

Lad os huske på, at Elastic Stack er baseret på den ikke-relationelle Elasticsearch-database, Kibana-webgrænsefladen og dataindsamlere og processorer (den mest berømte Logstash, forskellige Beats, APM og andre). En af de gode tilføjelser til hele stakken af produkter nævnt ovenfor er dataanalyse ved hjælp af maskinlæringsalgoritmer. I denne artikel vil vi se på, hvad disse algoritmer er. Se venligst nedenfor.
Machine learning er en betalt funktion i freemium Elastic Stack og er inkluderet i X-Pack. For at begynde at bruge det skal du blot aktivere 30-dages prøveversion efter installationen. Når prøveperioden udløber, kan du bede support om en forlængelse eller købe et abonnement. Abonnementsprisen beregnes ikke ud fra mængden af data, men ud fra antallet af anvendte noder. Nej, mængden af data påvirker selvfølgelig antallet af nødvendige noder, men alligevel er denne tilgang til licensering mere human i forhold til virksomhedens budget. Hvis der ikke er behov for høj ydeevne, kan du spare penge.
ML i Elastic Stack er skrevet i C++ og kører uden for den JVM, hvor Elasticsearch selv kører. Det vil sige, at processen (det kaldes i øvrigt autodetect) forbruger alt, hvad JVM'en ikke sluger. På en demostand er dette ikke så kritisk, men i et produktionsmiljø er det vigtigt at allokere separate noder til ML-opgaver.
Maskinlæringsalgoritmer er opdelt i to kategorier - и . I Elastic Stack er algoritmen fra kategorien "uovervåget". Ved Du kan se på maskinlæringsalgoritmernes matematiske apparat.
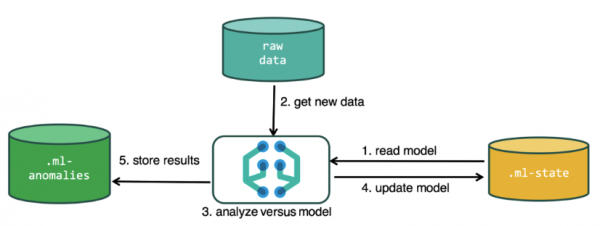
For at udføre analysen bruger maskinlæringsalgoritmen data gemt i Elasticsearch-indekser. Du kan oprette opgaver til analyse både fra Kibana-grænsefladen og via API'et. Hvis du gør dette gennem Kibana, er der nogle ting, du ikke behøver at vide. For eksempel yderligere indekser, som algoritmen bruger under sin drift.
Yderligere indekser brugt i analyseprocessen.ml-state — information om statistiske modeller (analyseindstillinger);
.ml-anomalier-* — resultater af ML-algoritmer;
.ml-meddelelser — indstillinger for meddelelser baseret på analyseresultater.
Datastrukturen i en Elasticsearch-database består af indekser og de dokumenter, der er gemt i dem. Hvis vi sammenligner det med en relationsdatabase, så kan et indeks sammenlignes med et databaseskema og et dokument med en post i en tabel. Denne sammenligning er betinget og er givet for at forenkle forståelsen af yderligere materiale for dem, der kun har hørt om Elasticsearch.
Den samme funktionalitet er tilgængelig gennem API'et som gennem webgrænsefladen, så for klarhed og forståelse af koncepterne vil vi vise, hvordan man konfigurerer gennem Kibana. I menuen til venstre er der en Machine Learning sektion, hvor du kan oprette et nyt job. I Kibana-grænsefladen ser det ud som på billedet nedenfor. Nu vil vi analysere hver type opgave og vise de analysetyper, der kan konstrueres her.
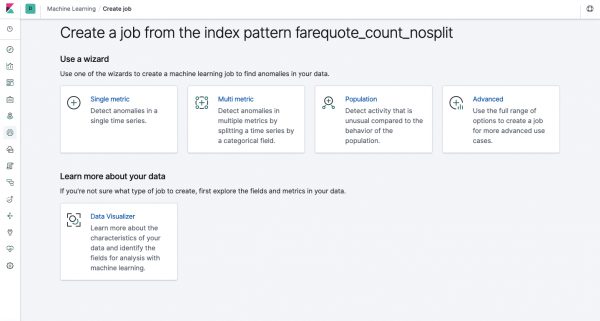
Enkelt metrisk - analyse af en metrik, Multi Metric - analyse af to eller flere metrikker. I begge tilfælde analyseres hver metrik i et isoleret miljø, dvs. algoritmen tager ikke højde for adfærden af parallel analyserede metrikker, som det kan se ud i tilfældet med Multi Metric. For at udføre beregninger under hensyntagen til sammenhængen mellem forskellige metrikker, kan du bruge Befolkningsanalyse. Og Advanced er en finjustering af algoritmer med yderligere muligheder for specifikke opgaver.
Enkelt metrisk
At analysere ændringer i en enkelt metrik er den enkleste ting, du kan gøre her. Når du har klikket på Opret job, vil algoritmen lede efter uregelmæssigheder.
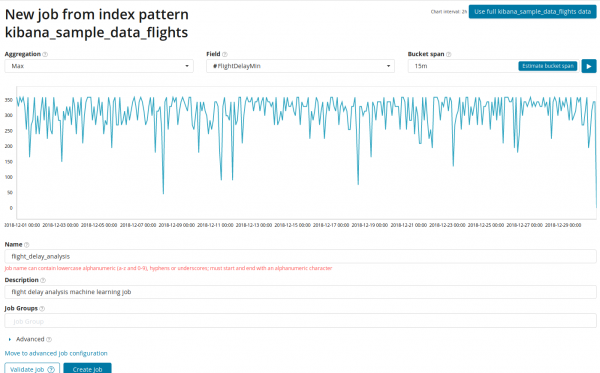
I feltet Sammenlægning du kan vælge en tilgang til at søge efter anomalier. For eksempel hvornår Min Værdier under typiske vil blive betragtet som unormale. Spise Max, High Mean, Low, Mean, Distinct og andre. Beskrivelse af alle funktioner kan ses .
I feltet Felt Det numeriske felt i dokumentet, som vi vil udføre analysen på, er angivet.
I feltet — granularitet af intervallerne på den tidslinje, som analysen vil blive udført for. Du kan stole på automatiseringen eller vælge manuelt. Billedet nedenfor viser et eksempel på for lav granularitet - du kan gå glip af en anomali. Denne indstilling giver dig mulighed for at ændre algoritmens følsomhed over for anomalier.
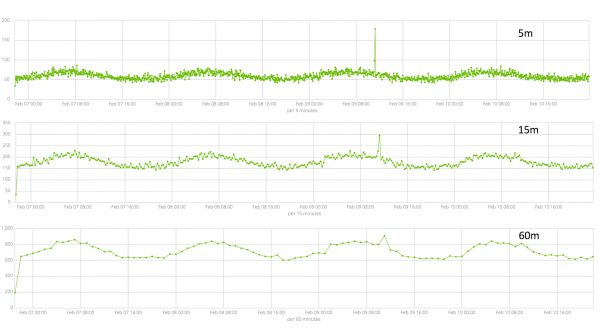
Varigheden af de indsamlede data er en central ting, der påvirker analysens effektivitet. Under analysen identificerer algoritmen gentagne intervaller, beregner konfidensintervallet (baselines) og identificerer anomalier - atypiske afvigelser fra metrikkens normale opførsel. Bare for eksempel:
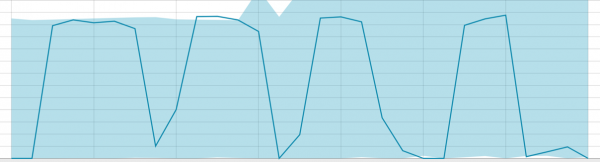
Grundlinjer for et lille datasegment:
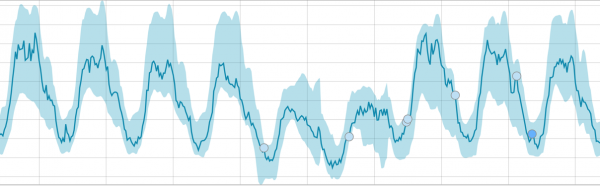
Når algoritmen har noget at lære af, ser basislinjerne således ud:
Efter at opgaven er lanceret, identificerer algoritmen unormale afvigelser fra normen og rangerer dem efter sandsynligheden for anomali (farven på den tilsvarende etiket er angivet i parentes):
Advarsel (blå): mindre end 25
Mindre (gul): 25-50
Major (orange): 50-75
Kritisk (rød): 75-100
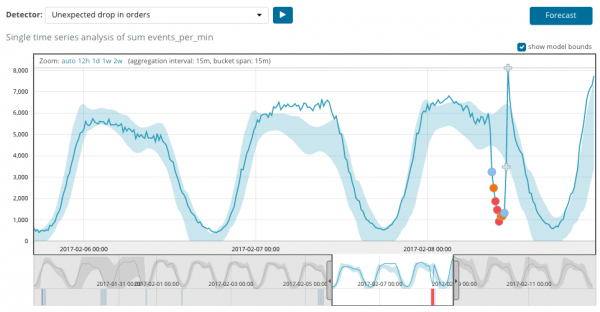
Grafen nedenfor viser et eksempel på de fundne anomalier.
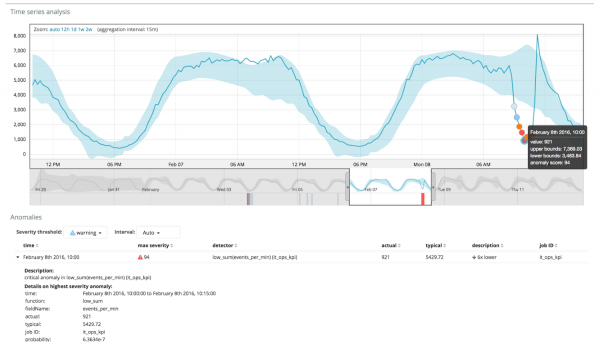
Her kan du se tallet 94, som angiver sandsynligheden for en anomali. Det er klart, at da værdien er tæt på 100, betyder det, at vi har en anomali. Kolonnen under grafen viser den nedsættende lille sandsynlighed på 0.000063634 % af den metriske værdi, der vises der.
Ud over at søge efter uregelmæssigheder kan du køre prognoser i Kibana. Dette gøres på en elementær måde og fra samme præsentation med anomalier - knap Forecast i øverste højre hjørne.
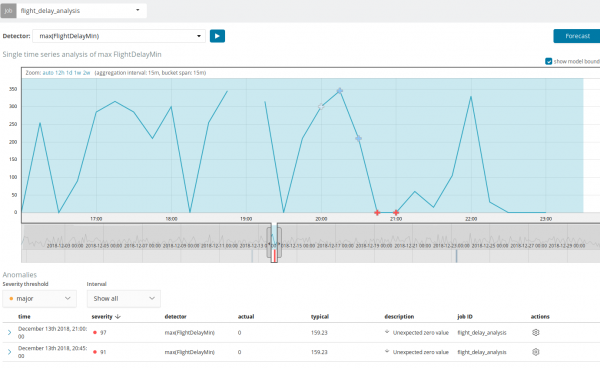
Prognosen er lavet for maksimalt 8 uger frem. Selvom du virkelig vil, kan du ikke designe mere.
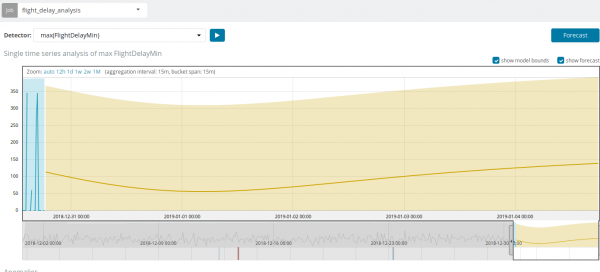
I nogle situationer vil prognosen være meget nyttig, for eksempel ved overvågning af brugerbelastning på infrastrukturen.
Multi-metrisk
Lad os gå videre til den næste ML-funktion i Elastic Stack - analysere flere metrics i én batch. Men dette betyder ikke, at en metriks afhængighed af en anden vil blive analyseret. Dette er det samme som Single Metric kun med flere metrics på én skærm for nem sammenligning af virkningen af en på en anden. Vi vil tale om analysen af en metriks afhængighed af en anden i Befolkningsafsnittet.
Efter at have klikket på firkanten med Multi Metric, vises et vindue med indstillinger. Lad os se på dem mere detaljeret.
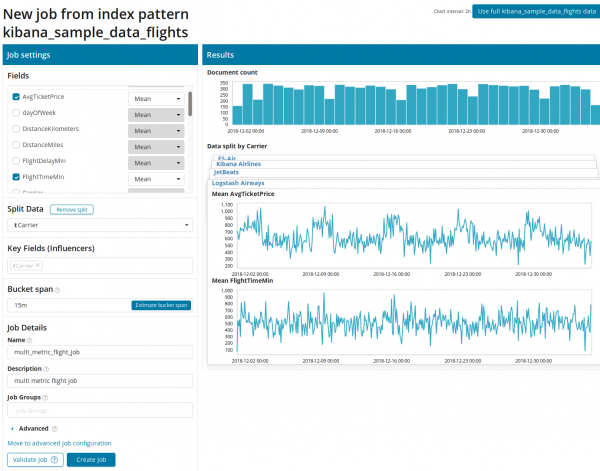
Først skal du vælge felterne til analyse og aggregering af data på dem. Aggregeringsmulighederne her er de samme som for Single Metric (Max, High Mean, Low, Mean, Distinct og andre). Yderligere kan dataene opdeles i et af felterne (felt Opdel data). I eksemplet gjorde vi det efter felt OriginAirportID. Bemærk, at metrik-grafen til højre nu præsenteres som flere grafer.
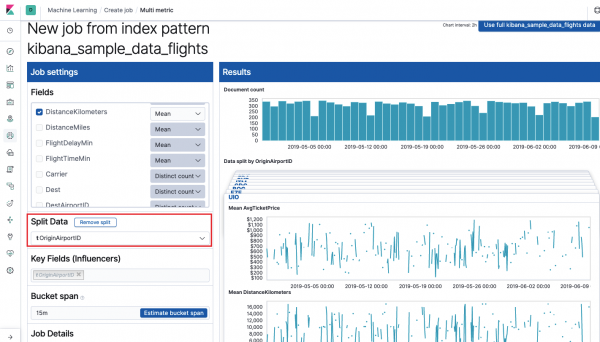
Field Nøglefelter (influencers) påvirker direkte de fundne anomalier. Som standard vil der altid være mindst én værdi her, men du kan tilføje flere. Algoritmen vil tage højde for indflydelsen af disse felter under analyse og vise de mest "indflydelsesrige" værdier.
Efter lancering vil Kibana-grænsefladen vise noget som dette.
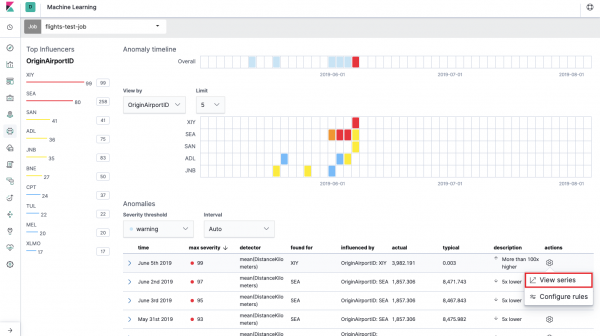
Dette er det såkaldte varmekort over anomalier for hver feltværdi OriginAirportID, som vi angav i Opdel data. Som med Single Metric angiver farven niveauet af outlier. En lignende analyse er praktisk at lave, for eksempel på arbejdsstationer for at spore dem med et mistænkeligt højt antal autorisationer osv. Vi skrev allerede , som også kan samles og analyseres her.
Nedenfor varmekortet er en liste over uregelmæssigheder, som hver især kan skiftes til Single Metric-visning for detaljeret analyse.
Befolkning
For at søge efter anomalier mellem korrelationer mellem forskellige metrikker har Elastic Stack en specialiseret befolkningsanalyse. Det er med dens hjælp, at du kan søge efter unormale værdier i ydeevnen af enhver server sammenlignet med andre, for eksempel når antallet af anmodninger til målsystemet stiger.
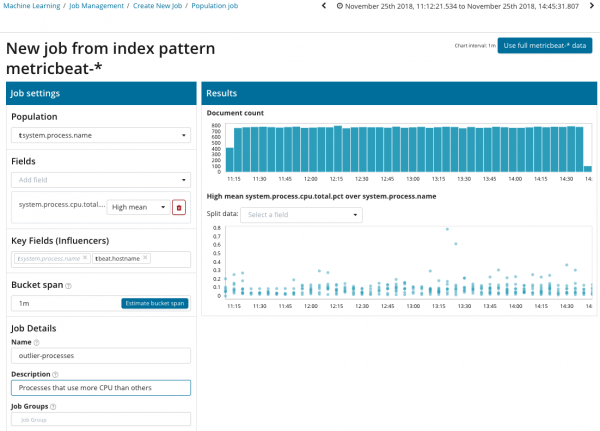
I denne illustration angiver feltet Population den værdi, som de analyserede metrics gælder for. I dette tilfælde er det navnet på processen. Som et resultat vil vi se, hvordan CPU-belastningen af hver proces påvirkede hinanden.
Bemærk venligst, at grafen over de analyserede data adskiller sig mellem Single Metric og Multi Metric tilfælde. Dette er gjort i Kibana ved design for at forbedre opfattelsen af fordelingen af værdier af de analyserede data.
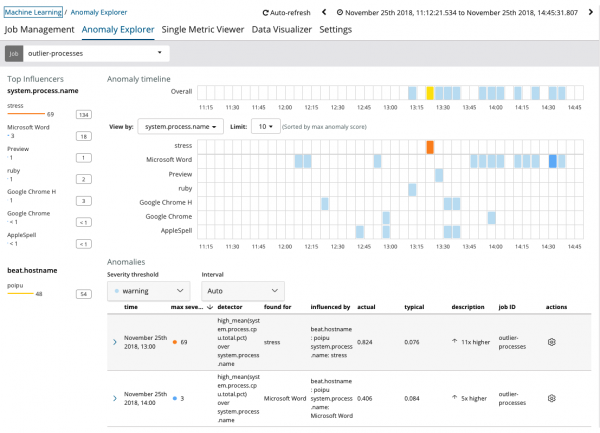
Det fremgår tydeligt af grafen, at processen opførte sig unormalt. stress (i øvrigt genereret af et særligt hjælpeprogram) på serveren poipu, der påvirkede (eller viste sig at være en influencer) i fremkomsten af denne anomali.
Avanceret
Finjusterede analyser. Avanceret analyse i Kibana giver yderligere indstillinger. Efter at have klikket på flisen Avanceret i oprettelsesmenuen, vises et vindue med faner som dette. Tab Job Detaljer savnet med vilje, er der grundlæggende indstillinger, som ikke er direkte relateret til analyseindstillingerne.
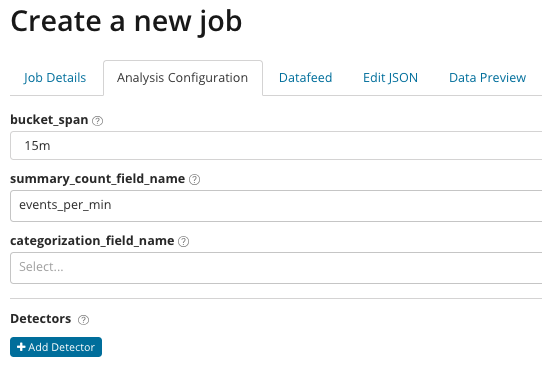
В summary_count_field_name Du kan eventuelt angive navnet på feltet fra de dokumenter, der indeholder de aggregerede værdier. I dette eksempel er antallet af hændelser pr. minut. I Navnet på feltværdien fra dokumentet, der indeholder en bestemt variabelværdi, er angivet. Ved at bruge en maske til dette felt kan du opdele de analyserede data i undersæt. Vær opmærksom på knappen Tilføj detektor i den forrige illustration. Nedenfor er resultatet af at klikke på denne knap.
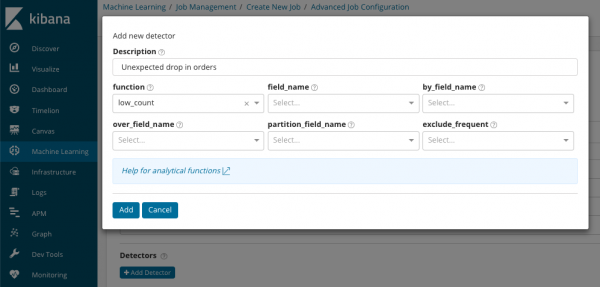
Her er en ekstra blok med indstillinger til konfiguration af anomalidetektoren til en specifik opgave. Vi planlægger at diskutere specifikke use cases (især sikkerhedsrelaterede) i de følgende artikler. f.eks. en af de adskilte sager. Det er relateret til søgningen efter sjældent forekommende værdier og er implementeret .
I feltet funktion Du kan vælge en specifik funktion for at søge efter uregelmæssigheder. Undtagen sjældne, der er et par flere interessante funktioner - . De identificerer anomalier i adfærden af metrikker i løbet af henholdsvis en dag eller uge. Andre analysefunktioner .
В feltnavn Det dokumentfelt, som analysen vil blive udført for, er angivet. By_field_name kan bruges til at adskille analyseresultaterne for hver enkelt værdi af det her specificerede dokumentfelt. Hvis du udfylder det over_field_name vi får den befolkningsanalyse, som vi diskuterede ovenfor. Hvis du angiver en værdi i partitionsfeltnavn, så vil separate basislinjer blive beregnet for hver værdi i dette dokumentfelt (f.eks. kan navnet på serveren eller processen på serveren fungere som en værdi). I ekskluder_hyppig du kan vælge alle eller ingen, hvilket vil betyde udelukkelse (eller medtagelse) af hyppigt forekommende dokumentfeltværdier.
I denne artikel forsøgte vi at give en meget kortfattet idé om mulighederne for maskinlæring i Elastic Stack, men der er stadig mange detaljer tilbage bag kulisserne. Fortæl os i kommentarerne, hvilke sager du formåede at løse ved hjælp af Elastic Stack, og til hvilke opgaver du bruger det. For at kontakte os kan du bruge private beskeder på Habr eller .
Kilde: www.habr.com
