

Bemærk. overs.: Denne artikel, skrevet af Galo Navarro, der har stillingen som Principal Software Engineer hos det europæiske firma Adevinta, er en fascinerende og lærerig "undersøgelse" inden for infrastrukturdrift. Dens oprindelige titel blev lidt udvidet i oversættelse af en grund, som forfatteren forklarer i begyndelsen.
Notat fra forfatteren: Ser ud som dette indlæg meget mere opmærksomhed end forventet. Jeg får stadig vrede kommentarer om, at artiklens titel er misvisende, og at nogle læsere er kede af det. Jeg forstår årsagerne til, hvad der sker, derfor vil jeg, på trods af risikoen for at ødelægge hele intrigen, straks fortælle dig, hvad denne artikel handler om. En mærkelig ting, jeg har set, mens teams migrerer til Kubernetes, er, at når der opstår et problem (såsom øget latenstid efter en migrering), er den første ting, der får skylden, Kubernetes, men så viser det sig, at orkestratoren ikke rigtig skal bebrejde. Denne artikel fortæller om et sådant tilfælde. Dens navn gentager udråbet fra en af vores udviklere (senere vil du se, at Kubernetes ikke har noget at gøre med det). Du vil ikke finde nogen overraskende afsløringer om Kubernetes her, men du kan forvente et par gode lektioner om komplekse systemer.
For et par uger siden migrerede mit team en enkelt mikrotjeneste til en kerneplatform, der inkluderede CI/CD, en Kubernetes-baseret runtime, metrics og andre godbidder. Flytningen var af prøvekarakter: Vi planlagde at tage den som grundlag og overføre cirka 150 flere tjenester i de kommende måneder. De er alle ansvarlige for driften af nogle af de største online platforme i Spanien (Infojobs, Fotocasa osv.).
Efter at vi havde implementeret applikationen til Kubernetes og omdirigeret noget trafik til den, ventede en alarmerende overraskelse os. Forsinke (reaktionstid) anmodninger i Kubernetes var 10 gange højere end i EC2. Generelt var det nødvendigt enten at finde en løsning på dette problem eller at opgive migreringen af mikrotjenesten (og muligvis hele projektet).
Hvorfor er latency så meget højere i Kubernetes end i EC2?
For at finde flaskehalsen indsamlede vi metrics langs hele anmodningsstien. Vores arkitektur er enkel: en API-gateway (Zuul) proxies anmodninger til mikroservice-instanser i EC2 eller Kubernetes. I Kubernetes bruger vi NGINX Ingress Controller, og backends er almindelige objekter som f.eks. med en JVM-applikation på Spring-platformen.
EC2
+---------------+
| +---------+ |
| | | |
+-------> BACKEND | |
| | | | |
| | +---------+ |
| +---------------+
+------+ |
Public | | |
-------> ZUUL +--+
traffic | | | Kubernetes
+------+ | +-----------------------------+
| | +-------+ +---------+ |
| | | | xx | | |
+-------> NGINX +------> BACKEND | |
| | | xx | | |
| +-------+ +---------+ |
+-----------------------------+Problemet så ud til at være relateret til initial latency i backend (jeg markerede problemområdet på grafen som "xx"). På EC2 tog ansøgningssvaret omkring 20 ms. I Kubernetes steg latensen til 100-200 ms.
Vi afviste hurtigt de sandsynlige mistænkte i forbindelse med runtime-ændringen. JVM-versionen forbliver den samme. Containeriseringsproblemer havde heller ikke noget at gøre med det: applikationen kørte allerede med succes i containere på EC2. Indlæser? Men vi observerede høje latenser selv ved 1 anmodning i sekundet. Pauser til affaldsindsamling kan også forsømmes.
En af vores Kubernetes-administratorer spekulerede på, om applikationen havde eksterne afhængigheder, fordi DNS-forespørgsler havde forårsaget lignende problemer tidligere.
Hypotese 1: DNS-navneopløsning
For hver anmodning får vores applikation adgang til en AWS Elasticsearch-instans én til tre gange i et domæne som f.eks. elastic.spain.adevinta.com. Inde i vores containere , så vi kan tjekke, om det faktisk tager lang tid at søge efter et domæne.
DNS-forespørgsler fra container:
[root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 22 msec
;; Query time: 22 msec
;; Query time: 29 msec
;; Query time: 21 msec
;; Query time: 28 msec
;; Query time: 43 msec
;; Query time: 39 msecLignende anmodninger fra en af de EC2-forekomster, hvor applikationen kører:
bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 77 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msecI betragtning af at opslaget tog omkring 30 ms, blev det klart, at DNS-opløsning ved adgang til Elasticsearch faktisk bidrog til stigningen i latens.
Dette var dog mærkeligt af to grunde:
- Vi har allerede et væld af Kubernetes-applikationer, der interagerer med AWS-ressourcer uden at lide af høj latenstid. Uanset årsagen, vedrører det specifikt denne sag.
- Vi ved, at JVM'en laver DNS-cache i hukommelsen. I vores billeder er TTL-værdien skrevet ind
$JAVA_HOME/jre/lib/security/java.securityog indstil til 10 sekunder:networkaddress.cache.ttl = 10. Med andre ord skal JVM'en cache alle DNS-forespørgsler i 10 sekunder.
For at bekræfte den første hypotese besluttede vi at stoppe med at ringe til DNS i et stykke tid og se, om problemet forsvandt. Først besluttede vi at omkonfigurere applikationen, så den kommunikerede direkte med Elasticsearch via IP-adresse i stedet for via et domænenavn. Dette ville kræve kodeændringer og en ny implementering, så vi kortlagde simpelthen domænet til dets IP-adresse i /etc/hosts:
34.55.5.111 elastic.spain.adevinta.comNu modtog containeren en IP næsten øjeblikkeligt. Dette resulterede i en vis forbedring, men vi var kun lidt tættere på de forventede latensniveauer. Selvom DNS-opløsning tog lang tid, undgik den egentlige årsag os stadig.
Diagnostik via netværk
Vi besluttede at analysere trafik fra containeren vha tcpdumpfor at se, hvad der præcist sker på netværket:
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap Vi sendte derefter flere anmodninger og downloadede deres optagelse (kubectl cp my-service:/capture.pcap capture.pcap) til yderligere analyse i .
Der var ikke noget mistænkeligt ved DNS-forespørgslerne (bortset fra en lille ting, som jeg vil tale om senere). Men der var visse mærkeligheder i den måde, vores service håndterede hver anmodning. Nedenfor er et skærmbillede af optagelsen, der viser, at anmodningen accepteres, før svaret begynder:
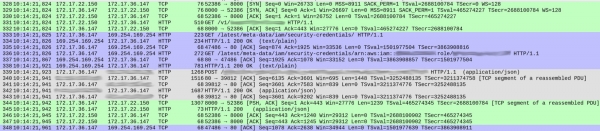
Pakkenumre er vist i første kolonne. For klarhedens skyld har jeg farvekodet de forskellige TCP-flows.
Den grønne strøm, der starter med pakke 328, viser, hvordan klienten (172.17.22.150) etablerede en TCP-forbindelse til containeren (172.17.36.147). Efter det første håndtryk (328-330), bragte pakke 331 HTTP GET /v1/.. — en indgående anmodning til vores service. Hele processen tog 1 ms.
Den grå strøm (fra pakke 339) viser, at vores tjeneste sendte en HTTP-anmodning til Elasticsearch-instansen (der er intet TCP-håndtryk, fordi det bruger en eksisterende forbindelse). Det tog 18 ms.
Indtil videre er alt fint, og tiderne svarer nogenlunde til de forventede forsinkelser (20-30 ms målt fra klienten).
Det blå afsnit tager dog 86ms. Hvad sker der i den? Med pakke 333 sendte vores service en HTTP GET-anmodning til /latest/meta-data/iam/security-credentials, og umiddelbart efter den, over den samme TCP-forbindelse, endnu en GET-anmodning til /latest/meta-data/iam/security-credentials/arn:...
Vi fandt ud af, at dette gentog sig ved hver anmodning under hele sporingen. DNS-opløsning er faktisk lidt langsommere i vores containere (forklaringen på dette fænomen er ret interessant, men jeg gemmer den til en separat artikel). Det viste sig, at årsagen til de lange forsinkelser var opkald til AWS Instance Metadata-tjenesten ved hver anmodning.
Hypotese 2: unødvendige opkald til AWS
Begge endepunkter hører til . Vores mikroservice bruger denne service, mens den kører Elasticsearch. Begge opkald er en del af den grundlæggende godkendelsesproces. Slutpunktet, der tilgås ved den første anmodning, udsteder den IAM-rolle, der er knyttet til instansen.
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
arn:aws:iam::<account_id>:role/some_roleDen anden anmodning beder det andet endepunkt om midlertidige tilladelser for denne instans:
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
{
"Code" : "Success",
"LastUpdated" : "2012-04-26T16:39:16Z",
"Type" : "AWS-HMAC",
"AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"Token" : "token",
"Expiration" : "2017-05-17T15:09:54Z"
} Klienten kan bruge dem i en kort periode og skal med jævne mellemrum indhente nye certifikater (før de er det Expiration). Modellen er enkel: AWS roterer midlertidige nøgler ofte af sikkerhedsmæssige årsager, men klienter kan cache dem i et par minutter for at kompensere for ydeevnestraffen forbundet med at få nye certifikater.
AWS Java SDK bør overtage ansvaret for at organisere denne proces, men af en eller anden grund sker det ikke.
Efter at have søgt efter problemer på GitHub stødte vi på et problem . Hun hjalp os med at bestemme retningen, hvor vi skulle "grave" yderligere.
AWS SDK opdaterer certifikater, når en af følgende forhold opstår:
- Udløbsdato (
Expiration) Fald indEXPIRATION_THRESHOLD, hårdkodet til 15 minutter. - Der er gået længere tid siden sidste forsøg på at forny certifikater end
REFRESH_THRESHOLD, hårdkodet i 60 minutter.
For at se den faktiske udløbsdato for de certifikater, vi modtager, kørte vi ovenstående cURL-kommandoer fra både containeren og EC2-instansen. Gyldighedsperioden for certifikatet modtaget fra containeren viste sig at være meget kortere: nøjagtigt 15 minutter.
Nu er alt blevet klart: for den første anmodning modtog vores service midlertidige certifikater. Da de ikke var gyldige i mere end 15 minutter, ville AWS SDK beslutte at opdatere dem på en efterfølgende anmodning. Og dette skete ved hver anmodning.
Hvorfor er certifikaternes gyldighedsperiode blevet kortere?
AWS Instance Metadata er designet til at fungere med EC2-instanser, ikke Kubernetes. På den anden side ønskede vi ikke at ændre applikationsgrænsefladen. Til dette brugte vi - et værktøj, der ved hjælp af agenter på hver Kubernetes-node giver brugere (ingeniører, der implementerer applikationer til en klynge) mulighed for at tildele IAM-roller til containere i pods, som om de var EC2-instanser. KIAM opsnapper opkald til AWS Instance Metadata-tjenesten og behandler dem fra sin cache efter tidligere at have modtaget dem fra AWS. Fra et applikationssynspunkt ændres intet.
KIAM leverer kortsigtede certifikater til pods. Dette giver mening i betragtning af, at den gennemsnitlige levetid for en pod er kortere end en EC2-instans. Standard gyldighedsperiode for certifikater .
Som et resultat, hvis du overlejrer begge standardværdier oven på hinanden, opstår der et problem. Hvert certifikat, der leveres til en ansøgning, udløber efter 15 minutter. AWS Java SDK tvinger dog en fornyelse af ethvert certifikat, der har mindre end 15 minutter tilbage før dets udløbsdato.
Som et resultat er det midlertidige certifikat tvunget til at blive fornyet med hver anmodning, hvilket medfører et par kald til AWS API og forårsager en betydelig stigning i latens. I AWS Java SDK fandt vi , som nævner et lignende problem.
Løsningen viste sig at være enkel. Vi har simpelthen omkonfigureret KIAM til at anmode om certifikater med en længere gyldighedsperiode. Når dette skete, begyndte anmodninger at strømme uden deltagelse af AWS Metadata-tjenesten, og latensen faldt til endnu lavere niveauer end i EC2.
Fund
Baseret på vores erfaring med migreringer er en af de mest almindelige kilder til problemer ikke fejl i Kubernetes eller andre elementer i platformen. Den adresserer heller ikke nogen grundlæggende fejl i de mikrotjenester, vi porterer. Problemer opstår ofte, blot fordi vi sætter forskellige elementer sammen.
Vi blander komplekse systemer, som aldrig har interageret med hinanden før, og forventer, at de sammen vil danne et enkelt, større system. Ak, jo flere elementer, jo mere plads til fejl, jo højere er entropien.
I vores tilfælde var den høje latenstid ikke resultatet af fejl eller dårlige beslutninger i Kubernetes, KIAM, AWS Java SDK eller vores mikroservice. Det var resultatet af at kombinere to uafhængige standardindstillinger: en i KIAM, den anden i AWS Java SDK. Taget hver for sig giver begge parametre mening: den aktive certifikatfornyelsespolitik i AWS Java SDK og den korte gyldighedsperiode for certifikater i KAIM. Men når du sætter dem sammen, bliver resultaterne uforudsigelige. To uafhængige og logiske løsninger behøver ikke at give mening, når de kombineres.
PS fra oversætteren
Du kan lære mere om arkitekturen af KIAM-værktøjet til at integrere AWS IAM med Kubernetes på fra dens skabere.
Læs også på vores blog:
- «";
- «";
- «";
- «'.
Kilde: www.habr.com
