

Pas på operationer, der bringer buffere...
Brug en lille forespørgsel som eksempel, lad os se på nogle universelle tilgange til optimering af forespørgsler i PostgreSQL. Om du bruger dem eller ej er op til dig, men det er værd at vide om dem.
I nogle efterfølgende versioner af PG kan situationen ændre sig, efterhånden som skemalæggeren bliver smartere, men for 9.4/9.6 ser det nogenlunde det samme ud som i eksemplerne her.
Lad os tage en meget reel anmodning:
SELECT
TRUE
FROM
"Документ" d
INNER JOIN
"ДокументРасширение" doc_ex
USING("@Документ")
INNER JOIN
"ТипДокумента" t_doc ON
t_doc."@ТипДокумента" = d."ТипДокумента"
WHERE
(d."Лицо3" = 19091 or d."Сотрудник" = 19091) AND
d."$Черновик" IS NULL AND
d."Удален" IS NOT TRUE AND
doc_ex."Состояние"[1] IS TRUE AND
t_doc."ТипДокумента" = 'ПланРабот'
LIMIT 1; om tabel- og feltnavneDe "russiske" navne på felter og tabeller kan behandles forskelligt, men det er en smagssag. Fordi der er ingen udenlandske udviklere, og PostgreSQL giver os mulighed for at give navne selv i hieroglyffer, hvis de omgivet af anførselstegn, så foretrækker vi at navngive objekter entydigt og tydeligt, så der ikke er uoverensstemmelser.
Lad os se på den resulterende plan:
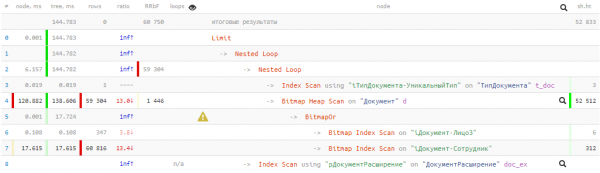
144ms og næsten 53K buffere - det vil sige mere end 400MB data! Og vi vil være heldige, hvis alle af dem er i cachen på tidspunktet for vores anmodning, ellers vil det tage mange gange længere tid, når de læses fra disken.
Algoritmen er vigtigst!
For på en eller anden måde at optimere enhver anmodning, skal du først forstå, hvad den skal gøre.
Lad os lade udviklingen af selve databasestrukturen ligge uden for rammerne af denne artikel for nu, og er enige om, at vi kan relativt "billigt" omskriv anmodningen og/eller rulle nogle af de ting, vi har brug for, på basen Indexes.
Så anmodningen:
— kontrollerer eksistensen af mindst et dokument
- i den stand vi har brug for og af en bestemt type
- hvor forfatteren eller udøveren er den medarbejder, vi har brug for
JOIN + LIMIT 1
Ganske ofte er det nemmere for en udvikler at skrive en forespørgsel, hvor et stort antal tabeller først samles, og så er der kun én post tilbage fra hele dette sæt. Men lettere for udvikleren betyder ikke mere effektiv for databasen.
I vores tilfælde var der kun 3 borde - og hvad er effekten...
Lad os først slippe af med forbindelsen med "Document Type"-tabellen, og samtidig fortælle databasen, at vores typeregistrering er unik (vi ved det, men planlæggeren har ingen idé endnu):
WITH T AS (
SELECT
"@ТипДокумента"
FROM
"ТипДокумента"
WHERE
"ТипДокумента" = 'ПланРабот'
LIMIT 1
)
...
WHERE
d."ТипДокумента" = (TABLE T)
...Ja, hvis tabellen/CTE består af et enkelt felt af en enkelt post, så kan du i PG endda skrive sådan, i stedet for
d."ТипДокумента" = (SELECT "@ТипДокумента" FROM T LIMIT 1)Doven evaluering i PostgreSQL-forespørgsler
BitmapOr vs UNION
I nogle tilfælde vil Bitmap Heap Scan koste os meget - for eksempel i vores situation, hvor en hel del poster opfylder den påkrævede betingelse. Vi fik det pga ELLER-tilstand omdannet til BitmapOr- drift i plan.
Lad os vende tilbage til det oprindelige problem - vi skal finde en tilsvarende post til enhver fra betingelserne - det vil sige, at der ikke er behov for at søge efter alle 59K-poster under begge betingelser. Der er en måde at finde ud af en betingelse, og gå kun til den anden, når der ikke blev fundet noget i den første. Følgende design vil hjælpe os:
(
SELECT
...
LIMIT 1
)
UNION ALL
(
SELECT
...
LIMIT 1
)
LIMIT 1"Ekstern" LIMIT 1 sikrer, at søgningen afsluttes, når den første post er fundet. Og hvis den allerede findes i den første blok, vil den anden blok ikke blive udført (aldrig henrettet med respekt for).
"Skjuler vanskelige forhold under CASE"
Der er et ekstremt ubelejligt øjeblik i den oprindelige forespørgsel - at kontrollere status mod den relaterede tabel "DocumentExtension". Uanset sandheden af andre forhold i udtrykket (f.eks. d. "Slettet" ER IKKE SAND), denne forbindelse udføres altid og "koster ressourcer". Mere eller mindre af dem vil blive brugt - afhænger af størrelsen på dette bord.
Men du kan ændre forespørgslen, så søgningen efter en relateret post kun finder sted, når det virkelig er nødvendigt:
SELECT
...
FROM
"Документ" d
WHERE
... /*index cond*/ AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
END En gang fra den linkede tabel til os ingen af felterne er nødvendige for resultatet, så har vi mulighed for at gøre JOIN til en betingelse på en underforespørgsel.
Lad os forlade de indekserede felter "uden for CASE-parenteserne", tilføje simple betingelser fra posten til WHEN-blokken - og nu udføres den "tunge" forespørgsel kun, når den går videre til THEN.
Mit efternavn er "Total"
Vi indsamler den resulterende forespørgsel med al mekanikken beskrevet ovenfor:
WITH T AS (
SELECT
"@ТипДокумента"
FROM
"ТипДокумента"
WHERE
"ТипДокумента" = 'ПланРабот'
)
(
SELECT
TRUE
FROM
"Документ" d
WHERE
("Лицо3", "ТипДокумента") = (19091, (TABLE T)) AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
END
LIMIT 1
)
UNION ALL
(
SELECT
TRUE
FROM
"Документ" d
WHERE
("ТипДокумента", "Сотрудник") = ((TABLE T), 19091) AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
END
LIMIT 1
)
LIMIT 1;Justering af [til] indekser
Et trænet øje bemærkede, at de indekserede forhold i UNION-underblokkene er lidt anderledes - det skyldes, at vi allerede har passende indekser på bordet. Og hvis de ikke eksisterede, ville det være værd at skabe: Dokument(Person3, DocumentType) и Dokument(DocumentType, Medarbejder).
om rækkefølgen af felter i RÆKKE-forholdFra planlæggerens synspunkt kan du selvfølgelig skrive (A, B) = (constA, constB)Og (B, A) = (constB, constA). Men ved optagelse i rækkefølgen af felterne i indekset, en sådan anmodning er simpelthen mere praktisk at fejlsøge senere.
Hvad er der i planen?
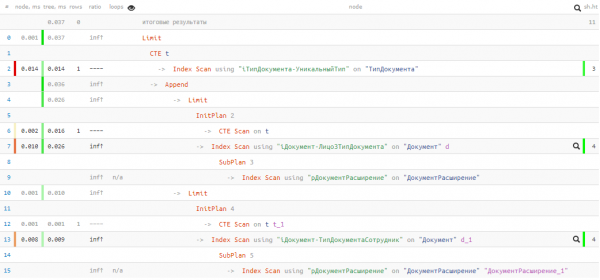
Desværre var vi uheldige, og der blev ikke fundet noget i den første UNION-blok, så den anden blev stadig henrettet. Men alligevel - kun 0.037 ms og 11 buffere!
Vi har fremskyndet anmodningen og reduceret datapumpning i hukommelsen flere tusinde gange, ved brug af ret simple teknikker - et godt resultat med lidt copy-paste. 🙂
Kilde: www.habr.com
