

Hinweis.: Die Autoren dieses Artikels sind Ingenieure eines kleinen tschechischen Unternehmens namens pipetail. Sie haben eine großartige Liste von [teilweise banalen, aber dennoch] so aktuellen Problemen und Missverständnissen im Zusammenhang mit der Nutzung von Kubernetes-Clustern zusammengestellt.

Im Laufe der Jahre mit Kubernetes haben wir mit einer Vielzahl von Clustern gearbeitet (sowohl verwalteten als auch nicht verwalteten – auf GCP, AWS und Azure). Im Laufe der Zeit haben wir bemerkt, dass einige Fehler ständig wiederholt werden. Dabei ist das nichts, wofür man sich schämen müsste: Wir haben selbst die meisten davon gemacht!
In diesem Artikel werden die häufigsten Fehler gesammelt und es wird erwähnt, wie man sie beheben kann.
1. Ressourcen: Anfragen und Limits
Dieser Punkt verdient definitiv die größte Aufmerksamkeit und den ersten Platz auf der Liste.
Die CPU-Anfrage ist in der Regel entweder gar nicht festgelegt oder hat einen sehr niedrigen Wert. (um so viele Pods wie möglich auf jedem Knoten bereitzustellen). Dadurch sind die Knoten überlastet. Bei hoher Last sind die Rechenressourcen des Knotens vollständig ausgelastet und die spezifische Arbeitslast erhält nur das, was sie "angefordert" hat durch CPU-Drosselung. Dies führt zu erhöhten Latenzen in der Anwendung, Timeouts und anderen unangenehmen Folgen. (Mehr dazu erfahren Sie in einer unserer anderen aktuellen Übersetzungen: „“ — Anm. d. Übers.)
BestEffort (äußerst nicht empfohlen):
resources: {}Extrem niedrige CPU-Anfrage (äußerst nicht empfohlen):
resources:
Requests:
cpu: "1m"Andererseits kann ein CPU-Limit zu unangemessenen Taktüberschreitungen durch Pods führen, selbst wenn die CPU des Knotens nicht vollständig ausgelastet ist. Auch dies kann zu erhöhten Latenzen führen. Es gibt immer noch Debatten über die CPU CFS-Quoten im Linux-Kernel und die CPU-Drosselung basierend auf festgelegten Grenzen, sowie das Deaktivieren der CFS-Quota… Leider können CPU-Limits mehr Probleme verursachen, als sie lösen können. Weitere Informationen finden Sie unter dem folgenden Link.
Überreservierung (overcommiting) Ein Mangel an Speicher kann zu größeren Problemen führen. Das Erreichen der CPU-Obergrenze hat Taktverluste zur Folge, während das Erreichen des Speicherkontingents das "Killen" des Pods nach sich zieht. Haben Sie jemals beobachtet, OOMKill? Да, речь идет именно о нем.
Möchten Sie die Wahrscheinlichkeit dieses Ereignisses minimieren? Vermeiden Sie übermäßige Speichermengen und verwenden Sie Guaranteed QoS (Quality of Service), indem Sie die memory request gleich dem Limit setzen (wie im nächsten Beispiel). Weitere Informationen finden Sie in der (Lead Engineer bei Zalando).
Burstable (höhere Wahrscheinlichkeit für OOMKills):
resources:
requests:
memory: "128Mi"
cpu: "500m"
limits:
memory: "256Mi"
cpu: 2Guaranteed:
resources:
requests:
memory: "128Mi"
cpu: 2
limits:
memory: "128Mi"
cpu: 2Was könnte bei der Ressourcenkonfiguration potenziell helfen?
Mit metrics-server können Sie den aktuellen CPU- und Speicherverbrauch der Pods (und der Container innerhalb dieser) einsehen. Höchstwahrscheinlich verwenden Sie es bereits. Führen Sie einfach die folgenden Befehle aus:
kubectl top pods
kubectl top pods --containers
kubectl top nodesSie zeigen jedoch nur die aktuelle Nutzung an. Damit können Sie eine grobe Vorstellung von den Größenordnungen gewinnen, aber letztendlich benötigen Sie eine Historie der Metrikänderungen über die Zeit (um Fragen wie: „Wie hoch war die CPU-Spitze?“, „Wie war die Auslastung gestern Morgen?“ usw. zu beantworten). Dafür können Sie Prometheus, DataDog und andere Tools verwenden. Sie erfassen einfach die Metriken vom metrics-server und speichern diese, sodass der Benutzer sie anfordern und entsprechende Grafiken erstellen kann.
ermöglicht es diesen Prozess zu automatisieren. Er überwacht die Historie der CPU- und Speicherauslastung und passt neue Requests und Limits basierend auf diesen Informationen an. dieses Prozesses. Er überwacht die Historie der CPU- und Speicherauslastung und passt neue Anfragen und Grenzen basierend auf diesen Informationen an.
Die effiziente Nutzung der Rechenressourcen ist eine anspruchsvolle Aufgabe. Es ist wie ein ständiges Spiel Tetris. Wenn Sie bei niedriger durchschnittlicher Auslastung (sagen wir ~10 %) zu viel für Rechenleistung bezahlen, empfehlen wir, Produkte zu betrachten, die auf AWS Fargate oder Virtual Kubelet basieren. Sie sind auf einem serverlosen / nutzungsabhängigen Abrechnungsmodell aufgebaut, was unter diesen Bedingungen kostengünstiger sein kann.
2. Liveness- und Readiness-Probes
Standardmäßig sind die Liveness- und Readiness-Überprüfungen in Kubernetes nicht aktiviert. Manchmal werden sie vergessen zu aktivieren…
Wie kann man jedoch den Dienst bei einem irreparablen Fehler neu starten? Und wie erfährt der Lastenausgleich, dass ein Pod bereit ist, Traffic zu empfangen? Oder dass er in der Lage ist, mehr Traffic zu verarbeiten?
Diese Überprüfungen werden oft verwechselt:
- Liveness — eine 'Lebensfähigkeit'-Überprüfung, die den Pod bei einem fehlerhaften Abschluss neu startet;
- Readiness — eine Bereitheitsüberprüfung, die den Pod bei einem Fehlschlag vom Kubernetes-Dienst trennt (das kann man überprüfen mit
kubectl get endpoints) und Traffic an ihn wird nicht gesendet, bis die nächste Überprüfung erfolgreich abgeschlossen ist.
Beide Überprüfungen WIRD IM LAUFE DES GESAMTEN LEBENSZYKLUS DES PODS AUSGEFÜHRT. Das ist sehr wichtig.
Es ist ein weit verbreitetes Missverständnis, dass Readiness-Überprüfungen nur beim Start durchgeführt werden, damit der Lastenausgleich erkennen kann, dass der Pod bereit ist (Bereit) und mit der Bearbeitung von Traffic beginnen kann. Das ist jedoch nur eine von vielen Anwendungsmöglichkeiten.
Eine andere ist die Möglichkeit zu prüfen, ob der Traffic auf den Pod übermäßig hoch ist und ihn überlastet (oder der Pod rechenintensive Berechnungen durchführt). In diesem Fall hilft die Readiness-Prüfung. die Last auf den Pod reduzieren und ihn «abkühlen». Ein erfolgreicher Abschluss der Readiness-Prüfung in der Zukunft ermöglicht es die Last auf den Pod wieder zu erhöhen. In diesem Fall wäre das Scheitern der Liveness-Prüfung bei einem Fehlschlag der Readiness-Prüfung sehr kontraproduktiv. Warum einen Pod neu starten, der gesund ist und sein Bestes gibt?
Deshalb ist in einigen Fällen ein vollständiger Verzicht auf Prüfungen besser als ihre Aktivierung mit falsch konfigurierten Parametern. Wie bereits erwähnt, wenn die Liveness-Prüfung die Readiness-Prüfung kopiert, dann haben Sie ein großes Problem. Eine mögliche Lösung wäre, , und außen vor zu lassen.
Beide Prüftypen sollten nicht bei einem Ausfall allgemeiner Abhängigkeiten fehlschlagen, da dies zu einem kaskadierenden (lawinenartigen) Ausfall aller Pods führen würde. Mit anderen Worten, .
3. LoadBalancer für jeden HTTP-Dienst
Wahrscheinlich haben Sie in Ihrem Cluster HTTP-Dienste, die Sie nach außen weiterleiten möchten.
Wenn Sie den Dienst als type: LoadBalancer, der Controller (abhängig vom Dienstanbieter) wird einen externen LoadBalancer bereitstellen und abstimmen (der nicht unbedingt auf L7, eher auf L4 arbeitet), und dies kann sich auf die Kosten auswirken (externe statische IPv4-Adresse, Rechenleistung, sekundengenaue Abrechnung) aufgrund der Notwendigkeit, eine große Anzahl ähnlicher Ressourcen zu erstellen.
In diesem Fall ist es viel logischer, einen einzigen externen Lastenausgleich zu verwenden, um Dienste als type: NodePortzu öffnen. Oder noch besser, etwas wie nginx-ingress-controller (oder traefik), der als einziger NodePort Endpunkt fungiert, der mit dem externen LoadBalancer verbunden ist und den Datenverkehr im Cluster über ingress-Ressourcen von Kubernetes weiterleitet.
Andere interne (Mikro)dienste, die miteinander interagieren, können über Dienste Typ ClusterIP und den integrierten Mechanismus zur Dienstentdeckung über DNS „kommunizieren“. Verwenden Sie dabei nicht ihre öffentlichen DNS/IPs, da dies die Latenz beeinträchtigen und zu steigenden Cloud-Kosten führen kann.
4. Automatisches Skalieren des Clusters unter Berücksichtigung seiner Besonderheiten
Beim Hinzufügen und Entfernen von Knoten aus einem Cluster sollte man sich nicht auf einige grundlegende Metriken wie die CPU-Auslastung dieser Knoten verlassen. Die Planung von Pods muss unter Berücksichtigung vieler Einschränkungen, wie z.B. Pod- und Knotenaffinität, Taints und Toleranzen, Ressourcenanforderungen, QoS usw. Der Einsatz eines externen Autoscalers, der diese Nuancen nicht beachtet, kann zu Problemen führen.
Stellen Sie sich vor, dass ein bestimmter Pod geplant werden soll, aber alle verfügbaren CPU-Ressourcen angefordert oder belegt sind und der Pod im Status Pendingsteckt. Der externe Autoscaler sieht die aktuelle durchschnittliche CPU-Auslastung (und nicht die angefragte) und initiiert keine Erweiterung (Scale-Out) — er fügt keinen weiteren Knoten hinzu. Infolgedessen wird dieser Pod nicht geplant.
Das Gegenteil, das Rückskalieren (Scale-In) — das Entfernen eines Knotens aus dem Cluster — ist immer schwieriger umzusetzen. Stellen Sie sich vor, Sie haben einen stateful Pod (mit angehängtem persistenten Speicher). Persistent Volumes gehören in der Regel zu einer bestimmten Verfügbarkeitszone. und sind nicht im Bereich repliziert. Wenn der externe Autoscaler also einen Knoten mit diesem Pod entfernt, kann der Scheduler diesen Pod nicht auf einen anderen Knoten planen, da dies nur in der Verfügbarkeitszone möglich ist, in der der Speicher lokalisiert ist. Der Pod bleibt im Zustand hängen. Pending.
In der Kubernetes-Community ist der sehr beliebt. Er arbeitet im Cluster, unterstützt die API von führenden Cloud-Anbietern, berücksichtigt alle Einschränkungen und kann in den oben genannten Fällen skalieren. Außerdem kann er ein Scale-In durchführen, wobei alle festgelegten Einschränkungen beibehalten werden, wodurch Geld gespart wird (das ansonsten für ungenutzte Kapazitäten ausgegeben worden wäre).
5. Missachtung der Möglichkeiten von IAM/RBAC
Seien Sie vorsichtig bei der Verwendung von IAM-Benutzern mit festen Geheimnissen für Maschinen und Anwendungen.Richten Sie temporären Zugang ein, indem Sie Rollen und Dienstkonten verwendet werden..
Wir sehen oft, dass Zugangsschlüssel (und Geheimnisse) hartkodiert in der Anwendungsconfiguration gespeichert sind, und dass die Rotation von Geheimnissen trotz vorhandener Zugriffsrechte auf Cloud IAM vernachlässigt wird. Verwenden Sie IAM-Rollen und Service-Konten anstelle von Benutzern, wo dies sinnvoll ist.

Vergessen Sie kube2iam und gehen Sie direkt zu IAM-Rollen für Service-Konten über (wie in der Štěpán Vraný):
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::123456789012:role/my-app-role
name: my-serviceaccount
namespace: defaultEine Annotation. So schwer ist das nicht, oder?
Darüber hinaus sollten Sie Service-Konten und Instance-Profile nicht mit Rechten ausstatten, admin und cluster-admin, wenn sie diese nicht benötigen. Das ist etwas komplizierter umzusetzen, besonders in RBAC K8s, aber die Mühe ist es definitiv wert.
6. Verlassen Sie sich nicht auf automatische Anti-Affinität für Pods.
Stellen Sie sich vor, Sie haben drei Replikate eines Deployments auf einem Knoten. Der Knoten fällt aus, und damit auch alle Replikate. Eine unangenehme Situation, oder? Aber warum waren alle Replikate auf einem Knoten? Sollte Kubernetes nicht Hochverfügbarkeit (HA) gewährleisten?!
Leider hält der Kubernetes-Planer aus eigener Initiative nicht die Regeln der Trennung ein. (anti-affinity) für Pods. Diese müssen ausdrücklich definiert werden:
// опущено для краткости
labels:
app: zk
// опущено для краткости
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: "app"
operator: In
values:
- zk
topologyKey: "kubernetes.io/hostname" Das ist alles. Jetzt werden die Pods auf verschiedene Knoten geplant (diese Bedingung wird nur während der Planung überprüft, jedoch nicht während ihrer Ausführung — daher requiredDuringSchedulingIgnoredDuringExecution).
Hier sprechen wir über podAntiAffinity auf unterschiedlichen Knoten: topologyKey: "kubernetes.io/hostname", — und nicht auf verschiedenen Verfügbarkeitszonen. Um eine umfassende HA zu realisieren, muss man tiefer in dieses Thema eintauchen.
7. Ignorierung von PodDisruptionBudgets
Stellen Sie sich vor, Sie haben eine Produktionslast in einem Kubernetes-Cluster. Regelmäßig müssen Knoten und das Cluster selbst aktualisiert (oder außer Betrieb genommen) werden. Das PodDisruptionBudget (PDB) ist eine Art Garantievereinbarung über die Wartung zwischen den Clusteradministratoren und den Benutzern.
PDB hilft, Unterbrechungen der Dienste zu vermeiden, die durch unzureichende Knoten verursacht werden:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: zookeeperIn diesem Beispiel erklären Sie als Benutzer eines Clusters den Administratoren: „Hey, ich habe einen Dienst namens Zookeeper, und egal was Sie tun, ich möchte, dass mindestens 2 Replikate dieses Dienstes immer verfügbar sind.“
Mehr dazu können Sie lesen .
8. Mehrere Benutzer oder Umgebungen in einem gemeinsamen Cluster
Kubernetes-Namensräume (namespaces) bieten keine starke Isolation.
Es ist ein weit verbreiteter Irrglaube, dass, wenn man eine nicht-produktive Last in einem Namensraum und eine produktive Last in einem anderen bereitstellt, diese sich gegenseitig nicht beeinflussen werden.… Dennoch kann durch Ressourcenzuteilungen / -begrenzungen, das Setzen von Quoten und die Zuweisung von priorityClasses ein gewisses Maß an Isolation erreicht werden. Eine gewisse „physische“ Isolation im Datenbereich bieten Affinitäten, Toleranzen, Taints (oder Node-Selectoren), jedoch ist eine solche Trennung schwierig umzusetzen.
Wer beide Arten von Arbeitslasten in einem Cluster kombinieren möchte, muss mit der Komplexität leben. Wenn dies jedoch nicht erforderlich ist und Sie es sich leisten können, einen weiteren Cluster zu erstellen. (zum Beispiel in der öffentlichen Cloud), dann sollten Sie es auch so handhaben. Das ermöglicht ein viel höheres Maß an Isolation.
9. externalTrafficPolicy: Cluster
Sehr oft beobachten wir, dass der gesamte Verkehr in den Cluster über einen Dienst wie NodePort läuft, für den standardmäßig die Politik festgelegt ist. externalTrafficPolicy: Cluster. Das bedeutet, dass NodePort auf jedem Knoten im Cluster geöffnet ist und jeder von ihnen verwendet werden kann, um mit dem gewünschten Dienst (Podd-Satz) zu kommunizieren.
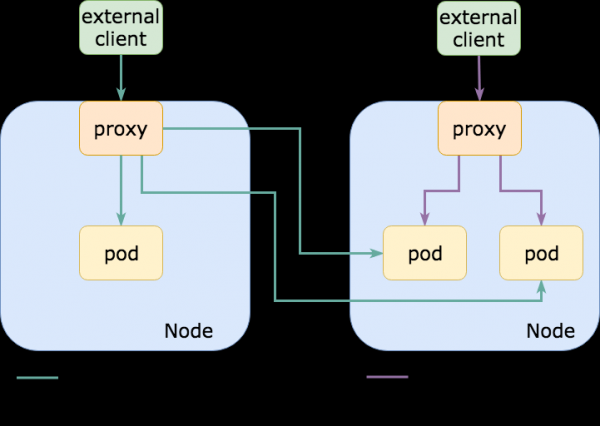
In der Regel sind die tatsächlichen Pods, die mit dem oben erwähnten NodePort-Dienst verbunden sind, nur auf einer Teilmenge dieser Knoten. Mit anderen Worten, wenn ich mich mit einem Knoten verbinde, der den benötigten Pod nicht hat, wird der Verkehr an einen anderen Knoten weitergeleitet, was einen Transitabschnitt (Hop) hinzufügt und die Latenz erhöht (wenn sich die Knoten in verschiedenen Verfügbarkeits- oder Rechenzentren befinden, kann die Latenz recht hoch sein; zudem steigen die Kosten für Egress-Verkehr).
Andererseits, wenn für einen bestimmten Kubernetes-Dienst die Politik externalTrafficPolicy: Local, sodass NodePort nur auf den Knoten geöffnet wird, auf denen die erforderlichen Pods tatsächlich laufen. Bei Verwendung eines externen Lastenausgleichers, der den Zustand überprüft (Healthchecking) der Endpunkte (wie es AWS ELBmacht), wird er den Verkehr nur an die benötigten Knoten senden,was sich positiv auf die Latenzen, den Rechenbedarf, die Egress-Kosten auswirkt (und gesunder Menschenverstand diktiert dasselbe).
Es ist sehr wahrscheinlich, dass Sie bereits etwas wie traefik oder nginx-ingress-controller als Endpunkt für NodePort (oder LoadBalancer, der ebenfalls NodePort nutzt) zur Routen von HTTP-Ingress-Verkehr verwenden, und die Aktivierung dieser Option kann die Latenz bei solchen Anfragen erheblich reduzieren.
In finden Sie detailliertere Informationen zur externalTrafficPolicy, deren Vor- und Nachteile.
10. Binden Sie sich nicht an Cluster und missbrauchen Sie den Control Plane
Früher wurden Server mit eigenen Namen bezeichnet: , HAL9000 und Colossus… Heute hingegen haben sie zufällig generierte Identifikatoren übernommen. Die Gewohnheit ist geblieben, und nun bekommen die Cluster eigene Namen.
Eine typische Geschichte (inspiriert von realen Ereignissen): Es begann mit einem Proof of Concept, weshalb der Cluster den stolzen Namen trug. testing… Jahre vergingen, und er wird IMMER NOCH in der Produktion verwendet, doch alle fürchten sich, ihn anzufassen.
Es gibt nichts Lustiges daran, dass Cluster zu Haustieren werden, daher empfehlen wir, sie regelmäßig zu löschen und dabei zu üben in der Wiederherstellung nach Ausfällen (dabei hilft — Anmerkung des Übersetzers).Außerdem ist es nicht verkehrt, sich um die Steuerungsebene (Control Plane)zu kümmern. Die Angst, ihn anzufassen, ist kein gutes Zeichen. Etcd tot? Leute, ihr habt euch wirklich in die Bredouille gebracht!
Andererseits sollte man sich nicht zu sehr mit ihm beschäftigen. Im Laufe der Zeit kann die Steuerungsebene langsam werden.Wahrscheinlich liegt dies daran, dass eine große Anzahl von Objekten ohne deren Rotation erstellt wird (eine gängige Situation bei der Verwendung von Helm mit den Standardkonfigurationen, wodurch der Status in ConfigMaps/Secrets nicht aktualisiert wird – in der Folge sammeln sich Tausende von Objekten in der Steuerungsschicht an) oder an der ständigen Bearbeitung von Kube-API-Objekten (für automatisches Skalieren, CI/CD, Monitoring, Ereignisprotokolle, Controller usw.).
Darüber hinaus empfehlen wir, die SLA/SLO-Vereinbarungen mit dem Anbieter von Managed Kubernetes zu überprüfen und auf Garantien zu achten. Der Anbieter kann garantieren die Verfügbarkeit der Steuerungsschicht (oder ihrer Subkomponenten), jedoch nicht die p99-Latenz der Anfragen, die Sie ihm senden. Mit anderen Worten, Sie können kubectl get nodeseingeben, und die Antwort erhalten Sie erst nach 10 Minuten, und das wäre kein Verstoß gegen die Servicevereinbarung.
11. Bonus: Verwendung des Tags latest
Das ist bereits ein Klassiker. In letzter Zeit begegnen wir dieser Technik nicht mehr so häufig, da viele, die aus schmerzlicher Erfahrung gelernt haben, aufgehört haben, das Tag :latest zu verwenden und begonnen haben, Versionen zu fixieren (pin). Hurra!
ECR ; wir empfehlen, sich mit diesem bemerkenswerten Feature vertraut zu machen.
Zusammenfassung
Erwarten Sie nicht, dass alles über Nacht funktioniert: Kubernetes ist kein Allheilmittel. Eine mangelhafte Anwendung (und könnte sogar noch schlimmer werden). Nachlässigkeit führt zu unnötiger Komplexität, langsamer und angespannter Leistung der Management-Schicht. Zudem riskieren Sie, ohne eine Notfallwiederherstellungsstrategie dazustehen. Setzen Sie nicht darauf, dass Kubernetes «out of the box» Isolierung und hohe Verfügbarkeit gewährleistet. Nehmen Sie sich etwas Zeit, um Ihre Anwendung wirklich cloud-native zu machen.
Einblicke in die Misserfolge verschiedener Teams erhalten Sie in von Henning Jacobs.
Wer die Liste der Fehler in diesem Artikel ergänzen möchte, kann uns auf Twitter kontaktieren (, ).
P.S. vom Übersetzer
Lesen Sie auch in unserem Blog:
- «»;
- «»;
- «» (Überblick und Video des Vortrags);
- «».
Quelle: habr.com
