

I dag vil der ikke være komplekse cases og sofistikerede algoritmer i SQL. Alt vil være meget enkelt, på niveau med Captain Obvious - lad os gøre det se begivenhedsregistret sorteret efter tid.
Det vil sige, at der er et skilt i databasen events, og hun har en mark ts - præcis det tidspunkt, hvor vi ønsker at vise disse poster på en ordnet måde:
CREATE TABLE events(
id
serial
PRIMARY KEY
, ts
timestamp
, data
json
);
CREATE INDEX ON events(ts DESC);Det er klart, at vi ikke vil have et dusin poster der, så vi får brug for en form for sidenavigation.
#0. "Jeg er min mors pogromist"
cur.execute("SELECT * FROM events;")
rows = cur.fetchall();
rows.sort(key=lambda row: row.ts, reverse=True);
limit = 26
print(rows[offset:offset+limit]);
Det er næsten ikke en joke – det er sjældent, men findes i naturen. Nogle gange, efter at have arbejdet med ORM, kan det være svært at skifte til "direkte" arbejde med SQL.
Men lad os gå videre til mere almindelige og mindre åbenlyse problemer.
#1. OFFSET
SELECT
...
FROM
events
ORDER BY
ts DESC
LIMIT 26 OFFSET $1; -- 26 - записей на странице, $1 - начало страницыHvor kom tallet 26 fra? Dette er det omtrentlige antal poster, der skal fylde én skærm. Mere præcist, 25 viste poster, plus 1, der signalerer, at der i det mindste er noget andet længere i prøven, og det giver mening at komme videre.
Selvfølgelig kan denne værdi ikke "syes" ind i forespørgslens krop, men sendes gennem en parameter. Men i dette tilfælde vil PostgreSQL-planlæggeren ikke være i stand til at stole på viden om, at der burde være relativt få poster – og vil nemt vælge en ineffektiv plan.
Og mens visning af registreringsdatabasen er implementeret i applikationsgrænsefladen som at skifte mellem visuelle "sider", bemærker ingen noget mistænkeligt i lang tid. Præcis indtil det øjeblik, hvor UI/UX i kampen om bekvemmelighed beslutter sig for at lave grænsefladen om til "endeløs scroll" - det vil sige, at alle registreringsdatabaseposter tegnes i en enkelt liste, som brugeren kan scrolle op og ned.
Og så under den næste test bliver du fanget duplikering af optegnelser i registret. Hvorfor, fordi tabellen har et normalt indeks (ts), som din forespørgsel bygger på?
Netop fordi du ikke tog højde for det ts er ikke en unik nøgle i denne tabel. Faktisk, og dens værdier er ikke unikke, som enhver "tid" under virkelige forhold - derfor "springer" den samme post i to tilstødende forespørgsler nemt fra side til side på grund af en anden endelig rækkefølge inden for rammerne af at sortere den samme nøgleværdi.
Faktisk er der også et andet problem gemt her, som er meget sværere at bemærke - nogle poster vil ikke blive vist overhovedet! De "duplikerede" optegnelser tog trods alt en andens plads. En detaljeret forklaring med smukke billeder kan findes .
Udvidelse af indekset
En snedig udvikler forstår, at indeksnøglen skal gøres unik, og den nemmeste måde er at udvide den med et åbenlyst unikt felt, som PK er perfekt til:
CREATE UNIQUE INDEX ON events(ts DESC, id DESC);Og anmodningen muterer:
SELECT
...
ORDER BY
ts DESC, id DESC
LIMIT 26 OFFSET $1;#2. Skift til "markører"
Nogen tid senere kommer en DBA til dig og er "glad" for dine ønsker , og generelt er det tid til at skifte til navigation fra sidst viste værdi. Din forespørgsel muterer igen:
SELECT
...
WHERE
(ts, id) < ($1, $2) -- последние полученные на предыдущем шаге значения
ORDER BY
ts DESC, id DESC
LIMIT 26;Du åndede lettet op, indtil det kom...
#3. Rengøringsindekser
Fordi en dag læste din DBA og indså det "ikke det seneste" tidsstempel er ikke godt. Og jeg kom til dig igen - nu med tanken om, at det indeks stadig skulle blive til igen (ts DESC).
Men hvad skal man gøre med det indledende problem med at "hoppe" poster mellem sider?.. Og alt er enkelt - du skal vælge blokke med et ufast antal poster!
Hvem forbyder os generelt ikke at læse "præcis 26", men "ikke mindre end 26"? For eksempel, så der i næste blok er optegnelser med åbenbart forskellige betydninger ts - så vil der ikke være noget problem med at "hoppe" poster mellem blokke!
Sådan opnår du dette:
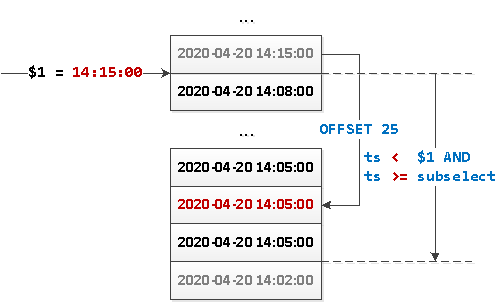
SELECT
...
WHERE
ts < $1 AND
ts >= coalesce((
SELECT
ts
FROM
events
WHERE
ts < $1
ORDER BY
ts DESC
LIMIT 1 OFFSET 25
), '-infinity')
ORDER BY
ts DESC;Hvad sker der her?
- Vi trin 25 registrerer "ned" og får "grænseværdien".
ts. - Hvis der ikke allerede er noget der, skal du erstatte NULL-værdien med
-infinity. - Vi trækker hele segmentet af værdier fra mellem den modtagne værdi
tsog $1-parameteren sendt fra grænsefladen (den forrige "sidste" gengivede værdi). - Hvis en blok returneres med mindre end 26 poster, er det den sidste.
Eller det samme billede:
For nu har vi det prøven har ikke nogen specifik "begyndelse", så forhindrer intet os i at "udvide" denne anmodning i den modsatte retning og implementere dynamisk indlæsning af datablokke fra "referencepunktet" i begge retninger - både ned og op.
bemærkning
- Ja, i dette tilfælde får vi adgang til indekset to gange, men alt er "rent efter indeks". Derfor vil en underforespørgsel kun resultere i til en ekstra kun indeksscanning.
- Det er helt indlysende, at denne teknik kun kan bruges, når du har værdier
tskan kun krydse tilfældigt, og der er ikke mange af dem. Hvis dit typiske tilfælde er "en million poster kl. 00:00:00.000", bør du ikke gøre dette. Jeg mener, du bør ikke tillade sådan en sag at ske. Men hvis dette sker, skal du bruge muligheden med et udvidet indeks.
Kilde: www.habr.com
