

Vi har udviklet et datacenternetværksdesign, der tillader udrulning af computerklynger større end 100 servere med en maksimal båndbredde på over en petabyte pr. sekund.
Fra Dmitry Afanasyevs rapport vil du lære om de grundlæggende principper for det nye design, skaleringstopologier, de problemer, der opstår med dette, muligheder for at løse dem, funktionerne ved routing og skalering af videresendelsesplanfunktionerne for moderne netværksenheder i "tæt forbundet" topologier med et stort antal ECMP-ruter. Derudover talte Dima kort om organiseringen af ekstern tilslutning, det fysiske lag, kabelsystemet og måder at øge kapaciteten yderligere på.
- God eftermiddag alle sammen! Mit navn er Dmitry Afanasyev, jeg er netværksarkitekt hos Yandex og designer primært datacenternetværk.

Min historie vil handle om det opdaterede netværk af Yandex-datacentre. Det er i høj grad en udvikling af det design, vi havde, men samtidig er der nogle nye elementer. Dette er en oversigtspræsentation, fordi der var meget information, der skulle pakkes ind i en lille mængde tid. Vi starter med at vælge en logisk topologi. Derefter vil der være et overblik over kontrolplanet og problemer med dataplans skalerbarhed, et valg af hvad der skal ske på det fysiske niveau, og vi vil se på nogle funktioner ved enhederne. Lad os røre lidt ved, hvad der sker i et datacenter med MPLS, som vi talte om for noget tid siden.

Så hvad er Yandex med hensyn til belastninger og tjenester? Yandex er en typisk hyperscaler. Ser vi på brugerne, behandler vi primært brugerønsker. Også diverse streamingtjenester og dataoverførsel, for vi har også lagertjenester. Hvis det er tættere på backend, så vises infrastrukturbelastninger og tjenester der, såsom distribueret objektlagring, datareplikering og selvfølgelig vedvarende køer. En af hovedtyperne af arbejdsbelastninger er MapReduce og lignende systemer, strømbehandling, maskinlæring mv.

Hvordan er infrastrukturen, hvorpå alt dette sker? Igen er vi en ret typisk hyperscaler, selvom vi måske er lidt tættere på den mindre hyperscaler side af spektret. Men vi har alle egenskaberne. Vi bruger råvarehardware og horisontal skalering, hvor det er muligt. Vi har fuld ressourcepooling: Vi arbejder ikke med individuelle maskiner, individuelle stativer, men kombinerer dem til en stor pulje af udskiftelige ressourcer med nogle ekstra services, der omhandler planlægning og allokering, og arbejder med hele denne pulje.
Så vi har det næste niveau - operativsystemet på computerklyngeniveau. Det er meget vigtigt, at vi har fuld kontrol over den teknologistak, vi bruger. Vi kontrollerer slutpunkterne (værterne), netværket og softwarestakken.
Vi har adskillige store datacentre i Rusland og i udlandet. De er forbundet via en backbone, der bruger MPLS-teknologi. Vores interne infrastruktur er næsten udelukkende bygget på IPv6, men da vi skal betjene ekstern trafik, som stadig primært kommer over IPv4, skal vi på en eller anden måde levere anmodninger, der kommer over IPv4, til frontend.servere, og også gå lidt til det eksterne IPv4-internet - for eksempel til indeksering.
De sidste par iterationer af datacenternetværksdesign har brugt flerlags Clos-topologier og er kun L3. Vi forlod L2 for et stykke tid siden og åndede lettet op. Endelig omfatter vores infrastruktur hundredtusindvis af computer (server) instanser. Den maksimale klyngestørrelse for nogen tid siden var omkring 10 tusinde servere. Dette skyldes i høj grad, hvordan de samme operativsystemer på klyngeniveau, planlæggere, ressourceallokering osv. kan fungere. Da der er sket fremskridt på siden af infrastruktursoftware, er målstørrelsen nu omkring 100 tusinde servere i en computerklynge, og Vi har en opgave - at være i stand til at bygge netværksfabrikker, der tillader effektiv ressourcepooling i sådan en klynge.

Hvad ønsker vi af et datacenternetværk? Først og fremmest er der en masse billig og nogenlunde ensartet fordelt båndbredde. Fordi netværket er rygraden, hvorigennem vi kan samle ressourcer. Den nye målstørrelse er omkring 100 tusinde servere i en klynge.
Vi ønsker selvfølgelig også et skalerbart og stabilt kontrolplan, for på så stor en infrastruktur opstår der en masse hovedpine selv fra blot tilfældige hændelser, og vi ønsker ikke, at kontrolplanet også giver os hovedpine. Samtidig vil vi minimere staten i det. Jo mindre tilstanden er, jo bedre og mere stabil virker alt, og jo lettere er det at diagnosticere.
Selvfølgelig har vi brug for automatisering, for det er umuligt at styre sådan en infrastruktur manuelt, og det har været umuligt i nogen tid. Vi har brug for driftsstøtte så meget som muligt og CI/CD support i det omfang det kan ydes.
Med sådanne størrelser af datacentre og klynger er opgaven med at understøtte trinvis implementering og udvidelse uden afbrydelse af tjenesten blevet ret akut. Hvis de på klynger på en størrelse på tusinde maskiner, måske tæt på ti tusinde maskiner, stadig kunne rulles ud som én operation - det vil sige, vi planlægger en udvidelse af infrastrukturen, og flere tusinde maskiner tilføjes som én operation, så opstår en klynge på en størrelse på hundrede tusinde maskiner ikke umiddelbart sådan, den bygges over en periode. Og det er ønskværdigt, at alt, hvad der allerede er pumpet ud, den infrastruktur, der er blevet indsat, skal være tilgængeligt.
Og et krav, som vi havde og forlod: understøttelse af multitenancy, det vil sige virtualisering eller netværkssegmentering. Nu behøver vi ikke at gøre dette på netværksstrukturniveau, fordi shardingen er gået til værterne, og det har gjort skalering meget let for os. Takket være IPv6 og et stort adresserum behøvede vi ikke at bruge duplikerede adresser i den interne infrastruktur; al adressering var allerede unik. Og takket være det faktum, at vi har taget filtrering og netværkssegmentering til værterne, behøver vi ikke oprette nogen virtuelle netværksenheder i datacenternetværk.

En meget vigtig ting er, hvad vi ikke har brug for. Hvis nogle funktioner kan fjernes fra netværket, gør dette livet meget lettere og udvider som regel udvalget af tilgængeligt udstyr og software, hvilket gør diagnosticering meget enkel.
Så hvad er det, vi ikke har brug for, hvad har vi kunnet give afkald på, ikke altid med glæde på det tidspunkt, det skete, men med stor lettelse, når processen er afsluttet?
Først og fremmest at opgive L2. Vi har ikke brug for L2, hverken ægte eller emuleret. Ubrugt hovedsagelig på grund af det faktum, at vi kontrollerer applikationsstakken. Vores applikationer er horisontalt skalerbare, de arbejder med L3-adressering, de er ikke særlig bekymrede over, at en enkelt instans er gået ud, de ruller simpelthen en ny ud, den behøver ikke at blive rullet ud på den gamle adresse, fordi der er en separat serviceniveau opdagelse og overvågning af maskiner placeret i klyngen. Vi uddelegerer ikke denne opgave til netværket. Netværkets opgave er at levere pakker fra punkt A til punkt B.
Vi har heller ikke situationer, hvor adresser bevæger sig inden for netværket, og det skal overvåges. I mange designs er dette typisk nødvendigt for at understøtte VM-mobilitet. Vi bruger ikke mobiliteten af virtuelle maskiner i den interne infrastruktur i det store Yandex, og desuden mener vi, at selvom dette gøres, bør det ikke ske med netværksunderstøttelse. Hvis det virkelig skal gøres, skal det gøres på værtsniveau, og push-adresser, der kan migrere til overlejringer, for ikke at røre ved eller lave for mange dynamiske ændringer i selve underlagets routingsystem (transportnetværk) .
En anden teknologi, som vi ikke bruger, er multicast. Hvis du vil, kan jeg fortælle dig i detaljer hvorfor. Dette gør livet meget lettere, for hvis nogen har beskæftiget sig med det og set på præcis, hvordan multicast-kontrolplanet ser ud, i alle undtagen de simpleste installationer, er dette en stor hovedpine. Og desuden er det svært at finde en velfungerende open source-implementering, f.eks.
Til sidst designer vi vores netværk, så de ikke ændrer sig for meget. Vi kan regne med, at strømmen af eksterne hændelser i routingsystemet er lille.

Hvilke problemer opstår, og hvilke begrænsninger skal der tages højde for, når vi udvikler et datacenternetværk? Omkostninger, selvfølgelig. Skalerbarhed, det niveau, vi ønsker at vokse til. Behovet for at udvide uden at stoppe tjenesten. Båndbredde, tilgængelighed. Synlighed af, hvad der sker på netværket for overvågningssystemer, for operationelle teams. Automatiseringsstøtte - igen, så meget som muligt, da forskellige opgaver kan løses på forskellige niveauer, herunder indførelse af yderligere lag. Nå, ikke [muligvis] afhængig af leverandører. Selvom det i forskellige historiske perioder, afhængigt af hvilket afsnit du ser på, var denne uafhængighed lettere eller sværere at opnå. Hvis vi tager et tværsnit af netværksenhedschips, så var det indtil for nylig meget betinget at tale om uafhængighed fra leverandører, hvis vi også ønskede chips med høj gennemstrømning.
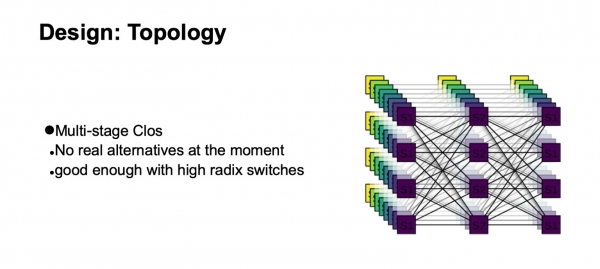
Hvilken logisk topologi vil vi bruge til at bygge vores netværk? Dette vil være en Clos på flere niveauer. Faktisk er der ingen reelle alternativer i øjeblikket. Og Clos-topologien er ganske god, selv sammenlignet med forskellige avancerede topologier, der er mere i området af akademisk interesse nu, hvis vi har store radix-switche.
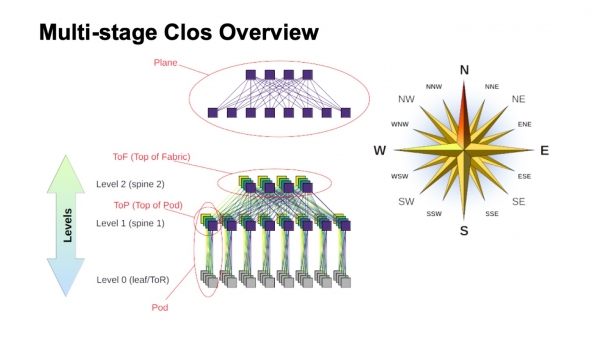
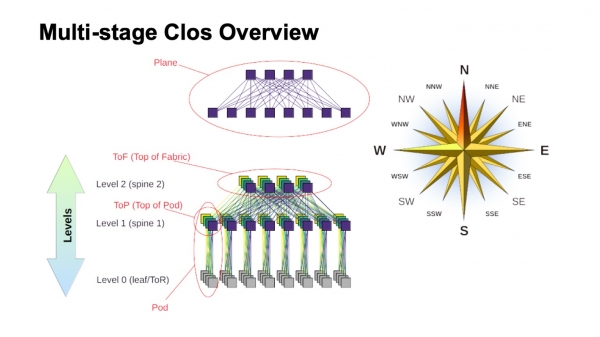
Hvordan er et Clos-netværk på flere niveauer groft opbygget, og hvad hedder de forskellige elementer i det? Først og fremmest steg vinden, for at orientere dig, hvor er nord, hvor er syd, hvor er øst, hvor er vest. Net af denne type bygges normalt af dem, der har meget stor vest-øst trafik. Hvad angår de resterende elementer, er der øverst en virtuel switch samlet af mindre switches. Dette er hovedideen med rekursiv konstruktion af Clos-netværk. Vi tager elementer med en form for radix og forbinder dem, så det vi får kan betragtes som en switch med en større radix. Hvis du har brug for endnu mere, kan proceduren gentages.
I tilfælde, for eksempel med to-niveau Clos, hvor det er muligt klart at identificere komponenter, der er lodrette i mit diagram, kaldes de normalt fly. Hvis vi skulle bygge en Clos med tre niveauer af rygsøjleafbrydere (som alle ikke er grænse- eller ToR-kontakter, og som kun bruges til transit), så ville flyene se mere komplekse ud; to-niveauer ser præcis sådan ud. Vi kalder en blok af ToR- eller bladafbrydere, og de første niveaus rygsøjlekontakter forbundet med dem for en Pod. Spine switches på spine-1 niveauet i toppen af Pod'en er toppen af Pod, toppen af Pod'en. Kontakterne, der er placeret i toppen af hele fabrikken, er det øverste lag af fabrikken, Top of fabric.

Selvfølgelig opstår spørgsmålet: Clos-netværk er blevet bygget i nogen tid, selve ideen kommer generelt fra tiden med klassisk telefoni, TDM-netværk. Måske er der dukket noget bedre op, måske kan noget gøres bedre? Ja og nej. Teoretisk ja, i praksis i den nærmeste fremtid absolut ikke. Fordi der er en række interessante topologier, bliver nogle af dem endda brugt i produktionen, for eksempel bruges Dragonfly i HPC-applikationer; Der er også interessante topologier såsom Xpander, FatClique, Jellyfish. Hvis man ser på rapporter på konferencer som SIGCOMM eller NSDI for nylig, kan man finde et ret stort antal værker om alternative topologier, der har bedre egenskaber (en eller anden) end Clos.
Men alle disse topologier har en interessant egenskab. Det forhindrer deres implementering i datacenternetværk, som vi forsøger at bygge på råvarehardware, og som koster ganske rimelige penge. I alle disse alternative topologier er det meste af båndbredden desværre ikke tilgængelig via de korteste veje. Derfor mister vi straks muligheden for at bruge det traditionelle kontrolfly.
Teoretisk set er løsningen på problemet kendt. Disse er f.eks. ændringer af forbindelsestilstand ved hjælp af k-korteste sti, men igen er der ingen sådanne protokoller, der ville blive implementeret i produktionen og bredt tilgængelige på udstyr.
Desuden, da det meste af kapaciteten ikke er tilgængelig via korteste stier, er vi nødt til at ændre mere end blot kontrolplanet for at vælge alle disse stier (og i øvrigt er dette betydeligt mere tilstand i kontrolplanet). Vi mangler stadig at ændre videresendelsesplanet, og som regel kræves der mindst to ekstra funktioner. Dette er evnen til at træffe alle beslutninger om pakkevideresendelse én gang, for eksempel på værten. Faktisk er dette kildedirigering, nogle gange i litteraturen om sammenkoblingsnetværk kaldes dette beslutninger om alt på én gang videresendelse. Og adaptiv routing er en funktion, som vi har brug for på netværkselementer, hvilket for eksempel bunder i, at vi vælger næste hop ud fra information om mindste belastning på køen. Som et eksempel er andre muligheder mulige.
Derfor er retningen interessant, men desværre kan vi ikke anvende den lige nu.

Okay, vi slog os fast på Clos logiske topologi. Hvordan skalerer vi det? Lad os se, hvordan det virker, og hvad der kan gøres.
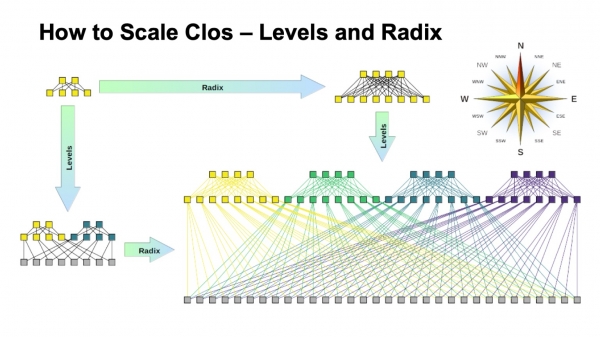
I et Clos-netværk er der to hovedparametre, som vi på en eller anden måde kan variere og få visse resultater: radixen af elementer og antallet af niveauer i netværket. Jeg har et skematisk diagram over, hvordan begge påvirker størrelsen. Ideelt set kombinerer vi begge dele.

Det kan ses, at den endelige bredde af Clos-netværket er produktet af alle niveauer af rygsøjleafbrydere i den sydlige radix, hvor mange links vi har nede, hvordan det forgrener sig. Sådan skalerer vi netværkets størrelse.
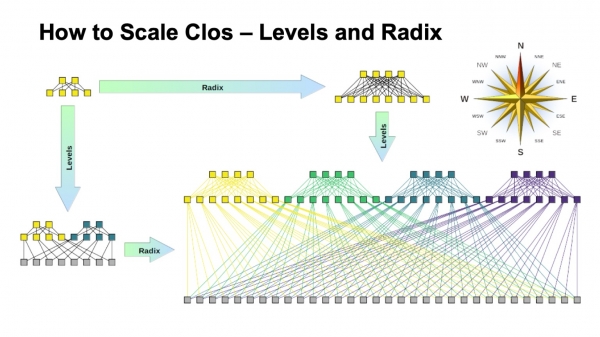
Med hensyn til kapacitet, især på ToR-switche, er der to skaleringsmuligheder. Enten kan vi, mens vi opretholder den generelle topologi, bruge hurtigere links, eller vi kan tilføje flere fly.
Hvis du ser på den udvidede version af Clos-netværket (i nederste højre hjørne) og vender tilbage til dette billede med Clos-netværket nedenfor...
... så er dette nøjagtig den samme topologi, men på denne slide er den kollapset mere kompakt, og fabrikkens planer er overlejret på hinanden. Det er det samme.

Hvordan ser skalering af et Clos-netværk ud i tal? Her giver jeg data om hvilken maksimal bredde et netværk kan opnås, hvilket maksimalt antal racks, ToR switche eller leaf switches, hvis de ikke er i racks, kan vi få afhængig af hvilken radix af switches vi bruger til spine -levels, og hvor mange niveauer vi bruger.
Her er hvor mange racks vi kan have, hvor mange servere og cirka hvor meget alt dette kan forbruge baseret på 20 kW pr. rack. Lidt tidligere nævnte jeg, at vi sigter efter en klyngestørrelse på omkring 100 tusinde servere.
Det kan ses, at i hele dette design er to en halv mulighed af interesse. Der er en mulighed med to lag spines og 64-ports switche, som kommer lidt til kort. Så er der perfekt passende muligheder for 128-ports (med radix 128) rygswitch med to niveauer eller switche med radix 32 med tre niveauer. Og i alle tilfælde, hvor der er flere radikser og flere lag, kan man lave et meget stort netværk, men ser man på det forventede forbrug, er der typisk gigawatt. Det er muligt at lægge et kabel, men vi får næppe så meget strøm på et sted. Ser man på statistik og offentlige data om datacentre, kan man finde meget få datacentre med en estimeret kapacitet på mere end 150 MW. De større er normalt datacentercampusser, flere store datacentre placeret ret tæt på hinanden.
Der er en anden vigtig parameter. Hvis du ser på venstre kolonne, er brugbar båndbredde angivet der. Det er let at se, at i et Clos-netværk bruges en betydelig del af portene til at forbinde switches med hinanden. Brugbar båndbredde, en nyttig strimmel, er noget, der kan gives udenfor, mod serverne. Jeg taler naturligvis om betingede porte og specifikt om bandet. Som regel er links inden for netværket hurtigere end links til servere, men per enhed båndbredde, så meget som vi kan sende det ud til vores serverudstyr, er der stadig en vis båndbredde i selve netværket. Og jo flere niveauer vi laver, jo større er de specifikke omkostninger ved at levere denne stribe til ydersiden.
Desuden er selv dette ekstra band ikke helt det samme. Mens spændviddene er korte, kan vi bruge noget som DAC (direct attach kobber, det vil sige twinax-kabler) eller multimode-optik, som koster endnu mere eller mindre rimelige penge. Så snart vi flytter til længere spændvidder - som regel er disse single-mode optik, og prisen på denne ekstra båndbredde stiger mærkbart.
Og igen, for at vende tilbage til det forrige dias, hvis vi opretter et Clos-netværk uden overabonnement, så er det nemt at se på diagrammet, se hvordan netværket er bygget op - tilføjer vi hvert niveau af rygsøjler, gentager vi hele strimlen, der var ved bund. Plus-niveau - plus det samme bånd, det samme antal porte på switchene, som der var på det forrige niveau, og det samme antal transceivere. Derfor er det yderst ønskværdigt at minimere antallet af niveauer af rygsøjleafbrydere.
Baseret på dette billede er det klart, at vi virkelig ønsker at bygge videre på noget som kontakter med en radix på 128.

Her er alt i princippet det samme, som jeg lige har sagt; dette er en dias til overvejelse senere.

Hvilke muligheder er der, som vi kan vælge som sådanne afbrydere? Det er en meget behagelig nyhed for os, at nu kan sådanne netværk endelig bygges på single-chip switche. Og det er meget fedt, de har en masse gode funktioner. For eksempel har de næsten ingen indre struktur. Det betyder, at de lettere går i stykker. De går i stykker på alle mulige måder, men de går heldigvis helt i stykker. I modulære enheder er der et stort antal fejl (meget ubehageligt), når det fra naboernes og kontrolplanets synspunkt ser ud til at fungere, men for eksempel en del af stoffet er gået tabt, og det fungerer ikke ved fuld kapacitet. Og trafikken til den er afbalanceret ud fra, at den er fuldt funktionsdygtig, og vi kan blive overbelastet.
Eller der opstår for eksempel problemer med bagplanet, for inde i den modulære enhed er der også højhastigheds SerDes - det er virkelig komplekst indeni. Enten er skiltene mellem videresendelseselementer synkroniserede eller ikke synkroniserede. Generelt indeholder enhver produktiv modulær enhed, der består af et stort antal elementer, som regel det samme Clos-netværk i sig selv, men det er meget vanskeligt at diagnosticere. Ofte er det svært for selv sælgeren selv at diagnosticere.
Og den har et stort antal fejlscenarier, hvor enheden nedbrydes, men ikke falder helt ud af topologien. Da vores netværk er stort, bliver der aktivt brugt balancering mellem identiske elementer, netværket er meget regulært, det vil sige, at den ene vej, hvor alt er i orden, ikke adskiller sig fra den anden vej, det er mere rentabelt for os blot at miste nogle af enhederne fra topologien end at ende i en situation, hvor nogle af dem ser ud til at virke, men nogle af dem ikke gør.

Den næste gode egenskab ved single-chip-enheder er, at de udvikler sig bedre og hurtigere. De har også en tendens til at have bedre kapacitet. Hvis vi tager de store samlede strukturer, som vi har på en cirkel, så er kapaciteten pr. rackenhed for porte med samme hastighed næsten dobbelt så god som for modulære enheder. Enheder bygget op omkring en enkelt chip er mærkbart billigere end modulære og bruger mindre energi.
Men det er selvfølgelig alt sammen af en grund, der er også ulemper. For det første er radixen næsten altid mindre end den for modulære enheder. Hvis vi kan få en enhed bygget op omkring én chip med 128 porte, så kan vi uden problemer få en modulær med flere hundrede porte nu.
Dette er en mærkbart mindre størrelse af videresendelsestabeller og som regel alt relateret til dataplans skalerbarhed. Overfladiske buffere. Og som regel ret begrænset funktionalitet. Men det viser sig, at hvis du kender disse restriktioner og sørger for i tide at omgå dem eller blot tage hensyn til dem, så er det ikke så skræmmende. Det faktum, at radixen er mindre, er ikke længere et problem på enheder med en radix på 128, der endelig er dukket op for nylig; vi kan indbygge to lag af rygsøjler. Men det er stadig umuligt at bygge noget mindre end to, der er interessant for os. Med ét niveau opnås meget små klynger. Selv vores tidligere designs og krav oversteg dem stadig.
Faktisk, hvis løsningen pludselig er et sted på kanten, er der stadig en måde at skalere på. Da det sidste (eller første), laveste niveau, hvor servere er tilsluttet, er ToR-switche eller leaf-switches, er vi ikke forpligtet til at tilslutte et rack til dem. Derfor, hvis løsningen kommer til kort med omkring det halve, kan du tænke på blot at bruge en switch med en stor radix på det nederste niveau og forbinde for eksempel to eller tre stativer i en switch. Dette er også en mulighed, det har sine omkostninger, men det fungerer ganske godt og kan være en god løsning, når du skal nå omkring den dobbelte størrelse.
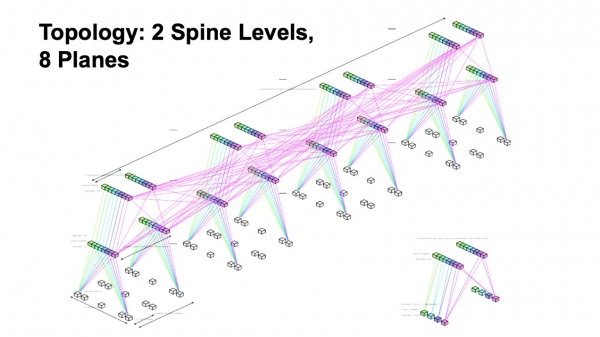
For at opsummere bygger vi på en topologi med to niveauer af rygsøjler med otte fabrikslag.

Hvad vil der ske med fysikken? Meget enkle beregninger. Hvis vi har to niveauer af spines, så har vi kun tre niveauer af switche, og vi forventer, at der vil være tre kabelsegmenter i netværket: fra servere til leaf switches, til spine 1, til spine 2. De muligheder, vi kan brug er - disse er twinax, multimode, single mode. Og her skal vi overveje, hvilken strimmel der er tilgængelig, hvor meget det vil koste, hvad de fysiske dimensioner er, hvilke spændvidder vi kan dække, og hvordan vi vil opgradere.
Med hensyn til omkostninger kan alt stå i kø. Twinaxes er væsentligt billigere end aktiv optik, billigere end multimode transceivere, hvis du tager den per flyvning fra enden, noget billigere end en 100-gigabit switch-port. Og bemærk venligst, at det koster mindre end single mode optik, for på flyvninger, hvor single mode er påkrævet, er det i datacentre af en række årsager fornuftigt at bruge CWDM, mens parallel single mode (PSM) ikke er særlig praktisk at arbejde med, meget store pakninger opnås fibre, og hvis vi fokuserer på disse teknologier, får vi cirka følgende prishierarki.
Endnu en bemærkning: Desværre er det ikke særlig muligt at bruge adskilte 100 til 4x25 multimode-porte. På grund af designfunktionerne i SFP28-transceivere er den ikke meget billigere end 28 Gbit QSFP100. Og denne demontering til multimode fungerer ikke særlig godt.
En anden begrænsning er, at vores datacentre på grund af størrelsen af computerklyngerne og antallet af servere viser sig at være fysisk store. Det betyder, at mindst én flyvning skal udføres med en singlemod. Igen, på grund af den fysiske størrelse af Pods, vil det ikke være muligt at køre to spænd med twinax (kobberkabler).
Som et resultat, hvis vi optimerer for pris og tager højde for geometrien af dette design, får vi en span af twinax, en span af multimode og en span af singlemode ved hjælp af CWDM. Dette tager højde for mulige opgraderingsstier.
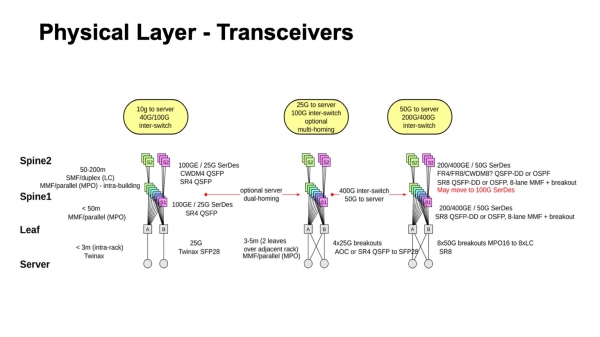
Sådan ser det ud for nylig, hvor vi er på vej hen, og hvad der er muligt. Det er i det mindste klart, hvordan man bevæger sig mod 50-Gigabit SerDes for både multimode og singlemode. Desuden, hvis man ser på, hvad der er i single-mode transceivere nu og i fremtiden for 400G, ofte selv når 50G SerDes ankommer fra den elektriske side, kan 100 Gbps pr. bane allerede gå til optik. Derfor er det meget muligt, at der i stedet for at flytte til 50 vil være en overgang til 100 Gigabit SerDes og 100 Gbps per bane, for ifølge løfterne fra mange leverandører forventes deres tilgængelighed ret hurtigt. Perioden, hvor 50G SerDes var hurtigst, ser det ud til, ikke bliver særlig lang, for de første kopier af 100G SerDes ruller ud næsten næste år. Og efter nogen tid efter det vil de nok være rimelige penge værd.

Endnu en nuance om valget af fysik. I princippet kan vi allerede bruge 400 eller 200 Gigabit-porte ved hjælp af 50G SerDes. Men det viser sig, at dette ikke giver meget mening, for, som jeg sagde tidligere, vil vi gerne have en ret stor radix på kontakterne, selvfølgelig inden for rimelighedens grænser. Vi vil have 128. Og hvis vi har begrænset chipkapacitet, og vi øger linkhastigheden, så falder radix naturligvis, der er ingen mirakler.
Og vi kan øge den samlede kapacitet ved hjælp af fly, og der er ingen særlige omkostninger, vi kan tilføje antallet af fly. Og hvis vi mister radix, bliver vi nødt til at indføre et ekstra niveau, så i den nuværende situation, med den nuværende maksimalt tilgængelige kapacitet pr. chip, viser det sig, at det er mere effektivt at bruge 100-gigabit-porte, fordi de giver dig mulighed for for at få en større radix.

Det næste spørgsmål er, hvordan fysikken er organiseret, men ud fra kabelinfrastrukturens synspunkt. Det viser sig, at det er organiseret på en ret sjov måde. Kabelføring mellem bladafbrydere og XNUMX. niveaus rygsøjler - der er ikke mange links der, alt er bygget relativt enkelt. Men hvis vi tager et fly, er det, der sker indeni, at vi skal forbinde alle rygsøjlen på det første niveau med alle rygsøjlen på det andet niveau.
Derudover er der som regel nogle ønsker til, hvordan det skal se ud inde i datacentret. For eksempel ville vi rigtig gerne kombinere kabler i et bundt og trække dem, så ét højdensitets-patch-panel gik helt ind i ét patch-panel, så der ikke var nogen zoologisk have med hensyn til længder. Det lykkedes os at løse dette problem. Hvis man indledningsvist ser på den logiske topologi, kan man se, at flyene er uafhængige, hvert fly kan bygges for sig. Men når vi tilføjer en sådan bundling og vil trække hele patchpanelet ind i et patchpanel, er vi nødt til at blande forskellige planer inde i et bundt og indføre en mellemstruktur i form af optiske krydsforbindelser for at ompakke dem fra den måde, de blev samlet. på et segment, i hvordan de vil blive indsamlet på et andet segment. Takket være dette får vi en god funktion: al den komplekse omskiftning går ikke ud over stativerne. Når du skal flette noget meget stærkt sammen, "folde flyene ud", som det nogle gange kaldes i Clos-netværk, er det hele koncentreret inde i ét rack. Vi har ikke meget adskilte, ned til individuelle led, skift mellem stativer.
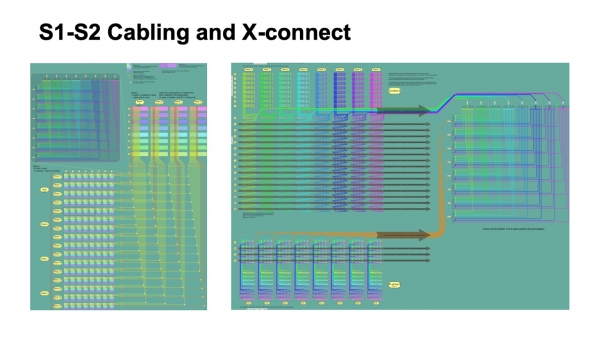
Sådan ser det ud fra den logiske organisering af kabelinfrastrukturen. På billedet til venstre viser de flerfarvede blokke blokke af første-niveau rygsøjleafbrydere, otte stykker hver, og fire bundter af kabler, der kommer fra dem, som går og krydser bundterne, der kommer fra blokkene af rygsøjle-2-afbrydere .
Små firkanter angiver kryds. Øverst til venstre er en opdeling af hver sådan krydsning, dette er faktisk et 512 x 512 port cross-connect modul, der ompakker kablerne, så de kommer helt ind i ét rack, hvor der kun er et spine-2 plan. Og til højre er en scanning af dette billede lidt mere detaljeret i forhold til flere Pods på spine-1 niveau, og hvordan det er pakket i en cross-connect, hvordan det kommer til spine-2 niveau.

Sådan ser det ud. Det endnu ikke færdigmonterede spine-2-stativ (til venstre) og krydsforbindelsesstativet. Desværre er der ikke meget at se der. Hele denne struktur er ved at blive implementeret lige nu i et af vores store datacentre, som er ved at blive udvidet. Dette er et igangværende arbejde, det vil se pænere ud, det vil blive udfyldt bedre.

Et vigtigt spørgsmål: vi valgte den logiske topologi og byggede fysikken. Hvad vil der ske med kontrolplanet? Det er ganske velkendt fra driftserfaring, der er en række rapporter om, at linktilstandsprotokoller er gode, det er en fornøjelse at arbejde med dem, men desværre skalerer de ikke godt på en tæt forbundet topologi. Og der er en hovedfaktor, der forhindrer dette - det er sådan, oversvømmelse fungerer i linkstatsprotokoller. Hvis man bare tager flooding-algoritmen og ser på, hvordan vores netværk er opbygget, kan man se, at der vil være en meget stor fanout ved hvert trin, og det vil simpelthen oversvømme kontrolplanet med opdateringer. Specifikt blander sådanne topologier sig meget dårligt med den traditionelle oversvømmelsesalgoritme i linktilstandsprotokoller.
Valget er at bruge BGP. Hvordan man forbereder det korrekt er beskrevet i RFC 7938 om brugen af BGP i store datacentre. De grundlæggende ideer er enkle: minimum antal præfikser pr. vært og generelt minimum antal præfikser på netværket, brug aggregering, hvis det er muligt, og undertrykk stijagt. Vi ønsker en meget omhyggelig, meget kontrolleret distribution af opdateringer, det der kaldes dalfri. Vi ønsker, at opdateringer skal implementeres præcis én gang, når de passerer gennem netværket. Hvis de stammer fra bunden, går de op og folder sig ikke mere end én gang. Der bør ikke være zigzags. Zigzags er meget dårlige.
For at gøre dette bruger vi et design, der er simpelt nok til at bruge de underliggende BGP-mekanismer. Det vil sige, vi bruger eBGP, der kører på link lokalt, og autonome systemer er tildelt som følger: et autonomt system på ToR, et autonomt system på hele blokken af spine-1 switches på en Pod, og et generelt autonomt system på hele toppen af stof. Det er ikke svært at se og se, at selv den normale opførsel af BGP giver os den distribution af opdateringer, vi ønsker.

Naturligvis skal adressering og adresseaggregering designes, så det er kompatibelt med den måde, routing er opbygget på, så det sikrer stabilitet af kontrolplanet. L3-adressering i transport er bundet til topologien, for uden denne er det umuligt at opnå aggregering; uden dette vil individuelle adresser krybe ind i routingsystemet. Og en ting mere er, at aggregering desværre ikke blander sig særlig godt med multi-path, for når vi har multi-path og vi har aggregering, er alt fint, når hele netværket er sundt, er der ingen fejl i det. Desværre, så snart der opstår fejl i netværket, og topologiens symmetri går tabt, kan vi komme til det punkt, hvorfra enheden blev annonceret, hvorfra vi ikke kan gå længere til, hvor vi skal gå. Derfor er det bedst at aggregere, hvor der ikke er yderligere multi-path, i vores tilfælde er disse ToR-switche.

Faktisk er det muligt at aggregere, men omhyggeligt. Hvis vi kan foretage kontrolleret disaggregering, når der opstår netværksfejl. Men dette er en ret vanskelig opgave, vi spekulerede endda på, om det ville være muligt at gøre dette, om det var muligt at tilføje yderligere automatisering og finite state-maskiner, der korrekt ville sparke BGP for at få den ønskede adfærd. Desværre er behandling af hjørnesager meget uoplagt og kompleks, og denne opgave løses ikke godt ved at vedhæfte eksterne bilag til BGP.
Meget interessant arbejde i denne henseende er blevet udført inden for rammerne af RIFT-protokollen, som vil blive diskuteret i næste rapport.

En anden vigtig ting er, hvordan dataplaner skaleres i tætte topologier, hvor vi har et stort antal alternative veje. I dette tilfælde anvendes flere yderligere datastrukturer: ECMP-grupper, som igen beskriver Next Hop-grupper.
I et normalt fungerende netværk, uden fejl, når vi går op i Clos-topologien, er det nok kun at bruge én gruppe, fordi alt, der ikke er lokalt, er beskrevet som standard, vi kan gå op. Når vi går fra top til bund mod syd, så er alle stier ikke ECMP, de er enkeltstier. Alt er fint. Problemet er, og det særlige ved den klassiske Clos-topologi er, at hvis vi ser på toppen af stof, på et hvilket som helst element, er der kun én vej til ethvert element nedenfor. Hvis der opstår fejl langs denne sti, så bliver dette særlige element øverst på fabrikken ugyldigt netop for de præfikser, der ligger bag den brudte sti. Men for resten er det gyldigt, og vi er nødt til at analysere ECMP-grupperne og indføre en ny stat.
Hvordan ser skalerbarheden af dataplanet ud på moderne enheder? Hvis vi laver LPM (længste præfiks-match), er alt ganske godt, over 100 præfikser. Hvis vi taler om Next Hop-grupper, så er alt værre, 2-4 tusinde. Hvis vi taler om en tabel, der indeholder en beskrivelse af Next Hops (eller adjacencies), så er dette et sted fra 16k til 64k. Og dette kan blive et problem. Og her kommer vi til en interessant digression: hvad skete der med MPLS i datacentre? I princippet ville vi gøre det.

To ting skete. Vi lavede mikrosegmentering på værterne; vi behøvede ikke længere at gøre det på netværket. Det var ikke særlig godt med support fra forskellige leverandører, og endnu mere med åbne implementeringer på hvide bokse med MPLS. Og MPLS, i det mindste dets traditionelle implementeringer, kombinerer desværre meget dårligt med ECMP. Og det er derfor.
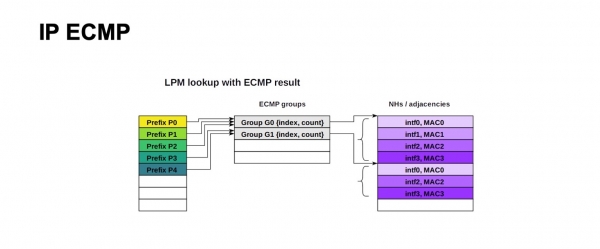
Sådan ser ECMP-videresendelsesstrukturen for IP ud. Et stort antal præfikser kan bruge den samme gruppe og den samme Next Hops-blok (eller adjacencies, dette kan kaldes forskelligt i forskellig dokumentation for forskellige enheder). Pointen er, at dette beskrives som den udgående port, og hvad man skal omskrive MAC-adressen til for at komme til det korrekte Next Hop. For IP ser alt simpelt ud, du kan bruge et meget stort antal præfikser for den samme gruppe, den samme Next Hops blok.
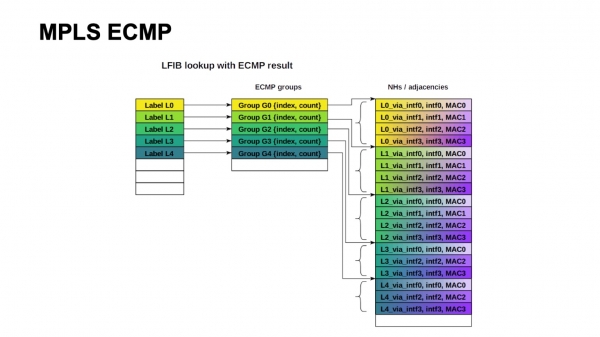
Den klassiske MPLS-arkitektur indebærer, at etiketten, afhængig af den udgående grænseflade, kan omskrives til forskellige værdier. Derfor er vi nødt til at beholde en gruppe og en Next Hops-blok for hver input-etiket. Og dette skalerer desværre ikke.
Det er let at se, at vi i vores design havde brug for omkring 4000 ToR-switche, den maksimale bredde var 64 ECMP-stier, hvis vi bevæger os væk fra spine-1 mod spine-2. Vi kommer knap nok ind i en tabel med ECMP-grupper, hvis kun ét præfiks med ToR forsvinder, og vi slet ikke kommer ind i Next Hops-tabellen.

Det hele er ikke håbløst, for arkitekturer som Segment Routing involverer globale mærker. Formelt ville det være muligt at kollapse alle disse Next Hops-blokke igen. For at gøre dette skal du bruge en joker-type-operation: tag en etiket og omskriv den til den samme uden en specifik værdi. Men desværre er dette ikke særlig til stede i de tilgængelige implementeringer.
Og endelig skal vi bringe ekstern trafik ind i datacentret. Hvordan gør man det? Tidligere blev trafik indført i Clos-netværket fra oven. Det vil sige, at der var kantroutere, der tilsluttede alle enheder på toppen af stoffet. Denne løsning fungerer ganske godt på små til mellemstore størrelser. For at sende trafik symmetrisk til hele netværket på denne måde er vi desværre nødt til at nå frem samtidigt til alle elementer i Top of-stoffet, og når der er mere end hundrede af dem, viser det sig, at vi også har brug for en stor radix på kantfræserne. Generelt koster dette penge, fordi kantroutere er mere funktionelle, portene på dem bliver dyrere, og designet er ikke særlig smukt.
En anden mulighed er at starte sådan trafik nedefra. Det er let at verificere, at Clos-topologien er bygget på en sådan måde, at trafik, der kommer nedefra, det vil sige fra ToR-siden, fordeles jævnt mellem niveauerne i hele Top of-stoffet i to iterationer, hvorved hele netværket indlæses. Derfor introducerer vi en speciel type Pod, Edge Pod, som giver ekstern tilslutning.
Der er en mulighed mere. Det gør Facebook f.eks. De kalder det Fabric Aggregator eller HGRID. Et ekstra rygsøjleniveau bliver introduceret for at forbinde flere datacentre. Dette design er muligt, hvis vi ikke har yderligere funktioner eller indkapslingsændringer ved grænsefladerne. Hvis de er yderligere berøringspunkter, er det svært. Typisk er der flere funktioner og en slags membran, der adskiller forskellige dele af datacentret. Det nytter ikke noget at gøre sådan en membran stor, men hvis den virkelig er nødvendig af en eller anden grund, så giver det mening at overveje muligheden for at tage den væk, gøre den så bred som muligt og overføre den til værterne. Dette gøres for eksempel af mange cloud-operatører. De har overlejringer, de tager udgangspunkt i værterne.

Hvilke udviklingsmuligheder ser vi? Først og fremmest forbedring af understøttelsen af CI/CD-pipelinen. Vi vil flyve, som vi tester og teste den måde, vi flyver på. Dette fungerer ikke særlig godt, fordi infrastrukturen er stor, og det er umuligt at duplikere den til test. Du skal forstå, hvordan du introducerer testelementer i produktionsinfrastrukturen uden at droppe det.
Bedre instrumentering og bedre overvågning er næsten aldrig overflødig. Hele spørgsmålet er en balance mellem indsats og afkast. Hvis du kan tilføje det med rimelig indsats, meget godt.
Åbne operativsystemer til netværksenheder. Bedre protokoller og bedre routingsystemer, såsom RIFT. Der er også behov for forskning i brugen af bedre overbelastningskontrolordninger og måske indførelsen, i det mindste på nogle punkter, af RDMA-støtte inden for klyngen.
Ser vi længere ud i fremtiden, har vi brug for avancerede topologier og muligvis netværk, der bruger mindre overhead. Af de friske ting er der for nylig kommet publikationer om stofteknologien til HPC Cray Slingshot, som er baseret på råvare Ethernet, men med mulighed for at bruge meget kortere headere. Som følge heraf reduceres overhead.

Alt skal holdes så enkelt som muligt, men ikke enklere. Kompleksitet er skalerbarhedens fjende. Enkelhed og regelmæssige strukturer er vores venner. Hvis du kan skalere ud et sted, så gør det. Og generelt er det fantastisk at være involveret i netværksteknologier nu. Der sker en masse interessante ting. Tak skal du have.
Kilde: www.habr.com
