

Vores brugere skriver beskeder til hinanden uden at føle sig trætte.

Det er ret meget. Hvis du satte dig for at læse alle beskeder fra alle brugere, ville det tage mere end 150 tusind år. Forudsat at du er en ret avanceret læser og ikke bruger mere end et sekund på hver besked.
Med en sådan mængde data er det afgørende, at logikken for lagring og adgang til dem er bygget optimalt. Ellers kan det i et knap så vidunderligt øjeblik blive klart, at alt snart vil gå galt.
For os kom dette øjeblik for halvandet år siden. Hvordan vi kom til dette, og hvad der skete i sidste ende - vi fortæller dig i rækkefølge.
sygehistorie
I den allerførste implementering fungerede VKontakte-meddelelser på en kombination af PHP-backend og MySQL. Dette er en helt normal løsning for en lille studerende hjemmeside. Dette websted voksede imidlertid ukontrolleret og begyndte at kræve optimering af datastrukturer for sig selv.
I slutningen af 2009 blev det første tekstmotorlager skrevet, og i 2010 blev meddelelser overført til det.
I tekstmotoren blev beskeder gemt i lister - en slags "postkasser". Hver sådan liste bestemmes af en uid - den bruger, der ejer alle disse meddelelser. En besked har et sæt attributter: samtalepartner-id, tekst, vedhæftede filer og så videre. Meddelelses-id'et inde i "boksen" er local_id, det ændres aldrig og tildeles sekventielt for nye beskeder. "Bokserne" er uafhængige og er ikke synkroniseret med hinanden inde i motoren kommunikationen mellem dem sker på PHP-niveau. Du kan se på tekst-motorens datastruktur og muligheder indefra .
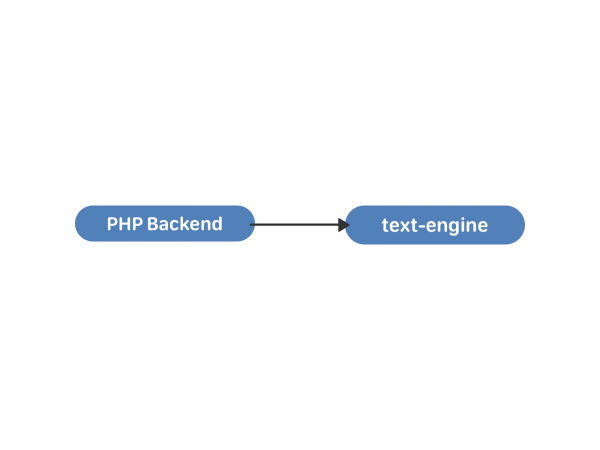
Dette var ganske nok til korrespondance mellem to brugere. Gæt hvad der skete derefter?
I maj 2011 introducerede VKontakte samtaler med flere deltagere - multichat. For at arbejde med dem rejste vi to nye klynger - medlemschat og chat-medlemmer. Den første gemmer data om chats af brugere, den anden gemmer data om brugere via chats. Ud over selve listerne omfatter dette for eksempel den inviterende bruger og tidspunktet, hvor de blev tilføjet chatten.
"PHP, lad os sende en besked til chatten," siger brugeren.
"Kom nu, {brugernavn}," siger PHP.
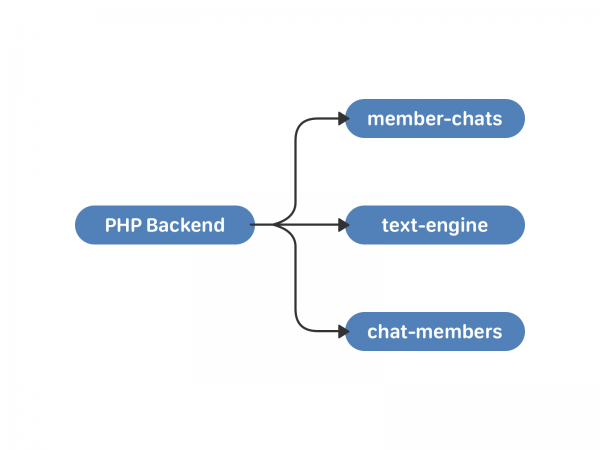
Der er ulemper ved denne ordning. Synkronisering er stadig PHPs ansvar. Store chats og brugere, der samtidig sender beskeder til dem, er en farlig historie. Da tekstmotorforekomsten afhænger af uid'et, kan chatdeltagere modtage den samme besked på forskellige tidspunkter. Det kunne man leve med, hvis fremskridtet stod stille. Men dette vil ikke ske.
I slutningen af 2015 lancerede vi fællesskabsbeskeder, og i begyndelsen af 2016 lancerede vi en API til dem. Med fremkomsten af store chatbots i fællesskaber var det muligt at glemme en jævn belastningsfordeling.
En god bot genererer flere millioner beskeder om dagen - selv de mest snakkesalige brugere kan ikke prale af dette. Det betyder, at nogle forekomster af tekstmotorer, som sådanne bots levede på, begyndte at lide det fulde.
Beskedmotorer i 2016 er 100 forekomster af chat-medlemmer og medlemschat, og 8000 tekst-motorer. De var hostet på tusinde servere, hver med 64 GB hukommelse. Som en første nødforanstaltning øgede vi hukommelsen med yderligere 32 GB. Vi estimerede prognoserne. Uden drastiske ændringer ville dette være nok til omkring endnu et år. Du skal enten have fat i hardware eller optimere selve databaserne.
På grund af arkitekturens natur giver det kun mening at øge hardware i multipler. Det vil sige i det mindste en fordobling af antallet af biler – det er naturligvis en ret dyr vej. Vi vil optimere.
Nyt koncept
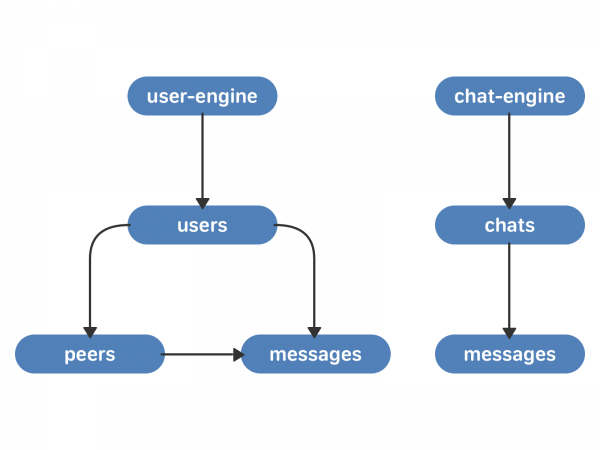
Den centrale essens af den nye tilgang er chat. En chat har en liste over beskeder, der vedrører den. Brugeren har en liste over chats.
Det påkrævede minimum er to nye databaser:
- chat-motor. Dette er et lager af chatvektorer. Hver chat har en vektor af beskeder, der relaterer til den. Hver besked har en tekst og en unik besked-id i chatten - chat_local_id.
- bruger-motor. Dette er en opbevaring af brugervektorer - links til brugere. Hver bruger har en vektor af peer_id (samtaler - andre brugere, multichat eller fællesskaber) og en vektor af meddelelser. Hver peer_id har en vektor af meddelelser, der relaterer til den. Hver besked har et chat_local_id og et unikt besked-id for den bruger - user_local_id.
Nye klynger kommunikerer med hinanden ved hjælp af TCP - dette sikrer, at rækkefølgen af anmodninger ikke ændres. Selve anmodningerne og bekræftelser på dem registreres på harddisken - så vi kan genoprette køens tilstand til enhver tid efter en fejl eller genstart af motoren. Da bruger-motoren og chat-motoren er på 4 tusinde shards hver, vil anmodningskøen mellem klyngerne blive fordelt jævnt (men i virkeligheden er der ingen overhovedet - og det virker meget hurtigt).
Arbejdet med disk i vores databaser er i de fleste tilfælde baseret på en kombination af en binær log over ændringer (binlog), statiske snapshots og et delvist billede i hukommelsen. Ændringer i løbet af dagen skrives til en binlog, og der oprettes med jævne mellemrum et øjebliksbillede af den aktuelle tilstand. Et snapshot er en samling af datastrukturer, der er optimeret til vores formål. Den består af en header (metaindeks af billedet) og et sæt metafiler. Headeren er permanent gemt i RAM og angiver, hvor der skal søges efter data fra øjebliksbilledet. Hver metafil indeholder data, der sandsynligvis vil være nødvendige på tætte tidspunkter - for eksempel relateret til en enkelt bruger. Når du forespørger i databasen ved hjælp af snapshot-headeren, læses den påkrævede metafil, og derefter tages der hensyn til ændringer i binlogen, der opstod efter at snapshottet blev oprettet. Du kan læse mere om fordelene ved denne tilgang .
Samtidig ændres dataene på selve harddisken kun én gang om dagen - sent om natten i Moskva, når belastningen er minimal. Takket være dette (ved at strukturen på disken er konstant i løbet af dagen), har vi råd til at erstatte vektorer med arrays af en fast størrelse - og på grund af dette øges hukommelsen.
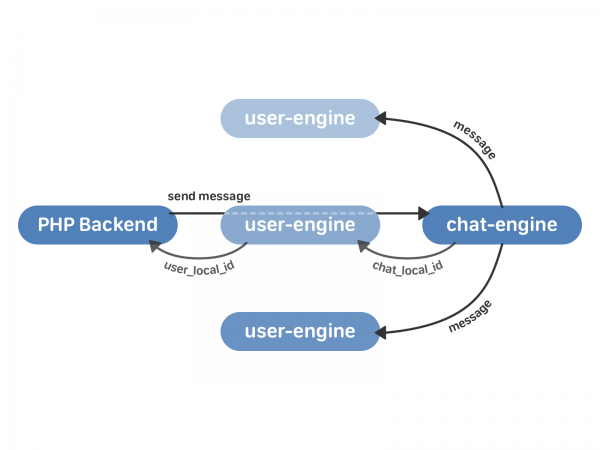
At sende en besked i den nye ordning ser sådan ud:
- PHP-backend kontakter brugermotoren med en anmodning om at sende en besked.
- user-engine proxiserer anmodningen til den ønskede chat-engine-instans, som returnerer til user-engine chat_local_id - en unik identifikator for en ny besked i denne chat. Chat-motoren udsender derefter beskeden til alle modtagere i chatten.
- user-engine modtager chat_local_id fra chat-engine og returnerer user_local_id til PHP - en unik besked-id for denne bruger. Denne identifikator bruges så for eksempel til at arbejde med beskeder via API'et.
Men ud over faktisk at sende beskeder, skal du implementere et par vigtigere ting:
- Underlister er for eksempel de seneste beskeder, du ser, når du åbner samtalelisten. Ulæste beskeder, beskeder med tags ("Vigtigt", "Spam" osv.).
- Komprimering af beskeder i chat-motor
- Caching af beskeder i brugermotor
- Søg (gennem alle dialoger og inden for en bestemt).
- Realtidsopdatering (Longpolling).
- Gemmer historik for at implementere caching på mobile klienter.
Alle underlister ændrer sig hurtigt i strukturer. Til at arbejde med dem bruger vi . Dette valg forklares ved, at vi i toppen af træet nogle gange gemmer et helt segment af beskeder fra et snapshot - for eksempel, efter natlig genindeksering, består træet af én top, som indeholder alle beskederne i underlisten. Splay-træet gør det nemt at indsætte i midten af sådan et vertex uden at skulle tænke på balancering. Derudover gemmer Splay ikke unødvendige data, hvilket sparer os for hukommelse.
Beskeder involverer en stor mængde information, for det meste tekst, som er nyttig at kunne komprimere. Det er vigtigt, at vi nøjagtigt kan arkivere selv en enkelt besked. Bruges til at komprimere beskeder med vores egen heuristik - for eksempel ved vi, at ord i beskeder veksler med "ikke-ord" - mellemrum, tegnsætningstegn - og vi husker også nogle af funktionerne ved at bruge symboler til det russiske sprog.
Da der er meget færre brugere end chats, for at gemme diskanmodninger med tilfældig adgang i chat-engine, cacher vi meddelelser i user-engine.
Beskedsøgning implementeres som en diagonal forespørgsel fra brugermotor til alle chat-motorforekomster, der indeholder chats fra denne bruger. Resultaterne kombineres i selve brugermotoren.
Nå, der er taget højde for alle detaljerne, der er kun tilbage at skifte til en ny ordning – og helst uden at brugerne opdager det.
Datamigrering
Så vi har en tekst-motor, der gemmer beskeder efter bruger, og to klynger chat-medlemmer og medlems-chat, der gemmer data om multi-chat rum og brugerne i dem. Hvordan flytter man fra denne til den nye bruger- og chat-motor?
medlemschats i den gamle ordning blev primært brugt til optimering. Vi overførte hurtigt de nødvendige data fra den til chat-medlemmer, og så deltog den ikke længere i migreringsprocessen.
Kø for chat-medlemmer. Det inkluderer 100 tilfælde, mens chat-motoren har 4 tusinde. For at overføre dataene skal du bringe dem i overensstemmelse - til dette blev chat-medlemmer opdelt i de samme 4 tusinde kopier, og derefter blev læsning af chat-medlemmers binlog aktiveret i chat-motoren.
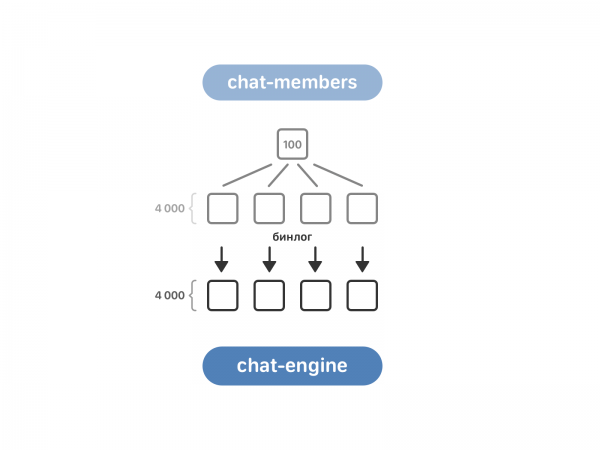
Nu kender chat-motoren til multi-chat fra chat-medlemmer, men den ved endnu ikke noget om dialoger med to samtalepartnere. Sådanne dialoger er placeret i tekst-motoren med reference til brugere. Her tog vi dataene "head-on": hver chat-engine-instans spurgte alle tekst-engine-instanser, om de havde den dialog, de havde brug for.
Fantastisk - chat-motoren ved, hvilke multi-chat-chats der er, og ved hvilke dialoger der er.
Du skal kombinere beskeder i multichat-chat, så du ender med en liste over beskeder i hver chat. For det første henter chat-motoren alle brugerbeskeder fra denne chat fra tekst-motoren. I nogle tilfælde er der ret mange af dem (op til hundredvis af millioner), men med meget sjældne undtagelser passer chatten helt ind i RAM. Vi har uordnede beskeder, hver i flere eksemplarer - de er trods alt alle trukket fra forskellige tekst-motor-instanser svarende til brugerne. Målet er at sortere beskeder og slippe af med kopier, der fylder unødvendigt.
Hver besked har et tidsstempel, der indeholder det tidspunkt, den blev sendt, og tekst. Vi bruger tid til sortering - vi placerer pointere til de ældste beskeder fra multichat-deltagere og sammenligner hashes fra teksten i de påtænkte kopier, og bevæger os mod at øge tidsstemplet. Det er logisk, at kopierne vil have samme hash og tidsstempel, men i praksis er det ikke altid tilfældet. Som du husker, blev synkronisering i det gamle skema udført af PHP - og i sjældne tilfælde var tidspunktet for afsendelse af den samme besked forskellig mellem forskellige brugere. I disse tilfælde tillod vi os selv at redigere tidsstemplet - normalt inden for et sekund. Det andet problem er den forskellige rækkefølge af beskeder for forskellige modtagere. I sådanne tilfælde tillod vi at oprette en ekstra kopi med forskellige bestillingsmuligheder for forskellige brugere.
Herefter sendes data om beskeder i multichat til brugermotoren. Og her kommer et ubehageligt træk ved importerede beskeder. Ved normal drift er beskeder, der kommer til motoren, sorteret strengt i stigende rækkefølge efter user_local_id. Meddelelser importeret fra den gamle motor til brugermotoren mistede denne nyttige egenskab. På samme tid, for at gøre det nemt at teste, skal du hurtigt kunne få adgang til dem, lede efter noget i dem og tilføje nye.
Vi bruger en særlig datastruktur til at gemme importerede beskeder.
Det repræsenterer en vektor af størrelse  hvor er allesammen
hvor er allesammen  - er forskellige og ordnet i faldende rækkefølge, med en særlig rækkefølge af elementer. I hvert segment med indekser
- er forskellige og ordnet i faldende rækkefølge, med en særlig rækkefølge af elementer. I hvert segment med indekser  elementer er sorteret. At søge efter et element i en sådan struktur tager tid
elementer er sorteret. At søge efter et element i en sådan struktur tager tid  gennem
gennem  binære søgninger. Tilføjelse af et element amortiseres over
binære søgninger. Tilføjelse af et element amortiseres over  .
.
Så vi fandt ud af, hvordan man overfører data fra gamle motorer til nye. Men denne proces tager flere dage - og det er usandsynligt, at vores brugere vil opgive vanen med at skrive til hinanden i løbet af disse dage. For ikke at miste beskeder i denne tid, skifter vi til en arbejdsordning, der bruger både gamle og nye klynger.
Data skrives til chat-medlemmer og bruger-motor (og ikke til tekst-motor, som ved normal drift i henhold til den gamle ordning). user-engine proxerer anmodningen til chat-engine - og her afhænger adfærden af, om denne chat allerede er slået sammen eller ej. Hvis chatten endnu ikke er blevet flettet, skriver chat-motoren ikke beskeden til sig selv, og dens behandling sker kun i tekst-motoren. Hvis chatten allerede er blevet flettet ind i chat-engine, returnerer den chat_local_id til user-engine og sender beskeden til alle modtagere. user-engine proxerer alle data til tekst-engine - så hvis der sker noget, kan vi altid rulle tilbage med alle de aktuelle data i den gamle motor. text-engine returnerer user_local_id, som brugermotor gemmer og returnerer til backend.
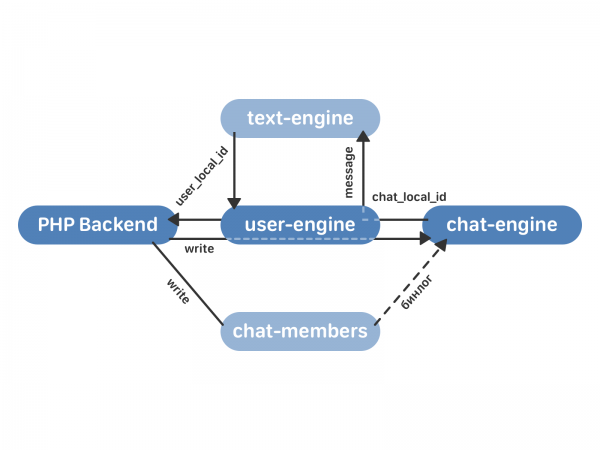
Som et resultat ser overgangsprocessen således ud: Vi forbinder tomme bruger-motor- og chat-engine-klynger. chat-engine læser hele chat-medlemmers binlog, hvorefter proxy starter i henhold til skemaet beskrevet ovenfor. Vi overfører de gamle data, vi får to synkroniserede klynger (gamle og nye). Det eneste, der er tilbage, er at skifte læsning fra tekst-motor til bruger-motor og deaktivere proxy.
Fund
Takket være den nye tilgang er alle motorernes ydeevnemålinger blevet forbedret, og problemer med datakonsistens er blevet løst. Nu kan vi hurtigt implementere nye funktioner i beskeder (og er allerede begyndt at gøre dette - vi øgede det maksimale antal chatdeltagere, implementerede en søgning efter videresendte beskeder, lancerede fastgjorte beskeder og hævede grænsen for det samlede antal beskeder pr. bruger) .
Ændringerne i logikken er virkelig enorme. Og jeg vil gerne bemærke, at dette ikke altid betyder hele års udvikling af et enormt team og myriader af kodelinjer. chat-motor og bruger-motor sammen med alle de ekstra historier som Huffman til meddelelseskomprimering, Splay-træer og struktur for importerede meddelelser er mindre end 20 tusind linjer kode. Og de blev skrevet af 3 udviklere på kun 10 måneder (det er dog værd at huske på, at - verdensmestre ).
Desuden, i stedet for at fordoble antallet af servere, reducerede vi deres antal til det halve - nu lever bruger-motoren og chat-motoren på 500 fysiske maskiner, mens den nye ordning har et stort frirum til belastning. Vi sparede mange penge på udstyr - omkring $5 millioner + $750 tusinde om året i driftsudgifter.
Vi stræber efter at finde de bedste løsninger til de mest komplekse og storstilede problemer. Dem har vi masser af - og derfor søger vi dygtige udviklere i databaseafdelingen. Hvis du elsker og ved, hvordan man løser sådanne problemer, har et fremragende kendskab til algoritmer og datastrukturer, inviterer vi dig til at slutte dig til teamet. Kontakt vores for detaljer.
Selvom denne historie ikke handler om dig, bemærk venligst, at vi værdsætter anbefalinger. Fortæl en ven om , og hvis han fuldfører prøvetiden med succes, vil du modtage en bonus på 100 tusind rubler.
Kilde: www.habr.com
