

Hallo, ich bin Dmitrij Logvinenko – Data Engineer in der Analytik-Abteilung der Unternehmensgruppe „Vezet“.
Ich möchte Ihnen ein fantastisches Werkzeug zur Entwicklung von ETL-Prozessen vorstellen – Apache Airflow. Doch Airflow ist so vielseitig und facettenreich, dass es sich auch für Sie lohnt, einen Blick darauf zu werfen, selbst wenn Sie sich nicht mit Datenströmen beschäftigen, sondern gelegentlich Prozesse starten und deren Ausführung überwachen müssen.
Und ja, ich werde nicht nur darüber sprechen, sondern auch zeigen: Es gibt viel Code, Screenshots und Empfehlungen im Programm.
Was gewöhnlich erscheint, wenn man nach dem Wort Airflow googelt / Wikimedia Commons
Inhaltsverzeichnis
Einführung
Apache Airflow – er ist genau wie Django:
- geschrieben in Python,
- mit einem hervorragenden Admin-Panel,
- ohne Einschränkungen erweiterbar,
– aber besser, und er wurde ganz für andere Zwecke entwickelt, nämlich (wie im Vorwort geschrieben):
- Start und Überwachung von Aufgaben auf einer unbegrenzten Anzahl von Maschinen (so viele wie es Celery/Kubernetes und Ihr Gewissen zulassen)
- mit dynamischer Workflow-Generierung aus leicht verständlichem Python-Code
- und der Möglichkeit, beliebige Datenbanken und APIs mit sowohl vorgefertigten Komponenten als auch selbstgebauten Plugins zu verbinden (was äußerst einfach ist).
Wir verwenden Apache Airflow wie folgt:
- wir sammeln Daten aus verschiedenen Quellen (z. B. mehrere Instanzen von SQL Server und PostgreSQL, verschiedene APIs mit Anwendungsmetriken, sogar 1C) in DWH und ODS (bei uns sind das Vertica und Clickhouse).
- als fortschrittliches
cron, das Datenkonsolidierungsprozesse im ODS ausführt und deren Wartung überwacht.
Bis vor kurzem deckte unsere Infrastruktur einen kleinen Server mit 32 Kernen und 50 GB RAM ab. In Airflow laufen dabei:
- mehr als 200 DAGs (tatsächlich Workflows, in denen wir Aufgaben platziert haben),
- in jedem durchschnittlich 70 Aufgaben,
- dieses System wird ( ebenfalls im Durchschnitt) einmal pro Stunde ausgeführt..
Wie wir uns erweitert haben, werde ich später schreiben, aber lassen Sie uns jetzt die übergeordnete Aufgabe definieren, die wir lösen wollen:
Es gibt drei SQL Server, jeder mit 50 Datenbanken – Instanzen eines Projekts, sodass die Struktur nahezu identisch ist (fast überall, muhahaha). Das bedeutet, dass jede eine Tabelle mit dem Namen „Orders“ enthält (zum Glück kann man eine solche Tabelle in jedes Geschäft einfügen). Wir extrahieren die Daten und fügen Feldinformationen hinzu (Quellserver, Quell-Datenbank, ETL-Task-ID) und werfen sie naiv in, sagen wir, Vertica.
Los geht's!
Der Hauptteil, praktisch (und ein wenig theoretisch)
Warum das für uns (und für Sie) wichtig ist
Als die Bäume groß waren und ich ein einfacher SQL-Bearbeiter in einem russischen Einzelhändler war, haben wir ETL-Prozesse aka Datenströme mit zwei verfügbaren Mitteln durchgeführt:
- Informatica Power Center – ein äußerst komplexes System, extrem leistungsstark, mit eigenen Hardware-Anforderungen und eigener Versionierung. Ich habe gerade einmal 1 % ihrer Möglichkeiten genutzt. Warum? Nun, erstens hat diese Benutzeroberfläche, die irgendwo aus den Nuller Jahren stammt, psychisch auf uns gelastet. Zweitens ist dieses Ding für extrem komplexe Prozesse, intensive Wiederverwendung von Komponenten und andere sehr wichtige Enterprise-Features ausgelegt. Darüber, dass es so viel kostet wie ein Flügel eines Airbus A380 pro Jahr, lassen wir uns lieber nicht aus.
Achtung, ein Screenshot könnte jüngeren Menschen unter 30 etwas schaden.

- SQL Server Integration Server — mit diesem Werkzeug haben wir in unseren internen Projektströmen gearbeitet. Aber mal im Ernst: SQL Server nutzen wir bereits, und es wäre unklug, seine ETL-Tools nicht zu verwenden. Alles daran ist gut: die Oberfläche ist ansprechend, die Ausführungsberichte… Doch dafür lieben wir Softwareprodukte nicht, oh nein, nicht dafür. Versionskontrolle vornehmen,
dtsx(das eine XML-Datei ist, in der beim Speichern die Knoten vermischt werden) können wir, aber was bringt das? Ein Paket von Aufgaben zu erstellen, das hundert Tabellen von einem Server auf einen anderen überträgt? Ach, was hundert – nach zwanzig Exemplaren wird Ihr Zeigefinger beim Klicken auf die Maustaste schmerzen. Aber es sieht zweifellos moderner aus:
Wir haben definitiv nach Auswegen gesucht. Es ging sogar so weit, fast einen selbstgeschriebenen SSIS-Paket-Generator zu erstellen…
... und dann fand mich ein neuer Job. Und dort traf mich Apache Airflow.
Als ich erfuhr, dass die Beschreibung von ETL-Prozessen einfach Python-Code ist, hätte ich fast einen Freudentanz aufgeführt. So wurden Datenströme versioniert und diffundiert, und das Zusammenfügen von Tabellen mit einheitlicher Struktur aus Hunderten von Datenbanken in ein Ziel wurde mit Python-Code auf einem 13-Zoll-Bildschirm zum Kinderspiel.
Cluster aufbauen
Lassen Sie uns nicht ins Kinderzimmer zurückfallen und über offensichtliche Dinge sprechen, wie die Installation von Airflow, Ihrer Datenbank, Celery und anderen Aspekten, die in der Dokumentation beschrieben sind.
Damit wir sofort mit den Experimenten beginnen können, habe ich einige Ideen skizziert. docker-compose.yml in dem:
- Wir werden also Airflow: Scheduler, Webserver. Dort wird auch Flower zur Überwachung der Celery-Aufgaben laufen (da es bereits in
apache/airflow:1.10.10-python3.7, und wir haben nichts dagegen); - PostgreSQL, in den Airflow seine Betriebsinformationen (Scheduler-Daten, Ausführungsstatistiken usw.) schreiben wird, während Celery die abgeschlossenen Aufgaben vermerkt;
- Redis, das als Aufgabenbroker für Celery dienen wird;
- Celery-Worker, der sich um die eigentliche Ausführung der Aufgaben kümmert.
- In den Ordner
./dagswerden wir unsere Dateien mit der Beschreibung der DAGs ablegen. Diese werden spontan erfasst, sodass wir das gesamte System nach jeder Kleinigkeit nicht neu starten müssen.
An einigen Stellen ist der Code in den Beispielen nicht vollständig angegeben (um den Text nicht zu überladen), und an anderen Stellen wird er während des Prozesses modifiziert. Vollständige, funktionierende Codebeispiele können im Repository angesehen werden. .
docker-compose.yml
version: '3.4'
x-airflow-config: &airflow-config
AIRFLOW__CORE__DAGS_FOLDER: /dags
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
AIRFLOW__CORE__FERNET_KEY: MJNz36Q8222VOQhBOmBROFrmeSxNOgTCMaVp2_HOtE0=
AIRFLOW__CORE__HOSTNAME_CALLABLE: airflow.utils.net:get_host_ip_address
AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgres+psycopg2://airflow:airflow@airflow-db:5432/airflow
AIRFLOW__CORE__PARALLELISM: 128
AIRFLOW__CORE__DAG_CONCURRENCY: 16
AIRFLOW__CORE__MAX_ACTIVE_RUNS_PER_DAG: 4
AIRFLOW__CORE__LOAD_EXAMPLES: 'False'
AIRFLOW__CORE__LOAD_DEFAULT_CONNECTIONS: 'False'
AIRFLOW__EMAIL__DEFAULT_EMAIL_ON_RETRY: 'False'
AIRFLOW__EMAIL__DEFAULT_EMAIL_ON_FAILURE: 'False'
AIRFLOW__CELERY__BROKER_URL: redis://broker:6379/0
AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@airflow-db/airflow
x-airflow-base: &airflow-base
image: apache/airflow:1.10.10-python3.7
entrypoint: /bin/bash
restart: always
volumes:
- ./dags:/dags
- ./requirements.txt:/requirements.txt
services:
# Redis als Celery-Broker
broker:
image: redis:6.0.5-alpine
# DB für die Airflow-Metadaten
airflow-db:
image: postgres:10.13-alpine
environment:
- POSTGRES_USER=airflow
- POSTGRES_PASSWORD=airflow
- POSTGRES_DB=airflow
volumes:
- ./db:/var/lib/postgresql/data
# Hauptcontainer mit Airflow Webserver, Scheduler, Celery Flower
airflow:
<<: *airflow-base
environment:
<
-c " sleep 10 &&
pip install --user -r /requirements.txt &&
/entrypoint initdb &&
(/entrypoint webserver &) &&
(/entrypoint flower &) &&
/entrypoint scheduler"
ports:
# Celery Flower
- 5555:5555
# Airflow Webserver
- 8080:8080
# Celery-Worker, wird mit `--scale=n` skaliert
worker:
<<: *airflow-base
environment:
<
-c " sleep 10 &&
pip install --user -r /requirements.txt &&
/entrypoint worker"
depends_on:
- airflow
- airflow-db
- brokerHinweise:
- In der Komposition von Compose habe ich mich stark auf ein bekanntes Bild gestützt. – schauen Sie unbedingt vorbei. Vielleicht benötigen Sie im Leben nichts anderes.
- Alle Einstellungen von Airflow sind nicht nur über
airflow.cfg, sondern auch über Umgebungsvariablen zugänglich (Dank an die Entwickler), was ich ausgiebig genutzt habe. - Natürlich ist es nicht produktionsbereit: Ich habe absichtlich keine Heartbeats auf die Container gesetzt und mich nicht um die Sicherheit gekümmert. Aber ich habe ein Minimum geschaffen, das für unsere Experimente geeignet ist.
- Bitte beachten Sie, dass:
- Der DAG-Ordner muss sowohl für den Scheduler als auch für die Worker zugänglich sein.
- Das Gleiche gilt für alle Drittanbieterbibliotheken – sie müssen auf den Maschinen mit dem Scheduler und den Workern installiert sein.
Nun, ganz einfach:
$ docker-compose up --scale worker=3Nachdem alles gestartet ist, können Sie sich die Web-Oberflächen ansehen:
- Airflow:
- Flower:
Wichtige Konzepte
Wenn Sie von all diesen „DAGs“ nichts verstanden haben, hier ist ein kurzer Glossar:
- Scheduler – der wichtigste Akteur in Airflow, der sicherstellt, dass die Roboter arbeiten und nicht der Mensch: er überwacht den Zeitplan, aktualisiert die DAGs und startet die Aufgaben.
Früher gab es in den älteren Versionen Probleme mit dem Speicher (nein, nicht Amnesie, sondern Lecks) und in den Konfigurationen blieb sogar ein Legacy-Parameter zurück.
run_duration— das Intervall für seinen Neustart. Aber jetzt läuft alles gut. - DAG (auch als „DAG“ bekannt) – „Directed Acyclic Graph“. Diese Definition sagt den meisten Leuten wenig, aber letztlich handelt es sich um einen Container für miteinander interagierende Tasks (siehe unten) oder um das Pendant zu Package in SSIS und Workflow in Informatica.
Zusätzlich zu DAGs kann es auch Sub-DAGs geben, aber wir werden wahrscheinlich nicht dazu kommen.
- DAG Run — ein initialisierter DAG, dem ein
execution_datezugewiesen ist. Die Runs eines DAGs können durchaus parallel laufen (sofern Sie Ihre Tasks natürlich idempotent gestaltet haben). - Operator — Teile des Codes, die für die Ausführung einer bestimmten Aktion verantwortlich sind. Es gibt drei Typen von Operatoren:
- Aktion, wie zum Beispiel unseren Lieblings-
PythonOperator, der in der Lage ist, jeden (gültigen) Python-Code auszuführen; - Überweisung, die Daten von einem Ort zum anderen transportieren, zum Beispiel,
MsSqlToHiveTransfer; - sensor , das Ihnen ermöglicht, auf Ereignisse zu reagieren oder die Durchführung des DAGs zu verlangsamen, bis ein bestimmtes Ereignis eintritt.
HttpSensorkann den angegebenen Endpunkt ansprechen, und wenn die benötigte Antwort kommt, den Transfer startenGoogleCloudStorageToS3Operator. Ein neugieriger Geist könnte fragen: „Warum? Man könnte die Wiederholungen doch direkt im Operator machen!“ Um jedoch den Task-Pool nicht mit hängenden Operatoren zu belasten. Der Sensor startet, überprüft und stirbt bis zum nächsten Versuch.
- Aktion, wie zum Beispiel unseren Lieblings-
- Task zurückgibt. — deklarierte Operatoren unabhängig vom Typ und dem an den DAG angehängten steigen auf den Rang eines Tasks.
- Task-Instanz — wenn der General-Planer entscheidet, dass die Tasks bereit sind, in den Kampf gegen die Worker-Executoren geschickt zu werden (sofort, wenn wir den
LocalExecutoroder auf einen entfernten Node im Falle desCeleryExecutor), weist er ihnen einen Kontext zu (d. h. ein Set von Variablen – Ausführungsparametern), entfaltet die Vorlagen für Befehle oder Anfragen und lagert diese im Pool.
Tasks generieren
Zunächst skizzieren wir das Gesamtkonzept unseres DAGs, und dann werden wir immer tiefer in die Details eintauchen, da wir einige nicht triviale Lösungen anwenden.
Also, in seiner einfachsten Form würde ein solcher DAG so aussehen:
from datetime import timedelta, datetime
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from commons.datasources import sql_server_ds
dag = DAG('orders',
schedule_interval=timedelta(hours=6),
start_date=datetime(2020, 7, 8, 0))
def workflow(**context):
print(context)
for conn_id, schema in sql_server_ds:
PythonOperator(
task_id=schema,
python_callable=workflow,
provide_context=True,
dag=dag)Lassen Sie uns klären:
- Zunächst importieren wir die notwendigen Bibliotheken und einige weitere Dinge;
sql_server_ds— istList[namedtuple[str, str]]mit den Namen der Verbindungen aus Airflow Connections und den Datenbanken, aus denen wir unsere Tabelle abrufen werden;dag— die Deklaration unseres DAGs, die unbedingt inglobals(), sonst findet Airflow ihn nicht. Dem DAG muss auch gesagt werden:- wie er heißt
orders— dieser Name wird später im Web-Interface angezeigt, - dass er um Mitternacht am achten Juli gestartet wird,
- und dass er etwa alle 6 Stunden ausgeführt werden sollte (für die Coolen hier kann anstelle von
timedelta()auchcron-String0 0 0/6 ? * * *verwendet werden, für die weniger Coolen – ein Ausdruck wie@daily);
- wie er heißt
workflow()wird die Hauptarbeit erledigen, aber nicht jetzt. Momentan geben wir einfach unseren Kontext ins Log aus.- Und jetzt die einfache Magie der Aufgaben Erstellung:
- wir durchlaufen unsere Quellen;
- initialisieren
PythonOperator, die unser Platzhalter ausführen wirdworkflow(). Vergessen Sie nicht, einen einzigartigen (innerhalb des DAGs) Task-Namen anzugeben und den DAG selbst zu verknüpfen. Flagprovide_contextwird in der Folge in die Funktion zusätzlicher Argumente hineingespeist, die wir sorgfältig mit Hilfe von**context.
Das war's vorerst. Was haben wir erhalten:
- ein neuer DAG im Web-Interface,
- eineinhalb Hundert Tasks, die parallel ausgeführt werden (sofern es die Konfigurationen von Airflow, Celery und die Serverkapazitäten zulassen).
Nun, fast haben wir es erhalten.
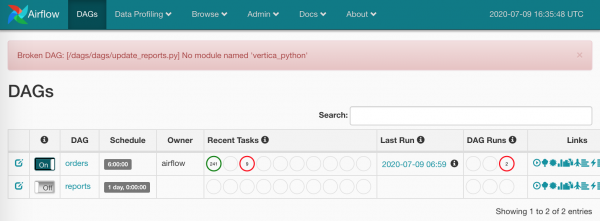
Wer kümmert sich um die Abhängigkeiten?
Um all das zu vereinfachen, habe ich in die docker-compose.yml Verarbeitung requirements.txt auf allen Knoten integriert.
Jetzt geht's los:
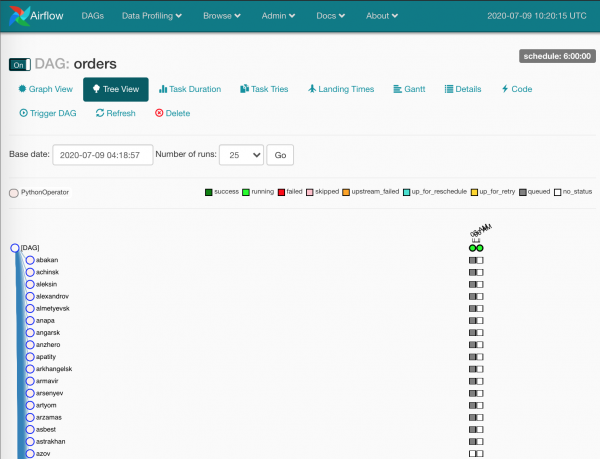
Graue Kästchen – Task-Instanzen, die vom Planer verarbeitet wurden.
Wir warten einen Moment, während die Worker die Aufgaben übernehmen:
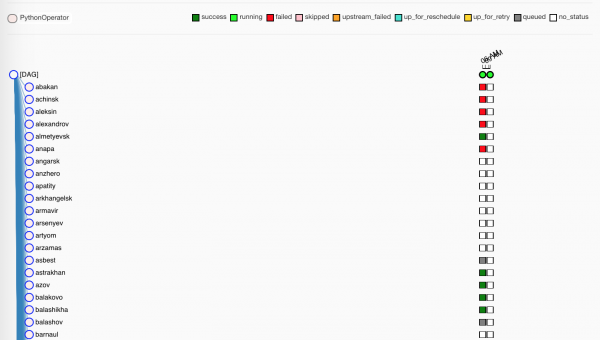
Die grünen sind, wie zu erwarten, – erfolgreich abgeschlossen. Die roten – nicht so erfolgreich.
Übrigens, auf unserem Produktivsystem gibt es keinen Ordner,
./dagsder zwischen den Maschinen synchronisiert – alle DAGs liegen aufgitunserem GitLab, und GitLab CI verteilt Updates auf die Maschinen beim Merge inmaster.
Ein bisschen über Flower
Während die Worker an unseren Platzhalter-Tasks arbeiten, erinnern wir uns an ein weiteres Tool, das uns einige Informationen zeigen kann – Flower.
Die erste Seite mit zusammenfassenden Informationen zu den Worker-Knoten:
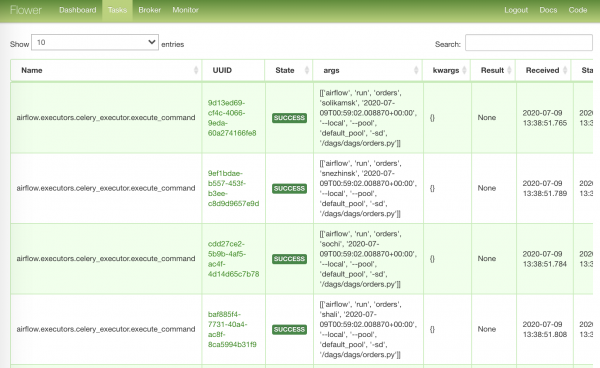
Die am stärksten gefüllte Seite mit den Aufgaben, die in Bearbeitung sind:
Die langweiligste Seite mit dem Status unseres Brokers:
Die auffälligste Seite – mit den Diagrammen zum Status der Aufgaben und deren Ausführungszeiten:
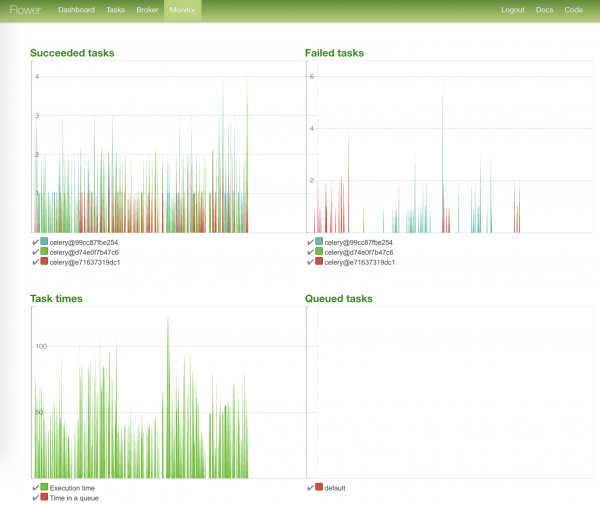
Noch nicht vollgeladene Elemente nachladen
Also, alle Aufgaben wurden bearbeitet, wir können die Verletzten abtransportieren.
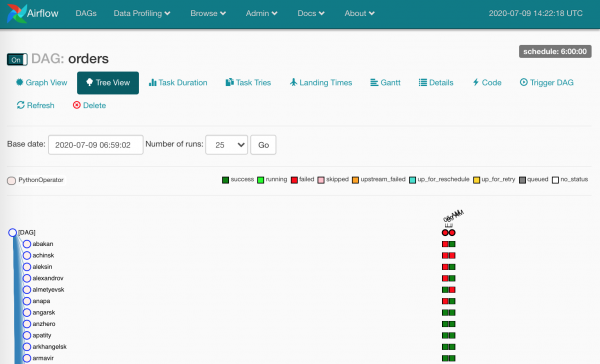
Und es gab viele Verletzte – aus verschiedenen Gründen. Bei korrekter Nutzung von Airflow zeigen diese Quadrate, dass die Daten definitiv nicht angekommen sind.
Es muss das Protokoll angesehen und die abgestürzten Task-Instanzen neu gestartet werden.
Durch Klicken auf eines der Quadrate sehen wir die verfügbaren Aktionen:
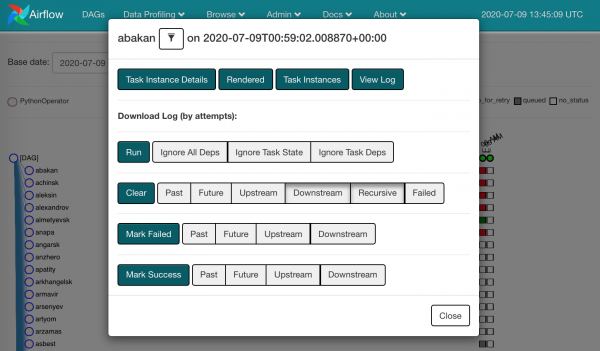
Wir können einfach die Clear-Option für die abgestürzte Instanz auswählen. Das heißt, wir vergessen, dass etwas schief gelaufen ist, und dieselbe Task-Instanz geht zurück zum Planer.

Es ist klar, dass es nicht sehr human ist, mit der Maus durch alle roten Quadrate zu fahren – das erwarten wir nicht von Airflow. Natürlich haben wir eine Massenzerstörungswaffe: Durchsuchen/Task-Instanzen
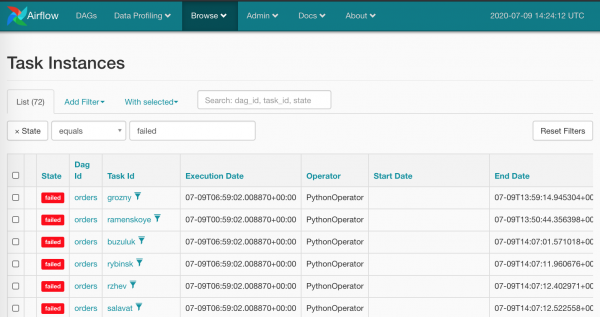
Wählen wir alles auf einmal aus und setzen wir den richtigen Punkt zurück:
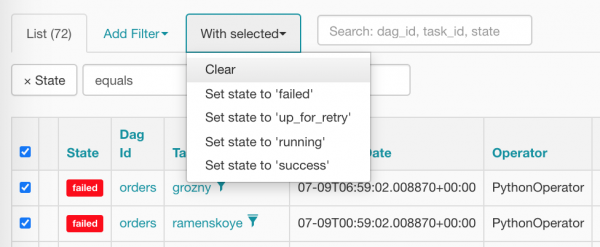
Nach der Rücksetzung sehen unsere Tasks so aus (sie können es kaum erwarten, bis der Scheduler sie plant):

Verbindungen, Hooks und andere Variablen
Es ist an der Zeit, den nächsten DAG zu betrachten, update_reports.py:
from collections import namedtuple
from datetime import datetime, timedelta
from textwrap import dedent
from airflow import DAG
from airflow.contrib.operators.vertica_operator import VerticaOperator
from airflow.operators.email_operator import EmailOperator
from airflow.utils.trigger_rule import TriggerRule
from commons.operators import TelegramBotSendMessage
dag = DAG('update_reports',
start_date=datetime(2020, 6, 7, 6),
schedule_interval=timedelta(days=1),
default_args={'retries': 3, 'retry_delay': timedelta(seconds=10)})
Report = namedtuple('Report', 'source target')
reports = [Report(f'{table}_view', table) for table in [
'reports.city_orders',
'reports.client_calls',
'reports.client_rates',
'reports.daily_orders',
'reports.order_duration']]
email = EmailOperator(
task_id='email_success', dag=dag,
to='{{ var.value.all_the_kings_men }}',
subject='DWH-Berichte aktualisiert',
html_content=dedent("""Sehr geehrte Damen und Herren, die Berichte wurden aktualisiert"""),
trigger_rule=TriggerRule.ALL_SUCCESS)
tg = TelegramBotSendMessage(
task_id='telegram_fail', dag=dag,
tg_bot_conn_id='tg_main',
chat_id='{{ var.value.failures_chat }}',
message=dedent("""
Наташа, wach auf! Wir haben {{ dag.dag_id }} verloren
"""),
trigger_rule=TriggerRule.ONE_FAILED)
for source, target in reports:
queries = [f"TRUNCATE TABLE {target}",
f"INSERT INTO {target} SELECT * FROM {source}"]
report_update = VerticaOperator(
task_id=target.replace('reports.', ''),
sql=queries, vertica_conn_id='dwh',
task_concurrency=1, dag=dag)
report_update >> [email, tg]Hat nicht jeder irgendwann schon einmal Berichte aktualisiert? Hier sind wir wieder: Es gibt eine Liste von Quellen, von denen wir Daten abrufen; es gibt eine Liste, wo wir sie ablegen; und wir vergessen nicht, ein Signal zu senden, wenn alles geklappt hat oder etwas kaputtgegangen ist (na ja, das gilt nicht für uns, oder?).
Lass uns noch einmal die Datei durchgehen und uns die neuen, unklaren Dinge anschauen:
from commons.operators import TelegramBotSendMessage— nichts hindert uns daran, eigene Operatoren zu erstellen, was wir auch getan haben, indem wir eine kleine Hülle für das Senden von Nachrichten in Entsperrt gebaut haben. (Über diesen Operator werden wir uns weiter unten unterhalten);default_args={}— der DAG kann denselben Argumenten an alle seine Operatoren verteilen;to='{{ var.value.all_the_kings_men }}'— das Feldzuwird bei uns nicht hartkodiert, sondern dynamisch mit Hilfe von Jinja und einer Variablen mit einer Liste von E-Mails gebildet, die ich sorgfältig inAdmin/Variables;trigger_rule=TriggerRule.ALL_SUCCESS— die Bedingung zum Starten des Operators. In unserem Fall wird die Nachricht an die Chefs nur gesendet, wenn alle Abhängigkeiten erfolgreich abgeschlossen wurden. erfolgreich.;tg_bot_conn_id='tg_main'— die Argumenteconn_idnehmen die Verbindungsidentifikatoren an, die wir inAdmin/Connections;trigger_rule=TriggerRule.ONE_FAILED— Nachrichten in Telegram werden nur gesendet, wenn Aufgaben fehlgeschlagen sind;task_concurrency=1— wir verbieten den gleichzeitigen Start mehrerer Task-Instanzen desselben Tasks. Andernfalls erhalten wir den gleichzeitigen Start mehrererVerticaOperator(die auf dieselbe Tabelle zugreifen);report_update >> [email, tg]— alleVerticaOperatorwerden in der Versendung von E-Mails und Nachrichten zusammenkommen, so:

Da jedoch bei den Benachrichtigungsoperators unterschiedliche Startbedingungen gelten, wird nur einer arbeiten. Im Baumdiagramm sieht alles etwas weniger übersichtlich aus:

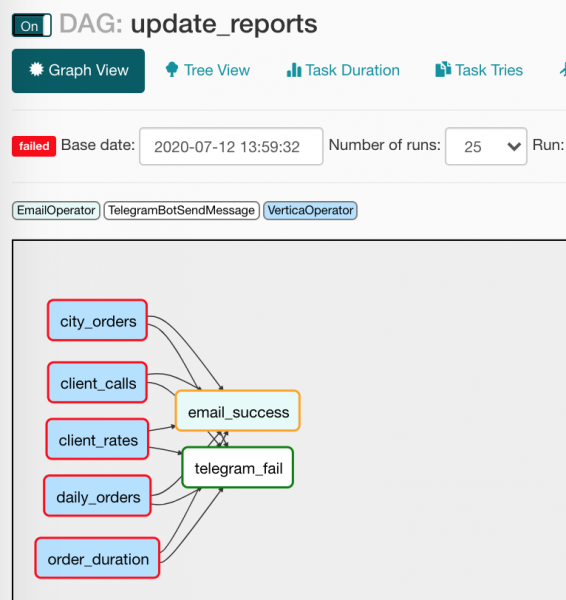

Ich möchte ein paar Worte über Makros und ihre Freunde — Variablen.
Makros sind Jinja-Platzhalter, die verschiedene nützliche Informationen in die Argumente der Operatoren einfügen können. Zum Beispiel so:
SELECT
id,
payment_dtm,
payment_type,
client_id
FROM orders.payments
WHERE
payment_dtm::DATE = '{{ ds }}'::DATE{{ ds }} wird in den Inhalt der Kontextvariable erweitert execution_date im Format YYYY-MM-DD: 2020-07-14. Das Angenehme ist, dass Kontextvariablen an eine bestimmte Task-Instanz (das Quadrat im Baumdiagramm) gebunden sind, und beim Neustart werden die Platzhalter in dieselben Werte aufgelöst.
Die zugewiesenen Werte können mit der Schaltfläche Rendered bei jeder Task-Instanz angezeigt werden. So sieht es bei der Task zum Versenden von E-Mails aus:
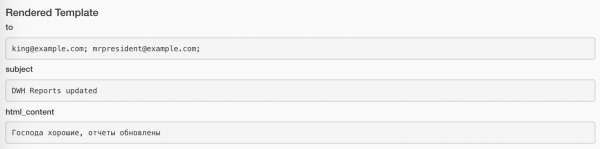
Und so bei der Task zum Versenden von Nachrichten:

Die vollständige Liste der integrierten Makros für die letzte verfügbare Version finden Sie hier:
Darüber hinaus können wir mit Plugins eigene Makros deklarieren, aber das ist eine ganz andere Geschichte.
Neben den vordefinierten Elementen können wir auch Werte unserer Variablen einsetzen (wie ich oben im Code bereits gezeigt habe). Lassen Sie uns in Admin/Variables ein paar Elemente erstellen:
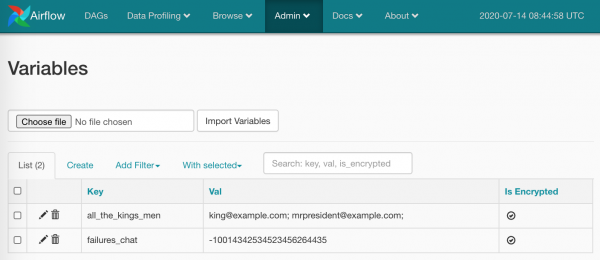
Alles klar, Sie können verwenden:
TelegramBotSendMessage(chat_id='{{ var.value.failures_chat }}')Im Wert kann ein Skalar sein, oder es kann auch JSON enthalten. Im Fall von JSON:
bot_config
{
"bot": {
"token": 881hskdfASDA16641,
"name": "Verter"
},
"service": "TG"
}verwenden Sie einfach den Pfad zum gewünschten Schlüssel: {{ var.json.bot_config.bot.token }}.
Ich werde nur ein Wort sagen und einen Screenshot über Verbindungenzeigen. Hier ist alles einfach: Auf der Seite Admin/Connections erstellen wir eine Verbindung, fügen unsere Logins/Passwörter und spezifischere Parameter hinzu. So geht's:
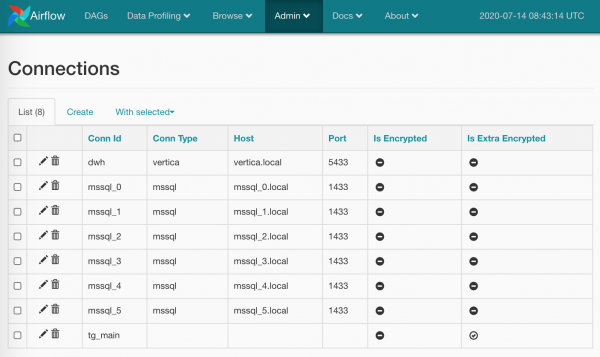
Passwörter können verschlüsselt werden (gründlicher als in der Standardversion), oder Sie können den Verbindungstyp weglassen (wie ich es für tg_main gemacht habe)) — das Problem ist, dass die Liste der Typen in den Airflow-Modellen fest verankert ist und ohne Eingriff in den Quellcode nicht verändert werden kann (falls ich etwas nicht gefunden habe, bitte korrigiert mich), aber es steht uns nichts im Wege, die Zugangsdaten einfach nach Namen zu erhalten.
Außerdem kann man mehrere Verbindungen mit demselben Namen erstellen: In diesem Fall wird die Methode BaseHook.get_connection(), die uns Verbindungen nach Namen bereitstellt, eine zufällige Auswahl aus mehreren Namensvettern zurückgeben (es wäre logischer, Round Robin zu implementieren, aber das überlasse ich den Entwicklern von Airflow).
Variablen und Verbindungen sind ohne Zweifel großartige Werkzeuge, aber es ist wichtig, die Balance nicht zu verlieren: welche Teile Ihrer Workflows speichern Sie im Code und welche überlassen Sie Airflow. Auf der einen Seite kann es praktisch sein, Werte wie eine E-Mail-Adresse schnell über das UI zu ändern. Auf der anderen Seite ist das doch ein Rückschritt zum Klick-Klick, den wir (ich) vermeiden wollten.
Die Arbeit mit Verbindungen ist eine der Aufgaben Hooks. Generell sind Hooks in Airflow Verbindungspunkte zu externen Diensten und Bibliotheken. Zum Beispiel wird JiraHook uns einen Client für die Interaktion mit Jira bereitstellen (wir können Aufgaben hin und her bewegen), und mit SambaHook kann man eine lokale Datei auf smb hochladen.-Punkt.
Einen benutzerdefinierten Operator analysieren
Und wir sind ganz nah daran, einen Blick darauf zu werfen, wie TelegramBotSendMessage
Code commons/operators.py mit dem eigentlichen Operator:
from typing import Union
from airflow.operators import BaseOperator
from commons.hooks import TelegramBotHook, TelegramBot
class TelegramBotSendMessage(BaseOperator):
"""Sendet eine Nachricht an chat_id über TelegramBotHook
Beispiel:
>>> TelegramBotSendMessage(
... task_id='telegram_fail', dag=dag,
... tg_bot_conn_id='tg_bot_default',
... chat_id='{{ var.value.all_the_young_dudes_chat }}',
... message='{{ dag.dag_id }} fehlgeschlagen :(',
... trigger_rule=TriggerRule.ONE_FAILED)
"""
template_fields = ['chat_id', 'message']
def __init__(self,
chat_id: Union[int, str],
message: str,
tg_bot_conn_id: str = 'tg_bot_default',
*args, **kwargs):
super().__init__(*args, **kwargs)
self._hook = TelegramBotHook(tg_bot_conn_id)
self.client: TelegramBot = self._hook.client
self.chat_id = chat_id
self.message = message
def execute(self, context):
print(f'Sende "{self.message}" an den Chat {self.chat_id}')
self.client.send_message(chat_id=self.chat_id,
message=self.message)Hier, wie alles andere in Airflow, ist alles sehr einfach:
- Abgeleitet von
BaseOperator, der viele Airflow-spezifische Dinge realisiert (sehen Sie sich das in Ruhe an) - Wir haben die Felder
template_fields, in denen Jinja nach Makros zur Verarbeitung suchen wird, deklariert. - Wir haben die richtigen Argumente für
__init__() organisiert., haben die Standardwerte dort gesetzt, wo es nötig ist. - Die Initialisierung des Elternteils haben wir ebenfalls nicht vergessen.
- Wir haben den entsprechenden Hook geöffnet
TelegramBotHook, und das Objekt-Client von ihm erhalten. - Wir haben die Methode
BaseOperator.execute()überschrieben, die Airflow aufrufen wird, wenn es an der Zeit ist, den Operator auszuführen – darin implementieren wir die Hauptaktion, wobei wir nicht vergessen, uns zu authentifizieren. (Übrigens protokollieren wir direkt instdoutundstderr– Airflow wird alles abfangen, schön verpacken und alles an den richtigen Ort sortieren.)
Lassen Sie uns ansehen, was wir in commons/hooks.pyhaben. Der erste Teil der Datei, mit dem Hook selbst:
from typing import Union
from airflow.hooks.base_hook import BaseHook
from requests_toolbelt.sessions import BaseUrlSession
class TelegramBotHook(BaseHook):
"""Telegram Bot API Hook
Hinweis: Fügen Sie eine Verbindung mit leeren Conn Type hinzu und vergessen Sie nicht,
Extra auszufüllen:
{"bot_token": "YOuRAwEsomeBOtToKen"}
"""
def __init__(self,
tg_bot_conn_id='tg_bot_default'):
super().__init__(tg_bot_conn_id)
self.tg_bot_conn_id = tg_bot_conn_id
self.tg_bot_token = None
self.client = None
self.get_conn()
def get_conn(self):
extra = self.get_connection(self.tg_bot_conn_id).extra_dejson
self.tg_bot_token = extra['bot_token']
self.client = TelegramBot(self.tg_bot_token)
return self.clientIch weiß nicht einmal, was ich hier erklären soll, ich möchte nur auf wichtige Punkte hinweisen:
- Wir erben, denken über die Argumente nach – in den meisten Fällen wird es nur eines sein:
conn_id; - Übliche Methoden neu definieren: ich habe mich eingeschränkt
get_conn(), in dem ich die Verbindungsparameter nach Name abfrage und lediglich den Abschnitt herausholeextra(dieses Feld für JSON), in das ich (nach meiner eigenen Anweisung!) das Token des Telegram-Bots gelegt habe:{"bot_token": "YOuRAwEsomeBOtToKen"}. - Ich erstelle eine Instanz unseres
TelegramBot, indem ich ihm das spezifische Token übergebe.
Das ist alles. Den Client aus dem Hook erhält man mit TelegramBotHook().clent oder TelegramBotHook().get_conn().
Und der zweite Teil der Datei, in dem ich eine Mikroverpackung für die Telegram REST API mache, um nicht die gleiche nur für eine Methode sendMessage.
class TelegramBot:
"""Telegram Bot API Wrapper
Beispiele:
>>> TelegramBot('YOuRAwEsomeBOtToKen', '@myprettydebugchat').send_message('Hallo, Schatz')
>>> TelegramBot('YOuRAwEsomeBOtToKen').send_message('Hallo, Schatz', chat_id=-1762374628374)
"""
API_ENDPOINT = 'https://api.telegram.org/bot{}/'
def __init__(self, tg_bot_token: str, chat_id: Union[int, str] = None):
self._base_url = TelegramBot.API_ENDPOINT.format(tg_bot_token)
self.session = BaseUrlSession(self._base_url)
self.chat_id = chat_id
def send_message(self, message: str, chat_id: Union[int, str] = None):
method = 'sendMessage'
payload = {'chat_id': chat_id or self.chat_id,
'text': message,
'parse_mode': 'MarkdownV2'}
response = self.session.post(method, data=payload).json()
if not response.get('ok'):
raise TelegramBotException(response)
class TelegramBotException(Exception):
def __init__(self, *args, **kwargs):
super().__init__((args, kwargs))Der richtige Weg ist, all dies zu kombinieren:
TelegramBotSendMessage,TelegramBotHook,TelegramBot— in das Plugin, in ein öffentliches Repository zu legen und als Open Source zur Verfügung zu stellen.
Während wir das alles untersucht haben, sind unsere Berichtsaktualisierungen erfolgreich gescheitert und haben mir eine Fehlermeldung in den Kanal gesendet. Ich werde schauen, was diesmal nicht stimmt...
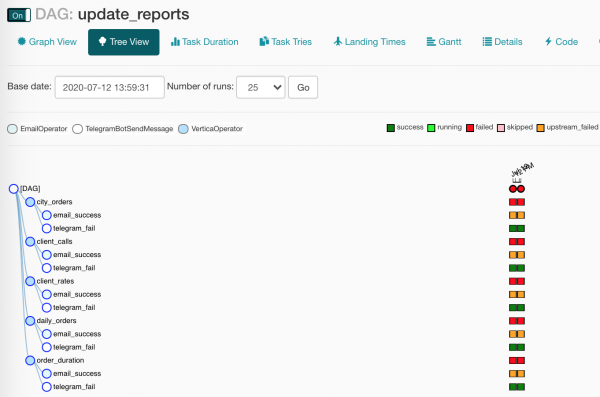
In unserem DAG ist etwas kaputt! War das nicht das, worauf wir gewartet haben? Genau!
Wirst du auch einschenken?
Habe ich etwas übersehen? Ich hatte versprochen, Daten von SQL Server nach Vertica zu migrieren, und habe mich dann einfach vom Thema abgewandt, wie ungezogen!
Die Tat war absichtlich, ich musste Ihnen unbedingt ein paar Begriffe erklären. Jetzt können wir weitermachen.
Unser Plan war folgender:
- Einen DAG erstellen
- Tasks generieren
- Überprüfen, wie schön alles aussieht
- Sessions für die Ladevorgänge zuweisen
- Daten aus SQL Server abrufen
- Daten in Vertica speichern
- Statistiken sammeln
Um all dies zu starten, habe ich eine kleine Ergänzung zu unserem docker-compose.yml:
docker-compose.db.yml
version: '3.4'
x-mssql-base: &mssql-base
image: mcr.microsoft.com/mssql/server:2017-CU21-ubuntu-16.04
restart: always
environment:
ACCEPT_EULA: Y
MSSQL_PID: Express
SA_PASSWORD: SayThanksToSatiaAt2020
MSSQL_MEMORY_LIMIT_MB: 1024
services:
dwh:
image: jbfavre/vertica:9.2.0-7_ubuntu-16.04
mssql_0:
<<: *mssql-base
mssql_1:
<<: *mssql-base
mssql_2:
<<: *mssql-base
mssql_init:
image: mio101/py3-sql-db-client-base
command: python3 ./mssql_init.py
depends_on:
- mssql_0
- mssql_1
- mssql_2
environment:
SA_PASSWORD: SayThanksToSatiaAt2020
volumes:
- ./mssql_init.py:/mssql_init.py
- ./dags/commons/datasources.py:/commons/datasources.pyDort heben wir an:
- Vertica als Host
dwhmit den Standardkonfigurationen, - drei SQL Server Instanzen,
- die Datenbanken mit einigen letzten Daten füllen (bitte schauen Sie auf keinen Fall in die
mssql_init.py!)
Wir starten alles mit einem etwas komplizierteren Befehl als beim letzten Mal:
$ docker-compose -f docker-compose.yml -f docker-compose.db.yml up --scale worker=3Was unser Wunder-Randomizer generiert hat, kann man nutzen, indem man Punkt Datenprofilierung/Ad-hoc-Abfragen:
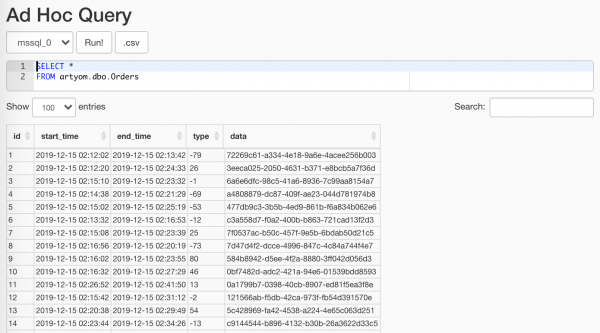
Wichtig ist, das nicht den Analysten zu zeigen
Detailliert darauf eingehen ETL-Sitzungen werde ich nicht, da alles trivial ist: wir erstellen eine Datenbank, darin eine Tabelle, umhüllen alles mit einem Kontextmanager, und nun machen wir Folgendes:
with Session(task_name) as session:
print('Laden', session.id, 'gestartet')
# Workflow laden
...
session.successful = True
session.loaded_rows = 15session.py
from sys import stderr
class Session:
"""ETL-Workflow-Sitzung
Beispiel:
mit Session(task_name) als session:
print(session.id)
session.successful = True
session.loaded_rows = 15
session.comment = 'Gut gemacht'
"""
def __init__(self, connection, task_name):
self.connection = connection
self.connection.autocommit = True
self._task_name = task_name
self._id = None
self.loaded_rows = None
self.successful = None
self.comment = None
def __enter__(self):
return self.open()
def __exit__(self, exc_type, exc_val, exc_tb):
if any(exc_type, exc_val, exc_tb):
self.successful = False
self.comment = f'{exc_type}: {exc_val}n{exc_tb}'
print(exc_type, exc_val, exc_tb, file=stderr)
self.close()
def __repr__(self):
return (f'')
@property
def task_name(self):
return self._task_name
@property
def id(self):
return self._id
def _execute(self, query, *args):
with self.connection.cursor() as cursor:
cursor.execute(query, args)
return cursor.fetchone()[0]
def _create(self):
query = """
CREATE TABLE IF NOT EXISTS sessions (
id SERIAL NOT NULL PRIMARY KEY,
task_name VARCHAR(200) NOT NULL,
started TIMESTAMPTZ NOT NULL DEFAULT current_timestamp,
finished TIMESTAMPTZ DEFAULT current_timestamp,
successful BOOL,
loaded_rows INT,
comment VARCHAR(500)
);
"""
self._execute(query)
def open(self):
query = """
INSERT INTO sessions (task_name, finished)
VALUES (%s, NULL)
RETURNING id;
"""
self._id = self._execute(query, self.task_name)
print(self, 'geöffnet')
return self
def close(self):
if not self._id:
raise SessionClosedError('Sitzung ist nicht geöffnet')
query = """
UPDATE sessions
SET
finished = DEFAULT,
successful = %s,
loaded_rows = %s,
comment = %s
WHERE
id = %s
RETURNING id;
"""
self._execute(query, self.successful, self.loaded_rows,
self.comment, self.id)
print(self, 'geschlossen',
', erfolgreich: ', self.successful,
', Geladen: ', self.loaded_rows,
', Kommentar:', self.comment)
class SessionError(Exception):
pass
class SessionClosedError(SessionError):
passEs ist an der Zeit unsere Daten abzuholen aus unseren mehr als hundert Tabellen. Das erledigen wir mit ein paar einfachen Zeilen:
source_conn = MsSqlHook(mssql_conn_id=src_conn_id, schema=src_schema).get_conn()
query = f"""
SELECT
id, start_time, end_time, type, data
FROM dbo.Orders
WHERE
CONVERT(DATE, start_time) = '{dt}'
"""
df = pd.read_sql_query(query, source_conn)- Mit dem Hook ziehen wir aus Airflow
pymssql-Verbindung - Im Anfrage fügen wir das Datum als Bedingung hinzu – der Template-Engine wird das übergeben.
- Wir füttern unsere Anfrage
pandas, die uns die Daten abrufen wirdDataFrame– sie wird uns später nützlich sein.
Ich benutze die Ersetzung
{dt}anstelle des Anfrageparameters%snicht, weil ich ein böser Buratino bin, sondern weilpandaser nicht mitpymssqlzurechtkommt und dem Letzterenparams: List, obwohl er es sehr gerne möchte.Tupel.
Beachten Sie auch, dass der Entwicklerpymssqlbeschlossen hat, ihn nicht länger zu unterstützen, und es Zeit ist, zu wechseln zupyodbc.
Sehen wir uns an, womit Airflow die Argumente unserer Funktionen gefüllt hat:
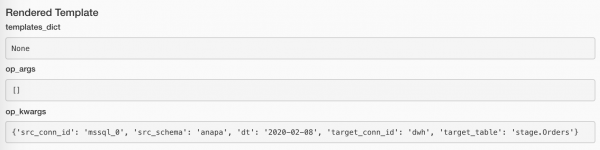
Wenn keine Daten vorhanden sind, macht es keinen Sinn, fortzufahren. Aber es wäre auch merkwürdig, die Einfügung als erfolgreich zu betrachten. Aber das ist kein Fehler. A-a-a, was nun?! So:
if df.empty:
raise AirflowSkipException('Keine Zeilen zum Laden')AirflowSkipException Airflow wird sagen, dass es keinen Fehler gibt, und wir den Task überspringen. Im Interface wird es kein grünes oder rotes Feld geben, sondern in Pink.
Wir fügen unseren Daten einige Spalten hinzu:
df['etl_source'] = src_schema
df['etl_id'] = session.id
df['hash_id'] = hash_pandas_object(df[['etl_source', 'id']])angegeben. Genauer gesagt:
- Die Datenbank, aus der wir die Bestellungen entnommen haben,
- Die ID unserer Lade-Session (diese wird unterschiedlich sein für jeden Task),
- Der Hash vom Quellen- und Bestell-Identifikator — damit wir in der finalen Datenbank (wo alles in einer Tabelle zusammengeführt wird) einen einzigartigen Bestell-Identifier haben.
Es bleibt nur noch ein Schritt: Alles in Vertica laden. Und tatsächlich ist einer der effektivsten Wege, dies zu tun — über CSV!
# Export data to CSV buffer
buffer = StringIO()
df.to_csv(buffer,
index=False, sep='|', na_rep='NUL', quoting=csv.QUOTE_MINIMAL,
header=False, float_format='%.8f', doublequote=False, escapechar='\')
buffer.seek(0)
# Push CSV
target_conn = VerticaHook(vertica_conn_id=target_conn_id).get_conn()
copy_stmt = f"""
COPY {target_table}({df.columns.to_list()})
FROM STDIN
DELIMITER '|'
ENCLOSED '"'
ABORT ON ERROR
NULL 'NUL'
"""
cursor = target_conn.cursor()
cursor.copy(copy_stmt, buffer)- Wir erstellen einen speziellen Empfänger
StringIO. pandaswird freundlich unsereDataFramein Form vonCSV-Zeilen speichern.- Wir öffnen eine Verbindung zu unserem bevorzugten Vertica über einen Hook.
- Und jetzt werden wir mit
copy()unsere Daten direkt an Vertica senden!
Wir holen von dem Treiber, wie viele Zeilen geladen wurden, und sagen dem Session-Manager, dass alles in Ordnung ist:
session.loaded_rows = cursor.rowcount
session.successful = TrueDas war's.
In der Produktion erstellen wir die Zieltabelle manuell. Hier habe ich mir eine kleine Automatisierung erlaubt:
create_schema_query = f'CREATE SCHEMA IF NOT EXISTS {target_schema};'
create_table_query = f"""
CREATE TABLE IF NOT EXISTS {target_schema}.{target_table} (
id INT,
start_time TIMESTAMP,
end_time TIMESTAMP,
type INT,
data VARCHAR(32),
etl_source VARCHAR(200),
etl_id INT,
hash_id INT PRIMARY KEY
);"""
create_table = VerticaOperator(
task_id='create_target',
sql=[create_schema_query,
create_table_query],
vertica_conn_id=target_conn_id,
task_concurrency=1,
dag=dag)Ich bin mit Hilfe von
VerticaOperator()erstelle ich das DB-Schema und die Tabelle (sofern sie noch nicht existieren, natürlich). Wichtig ist, die Abhängigkeiten richtig zu setzen:
for conn_id, schema in sql_server_ds:
load = PythonOperator(
task_id=schema,
python_callable=workflow,
op_kwargs={
'src_conn_id': conn_id,
'src_schema': schema,
'dt': '{{ ds }}',
'target_conn_id': target_conn_id,
'target_table': f'{target_schema}.{target_table}'},
dag=dag)
create_table >> loadZusammenfassung
— Nun, — sagte das Mäuschen, — nicht wahr, jetzt
Bist du überzeugt, dass ich im Wald das furchterregendste Tier bin?
Julia Donaldson, „Der Grüffelo“
Ich denke, wenn meine Kollegen und ich einen Wettbewerb veranstalten würden, wer am schnellsten einen ETL-Prozess von Grund auf entwickelt: sie mit ihren SSIS und mir mit Airflow… Und danach würden wir außerdem die Wartungsfreundlichkeit vergleichen… Oh, ich denke, ihr werdet zustimmen, dass ich sie in jeder Hinsicht übertreffen werde!
Wenn es etwas ernster wird, hat Apache Airflow – durch die Beschreibung von Prozessen in Form von Programmcode – meine Arbeit deutlich bequemer und angenehmer gestaltet.
Seine unbegrenzte Erweiterbarkeit – sowohl bei Plugins als auch hinsichtlich der Skalierbarkeit – ermöglicht es Ihnen, Airflow praktisch in jedem Bereich anzuwenden: sei es im vollständigen Zyklus der Datensammlung, -aufbereitung und -verarbeitung oder beim Start von Raketen (natürlich für den Mars).
Der abschließende, informative Teil
Die Stolpersteine, die wir für Sie gesammelt haben
start_date. Ja, das ist schon ein lokales Meme. Durch das Hauptargument des DAGsstart_datewerden alle durchlaufen. Kurz gesagt, wenn Sie in derstart_dateaktuellen Datumsangabe angeben und imschedule_interval– einen Tag, wird der DAG morgen frühestens gestartet.start_date = datetime(2020, 7, 7, 0, 1, 2)Und keine weiteren Probleme.
Damit ist auch ein weiterer Ausführungsfehler verbunden:
Task is missing the start_date parameter, der meist bedeutet, dass Sie vergessen haben, den DAG-Operator zuzuordnen.- Alles auf einem einzigen Gerät. Ja, sowohl die Datenbanken (von Airflow selbst und unserer Schicht), der Webserver, der Scheduler und die Worker. Und es hat sogar funktioniert. Aber im Laufe der Zeit wuchs die Anzahl der Aufgaben in den Services, und als PostgreSQL begann, Antworten über den Index in 20 ms statt in 5 ms zu geben, haben wir ihn einfach entfernt.
- LocalExecutor. Ja, wir nutzen es immer noch und stehen nun am Rand des Abgrunds. Der LocalExecutor hat uns bisher ausgereicht, aber jetzt ist es an der Zeit, mindestens einen Worker hinzuzufügen, und wir müssen uns anstrengen, um auf den CeleryExecutor umzusteigen. Da man mit diesem auch auf einer Maschine arbeiten kann, gibt es nichts, was uns davon abhält, Celery selbst auf einem Server zu verwenden, der „natürlich niemals in die Produktion gehen wird, das schwöre ich!“
- Nicht verwendet integrierte Mittel:
- Verbindungen zum Speichern von Service-Anmeldeinformationen,
- SLA-Verstöße zum Handeln von Aufgaben, die nicht rechtzeitig verarbeitet wurden,
- XCom zum Austausch von Metadaten (ich habe „Meta“ gesagt Daten!) zwischen den Aufgaben des DAGs.Missbrauch von E-Mails. Was soll man dazu sagen? Es wurden Benachrichtigungen für alle Wiederholungen fehlgeschlagener Aufgaben eingerichtet. Jetzt habe ich über 90.000 Emails von Airflow in meinem Arbeits-Gmail, und die Weboberfläche des E-Mail-Clients weigert sich, mehr als 100 Stück auf einmal zu löschen.
- Weitere Fallstricke:
Apache Airflow Fallstricke
Mittel zur weiteren Automatisierung
Um sicherzustellen, dass wir noch mehr mit dem Kopf und nicht mit den Händen arbeiten, hat Airflow Folgendes für uns vorbereitet:
- — es hat immer noch den Status Experimental, was seiner Funktionalität jedoch nicht im Wege steht. Damit können Sie nicht nur Informationen zu DAGs und Tasks abrufen, sondern auch DAGs anhalten oder starten, einen DAG Run erstellen oder einen Pool verwalten.
- — über die Kommandozeile stehen viele Werkzeuge zur Verfügung, die entweder umständlich über die WebUI zu bedienen sind oder dort gar nicht vorhanden sind. Beispielsweise:
backfillwird benötigt, um Task-Instanzen erneut zu starten.
Sagen wir, Analysten kommen und sagen: „Ihre Daten vom 1. bis 13. Januar sind nicht in Ordnung! Reparieren Sie das!“ Und Sie denken sich:airflow backfill -s '2020-01-01' -e '2020-01-13' orders- Datenbankpflege:
initdb,resetdb,upgradedb,checkdb. run, welches es ermöglicht, eine einzelne Task-Instanz zu starten, ohne sich um Abhängigkeiten kümmern zu müssen. Darüber hinaus kann es überLocalExecutor, auch wenn Sie einen Celery-Cluster haben.- Etwa das gleiche tut
test, nur dass es nicht in die Datenbank schreibt. connectionsermöglicht das massenhafte Erstellen von Verbindungen aus der Shell.
- — ist eine ziemlich anspruchsvolle Interaktionsmethode, die für Plugins gedacht ist, nicht für das Herumprobieren. Aber wer hält uns davon ab, zu
/home/airflow/dags, zu startenipythonund einfach loszulegen? Man kann beispielsweise alle Verbindungen mit folgendem Code exportieren:from airflow import settings from airflow.models import Connection fields = 'conn_id conn_type host port schema login password extra'.split() session = settings.Session() for conn in session.query(Connection).order_by(Connection.conn_id): d = {field: getattr(conn, field) for field in fields} print(conn.conn_id, '=', d) - Verbindung zur Airflow-Metadatenbank. Ich empfehle nicht, in diese zu schreiben, aber es ist deutlich schneller und einfacher, die Zustände von Tasks für verschiedene spezifische Metriken abzurufen, als über eine der APIs.
Sagen wir, nicht alle unsere Tasks sind idempotent und können manchmal fehlschlagen, was in Ordnung ist. Aber mehrere Fehler sind schon verdächtig, da sollte man nachforschen.
Vorsicht, SQL!
WITH last_executions AS ( SELECT task_id, dag_id, execution_date, state, row_number() OVER ( PARTITION BY task_id, dag_id ORDER BY execution_date DESC) AS rn FROM public.task_instance WHERE execution_date > now() - INTERVAL '2' DAY ), failed AS ( SELECT task_id, dag_id, execution_date, state, CASE WHEN rn = row_number() OVER ( PARTITION BY task_id, dag_id ORDER BY execution_date DESC) THEN TRUE END AS last_fail_seq FROM last_executions WHERE state IN ('failed', 'up_for_retry') ) SELECT task_id, dag_id, count(last_fail_seq) AS unsuccessful, count(CASE WHEN last_fail_seq AND state = 'failed' THEN 1 END) AS failed, count(CASE WHEN last_fail_seq AND state = 'up_for_retry' THEN 1 END) AS up_for_retry FROM failed GROUP BY task_id, dag_id HAVING count(last_fail_seq) > 0
Links
Natürlich sind die ersten zehn Links in der Google-Suche Inhalte aus meinem Airflow-Ordner.
- — Natürlich sollte man mit der offiziellen Dokumentation beginnen, aber wer liest schon Anleitungen?
- — Lesen Sie zumindest die Empfehlungen der Entwickler.
- — Der Anfang: eine grafische Übersicht der Benutzeroberfläche
- — Gut erklärte Grundbegriffe, falls Sie (ausnahmsweise!) etwas bei mir nicht verstanden haben.
- — Ein kurzer Leitfaden zur Konfiguration eines Airflow-Clusters.
- — Fast ein ebenso interessanter Artikel, nur mit mehr Formalismus und weniger Beispielen.
- — Arbeiten im Zusammenspiel mit Celery.
- — Über Idempotenz von Tasks, das Laden nach ID statt Datum, Transformationen, Dateistrukturen und andere interessante Aspekte.
- — Task-Abhängigkeiten und Trigger-Regeln, die ich nur am Rande erwähnt habe.
- — Wie man gewisse „es funktioniert wie geplant“ beim Scheduler überwindet, verlorene Daten lädt und die Prioritäten der Tasks festlegt.
- — nützliche SQL-Abfragen für die Metadaten von Airflow.
- — es gibt einen hilfreichen Abschnitt über die Erstellung eines benutzerdefinierten Sensors.
- — eine interessante kurze Notiz zum Aufbau einer Infrastruktur auf AWS für Data Science.
- — gängige Fehler (wenn jemand die Anleitungen nicht liest).
- — lächeln Sie, wie Leute das Speichern von Passwörtern umgangen haben, obwohl sie einfach Connections verwenden könnten.
- — implizite Übertragung von DAGs, Kontextübergabe in Funktionen, erneut über Abhängigkeiten und das Überspringen von Task-Ausführungen.
- — zur Verwendung von
StandardargumentenundParameterin Vorlagen sowie zu Variablen und Verbindungen. - — eine Erzählung darüber, wie der Scheduler auf Airflow 2.0 vorbereitet wird.
- — ein etwas veralteter Artikel über das Deployment unseres Clusters in
version: '1' services: simplesample-sonar: image: sonarqube:lts ports: - 9001:9000 - 9092:9092 network_mode: bridge. - — dynamische Aufgaben mithilfe von Vorlagen und Kontextübergabe.
- — Standard- und benutzerdefinierte Benachrichtigungen über E-Mail und Slack.
- — Task-Verzweigungen, Makros und XCom.
Und die in diesem Artikel verwendeten Links:
- — Platzhalter, die in Vorlagen verwendet werden können.
- — Verbreitete Fehler beim Erstellen von DAGs.
- —
version: '1' services: simplesample-sonar: image: sonarqube:lts ports: - 9001:9000 - 9092:9092 network_mode: bridgefür Experimente, Debugging und mehr. - — Python-Wrapper für die Telegram REST API.
Quelle: habr.com
