

Vi tænkte på at skabe et overvågningssystem på tidspunktet for dannelsen af produktteams. Det blev klart, at vores forretning - udnyttelse - ikke falder ind i disse teams. Hvorfor det?
Faktum er, at alle vores teams er bygget op omkring individuelle informationssystemer, mikrotjenester og fronter, så teamene ser ikke den overordnede sundhed i hele systemet som helhed. For eksempel ved de måske ikke, hvordan en lille del i den dybe bagende påvirker forenden. Deres interesseområde er begrænset til de systemer, som deres system er integreret med. Hvis et team og dets service A næsten ikke har nogen forbindelse med service B, så er en sådan service næsten usynlig for teamet.
Vores team arbejder til gengæld med systemer, der er meget stærkt integrerede med hinanden: Der er mange forbindelser mellem dem, det er en meget stor infrastruktur. Og driften af onlinebutikken afhænger af alle disse systemer (som vi i øvrigt har et stort antal af).
Så det viser sig, at vores afdeling ikke tilhører noget hold, men ligger lidt til siden. I hele denne historie er vores opgave at forstå, hvordan informationssystemer fungerer, deres funktionalitet, integrationer, software, netværk, hardware, og hvordan alt dette er forbundet med hinanden.
Platformen, som vores netbutikker opererer på, ser således ud:
- forsiden
- mellemkontor
- back office
Uanset hvor meget vi gerne vil, sker det ikke, at alle systemer fungerer gnidningsfrit og fejlfrit. Pointen er igen antallet af systemer og integrationer - med noget som vores er nogle hændelser uundgåelige på trods af testens kvalitet. Desuden både inden for et separat system og med hensyn til deres integration. Og du skal overvåge tilstanden af hele platformen grundigt, og ikke bare en individuel del af den.
Ideelt set bør platformsdækkende sundhedsovervågning automatiseres. Og vi kom til overvågning som en uundgåelig del af denne proces. I starten blev det kun bygget til frontlinjedelen, mens netværksspecialister, software- og hardwareadministratorer havde og stadig har deres egne lag-for-lag overvågningssystemer. Alle disse mennesker fulgte kun overvågningen på deres eget niveau; ingen havde heller en omfattende forståelse.
For eksempel, hvis en virtuel maskine går ned, er det i de fleste tilfælde kun den administrator, der er ansvarlig for hardwaren og den virtuelle maskine, der kender til det. I sådanne tilfælde så frontline-teamet selve kendsgerningen af programmets nedbrud, men det havde ikke data om nedbruddet af den virtuelle maskine. Og administratoren kan vide, hvem kunden er og have en nogenlunde idé om, hvad der i øjeblikket kører på denne virtuelle maskine, forudsat at det er en slags stort projekt. Han kender højst sandsynligt ikke til de små. Under alle omstændigheder skal administratoren gå til ejeren og spørge, hvad der var på denne maskine, hvad der skal gendannes, og hvad der skal ændres. Og hvis noget rigtig alvorligt gik i stykker, begyndte de at løbe rundt i ring – for ingen så systemet som en helhed.
I sidste ende påvirker sådanne forskellige historier hele frontend, brugere og vores kerneforretningsfunktion - onlinesalg. Da vi ikke er en del af et team, men er engageret i driften af alle e-handelsapplikationer som en del af en netbutik, påtog vi os opgaven med at skabe et omfattende overvågningssystem til e-handelsplatformen.
Systemstruktur og stak
Vi startede med at identificere flere overvågningslag for vores systemer, inden for hvilke vi skulle indsamle metrics. Og alt dette skulle kombineres, hvilket vi gjorde i første fase. Nu på dette stadium er vi ved at færdiggøre den højeste kvalitetsindsamling af metrics på tværs af alle vores lag for at opbygge en sammenhæng og forstå, hvordan systemer påvirker hinanden.
Manglen på omfattende overvågning i de indledende faser af applikationslanceringen (siden vi begyndte at bygge den, da de fleste af systemerne var i produktion) førte til, at vi havde betydelig teknisk gæld til at opsætte overvågning af hele platformen. Vi havde ikke råd til at fokusere på at opsætte overvågning for én IS og udarbejde overvågning for den i detaljer, da resten af systemerne ville stå uden overvågning i nogen tid. For at løse dette problem identificerede vi en liste over de mest nødvendige målinger til vurdering af informationssystemets tilstand for lag og begyndte at implementere den.
Derfor besluttede de at spise elefanten i dele.
Vores system består af:
- hardware;
- operativ system;
- software;
- UI-dele i overvågningsapplikationen;
- forretningsmålinger;
- integration applikationer;
- informationssikkerhed;
- netværk;
- trafikbalancer.
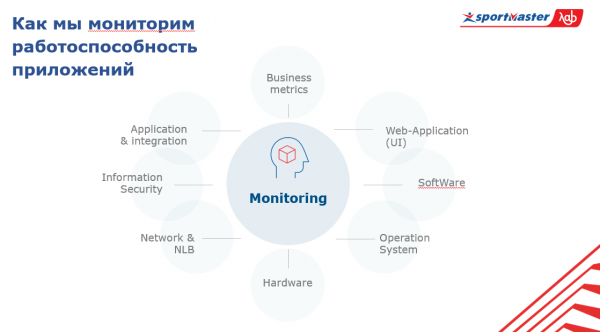
I centrum af dette system er overvågningen af sig selv. For generelt at forstå hele systemets tilstand, skal du vide, hvad der sker med applikationer på alle disse lag og på tværs af hele applikationssættet.
Altså om stakken.
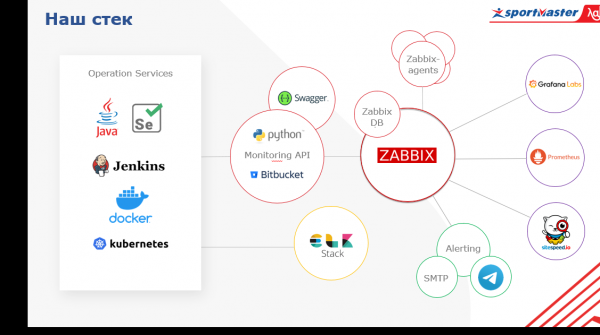
Vi bruger open source software. I centret har vi Zabbix, som vi primært bruger som alarmeringssystem. Alle ved, at den er ideel til infrastrukturovervågning. Hvad betyder det? Præcis de lavniveau-metrics, som enhver virksomhed, der vedligeholder sit eget datacenter, har (og Sportmaster har sine egne datacentre) - servertemperatur, hukommelsesstatus, raid, netværksenhedsmålinger.
Vi har integreret Zabbix med Telegram messenger og Microsoft Teams, som bruges aktivt i teams. Zabbix dækker laget af det faktiske netværk, hardware og noget software, men det er ikke et vidundermiddel. Vi beriger disse data fra nogle andre tjenester. På hardwareniveau forbinder vi for eksempel direkte via API til vores virtualiseringssystem og indsamler data.
Hvad ellers. Ud over Zabbix bruger vi Prometheus, som giver os mulighed for at overvåge metrikker i en dynamisk miljøapplikation. Det vil sige, at vi kan modtage applikations-metrics via et HTTP-slutpunkt og ikke bekymre os om, hvilke metrics, der skal indlæses i det, og hvilke der ikke. Baseret på disse data kan analytiske forespørgsler udvikles.
Datakilder for andre lag, for eksempel forretningsmålinger, er opdelt i tre komponenter.
For det første er disse eksterne forretningssystemer, Google Analytics, vi indsamler metrics fra logfiler. Fra dem får vi data om aktive brugere, konverteringer og alt andet relateret til virksomheden. For det andet er dette et UI-overvågningssystem. Det skal beskrives mere detaljeret.
Engang startede vi med manuel test, og det voksede til automatiske test af funktionalitet og integrationer. Ud fra dette lavede vi overvågning, efterlod kun hovedfunktionaliteten og stolede på markører, der er så stabile som muligt og ikke ændrer sig ofte over tid.
Den nye teamstruktur betyder, at alle applikationsaktiviteter er begrænset til produktteams, så vi holdt op med at lave rene tests. I stedet lavede vi UI-overvågning fra testene, skrevet i Java, Selenium og Jenkins (bruges som et system til at starte og generere rapporter).
Vi havde mange tests, men i sidste ende besluttede vi at gå til hovedvejen, det øverste niveau. Og hvis vi har en masse specifikke test, bliver det svært at holde data opdateret. Hver efterfølgende udgivelse vil bryde hele systemet markant, og alt, hvad vi vil gøre, er at rette det. Derfor fokuserede vi på helt fundamentale ting, som sjældent ændrer sig, og vi overvåger dem kun.
Endelig, for det tredje, er datakilden et centraliseret logningssystem. Vi bruger Elastic Stack til logfiler, og så kan vi trække disse data ind i vores overvågningssystem til forretningsmålinger. Udover alt dette har vi vores egen Monitoring API-tjeneste, skrevet i Python, som forespørger på alle tjenester via API og indsamler data fra dem til Zabbix.
En anden uundværlig egenskab ved overvågning er visualisering. Vores er baseret på Grafana. Det skiller sig ud blandt andre visualiseringssystemer ved, at det giver dig mulighed for at visualisere metrics fra forskellige datakilder på dashboardet. Vi kan indsamle topniveau-metrics for en onlinebutik, for eksempel antallet af ordrer, der er afgivet i den sidste time fra DBMS, ydeevnemålinger for det operativsystem, som denne onlinebutik kører på fra Zabbix, og metrics for forekomster af denne applikation fra Prometheus. Og alt dette vil være på ét dashboard. Overskuelig og tilgængelig.
Lad mig notere om sikkerhed - vi er i øjeblikket ved at færdiggøre systemet, som vi senere vil integrere med det globale overvågningssystem. Efter min mening er de største problemer, som e-handel står over for inden for informationssikkerhed, relateret til bots, parsere og brute force. Det skal vi holde øje med, for alt dette kan kritisk påvirke både driften af vores applikationer og vores omdømme fra et forretningsmæssigt synspunkt. Og med den valgte stak dækker vi disse opgaver med succes.
En anden vigtig pointe er, at påføringslaget er samlet af Prometheus. Selv er han også integreret med Zabbix. Og vi har også sitespeed, en tjeneste, der giver os mulighed for at se parametre såsom indlæsningshastigheden på vores side, flaskehalse, sidegengivelse, indlæsning af scripts osv., den er også API integreret. Så vores metrics er samlet i Zabbix, og derfor advarer vi også derfra. Alle advarsler sendes i øjeblikket til de vigtigste afsendelsesmetoder (for nu er det e-mail og telegram, MS Teams er også for nylig blevet forbundet). Der er planer om at opgradere alarmering til en sådan tilstand, at smart bots fungerer som en service og leverer overvågningsinformation til alle interesserede produktteams.
For os er metrikker ikke kun vigtige for individuelle informationssystemer, men også for generelle metrikker på tværs af hele den infrastruktur, som applikationer bruger: klynger fysiske servere, som kører virtuelle maskiner, trafikbalancere, netværksbelastningsbalancere, selve netværket og båndbreddeudnyttelse. Plus metrikker for vores egne datacentre (vi har flere af dem, og infrastrukturen er ret stor).
Fordelene ved vores overvågningssystem er, at vi med dets hjælp ser sundhedstilstanden for alle systemer og kan vurdere deres indvirkning på hinanden og på fælles ressourcer. Og i sidste ende giver det os mulighed for at engagere os i ressourceplanlægning, hvilket også er vores ansvar. Vi administrerer serverressourcer - en pulje indenfor e-handel, idriftsættelse og nedlukning af nyt udstyr, indkøb af yderligere nyt udstyr, foretager revision af ressourceudnyttelse mv. Hvert år planlægger teams nye projekter, udvikler deres systemer, og det er vigtigt for os at give dem ressourcer.
Og ved hjælp af målinger ser vi udviklingen i vores informationssystemers ressourceforbrug. Og ud fra dem kan vi planlægge noget. På virtualiseringsniveau indsamler vi data og ser information om den tilgængelige mængde ressourcer efter datacenter. Og allerede inde i datacentret kan du se genanvendelsen, den faktiske fordeling og forbruget af ressourcer. Desuden både med selvstændige servere og virtuelle maskiner og klynger af fysiske servere, hvorpå alle disse virtuelle maskiner snurrer kraftigt.
Udsigterne
Nu har vi kernen i systemet som helhed klar, men der er stadig mange ting, der stadig skal arbejdes på. Dette er som minimum et informationssikkerhedslag, men det er også vigtigt at nå netværket, udvikle alarmering og løse problemet med korrelation. Vi har mange lag og systemer, og på hvert lag er der mange flere målinger. Det viser sig at være en matryoshka i samme grad som en matryoshka.
Vores opgave er i sidste ende at lave de rigtige advarsler. For eksempel, hvis der var et problem med hardwaren, igen med en virtuel maskine, og der var en vigtig applikation, og tjenesten blev ikke sikkerhedskopieret på nogen måde. Vi finder ud af, at den virtuelle maskine er død. Så vil forretningsmålinger advare dig: brugere er forsvundet et sted, der er ingen konvertering, brugergrænsefladen i grænsefladen er utilgængelig, software og tjenester er også døde.
I denne situation vil vi modtage spam fra advarsler, og dette passer ikke længere ind i formatet af et ordentligt overvågningssystem. Spørgsmålet om sammenhæng opstår. Derfor burde vores overvågningssystem ideelt set sige: "Gunner, jeres fysiske maskine er død, og sammen med den denne applikation og disse målinger," ved hjælp af en advarsel, i stedet for rasende at bombardere os med hundrede advarsler. Det bør rapportere det vigtigste - årsagen, som hjælper med hurtigt at eliminere problemet på grund af dets lokalisering.
Vores meddelelsessystem og alarmbehandling er bygget op omkring en XNUMX-timers hotline-service. Alle advarsler, der anses for at være et must-have, og som er inkluderet i tjeklisten, sendes dertil. Hver advarsel skal have en beskrivelse: hvad der skete, hvad det faktisk betyder, hvad det påvirker. Og også et link til dashboardet og instruktioner om, hvad du skal gøre i dette tilfælde.
Det hele handler om kravene til opbygning af en alarm. Så kan situationen udvikle sig i to retninger – enten er der et problem og skal løses, eller også er der sket en fejl i overvågningssystemet. Men under alle omstændigheder skal du gå og finde ud af det.
I gennemsnit modtager vi nu omkring hundrede advarsler om dagen, under hensyntagen til, at korrelationen af advarsler endnu ikke er korrekt konfigureret. Og hvis vi skal udføre teknisk arbejde, og vi tvangsslukker noget, stiger deres antal betydeligt.
Ud over at overvåge de systemer, som vi driver, og indsamle metrics, der anses for vigtige fra vores side, giver overvågningssystemet os mulighed for at indsamle data til produktteams. De kan påvirke sammensætningen af målinger i de informationssystemer, som vi overvåger.
Vores kollega kommer måske og beder om at tilføje noget metric, der vil være nyttigt for både os og teamet. Eller for eksempel kan teamet ikke have nok af de grundlæggende metrics, som vi har; de skal spore nogle specifikke. I Grafana opretter vi et rum til hvert hold og giver administratorrettigheder. Også, hvis et team har brug for dashboards, men de ikke selv kan/ved ikke, hvordan det skal gøres, hjælper vi dem.
Da vi er uden for strømmen af teamets værdiskabelse, deres udgivelser og planlægning, er vi gradvist ved at nå til den konklusion, at udgivelser af alle systemer er problemfrie og kan rulles ud dagligt uden koordinering med os. Og det er vigtigt for os at overvåge disse udgivelser, fordi de potentielt kan påvirke driften af applikationen og ødelægge noget, og det er afgørende. Til at administrere udgivelser bruger vi Bamboo, hvorfra vi modtager data via API og kan se hvilke udgivelser der er udgivet i hvilke informationssystemer og deres status. Og det vigtigste er på hvilket tidspunkt. Vi overlejrer frigivelsesmarkører på de vigtigste kritiske metrikker, hvilket visuelt er meget vejledende i tilfælde af problemer.
På denne måde kan vi se sammenhængen mellem nye udgivelser og nye problemer. Hovedideen er at forstå, hvordan systemet fungerer på alle lag, hurtigt lokalisere problemet og rette det lige så hurtigt. Det sker jo ofte, at det, der tager mest tid, ikke er at løse problemet, men at søge efter årsagen.
Og på dette område vil vi i fremtiden fokusere på proaktivitet. Ideelt set vil jeg gerne vide om et nærliggende problem på forhånd, og ikke efter kendsgerningen, så jeg kan forhindre det i stedet for at løse det. Nogle gange opstår der falske alarmer fra overvågningssystemet, både på grund af menneskelige fejl og på grund af ændringer i applikationen. Og vi arbejder på dette, fejlretter det og forsøger at advare brugere, der bruger det sammen med os, om dette før enhver manipulation af overvågningssystemet , eller udfør disse aktiviteter i det tekniske vindue.
Så systemet er blevet lanceret og har fungeret med succes siden begyndelsen af foråret... og viser meget reelle overskud. Selvfølgelig er dette ikke den endelige version; vi vil introducere mange flere nyttige funktioner. Men lige nu, med så mange integrationer og applikationer, er overvågningsautomatisering virkelig uundgåelig.
Hvis du også overvåger store projekter med et betydeligt antal integrationer, så skriv i kommentarerne, hvilken sølvkugle du fandt til dette.
Kilde: www.habr.com
