

In Ich habe ein Framework für die Netzwerkautomatisierung beschrieben. Laut Rückmeldungen konnten einige Leute durch diesen ersten Ansatz bereits einige Fragen klarer verstehen. Das freut mich sehr, denn unser Ziel in diesem Zyklus ist es, nicht mit Python-Skripten über Ansible zu arbeiten, sondern ein System aufzubauen.
Dieses Framework legt auch die Reihenfolge fest, in der wir uns mit dem Thema auseinandersetzen werden.
Die Netzwerkvirtualisierung, die in dieser Ausgabe behandelt wird, passt nicht wirklich in das Thema ADSM, wo wir Automatisierung besprechen.
Aber lassen Sie uns einen anderen Blickwinkel einnehmen.
Bereits seit geraumer Zeit nutzen viele Dienste ein und dasselbe Netzwerk. Bei einem Telekommunikationsanbieter sind das zum Beispiel 2G, 3G, LTE, DSL und B2B. Bei Rechenzentren: Konnektivität für verschiedene Kunden, Internet, Blockspeicher, Objektspeicher.
Und alle Dienste erfordern eine Isolation voneinander. So entstanden Overlay-Netzwerke.
Und alle Dienste möchten nicht warten, bis jemand sie manuell konfiguriert. So kamen Orchestratoren und SDN ins Spiel.
Der erste Schritt zur systematischen Automatisierung von Netzwerken, genauer gesagt von Teilen davon, wurde schon lange unternommen und ist an vielen Stellen umgesetzt: VMWare, OpenStack, Google Compute Cloud, AWS, Facebook.
Genau darum werden wir uns heute kümmern.
Inhalt
- Gründe
- Terminologie
- Underlay – physisches Netzwerk
- Overlay – virtuelles Netzwerk
- Overlay vom ToR
- Overlay vom Host
- Am Beispiel von Tungsten Fabric
- Kommunikation innerhalb eines physischen Geräts
- Kommunikation zwischen VM, die auf verschiedenen physischen Geräten platziert sind
- Verbindung zur Außenwelt
- FAQ
- Fazit
- Nützliche Links
Gründe
Und da wir gerade darüber sprechen, sollten wir auch die Voraussetzungen für die Netzwerkvirtualisierung erwähnen. Tatsächlich hat dieser Prozess nicht erst gestern begonnen.
Wahrscheinlich haben Sie schon oft gehört, dass das Netzwerk immer der trägste Teil eines Systems war. Und das ist in vielerlei Hinsicht wahr. Das Netzwerk ist die Basis, auf der alles aufbaut, und Änderungen daran sind ziemlich schwierig – Dienste können es nicht ertragen, wenn das Netzwerk ausfällt. Oft kann die Stilllegung eines einzelnen Knotens einen Großteil der Anwendungen lahmlegen und viele Kunden beeinflussen. Teilweise deshalb kann das Netzwerkteam gegen Änderungen resistent sein – weil es im Moment irgendwie funktioniert (wir wissen möglicherweise sogar nicht, wie)), und hier muss etwas Neues eingerichtet werden, und es ist unklar, wie sich das auf das Netzwerk auswirken wird.
Um nicht darauf zu warten, dass die Netzwerktechniker VLANs bereitstellen und keine Dienste an jedem Knoten im Netzwerk eintragen zu müssen, haben die Leute Overlay-Netzwerke erfunden – eine Vielzahl von überlagerten Netzwerken: GRE, IPinIP, MPLS, MPLS L2/L3VPN, VXLAN, GENEVE, MPLSoverUDP, MPLSoverGRE usw.
Ihr Reiz liegt in zwei einfachen Aspekten:
- Es werden nur die Endknoten konfiguriert – die Transitgeräte bleiben unberührt. Das beschleunigt den Prozess erheblich und kann es sogar ermöglichen, die Abteilung für Netzwerkinfrastruktur aus dem Prozess der Einführung neuer Dienste herauszunehmen.
- Die Last ist tief in den Headern verborgen – die Transitknoten müssen nichts darüber wissen, über die Adressierung auf den Hosts oder die Routen des Overlay-Netzwerks. Das bedeutet, dass weniger Informationen in den Tabellen gespeichert werden müssen, was einfachere und günstigere Geräte ermöglicht.
In dieser nicht ganz vollständigen Ausgabe plane ich nicht, alle möglichen Technologien zu behandeln, sondern eher den Rahmen für die Arbeit mit Overlay-Netzwerken im Rechenzentrum zu skizzieren.
Die gesamte Serie wird ein Rechenzentrum beschreiben, das aus Reihen identischer Racks besteht, in denen die gleiche Serverhardware installiert ist.
Auf dieser Hardware werden virtuelle Maschinen/Container/Serverless-Dienste bereitgestellt.

Terminologie
Im Folgenden dem Server durch werde ich das Programm, das die Server-Seite der Client-Server-Kommunikation implementiert, benennen.
Physische Maschinen im Rack werden als Server nicht bezeichnet.
Physische Maschine — ein x86-Computer, der in einem Rack installiert ist. Der Begriff Hostwird am häufigsten verwendet. So werden wir sie auch «Maschine» oder Host.
Hypervisor — eine Anwendung, die auf einer physischen Maschine läuft und die physikalischen Ressourcen emuliert, auf denen die virtuellen Maschinen laufen. In der Literatur und im Netz wird das Wort «Hypervisor» manchmal synonym mit «Host» verwendet.
Virtuelle Maschine — das Betriebssystem, das auf der physischen Maschine über dem Hypervisor läuft. Für uns ist es innerhalb dieses Rahmens nicht so wichtig, ob es sich tatsächlich um eine virtuelle Maschine oder einfach um einen Container handelt. Wir werden dies als «VM«
Tenant — ein breiter Begriff, den ich in diesem Artikel als separaten Dienst oder Kunden definieren werde.
Multitenancy oder Multi-Tenancy – die Nutzung derselben Anwendung durch verschiedene Kunden/Dienste. Dabei wird die Isolierung der Kunden durch die Architektur der Anwendung und nicht durch separate Instanzen erreicht.
ToR – Top of the Rack Switch – ein in einem Rack installierter Switch, an den alle physischen Maschinen angeschlossen sind.
Neben der ToR-Topologie praktizieren verschiedene Anbieter auch End of Row (EoR) oder Middle of Row (obwohl Letzteres eine vernachlässigbare Seltenheit ist und ich die Abkürzung MoR nicht gesehen habe).
Unterlagenetzwerk oder physisches Netzwerk oder Underlay – die physische Netzwerkinfrastruktur: Switches, Router, Kabel.
Overlay-Netzwerk oder virtuelle Netzwerke oder Overlays – ein virtuelles Netzwerk von Tunneln, das über dem physischen Netzwerk arbeitet.
L3-Fabrik oder IP-Fabrik – eine beeindruckende menschliche Erfindung, die es ermöglicht, bei Gesprächen STP nicht zu wiederholen und TRILL nicht zu lernen. Ein Konzept, bei dem das gesamte Netzwerk bis zur Zugriffsebene ausschließlich L3 ist, ohne VLANs und folglich riesige, ausgedehnte Broadcast-Domänen. Woher der Begriff „Fabrik“ stammt, werden wir im nächsten Teil untersuchen.
SDN — Software Defined Network. Braucht kaum eine Einführung. Der Ansatz zur Netzwerkverwaltung, bei dem Änderungen im Netzwerk nicht von Menschen, sondern von Software vorgenommen werden. Bedeutet in der Regel, dass die Control Plane außerhalb der Endgeräte auf einen Controller verlagert wird.
NFV — Network Function Virtualization — die Virtualisierung von Netzwerkelementen, die besagt, dass einige Funktionen des Netzwerks in Form von virtuellen Maschinen oder Containern ausgeführt werden können, um die Einführung neuer Dienste zu beschleunigen, Service Chaining zu ermöglichen und die horizontale Skalierbarkeit zu vereinfachen.
VNF — Virtual Network Function. Ein spezifisches virtuelles Gerät: Router, Switch, Firewall, NAT, IPS/IDS usw.
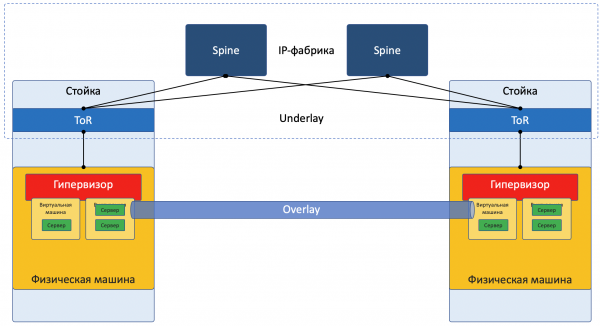
Ich vereinfache die Beschreibung jetzt absichtlich auf eine spezifische Implementierung, um den Leser nicht zu verwirren. Für eine tiefere Lektüre verweise ich auf den Abschnitt . Darüber hinaus verspricht Roma Gorge, der diesen Artikel für Ungenauigkeiten kritisiert, eine separate Ausgabe über Server- und Netvirtualisierungstechnologien zu schreiben, die detaillierter und sorgfältiger ausfallen wird.
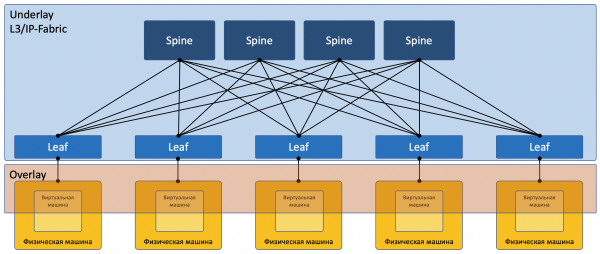
Die meisten Netzwerke lassen sich heute eindeutig in zwei Bereiche unterteilen:
Underlay — ein physisches Netzwerk mit stabiler Konfiguration.
Overlay — Abstraktion über dem Underlay zur Isolierung von Mandanten.
Das gilt sowohl für den Fall des Rechenzentrums (den wir in diesem Artikel behandeln werden) als auch für den ISP (den wir nicht behandeln werden, da dies bereits in ). Bei Unternehmensnetzwerken ist die Situation natürlich etwas anders.
Bild mit Fokus auf das Netzwerk:
Underlay
Underlay ist das physische Netzwerk: Hardware-Switches und Kabel. Geräte im Underlay wissen, wie sie die physischen Maschinen erreichen.
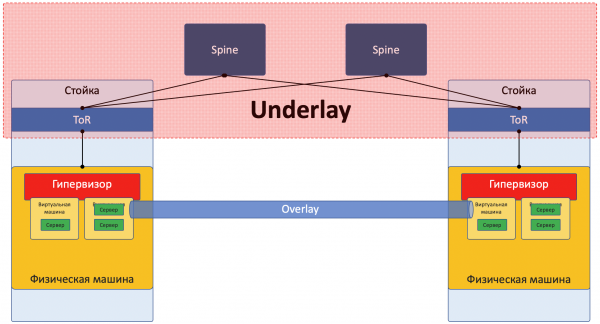
Es basiert auf standardisierten Protokollen und Technologien. Nicht zuletzt, weil Hardware-Geräte bis heute auf proprietärer Software laufen, die weder die Programmierung der Chips noch die Implementierung eigener Protokolle zulässt. Daher ist Kompatibilität mit anderen Anbietern und Standardisierung notwendig.
Jemand wie Google kann sich jedoch erlauben, eigene Switches zu entwickeln und auf gängige Protokolle zu verzichten. Aber LAN_DC ist nicht Google.
Das Underlay ändert sich vergleichsweise selten, da seine Aufgabe die grundlegende IP-Konnektivität zwischen physischen Maschinen ist. Underlay weiß nichts über die darauf laufenden Dienste, Kunden oder Mandanten — es muss lediglich das Paket von einer Maschine zur anderen liefern.
Underlay kann zum Beispiel so aussehen:
- IPv4+OSPF
- IPv6+ISIS+BGP+L3VPN
- L2+TRILL
- L2+STP
Das Underlay-Netzwerk wird klassisch konfiguriert: CLI/GUI/NETCONF.
Manuell, mit Skripten, proprietären Tools.
Eine detaillierte Betrachtung des Underlays wird in der nächsten Artikelreihe behandelt.
Overlay
Overlay ist ein virtuelles Netzwerk von Tunneln, das über das Underlay gespannt ist und es ermöglicht, dass VMs eines Kunden untereinander kommunizieren, während sie von anderen Kunden isoliert bleiben.
Die Kundendaten werden in Tunnel-Headern eingekapselt, um über das gemeinsame Netzwerk übertragen zu werden.
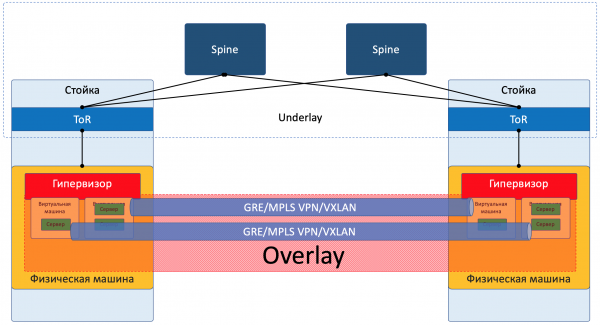
So können VMs eines Kunden (eines Dienstes) über das Overlay miteinander kommunizieren, ohne zu wissen, welchen tatsächlichen Weg das Paket nimmt.
Overlay könnte zum Beispiel so aussehen, wie ich bereits oben erwähnt habe:
- GRE-Tunnel
- VXLAN
- EVPN
- L3VPN
- GENEVE
Das Overlay-Netzwerk wird in der Regel über einen zentralen Controller eingerichtet und verwaltet. Von dort aus werden Konfiguration, Control Plane und Data Plane an die Geräte geliefert, die für das Routing und die Kapselung des Kundenverkehrs verantwortlich sind. Lassen Sie uns dies anhand von Beispielen näher erläutern. Ja, das ist SDN in reinster Form.
Es gibt zwei grundlegend verschiedene Ansätze zur Organisation eines Overlay-Netzwerks:
Es gibt zwei grundlegend unterschiedliche Ansätze zur Organisation von Overlay-Netzen:
- Overlay vom ToR
- Overlay vom Host
Overlay vom ToR
Ein Overlay kann auf einem Zugangs-Switch (ToR), der im Rack steht, beginnen, wie es beispielsweise bei einer VXLAN-Fabrik der Fall ist.
Dies ist ein bewährter Mechanismus in ISP-Netzen, und alle Anbieter von Netzwerkgeräten unterstützen ihn.
In diesem Fall muss der ToR-Switch jedoch in der Lage sein, verschiedene Dienste entsprechend zu trennen, und der Netzwerkadministrator muss in gewissem Maße mit den Administratoren der virtuellen Maschinen zusammenarbeiten und (auch automatisch) Änderungen an der Konfiguration der Geräte vornehmen.
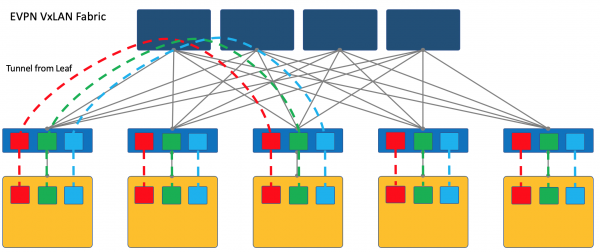
Hier verweise ich den Leser auf den Artikel über unseren alten Freund .
In diesem beschreiben ausführlich die Ansätze zum Aufbau eines DC-Netzes mit einer EVPN VXLAN-Fabrik.
Für ein tieferes Verständnis kann man das Buch von Cisco lesen .
Ich möchte anmerken, dass VXLAN nur eine Methode der Kapselung ist, und die Terminierung der Tunnel kann nicht nur am ToR, sondern auch am Host stattfinden, wie es beispielsweise bei OpenStack der Fall ist.
Allerdings ist eine VXLAN-Fabrik, bei der das Overlay am ToR beginnt, ein etablierter Entwurf für ein Overlay-Netzwerk.
Overlay vom Host
Ein anderer Ansatz besteht darin, Tunnel an End-Hosts zu beginnen und zu terminieren.
In diesem Fall bleibt das Netzwerk (Underlay) so einfach und statisch wie möglich.
Der Host übernimmt die notwendigen Kapselungen.
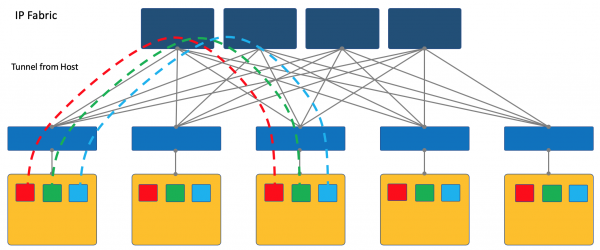
Dafür ist es notwendig, eine spezielle Anwendung auf den Hosts zu starten, aber es lohnt sich.
Erstens ist es einfacher, einen Client auf einer Linux-Maschine zu starten oder, sagen wir mal, - es ist überhaupt möglich - während man wahrscheinlich bei einem Switch auf proprietäre SDN-Lösungen zurückgreifen muss, was die Idee der Multi-Vendor-Fähigkeit untergräbt.
Zweitens kann der ToR-Switch in diesem Fall so einfach wie möglich gehalten werden, sowohl in Bezug auf das Control Plane als auch auf das Data Plane. Tatsächlich muss er dann nicht mit dem SDN-Controller kommunizieren und muss auch nicht die Netze/ARP aller angeschlossenen Clients speichern - es genügt, die IP-Adresse der physischen Maschine zu kennen, was die Switching-/Routing-Tabellen erheblich vereinfacht.
In der ADS-M-Serie wähle ich den Overlay-Ansatz vom Host aus - fortan sprechen wir nur darüber und werden nicht zur VXLAN-Fabrik zurückkehren.
Am einfachsten kann man das an Beispielen verdeutlichen. Als Versuchsträger nehmen wir die OpenSource-SDN-Plattform OpenContrail, die heute bekannt ist als .
Am Ende des Artikels werde ich einige Gedanken zur Analogie mit OpenFlow und OpenvSwitch präsentieren.
Am Beispiel von Tungsten Fabric
Auf jeder physischen Maschine gibt es vRouter — ein virtueller Router, der über die angeschlossenen Netzwerke und deren Kunden informiert ist — im Grunde ein PE-Router. Für jeden Kunden hält er eine isolierte Routing-Tabelle (VRF). Und genau der vRouter ermöglicht das Overlay-Tunneling.
Ein wenig mehr Informationen zum vRouter — am Ende des Artikels.
Jede VM, die auf dem Hypervisor läuft, verbindet sich über .
TAP — Terminal Access Point — eine virtuelle Schnittstelle im Linux-Kernel, die Netzwerkinteraktionen ermöglicht.
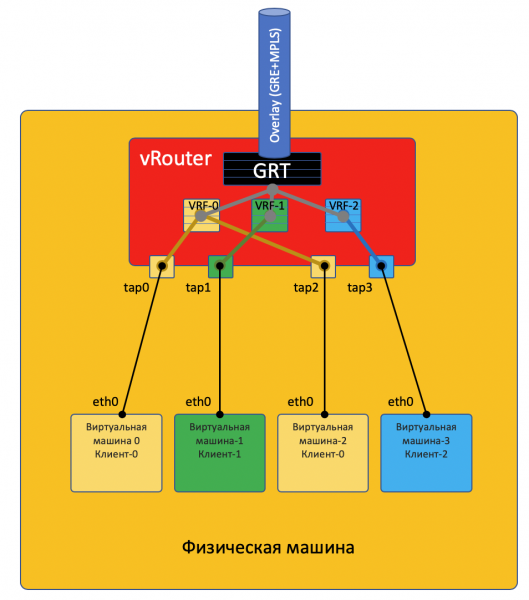
Wenn hinter dem vRouter mehrere Netzwerke vorhanden sind, wird für jedes ein virtuelles Interface erstellt, dem eine IP-Adresse zugewiesen wird — diese dient als Standardgateway.
Alle Netzwerke eines Kunden werden in eine VRF (eine Tabelle) eingeordnet, unterschiedliche in verschiedene.
Ich möchte anmerken, dass es nicht ganz so einfach ist und empfehle dem neugierigen Leser, zum Ende des Artikels zu gehen..
Um sicherzustellen, dass die vRouter miteinander kommunizieren können und damit auch die dahinterliegenden VMs, tauschen sie Routing-Informationen über den SDN-Controller.
Um in die Außenwelt zu gelangen, gibt es einen Ausgang aus der Matrix – das virtuelle Netzwerk-Gateway VNGW – Virtual Network GateWay (dieser Begriff ist von mir).
Jetzt betrachten wir Beispiele für Kommunikationen – dann wird es klar.
Kommunikation innerhalb eines physischen Geräts
VM0 möchte ein Paket an VM2 senden. Nehmen wir vorerst an, dass dies VMs eines Kunden sind.
Data Plane
- VM0 hat eine Standardroute über sein Interface eth0. Das Paket wird dorthin gesendet.
Dieses Interface eth0 ist tatsächlich virtuell mit dem virtuellen Router vRouter über das TAP-Interface tap0 verbunden. - Der vRouter analysiert, über welches Interface das Paket empfangen wurde, d.h. zu welchem Kunden (VRF) es gehört, und vergleicht die Zieladresse mit der Routing-Tabelle dieses Clients.
- Stellt er fest, dass der Empfänger auf demselben Rechner über einen anderen Port ist, sendet der vRouter das Paket einfach ohne zusätzliche Header weiter – zu diesem Zweck gibt es bereits einen ARP-Eintrag auf dem vRouter.
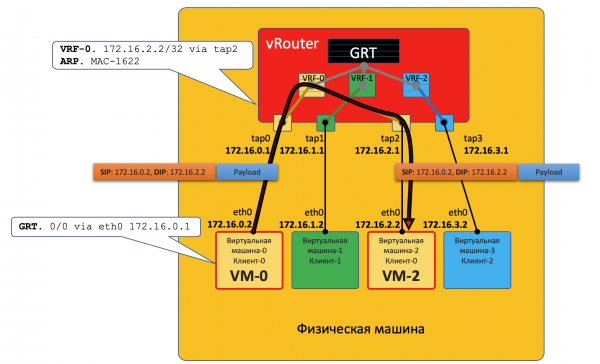
In diesem Fall gelangt das Paket nicht ins physische Netzwerk – es wurde intern im vRouter geroutet.
Control Plane
Der Hypervisor informiert beim Start der virtuellen Maschine:
- Ihre eigene IP-Adresse.
- Die Standardroute führt über die IP-Adresse des vRouters in diesem Netzwerk.
Der vRouter teilt dem Hypervisor über eine spezielle API mit:
- Dass ein virtuelles Interface erstellt werden muss.
- Welches Virtual Network für sie (VM) erstellt werden muss.
- An welches VRF es (VN) gebunden werden soll.
- Einen statischen ARP-Eintrag für diese VM – welches Interface mit ihrer IP-Adresse verbunden ist und welche MAC-Adresse ihm zugeordnet ist.
Und erneut wurde das tatsächliche Interaktionsverfahren zur besseren Verständlichkeit vereinfacht.
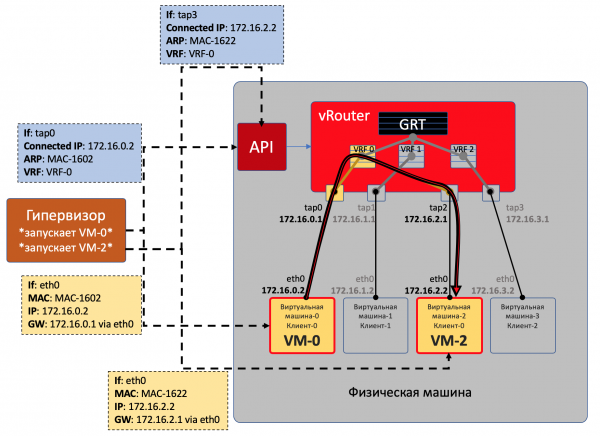
So sieht der vRouter alle VMs eines Kunden auf dieser Maschine als direkt angeschlossene Netzwerke und kann selbst zwischen ihnen routen.
VM0 und VM1 gehören jedoch unterschiedlichen Kunden an und befinden sich daher in verschiedenen vRouter-Tabellen.
Ob sie direkt miteinander kommunizieren können, hängt von den Einstellungen des vRouters und dem Design des Netzwerks ab.
Wenn beide Kunden-VMs öffentliche Adressen verwenden oder NAT direkt im vRouter erfolgt, kann eine direkte Route zum vRouter eingerichtet werden.
Andernfalls könnte es zu Überschneidungen in den Adressräumen kommen – man muss über einen NAT-Server gehen, um eine öffentliche Adresse zu erhalten – das ist vergleichbar mit dem Zugang zu externen Netzwerken, was weiter unten erklärt wird.
Kommunikation zwischen VM, die auf verschiedenen physischen Geräten platziert sind
Data Plane
- Der Beginn ist genau derselbe: VM-0 sendet ein Paket an VM-7 (172.17.3.2) gemäß seiner Standardeinstellung.
- vRouter empfängt es und erkennt diesmal, dass der Empfänger sich auf einer anderen Maschine befindet und über das Tunnel Tunnel0 erreichbar ist.
- Zuerst fügt es ein MPLS-Label hinzu, das das entfernte Interface identifiziert, damit vRouter auf der anderen Seite bestimmen kann, wo dieses Paket platziert werden soll, ohne zusätzliche Umwege.
- Tunnel0 hat die Quelladresse 10.0.0.2 und den Empfänger: 10.0.1.2.
vRouter fügt GRE- (oder UDP-)Headers und eine neue IP-Adresse zum ursprünglichen Paket hinzu. - In der Routing-Tabelle hat vRouter eine Standardroute über die Adresse ToR1 10.0.0.1. Dorthin wird das Paket gesendet.

- ToR1 als Teil des Underlay-Netzwerks weiß (z.B. über OSPF), wie man zu 10.0.1.2 gelangt, und sendet das Paket über den festgelegten Pfad. Beachten Sie, dass hier ECMP aktiviert ist. In der Abbildung gibt es zwei Next Hops, und verschiedene Ströme werden basierend auf Hashing auf diese verteilt. In einer echten Fabrik könnte es hier eher vier Next Hops geben.
Es ist dabei nicht notwendig, zu wissen, was sich unter dem externen IP-Header befindet. Das heißt, unter der IP kann beispielsweise eine Zusammenstellung von IPv6 über MPLS über Ethernet über MPLS über GRE über... sein.
- Entsprechend entfernt der vRouter auf der empfangenden Seite GRE und versteht anhand des MPLS-Tags, welches Interface das Paket erhalten soll, entpackt es und sendet es im ursprünglichen Zustand an den Empfänger.
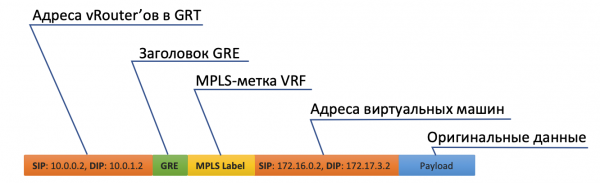
Control Plane
Beim Start der Maschine geschieht alles, was oben beschrieben wurde.
Und zusätzlich das Folgende:
- Für jeden Kunden weist der vRouter ein MPLS-Tag zu. Dies ist ein Service-Tag für L3VPN, mit dem die Kunden innerhalb einer physischen Maschine getrennt werden.
Tatsächlich wird das MPLS-Tag vom vRouter immer zugewiesen, denn es ist im Voraus nicht bekannt, ob die Maschine nur mit anderen Maschinen über denselben vRouter interagiert, und es ist wahrscheinlich sogar nicht so.
- Der vRouter stellt eine Verbindung zum SDN-Controller über das BGP-Protokoll (oder ein ähnliches – im Fall von TF ist es XMPP 0_o) her.
- Über diese Sitzung informiert der vRouter den SDN-Controller über die Routen zu den angeschlossenen Netzwerken:
- Netzadresse
- Kapselungsmethode (MPLSoGRE, MPLSoUDP, VXLAN)
- MPLS-Tag des Kunden
- Seine IP-Adresse als nexthop
- Der SDN-Controller erhält solche Routen von allen angeschlossenen vRoutern und spiegelt sie an andere. Das heißt, er fungiert als Route Reflector.
Das Gleiche geschieht auch in die entgegengesetzte Richtung.
Overlay kann sich jede Minute ändern. So funktioniert es in öffentlichen Clouds, wenn Kunden regelmäßig ihre virtuellen Maschinen starten und stoppen.
Der zentrale Controller übernimmt alle Herausforderungen, die mit der Konfiguration und Kontrolle der Switching/Routing-Tabellen auf vRouter verbunden sind.
Groß gesagt, verbindet sich der Controller mit allen vRoutern über BGP (oder ein ähnliches Protokoll) und überträgt einfach die Routing-Informationen. BGP hat beispielsweise bereits eine Address-Family für die Übertragung der Kapselungsmethode. oder .
Dabei bleibt die Konfiguration des Underlay-Netzwerks in keiner Weise unverändert, die übrigens um ein Vielfaches schwerer zu automatisieren ist, und es ist einfacher, sie mit einem ungeschickten Handgriff zu beschädigen.
Verbindung zur Außenwelt
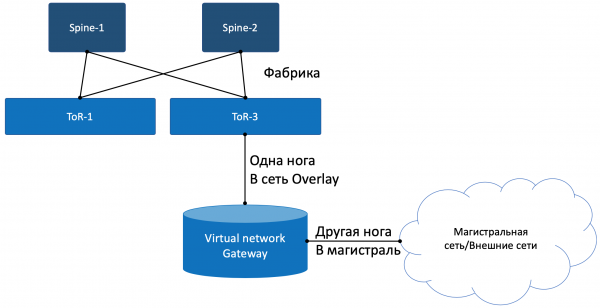
Irgendwo muss die Simulation enden, und es ist notwendig, aus der virtuellen Welt in die reale zu treten. Und ein Gateway-Telefon ist erforderlich.
Es werden zwei Ansätze praktiziert:
- Ein Hardware-Router wird installiert.
- Es wird eine Art Appliance gestartet, die die Funktionen eines Routers implementiert (ja, ja, nach SDN haben wir es jetzt auch mit VNF zu tun). Nennen wir ihn virtueller Gateway.
Der Vorteil des zweiten Ansatzes mit kostengünstiger horizontaler Skalierbarkeit liegt darin, dass nicht genügend Leistung vorhanden ist – eine weitere virtuelle Maschine mit einem Gateway wurde gestartet. Auf jeder physischen Maschine, ohne dass man nach freien Racks, Einheiten, Stromanschlüssen suchen, die Hardware kaufen, transportieren, installieren, verkabeln, konfigurieren und dann noch fehlerhafte Komponenten austauschen muss.
Die Nachteile eines virtuellen Gateways liegen darin, dass die physische Routereinheit um ein Vielfaches leistungsfähiger ist als eine multicore virtuelle Maschine, während die Software, die auf die Hardwarebasis abgestimmt ist, deutlich stabiler funktioniert. (nein). Man kann auch nicht leugnen, dass das Hardware-Software-System einfach funktioniert, nur eine Konfiguration benötigt, während der Start und Betrieb eines virtuellen Gateways eine Aufgabe für versierte Ingenieure ist.
Mit einem seiner Füße schaut das Gateway in das Overlay-Virtualnetzwerk, wie eine gewöhnliche virtuelle Maschine, und kann mit allen anderen VMs interagieren. Gleichzeitig kann es die Netzwerke aller Kunden terminieren und somit das Routing zwischen ihnen durchführen.
Mit dem anderen Bein blickt der Gateway bereits ins Backbone-Netz und weiß, wie man ins Internet gelangt.
Data Plane
Der Prozess sieht folgendermaßen aus:
- VM-0 sendet ein Paket an einen Empfänger in der Außenwelt (185.147.83.177) über das Interface eth0, wobei der Standard weiterhin der gleiche vRouter ist.
- Der vRouter empfängt dieses Paket und führt eine Zieladresse-Suche in der Routing-Tabelle durch – er findet die Standardroute über den Gateway VNGW1 durch Tunnel 1.
Außerdem sieht er, dass es sich um einen GRE-Tunnel mit SIP 10.0.0.2 und DIP 10.0.255.2 handelt, und dass zuerst das MPLS-Label des Kunden gesetzt werden muss, das VNGW1 erwartet. - Der vRouter verpackt das ursprüngliche Paket in MPLS-, GRE- und neuen IP-Headern und sendet es standardmäßig an die Adresse ToR1 10.0.0.1.
- Das zugrunde liegende Netzwerk liefert das Paket an den Gateway VNGW1.
- Der Gateway VNGW1 entfernt die Tunnel-Header GRE und MPLS, sieht die Zieladresse, bezieht sich auf seine Routing-Tabelle und erkennt, dass es ins Internet geht – also über Full View oder Default. Bei Bedarf wird eine NAT-Übersetzung durchgeführt.
- Von VNGW zu Border könnte es ein gewöhnliches IP-Netz sein, was jedoch unwahrscheinlich ist.
Es könnte ein klassisches MPLS-Netz (IGP+LDP/RSVP TE) sein oder eine Rückfabrik mit BGP LU oder ein GRE-Tunnel von VNGW bis zur Border über das IP-Netz.
VNGW1 führt die notwendigen Kapselungen durch und sendet das ursprüngliche Paket in Richtung Border.
Der Rückverkehr durchläuft die gleichen Schritte in umgekehrter Reihenfolge.
- Der Border sendet das Paket an VNGW1 weiter.
- Dieser analysiert das Paket, prüft die Zieladresse und stellt fest, dass sie über Tunnel Tunnel1 (MPLSoGRE oder MPLSoUDP) erreichbar ist.
- Daraufhin fügt er die MPLS-Markierung, den GRE/UDP-Header und die neue IP hinzu und sendet es an sein ToR3 10.0.255.1.
Die Zieladresse des Tunnels ist die IP-Adresse des vRouters, hinter dem die Ziel-VM steht – 10.0.0.2. - Das unterliegende Netzwerk liefert das Paket an den entsprechenden vRouter.
- Der Ziel-vRouter entfernt GRE/UDP, bestimmt das Interface anhand der MPLS-Markierung und sendet das rohe IP-Paket an sein TAP-Interface, das mit eth0 der VM verbunden ist.
Control Plane
VNGW1 stellt eine BGP-Nachbarschaft mit dem SDN-Controller her, von dem er alle Routinginformationen über die Kunden erhält: Welcher IP-Adresse (vRouter) welcher Kunde zugeordnet ist und welche MPLS-Markierung er hat.
Ähnlich teilt er dem SDN-Controller die Standardroute mit der Markierung dieses Kunden mit und gibt sich selbst als nexthop an. Diese Standardroute gelangt dann zu den vRoutern.
Am VNGW erfolgt normalerweise die Aggregation von Routen oder die NAT-Übersetzung.
In einer Sitzung mit Border-Gateways oder Route-Reflectoren überträgt er genau diese aggregierte Route. Von ihnen erhält er die Standardroute, sei es Full-View oder etwas anderes.
In Bezug auf Kapselung und Datenverkehrsaustausch unterscheidet sich VNGW nicht von vRouter.
Wenn wir den Bereich etwas erweitern, können wir zu VNGW und vRoutern auch andere Netzwerkgeräte hinzufügen, wie Firewalls, Reinigungs- oder Anreicherungsfarmen, IPS und so weiter.
Durch die schrittweise Erstellung von VRF und die richtige Ankündigung von Routen kann man den Datenverkehr nach Belieben lenken, was als Service Chaining bezeichnet wird.
Das bedeutet, dass der SDN-Controller hier als Route-Reflector zwischen VNGW, vRoutern und anderen Netzwerkgeräten fungiert.
Doch tatsächlich gibt der Controller auch Informationen über ACL und PBR (Policy Based Routing) weiter, was dazu führt, dass einzelne Datenströme nicht den Pfad folgen, den die Route vorgibt.
FAQ
Warum machst du ständig diese Bemerkung zu GRE/UDP?
Nun, das ist eigentlich spezifisch für Tungsten Fabric – man kann es durchaus ignorieren.
Aber falls es relevant ist, hat TF, als es noch OpenContrail war, beide Kapselungsarten unterstützt: MPLS in GRE und MPLS in UDP.
UDP hat den Vorteil, dass im Quellportfeld seines Headers sehr einfach eine Hash-Funktion der ursprünglichen IP+Proto+Port kodiert werden kann, was eine Lastverteilung ermöglicht.
Im Fall von GRE gibt es leider nur äußere IP- und GRE-Header, die für den gesamten inkapsulierten Traffic gleich sind. Eine Lastverteilung ist hier nicht möglich, da nur wenige so tief in das Paket eindringen können.
Bis vor kurzem konnten Router, wenn sie dynamische Tunnel unterstützten, lediglich MPLSoGRE. Erst ganz kürzlich lernten sie, auch MPLSoUDP zu verwenden. Daher muss immer auf die Möglichkeit von zwei unterschiedlichen Inkapsulierungen hingewiesen werden.
Fairerweise sollte man erwähnen, dass TF auch die L2-Konnektivität über VXLAN unterstützt.
Du hast versprochen, Parallelen zu OpenFlow zu ziehen.
Diese sind wirklich naheliegend. Der vSwitch in OpenStack macht sehr ähnliche Dinge, indem er VXLAN verwendet, welches übrigens auch einen UDP-Header hat.
Im Data Plane arbeiten sie ungefähr gleich, während sich das Control Plane erheblich unterscheidet. Tungsten Fabric verwendet XMPP zur Zustellung von Routeninformationen an den vRouter, während in OpenStack OpenFlow genutzt wird.
Kannst du etwas mehr über den vRouter erzählen?
Er besteht aus zwei Teilen: dem vRouter Agent und dem vRouter Forwarder.
Der erste wird im User Space des Host-Betriebssystems gestartet und kommuniziert mit dem SDN-Controller, indem er Informationen über Routen, VRF und ACL austauscht.
Der zweite implementiert die Datenebene — normalerweise im Kernel Space, kann aber auch auf SmartNICs ausgeführt werden — Netzwerkarten mit CPU und einem separaten programmierbaren Switch-Chip, was die CPU-Belastung des Host-Systems reduziert und die Netzwerkgeschwindigkeit sowie Vorhersehbarkeit erhöht.
Es ist auch möglich, dass der vRouter eine DPDK-Anwendung im User Space ist.
Der vRouter-Agent überträgt die Einstellungen an den vRouter Forwarder.
Was ist ein virtuelles Netzwerk?
Ich erwähnte zu Beginn des Artikels das VRF, dass jeder Mandant mit seinem eigenen VRF verbunden ist. Und während das für ein oberflächliches Verständnis der Funktionsweise des Overlay-Netzwerks ausreichte, ist es beim nächsten Durchgang notwendig, genauere Angaben zu machen.
In Virtualisierungssystemen wird die Entität Virtual Network (dies ist als Eigenname zu betrachten) normalerweise separat von den Clients/Tenants/virtuellen Maschinen behandelt — es handelt sich um eine eigenständige Einheit. Dieses Virtual Network kann dann über Schnittstellen an einen Tenant, einen anderen oder sogar mehrere angeschlossen werden. So wird beispielsweise Service Chaining implementiert, bei dem der Datenverkehr durch bestimmte Knoten in der gewünschten Reihenfolge geleitet wird, indem einfach die Virtual Networks in der richtigen Reihenfolge erstellt und zugewiesen werden.
Daher gibt es keine direkte Entsprechung zwischen Virtual Network und Tenant.
Fazit
Dies ist eine sehr oberflächliche Beschreibung der Funktionsweise eines virtuellen Netzwerks mit Overlay vom Host und dem SDN-Controller. Aber unabhängig davon, welche Virtualisierungsplattform Sie heute verwenden, wird sie ähnlich funktionieren, egal ob es sich um VMWare, ACI, OpenStack, CloudStack, Tungsten Fabric oder Juniper Contrail handelt. Sie unterscheiden sich in den Arten der Kapselung und Header, den Protokollen zur Informationsübertragung an die Endgeräte, aber das Prinzip eines programmierbaren Overlay-Netzes, das über einem vergleichsweise einfachen und statischen Underlay-Netzwerk arbeitet, bleibt gleich.
Es lässt sich sagen, dass der Bereich der Erstellung von privaten Clouds, basierend auf SDN mit Overlay-Netzwerken, derzeit die Oberhand gewonnen hat. Das bedeutet jedoch nicht, dass OpenFlow in der modernen Welt keinen Platz hat – es wird in OpenStack und in VMWare NSX verwendet, und soweit ich weiß, nutzt Google es zur Einrichtung des Underlay-Netzwerks.
Hier unten habe ich Links zu ausführlicheren Materialien aufgeführt, falls Sie das Thema tiefer erforschen möchten.
Und wie steht es um unser Underlay?
Im Grunde genommen nichts. Es hat sich die ganze Zeit über nicht verändert. Alles, was es im Falle eines Overlays vom Host aus tun muss, ist, die Routen und ARPs zu aktualisieren, sobald vRouter/VNGW erscheinen und verschwinden, und die Pakete zwischen ihnen zu transportieren.
Lassen Sie uns eine Liste der Anforderungen an das Underlay-Netzwerk formulieren.
- Fähig sein, ein Routing-Protokoll, in unserem Fall – BGP, zu unterstützen.
- Eine breite Bandbreite haben, idealerweise ohne Überbuchung, damit keine Pakete aufgrund von Überlastungen verloren gehen.
- Die Unterstützung von ECMP ist ein wesentlicher Bestandteil der Fabrik.
- In der Lage sein, QoS bereitzustellen, einschließlich anspruchsvoller Dinge wie ECN.
- Die Unterstützung von NETCONF – eine Vorbereitung für die Zukunft.
Ich habe nur wenig Zeit damit verbracht, mich mit dem Underlay-Netzwerk zu beschäftigen. Das liegt daran, dass ich mich in dieser Reihe genau darauf konzentrieren werde, während wir das Overlay nur am Rande behandeln.
Offensichtlich schränke ich uns alle stark ein, indem ich als Beispiel ein Rechenzentrum verwende, das auf Clos-Netzwerk-Architektur mit reinem IP-Routing und Overlay von Hosts basiert.
Ich bin jedoch überzeugt, dass jedes Netzwerk, das ein Design hat, in formalen Begriffen beschrieben und automatisiert werden kann. Mein Ziel ist es hier, die Ansätze zur Automatisierung zu verstehen und nicht alle durch eine allgemeine Lösung zu verwirren.
Im Rahmen des ADSM planen Roman Gorge und ich, eine spezielle Ausgabe über die Virtualisierung von Rechenressourcen und deren Interaktion mit der Netzwerkvirtualisierung zu veröffentlichen. Bleiben Sie dran.
Nützliche Links
- .
- . 6 Stunden über Yandex.Cloud, wo auch das virtuelle Netzwerk auf TF behandelt wird.
- .
- . Hier wird das gesamte Rechenzentrum beschrieben, einschließlich Underlay, Overlay, Ansätze zur Multi-Homing und Management.
Vielen Dank
- — dem ehemaligen Gastgeber des Podcasts linkmeup und jetzt Experten für Cloud-Plattformen. Für Kommentare und Korrekturen. Wir freuen uns auch auf seinen ausführlicheren Artikel über Virtualisierung in naher Zukunft.
- — meinem Kollegen und Experten für die Entwicklung virtueller Netzwerke. Für Kommentare und Korrekturen.
- — meinem Kollegen und Experten für Tungsten Fabric. Für Kommentare und Korrekturen.
- — Illustrator für linkmeup. Für die KDPV.
- Alexander Limonow. Für das Meme «automato».
Quelle: habr.com
