

Hallo Habr! Die Datenmengen für Big Data und maschinelles Lernen wachsen exponentiell, und wir müssen sie schnell verarbeiten. Unser Beitrag behandelt eine weitere innovative Technologie im Bereich des Hochleistungsrechnens (HPC, High Performance Computing), die am Stand von Kingston auf präsentiert wurde. Hierbei handelt es sich um die Anwendung von Hi-End Speicherlösungen (SAS) in Servern mit Grafikprozessoren (GPU) und der GPUDirect Storage-Technologie. Durch den direkten Datenaustausch zwischen SAS und GPU, ohne den Umweg über die CPU, wird das Laden von Daten in GPU-Beschleuniger um ein Vielfaches beschleunigt, sodass Big Data-Anwendungen mit der maximalen Leistung von GPUs laufen. Gleichzeitig interessieren sich Entwickler von HPC-Systemen für Fortschritte im Bereich von Speicherlösungen mit höchster Ein- und Ausgabegeschwindigkeit — solche, wie sie von Kingston angeboten werden.

Die Leistung von GPUs übertrifft das Laden von Daten
Seit der Einführung von CUDA im Jahr 2007 — einer Software-Hardware-Architektur für paralleles Rechnen auf Basis von GPUs zur Entwicklung von Anwendungen für allgemeine Zwecke — sind die Hardwarefähigkeiten der GPUs enorm gewachsen. Heute finden GPUs zunehmend Anwendung in Bereichen von HPC-Anwendungen wie Big Data, maschinellem Lernen (ML) und Deep Learning (DL).
Es ist zu beachten, dass die letzten beiden Begriffe, trotz ihrer Ähnlichkeit, algorithmisch unterschiedliche Aufgaben darstellen. ML trainiert Computer anhand strukturierter Daten, während DL auf den Reaktionen von neuronalen Netzwerken basiert. Ein Beispiel, das die Unterschiede erläutert, ist recht einfach. Angenommen, der Computer soll Fotos von Katzen und Hunden, die von einem SAN hochgeladen werden, unterscheiden. Für ML sollte eine Bilderauswahl mit vielen Tags bereitgestellt werden, die jeweils ein bestimmtes Merkmal des Tieres definiert. Für DL genügt es, eine viel größere Anzahl von Bildern hochzuladen, jedoch nur mit einem einzigen Tag „das ist eine Katze“ oder „das ist ein Hund“. DL ähnelt stark der Art und Weise, wie kleine Kinder unterrichtet werden — sie sehen einfach Bilder von Hunden und Katzen in Büchern und im echten Leben (meistens, ohne dass die detaillierten Unterschiede erklärt werden), und das Gehirn des Kindes beginnt, den Typ des Tieres nach einer gewissen kritischen Anzahl von Bildern zum Vergleich zu erkennen (schätzungsweise handelt es sich um etwa hundert bis zweihundert Ansichten während der frühen Kindheit). Die DL-Algorithmen sind noch nicht so perfekt: Damit ein neuronales Netzwerk ebenfalls erfolgreich bei der Bilderkennung arbeiten kann, müssen Millionen von Bildern auf einer GPU bereitgestellt und verarbeitet werden.
Zusammenfassung des Vorworts: Auf Basis von GPUs können HPC-Anwendungen im Bereich Big Data, ML und DL erstellt werden, jedoch gibt es ein Problem – die Datensätze sind so groß, dass die Zeit, die benötigt wird, um Daten aus dem Speicher in die GPU zu laden, die Gesamtleistung der Anwendung zu reduzieren beginnt. Mit anderen Worten, schnelle Grafikkarten bleiben aufgrund langsamer Datenübertragung von anderen Subsystemen unterausgelastet. Der Geschwindigkeitsunterschied bei der Ein-/Ausgabe zwischen GPU und Bus zu CPU/Speicher kann um Größenordnungen variieren.
Wie funktioniert die Technologie GPUDirect Storage?
Der Eingabe-/Ausgabeprozess wird vom CPU kontrolliert, ebenso wie der Prozess des Ladens von Daten aus dem Speicher in die Grafikkarten zur weiteren Verarbeitung. Daher entstand die Nachfrage nach einer Technologie, die einen direkten Zugang zwischen GPUs und NVMe-Laufwerken für eine schnelle Interaktion voneinander ermöglicht. NVIDIA war das erste Unternehmen, das eine solche Technologie entwickelte und sie GPUDirect Storage nannte. Im Grunde handelt es sich um eine Variante der zuvor von ihnen entwickelten GPUDirect RDMA (Remote Direct Memory Address) Technologie.
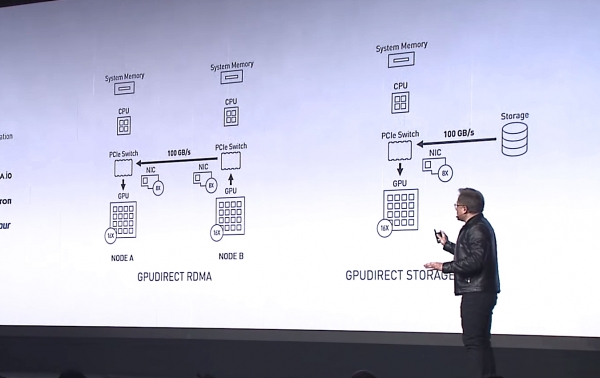
Jensen Huang, CEO von NVIDIA, präsentiert GPUDirect Storage als eine Variante von GPUDirect RDMA auf der Messe SC-19. Quelle: NVIDIA
Der Unterschied zwischen GPUDirect RDMA und GPUDirect Storage liegt in den Geräten, zwischen denen die Adressierung erfolgt. Die GPUDirect RDMA-Technologie ist darauf ausgelegt, Daten direkt zwischen der Eingangsnetzwerkkarte (NIC) und dem GPU-Speicher zu verschieben, während GPUDirect Storage einen direkten Datenübertragungsweg zwischen lokalem oder entferntem Speicher, wie NVMe oder NVMe über Fabric (NVMe-oF), und dem GPU-Speicher bereitstellt.
Beide Optionen, GPUDirect RDMA und GPUDirect Storage, vermeiden unnötige Datenbewegungen über den CPU-Speicherpuffer und ermöglichen es dem Direct Memory Access (DMA) Mechanismus, Daten sofort von der Netzwerkkarte oder dem Speicher direkt in den GPU-Speicher zu verschieben oder von dort zu lesen — und das alles ohne Belastung des zentralen Prozessors. Bei GPUDirect Storage spielt der Speicherort keine Rolle: er kann sich auf einer NVME-Festplatte innerhalb einer GPU-Einheit, innerhalb eines Racks oder über das Netzwerk als NVMe-oF anschließen.
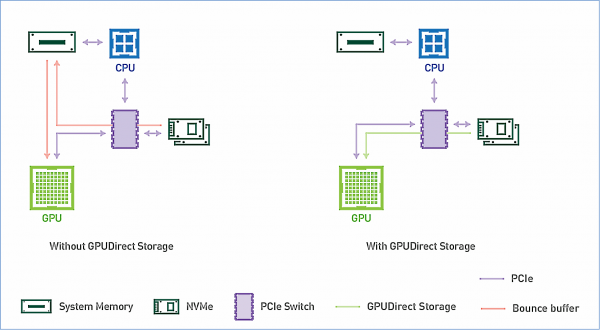
Funktionsschema von GPUDirect Storage. Quelle: NVIDIA
High-End-Speichersysteme auf NVMe sind auf dem Markt für HPC-Anwendungen gefragt.
Mit dem Aufkommen von GPUDirect Storage wird das Interesse großer Kunden auf Speichersysteme gelenkt, die eine I/O-Geschwindigkeit bieten, die der Bandbreite von GPUs entspricht. Auf der SC-19 hat Kingston eine Demo eines Systems präsentiert, das aus einem NVMe-basierten Speicher und einer GPU-Einheit bestand, in der tausende von Satellitenbildern pro Sekunde analysiert wurden. Über einen solchen Speicher mit 10 DC1000M U.2 NVMe-Laufwerken haben wir bereits berichtet. .

Der Speicher mit 10 DC1000M U.2 NVMe-Laufwerken ergänzt den Server mit Grafikbeschleunigern hervorragend. Quelle: Kingston.
Dieser Speicher wird als 1U-Rack-Einheit oder größer ausgeführt und kann je nach Anzahl der DC1000M U.2 NVMe-Laufwerke, die jeweils eine Kapazität von 3.84-7.68 TB bieten, skaliert werden. Der DC1000M ist das erste NVMe SSD-Modell im U.2-Formfaktor in der Kingston-Reihe von Datacenter-Laufwerken. Er bietet eine Haltbarkeitsbewertung (DWPD, Drive Writes Per Day), die es ermöglicht, die Daten einmal täglich auf der vollen Kapazität während der garantierten Lebensdauer des Laufwerks zu überschreiben.
Im Test fio v3.13 auf dem Betriebssystem Ubuntu 18.04.3 LTS zeigte der Linux-Kernel 5.0.0-31-generic, dass das Ausstellungsmodell des Speicher-Arrays eine Leseleistung (Sustained Read) von 5,8 Millionen IOPS bei einer konstanten Bandbreite (Sustained Bandwidth) von 23,8 Gbit/s erreichte.
Ariel Pérez, Geschäftsleiter für SSD bei Kingston, charakterisierte die neuen Speicher-Arrays folgendermaßen: „Wir sind bereit, die nächste Generation von Servern mit SSD-Lösungen U.2 NVMe zu versorgen, um viele der Übertragungsengpässe zu beseitigen, die traditionell mit Speichersystemen verbunden sind. Die Kombination aus NVMe SSDs und unserem Premium Server Premier DRAM macht Kingston zu einem der umfassendsten Anbieter von integrierten Datenverarbeitungslösungen in der Branche.“
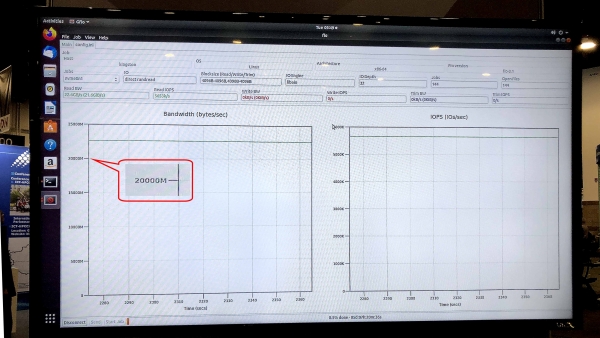
Der Test gfio v3.13 zeigte eine Bandbreite von 23,8 Gbit/s für das Demomodel des Speicher-Arrays mit DC1000M U.2 NVMe-Laufwerken. Quelle: Kingston
Wie sieht ein typisches System für HPC-Anwendungen aus, in dem die Technologie GPUDirect Storage oder eine ähnliche implementiert ist? Es handelt sich um eine Architektur mit physischer Trennung funktionaler Blöcke innerhalb eines Racks: ein oder zwei Einheiten für den Arbeitsspeicher, mehrere für die GPU- und CPU-Berechnungs-Knoten und eine oder mehrere Einheiten für das Speicher-Array.
Mit der Ankündigung von GPUDirect Storage und der möglichen Einführung ähnlicher Technologien bei anderen GPU-Anbietern wächst die Nachfrage nach Speichersystemen von Kingston, die für den Einsatz in Hochleistungsrechnungen ausgelegt sind. Ein Marker wird die Lesegeschwindigkeit von Daten aus Speichersystemen sein, die mit der Bandbreite von 40 oder 100 Gbit/s Netzwerkkarten am Eingang zu Einheiten mit GPU vergleichbar ist. Auf diese Weise werden ultraschnelle Speichersysteme, einschließlich externer NVMe über Fabriken, von einer exotischen Nische zum Mainstream für HPC-Anwendungen. Neben Wissenschaft und finanziellen Berechnungen werden sie auch in vielen anderen praktischen Bereichen Anwendung finden, wie beispielsweise in Sicherheitslösungen für Megastädte (Safe City) oder in Verkehrszentren, wo eine Erkennungs- und Identifikationsgeschwindigkeit auf dem Niveau von Millionen von HD-Bildern pro Sekunde erforderlich ist,” — so wird die Marktnische der Spitzen-Speichersysteme umschrieben.
Weitere Informationen zu den Produkten von Kingston finden Sie auf das Unternehmen.
Quelle: habr.com
