


Hallo, Habr! In diesem Artikel möchte ich Ihnen ein bemerkenswertes Werkzeug zur Entwicklung von Batch-Prozessen zur Datenverarbeitung vorstellen, zum Beispiel in der Infrastruktur eines Unternehmens-DWH oder Ihres DataLake. Es geht um Apache Airflow (im Folgenden Airflow). Auf Habr erhält es zu Unrecht wenig Aufmerksamkeit, und im Hauptteil werde ich versuchen, Sie davon zu überzeugen, dass es sich zumindest lohnt, Airflow bei der Auswahl eines Planers für Ihre ETL/ELT-Prozesse in Betracht zu ziehen.
Früher habe ich eine Artikelreihe über DWH geschrieben, als ich bei der Tinkoff Bank gearbeitet habe. Nun bin ich Teil des Teams von Mail.Ru Group und beschäftige mich mit der Entwicklung einer Plattform zur Datenanalyse im Gaming-Bereich. Tatsächlich werden wir, sobald neue Informationen und interessante Lösungen verfügbar sind, hier über unsere Datenanalyse-Plattform berichten.
Prolog
Also, fangen wir an. Was ist Airflow? Es ist eine Bibliothek (oder ) zur Entwicklung, Planung und Überwachung von Arbeitsprozessen. Das Hauptmerkmal von Airflow: zur Beschreibung (Entwicklung) von Prozessen wird Python-Code verwendet. Dies bringt zahlreiche Vorteile für die Organisation Ihres Projekts und die Entwicklung mit sich: Ihr (zum Beispiel) ETL-Projekt ist im Grunde genommen einfach ein Python-Projekt, das Sie nach Ihren Bedürfnissen und unter Berücksichtigung der Infrastruktur, der Teamgröße und anderer Anforderungen organisieren können. In Bezug auf die Werkzeuge ist alles einfach. Verwenden Sie beispielsweise PyCharm + Git. Das ist großartig und sehr praktisch!
Lassen Sie uns nun die grundlegenden Entitäten von Airflow betrachten. Wenn Sie deren Wesen und Zweck verstehen, können Sie die Architektur der Prozesse optimal organisieren. Die vielleicht wichtigste Entität ist das Directed Acyclic Graph (DAG).
DAG
Ein DAG ist eine semantische Zusammenfassung Ihrer Aufgaben, die Sie in einer streng definierten Reihenfolge zu einem bestimmten Zeitplan ausführen möchten. Airflow bietet eine benutzerfreundliche Web-Oberfläche für die Arbeit mit DAGs und anderen Entitäten:
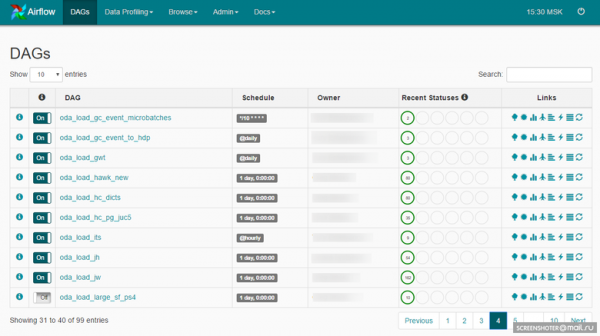
Ein DAG könnte folgendermaßen aussehen:
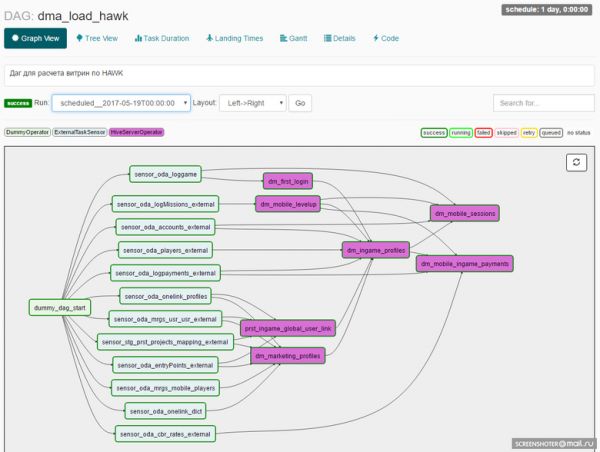
Der Entwickler legt beim Entwerfen des DAGs eine Reihe von Operatoren fest, auf denen die Aufgaben innerhalb des DAGs aufgebaut werden. Hier kommen wir zu einer weiteren wichtigen Entität: der Airflow-Operator.
Operatoren
Ein Operator ist eine Entität, auf deren Grundlage Instanzen von Aufgaben erstellt werden, in denen beschrieben wird, was während der Ausführung einer Aufgabeninstanz passieren wird. enthalten bereits eine Reihe von einsatzbereiten Operatoren. Beispiele:
- BashOperator – ein Operator zur Ausführung von Bash-Befehlen.
- PythonOperator – ein Operator zum Aufruf von Python-Code.
- EmailOperator – ein Operator zum Versenden von E-Mails.
- HTTPOperator – ein Operator zur Bearbeitung von HTTP-Anfragen.
- SqlOperator – ein Operator zur Ausführung von SQL-Code.
- Sensor – ein Operator, der auf ein Ereignis wartet (wie das Eintreten der gewünschten Zeit, das Vorhandensein einer benötigten Datei, einer Datenbankzeile, einer Antwort aus der API usw.).
Es gibt spezifischere Operatoren: DockerOperator, HiveOperator, S3FileTransferOperator, PrestoToMysqlOperator, SlackOperator.
Sie können auch Operatoren entwickeln, die auf Ihren spezifischen Anforderungen basieren, und diese in Ihrem Projekt verwenden. Beispielsweise haben wir MongoDBToHiveViaHdfsTransfer erstellt, einen Operator zum Export von Dokumenten aus MongoDB nach Hive, sowie mehrere Operatoren zur Bearbeitung von : CHLoadFromHiveOperator und CHTableLoaderOperator. Sobald in einem Projekt wiederholt verwendeter Code, der auf grundlegenden Operatoren basiert, entsteht, sollte man darüber nachdenken, ihn in einen neuen Operator zusammenzufassen. Dies vereinfacht die weitere Entwicklung und bereichert Ihre Operatorbibliothek im Projekt.
Im nächsten Schritt müssen all diese Task-Instanzen ausgeführt werden, und nun geht es um den Scheduler.
Scheduler
Der Task-Scheduler in Airflow basiert auf . Celery ist eine Python-Bibliothek, die es ermöglicht, Warteschlangen sowie asynchrone und verteilte Task-Ausführung zu organisieren. In Airflow werden alle Aufgaben in Pools unterteilt. Pools werden manuell erstellt und dienen in der Regel dazu, die Belastung bei der Arbeit mit einer Quelle zu begrenzen oder Aufgaben innerhalb eines DWH zu typisieren. Pools können über die Web-Oberfläche verwaltet werden:
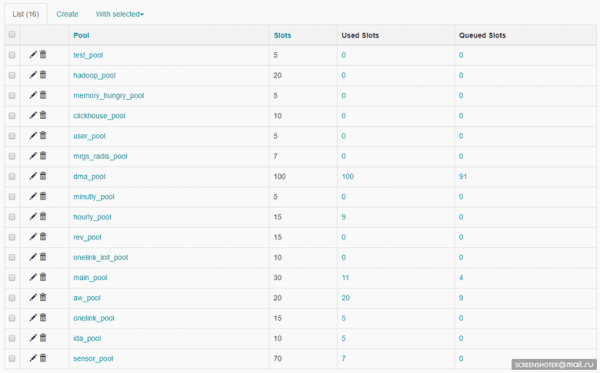
Jeder Pool hat eine Begrenzung der Slotanzahl. Bei der Erstellung von DAGs wird ihm ein Pool zugewiesen:
ALERT_MAILS = Variable.get("gv_mail_admin_dwh")
DAG_NAME = 'dma_load'
OWNER = 'Vasya Pupkin'
DEPENDS_ON_PAST = True
EMAIL_ON_FAILURE = True
EMAIL_ON_RETRY = True
RETRIES = int(Variable.get('gv_dag_retries'))
POOL = 'dma_pool'
PRIORITY_WEIGHT = 10
start_dt = datetime.today() - timedelta(1)
start_dt = datetime(start_dt.year, start_dt.month, start_dt.day)
default_args = {
'owner': OWNER,
'depends_on_past': DEPENDS_ON_PAST,
'start_date': start_dt,
'email': ALERT_MAILS,
'email_on_failure': EMAIL_ON_FAILURE,
'email_on_retry': EMAIL_ON_RETRY,
'retries': RETRIES,
'pool': POOL,
'priority_weight': PRIORITY_WEIGHT
}
dag = DAG(DAG_NAME, default_args=default_args)
dag.doc_md = __doc__Der auf DAG-Ebene festgelegte Pool kann auf Aufgabenebene überschrieben werden.
Für die Planung aller Aufgaben in Airflow ist ein separater Prozess — der Scheduler — verantwortlich. Der Scheduler kümmert sich um die gesamte Mechanik der Aufgabenverwaltung. Bevor eine Aufgabe zur Ausführung kommt, durchläuft sie mehrere Phasen:
- Im DAG sind die vorherigen Aufgaben abgeschlossen; eine neue kann in die Warteschlange gestellt werden.
- Die Warteschlange wird je nach Priorität der Aufgaben sortiert (Prioritäten können ebenfalls verwaltet werden), und wenn im Pool ein freier Slot verfügbar ist, kann die Aufgabe in die Bearbeitung aufgenommen werden.
- Wenn ein freier Celery-Worker vorhanden ist, wird die Aufgabe an ihn weitergeleitet; die Arbeit, die Sie in der Aufgabe programmiert haben, beginnt unter Verwendung des entsprechenden Operators.
Es ist ganz einfach.
Der Scheduler arbeitet mit zahlreichen DAGs und allen Aufgaben innerhalb der DAGs.
Um den Scheduler mit einem DAG zu starten, muss für den DAG ein Zeitplan festgelegt werden:
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='@hourly')Es gibt eine Reihe vordefinierter Presets: @once, @hourly, @daily, @weekly, @monthly, @yearly.
Auch Cron-Ausdrücke können verwendet werden:
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='*/10 * * * *')Ausführungsdatum
Um zu verstehen, wie Airflow funktioniert, ist es wichtig zu wissen, was das Ausführungsdatum für einen DAG bedeutet. In Airflow hat ein DAG eine Dimension des Ausführungsdatums, d. h. je nach Zeitplan des DAGs werden Instanzen von Aufgaben für jedes Ausführungsdatum erstellt. Für jedes Ausführungsdatum können die Aufgaben erneut ausgeführt werden - oder der DAG kann beispielsweise gleichzeitig in mehreren Ausführungsdaten arbeiten. Dies ist hier anschaulich dargestellt:
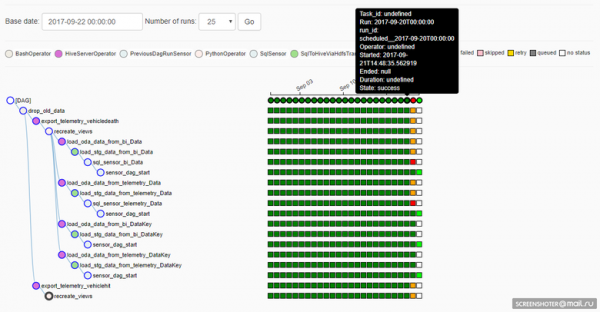
Leider (oder vielleicht auch nicht, das hängt von der Situation ab) wird, wenn die Implementierung der Aufgabe im DAG geändert wird, die Ausführung am vorherigen Ausführungstermin bereits unter Berücksichtigung der Anpassungen erfolgen. Das ist gut, wenn man Daten aus früheren Zeiträumen mit einem neuen Algorithmus neu berechnen muss, aber schlecht, weil die Reproduzierbarkeit des Ergebnisses verloren geht (natürlich steht es jedem frei, die passende Version des Quellcodes aus Git zurückzuholen und das Notwendige einmalig so zu berechnen, wie es benötigt wird).
Aufgabengenerierung
Die Implementierung des DAG erfolgt in Python, weshalb wir einen sehr praktischen Weg haben, um den Codeumfang zu reduzieren, zum Beispiel bei der Arbeit mit sharded Quellen. Angenommen, Sie haben drei MySQL-Shards als Quellen, und müssen auf jeden zugreifen, um bestimmte Daten abzurufen. Dies geschieht unabhängig und parallel. Der Python-Code im DAG könnte so aussehen:
connection_list = lv.get('connection_list')
export_profiles_sql = '''
SELECT
id,
user_id,
nickname,
gender,
{{params.shard_id}} as shard_id
FROM profiles
'''
for conn_id in connection_list:
export_profiles = SqlToHiveViaHdfsTransfer(
task_id='export_profiles_from_' + conn_id,
sql=export_profiles_sql,
hive_table='stg.profiles',
overwrite=False,
tmpdir='/data/tmp',
conn_id=conn_id,
params={'shard_id': conn_id[-1:], },
compress=None,
dag=dag
)
export_profiles.set_upstream(exec_truncate_stg)
export_profiles.set_downstream(load_profiles)Der DAG sieht folgendermaßen aus:
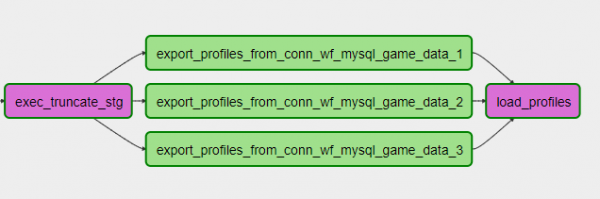
Dabei kann man einen Shard hinzufügen oder entfernen, indem man die Einstellungen einfach anpasst und den DAG aktualisiert. Sehr praktisch!
Es ist auch möglich, komplexere Code-Generierungen zu verwenden, zum Beispiel mit Datenbankquellen zu arbeiten oder die Tabellenstruktur, den Algorithmus zur Verarbeitung der Tabelle zu beschreiben und unter Berücksichtigung der Besonderheiten der DWH-Infrastruktur den Ladeprozess für N Tabellen in Ihr Repository zu generieren. Oder beispielsweise mit einer API zu arbeiten, die keine Liste als Parameter unterstützt; Sie können für diese Liste N Aufgaben im DAG generieren, die Parallelität der API-Anfragen durch einen Pool einschränken und die benötigten Daten aus der API abrufen. Flexibel!
Repository
Airflow verfügt über ein eigenes Backend-Repository, eine Datenbank (entweder MySQL oder Postgres, bei uns ist es Postgres), in der die Zustände von Aufgaben, DAGs, Verbindungseinstellungen, globale Variablen usw. gespeichert werden. Es ist erwähnenswert, dass das Repository in Airflow sehr einfach ist (ca. 20 Tabellen) und benutzerfreundlich, falls Sie einen eigenen Prozess darauf aufbauen möchten. Es erinnert mich an die unzähligen Tabellen im Informatica-Repository, die man lange studieren musste, bevor man verstand, wie man eine Abfrage erstellt.
Überwachung
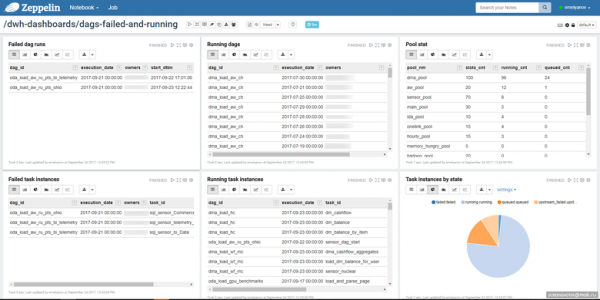
Angesichts der Einfachheit des Repositories können Sie Ihren eigenen Monitoring-Prozess für Aufgaben erstellen. Wir verwenden ein Notizbuch in Zeppelin, um den Status der Aufgaben zu überwachen:
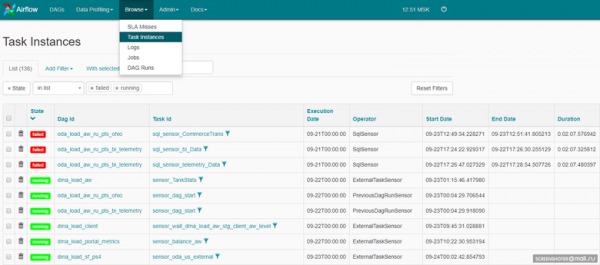
Das kann auch die Weboberfläche von Airflow sein:
Der Code von Airflow ist offen, daher haben wir bei uns eine Benachrichtigung in Telegram hinzugefügt. Jedes laufende Instanz der Aufgabe spamt, wenn ein Fehler auftritt, in eine Telegram-Gruppe, in der das gesamte Entwicklungs- und Support-Team enthalten ist.
Wir erhalten über Telegram eine schnelle Reaktion (falls erforderlich) und durch Zeppelin ein Gesamtbild der Aufgaben in Airflow.
Gesamt
Airflow ist in erster Linie Open Source, und man sollte keine Wunder erwarten. Seien Sie bereit, Zeit und Energie zu investieren, um eine funktionierende Lösung aufzubauen. Das Ziel ist erreichbar; glauben Sie mir, es lohnt sich. Die Geschwindigkeit der Entwicklung, die Flexibilität und die einfache Integration neuer Prozesse werden Ihnen gefallen. Natürlich ist es wichtig, viel Aufmerksamkeit auf die Projektorganisation und die Stabilität von Airflow zu legen: Wunder geschehen nicht.
Aktuell bearbeitet unser Airflow täglich etwa 6.500 Aufgaben. Diese sind sehr vielfältig. Es gibt Aufgaben zum Laden von Daten in das zentrale DWH aus zahlreichen unterschiedlichen und sehr spezifischen Quellen, es gibt Aufgaben zur Berechnung von Dashboards innerhalb des zentralen DWH, Aufgaben zur Veröffentlichung von Daten in ein schnelles DWH und viele, viele verschiedene Aufgaben — und Airflow bewältigt sie Tag für Tag. Wenn man es in Zahlen ausdrückt, sind das 2.300 ELT-Aufgaben unterschiedlicher Komplexität innerhalb des DWH (Hadoop), etwa 250 Datenquellen; es gibt ein Team von vier ETL-Entwicklern, die sich auf die ETL-Datenverarbeitung im DWH und die ELT-Datenverarbeitung innerhalb des DWH aufteilen und natürlich noch einen Administrator, der sich um die Infrastruktur des Dienstes kümmert.
Zukunftspläne
Die Anzahl der Prozesse wächst unweigerlich, und unser Hauptfokus bei der Infrastruktur von Airflow wird auf der Skalierung liegen. Wir möchten ein Airflow-Cluster aufbauen, ein paar Nodes für die Celery-Worker bereitstellen und ein redundantes Head-Node mit Job-Planungsprozessen und einem Repository erstellen.
Epilog
Das ist natürlich nicht alles, was ich über Airflow erzählen möchte, aber ich habe versucht, die wichtigsten Punkte zu beleuchten. Der Appetit kommt beim Essen, versuchen Sie es - es wird Ihnen gefallen 🙂
Quelle: habr.com
