


Indrejse
Hi!
I denne artikel vil jeg dele min erfaring med at bygge en mikroservicearkitektur til et projekt ved hjælp af neurale netværk.
Lad os tale om arkitekturkravene, se på forskellige strukturelle diagrammer, analysere hver af komponenterne i den færdige arkitektur og også evaluere løsningens tekniske målinger.
Nyd læsning!
Et par ord om problemet og dets løsning
Hovedideen er at vurdere en persons tiltrækningskraft på en ti-punkts skala baseret på et foto.
I denne artikel vil vi gå væk fra at beskrive både de anvendte neurale netværk og processen med dataforberedelse og træning. Men i en af de følgende publikationer vil vi helt sikkert vende tilbage til at analysere vurderingspipelinen på et dybdegående niveau.
Nu vil vi gennemgå evalueringspipelinen på topniveau og fokusere på interaktionen mellem mikrotjenester i sammenhæng med den overordnede projektarkitektur.
Under arbejdet med pipeline til vurdering af attraktivitet blev opgaven opdelt i følgende komponenter:
- Valg af ansigter på billeder
- Bedømmelse af hver person
- Gengiv resultatet
Den første er løst af kræfterne fra fortrænede . For det andet blev et konvolutionelt neuralt netværk trænet på PyTorch ved hjælp af – fra balancen "kvalitet / hastighed af inferens på CPU'en"

Funktionelt diagram af evalueringspipeline
Analyse af krav til projektarkitektur
I livscyklussen projektstadier i arbejdet med arkitektur og automatisering af modelimplementering er ofte blandt de mest tids- og ressourcekrævende.
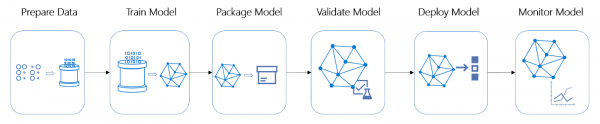
Livscyklus for et ML-projekt
Dette projekt er ingen undtagelse - beslutningen blev truffet om at pakke vurderingspipelinen ind i en onlinetjeneste, hvilket krævede at fordybe os i arkitekturen. Følgende grundlæggende krav blev identificeret:
- Samlet loglagring – alle tjenester skal skrive logs på ét sted, de skal være praktiske at analysere
- Mulighed for horisontal skalering af vurderingstjenesten - som den mest sandsynlige flaskehals
- Den samme mængde processorressourcer bør allokeres til at evaluere hvert billede for at undgå afvigelser i fordelingen af tid til slutninger
- Hurtig (gen)implementering af både specifikke tjenester og stakken som helhed
- Evnen til, om nødvendigt, at bruge fælles objekter i forskellige tjenester
arkitektur
Efter at have analyseret kravene blev det klart, at mikroservicearkitekturen passer næsten perfekt.
For at slippe af med unødvendig hovedpine blev Telegram API valgt som frontend.
Lad os først se på det strukturelle diagram af den færdige arkitektur, derefter gå videre til en beskrivelse af hver af komponenterne og også formalisere processen med vellykket billedbehandling.
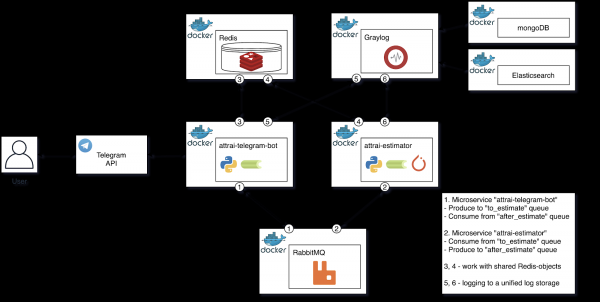
Strukturdiagram af den færdige arkitektur
Lad os tale mere detaljeret om hver af komponenterne i diagrammet, der betegner dem Single Responsibility i processen med billedevaluering.
Microservice "attrai-telegram-bot"
Denne mikrotjeneste indkapsler alle interaktioner med Telegram API. Der er 2 hovedscenarier: arbejde med et tilpasset billede og arbejde med resultatet af en vurderingspipeline. Lad os se på begge scenarier i generelle vendinger.
Når du modtager en brugerdefineret besked med et billede:
- Filtrering udføres, bestående af følgende kontroller:
- Tilgængelighed af optimal billedstørrelse
- Antal brugerbilleder, der allerede er i kø
- Når den indledende filtrering er gennemført, gemmes billedet i docker-volumen
- Der produceres en opgave i "to_estimate"-køen, som blandt andet inkluderer stien til billedet, der ligger i vores bind
- Hvis ovenstående trin er gennemført med succes, vil brugeren modtage en besked med den omtrentlige billedbehandlingstid, som beregnes ud fra antallet af opgaver i køen. Hvis der opstår en fejl, vil brugeren få en eksplicit besked ved at sende en besked med information om, hvad der kan være gået galt.
Desuden lytter denne mikroservice, ligesom en selleriarbejder, til "efter_estimate"-køen, som er beregnet til opgaver, der er gået gennem evalueringspipelinen.
Når du modtager en ny opgave fra "after_estimate":
- Hvis billedet behandles med succes, sender vi resultatet til brugeren; hvis ikke, giver vi besked om en fejl.
- Fjernelse af billedet, der er resultatet af evalueringspipelinen
Evaluering mikroservice "attrai-estimator"
Denne mikroservice er en selleriarbejder og indkapsler alt relateret til billedevalueringspipeline. Der er kun én fungerende algoritme her - lad os analysere den.
Når du modtager en ny opgave fra "to_estimate":
- Lad os køre billedet gennem evalueringspipelinen:
- Indlæser billedet i hukommelsen
- Vi bringer billedet til den ønskede størrelse
- Finder alle ansigter (MTCNN)
- Vi evaluerer alle ansigter (vi pakker de ansigter, der blev fundet i sidste trin ind i en batch og konkluderer ResNet34)
- Gengiv det endelige billede
- Lad os tegne afgrænsningsfelterne
- Tegning af vurderinger
- Sletning af et brugerdefineret (originalt) billede
- Gemmer output fra evalueringspipeline
- Vi sætter opgaven i "after_estimate"-køen, som lyttes til af "attrai-telegram-bot"-mikrotjenesten diskuteret ovenfor.
Graylog (+ mongoDB + Elasticsearch)
er en løsning til centraliseret logstyring. I dette projekt blev det brugt til det tilsigtede formål.
Valget faldt på ham, og ikke på den sædvanlige stack, på grund af bekvemmeligheden ved at arbejde med det fra Python. Alt du skal gøre for at logge på Graylog er at tilføje GELFTCPHandler fra pakken til resten af rodlogger-handlerne i vores python-mikrotjeneste.
Som en, der tidligere kun havde arbejdet med ELK-stakken, havde jeg en generelt positiv oplevelse, mens jeg arbejdede med Graylog. Det eneste, der er deprimerende, er overlegenheden i Kibana-funktioner over Graylog-webgrænsefladen.
RabbitMQ
er en meddelelsesmægler baseret på AMQP-protokollen.
I dette projekt blev det brugt som mægler for Selleri og arbejdede i holdbar tilstand.
Omfor
er et NoSQL DBMS, der arbejder med nøgleværdi datastrukturer
Nogle gange er der behov for at bruge almindelige objekter, der implementerer bestemte datastrukturer i forskellige Python-mikrotjenester.
For eksempel gemmer Redis et hashmap af formen "telegram_user_id => antal aktive opgaver i køen", som giver dig mulighed for at begrænse antallet af anmodninger fra én bruger til en bestemt værdi og derved forhindre DoS-angreb.
Lad os formalisere processen med vellykket billedbehandling
- Brugeren sender et billede til Telegram-bot
- "attrai-telegram-bot" modtager en besked fra Telegram API og analyserer den
- Opgaven med billedet føjes til den asynkrone kø "to_estimate"
- Brugeren modtager en besked med den planlagte vurderingstid
- "attrai-estimator" tager en opgave fra "to_estimate"-køen, kører estimaterne gennem pipelinen og producerer opgaven i "after_estimate"-køen
- "attrai-telegram-bot" lytter til "after_estimate"-køen, sender resultatet til brugeren
DevOps
Endelig, efter at have gennemgået arkitekturen, kan du gå videre til den lige så interessante del - DevOps
Docker sværm

— et klyngesystem, hvis funktionalitet er implementeret inde i Docker Engine og er tilgængelig direkte fra kassen.
Ved at bruge en "sværm" kan alle noder i vores klynge opdeles i 2 typer - arbejder og leder. På maskiner af den første type er grupper af containere (stakke) indsat, maskiner af den anden type er ansvarlige for skalering, balancering og . Ledere er også arbejdere som standard.
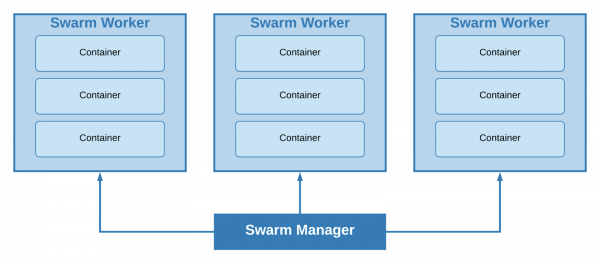
Klynge med en lederleder og tre medarbejdere
Den mindst mulige klyngestørrelse er 1 node; en enkelt maskine vil samtidigt fungere som lederleder og arbejder. På baggrund af projektets størrelse og minimumskravene til fejltolerance blev det besluttet at anvende denne tilgang.
Når jeg ser fremad, vil jeg sige, at siden den første produktionslevering, som var i midten af juni, har der ikke været problemer forbundet med denne klyngeorganisation (men det betyder ikke, at en sådan organisation på nogen måde er acceptabel i nogen mellem-stor projekter, som er underlagt fejltolerancekrav).
Docker Stack
I sværmtilstand er han ansvarlig for at implementere stakke (sæt af docker-tjenester)
Det understøtter docker-compose-konfigurationer, hvilket giver dig mulighed for yderligere at bruge implementeringsparametre.
Ved at bruge disse parametre var ressourcerne for hver af evalueringsmikrotjenesteinstanserne f.eks. begrænsede (vi tildeler N kerner til N instanser, i selve mikrotjenesten begrænser vi antallet af kerner brugt af PyTorch til én)
attrai_estimator:
image: 'erqups/attrai_estimator:1.2'
deploy:
replicas: 4
resources:
limits:
cpus: '4'
restart_policy:
condition: on-failure
…Det er vigtigt at bemærke, at Redis, RabbitMQ og Graylog er stateful tjenester, og de kan ikke skaleres så let som "attrai-estimator"
Foreskygger spørgsmålet - hvorfor ikke Kubernetes?
Det ser ud til, at det er en overhead at bruge Kubernetes i små og mellemstore projekter; al den nødvendige funktionalitet kan fås fra Docker Swarm, som er ret brugervenlig for en containerorkestrator og også har en lav adgangsbarriere.
Infrastruktur
Alt dette blev implementeret på VDS med følgende egenskaber:
- CPU: 4-kernet Intel® Xeon® Gold 5120 CPU @ 2.20 GHz
- RAM: 8 GB
- SSD: 160GB
Efter lokal belastningstest så det ud til, at med en seriøs tilstrømning af brugere ville denne maskine være nok.
Men umiddelbart efter implementeringen postede jeg et link til et af de mest populære imageboards i CIS (yup, det samme), hvorefter folk blev interesserede, og i løbet af få timer behandlede tjenesten titusindvis af billeder. På samme tid blev CPU- og RAM-ressourcer ikke engang halvt brugt i spidsbelastningsperioder.
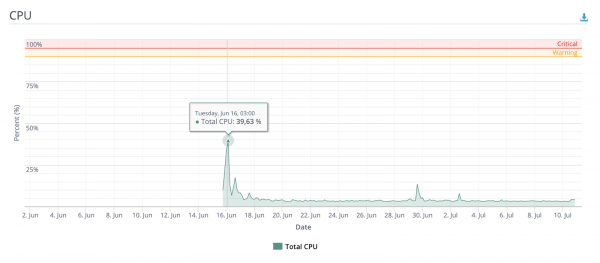
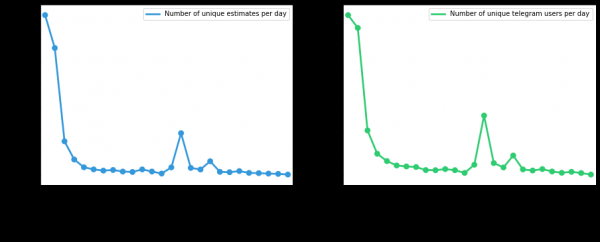
Lidt mere grafik
Antal unikke brugere og evalueringsanmodninger siden implementeringen, afhængigt af dagen
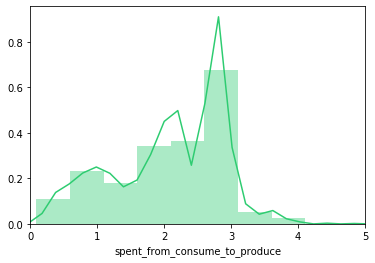
Evaluering pipeline inferens tidsfordeling
Fund
For at opsummere kan jeg sige, at arkitekturen og tilgangen til orkestrering af containere fuldt ud berettigede sig selv - selv i spidsbelastningsperioder var der ingen fald eller fald i behandlingstiden.
Jeg tror, at små og mellemstore projekter, der bruger realtidsslutning af neurale netværk på CPU'en i deres proces, med succes kan anvende den praksis, der er beskrevet i denne artikel.
Jeg vil tilføje, at artiklen oprindeligt var længere, men for ikke at skrive en longread, besluttede jeg at udelade nogle punkter i denne artikel - vi vender tilbage til dem i fremtidige publikationer.
Du kan stikke botten på Telegram - @AttraiBot, det vil fungere i det mindste indtil slutningen af efteråret 2020. Lad mig minde dig om, at der ikke gemmes nogen brugerdata - hverken de originale billeder eller resultaterne af evalueringspipelinen - alt bliver revet ned efter behandling.
Kilde: www.habr.com
