

27. April auf der Konferenz Im Rahmen des Abschnitts „DevOps“ wurde der Bericht „Autoscaling und Ressourcenmanagement in Kubernetes“ veröffentlicht. Es geht darum, wie Sie K8s nutzen können, um eine hohe Verfügbarkeit Ihrer Anwendungen und Spitzenleistung sicherzustellen.

Aus Tradition präsentieren wir gerne (44 Minuten, viel informativer als der Artikel) und die Hauptzusammenfassung in Textform. Gehen!
Lassen Sie uns das Thema des Berichts Wort für Wort analysieren und am Ende beginnen.
Kubernetes
Nehmen wir an, wir haben Docker-Container auf unserem Host. Wofür? Um Wiederholbarkeit und Isolation zu gewährleisten, was wiederum eine einfache und gute Bereitstellung ermöglicht, CI/CD. Wir haben viele solcher Fahrzeuge mit Containern.
Was bietet Kubernetes in diesem Fall?
- Wir hören auf, an diese Maschinen zu denken und fangen an, mit der „Cloud“ zu arbeiten. Cluster von Containern oder Pods (Gruppen von Behältern).
- Darüber hinaus denken wir nicht einmal an einzelne Pods, sondern verwalten mehrоgrößere Gruppen. Solch Grundelemente auf hoher Ebene Lassen Sie uns sagen, dass es eine Vorlage zum Ausführen einer bestimmten Arbeitslast gibt, und hier ist die erforderliche Anzahl von Instanzen, um sie auszuführen. Wenn wir die Vorlage nachträglich ändern, ändern sich alle Instanzen.
- Mit deklarative API Anstatt eine Folge spezifischer Befehle auszuführen, beschreiben wir die „Struktur der Welt“ (in YAML), die von Kubernetes erstellt wird. Und noch einmal: Wenn sich die Beschreibung ändert, ändert sich auch die tatsächliche Darstellung.
Ressourcen Management
CPU
Lassen Sie uns Nginx, PHP-FPM und MySQL auf dem Server ausführen. Bei diesen Diensten werden tatsächlich noch mehr Prozesse ausgeführt, die jeweils Rechenressourcen erfordern:
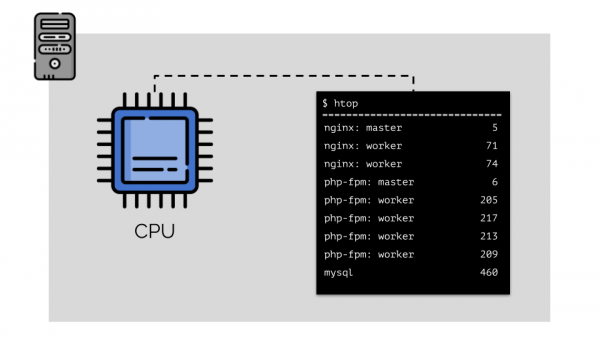
(Die Zahlen auf der Folie sind „Papageien“, der abstrakte Bedarf jedes Prozesses an Rechenleistung)
Um die Arbeit damit zu erleichtern, ist es logisch, Prozesse in Gruppen zusammenzufassen (z. B. alle Nginx-Prozesse in einer Gruppe „nginx“). Eine einfache und offensichtliche Möglichkeit, dies zu tun, besteht darin, jede Gruppe in einen Container zu legen:
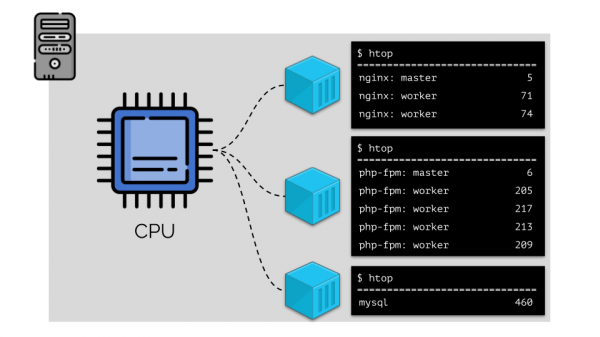
Um fortzufahren, müssen wir uns daran erinnern, was ein Container ist (in LinuxIhr Auftreten wurde durch drei Schlüsselfunktionen im Kernel ermöglicht, die bereits vor einiger Zeit implementiert wurden: , и . Und die weitere Entwicklung wurde durch andere Technologien erleichtert (einschließlich praktischer „Shells“ wie Docker):
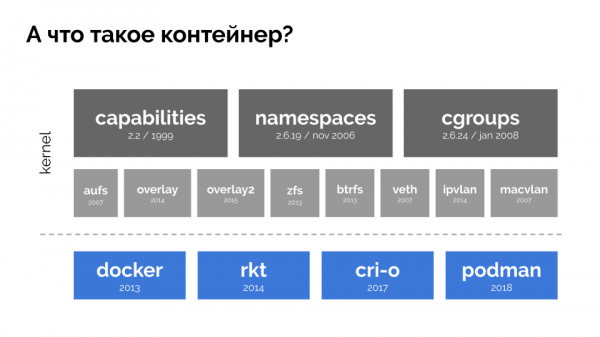
Im Rahmen des Berichts interessiert uns nur Gruppen, da Kontrollgruppen der Teil der Funktionalität von Containern (Docker usw.) sind, der die Ressourcenverwaltung implementiert. Zu Gruppen zusammengefasste Prozesse sind, wie wir es wollten, Kontrollgruppen.
Kehren wir zu den CPU-Anforderungen für diese Prozesse und nun für Gruppen von Prozessen zurück:
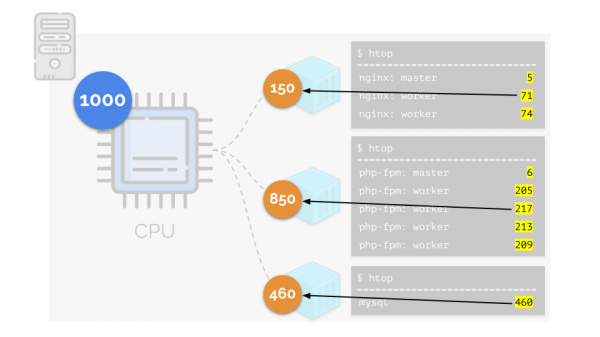
(Ich wiederhole, dass alle Zahlen ein abstrakter Ausdruck des Ressourcenbedarfs sind)
Gleichzeitig verfügt die CPU selbst über eine gewisse endliche Ressource (im Beispiel ist das 1000), die jedem fehlen kann (die Summe der Bedürfnisse aller Gruppen beträgt 150+850+460=1460). Was wird in diesem Fall passieren?
Der Kernel beginnt mit der Verteilung der Ressourcen und tut dies „fair“, indem er jeder Gruppe die gleiche Menge an Ressourcen zuteilt. Im ersten Fall sind jedoch mehr davon vorhanden als benötigt (333>150), sodass der Überschuss (333-150=183) in der Reserve verbleibt, die ebenfalls gleichmäßig auf zwei andere Behälter verteilt wird:
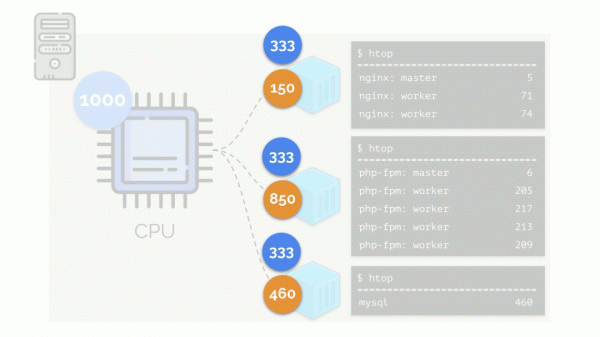
Das Ergebnis: Der erste Container hatte genügend Ressourcen, der zweite – er hatte nicht genug Ressourcen, der dritte – er hatte nicht genug Ressourcen. Dies ist das Ergebnis von Handlungen "ehrlicher" Planer in Linux - . Seine Bedienung kann über die Zuordnung angepasst werden Gewichte jeden der Behälter. Zum Beispiel so:
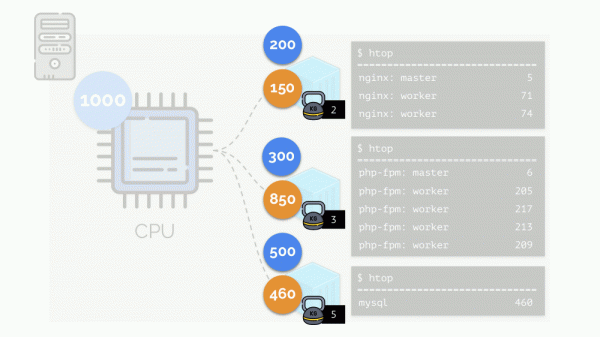
Schauen wir uns den Fall eines Ressourcenmangels im zweiten Container (php-fpm) an. Alle Containerressourcen werden gleichmäßig auf die Prozesse verteilt. Infolgedessen funktioniert der Master-Prozess gut, aber alle Arbeiter werden langsamer und erhalten weniger als die Hälfte von dem, was sie benötigen:
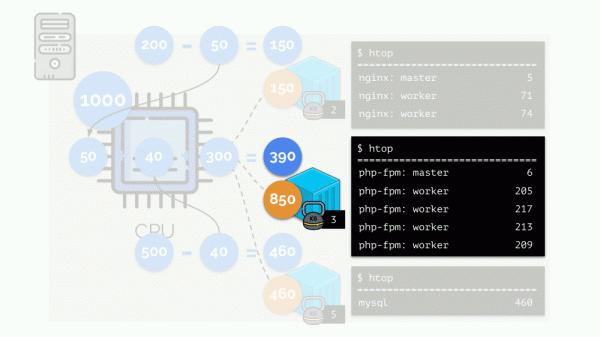
So funktioniert der CFS-Scheduler. Wir werden weiterhin die Gewichte nennen, die wir Containern zuweisen Anfragen. Warum das so ist – siehe weiter.
Schauen wir uns die ganze Situation von der anderen Seite an. Wie Sie wissen, führen alle Wege nach Rom und im Fall eines Computers zur CPU. Eine CPU, viele Aufgaben – Sie brauchen eine Ampel. Der einfachste Weg, Ressourcen zu verwalten, ist „Ampel“: Sie geben einem Prozess eine feste Zugriffszeit auf die CPU, dann dem nächsten usw.
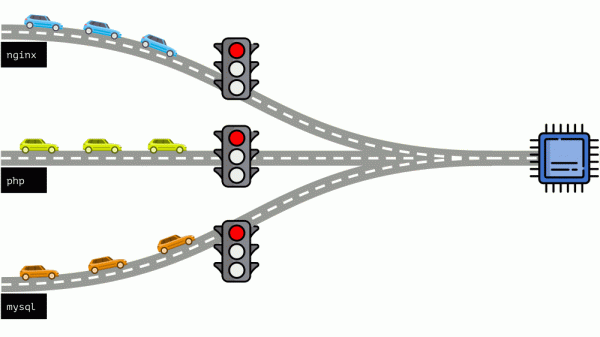
Dieser Ansatz wird als harte Quoten bezeichnet (harte Begrenzung). Erinnern wir uns einfach daran Grenzen. Wenn man jedoch Limits auf alle Container verteilt, entsteht ein Problem: MySQL lief die Straße entlang und irgendwann endete sein CPU-Bedarf, aber alle anderen Prozesse müssen warten, bis die CPU leer ist Leerlauf.
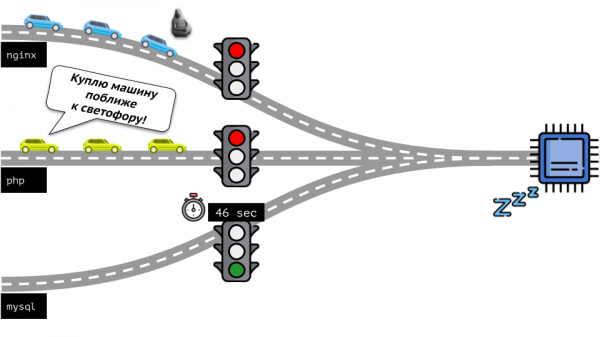
Kehren wir zum Kern zurück Linux und seine Wechselwirkung mit der CPU – das Gesamtbild stellt sich wie folgt dar:
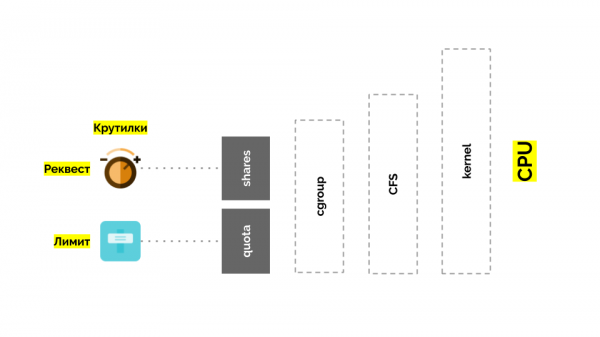
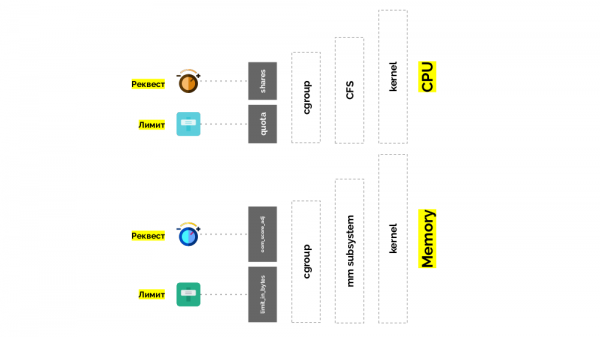
cgroup verfügt über zwei Einstellungen – im Wesentlichen sind dies zwei einfache „Wendungen“, mit denen Sie Folgendes bestimmen können:
- Gewicht für Container (Anfragen) beträgt Aktien;
- Prozentsatz der gesamten CPU-Zeit für die Arbeit an Containeraufgaben (Limits). Aktie.
Wie misst man die CPU?
Es gibt verschiedene Möglichkeiten:
- Welche Papageien, niemand weiß es – Sie müssen jedes Mal verhandeln.
- Interesse Klarer, aber relativ: 50 % eines Servers mit 4 Kernen und mit 20 Kernen sind völlig unterschiedliche Dinge.
- Sie können die bereits genannten verwenden Gewichte, was er weiß LinuxAber sie sind auch relativ.
- Die angemessenste Option besteht darin, die Rechenressourcen zu messen Sekunden. Diese. in Sekunden Prozessorzeit relativ zu Sekunden Echtzeit: Pro 1 realen Sekunde wurde 1 Sekunde Prozessorzeit angegeben – das ist ein ganzer CPU-Kern.
Um das Sprechen noch einfacher zu machen, begannen sie direkt einzumessen Kerne, was für sie bedeutet, dass die CPU-Zeit im Verhältnis zur tatsächlichen Zeit gleich ist. Da Linux Das System versteht Gewichtungen, aber nicht Prozessorzeit/Kerne; daher war ein Mechanismus zur Umrechnung von der einen in die andere Größe erforderlich.
Betrachten wir ein einfaches Beispiel mit einem Server mit 3 CPU-Kernen, bei dem drei Pods Gewichtungen (500, 1000 und 1500) erhalten, die leicht in die entsprechenden Teile der ihnen zugewiesenen Kerne (0,5, 1 und 1,5) umgewandelt werden können.
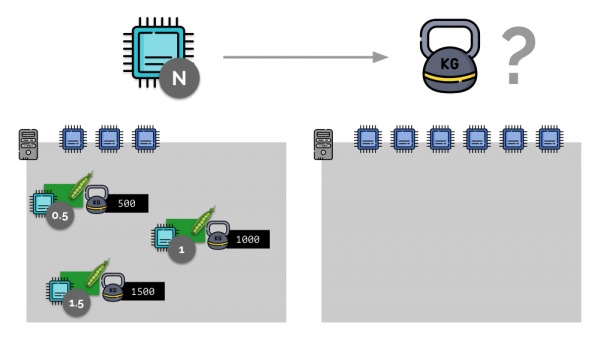
Wenn Sie einen zweiten Server nehmen, auf dem es doppelt so viele Kerne gibt (6), und dort die gleichen Pods platzieren, lässt sich die Verteilung der Kerne leicht berechnen, indem Sie einfach mit 2 multiplizieren (1, 2 bzw. 3). Ein wichtiger Moment tritt jedoch ein, wenn auf diesem Server ein vierter Pod erscheint, dessen Gewicht der Einfachheit halber 3000 beträgt. Dadurch wird ein Teil der CPU-Ressourcen (die Hälfte der Kerne) weggenommen, und für die verbleibenden Pods werden sie neu berechnet (halbiert):
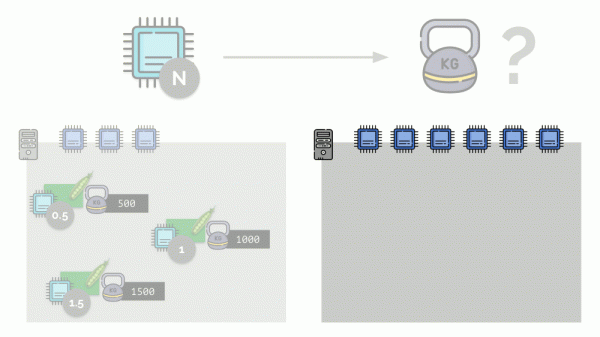
Kubernetes und CPU-Ressourcen
In Kubernetes werden CPU-Ressourcen normalerweise in gemessen Millidrax, d.h. Als Basisgewicht werden 0,001 Kerne angenommen. (Gleiche Terminologie) Linux/cgroups werden als CPU-Anteile bezeichnet, genauer gesagt: 1000 Millicores = 1024 CPU-Anteile. K8s stellt sicher, dass nicht mehr Pods auf dem Server platziert werden, als CPU-Ressourcen für die Summe der Gewichtungen aller Pods vorhanden sind.
Wie kommt es dazu? Wenn Sie einen Server zu einem Kubernetes-Cluster hinzufügen, wird gemeldet, wie viele CPU-Kerne ihm zur Verfügung stehen. Und beim Erstellen eines neuen Pods weiß der Kubernetes-Scheduler, wie viele Kerne dieser Pod benötigt. Somit wird der Pod einem Server zugewiesen, auf dem genügend Kerne vorhanden sind.
Was wird passieren wenn nicht Anfrage angegeben ist (d. h. der Pod verfügt nicht über eine definierte Anzahl von Kernen, die er benötigt)? Lassen Sie uns herausfinden, wie Kubernetes im Allgemeinen Ressourcen zählt.
Für einen Pod können Sie sowohl Anfragen (CFS-Scheduler) als auch Limits (erinnern Sie sich an die Ampel?) angeben:
- Wenn sie gleich angegeben sind, wird dem Pod eine QoS-Klasse zugewiesen garantiert. Diese Anzahl der ihm immer zur Verfügung stehenden Kerne ist garantiert.
- Wenn die Anforderung unter dem Grenzwert liegt – QoS-Klasse platzbar. Diese. Wir erwarten beispielsweise, dass ein Pod immer 1 Kern verwendet, dieser Wert stellt jedoch keine Einschränkung dar: manchmal Pod kann mehr nutzen (wenn der Server dafür freie Ressourcen hat).
- Es gibt auch eine QoS-Klasse beste Anstrengung – Es umfasst genau die Pods, für die keine Anfrage angegeben ist. Die Ressourcen werden ihnen zuletzt zugewiesen.
Память
Beim Gedächtnis ist die Situation ähnlich, aber etwas anders – schließlich ist die Beschaffenheit dieser Ressourcen anders. Im Allgemeinen lautet die Analogie wie folgt:
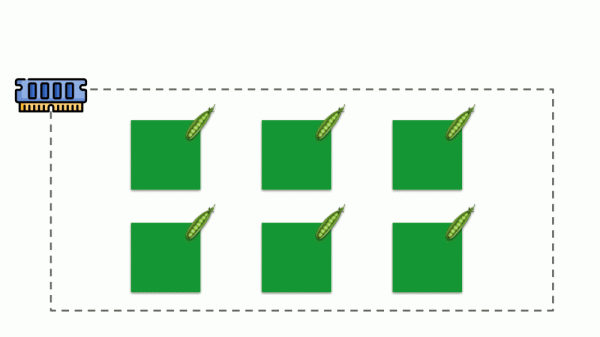
Sehen wir uns an, wie Anforderungen im Speicher implementiert werden. Lassen Sie die Pods auf dem Server verbleiben, wodurch sich der Speicherverbrauch ändert, bis einer von ihnen so groß wird, dass ihm der Speicher ausgeht. In diesem Fall erscheint der OOM-Killer und beendet den größten Prozess:
Das passt nicht immer zu uns, daher lässt sich regeln, welche Prozesse für uns wichtig sind und nicht abgetötet werden sollten. Verwenden Sie dazu den Parameter oom_score_adj.
Kehren wir zu den QoS-Klassen der CPU zurück und ziehen wir eine Analogie zu den oom_score_adj-Werten, die die Speicherverbrauchsprioritäten für Pods bestimmen:
- Der niedrigste oom_score_adj-Wert für einen Pod – -998 – bedeutet, dass ein solcher Pod zuletzt getötet werden sollte garantiert.
- Der höchste – 1000 – ist beste Anstrengung, solche Schoten werden zuerst getötet.
- Um die restlichen Werte zu berechnen (platzbar) gibt es eine Formel, deren Kern darin besteht, dass die Wahrscheinlichkeit, dass ein Pod getötet wird, umso geringer ist, je mehr Ressourcen er angefordert hat.

Die zweite „Wendung“ – limit_in_bytes - für Grenzen. Damit ist alles einfacher: Wir weisen einfach die maximale Menge an ausgegebenem Speicher zu, und hier (im Gegensatz zur CPU) stellt sich keine Frage, wie man ihn (Speicher) misst.
Insgesamt
Jeder Pod in Kubernetes ist angegeben requests и limits - beide Parameter für CPU und Speicher:
- Basierend auf Anfragen arbeitet der Kubernetes-Scheduler, der Pods auf Server verteilt.
- Basierend auf allen Parametern wird die QoS-Klasse des Pods bestimmt.
- Relative Gewichtungen werden basierend auf CPU-Anfragen berechnet;
- der CFS-Scheduler wird basierend auf CPU-Anfragen konfiguriert;
- Der OOM-Killer wird basierend auf Speicheranforderungen konfiguriert.
- eine „Ampel“ wird basierend auf CPU-Grenzwerten konfiguriert;
- Basierend auf Speicherlimits wird ein Limit für die cgroup konfiguriert.
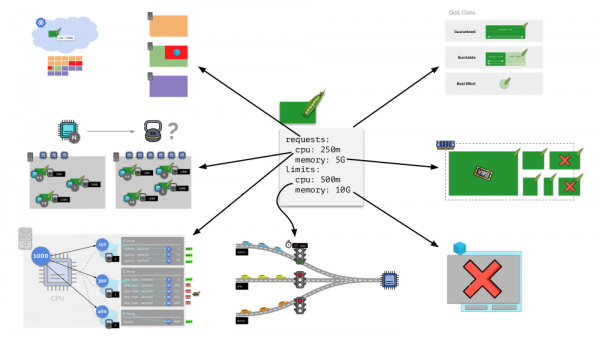
Im Allgemeinen beantwortet dieses Bild alle Fragen dazu, wie der Hauptteil der Ressourcenverwaltung in Kubernetes abläuft.
Automatische Skalierung
K8s Cluster-Autoscaler
Stellen wir uns vor, dass der gesamte Cluster bereits belegt ist und ein neuer Pod erstellt werden muss. Obwohl der Pod nicht angezeigt werden kann, bleibt er im Status hängen Zu überprüfen. Damit es angezeigt wird, können wir einen neuen Server mit dem Cluster verbinden oder ... Cluster-Autoscaler installieren, der das für uns erledigt: eine virtuelle Maschine beim Cloud-Anbieter bestellen (mithilfe einer API-Anfrage) und sie mit dem Cluster verbinden Anschließend wird der Pod hinzugefügt.
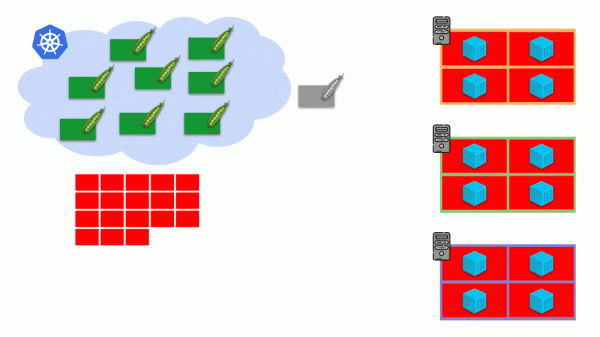
Dabei handelt es sich um eine automatische Skalierung des Kubernetes-Clusters, die unserer Erfahrung nach hervorragend funktioniert. Allerdings gibt es hier, wie auch anderswo, einige Nuancen...
Solange wir die Clustergröße erhöht haben, war alles in Ordnung, aber was passiert, wenn der Cluster begann sich zu befreien? Das Problem besteht darin, dass die Migration von Pods (um Hosts freizugeben) technisch sehr schwierig und ressourcenintensiv ist. Kubernetes verwendet einen völlig anderen Ansatz.
Stellen Sie sich einen Cluster aus drei Servern vor, der über Deployment verfügt. Es verfügt über 3 Pods: Jetzt gibt es 6 für jeden Server. Aus irgendeinem Grund wollten wir einen der Server abschalten. Dazu verwenden wir den Befehl kubectl drain, welche:
- wird das Senden neuer Pods an diesen Server verbieten;
- löscht vorhandene Pods auf dem Server.
Da Kubernetes für die Aufrechterhaltung der Anzahl der Pods (6) verantwortlich ist, ist dies einfach wird neu erstellen sie auf anderen Knoten, jedoch nicht auf dem deaktivierten Knoten, da dieser bereits als nicht verfügbar für das Hosten neuer Pods markiert ist. Dies ist ein grundlegender Mechanismus für Kubernetes.
Allerdings gibt es auch hier eine Nuance. In einer ähnlichen Situation sind die Aktionen für StatefulSet (anstelle von Deployment) unterschiedlich. Jetzt haben wir bereits eine zustandsbehaftete Anwendung – zum Beispiel drei Pods mit MongoDB, von denen einer ein Problem hat (die Daten sind beschädigt oder ein anderer Fehler, der den korrekten Start des Pods verhindert). Und wir beschließen erneut, einen Server zu deaktivieren. Was wird passieren?
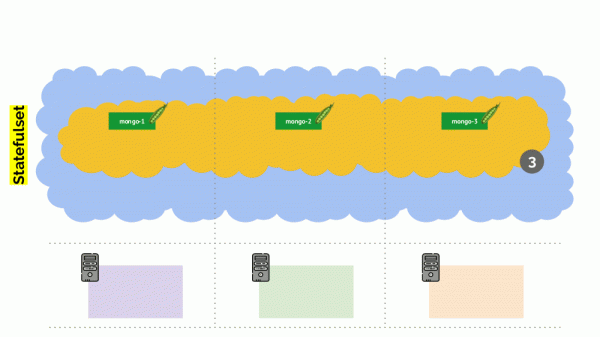
MongoDB könnte sterben, weil es ein Quorum braucht: Bei einem Cluster aus drei Installationen müssen mindestens zwei funktionieren. Allerdings ist dies passiert nicht - Dank an PodDisruptionBudget. Dieser Parameter bestimmt die minimal erforderliche Anzahl an Arbeits-Pods. Zu wissen, dass einer der MongoDB-Pods nicht mehr funktioniert, und zu sehen, dass PodDisruptionBudget für MongoDB festgelegt ist minAvailable: 2, Kubernetes erlaubt Ihnen nicht, einen Pod zu löschen.
Fazit: Damit die Verschiebung (und tatsächlich die Neuerstellung) von Pods bei der Freigabe des Clusters ordnungsgemäß funktioniert, muss PodDisruptionBudget konfiguriert werden.
Horizontale Skalierung
Betrachten wir eine andere Situation. Es gibt eine Anwendung, die als Bereitstellung in Kubernetes ausgeführt wird. Der Benutzerverkehr gelangt zu seinen Pods (es gibt beispielsweise drei davon) und wir messen darin einen bestimmten Indikator (z. B. CPU-Auslastung). Wenn die Last zunimmt, zeichnen wir dies nach einem Zeitplan auf und erhöhen die Anzahl der Pods, um Anfragen zu verteilen.
Heutzutage muss dies in Kubernetes nicht mehr manuell erfolgen: Abhängig von den Werten der gemessenen Lastindikatoren wird eine automatische Erhöhung/Verringerung der Anzahl der Pods konfiguriert.
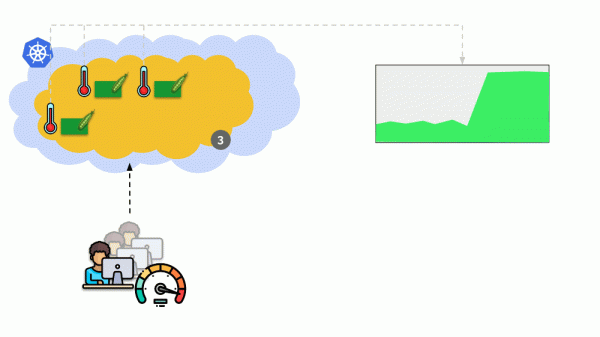
Die Hauptfragen hier sind: was genau gemessen werden soll и wie interpretieren erhaltene Werte (zur Entscheidungsfindung über die Änderung der Anzahl der Pods). Man kann vieles messen:

Wie geht das technisch? Sammeln Sie Metriken usw. — Ich habe im Bericht ausführlich darüber gesprochen . Und der wichtigste Ratschlag zur Auswahl der optimalen Parameter ist Experiment!
Es gibt (Auslastungssättigung und Fehler), dessen Bedeutung wie folgt ist. Auf welcher Grundlage ist es sinnvoll, beispielsweise PHP-FPM zu skalieren? Basierend auf der Tatsache, dass die Arbeitskräfte knapp werden, ist dies der Fall Nutzung. Und wenn die Arbeiter vorbei sind und neue Verbindungen nicht angenommen werden, ist dies bereits der Fall Sättigung. Beide Parameter müssen gemessen und abhängig von den Werten skaliert werden.
Statt einer Schlussfolgerung
Der Bericht hat eine Fortsetzung: über vertikale Skalierung und wie man die richtigen Ressourcen auswählt. Ich werde darüber in zukünftigen Videos sprechen - Abonnieren Sie, damit Sie nichts verpassen!
Videos und Folien
Video vom Auftritt (44 Minuten):

Präsentation des Berichts:
PS
Weitere Berichte zu Kubernetes auf unserem Blog:
- «» (Andrey Polovov; 8. April 2019 auf Saint HighLoad++);
- «» (Dmitry Stolyarov; 8. November 2018 auf HighLoad++);
- «» (Dmitry Stolyarov; 28. Mai 2018 auf der RootConf);
- «» (Dmitry Stolyarov; 7. November 2017 auf HighLoad++);
- «» (Dmitry Stolyarov; 6. Juni 2017 bei RootConf).
Source: habr.com
