


Hallo Habr-Leser! Im letzten Artikel haben wir über ein einfaches Mittel zur Notfallwiederherstellung in AERODISK ENGINE-Speichersystemen gesprochen – die Replikation. In diesem Artikel befassen wir uns mit einem komplexeren und interessanteren Thema – einem Metrocluster, also einem automatisierten Katastrophenschutztool für zwei Rechenzentren, das es Rechenzentren ermöglicht, im Aktiv-Aktiv-Modus zu arbeiten. Wir werden erzählen, zeigen, brechen und reparieren.
Wie üblich am Anfang der Theorie
Ein Metrocluster ist ein Cluster, der über mehrere Standorte innerhalb einer Stadt oder eines Bezirks verteilt ist. Das Wort „Cluster“ weist für uns deutlich darauf hin, dass der Komplex automatisiert ist, das heißt, die Umschaltung der Clusterknoten bei Ausfällen (Failover) erfolgt automatisch.
Hier liegt der Hauptunterschied zwischen einem Metrocluster und einer regulären Replikation. Automatisierung von Abläufen. Das heißt, im Falle bestimmter Vorfälle (Ausfall des Rechenzentrums, Kanalunterbrechung usw.) führt das Speichersystem selbstständig die notwendigen Maßnahmen durch, um die Datenverfügbarkeit aufrechtzuerhalten. Bei Verwendung regulärer Replikate werden diese Aktionen ganz oder teilweise manuell vom Administrator durchgeführt.
Was macht er?
Das Hauptziel, das Kunden mit bestimmten Metrocluster-Implementierungen verfolgen, ist die Minimierung des RTO (Recovery Time Objective). Das heißt, die Wiederherstellungszeit von IT-Diensten nach einem Ausfall zu minimieren. Wenn Sie die herkömmliche Replikation verwenden, ist die Wiederherstellungszeit immer länger als die Wiederherstellungszeit mit einem Metro-Cluster. Warum? Sehr einfach. Der Administrator muss am Arbeitsplatz sein und die Replikation manuell umstellen, während der Metro-Cluster dies automatisch erledigt.
Wenn Sie keinen engagierten Administrator haben, der nicht schläft, nicht isst, nicht raucht oder krank wird, sondern 24 Stunden am Tag den Zustand des Speichersystems überwacht, kann nicht garantiert werden, dass der Administrator bei einem Ausfall für manuelles Umschalten zur Verfügung steht.
Dementsprechend entspricht die RTO in Abwesenheit eines Metro-Clusters oder eines unsterblichen Administrators der 99. Ebene des Dienstdienstes der Administratoren der Summe der Umschaltzeit aller Systeme und der maximalen Zeitspanne, nach der der Administrator garantiert mit der Arbeit mit dem Speichersystem und zugehörigen Systemen beginnen kann.
Daher kommen wir zu der offensichtlichen Schlussfolgerung, dass der Metrocluster verwendet werden sollte, wenn die RTO-Anforderung Minuten und nicht Stunden oder Tage beträgt. Das heißt, wenn die IT-Abteilung im Falle des schlimmsten Ausfalls im Rechenzentrum dem Unternehmen Zeit geben muss, den Zugriff auf IT-Dienste innerhalb von Minuten oder sogar Sekunden wiederherzustellen.
Wie funktioniert es?
Auf der unteren Ebene verwendet der Metrocluster den synchronen Datenreplikationsmechanismus, den wir im vorherigen Artikel beschrieben haben (siehe unten). ). Da die Replikation synchron ist, sind die Anforderungen dafür angemessen, oder besser gesagt:
- Glasfaser als Physik, 10-Gigabit-Ethernet (oder höher);
- die Entfernung zwischen Rechenzentren beträgt nicht mehr als 40 Kilometer;
- optische Kanalverzögerung zwischen Rechenzentren (zwischen Speichersystemen) bis zu 5 Millisekunden (optimal 2).
Alle diese Anforderungen haben beratenden Charakter, das heißt, der Metro-Cluster funktioniert auch dann, wenn diese Anforderungen nicht erfüllt sind. Es muss jedoch klar sein, dass die Folgen der Nichteinhaltung dieser Anforderungen einer Verlangsamung des Betriebs beider Speichersysteme im Metro-Cluster gleichkommen.
Ein synchrones Replikat wird also zum Übertragen von Daten zwischen Speichersystemen verwendet. Aber wie wechseln Replikate automatisch und, was am wichtigsten ist, wie kann ein Split-Brain vermieden werden? Dazu wird auf der darüber liegenden Ebene eine zusätzliche Instanz eingesetzt – der Schiedsrichter.
Wie arbeitet ein Schiedsrichter und was ist seine Aufgabe?
Der Arbitrator ist eine kleine virtuelle Maschine oder ein Hardware-Cluster, der an einem dritten Standort (z. B. in einem Büro) gestartet werden muss und über ICMP und SSH Zugriff auf den Speicher bietet. Nach dem Start sollte der Arbiter die IP festlegen und dann seine Adresse von der Speicherseite sowie die Adressen der Remote-Controller angeben, die am Metro-Cluster teilnehmen. Danach ist der Schiedsrichter startklar.
Der Schiedsrichter überwacht ständig alle Speichersysteme im Metro-Cluster und beschließt, für den Fall, dass ein bestimmtes Speichersystem nicht verfügbar ist, nach Bestätigung der Nichtverfügbarkeit durch ein anderes Cluster-Mitglied (eines der „Live“-Speichersysteme) das Verfahren zum Wechseln der Replikationsregeln und Zuordnung zu starten.
Ein sehr wichtiger Punkt. Der Arbiter muss sich immer an einem anderen Standort befinden als dem, an dem sich die Speichersysteme befinden, also weder in DPC 1, wo sich Speicher 1 befindet, noch in DPC 2, wo Speicher 2 installiert ist.
Warum? Denn nur so kann der Schiedsrichter mit Hilfe eines der überlebenden Speichersysteme den Untergang eines der beiden Standorte, an denen die Speichersysteme installiert sind, eindeutig und genau bestimmen. Jede andere Art und Weise, einen Schiedsrichter einzusetzen, kann zu einer Spaltung des Gehirns führen.
Lassen Sie uns nun näher auf die Arbeit des Schiedsrichters eingehen.
Auf dem Arbiter laufen mehrere Dienste, die ständig alle Speichercontroller abfragen. Wenn das Ergebnis der Umfrage vom vorherigen abweicht (verfügbar/nicht verfügbar), wird es in eine kleine Datenbank geschrieben, die auch auf dem Arbiter funktioniert.
Betrachten Sie die Logik des Schiedsrichters genauer.
Schritt 1. Feststellung der Nichtverfügbarkeit. Ein Ereignis, das einen Speichersystemausfall signalisiert, ist das Ausbleiben eines Pings von beiden Controllern desselben Speichersystems für 5 Sekunden.
Schritt 2. Starten des Umschaltvorgangs. Nachdem der Schiedsrichter festgestellt hat, dass eines der Speichersysteme nicht verfügbar ist, sendet er eine Anfrage an das „lebende“ Speichersystem, um sicherzustellen, dass das „tote“ Speichersystem wirklich tot ist.
Nach Erhalt eines solchen Befehls vom Schlichter prüft das zweite (lebende) Speichersystem zusätzlich die Verfügbarkeit des gefallenen ersten Speichersystems und sendet, falls nicht, eine Bestätigung seiner Vermutung an den Schlichter. SHD ist tatsächlich nicht verfügbar.
Nach Erhalt einer solchen Bestätigung startet der Schiedsrichter einen Remote-Vorgang zum Umschalten der Replikation und zum Erhöhen der Zuordnung auf den Replikaten, die auf dem ausgefallenen Speichersystem aktiv (primär) waren, und sendet einen Befehl an das zweite Speichersystem, um diese Replikate von sekundär auf primär umzustellen und die Zuordnung zu erhöhen. Nun, das zweite Speichersystem führt diese Vorgänge jeweils durch und stellt anschließend den Zugriff auf die verlorenen LUNs selbst bereit.
Warum ist eine zusätzliche Verifizierung erforderlich? Für das Quorum. Das heißt, die Mehrheit der gesamten ungeraden (3) Anzahl an Clustermitgliedern muss den Ausfall eines der Clusterknoten bestätigen. Nur dann wird diese Entscheidung genau richtig sein. Dies ist notwendig, um Fehlschaltungen und damit Split-Brain zu vermeiden.
Schritt 2 dauert etwa 5 bis 10 Sekunden. Unter Berücksichtigung der zur Feststellung der Nichtverfügbarkeit erforderlichen Zeit (5 Sekunden) sind LUNs mit einem ausgefallenen Speichersystem innerhalb von 10 bis 15 Sekunden nach dem Ausfall automatisch für die Arbeit mit Live-Speicher verfügbar.
Es ist klar, dass Sie zur Vermeidung von Verbindungsabbrüchen mit Hosts auch auf die korrekte Einstellung von Timeouts auf den Hosts achten müssen. Das empfohlene Timeout beträgt mindestens 30 Sekunden. Dadurch wird verhindert, dass der Host während einer Failover-Last die Verbindung zum Speicher abbricht, und es kann sichergestellt werden, dass es zu keiner E/A-Unterbrechung kommt.
Moment mal, es stellt sich heraus: Wenn mit dem Metro-Cluster alles in Ordnung ist, warum brauchen wir dann überhaupt eine regelmäßige Replikation?
Tatsächlich ist nicht alles so einfach.
Berücksichtigen Sie die Vor- und Nachteile des Metroclusters
Wir haben also erkannt, dass die offensichtlichen Vorteile des Metroclusters im Vergleich zur herkömmlichen Replikation folgende sind:
- Vollständige Automatisierung, die im Katastrophenfall eine minimale Wiederherstellungszeit gewährleistet;
- Und alle :-).
Und nun Achtung, Nachteile:
- Lösungskosten. Obwohl für den Metrocluster in Aerodisk-Systemen keine zusätzliche Lizenzierung erforderlich ist (es wird die gleiche Lizenz wie für das Replikat verwendet), sind die Kosten der Lösung immer noch höher als bei der Verwendung der synchronen Replikation. Sie müssen alle Anforderungen für eine synchrone Replik sowie die Anforderungen für den Metro-Cluster im Zusammenhang mit zusätzlichem Switching und zusätzlichem Standort implementieren (siehe Metro-Cluster-Planung);
- Die Komplexität der Entscheidung. Ein Metrocluster ist viel komplexer als eine normale Replik und erfordert viel mehr Aufmerksamkeit und Aufwand bei der Planung, Konfiguration und Dokumentation.
Zusammenfassend. Metrocluster ist sicherlich eine sehr technologische und gute Lösung, wenn Sie RTO wirklich in Sekunden oder Minuten bereitstellen müssen. Aber wenn es keine solche Aufgabe gibt und RTO in Stunden für das Geschäft in Ordnung ist, dann macht es keinen Sinn, Spatzen aus einer Kanone zu schießen. Die übliche Arbeiter-Bauern-Replikation reicht aus, da der Metro-Cluster zusätzliche Kosten und Komplikationen in der IT-Infrastruktur verursachen wird.
Metro-Cluster-Planung
Dieser Abschnitt erhebt nicht den Anspruch, ein umfassendes Tutorial zum Design von Metro-Clustern zu sein, sondern zeigt lediglich die Hauptrichtungen auf, die ausgearbeitet werden sollten, wenn Sie sich für den Aufbau eines solchen Systems entscheiden. Daher sollten Sie bei der eigentlichen Implementierung des Metro-Clusters unbedingt den Hersteller des Speichersystems (also uns) und anderer verwandter Systeme zur Beratung einbeziehen.
Veranstaltungsorte
Wie oben erwähnt, erfordert ein Metro-Cluster mindestens drei Standorte. Zwei Rechenzentren, in denen Speichersysteme und zugehörige Systeme funktionieren, sowie ein dritter Standort, an dem der Schiedsrichter arbeiten wird.
Der empfohlene Abstand zwischen Rechenzentren beträgt nicht mehr als 40 Kilometer. Eine größere Entfernung führt mit hoher Wahrscheinlichkeit zu zusätzlichen Verzögerungen, die im Falle eines Metro-Clusters höchst unerwünscht sind. Denken Sie daran, dass Verzögerungen bis zu 5 Millisekunden betragen sollten, obwohl es wünschenswert ist, innerhalb von 2 zu bleiben.
Es wird außerdem empfohlen, Verzögerungen bereits im Planungsprozess zu prüfen. Jeder mehr oder weniger erwachsene Anbieter, der Glasfaser zwischen Rechenzentren bereitstellt, kann ziemlich schnell eine Qualitätsprüfung veranlassen.
Was die Verzögerungen beim Schiedsrichter (also zwischen dem dritten Standort und den ersten beiden) angeht, liegt der empfohlene Verzögerungsschwellenwert bei bis zu 200 Millisekunden, d. h. eine normale Unternehmens-VPN-Verbindung über das Internet reicht aus.
Switching und Netzwerk
Im Gegensatz zum Replikationsschema, bei dem es ausreicht, Speichersysteme von verschiedenen Standorten zu verbinden, erfordert das Metro-Cluster-Schema die Verbindung von Hosts mit beiden Speichersystemen an verschiedenen Standorten. Um den Unterschied deutlicher zu machen, werden im Folgenden beide Schemata aufgeführt.
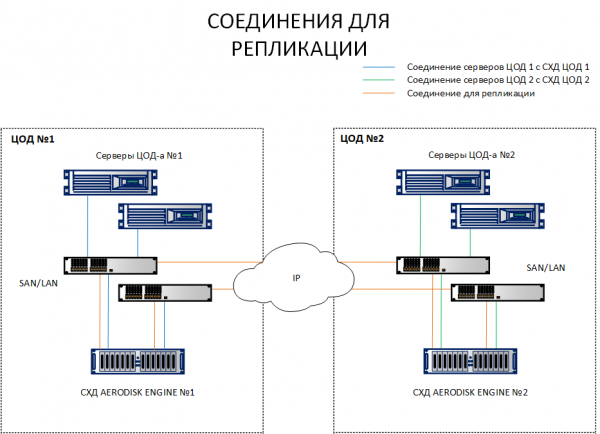
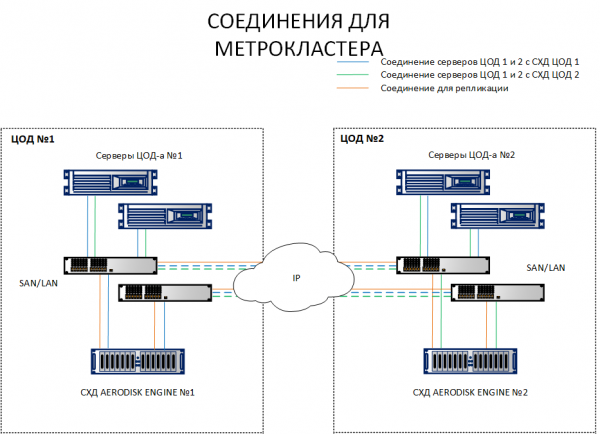
Wie Sie dem Diagramm entnehmen können, haben wir Hosts von Standort 1, die sowohl Speicher 1 als auch Speicher 2 betrachten. Im Gegensatz dazu betrachten Hosts von Standort 2 sowohl Speicher 2 als auch Speicher 1. Das heißt, jeder Host sieht beide Speichersysteme. Dies ist Voraussetzung für den Betrieb des Metroclusters.
Natürlich ist es nicht nötig, jeden Host mit einem optischen Kabel zu einem anderen Rechenzentrum zu ziehen, da dann nicht genügend Ports und Kabel vorhanden sind. Alle diese Verbindungen müssen über Ethernet 10G+- oder FibreChannel 8G+-Switches hergestellt werden (FC nur zum Anschließen von Hosts und Speicher für IO, der Replikationskanal ist derzeit nur über IP verfügbar (Ethernet 10G+).
Nun ein paar Worte zur Netzwerktopologie. Ein wichtiger Punkt ist die richtige Konfiguration von Subnetzen. Sie müssen sofort mehrere Subnetze für die folgenden Verkehrstypen definieren:
- Subnetz für die Replikation, über das Daten zwischen Speichersystemen synchronisiert werden. Es kann mehrere davon geben, in diesem Fall spielt es keine Rolle, es hängt alles von der aktuellen (bereits implementierten) Netzwerktopologie ab. Wenn es zwei davon gibt, muss natürlich das Routing zwischen ihnen konfiguriert werden;
- Speichersubnetze, über die Hosts auf Speicherressourcen zugreifen (wenn es sich um iSCSI handelt). In jedem Rechenzentrum sollte es ein solches Subnetz geben;
- Steuersubnetze, also drei routbare Subnetze an drei Standorten, von denen aus der Speicher verwaltet wird, und dort befindet sich auch der Arbiter.
Subnetze für den Zugriff auf Host-Ressourcen betrachten wir hier nicht, da sie stark von Aufgaben abhängig sind.
Die Trennung des unterschiedlichen Datenverkehrs über verschiedene Subnetze ist äußerst wichtig (es ist besonders wichtig, das Replikat von der E/A zu trennen), denn wenn Sie den gesamten Datenverkehr in einem „dicken“ Subnetz mischen, ist dieser Datenverkehr nicht zu verwalten, und unter den Bedingungen von zwei Rechenzentren kann dies immer noch zu Netzwerkkollisionen verschiedener Art führen. Wir werden im Rahmen dieses Artikels nicht näher auf dieses Thema eingehen, da Sie die Planung eines zwischen Rechenzentren ausgedehnten Netzwerks auf den Ressourcen von Netzwerkgeräteherstellern nachlesen können, wo dies ausführlich beschrieben wird.
Schiedsrichterkonfiguration
Der Arbitrator muss über ICMP- und SSH-Protokolle Zugriff auf alle Steuerschnittstellen des Speichersystems ermöglichen. Sie sollten auch über die Fehlertoleranz des Schiedsrichters nachdenken. Hier gibt es eine Nuance.
Ein Arbiter-Failover ist äußerst wünschenswert, aber nicht erforderlich. Und was passiert, wenn der Schiedsrichter zum falschen Zeitpunkt abstürzt?
- Der Betrieb des Metroclusters im Normalmodus ändert sich nicht, weil arbtir hat keinerlei Einfluss auf den Betrieb des Metroclusters im Normalmodus (seine Aufgabe besteht darin, die Last rechtzeitig zwischen Rechenzentren umzuschalten).
- Wenn gleichzeitig der Schiedsrichter aus dem einen oder anderen Grund fällt und den Unfall im Rechenzentrum „schläft“, findet keine Umschaltung statt, da niemand da ist, der die notwendigen Umschaltungsbefehle erteilt und ein Quorum organisiert. In diesem Fall wird der Metro-Cluster zu einem regulären Replikationsschema, das im Katastrophenfall manuell umgeschaltet werden muss, was sich auf die RTO auswirkt.
Was folgt daraus? Wenn Sie wirklich eine minimale RTO bereitstellen müssen, müssen Sie die Fehlertoleranz des Arbiters sicherstellen. Hierfür gibt es zwei Möglichkeiten:
- Führen Sie eine virtuelle Maschine mit einem Arbiter auf einem fehlertoleranten Hypervisor aus, da alle erwachsenen Hypervisoren Fehlertoleranz unterstützen.
- Wenn es am dritten Standort (in einem bedingten Büro) zu faul ist, einen normalen Cluster zu installieren, und kein Hypervisor-Cluster vorhanden ist, haben wir eine Hardwareversion des Arbiters bereitgestellt, die in einer 2U-Box hergestellt wird, in der zwei normale x-86-Server arbeiten und die einen lokalen Ausfall überstehen kann.
Wir empfehlen Ihnen dringend, die Fehlertoleranz des Arbiters sicherzustellen, auch wenn der Metro-Cluster diese im Normalmodus nicht benötigt. Aber wie Theorie und Praxis zeigen, ist es besser, auf Nummer sicher zu gehen, wenn man eine wirklich zuverlässige, katastrophentolerante Infrastruktur aufbaut. Es ist besser, sich und Ihr Unternehmen vor dem „Gesetz der Gemeinheit“ zu schützen, also vor dem Versagen sowohl des Schiedsrichters als auch eines der Standorte, an denen sich das Speichersystem befindet.
Lösungsarchitektur
Unter Berücksichtigung der oben genannten Anforderungen erhalten wir die folgende allgemeine Lösungsarchitektur.
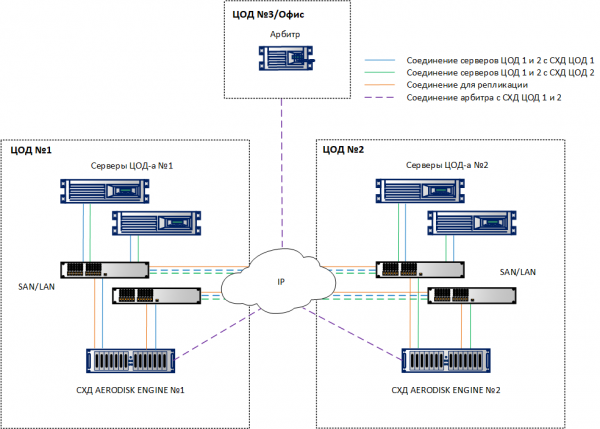
LUNs sollten gleichmäßig auf die beiden Standorte verteilt werden, um eine starke Überlastung zu vermeiden. Gleichzeitig ist es bei der Dimensionierung in beiden Rechenzentren erforderlich, nicht nur das doppelte Volumen (das zur gleichzeitigen Speicherung von Daten auf zwei Speichersystemen erforderlich ist), sondern auch die doppelte Leistung in IOPS und MB/s bereitzustellen, um eine Verschlechterung der Anwendungen im Falle eines Ausfalls eines der Rechenzentren zu verhindern.
Unabhängig davon stellen wir fest, dass es bei einem ordnungsgemäßen Ansatz zur Dimensionierung (d. h. unter der Voraussetzung, dass wir die richtigen Obergrenzen für IOPS und MB/s sowie die erforderlichen CPU- und RAM-Ressourcen vorgesehen haben) bei einem Ausfall eines der Speichersysteme im Metro-Cluster zu keinem ernsthaften Leistungsabfall bei temporären Arbeitsbedingungen auf einem Speichersystem kommt.
Dies erklärt sich aus der Tatsache, dass die Ausführung der synchronen Replikation unter Bedingungen, an denen zwei Standorte gleichzeitig arbeiten, die Hälfte der Schreibleistung „frisst“, da jede Transaktion auf zwei Speichersysteme geschrieben werden muss (ähnlich wie bei RAID-1/10). Wenn also eines der Speichersysteme ausfällt, verschwindet der Effekt der Replikation vorübergehend (bis das ausgefallene Speichersystem wieder hochgefahren wird) und wir erhalten eine Verdoppelung der Schreibleistung. Nachdem die LUNs des ausgefallenen Speichersystems auf dem funktionierenden Speichersystem neu gestartet wurden, verschwindet dieser zweifache Anstieg aufgrund der Tatsache, dass die LUNs eines anderen Speichersystems belastet werden, und wir kehren zu demselben Leistungsniveau zurück, das wir vor dem „Absturz“ hatten, jedoch nur innerhalb desselben Standorts.
Mit Hilfe einer kompetenten Dimensionierung ist es möglich, Bedingungen zu schaffen, unter denen der Anwender den Ausfall des gesamten Speichersystems überhaupt nicht spürt. Aber auch hier ist eine sehr sorgfältige Größenbestimmung erforderlich, die Sie übrigens kostenlos bei uns erfragen können :-).
Aufbau eines Metro-Clusters
Das Einrichten eines Metro-Clusters ähnelt sehr dem Einrichten der regulären Replikation, die wir in beschrieben haben . Konzentrieren wir uns also einfach auf die Unterschiede. Wir haben im Labor einen Stand aufgebaut, der auf der oben genannten Architektur basiert, nur in der Minimalversion: zwei Speichersysteme, die über 10G-Ethernet miteinander verbunden sind, zwei 10G-Switches und ein Host, der über die Switches auf beide Speichersysteme mit 10G-Ports schaut. Der Schiedsrichter läuft auf einer virtuellen Maschine.
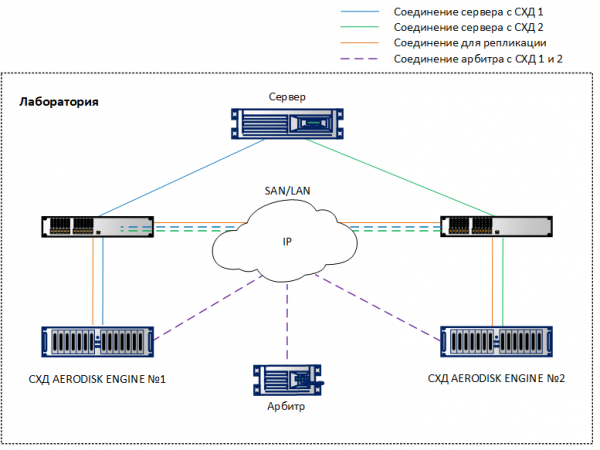
Wenn Sie virtuelle IP (VIP) für ein Replikat konfigurieren, sollten Sie den VIP-Typ auswählen – für einen Metro-Cluster.
Erstellte zwei Replikationslinks für zwei LUNs und verteilte sie auf zwei Speichersysteme: LUN TEST Primary auf Speicher1 (METRO-Verbindung), LUN TEST2 Primary für Speicher2 (METRO2-Verbindung).
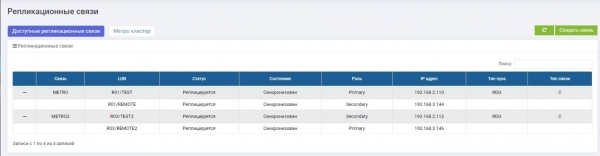
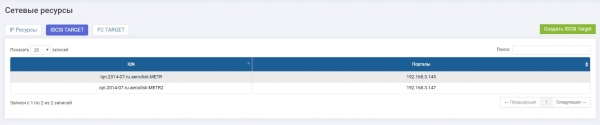
Für sie haben wir zwei identische Ziele konfiguriert (in unserem Fall iSCSI, aber FC wird auch unterstützt, die Konfigurationslogik ist dieselbe).
Speicher1:

Speicher2:
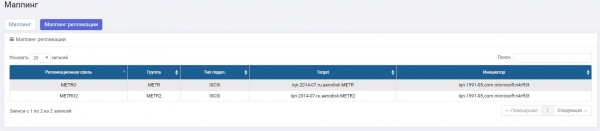
Für Replikationslinks wurden Zuordnungen auf jedem Speichersystem vorgenommen.
Speicher1:
Speicher2:
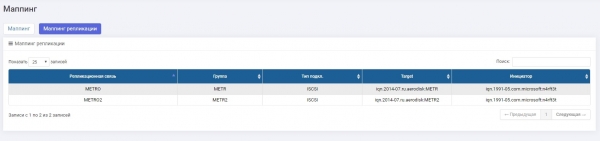
Wir haben Multipath eingerichtet und dem Host präsentiert.
Einrichtung eines Schiedsrichters
Mit dem Arbiter selbst müssen Sie nichts Besonderes tun, Sie müssen ihn lediglich auf der dritten Site einschalten, seine IP festlegen und den Zugriff darauf über ICMP und SSH konfigurieren. Die Konfiguration selbst erfolgt über die Speichersysteme selbst. Gleichzeitig reicht es aus, den Arbiter einmal auf einem der Speichercontroller im Metro-Cluster zu konfigurieren. Diese Einstellungen werden automatisch an alle Controller verteilt.
Unter Remote-Replikation >> Metrocluster (auf jedem Controller) >> Schaltfläche Konfigurieren.
Wir geben die IP des Arbiters sowie die Steuerschnittstellen der beiden Remote-Storage-Controller ein.
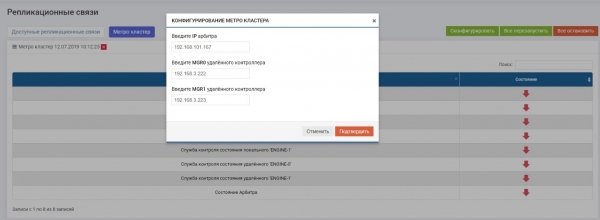
Danach müssen Sie alle Dienste aktivieren (Schaltfläche „Alles neu starten“). Wenn Sie in Zukunft eine Neukonfiguration durchführen, müssen die Dienste neu gestartet werden, damit die Einstellungen wirksam werden.
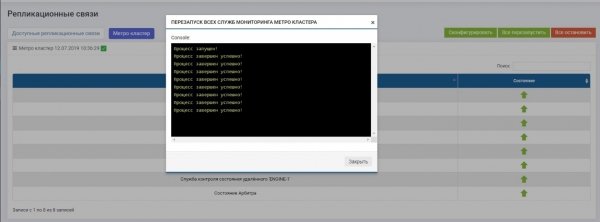
Wir prüfen, ob alle Dienste ausgeführt werden.
Damit ist die Metrocluster-Einrichtung abgeschlossen.
Crashtest
Der Crashtest wird in unserem Fall recht einfach und schnell sein, da die Replikationsfunktionalität (Switching, Konsistenz usw.) berücksichtigt wurde . Um die Zuverlässigkeit des Metro-Clusters zu testen, reicht es daher aus, die Automatisierung der Unfallerkennung, des Umschaltens und das Fehlen von Schreibverlusten (I/O-Stopps) zu überprüfen.
Dazu emulieren wir einen Komplettausfall eines der Speichersysteme, indem wir beide Controller physisch ausschalten, nachdem wir mit dem Kopieren einer großen Datei auf eine LUN begonnen haben, die auf einem anderen Speichersystem aktiviert werden soll.
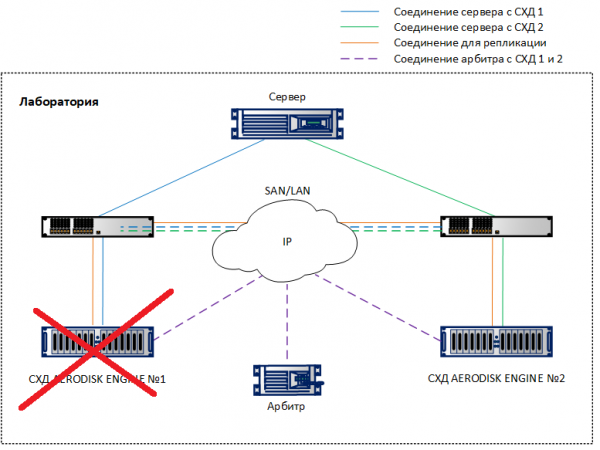
Deaktivieren Sie ein Speichersystem. Auf dem zweiten Speichersystem sehen wir in den Protokollen Warnungen und Meldungen, dass die Verbindung zum Nachbarsystem verschwunden ist. Wenn Benachrichtigungen per SMTP- oder SNMP-Überwachung konfiguriert sind, werden die entsprechenden Benachrichtigungen an den Administrator gesendet.
Genau 10 Sekunden später (in beiden Screenshots zu sehen) wurde der METRO-Replikationslink (derjenige, der auf dem ausgefallenen Speichersystem primär war) automatisch zum primären Link auf dem funktionierenden Speichersystem. Unter Verwendung der vorhandenen Zuordnung blieb LUN TEST für den Host verfügbar, die Aufzeichnung sank etwas (innerhalb der versprochenen 10 Prozent), wurde jedoch nicht gestoppt.

Der Test wurde erfolgreich abgeschlossen.
Zusammenfassung
Die aktuelle Implementierung des Metroclusters in den Speichersystemen der AERODISK Engine N-Serie ermöglicht es Ihnen, Probleme vollständig zu lösen, bei denen Sie Ausfallzeiten von IT-Diensten beseitigen oder minimieren und deren Betrieb im 24/7/365-Modus mit minimalen Arbeitskosten sicherstellen müssen.
Man kann natürlich sagen, dass das alles Theorie ist, ideale Laborbedingungen usw. ... ABER wir haben eine Reihe umgesetzter Projekte, in denen wir die Disaster-Recovery-Funktionalität implementiert haben und die Systeme funktionieren perfekt. Einer unserer recht bekannten Kunden, bei dem nur zwei Speichersysteme in einer katastrophentoleranten Konfiguration zum Einsatz kommen, hat bereits zugestimmt, Informationen über das Projekt zu veröffentlichen, daher werden wir im nächsten Teil über die Kampfimplementierung sprechen.
Vielen Dank, ich freue mich auf eine produktive Diskussion.
Source: habr.com
