

In den ersten beiden Artikeln habe ich das Thema Automatisierung angesprochen und einen Rahmen skizziert, im zweiten Artikel habe ich einen Exkurs zur virtuellen Netzwerktechnik gemacht, die als erster Ansatz zur Automatisierung der Konfiguration von Diensten dient.
Jetzt ist es an der Zeit, das Schema des physischen Netzwerks zu zeichnen.
Wenn Sie nicht versiert im Umgang mit Einrichtungen von Rechenzentrumsnetzen sind, empfehle ich Ihnen dringend, mit der .
Alle Ausgaben:
Die in dieser Serie beschriebenen Praktiken sollten auf Netzwerke jeglicher Art, Größe und mit beliebiger Vielseitigkeit von Anbietern anwendbar sein (nicht). Allerdings lässt sich kein universelles Beispiel für die Anwendung dieser Ansätze beschreiben. Daher konzentriere ich mich auf die moderne Architektur von Rechenzentrumsnetzwerken: .
Die DCI realisieren wir über MPLS L3VPN.
Über dem physischen Netzwerk arbeitet ein Overlay-Netzwerk vom Host aus (das kann VXLAN von OpenStack oder Tungsten Fabric oder etwas anderes sein, das vom Netzwerk lediglich eine grundlegende IP-Konnektivität erfordert).
In diesem Fall erhalten wir ein relativ einfaches Automatisierungsszenario, da wir viel Hardware haben, die auf die gleiche Weise konfiguriert ist.
Wir wählen ein sphärisches Rechenzentrum im Vakuum:
- Eine Designversion überall.
- Zwei Anbieter, die zwei Netzwerkebenen bilden.
- Ein Rechenzentrum ähnelt dem anderen wie zwei Erbsen in einer Schote.
Inhalt
- Physikalische Topologie
- Routing
- IP-Plan
- Labor
- Fazit
- Nützliche Links
Lassen Sie unseren Serviceanbieter LAN_DC beispielsweise Schulungsvideos über das Überleben in steckengebliebenen Aufzügen hosten.
In Großstädten erfreut sich dies großer Beliebtheit, weshalb viele physische Maschinen benötigt werden.
Zuerst beschreibe ich das Netzwerk ungefähr so, wie ich es mir wünsche. Danach vereinfache ich es für das Labor.
Physikalische Topologie
Standorte
LAN_DC wird 6 Rechenzentren haben:
- Russland (RU):
- Moskau (msk)
- Kazan (kzn)
- Spanien (SP):
- Barcelona (bcn)
- Málaga (mlg)
- China (CN):
- Shanghai (sha)
- Xi'an (sia)

Innerhalb des Rechenzentrums (Intra-DC)
In allen Rechenzentren identische interne Netzwerke basierend auf Clos-Topologie.
Was sind Clos-Netzwerke und warum genau diese – in einem separaten .
In jedem Rechenzentrum gibt es 10 Racks mit Maschinen, sie werden nummeriert als A, B, C Und so weiter.
In jedem Rack befinden sich 30 Maschinen. Diese werden uns nicht interessieren.
In jedem Rack befindet sich zudem ein Switch, der alle Maschinen verbindet – das ist der Top-of-Rack-Switch – ToR oder, in den Begriffen der Clos-Fabrik, werden wir ihn Leaf.

vergleichen. Hier ist das allgemeine Schema der Fabrik.
Wir werden sie benennen als XXX-leafY, wobei XXX – eine dreibuchstabige Abkürzung für das Rechenzentrum, und Y – die Seriennummer. Zum Beispiel, kzn-leaf11.
In meinen Artikeln gestatte ich mir, die Begriffe Leaf und ToR recht flexibel als Synonyme zu verwenden. Dabei muss jedoch beachtet werden, dass das nicht korrekt ist.
ToR ist ein Switch, der in einem Rack installiert ist, an den Maschinen angeschlossen werden.
Leaf ist die Rolle eines Geräts im physischen Netzwerk oder der Switch der ersten Ebene in Clos-Terminologie.
Das bedeutet, Leaf != ToR.
Ein Leaf kann beispielsweise ein EndofRow-Switch sein.
Dennoch werden wir in diesem Artikel weiterhin so tun, als wären sie Synonyme.
Jeder ToR-Switch ist seinerseits mit vier übergeordneten Aggregations-Switches verbunden – Spine. Für Spine ist jeweils ein Rack im Rechenzentrum vorgesehen. Wir werden sie ähnlich benennen: XXX-spineY.
In diesem Rack wird auch die Netzwerkausrüstung stehen, die die Verbindung zwischen den Rechenzentren herstellt – zwei Router mit MPLS an Bord. Aber grundsätzlich sind das die gleichen ToR-Geräte. Das heißt, aus der Sicht der Spine-Switches spielt es keine Rolle, ob es sich um einen normalen ToR mit angeschlossenen Maschinen oder um einen Router für DCI handelt – beide leiten Daten weiter.
Solche speziellen ToR-Geräte werden genannt Edge-leaf. Wir werden sie XXX-edgeY.
nennen. So wird es aussehen.
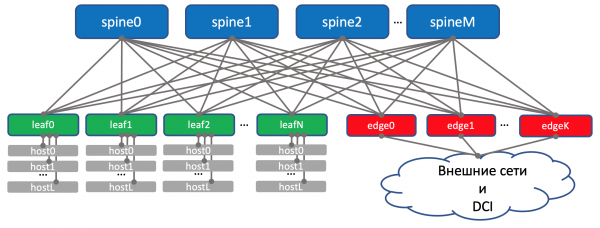
In dem obigen Diagramm habe ich tatsächlich Edge und Leaf auf derselben Ebene platziert. haben uns gelehrt, den Uplink (von hier stammt auch der Begriff) als Verbindungen nach oben zu betrachten. Hier verläuft jedoch der 'Uplink' DCI nach unten, was die gewohnte Logik etwas durcheinanderbringt. In großen Netzwerken, in denen die Rechenzentren weiter in kleinere Einheiten unterteilt werden – PODs‘(Point Of Delivery), werden separate Edge-PODsfür DCI und den Zugang zu externen Netzwerken выделены.
Zur besseren Verständlichkeit werde ich dennoch Edge über Spine zeichnen, wobei wir im Hinterkopf behalten, dass es keinen intelligentes Verhalten auf Spine gibt und keine Unterschiede im Betrieb mit normalen Leaf- und Edge-leaf-Geräten (obwohl es hier Nuancen geben kann, aber im Großen und Ganzen ist das so).
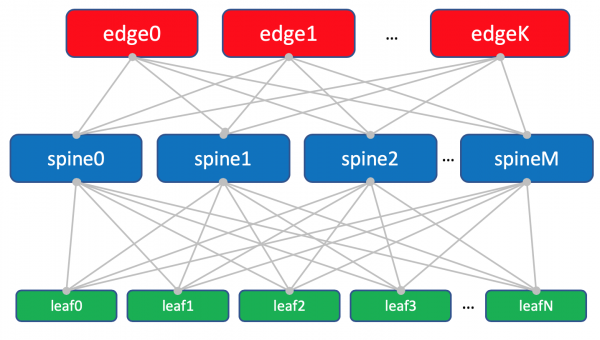
Das Schema der Fabrik mit Edge-leafs.
Die Leaf-, Spine- und Edge-Geräte bilden ein Underlay-Netzwerk oder eine Fabrik.
Die Aufgabe der Netzwerkfabrik (Underlay), wie wir bereits festgestellt haben, ist sehr einfach: IP-Konnektivität zwischen den Maschinen sowohl innerhalb eines einzelnen Rechenzentrums als auch zwischen ihnen sicherzustellen. Das ist auch der Grund, warum das Netzwerk als Fabrik bezeichnet wird, ähnlich wie die Fabrik der Switching-Technologie innerhalb modularer Netzwerkschalen, über die man mehr in
SDM14 .
Die Fabrik ist vollständig L3. Keine VLANs, kein Broadcast – unsere hervorragenden Programmierer im LAN_DC können Anwendungen schreiben, die im L3-Paradigma leben, und virtuelle Maschinen benötigen keine Live-Migration mit der Beibehaltung der IP-Adresse.
Und noch einmal: Die Antwort auf die Frage, warum Fabrik und warum L3 – findet man in einem separaten
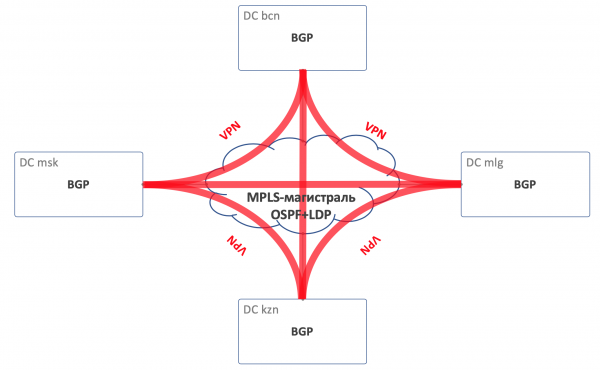
DCI – Data Center Interconnect (Inter-DC) .
Die DCI wird mithilfe von Edge-Leaf organisiert, also sind sie unser Ausgangspunkt für die Anbindung an die Backbone-Strukturen.
Zur Vereinfachung nehmen wir an, dass die Rechenzentren durch direkte Verbindungen miteinander verbunden sind.
Lassen wir externe Verbindungen außer Acht.
Wir werden die externe Vernetzung ausschließen.
Ich bin mir bewusst, dass ich jedes Mal, wenn ich ein Element entferne, das Netzwerk erheblich vereinfache. Und bei der Automatisierung unseres abstrahierten Netzwerks wird alles gut sein, aber in der realen Welt wird es Einschränkungen geben.
Das ist richtig. Dennoch besteht das Ziel dieser Reihe darin, über Ansätze nachzudenken und daran zu arbeiten, anstatt heldenhaft erfundene Probleme zu lösen.
Auf den Edge-Leafs wird das Underlay in ein VPN gelegt und über den MPLS-Kern übertragen (dieser direkte Link).
So sieht das High-Level-Diagramm aus.

Routing
Für die Routing innerhalb des Rechenzentrums werden wir BGP verwenden.
Im MPLS-Kern OSPF+LDP.
Für DCI, also die Organisation der Konnektivität im Underlay – BGP L3VPN über MPLS.
Allgemeines Routingdiagramm
Im Fabriknetzwerk wird es keine OSPF und ISIS (das in der Russischen Föderation verbotene Routing-Protokoll) geben.
Das bedeutet, dass es keine Auto-Discovery und Berechnung der kürzesten Wege geben wird – lediglich eine manuelle (in Wirklichkeit automatisierte – schließlich reden wir hier über Automatisierung) Konfiguration des Protokolls, der Nachbarschaften und der Richtlinien.
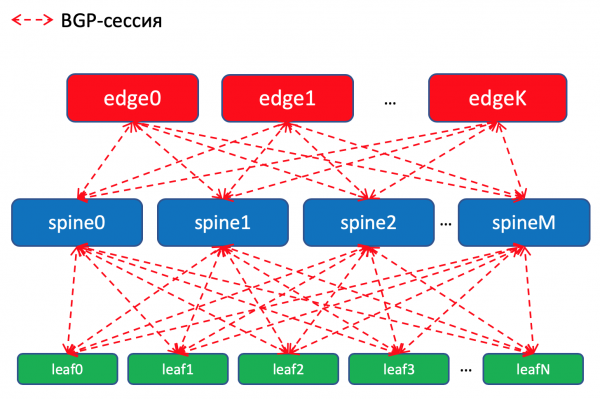
BGP-Routing-Diagramm innerhalb des Rechenzentrums
Warum BGP?
Zu diesem Thema gibt es von Facebook und Arista, in dem erläutert wird, wie man sehr große Rechenzentren über BGP. Das klingt fast wie ein Kunstwerk, ich kann es für einen entspannten Abend sehr empfehlen.
Ein ganzer Abschnitt in meinem Artikel widmet sich diesem Thema. Wohin ich Sie auch .
Kurz gesagt, keinen IGP eignen sich für die Netzwerke großer Rechenzentren, wo die Anzahl der Netzwerkgeräte in die Tausende geht.
Außerdem ermöglicht der Einsatz von BGP überall, sich nicht auf die Unterstützung mehrerer verschiedener Protokolle und die Synchronisation zwischen ihnen zu konzentrieren.
Ehrlich gesagt, auf unserer Fabrik, die mit großer Wahrscheinlichkeit nicht schnell wachsen wird, wäre OSPF mehr als ausreichend. Das sind tatsächlich die Probleme von Megaskalierern und Cloud-Titanen. Aber lassen Sie uns nur für ein paar Ausgaben träumen, dass wir das brauchen, und BGP verwenden, wie es Peter Lapuchov vorschlug.
Routing-Politiken
Auf den Leaf-Switches importieren wir die Präfixe aus den Underlay-Schnittstellen mit den Netzwerken in BGP.
Wir werden eine BGP-Session zwischen jedem Leaf-Spine-Paar haben, in dem diese Underlay-Präfixe im Netzwerk angekündigt werden.
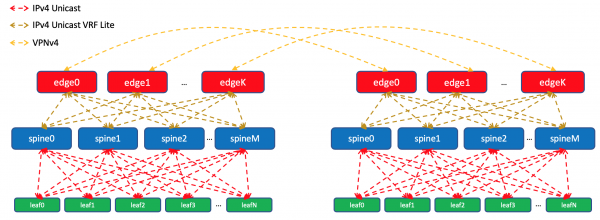
Innerhalb eines Rechenzentrums werden wir die spezifischen Daten, die wir in das Netzwerk importiert haben, verbreiten. Auf den Edge-Leafs werden wir sie aggregieren und in entfernte Rechenzentren ankündigen sowie bis zu den Toren hinunterleiten. Das bedeutet, dass jedes Tor genau wissen wird, wie es zu einem anderen Tor im selben Rechenzentrum gelangt und wo der Zugangspunkt zu einem Tor in einem anderen Rechenzentrum ist.
In DCI werden die Routen als VPNv4 übermittelt. Dazu wird die Edge-Leaf-Schnittstelle zur Fabrik in eine VRF eingefügt, die wir UNDERLAY nennen, und die Nachbarschaft zum Spine auf dem Edge-Leaf wird innerhalb der VRF hergestellt, während zwischen den Edge-Leafs in der VPNv4-Familie gearbeitet wird.
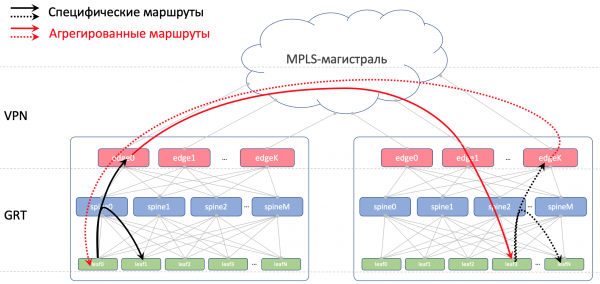
Außerdem werden wir es verbieten, Routen, die von Spines erhalten wurden, zurück zu diesen zu reanonsieren.
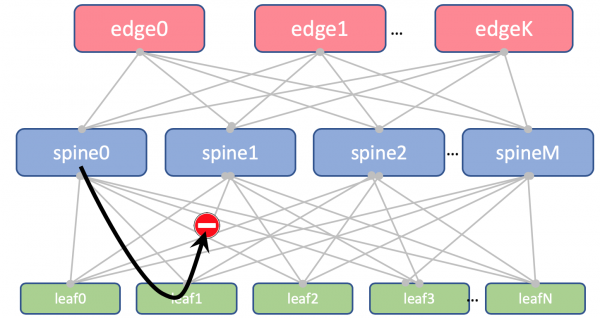
Auf Leaf und Spine werden wir keine Loopbacks importieren. Diese benötigen wir nur zur Bestimmung der Router-ID.
Auf den Edge-Leafs hingegen importieren wir sie in das globale BGP. Zwischen den Loopback-Adressen werden die Edge-Leafs BGP-Sitzungen in der IPv4 VPN-Familie miteinander aufbauen.
Zwischen den EDGE-Geräten werden wir ein weitreichendes Backbone über OSPF+LDP haben. Alles in einer Zone. Eine extrem einfache Konfiguration.
Das ist das Bild der Routing-Architektur.
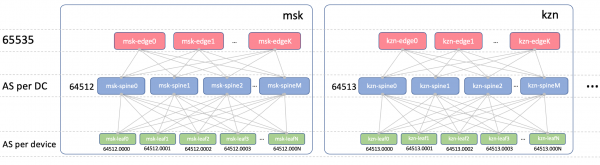
BGP ASN
Edge-Leaf ASN
Es wird eine ASN für alle Edge-Leafs in den Rechenzentren geben. Das ist wichtig, damit zwischen den Edge-Leafs ein iBGP besteht und wir nicht auf die Feinheiten von eBGP stoßen. Lassen Sie uns 65535 verwenden. In der Realität könnte dies eine öffentliche AS-Nummer sein.
Spine ASN
Bei Spine haben wir eine ASN für jedes Rechenzentrum. Wir beginnen hier mit der ersten Nummer aus dem Bereich der privaten AS – 64512, 64513 und so weiter.
Warum ASN in den Rechenzentren?
Lassen Sie uns diese Frage in zwei Teile zerlegen:
- Warum dieselbe ASN für alle Spines eines Rechenzentrums?
- Warum variiert sie in verschiedenen Rechenzentren?
Warum dieselbe ASN für alle Spines eines Rechenzentrums
So wird der AS-Path des Underlay-Routes auf Edge-Leaf aussehen:
[leafX_ASN, spine_ASN, edge_ASN]
Wenn wir versuchen, ihn zurück an das Spine anzukündigen, wird es ihn abweisen, weil dessen AS (Spine_AS) bereits in der Liste vorhanden ist.
Innerhalb des Rechenzentrums ist es für uns absolut akzeptabel, dass die Underlay-Routen, die zu Edge gelangen, nicht nach unten zurückfallen. Alle Kommunikationen zwischen den Hosts innerhalb des Rechenzentrums müssen innerhalb der Spine-Ebene stattfinden.
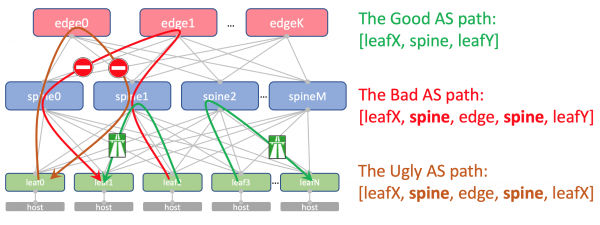
Die aggregierten Routen anderer Rechenzentren werden jedoch ungehindert zu den ToRs gelangen – in ihrem AS-Path wird nur die ASN 65535 vorhanden sein – die Nummer des AS der Edge-Leafs, weil sie genau dort erstellt wurden.
Warum variiert sie in verschiedenen Rechenzentren
Theoretisch könnte es notwendig sein, Loopbacks von bestimmten Service-VMs zwischen den Rechenzentren zu ziehen.
Zum Beispiel wird auf dem Host ein Route Reflector oder (Virtual Network Gateway) laufen, das sich über BGP mit dem ToR verknüpft und sein Loopback ankündigt, das aus allen Rechenzentren erreichbar sein sollte.
So könnte sein AS-Pfad aussehen:
[VNF_ASN, leafX_DC1_ASN, spine_DC1_ASN, edge_ASN, spine_DC2_ASN, leafY_DC2_ASN]
Hierbei sollten keine sich wiederholenden ASN vorkommen.
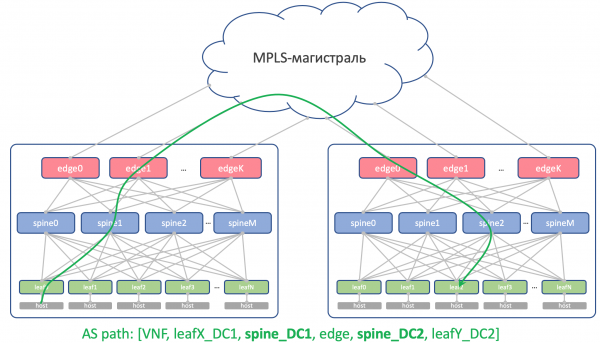
Das bedeutet, dass Spine_DC1 und Spine_DC2 unterschiedlich sein müssen, ebenso wie leafX_DC1 und leafY_DC2, was wir genau anstreben.
Wie Sie wahrscheinlich wissen, gibt es Hacks, die es erlauben, Routen mit sich wiederholenden ASN entgegen dem Mechanismus zur Vermeidung von Schleifen (allowas-in auf Cisco) zu akzeptieren. Und es gibt sogar legitime Anwendungen dafür. Aber das stellt ein potenzielles Risiko für die Netzwerkstabilität dar. Ich bin persönlich ein paar Mal damit konfrontiert worden.
Und wenn wir die Möglichkeit haben, gefährliche Dinge zu vermeiden, werden wir sie nutzen.
Leaf ASN
Jeder Leaf-Switch wird über einen individuellen ASN im gesamten Netzwerk verfügen.
Wir handeln so aus den oben genannten Gründen: AS-Pfad ohne Schleifen, BGP-Konfiguration ohne Hintertüren.
Damit Routen zwischen den Leaf-Switches ungehindert durchkommen, sollte der AS-Pfad folgendermaßen aussehen:
[leafX_ASN, spine_ASN, leafY_ASN]
Es wäre wünschenswert, dass leafX_ASN und leafY_ASN unterschiedlich sind.
Dies ist auch für die Situation mit der Ankündigung des VNF-Loopbacks zwischen den Rechenzentren erforderlich:
[VNF_ASN, leafX_DC1_ASN, spine_DC1_ASN, edge_ASN, spine_DC2_ASN, leafY_DC2_ASN]
Wir werden eine 4-Byte-ASN verwenden und sie basierend auf der ASN des Spine und der Nummer des Leaf-Switches generieren, nämlich so: Spine_ASN.0000X.
So sieht es mit der ASN aus.
IP-Plan
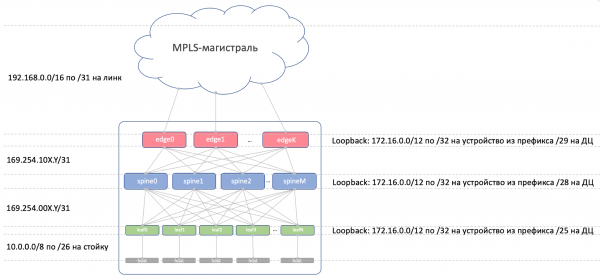
Grundsätzlich müssen wir Adressen für die folgenden Verbindungen bereitstellen:
- Die Underlay-Netzwerkadressen zwischen dem ToR und der Maschine. Diese müssen innerhalb des gesamten Netzwerks einzigartig sein, damit jede Maschine mit jeder anderen kommunizieren kann. Das eignet sich hervorragend. 10/8. Pro Rack werden wir /26 mit Puffer bereitstellen. Wir werden /19 für die Rechenzentren und /17 für die Region bereitstellen.
- Verbindungsadressen zwischen Leaf/Tor und Spine.
Diese würden wir gerne algorithmisch zuweisen, also basierend auf den Namen der Geräte, die verbunden werden sollen.
Lassen Sie es 169.254.0.0/16 sein.
Und zwar 169.254.00X.Y/31, wobei X — Nummer des Spine, Y — P2P-Netzwerk /31.
Dies ermöglicht den Betrieb von bis zu 128 Racks und bis zu 10 Spine im Rechenzentrum. Die Verbindungsadressen können (und werden) zwischen den Rechenzentren wiederholt werden. - Die Verbindung zwischen Spine und Edge-Leaf wird auf Subnetzen organisiert 169.254.10X.Y/31, wo es genauso sein wird. X — Nummer des Spine, Y — P2P-Netzwerk /31.
- Link-Adressen von Edge-Leaf zur MPLS-Hauptleitung. Hier ist die Situation etwas anders – der Anschluss aller Teile zu einem ganzen System, daher können wir nicht die gleichen Adressen wiederverwenden – wir müssen das nächstverfügbare Subnetz wählen. Deshalb nehmen wir als Grundlage 192.168.0.0/16 und werden daraus verfügbare Adressen extrahieren.
- Loopback-Adressen. Wir werden den gesamten Bereich dafür nutzen 172.16.0.0/12.
- Leaf – pro /25 für die Rechenzentren – dasselbe gilt für 128 Racks. Wir reservieren /23 für die Region.
- Spine – pro /28 für die Rechenzentren – bis zu 16 Spine. Wir reservieren /26 für die Region.
- Edge-Leaf – pro /29 für die Rechenzentren – bis zu 8 Geräte. Wir reservieren /27 für die Region.
Wenn uns die zugewiesenen Bereiche in den Rechenzentren nicht ausreichen (was sie nicht tun werden – wir streben schließlich hyperscale Wachstum an), reservieren wir einfach den nächsten Block.
Das ist das Bild zur IP-Adressierung.
Loopbacks:
Präfix
Geräterechnung
Region
Rechenzentrum
172.16.0.0/23
edge
172.16.0.0/27
ru
172.16.0.0/29
msk
172.16.0.8/29
kzn
172.16.0.32/27
sp
172.16.0.32/29
bcn
172.16.0.40/29
mlg
172.16.0.64/27
cn
172.16.0.64/29
sha
172.16.0.72/29
sia
172.16.2.0/23
spine
172.16.2.0/26
ru
172.16.2.0/28
msk
172.16.2.16/28
kzn
172.16.2.64/26
sp
172.16.2.64/28
bcn
172.16.2.80/28
mlg
172.16.2.128/26
cn
172.16.2.128/28
sha
172.16.2.144/28
sia
172.16.8.0/21
leaf
172.16.8.0/23
ru
172.16.8.0/25
msk
172.16.8.128/25
kzn
172.16.10.0/23
sp
172.16.10.0/25
bcn
172.16.10.128/25
mlg
172.16.12.0/23
cn
172.16.12.0/25
sha
172.16.12.128/25
sia
Underlay:
Präfix
Region
Rechenzentrum
10.0.0.0/17
ru
10.0.0.0/19
msk
10.0.32.0/19
kzn
10.0.128.0/17
sp
10.0.128.0/19
bcn
10.0.160.0/19
mlg
10.1.0.0/17
cn
10.1.0.0/19
sha
10.1.32.0/19
sia
Labor
Zwei Anbieter. Ein Netzwerk. ADSM.
Juniper + Arista. Ubuntu. Die alte gute Eva.
Die Anzahl der Ressourcen auf unserer virtuellen Maschine in Mirana ist jedoch begrenzt, daher verwenden wir für die Praxis ein stark vereinfachtes Netzwerk.
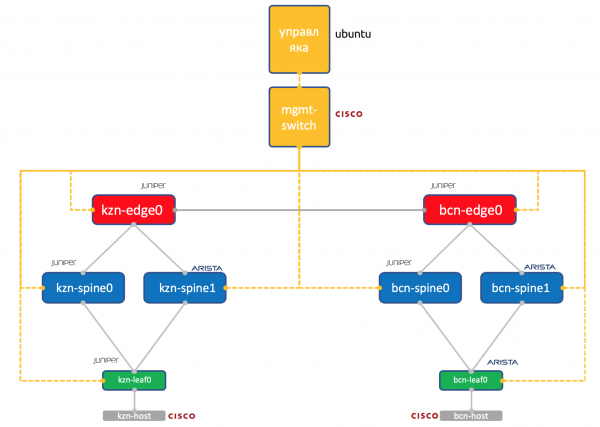
Zwei Rechenzentren: Kasan und Barcelona.
- Je zwei Spine in jedem: Juniper und Arista.
- In jedem Leaf gibt es einen Juniper und einen Arista, mit einem verbundenen Host (wir nehmen hier einen leichten Cisco IOL).
- Eine Edge-Leaf-Node (vorerst nur Juniper).
- Ein Cisco-Switch, der alle vereint.
- Neben den Netzwerkgeräten läuft eine Verwaltungs-VM. Betrieben unter Ubuntu.
Sie hat Zugang zu allen Geräten und wird IPAM/DCIM-Systeme, eine Sammlung von Python-Skripten, Ansible und alles andere, was wir benötigen, betreiben.
aller Netzwerkgeräte, die wir mit Automatisierung nachbilden möchten.
Fazit
Ist das üblich? Unter jedem Artikel einen kurzen Überblick zu geben?
Also haben wir ausgewählt Clos-Netzwerk innerhalb des Rechenzentrums, da wir viel East-West-Traffic erwarten und ECMP nutzen möchten.
Das Netzwerk wurde in physische (Underlay) und virtuelle (Overlay) Segmente unterteilt. Dabei beginnt das Overlay mit dem Host, was die Anforderungen an das Underlay vereinfacht.
Wir haben BGP als Routing-Protokoll für das Underlay-Netzwerk gewählt, aufgrund seiner Skalierbarkeit und Flexibilität der Richtlinien.
Es wird separate Knoten zur Organisation von DCI geben – Edge-Leaf.
Auf der Backbone wird OSPF+LDP implementiert.
DCI wird auf Basis von MPLS L3VPN realisiert.
Für P2P-Links berechnen wir die IP-Adressen algorithmisch basierend auf den Gerätnamen.
Loopbacks werden entsprechend der Rolle der Geräte und ihrer Position nacheinander zugewiesen.
Unterliegende Präfixe nur auf Leaf-Switches sequential basierend auf ihrer Position.
Angenommen, wir haben aktuell noch keine Ausrüstung installiert.
Deshalb werden unsere nächsten Schritte darin bestehen, diese in den Systemen (IPAM, Inventar) anzulegen, den Zugang zu organisieren, die Konfiguration zu generieren und sie zu deployen.
Im nächsten Artikel werden wir uns mit Netbox beschäftigen – einem System zur Inventarisierung und Verwaltung von IP-Ressourcen im Rechenzentrum.
Vielen Dank
- Danke an Andrej Glazkov aka @glazgoo für das Korrekturlesen und die Anpassungen.
- Danke an Alexander Klimenko aka @v00lk für das Korrekturlesen und die Anpassungen.
- Danke an Artem Tschernobai für das KDPV.
Quelle: habr.com
