

De dage er forbi, hvor du ikke behøvede at bekymre dig om at optimere databasens ydeevne. Tiden står ikke stille. Enhver ny tech-iværksætter ønsker at skabe den næste Facebook, samtidig med at de forsøger at indsamle alle de data, de kan få fat i. Disse data er nødvendige for virksomheder for bedre at kunne træne modeller, der hjælper dem med at tjene penge. Under sådanne forhold er programmører nødt til at oprette API'er, der giver dem mulighed for at arbejde hurtigt og pålideligt med enorme mængder information.
Hvis du har designet server-side applikationer eller databaser i et stykke tid, har du sandsynligvis skrevet kode til at udføre paginerede forespørgsler. For eksempel denne her:
SELECT * FROM table_name LIMIT 10 OFFSET 40
Er det sådan?
Men hvis det er sådan, du har lavet din paginering, må jeg desværre sige, at du ikke har gjort det på den mest effektive måde.
Vil du protestere mod mig? . , и bruger allerede de teknikker, jeg vil tale om i dag.
Nævn én backend-udvikler, der aldrig har brugt OFFSET и LIMIT at udføre paginerede forespørgsler. I MVP (Minimum Viable Product) og i projekter, hvor der anvendes små mængder data, er denne tilgang ret anvendelig. Det "virker bare", så at sige.
Men hvis du har brug for at oprette pålidelige og effektive systemer fra bunden, bør du på forhånd sørge for effektiviteten af at udføre forespørgsler til de databaser, der bruges i sådanne systemer.
I dag vil vi tale om de problemer, der er forbundet med udbredte (desværre) implementeringer af paginerede forespørgselsmotorer, og hvordan man opnår høj ydeevne, når man udfører sådanne forespørgsler.
Hvad er der galt med OFFSET og LIMIT?
Som allerede sagt, OFFSET и LIMIT De klarer sig godt i projekter, der ikke kræver arbejde med store mængder data.
Problemet opstår, når databasen vokser til en sådan størrelse, at den ikke længere passer i serverens hukommelse. Men når du arbejder med denne database, skal du bruge forespørgsler med pagination.
For at dette problem kan manifestere sig, skal der opstå en situation, hvor DBMS'et tyr til en ineffektiv fuld tabelscanningsoperation for hver pagineret forespørgsel (samtidig kan der forekomme indsættelses- og sletningsoperationer, og vi har ikke brug for de forældede data!).
Hvad er en "fuld tabelscanning" (eller "sekventiel tabelscanning")? Dette er en operation, hvor DBMS'en sekventielt læser hver række i tabellen, dvs. dataene i den, og kontrollerer, om de overholder en given betingelse. Denne type tabelscanning er kendt for at være den langsomste. Pointen er, at når den udføres, udføres der mange input/output-operationer, som involverer serverens diskundersystem. Situationen forværres af den latenstid, der er forbundet med at arbejde med data gemt på diske, og det faktum, at overførsel af data fra disk til hukommelse er en ressourcekrævende operation.
For eksempel har du poster på 100000000 brugere, og du udfører en forespørgsel med konstruktionen OFFSET 50000000. Det betyder, at DBMS'en skal indlæse alle disse poster (og vi har ikke engang brug for dem!), lægge dem i hukommelsen, og først derefter tage, lad os sige, de 20 resultater, der rapporteres i LIMIT.
Lad os sige, at det kunne se sådan ud: "vælg rækker fra 50000 til 50020 ud af 100000". Det vil sige, at systemet først skal indlæse 50000 rækker for at udføre forespørgslen. Se hvor meget unødvendigt arbejde hun bliver nødt til at lave?
Hvis du ikke tror mig, så tag et kig på det eksempel, jeg har lavet ved hjælp af funktionerne .
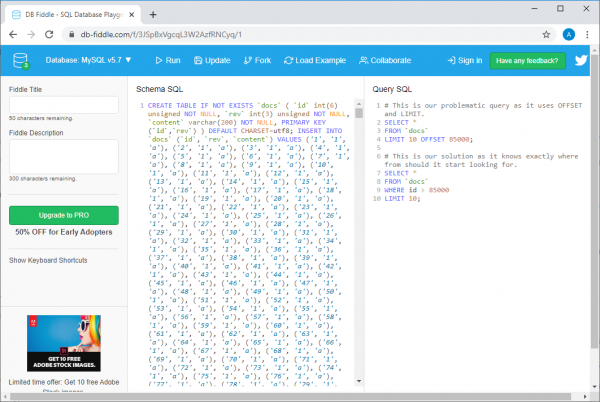
Eksempel på db-fiddle.com
Der, til venstre, på marken Schema SQL, der er kode, der indsætter 100000 rækker i databasen, og til højre, i feltet Query SQL, der vises to forespørgsler. Den første, langsomme, ser sådan ud:
SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
Og den anden, som er en effektiv løsning på det samme problem, er:
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
For at udføre disse anmodninger skal du blot klikke på knappen Run øverst på siden. Når vi har gjort dette, lad os sammenligne oplysningerne om udførelsestiden for forespørgsler. Det viser sig, at den ineffektive forespørgsel tager mindst 30 gange længere tid at udføre end den anden (denne tid varierer fra kørsel til kørsel, for eksempel kan systemet rapportere, at den første forespørgsel tog 37 ms at udføre, mens den anden tog 1 ms).
Og hvis der er flere data, så vil alt se endnu værre ud (for at se dette, tag et kig på min med 10 millioner linjer).
Det, vi lige har diskuteret, burde give dig en vis forståelse af, hvordan databaseforespørgsler rent faktisk behandles.
Bemærk venligst, at jo højere værdien er OFFSET — jo længere tid tager det at udføre anmodningen.
Hvad skal bruges i stedet for kombinationen af OFFSET og LIMIT?
I stedet for en kombination OFFSET и LIMIT Det er værd at bruge et design bygget i henhold til følgende skema:
SELECT * FROM table_name WHERE id > 10 LIMIT 20
Dette er en markørbaseret pagination-forespørgselsudførelse.
I stedet for at gemme de nuværende lokalt OFFSET и LIMIT og sende dem med hver anmodning, skal du gemme den sidst modtagne primære nøgle (normalt er dette ID) Og LIMIT, som følge heraf vil du modtage forespørgsler svarende til den ovenfor.
Hvorfor? Pointen er, at ved eksplicit at angive identifikatoren for den sidst læste række, fortæller du din DBMS, hvor den skal begynde at søge efter de nødvendige data. Desuden vil søgningen, takket være brugen af nøglen, blive udført effektivt; Systemet behøver ikke at blive distraheret af linjer, der er placeret uden for det angivne område.
Lad os se på følgende præstationssammenligning af forskellige forespørgsler. Her er en ineffektiv forespørgsel.
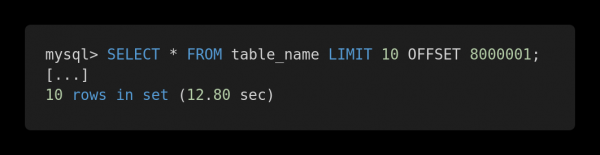
Langsom anmodning
Her er en optimeret version af denne forespørgsel.
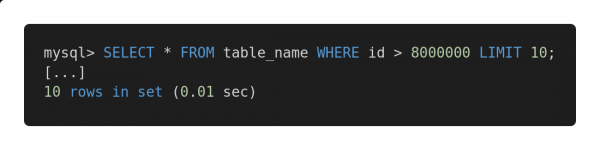
Hurtig anmodning
Begge forespørgsler returnerer præcis den samme mængde data. Men den første tager 12,80 sekunder at gennemføre, og den anden tager 0,01 sekunder. Mærker du forskellen?
Mulige problemer
For at den foreslåede forespørgselsudførelsesmetode kan fungere effektivt, skal tabellen have en kolonne (eller kolonner), der indeholder unikke, sekventielle indekser, f.eks. et heltals-id. I nogle specifikke tilfælde kan dette afgøre, om sådanne forespørgsler kan bruges til at forbedre hastigheden på arbejdet med databasen.
Når du konstruerer forespørgsler, skal du naturligvis tage højde for tabelarkitekturens funktioner og vælge de mekanismer, der fungerer bedst på de eksisterende tabeller. Hvis du for eksempel skal arbejde med forespørgsler med store mængder relaterede data, kan det være interessant for dig artikel.
Hvis vi står over for problemet med fraværet af en primærnøgle, for eksempel hvis vi har en tabel med en mange-til-mange-relation, så er den traditionelle tilgang, som involverer brugen af OFFSET и LIMIT, vi er garanteret at kunne lide det. Men brugen af den kan resultere i potentielt langsomme forespørgsler. I tilfælde som disse vil jeg anbefale at bruge en automatisk inkrementerende primærnøgle, selvom det kun er nødvendigt for at aktivere paginerede forespørgsler.
Hvis du er interesseret i dette emne - , и - nogle nyttige materialer.
Resultaterne af
Den vigtigste konklusion, vi kan drage, er, at uanset hvilken størrelse database vi taler om, bør vi altid analysere forespørgselsudførelseshastigheden. I dag er skalerbarhed af løsninger ekstremt vigtig, og hvis alt er designet korrekt fra starten af arbejdet på et bestemt system, kan dette spare udvikleren for mange problemer i fremtiden.
Hvordan analyserer og optimerer du databaseforespørgsler?
Kilde: www.habr.com
