

Jeg foreslår, at du læser udskriften af Vladimir Sitnikovs tidlige 2016-rapport "PostgreSQL og JDBC presser al saften ud"


God eftermiddag Mit navn er Vladimir Sitnikov. Jeg har arbejdet for NetCracker i 10 år. Og jeg er mest til produktivitet. Alt relateret til Java, alt relateret til SQL er det, jeg elsker.
Og i dag vil jeg fortælle om, hvad vi stødte på i virksomheden, da vi begyndte at bruge PostgreSQL som databaseserver. Og vi arbejder mest med Java. Men det, jeg vil fortælle dig i dag, handler ikke kun om Java. Som praksis har vist, sker dette også på andre sprog.

Vi vil tale:
- om datasampling.
- Om at gemme data.
- Og også om ydeevne.
- Og om de undersøiske river, der ligger begravet der.

Lad os starte med et simpelt spørgsmål. Vi vælger en række fra tabellen baseret på den primære nøgle.

Databasen er placeret på den samme vært. Og alt dette landbrug tager 20 millisekunder.

Disse 20 millisekunder er meget. Hvis du har 100 sådanne anmodninger, så bruger du tid pr. sekund på at scrolle gennem disse anmodninger, dvs. vi spilder tid.
Vi kan ikke lide at gøre dette og se på, hvad basen tilbyder os til dette. Databasen giver os to muligheder for at udføre forespørgsler.

Den første mulighed er en simpel anmodning. Hvad er godt ved det? Det, at vi tager det og sender det, og intet mere.

Databasen har også en avanceret forespørgsel, som er mere tricky, men mere funktionel. Du kan separat sende en anmodning om parsing, eksekvering, variabel binding osv.
Super udvidet forespørgsel er noget, vi ikke vil dække i den aktuelle rapport. Vi vil måske have noget fra databasen, og der er en ønskeliste, som er blevet dannet i en eller anden form, dvs. det er det, vi ønsker, men det er umuligt nu og i det næste år. Så vi har lige optaget det, og vi vil gå rundt og ryste hovedpersonerne.

Og hvad vi kan gøre er simpel forespørgsel og udvidet forespørgsel.
Hvad er specielt ved hver tilgang?
En simpel forespørgsel er god til engangsudførelse. En gang gjort og glemt. Og problemet er, at det ikke understøtter det binære dataformat, dvs. det er ikke egnet til nogle højtydende systemer.

Udvidet forespørgsel – giver dig mulighed for at spare tid på parsing. Dette er, hvad vi gjorde og begyndte at bruge. Dette hjalp os virkelig. Der er ikke kun besparelser på parsing. Der er besparelser på dataoverførsel. Overførsel af data i binært format er meget mere effektivt.

Lad os gå videre til praksis. Sådan ser en typisk applikation ud. Det kan være Java osv.
Vi lavede statement. Udførte kommandoen. Oprettet tæt. Hvor er fejlen her? Hvad er problemet? Intet problem. Sådan står der i alle bøgerne. Sådan skal det skrives. Hvis du vil have maksimal ydeevne, så skriv sådan.

Men praksis har vist, at det ikke virker. Hvorfor? For vi har en "tæt" metode. Og når vi gør dette, viser det sig fra databasesynspunktet, at det er ligesom en ryger, der arbejder med en database. Vi sagde "PARSE EXECUTE DEALLOCATE".
Hvorfor al denne ekstra oprettelse og aflæsning af udsagn? Ingen har brug for dem. Men hvad der normalt sker i PreparedStatements er, at når vi lukker dem, lukker de alt på databasen. Det er ikke det, vi ønsker.

Vi ønsker, ligesom raske mennesker, at arbejde med basen. Vi tog og forberedte vores erklæring én gang, så udfører vi den mange gange. Faktisk er de mange gange - det er en gang i hele applikationernes levetid - blevet analyseret. Og vi bruger det samme statement-id på forskellige REST'er. Dette er vores mål.

Hvordan kan vi opnå dette?

Det er meget enkelt - ingen grund til at lukke erklæringer. Vi skriver det sådan her: "forbered" "udfør".


Hvis vi lancerer noget som dette, så er det klart, at noget vil flyde over et sted. Hvis det ikke er klart, kan du prøve det. Lad os skrive et benchmark, der bruger denne enkle metode. Opret en erklæring. Vi starter den på en eller anden version af driveren og opdager, at den går ned ret hurtigt med tab af al den hukommelse, den havde.
Det er klart, at sådanne fejl let kan rettes. Jeg vil ikke tale om dem. Men jeg vil sige, at den nye version virker meget hurtigere. Metoden er dum, men alligevel.

Hvordan arbejder man korrekt? Hvad skal vi gøre for dette?
I virkeligheden lukker ansøgninger altid erklæringer. I alle bøger siger man, at man skal lukke den, ellers vil hukommelsen lække.
Og PostgreSQL ved ikke, hvordan man cacher forespørgsler. Det er nødvendigt, at hver session opretter denne cache for sig selv.
Og vi ønsker heller ikke at spilde tid på at analysere.

Og som sædvanlig har vi to muligheder.
Den første mulighed er, at vi tager det og siger, at lad os pakke alt ind i PgSQL. Der er en cache der. Den cacher alt. Det bliver fantastisk. Vi så dette. Vi har 100500 anmodninger. Virker ikke. Vi accepterer ikke at omdanne anmodninger til procedurer manuelt. Nej nej.
Vi har en anden mulighed - tag den og skær den selv. Vi åbner kilderne og begynder at skære. Vi så og så. Det viste sig, at det ikke er så svært at gøre.

Dette dukkede op i august 2015. Nu er der en mere moderne version. Og alt er fantastisk. Det fungerer så godt, at vi ikke ændrer noget i applikationen. Og vi holdt endda op med at tænke i retning af PgSQL, dvs. dette var ganske nok til, at vi kunne reducere alle overheadomkostninger til næsten nul.
Derfor aktiveres serverforberedte sætninger ved den 5. udførelse for at undgå spild af hukommelse i databasen ved hver engangsanmodning.

Du kan spørge – hvor er tallene? Hvad får du? Og her vil jeg ikke give tal, for hver anmodning har sin egen.
Vores forespørgsler var sådan, at vi brugte omkring 20 millisekunder på at parse på OLTP-forespørgsler. Der var 0,5 millisekunder til udførelse, 20 millisekunder til parsing. Anmodning – 10 KiB tekst, 170 linjers plan. Dette er en OLTP-anmodning. Den kræver 1, 5, 10 linjer, nogle gange mere.
Men vi ville slet ikke spilde 20 millisekunder. Vi reducerede det til 0. Alt er fantastisk.
Hvad kan du tage med herfra? Hvis du har Java, så tager du den moderne version af driveren og glæder dig.
Hvis du taler et andet sprog, så tænk - måske har du også brug for dette? For fra det endelige sprogs synspunkt, for eksempel, hvis PL 8 eller du har LibPQ, så er det ikke indlysende for dig, at du bruger tid på ikke at udføre, på at parse, og det er værd at tjekke. Hvordan? Alt er gratis.
Bortset fra at der er fejl og nogle ejendommeligheder. Og vi vil tale om dem lige nu. Det meste vil handle om industriel arkæologi, om hvad vi fandt, hvad vi stødte på.

Hvis anmodningen genereres dynamisk. Det sker. Nogen limer strengene sammen, hvilket resulterer i en SQL-forespørgsel.
Hvorfor er han dårlig? Det er slemt, for hver gang ender vi med en anden streng.
Og hashkoden for denne forskellige streng skal læses igen. Dette er virkelig en CPU-opgave - at finde en lang anmodningstekst i selv en eksisterende hash er ikke så let. Derfor er konklusionen enkel - generer ikke anmodninger. Gem dem i én variabel. Og glæd dig.

Næste problem. Datatyper er vigtige. Der er ORM'er, der siger, at det er ligegyldigt, hvilken slags NULL der er, lad der være en slags. Hvis Int, så siger vi setInt. Og hvis NULL, så lad det altid være VARCHAR. Og hvilken forskel gør det i sidste ende, hvilken NULL der er? Databasen selv vil forstå alt. Og dette billede virker ikke.
I praksis er databasen overhovedet ligeglad. Hvis du sagde første gang, at dette er et tal, og anden gang, du sagde, at det er en VARCHAR, så er det umuligt at genbruge server-forberedte udsagn. Og i dette tilfælde er vi nødt til at genskabe vores erklæring.

Hvis du udfører den samme forespørgsel, skal du sørge for, at datatyperne i din kolonne ikke forveksles. Du skal passe på NULL. Dette er en almindelig fejl, vi havde efter vi begyndte at bruge PreparedStatements

Okay, tændt. Måske tog de chaufføren. Og produktiviteten faldt. Tingene blev dårlige.
Hvordan sker dette? Er dette en fejl eller en funktion? Desværre var det ikke muligt at forstå, om dette er en fejl eller en funktion. Men der er et meget simpelt scenarie til at reproducere dette problem. Hun overfaldt os helt uventet. Og det består af stikprøver bogstaveligt talt fra én tabel. Vi havde selvfølgelig flere sådanne anmodninger. Som regel inkluderede de to eller tre borde, men der er et sådant afspilningsscenarie. Tag en hvilken som helst version fra din database og afspil den.

Pointen er, at vi har to kolonner, som hver er indekseret. Der er en million rækker i én NULL-kolonne. Og den anden kolonne indeholder kun 20 linjer. Når vi udfører uden bundne variable, fungerer alt godt.
Hvis vi begynder at udføre med bundne variabler, dvs. vi udfører "?" eller "$1" for vores anmodning, hvad ender vi med at få?
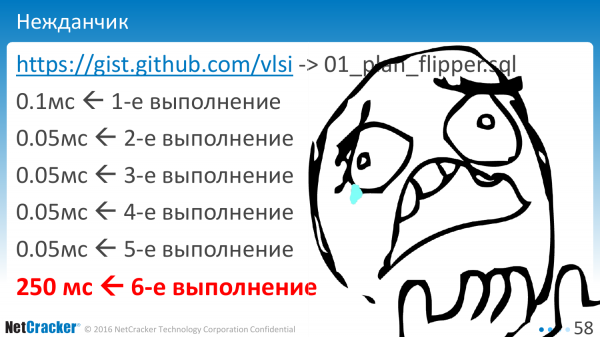
Den første udførelse er som forventet. Den anden er lidt hurtigere. Noget blev gemt. Tredje, fjerde, femte. Så knald – og sådan noget. Og det værste er, at det sker ved den sjette henrettelse. Hvem vidste, at det var nødvendigt at lave præcis seks henrettelser for at forstå, hvad den egentlige henrettelsesplan var?

Hvem er skyldig? Hvad skete der? Databasen indeholder optimering. Og det ser ud til at være optimeret til det generiske tilfælde. Og derfor skifter hun på et tidspunkt til en generisk plan, som desværre kan vise sig at være anderledes. Det kan vise sig at være det samme, eller det kan være anderledes. Og der er en form for tærskelværdi, der fører til denne adfærd.
Hvad kan du gøre ved det? Her er det selvfølgelig sværere at antage noget. Der er en simpel løsning, som vi bruger. Dette er +0, OFFSET 0. Du kender sikkert sådanne løsninger. Vi tager det bare og tilføjer "+0" til anmodningen, og alt er i orden. Jeg viser dig senere.
Og der er en anden mulighed - se nærmere på planerne. Udvikleren skal ikke kun skrive en anmodning, men også sige "forklar analyser" 6 gange. Hvis det er 5, virker det ikke.
Og der er en tredje mulighed - skriv et brev til pgsql-hackere. Jeg skrev, men det er endnu ikke klart, om dette er en fejl eller en funktion.

Mens vi overvejer, om dette er en fejl eller en funktion, lad os rette det. Lad os tage vores anmodning og tilføje "+0". Alt er fint. To symboler, og du behøver ikke engang at tænke på, hvordan det er, eller hvad det er. Meget simpelt. Vi forbød simpelthen databasen at bruge et indeks på denne kolonne. Vi har ikke et indeks på "+0" kolonnen, og det er det, databasen bruger ikke indekset, alt er fint.

Dette er reglen om 6 forklar. Nu i nuværende versioner skal du gøre det 6 gange, hvis du har bundne variable. Hvis du ikke har bundne variabler, er det, hvad vi gør. Og i sidste ende er det netop denne anmodning, der slår fejl. Det er ikke en tricky ting.
Det ser ud til, hvor meget er muligt? En fejl her, en fejl der. Faktisk er fejlen overalt.

Lad os se nærmere. For eksempel har vi to skemaer. Skema A med tabel S og diagram B med tabel S. Forespørgsel – vælg data fra en tabel. Hvad vil vi have i dette tilfælde? Vi vil have en fejl. Vi vil have alt ovenstående. Reglen er - en fejl er overalt, vi vil have alt det ovenstående.

Nu er spørgsmålet: "Hvorfor?" Det ser ud til, at der er dokumentation for, at hvis vi har et skema, så er der en "search_path"-variabel, der fortæller os, hvor vi skal lede efter tabellen. Det ser ud til, at der er en variabel.
Hvad er problemet? Problemet er, at server-forberedte sætninger ikke har mistanke om, at search_path kan ændres af nogen. Denne værdi forbliver så at sige konstant for databasen. Og nogle dele får måske ikke nye betydninger.

Det afhænger selvfølgelig af den version du tester på. Afhænger af, hvor alvorligt dine borde adskiller sig. Og version 9.1 vil simpelthen udføre de gamle anmodninger. Nye versioner kan fange fejlen og fortælle dig, at du har en fejl.

Hvordan behandler man det? Der er en simpel opskrift - gør det ikke. Der er ingen grund til at ændre søgesti, mens applikationen kører. Hvis du ændrer, er det bedre at oprette en ny forbindelse.
Du kan diskutere, altså åbne, diskutere, tilføje. Måske kan vi overbevise databaseudviklerne om, at når nogen ændrer en værdi, skal databasen fortælle klienten om dette: “Se, din værdi er blevet opdateret her. Måske skal du nulstille udsagn og genskabe dem?” Nu opfører databasen sig hemmeligt og melder på ingen måde om, at udsagnene har ændret sig et eller andet sted indeni.
Og jeg vil understrege igen - det er noget, der ikke er typisk for Java. Vi vil se det samme i PL/pgSQL én til én. Men det vil blive gengivet der.

Lad os prøve noget mere datavalg. Vi vælger og vælger. Vi har en tabel med en million rækker. Hver linje er en kilobyte. Cirka en gigabyte data. Og vi har en arbejdshukommelse i Java-maskinen på 128 megabyte.
Vi, som anbefalet i alle bøger, bruger strømbehandling. Det vil sige, at vi åbner resultSet og læser dataene derfra lidt efter lidt. Vil det virke? Vil det falde fra hukommelsen? Vil du læse lidt? Lad os stole på databasen, lad os stole på Postgres. Vi tror ikke på det. Vil vi falde ud af hukommelsen? Hvem oplevede OutOfMemory? Hvem formåede at rette det efter det? Nogen formåede at ordne det.
Hvis du har en million rækker, kan du ikke bare vælge og vrage. OFFSET/LIMIT er påkrævet. Hvem er for denne mulighed? Og hvem går ind for at spille med autoCommit?
Her viser sig som sædvanligt den mest uventede mulighed at være korrekt. Og hvis du pludselig slår autoCommit fra, hjælper det. Hvorfor det? Videnskaben ved ikke om dette.

Men som standard henter alle klienter, der forbinder til en Postgres-database, alle data. PgJDBC er ingen undtagelse i denne henseende; den vælger alle rækker.
Der er en variation af FetchSize-temaet, dvs. du kan sige på niveauet af en separat erklæring, at her skal du vælge data med 10, 50. Men dette virker ikke, før du slår autoCommit fra. Slået autoCommit fra - det begynder at virke.
Men det er ubelejligt at gå igennem koden og indstille setFetchSize overalt. Derfor lavede vi en indstilling, der vil sige standardværdien for hele forbindelsen.
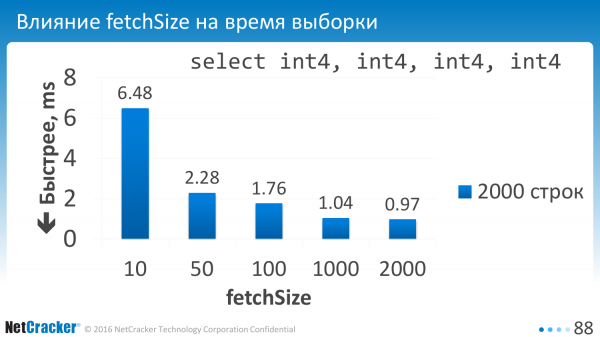
Det sagde vi. Parameteren er blevet konfigureret. Og hvad fik vi? Vælger vi små beløb, hvis vi for eksempel vælger 10 rækker ad gangen, så har vi meget store overheadomkostninger. Derfor bør denne værdi sættes til omkring hundrede.
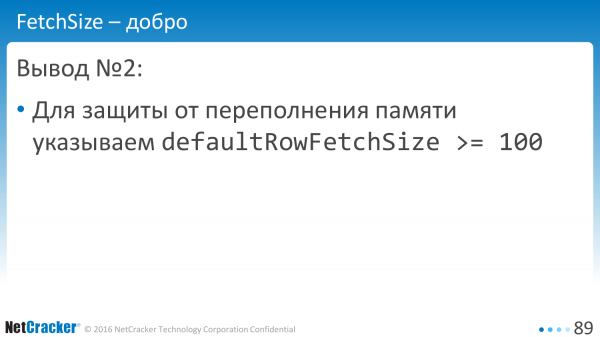
Ideelt set skal du selvfølgelig stadig lære at begrænse det i bytes, men opskriften er denne: sæt defaultRowFetchSize til mere end hundrede og vær glad.

Lad os gå videre til at indsætte data. Indsættelse er nemmere, der er forskellige muligheder. F.eks. INSERT, VALUES. Dette er en god mulighed. Du kan sige "INSERT SELECT". I praksis er det det samme. Der er ingen forskel i ydeevne.
Bøger siger, at du skal udføre en Batch-sætning, bøger siger, at du kan udføre mere komplekse kommandoer med flere parenteser. Og Postgres har en vidunderlig funktion - du kan lave COPY, dvs. gøre det hurtigere.

Hvis du måler det, kan du igen gøre nogle interessante opdagelser. Hvordan vil vi have det til at fungere? Vi ønsker ikke at parse og ikke udføre unødvendige kommandoer.
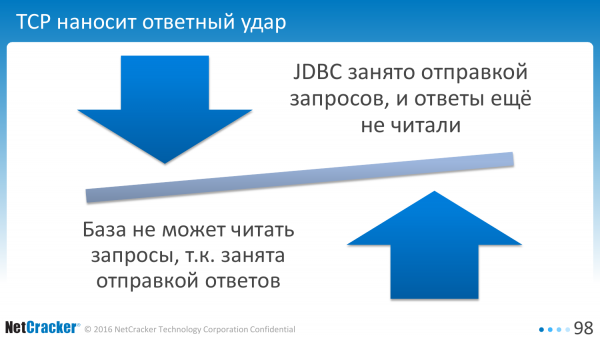
I praksis tillader TCP os ikke at gøre dette. Hvis klienten er optaget af at sende en anmodning, læser databasen ikke anmodningerne i forsøg på at sende os svar. Slutresultatet er, at klienten venter på, at databasen læser anmodningen, og databasen venter på, at klienten læser svaret.

Og derfor er klienten tvunget til med jævne mellemrum at sende en synkroniseringspakke. Ekstra netværksinteraktioner, ekstra spild af tid.
 Og jo flere vi tilføjer dem, jo værre bliver det. Driveren er ret pessimistisk og tilføjer dem ret ofte, cirka en gang for hver 200 linjer, afhængigt af størrelsen på linjerne osv.
Og jo flere vi tilføjer dem, jo værre bliver det. Driveren er ret pessimistisk og tilføjer dem ret ofte, cirka en gang for hver 200 linjer, afhængigt af størrelsen på linjerne osv.
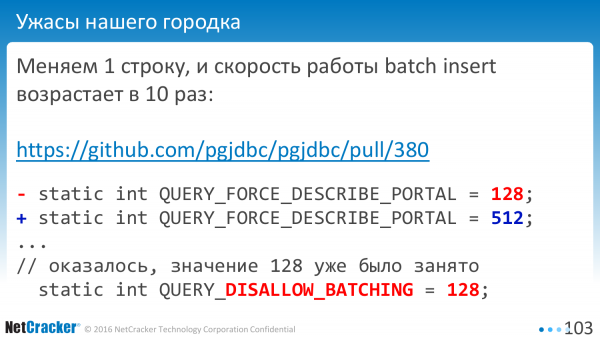
Det sker, at du kun retter en linje, og alt vil fremskynde 10 gange. Det sker. Hvorfor? Som sædvanlig er en konstant som denne allerede blevet brugt et sted. Og værdien "128" betød ikke at bruge batching.

Det er godt, at dette ikke var inkluderet i den officielle version. Opdaget før udgivelsen begyndte. Alle de betydninger, jeg giver, er baseret på moderne versioner.

Lad os prøve det. Vi måler InsertBatch enkelt. Vi måler InsertBatch flere gange, det vil sige det samme, men der er mange værdier. Vanskeligt træk. Ikke alle kan gøre dette, men det er så simpelt et træk, meget nemmere end COPY.

Du kan lave COPY.

Og du kan gøre dette på strukturer. Erklærer brugerens standardtype, pass array og INSERT direkte til tabellen.
Hvis du åbner linket: pgjdbc/ubenchmsrk/InsertBatch.java, så er denne kode på GitHub. Du kan se specifikt, hvilke anmodninger der genereres der. Det er lige meget.
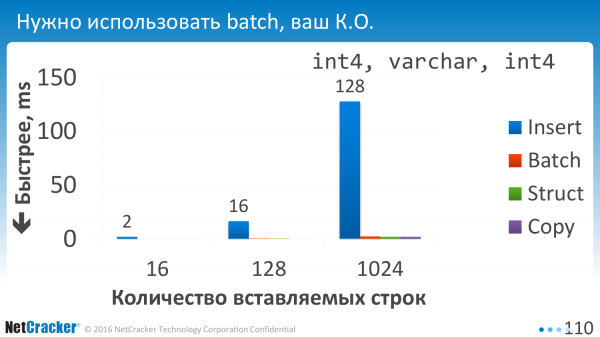
Vi lancerede. Og det første, vi indså, var, at det simpelthen er umuligt at bruge batch. Alle batchmuligheder er nul, dvs. udførelsestiden er praktisk talt nul sammenlignet med en engangsudførelse.
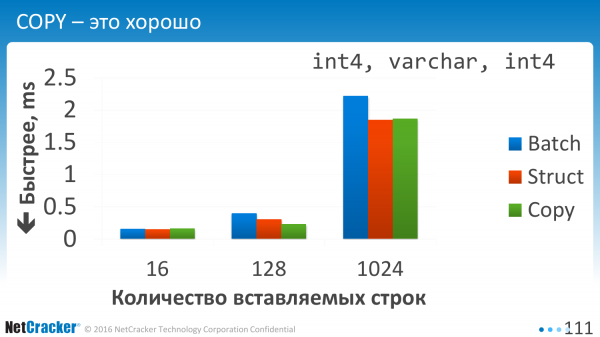
Vi indsætter data. Det er et meget simpelt bord. Tre søjler. Og hvad ser vi her? Vi ser, at alle disse tre muligheder er nogenlunde sammenlignelige. Og COPY er selvfølgelig bedre.
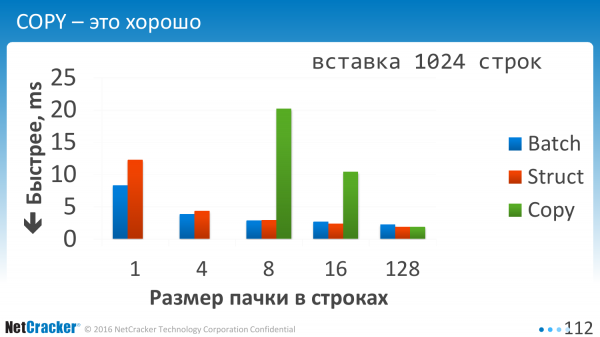
Det er, når vi indsætter stykker. Da vi sagde en VALUES-værdi, to VALUES-værdier, tre VALUES-værdier, eller vi angav 10 af dem adskilt af et komma. Det er bare vandret nu. 1, 2, 4, 128. Det kan ses, at Batch Insert, som er tegnet med blåt, får ham til at føle sig meget bedre. Det vil sige, at når man indsætter én ad gangen eller endda når man indsætter fire ad gangen, bliver det dobbelt så godt, simpelthen fordi vi proppede lidt mere ind i VALUES. Færre UDFØR operationer.
At bruge COPY på små mængder er ekstremt lovende. Jeg tegnede ikke engang på de to første. De går til himlen, altså disse grønne tal for COPY.
COPY skal bruges, når du har mindst hundrede rækker med data. Overheaden ved at åbne denne forbindelse er stor. Og for at være ærlig gravede jeg ikke i denne retning. Jeg optimerede Batch, men ikke COPY.
Hvad gør vi så? Vi prøvede det. Vi forstår, at vi skal bruge enten strukturer eller en smart batch, der kombinerer flere betydninger.

Hvad skal du tage med fra dagens rapport?
- PreparedStatement er vores alt. Dette giver meget for produktiviteten. Det giver et stort flop i salven.
- Og du skal gøre EXPLAIN ANALYSE 6 gange.
- Og vi skal fortynde OFFSET 0 og tricks som +0 for at rette den resterende procentdel af vores problematiske forespørgsler.
Kilde: www.habr.com
