


В Vi så på RabbitMQ-klynger for at give fejltolerance og høj tilgængelighed. Lad os nu grave dybt i Apache Kafka.
Her er replikationsenheden partitionen. Hvert emne har et eller flere afsnit. Hver sektion har en leder med eller uden følgere. Når du opretter et emne, angives antallet af sektioner og replikeringsfaktoren. Den sædvanlige værdi er 3, hvilket betyder tre svar: en leder og to følgere.
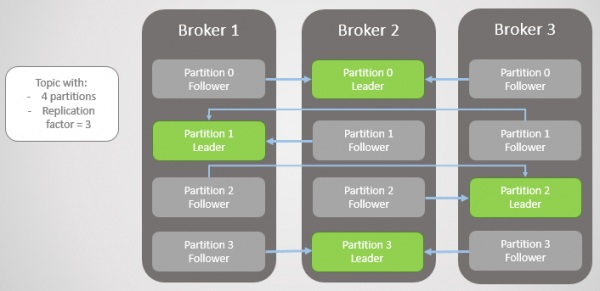
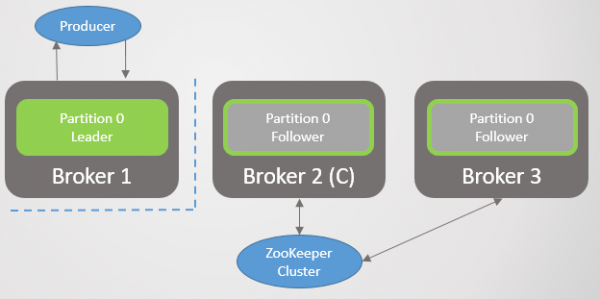
Ris. 1. Fire sektioner er fordelt på tre mæglere
Alle læse- og skriveanmodninger går til lederen. Følgere sender med jævne mellemrum anmodninger til lederen om at modtage de seneste beskeder. Forbrugere engagerer sig aldrig med følgere, de eksisterer kun for redundans og fejlsikkerhed.
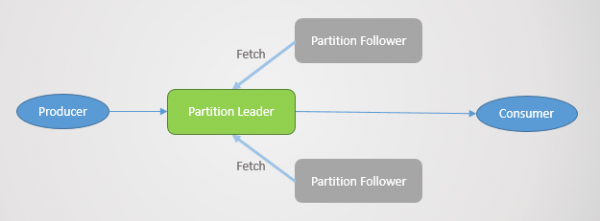
Partitionsfejl
Når en mægler går ned, fejler lederne af flere sektioner ofte. I hver af dem er lederen en følger fra en anden knude. Det er faktisk ikke altid tilfældet, da synkroniseringsfaktoren også spiller en rolle: er der synkroniserede følgere, og hvis ikke, er overgangen til en usynkroniseret replika tilladt. Men lad os ikke komplicere tingene lige nu.
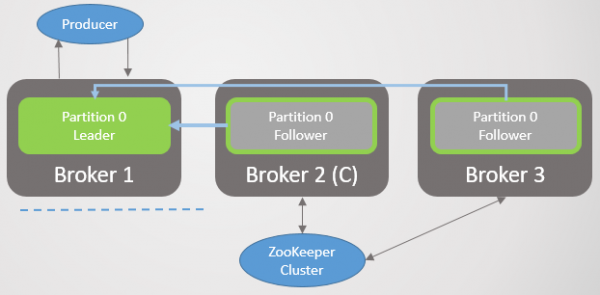
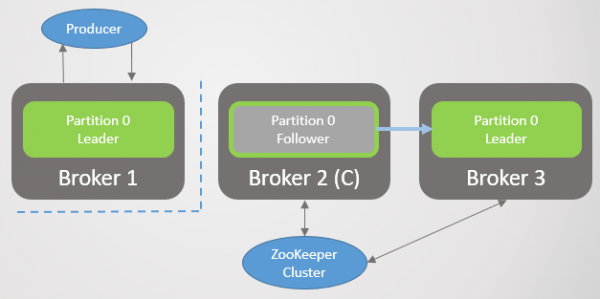
Mægler 3 forlader netværket, og der vælges en ny leder for parti 2 på mægler 2.
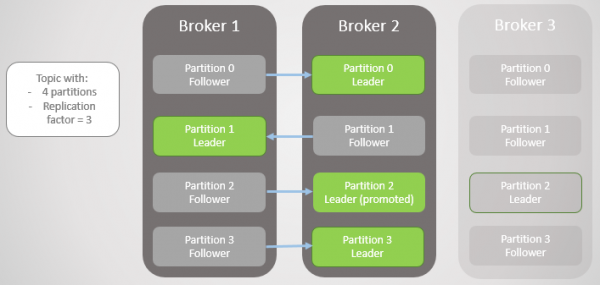
Ris. 2. Mægler 3 dør og hans følger på mægler 2 vælges som ny leder af § 2
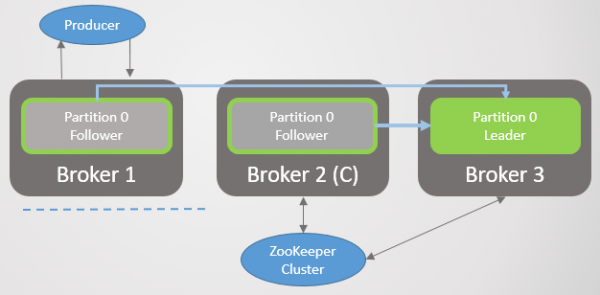
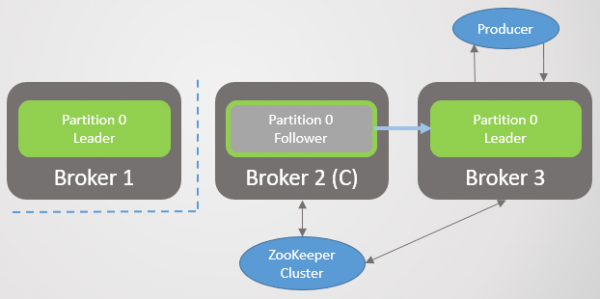
Så forlader mægler 1 og sektion 1 mister også sin leder, hvis rolle overgår til mægler 2.
Ris. 3. Der er kun én mægler tilbage. Alle ledere er på én mægler med nul redundans
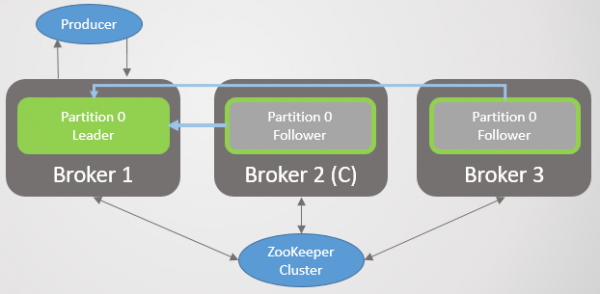
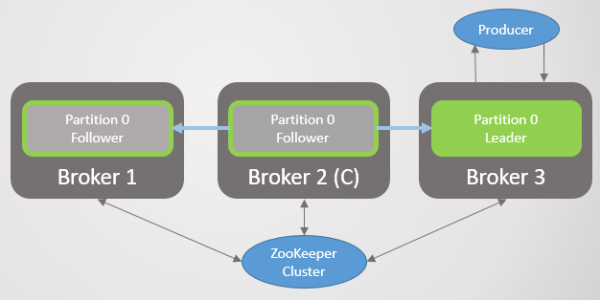
Når mægler 1 kommer online igen, tilføjer den fire følgere, hvilket giver en vis redundans til hver partition. Men alle lederne forblev stadig på mægler 2.
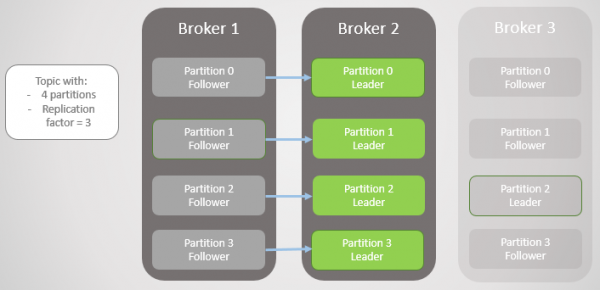
Ris. 4. Ledere forbliver på mægler 2
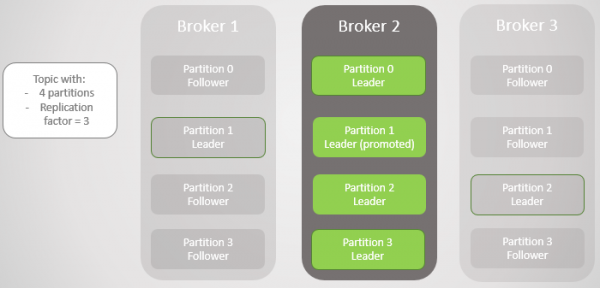
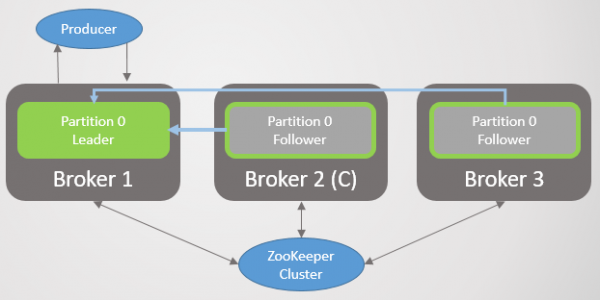
Når broker 3 kommer op, går vi tilbage til tre replikaer pr. partition. Men alle lederne er stadig på broker 2.
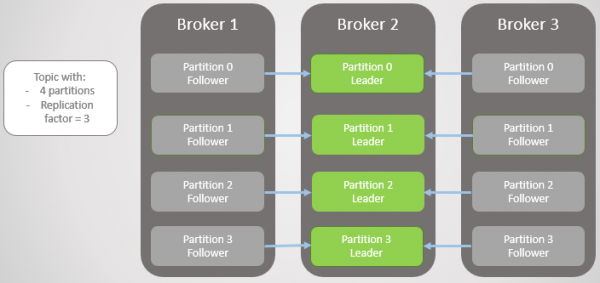
Ris. 5. Ubalanceret placering af ledere efter gendannelse af mægler 1 og 3
Kafka har et bedre værktøj til lederrebalancering end RabbitMQ. Der skulle du bruge et tredjeparts plugin eller script, der ændrede politikkerne for migrering af masterknudepunktet ved at reducere redundans under migrering. Derudover, for store køer, måtte man finde sig i utilgængelighed under synkronisering.
Kafka har begrebet "foretrukne replikaer" til lederrollen. Når emneopdelinger oprettes, forsøger Kafka at fordele ledere jævnt på tværs af noder og markerer disse tidlige ledere som foretrukne. Over tid, på grund af servergenstart, fejl og forbindelsesproblemer, kan ledere ende på andre noder, som i det ekstreme tilfælde beskrevet ovenfor.
For at rette op på dette tilbyder Kafka to muligheder:
- valgmulighed auto.leader.rebalance.enable=true gør det muligt for controller-knudepunktet automatisk at omplacere ledere tilbage til foretrukne replikaer og derved genoprette en ensartet fordeling.
- Administrator kan køre scriptet kafka-preferred-replica-election.sh til manuel omplacering.
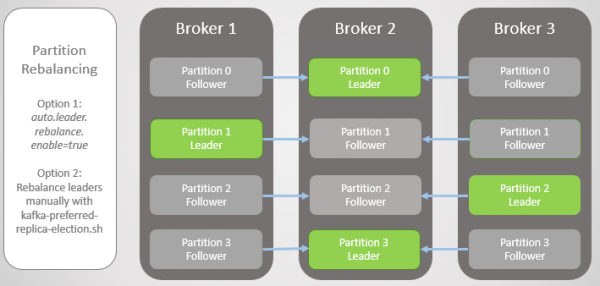
Ris. 6. Replikaer efter rebalancering
Dette var en forenklet version af fejlen, men virkeligheden er mere kompleks, selvom der ikke er noget for kompliceret her. Det hele kommer ned til In-Sync Replicas (ISR'er).
Synkroniserede replikaer (ISR)
En ISR er et sæt replikaer af en partition, der betragtes som "synkroniseret". Der er en leder her, men der er muligvis ingen tilhængere. En følger betragtes som synkroniseret, hvis den har lavet nøjagtige kopier af alle lederens beskeder inden intervallet udløber. replika.forsinkelsestid.maks.ms.
En følger fjernes fra ISR-sættet, hvis han:
- har ikke fremsat en anmodning om prøveudtagning inden for intervallet replika.forsinkelsestid.maks.ms (formodes død)
- nåede ikke at opdatere i intervallet replika.forsinkelsestid.maks.ms (betragtes som langsom)
Følgere anmoder om valg i intervallet replica.fetch.wait.max.ms, som som standard er 500 ms.
For klart at forklare formålet med ISR er vi nødt til at se på producentens anerkendelser og nogle fejlscenarier. Producenterne kan vælge, hvornår mægleren sender bekræftelse:
- acks=0, kvittering sendes ikke
- acks=1, bekræftelsen sendes efter at lederen har skrevet beskeden til sin lokale log
- acks=all, bekræftelsen sendes efter at alle replikaer i ISR har skrevet beskeden til deres lokale logfiler
I Kafka-terminologi, hvis ISR har gemt en besked, er den "committed". Acks=all er den sikreste mulighed, men tilføjer også yderligere forsinkelse. Lad os se på to eksempler på fiasko, og hvordan de forskellige 'acks'-muligheder interagerer med ISR-konceptet.
Acks=1 og ISR
I dette eksempel vil vi se, at hvis lederen ikke venter på, at hver besked fra alle følgere bliver gemt, så er datatab muligt, hvis lederen fejler. Skift til en usynkroniseret følger kan tillades eller forbydes af indstillingen uren.leder.valg.aktivere.
I dette eksempel har producenten acks=1 sæt. Afsnittet er fordelt på alle tre mæglere. Broker 3 halter bagud, den synkroniserede med lederen for otte sekunder siden og er nu 7456 beskeder bagud. Mægler 1 var kun et sekund efter. Vores producer sender en besked og får hurtigt et ack tilbage, uden overhead af langsomme eller døde følgere, som lederen ikke forventer.
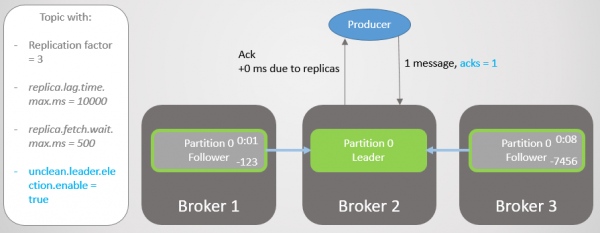
Ris. 7. ISR med tre replikaer
Broker 2 fejler, og producenten modtager en forbindelsesfejl. Efter ledelsesovergangen til mægler 1 mister vi 123 beskeder. Følger på broker 1 gik ind i ISR, men var ikke fuldt synkroniseret med lederen, da den gik ned.
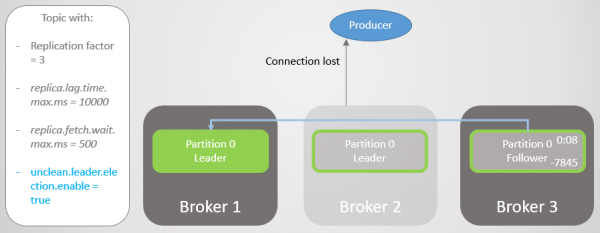
Ris. 8. Beskeder går tabt, når der er et nedbrud
I konfiguration bootstrap.servere Producenten har flere mæglere opført og kan spørge en anden mægler, som er blevet ny sektionsleder. Den etablerer derefter en forbindelse med mægler 1 og fortsætter med at sende beskeder.
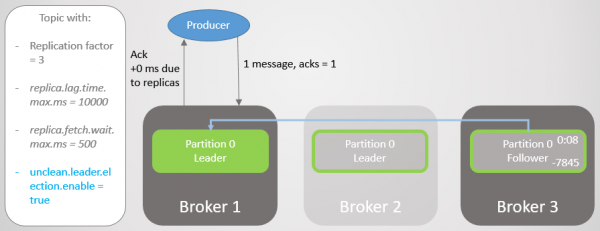
Ris. 9. Afsendelse af beskeder genoptages efter en kort pause
Broker 3 er endnu længere bagud. Den foretager hentningsanmodninger, men kan ikke synkronisere. Dette kan skyldes langsom netværksforbindelse mellem mæglere, lagringsproblem osv. Det fjernes fra ISR. Nu består ISR af én replika - lederen! Producenten fortsætter med at sende beskeder og modtage bekræftelser.
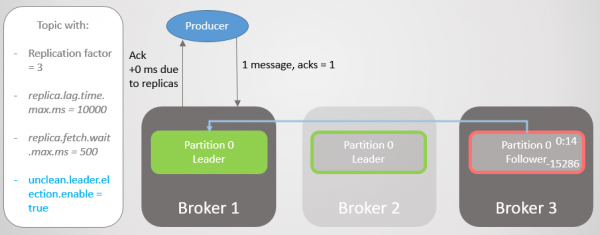
Ris. 10. Følger på mægler 3 fjernes fra ISR
Mægler 1 går ned, og lederrollen overgår til mægler 3 med tab af 15286 beskeder! Producenten modtager en forbindelsesfejlmeddelelse. Overgangen til lederen uden for ISR var kun mulig på grund af indstillingen unclean.leader.election.enable=sand. Hvis det er installeret i falsk, så ville overgangen ikke være sket, og alle læse- og skriveanmodninger ville være blevet afvist. I dette tilfælde venter vi på, at mægler 1 vender tilbage med sine uberørte data i en replika, der igen vil overtage ledelsen.
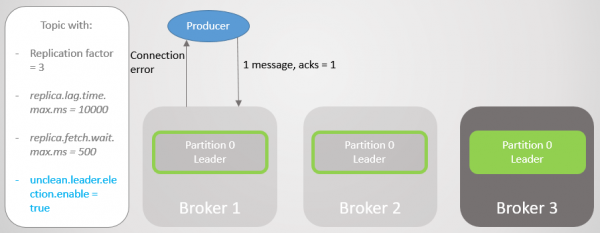
Ris. 11. Mægler 1 falder. Når et nedbrud opstår, går et stort antal meddelelser tabt.
Producenten etablerer en forbindelse med den sidste mægler og ser, at den nu er partitionslederen. Det begynder at sende beskeder til mægler 3.
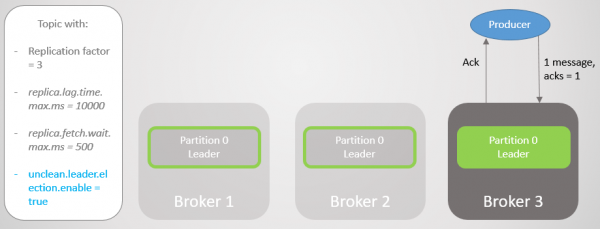
Ris. 12. Efter en kort pause sendes beskeder til afdeling 0 igen.
Vi så, at ud over korte afbrydelser for at etablere nye forbindelser og søge efter en ny leder, sendte producenten konstant beskeder. Denne konfiguration giver tilgængelighed på bekostning af konsistens (datasikkerhed). Kafka mistede tusindvis af beskeder, men fortsatte med at acceptere nye skriverier.
Acks=alle og ISR
Lad os gentage dette scenarie igen, men med acks = alle. Broker 3 forsinkelse er i gennemsnit fire sekunder. Producenten sender en besked med acks = alle, og modtager nu ikke et hurtigt svar. Lederen venter på, at alle replikaer i ISR'en gemmer beskeden.
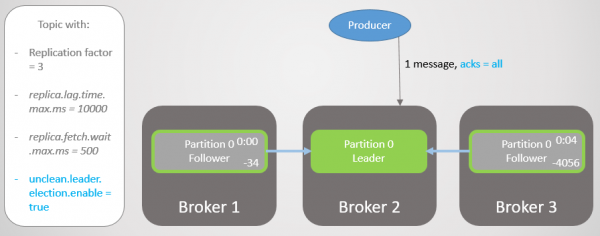
Ris. 13. ISR med tre kopier. Den ene er langsom, hvilket forårsager optagelsesforsinkelser.
Efter fire sekunders yderligere forsinkelse sender mægler 2 et kvittering. Alle replikaer er nu fuldt opdateret.
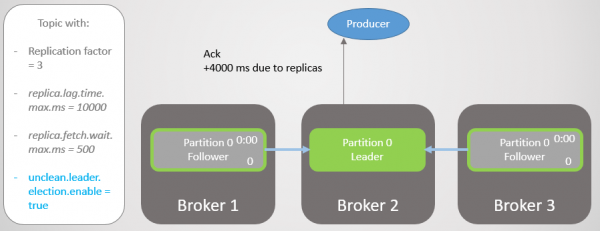
Ris. 14. Alle replikaer gemmer beskeder og kvittering sendes
Broker 3 halter nu endnu længere og er fjernet fra ISR. Latency reduceres betydeligt, da der ikke er nogen langsomme replikaer tilbage i ISR. Broker 2 venter nu kun på broker 1, og den har en gennemsnitlig forsinkelse på 500 ms.
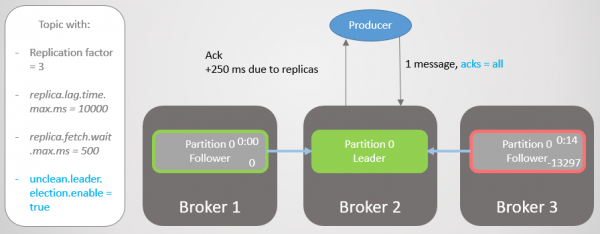
Ris. 15. Replikaen på mægler 3 fjernes fra ISR
Så går mægler 2 ned, og ledelsen overgår til mægler 1 uden at miste beskeder.
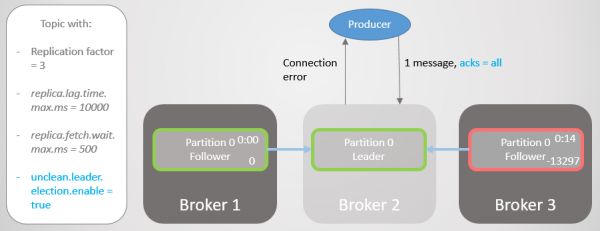
Ris. 16. Mægler 2 falder
Producenten finder en ny leder og begynder at sende ham beskeder. Latensen er yderligere reduceret, fordi ISR nu består af en enkelt replika! Derfor muligheden acks = alle tilføjer ikke redundans.
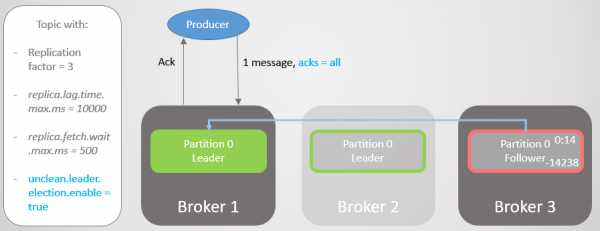
Ris. 17. Replika på mægler 1 overtager ledelsen uden at miste beskeder
Så går mægler 1 ned, og føringen går til mægler 3 med et tab på 14238 beskeder!
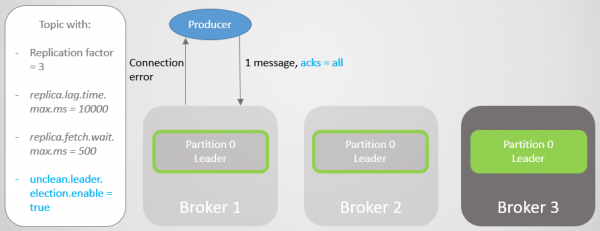
Ris. 18. Broker 1 dør og lederskabsovergang med urent opsætning resulterer i massivt datatab
Vi kunne ikke have installeret muligheden uren.leder.valg.aktivere i betydning sand. Som standard er det ens falsk. Indstilling acks = alle с unclean.leader.election.enable=sand giver tilgængelighed med en vis ekstra datasikkerhed. Men som du kan se, kan vi stadig miste beskeder.
Men hvad nu hvis vi vil øge datasikkerheden? Du kan sætte det unclean.leader.election.enable = falsk, men dette vil ikke nødvendigvis beskytte os mod tab af data. Hvis lederen er faldet hårdt og taget dataene med sig, er beskederne stadig tabt, plus at tilgængeligheden går tabt, indtil administratoren genopretter situationen.
Det er bedre at sikre, at alle meddelelser er overflødige, ellers nægter at optage. Så er datatab, i hvert fald fra mæglerens synspunkt, kun muligt i tilfælde af to eller flere samtidige fejl.
Acks=all, min.insync.replicas og ISR
Med emne konfiguration min.insync.replikaer Vi øger niveauet af datasikkerhed. Lad os gennemgå den sidste del af det forrige scenarie igen, men denne gang med min.insync.replicas=2.
Så mægler 2 har en replika-leder, og følgeren på mægler 3 er blevet fjernet fra ISR.
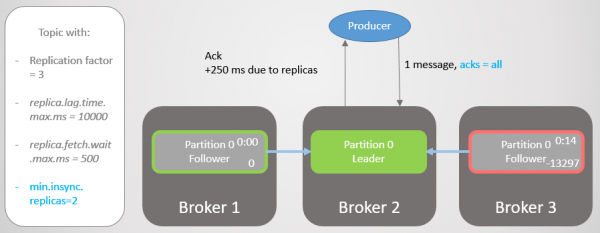
Ris. 19. ISR fra to kopier
Mægler 2 går ned, og ledelsen overgår til mægler 1 uden at miste beskeder. Men nu består ISR kun af én replika. Dette opfylder ikke minimumsantallet for at modtage poster, og derfor reagerer mægleren på skriveforsøget med en fejl Ikke nok replikaer.
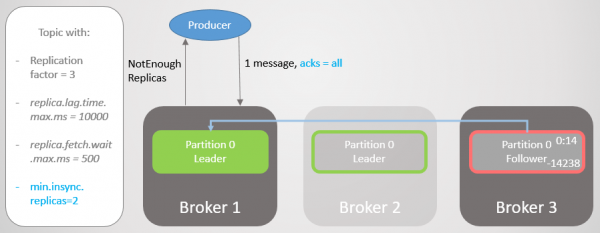
Ris. 20. Antallet af ISR'er er én lavere end angivet i min.insync.replicas
Denne konfiguration ofrer tilgængelighed for konsistens. Før vi bekræfter en besked, sikrer vi, at den er skrevet til mindst to replikaer. Dette giver producenten meget mere selvtillid. Her er beskedtab kun muligt, hvis to replikaer fejler samtidigt inden for et kort interval, før beskeden replikeres til en ekstra følger, hvilket er usandsynligt. Men hvis du er super paranoid, kan du indstille replikationsfaktoren til 5, og min.insync.replikaer på 3. Her skal tre mæglere falde på samme tid for at miste rekorden! Selvfølgelig vil du betale for en sådan pålidelighed med yderligere forsinkelse.
Når tilgængelighed er afgørende for datasikkerheden
Som i , nogle gange er tilgængelighed nødvendig for datasikkerhed. Her er hvad du skal tænke over:
- Kan udgiveren blot returnere en fejl og få upstream-tjenesten eller brugeren til at prøve igen senere?
- Kan udgiveren gemme meddelelsen lokalt eller i en database for at prøve igen senere?
Hvis svaret er nej, forbedrer optimering af tilgængeligheden datasikkerheden. Du mister mindre data, hvis du vælger tilgængelighed i stedet for ikke at optage. Så det hele handler om at finde en balance, og løsningen afhænger af den konkrete situation.
Betydningen af ISR
ISR-sættet giver dig mulighed for at vælge den optimale balance mellem datasikkerhed og latenstid. For eksempel for at sikre tilgængelighed i tilfælde af fejl på de fleste replikaer, samtidig med at virkningen af døde eller langsomme replikaer minimeres med hensyn til latenstid.
Vi vælger selv meningen replika.forsinkelsestid.maks.ms efter dine behov. I det væsentlige betyder denne parameter, hvor meget forsinkelse vi er villige til at acceptere hvornår acks = alle. Standardværdien er ti sekunder. Hvis dette er for langt for dig, kan du forkorte det. Så vil hyppigheden af ændringer i ISR stige, da følgere vil blive fjernet og tilføjet oftere.
I RabbitMQ er der simpelthen et sæt spejle, der skal replikeres. Langsomme spejle introducerer yderligere latenstid, og døde spejle kan tage op til et flueben for at reagere. ISR er en interessant måde at undgå disse latensproblemer på. Men vi risikerer at miste redundans, da ISR kun kan skrumpe ind til lederen. Brug indstillingen for at undgå denne risiko min.insync.replikaer.
Kundeforbindelsesgaranti
I indstillinger bootstrap.servere Producenten og forbrugeren kan angive flere mæglere til at forbinde kunder. Tanken er, at hvis en node går ned, er der stadig flere reserveknuder, som klienten kan åbne en forbindelse med. Disse er ikke nødvendigvis sektionsledere, men blot et springbræt til indledende læsning. Klienten kan spørge dem, hvilken node der er vært for læse/skrive partitionslederen.
I RabbitMQ kan klienter oprette forbindelse til enhver node, og intern routing sender anmodningen, hvor den skal hen. Det betyder, at du kan installere en load balancer foran RabbitMQ. Kafka kræver, at klienter opretter forbindelse til den node, der er vært for lederen af den tilsvarende partition. I en sådan situation er det umuligt at installere en belastningsbalancer. Liste bootstrap.servere er afgørende for at sikre, at klienter kan få adgang til og lokalisere de korrekte noder efter en fejl.
Kafka konsensusarkitektur
Indtil videre har vi ikke overvejet, hvordan klyngen lærer om mæglerkrakket, og hvordan en ny leder vælges. For at forstå, hvordan Kafka arbejder med netværkspartitioner, skal du først forstå konsensusarkitekturen.
Hver Kafka-klynge er implementeret sammen med en Zookeeper-klynge, en distribueret konsensustjeneste, der gør det muligt for systemet at nå konsensus om en given tilstand, idet der prioriteres konsistens frem for tilgængelighed. Et flertal af Zookeeper-noder skal acceptere at godkende læse- og skriveoperationer.
Zookeeper gemmer klyngetilstanden:
- Liste over emner, sektioner, konfiguration, nuværende ledersvar, foretrukne svar.
- Klyngemedlemmer. Hver mægler pinger Zookeeper-klyngen. Hvis den ikke modtager et ping inden for en bestemt periode, markerer Zookeeper mægleren som utilgængelig.
- Valg af primære og sekundære noder til controlleren.
Controllernoden er en af Kafka-mæglerne, der er ansvarlig for at vælge replika-ledere. Zookeeper sender meddelelser om klyngemedlemskab og emneændringer til controlleren, og controlleren skal handle på disse ændringer.
Overvej for eksempel et nyt emne med ti partitioner og en replikeringsfaktor på 3. Controlleren skal vælge en leder for hver partition, og forsøge at fordele ledere optimalt blandt mæglere.
For hver sektion skal controlleren:
- opdaterer oplysninger i Zookeeper om ISR og leder;
- sender en LeaderAndISRCommand til hver mægler, der er vært for en replika af denne partition, og informerer mæglerne om ISR'en og lederen.
Når en mægler med en leder går ned, sender Zookeeper en notifikation til controlleren, som vælger en ny leder. Igen opdaterer controlleren først Zookeeper og sender derefter en kommando til hver mægler, der underretter dem om ledelsesændringen.
Hver leder er ansvarlig for at indstille ISR. Indstilling replika.forsinkelsestid.maks.ms bestemmer, hvem der kommer ind der. Når ISR ændres, videregiver lederen de nye oplysninger til Zookeeper.
Zookeeper orienteres altid om eventuelle ændringer, så ledelsen i tilfælde af fejl kan overgå til en ny leder uden problemer.
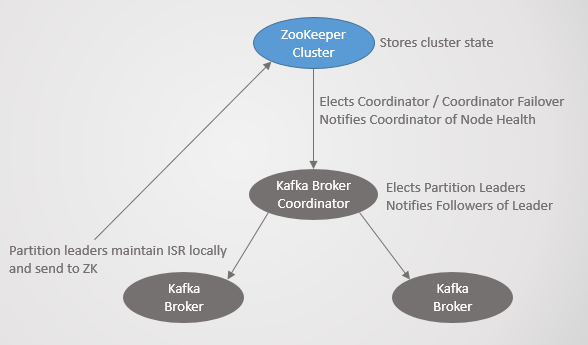
Ris. 21. Kafka-konsensus
Replikationsprotokol
At forstå detaljerne i replikering hjælper dig med bedre at forstå potentielle datatabsscenarier.
Hent forespørgsler, Log End Offset (LEO) og Highwater Mark (HW)
Vi har set, at følgere med jævne mellemrum sender henteanmodninger til lederen. Standardintervallet er 500ms. Dette adskiller sig fra RabbitMQ ved, at replikering i RabbitMQ ikke initieres af køspejlet, men af masteren. Mesteren skubber ændringer til spejlene.
Lederen og alle følgere beholder Log End Offset (LEO) og Highwater-mærket (HW). LEO-mærket gemmer forskydningen af den sidste besked i den lokale replika, og HW-mærket gemmer forskydningen af den sidste commit. Husk, at for at opnå forpligtelsesstatus, skal meddelelsen bevares i alle ISR-replikaer. Det betyder, at LEO normalt er lidt foran HW.
Når lederen modtager en besked, gemmer den den lokalt. En følger anmoder om et valg ved at videregive sin LEO. Lederen sender derefter en byge af beskeder, der starter fra denne LEO og udsender også den aktuelle HW. Når lederen modtager information om, at alle replikaer har gemt beskeden med en given offset, flytter den HW-mærket. Kun lederen kan flytte HW, og så kender alle følgere den aktuelle værdi i svarene på deres anmodning. Det betyder, at følgere kan halte bagefter lederen i både budskaber og HW viden. Forbrugere modtager kun beskeder op til den aktuelle HW.
Bemærk, at "vedvarende" betyder skrevet til hukommelsen, ikke til disken. For ydeevne synkroniserer Kafka til disk med jævne mellemrum. RabbitMQ har også et sådant interval, men det vil først sende en bekræftelse til udgiveren, når masteren og alle spejle har skrevet beskeden til disken. Kafka-udviklerne tog beslutningen om at sende en ack, så snart beskeden er skrevet til hukommelsen af ydeevnemæssige årsager. Kafka satser på, at redundans opvejer risikoen for kun at gemme bekræftede beskeder i hukommelsen i kort tid.
Leder fiasko
Når en leder falder, underretter Zookeeper controlleren, som vælger en ny leder-replika. Den nye leder sætter et nyt HW-mærke i henhold til sin LEO. Så modtager følgerne information om den nye leder. Afhængigt af Kafka-versionen vil følgeren vælge et af to scenarier:
- Afkort den lokale log til en kendt HW og send en anmodning til den nye leder om beskeder efter dette mærke.
- Send en forespørgsel til lederen for at finde ud af HW på det tidspunkt, hvor den blev valgt til leder, og afkort derefter loggen til den forskydning. Det vil derefter begynde at lave periodiske prøveanmodninger startende fra denne offset.
En følger kan være nødt til at trimme loggen af følgende årsager:
- Når en leder fejler, vinder den første følger fra ISR-sættet, der er registreret i Zookeeper valget og bliver leder. Alle følgere i ISR, selvom de betragtes som "synkroniserede", har muligvis ikke modtaget kopier af alle beskeder fra den tidligere leder. Det er meget muligt, at den valgte følger ikke har den mest opdaterede kopi. Kafka garanterer, at der ikke er nogen divergens mellem replikaer. For at undgå uoverensstemmelse skal hver følger afkorte sin log til HW-værdien for den nye leder på tidspunktet for dens valg. Dette er en anden grund til, at indstillingen acks = alle så vigtigt for konsistensen.
- Meddelelser skrives til disk med jævne mellemrum. Hvis alle klynge noder fejler samtidigt, vil replikaer med forskellige offsets blive gemt på diskene. Det er meget muligt, at når mæglere kommer online igen, vil den nye leder, der bliver valgt, stå bag sine følgere, fordi han har gemt på disk tidligere end andre.
Genforening med klyngen
Når de slutter sig til klyngen igen, fungerer replikaer på samme måde, som når lederen fejler: de tjekker lederens replika og afkorter deres log til dens HW (på valgtidspunktet). Til sammenligning behandler RabbitMQ genforbundne noder lige så, som om de var helt nye. I begge tilfælde kasserer mægleren enhver eksisterende tilstand. Hvis automatisk synkronisering bruges, skal masteren replikere absolut alt nuværende indhold til det nye spejl på en "og lad verden vente" måde. Under denne operation accepterer masteren ikke nogen læse- eller skrivehandlinger. Denne tilgang skaber problemer i lange køer.
Kafka er en distribueret log og gemmer generelt flere beskeder end en RabbitMQ-kø, hvor data fjernes fra køen, efter at de er læst. Aktive køer bør forblive relativt små. Men Kafka er en logger med sin egen opbevaringspolitik, som kan indstilles til dage eller uger. Tilgangen med køblokering og fuld synkronisering er absolut uacceptabel for en distribueret log. I stedet for afkorter Kafka-tilhængere simpelthen deres log til lederens HW (på tidspunktet for dets valg), hvis deres kopi er foran lederen. I det mere sandsynlige tilfælde, at en følger er bagud, begynder den simpelthen at lave hentningsanmodninger fra sin nuværende LEO.
Nye eller gentilsluttede følgere starter uden for ISR og deltager ikke i commits. De arbejder simpelthen sammen med gruppen og modtager beskeder så hurtigt som de kan, indtil de indhenter lederen og går ind i ISR. Der er ingen blokering, og du behøver ikke at smide alle dine data væk.
Overtrædelse af tilslutningsmuligheder
Kafka har flere komponenter end RabbitMQ, så det har et mere komplekst sæt adfærd, når klyngen mister forbindelse. Men Kafka er designet fra bunden til klynger, så løsningerne er meget gennemtænkte.
Nedenfor er nogle scenarier for forbindelsesfejl:
- Scenario 1: Følgeren kan ikke se lederen, men ser stadig Zookeeper.
- Scenarie 2: Lederen ser ingen følgere, men ser stadig Zookeeper.
- Scenarie 3: Følgeren ser lederen, men ser ikke Zookeeper.
- Scenarie 4: Lederen ser følgere, men ser ikke Zookeeper.
- Scenario 5: Følgeren er fuldstændig adskilt fra både andre Kafka-knuder og Zookeeper.
- Scenarie 6: Lederen er fuldstændig adskilt fra både andre Kafka noder og Zookeeper.
- Scenarie 7: Kafka controller node ser ikke en anden Kafka node.
- Scenarie 8: Kafka-controlleren kan ikke se Zookeeper.
Hvert scenarie har sin egen adfærd.
Scenario 1: Følgeren kan ikke se lederen, men ser stadig Zookeeper
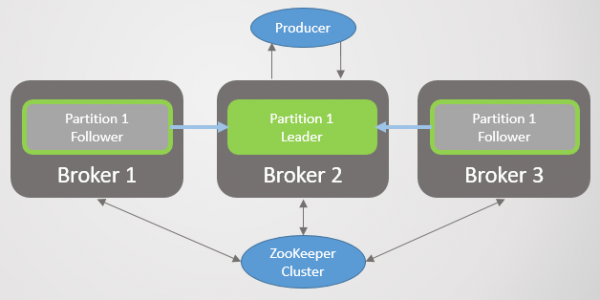
Ris. 22. Scenarie 1. ISR fra tre replikaer
Forbindelsesbruddet adskiller mægler 3 fra mægler 1 og 2, men ikke fra Zookeeper. Broker 3 kan ikke længere sende hentningsanmodninger. Efter at tiden er gået replika.forsinkelsestid.maks.ms den fjernes fra ISR'en og deltager ikke i meddelelsescommits. Når forbindelsen er genoprettet, vil den genoptage hentningsanmodninger og slutte sig til ISR'en, når den indhenter lederen. Zookeeper vil fortsat modtage ping og antage, at mægleren lever og har det godt.
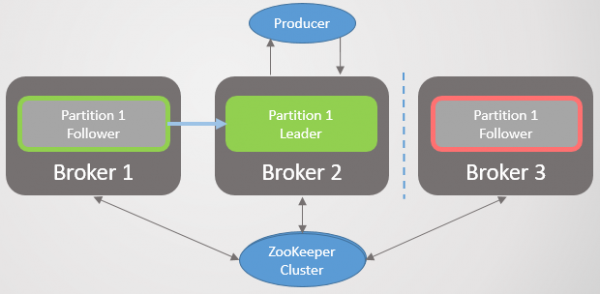
Ris. 23. Scenarie 1. Brokeren fjernes fra ISR'en, hvis der ikke modtages en henteanmodning fra den inden for replica.lag.time.max.ms intervallet.
Der er ingen split-hjerne eller node suspension som i RabbitMQ. I stedet reduceres redundansen.
Scenarie 2: Lederen ser ingen følgere, men ser stadig Zookeeper
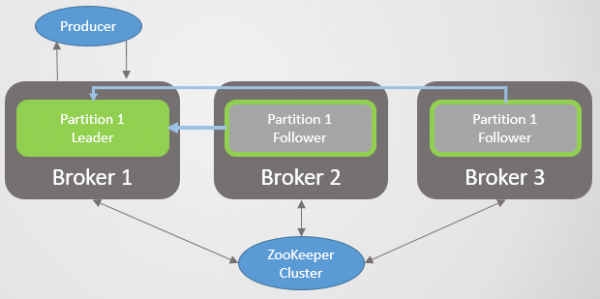
Ris. 24. Scenarie 2. Leder og to følgere
Et nedbrud i netværksforbindelsen adskiller lederen fra følgerne, men mægleren ser stadig Zookeeper. Som i det første scenarie skrumper ISR, men denne gang kun til lederen, da alle følgere holder op med at sende hentningsanmodninger. Igen er der ingen logisk opdeling. I stedet er der et tab af redundans for nye beskeder, indtil forbindelsen er genoprettet. Zookeeper fortsætter med at modtage ping og mener, at mægleren lever og har det godt.
Ris. 25. Scenario 2. ISR er kun skrumpet til lederen
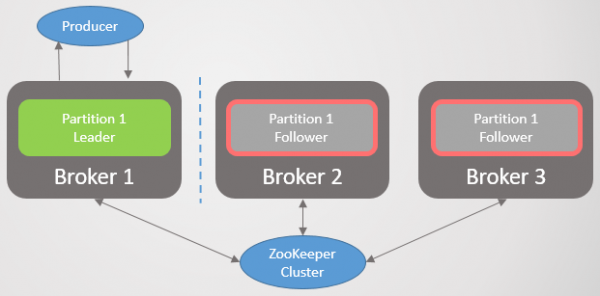
Scenarie 3: Følgeren ser lederen, men ser ikke Zookeeper
Følgeren er adskilt fra Zookeeper, men ikke fra mægleren med lederen. Som et resultat fortsætter følgeren med at foretage hentningsanmodninger og være medlem af ISR. Zookeeper modtager ikke længere ping og registrerer et mæglernedbrud, men da det kun er en følger, er der ingen konsekvenser ved genopretning.
Ris. 26. Scenario 3. Følgeren fortsætter med at sende anmodninger til lederen om udvælgelse
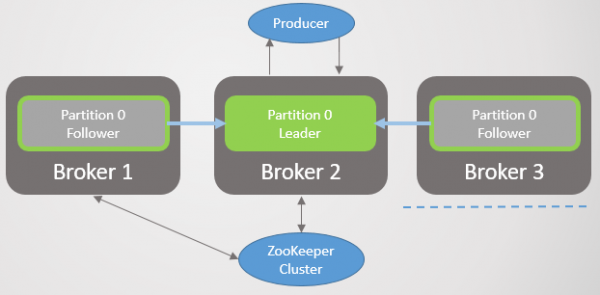
Scenarie 4: Leder ser følgere, men ser ikke Zookeeper
Ris. 27. Scenarie 4. Leder og to følgere
Lederen er adskilt fra Zookeeper, men ikke fra mæglerne med følgere.
Ris. 28. Scenario 4. Lederen er isoleret fra Zookeeper
Efter nogen tid vil Zookeeper registrere mæglerkrakket og underrette controlleren om det. Han vil vælge en ny leder blandt sine følgere. Den oprindelige leder vil dog fortsætte med at tro, at det er lederen og vil fortsætte med at tage imod tilmeldinger fra acks=1. Følgere sender det ikke længere henteanmodninger, så det vil betragte dem som døde og forsøge at formindske ISR'en til sig selv. Men da den ikke har en forbindelse til Zookeeper, vil den ikke kunne gøre dette, og på det tidspunkt vil den nægte at acceptere yderligere tilmeldinger.
meddelelser acks = alle vil ikke modtage bekræftelse, fordi først ISR inkluderer alle replikaer, og beskeder når dem ikke. Når den oprindelige leder forsøger at fjerne dem fra ISR, vil den ikke være i stand til at gøre det og vil stoppe med at acceptere nogen beskeder overhovedet.
Kunder bemærker snart ændringen i leder og begynder at sende poster til den nye server. Når netværket er gendannet, ser den oprindelige leder, at den ikke længere er lederen, og afkorter sin log til den HW-værdi, som den nye leder havde på tidspunktet for fejlen i at undgå logdivergens. Det vil derefter begynde at sende hentningsanmodninger til den nye leder. Alle poster fra den oprindelige leder, der ikke er blevet replikeret til den nye leder, går tabt. Det betyder, at beskeder, der ikke blev bekræftet af den oprindelige leder i løbet af de få sekunder, hvor to ledere var i drift, vil gå tabt.
Ris. 29. Scenarie 4. Lederen på mægler 1 bliver en følger efter netværket er gendannet
Scenarie 5: Follower er fuldstændig adskilt fra både andre Kafka noder og Zookeeper
Tilhængeren er fuldstændig isoleret fra både andre Kafka-noder og Zookeeper. Den fjerner sig simpelthen fra ISR'en, indtil netværket genopretter sig, og indhenter derefter de andre.

Ris. 30. Scenario 5: En isoleret følger fjernes fra ISR
Scenarie 6: Lederen er fuldstændig adskilt fra både andre Kafka noder og Zookeeper
Ris. 31. Scenarie 6. Leder og to følgere
Lederen er fuldstændig isoleret fra sine følgere, controlleren og dyrepasseren. I en kort periode vil den fortsætte med at modtage tilmeldinger fra acks=1.
Ris. 32. Scenario 6. Isolering af lederen fra andre Kafka og Zookeeper noder
Modtager ikke anmodninger efter udløb replika.forsinkelsestid.maks.ms, vil den forsøge at formindske ISR'en til sig selv, men vil ikke være i stand til at gøre det, fordi der ikke er nogen forbindelse til Zookeeper, så holder den op med at acceptere skriverier.
I mellemtiden vil Zookeeper markere den isolerede mægler som død, og controlleren vil vælge en ny leder.
Ris. 33. Scenarie 6. To ledere
Den første leder accepterer muligvis skrivninger i et par sekunder, men holder derefter op med at acceptere beskeder. Klienter opdateres hvert 60. sekund med de seneste metadata. De vil blive informeret om lederskiftet og vil begynde at sende indlæg til den nye leder.
Ris. 34. Scenario 6: Producenter skifter til en ny leder
Alle forpligtede skriverier lavet af den oprindelige leder, da tabet af forbindelse vil gå tabt. Når netværket er genoprettet, vil den oprindelige leder opdage gennem Zookeeper, at den ikke længere er lederen. Den vil derefter afkorte sin log til den nye leders HW på valgtidspunktet og begynde at sende anmodninger som følger.
Ris. 35. Scenarie 6: Den oprindelige leder bliver en følger efter netværksforbindelsen er gendannet
I denne situation kan en logisk adskillelse observeres i en kort periode, men kun hvis acks=1 и min.insync.replikaer også 1. Logisk opdeling afsluttes automatisk, enten når netværket gendannes, når den oprindelige leder indser, at den ikke længere er lederen, eller når alle klienter indser, at lederen har ændret sig og begynder at skrive til den nye leder - alt efter hvad der kommer først. Under alle omstændigheder vil nogle beskeder gå tabt, men kun med acks=1.
Der er en anden variant af dette scenarie, hvor tilhængerne lige før netværkets splittelse faldt bagud, og lederen komprimerede ISR til kun sig selv. Det bliver derefter isoleret på grund af tab af forbindelse. En ny leder vælges, men den oprindelige leder fortsætter med at tage imod tilmeldinger, selv acks = alle, fordi der ikke er andre i ISR end ham. Disse registreringer vil gå tabt, når netværket er gendannet. Den eneste måde at undgå denne mulighed er min.insync.replicas = 2.
Scenarie 7: Kafka controller node ser ikke en anden Kafka node
Generelt, efter at have mistet forbindelsen til en Kafka-node, vil controlleren ikke være i stand til at videregive nogen information om lederændringen til den. I værste fald vil dette føre til en kortsigtet logisk splittelse, som i scenario 6. Oftere end ikke vil mægleren simpelthen ikke være en kandidat til lederskabet, hvis sidstnævnte fejler.
Scenario 8. Kafka-controlleren kan ikke se Zookeeper
Zookeeper vil ikke modtage et ping fra den fejlbehæftede controller og vil vælge en ny Kafka-node som controller. Den originale controller kan fortsætte med at præsentere sig selv som sådan, men den vil ikke modtage meddelelser fra Zookeeper, så den vil ikke have nogen opgaver at udføre. Når netværket er gendannet, vil det indse, at det ikke længere er en controller, men er blevet en almindelig Kafka-node.
Konklusioner fra scenarierne
Vi ser, at tabet af follower-forbindelse ikke resulterer i tab af beskeder, men blot midlertidigt reducerer redundans, indtil netværket genopretter sig. Dette kan naturligvis føre til tab af data, hvis en eller flere noder går tabt.
Hvis lederen er adskilt fra Zookeeper på grund af forbindelsestab, kan dette resultere i, at beskeder går tabt fra acks=1. Tab af kommunikation med Zookeeper forårsager en kortsigtet logisk splittelse med to ledere. Dette problem løses af parameteren acks = alle.
Parameter min.insync.replikaer i to eller flere replikaer giver yderligere garantier for, at sådanne kortsigtede scenarier ikke vil resultere i tab af meddelelser, som i scenario 6.
Resumé af beskedtab
Lad os liste alle de måder, du kan miste data på i Kafka:
- Enhver lederfejl, hvis beskeder blev bekræftet af acks=1
- Enhver uren ledelsesovergang, dvs. til en tilhænger uden for ISR, selv med acks = alle
- Isoler leder fra Zookeeper, hvis beskeder blev bekræftet med acks=1
- Fuldstændig isolation af lederen, som allerede havde komprimeret ISR-gruppen til sig selv. Alle beskeder vil gå tabt, endda acks = alle. Dette er kun sandt, hvis min.insync.replicas=1.
- Samtidige fejl i alle noder i en partition. Da beskeder bekræftes fra hukommelsen, er nogle muligvis endnu ikke skrevet til disken. Efter genstart af serverne kan der mangle nogle meddelelser.
Urene lederskabsovergange kan undgås enten ved at forbyde dem eller ved at sikre en redundans på mindst to. Den mest robuste konfiguration er en kombination acks = alle и min.insync.replikaer over 1.
Direkte sammenligning af RabbitMQ og Kafka pålidelighed
For at sikre pålidelighed og høj tilgængelighed implementerer begge platforme et primært og sekundært replikeringssystem. RabbitMQ har dog en akilleshæl. Når der genoprettes forbindelse efter en fejl, kasserer noder deres data, og synkroniseringen blokeres. Denne dobbelthed sætter spørgsmålstegn ved holdbarheden af store køer i RabbitMQ. Du bliver nødt til at acceptere enten reduceret redundans eller langvarige blokeringer. Reduktion af redundans øger risikoen for massivt datatab. Men hvis køerne er små, kan korte perioder med utilgængelighed (et par sekunder) af hensyn til redundansen håndteres ved gentagne forbindelsesforsøg.
Kafka har ikke dette problem. Det kasserer kun data fra divergenspunktet mellem lederen og følgeren. Alle generelle data gemmes. Derudover blokerer replikering ikke systemet. Lederen fortsætter med at acceptere skrivninger, mens den nye følger indhenter det, så det bliver en triviel opgave for DevOps at tilslutte sig eller gentilslutte sig en klynge. Selvfølgelig er der stadig problemer såsom netværksbåndbredde under replikering. Hvis du tilføjer flere følgere på samme tid, kan du løbe ind i båndbreddegrænser.
RabbitMQ overgår Kafka med hensyn til pålidelighed, når flere servere i en klynge fejler samtidigt. Som vi allerede har sagt, sender RabbitMQ først en bekræftelse til udgiveren, efter at meddelelsen er skrevet til disken på masteren og alle spejle. Men dette tilføjer yderligere forsinkelse af to grunde:
- fsync hvert par hundrede millisekunder
- En spejlfejl kan først bemærkes, efter at levetiden for de pakker, der kontrollerer tilgængeligheden af hver node (nettick), er udløbet. Hvis spejlet er langsomt eller er faldet, tilføjer dette en forsinkelse.
Kafka satser på, at hvis en besked er gemt på tværs af flere noder, kan den godkende beskeder, så snart de er i hukommelsen. Dette skaber en risiko for at miste meddelelser af enhver type (selv acks = alle, min.insync.replicas=2) i tilfælde af samtidig afslag.
Samlet set har Kafka bedre ydeevne og er designet til klynger fra bunden af. Antallet af følgere kan øges til 11, hvis det er nødvendigt for pålideligheden. Replikationsfaktor 5 og minimum antal replikaer i synkroniseret tilstand min.insync.replicas=3 vil gøre tab af besked til en meget sjælden begivenhed. Hvis din infrastruktur kan understøtte denne replikeringsfaktor og redundansniveau, kan du vælge denne mulighed.
RabbitMQ clustering er god til små køer. Men selv små køer kan hurtigt vokse, når der er tæt trafik. Når først køerne bliver lange, bliver du nødt til at træffe svære valg mellem tilgængelighed og pålidelighed. RabbitMQ-klynger er bedst egnet til ikke-typiske situationer, hvor fordelene ved RabbitMQ's fleksibilitet opvejer eventuelle ulemper ved dets clustering.
En modgift mod RabbitMQs sårbarhed over for store køer er at opdele dem i mange mindre. Hvis du ikke kræver fuld bestilling af hele køen, men kun de relevante meddelelser (for eksempel meddelelser fra en specifik klient), eller slet ikke bestiller noget, så er denne mulighed acceptabel: se mit projekt at opdele køen (projektet er stadig i sin tidlige fase).
Glem endelig ikke en række fejl i klynge- og replikeringsmekanismerne for både RabbitMQ og Kafka. Med tiden er systemerne blevet mere modne og stabile, men ingen besked vil nogensinde være 100 % sikker mod tab! Derudover sker der storstilede ulykker i datacentre!
Hvis jeg er gået glip af noget, lavet en fejl, eller du er uenig i nogen af punkterne, er du velkommen til at efterlade en kommentar eller kontakte mig.
Jeg bliver ofte spurgt: "Hvad skal jeg vælge, Kafka eller RabbitMQ?", "Hvilken platform er bedre?" Sandheden er, at det virkelig afhænger af din situation, aktuelle erfaringer osv. Jeg tøver med at give min mening til kende, da det ville være for meget af en overforenkling at anbefale én platform til alle use cases og mulige begrænsninger. Jeg skrev denne serie af artikler, så du kan danne dig din egen mening.
Jeg vil gerne sige, at begge systemer er førende på dette område. Jeg er måske en smule forudindtaget, fordi jeg ud fra min erfaring med projekter har en tendens til at værdsætte ting som garanteret bestilling af beskeder og pålidelighed mere.
Jeg ser andre teknologier, der mangler denne pålidelighed og garanteret bestilling, så ser jeg på RabbitMQ og Kafka, og jeg ser en utrolig værdi i begge disse systemer.
Kilde: www.habr.com
