenbart ikke historiens drama særlig godt. Vi befandt os i en situation, hvor noget skulle gøres, og vi gik i det væsentlige med to parallelle teams:
- Den ene var at lancere et overvågningssystem ved hjælp af nye metoder: overvågning som en service, et standardsæt af open source-løsninger, som vi kombinerer og derefter forsøger at ændre forretningsprocessen for at kunne arbejde med det nye overvågningssystem.
- Samtidig havde vi en entusiastisk programmør, der gjorde dette (om sig selv). Det skete, at han vandt.
EN: – Og hvad er holdets størrelse?
MCH: - Hun er foran dig.
EN: – Så som altid har du brug for en passioneret?
MM: - Jeg ved ikke, hvad en passioneret er.
EN: - I dette tilfælde, åbenbart dig. Mange tak, du er fantastisk.
MM: - Tak.
Om patches til Zabbix
EN: – For et system, der bruger proxyer (for eksempel i nogle distribuerede systemer), er det muligt at tilpasse og lappe f.eks. pollers, proxyer og delvist selve Zabbix preprocessor; og deres interaktion? Er det muligt at optimere eksisterende udviklinger til et system med flere proxyer?
MM: – Jeg ved, at Zabbix-serveren er samlet ved hjælp af en proxy (koden er kompileret og hentet). Vi har ikke testet dette i produktionen. Jeg er ikke sikker på dette, men jeg tror, at præprocessormanageren ikke bruges i proxyen. Proxyens opgave er at tage et sæt metrics fra Zabbix, flette dem (den registrerer også konfigurationen, den lokale database) og give det tilbage til Zabbix-serveren. Serveren selv vil derefter udføre forbehandlingen, når den modtager den.
Interessen for fuldmagter er forståelig. Vi tjekker det ud. Dette er et interessant emne.
EN: – Ideen var denne: Hvis du kan patche pollere, kan du patch dem på proxyen og patch interaktionen med serveren og tilpasse præprocessoren til disse formål kun på serveren.
MM: - Jeg tror, det er endnu nemmere. Du tager koden, anvender en patch og derefter konfigurerer den, som du har brug for - saml proxyservere (for eksempel med ODBC) og distribuer den patchede kode på tværs af systemer. Hvor det er nødvendigt - indhent en proxy, hvor det er nødvendigt - en server.
EN: - Mest sandsynligt behøver du ikke at patche proxy-transmissionen til serveren yderligere?
MCH: - Nej, det er standard.
MM: – Faktisk lød en af ideerne ikke. Vi har altid bevaret en balance mellem eksplosionen af ideer og mængden af ændringer og let support.

Nogle annoncer 🙂
Tak fordi du blev hos os. Kan du lide vores artikler? Vil du se mere interessant indhold? Støt os ved at afgive en ordre eller anbefale til venner, , en unik analog af entry-level servere, som blev opfundet af os til dig: (tilgængelig med RAID1 og RAID10, op til 24 kerner og op til 40 GB DDR4).
Dell R730xd 2 gange billigere i Equinix Tier IV datacenter i Amsterdam? Kun her i Holland! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - fra $99! Læse om
Kilde: www.habr.com
