


Skalierbarkeit ist eine Schlüsselanforderung für Cloud-Anwendungen. Mit Kubernetes ist das Skalieren einer Anwendung so einfach wie das Erhöhen der Anzahl der Replikate für das entsprechende Deployment oder ReplicaSet — aber das ist ein manueller Prozess.
Kubernetes ermöglicht das automatische Skalieren von Anwendungen (das heißt Pods in einem Deployment oder ReplicaSet) auf deklarative Weise mithilfe der Spezifikation des Horizontal Pod Autoscalers. Standardmäßig basieren die Kriterien für das automatische Skalieren auf den CPU-Nutzungsmetriken (Ressourcennutzungsmetriken), aber es können auch benutzerdefinierte Metriken und externe Metriken integriert werden.
Der Befehl hat einen Artikel verfasst, der beschreibt, wie externe Metriken zur automatischen Skalierung einer Kubernetes-Anwendung verwendet werden können. Um zu demonstrieren, wie das alles funktioniert, verwendet der Autor HTTP-Zugriffsmetriken, die mit Prometheus gesammelt werden.
Anstelle einer horizontalen automatischen Skalierung von Pods kommt Kubernetes Event Driven Autoscaling (KEDA) zum Einsatz — ein Open-Source-Kubernetes-Operator. Dieser integriert sich von Anfang an mit dem Horizontal Pod Autoscaler, um ein nahtloses Autoscaling (auch hinauf und hinunter) für ereignisgesteuerte Workloads zu gewährleisten. Der Code ist verfügbar auf .
Kurze Übersicht der Systemfunktionalität
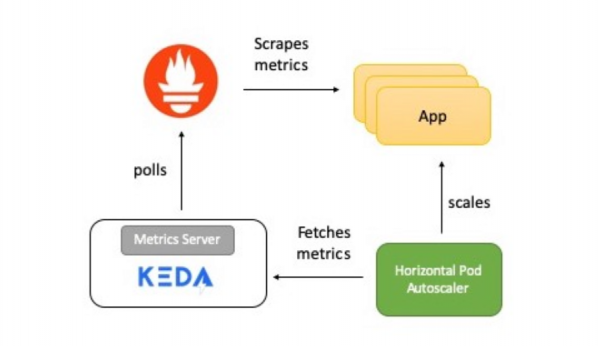
Die Abbildung zeigt eine kurze Beschreibung, wie alles funktioniert:
- Die Anwendung stellt Metriken der HTTP-Anfragen im Prometheus-Format bereit.
- Prometheus ist so konfiguriert, dass diese Kennzahlen gesammelt werden.
- Der Prometheus-Scalierer in KEDA ist so eingerichtet, dass er die Anwendung basierend auf der Anzahl der HTTP-Anfragen automatisch skaliert.
Jetzt werde ich auf jedes Element detailliert eingehen.
KEDA und Prometheus
Prometheus ist ein Open-Source-Toolkit zur Überwachung und Alarmierung von Systemen, das Teil von . Es sammelt Metriken aus verschiedenen Quellen und speichert diese als Zeitreihendaten. Zur Visualisierung der Daten können oder andere Visualisierungstools verwendet werden, die mit der Kubernetes-API arbeiten.
KEDA unterstützt das Konzept des Scalers – er fungiert als Brücke zwischen KEDA und einem externen System. Die Implementierung des Scalers ist spezifisch für jedes Zielsystem und zieht Daten daraus. Anschließend verwendet KEDA diese Daten zur Steuerung der automatischen Skalierung.
Scaler unterstützen mehrere Datenquellen, wie z. B. Kafka, Redis und Prometheus. Das bedeutet, dass KEDA zur automatischen Skalierung von Kubernetes-Bereitstellungen verwendet werden kann, wobei Prometheus-Metriken als Kriterien dienen.
Testanwendung
Die Test-Golang-Anwendung ermöglicht den Zugriff über HTTP und erfüllt zwei wichtige Funktionen:
- Sie verwendet die Clientbibliothek Prometheus Go zur Instrumentierung der Anwendung und stellt die Metrik http_requests bereit, die einen Zähler für Anfragen enthält. Der Endpunkt, an dem die Prometheus-Metriken verfügbar sind, befindet sich unter dem URI
/metrics.var httpRequestsCounter = promauto.NewCounter(prometheus.CounterOpts{ Name: "http_requests", Help: "Anzahl der HTTP-Anfragen", }) - Als Antwort auf die Anfrage
GETerhöht die Anwendung den Wert des Schlüssels (access_count) in Redis. Dies ist eine einfache Möglichkeit, die Arbeit als Teil des HTTP-Handlers auszuführen und gleichzeitig die Prometheus-Metriken zu überprüfen. Der Wert der Metrik sollte dem Wert entsprechenaccess_countin Redis.func main() { http.Handle("/metrics", promhttp.Handler()) http.HandleFunc("/test", func(w http.ResponseWriter, r *http.Request) { defer httpRequestsCounter.Inc() count, err := client.Incr(redisCounterName).Result() if err != nil { fmt.Println("Fehler beim Inkrementieren des Redis-Zählers", err) os.Exit(1) } resp := "Zugriff am " + time.Now().String() + "nZugriffsanzahl " + strconv.Itoa(int(count)) w.Write([]byte(resp)) }) http.ListenAndServe(":8080", nil) }
Die Anwendung wird über Kubernetes bereitgestellt Deployment. Außerdem wird ein Dienst erstellt ClusterIP, der es dem Prometheus-Server ermöglicht, Metriken der Anwendung zu erhalten.
Hier .
Prometheus-Server
Das Bereitstellungsmanifest von Prometheus besteht aus:
ConfigMap— zur Übertragung der Prometheus-Konfiguration;Deployment— zur Bereitstellung von Prometheus im Kubernetes-Cluster;ClusterIP— Dienst für den Zugriff auf die Prometheus-Benutzeroberfläche;ClusterRole,ClusterRoleBindingundServiceAccount— für die Auto-Erkennung von Diensten in Kubernetes.
Hier .
KEDA Prometheus ScaledObject
Der Scaler fungiert als Brücke zwischen KEDA und einem externen System, aus dem Metriken abgerufen werden müssen. ScaledObject — eine anpassbare Ressource, die bereitgestellt werden muss, um die Bereitstellung mit der Ereignisquelle in diesem Fall Prometheus zu synchronisieren.
ScaledObject enthält Informationen zur Skalierung des Deployments, Metadaten zur Quelle des Ereignisses (zum Beispiel Verbindungsgeheimnisse, Warteschlangenname), Abfrageintervall, Wiederherstellungszeit und weitere Daten. Es verweist auf die entsprechende Autoscaling-Ressource (HPA-Definition) zur Skalierung des Deployments.
Wenn das Objekt ScaledObject gelöscht wird, wird die entsprechende HPA-Definition bereinigt.
Hier ist die Definition ScaledObject für unser Beispiel, in dem ein Scaler verwendet wird: Prometheus:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: default
labels:
deploymentName: go-prom-app
spec:
scaleTargetRef:
deploymentName: go-prom-app
pollingInterval: 15
cooldownPeriod: 30
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: prometheus
metadata:
serverAddress:
http://prometheus-service.default.svc.cluster.local:9090
metricName: access_frequency
threshold: '3'
query: sum(rate(http_requests[2m]))
Beachten Sie die folgenden Punkte:
- Es verweist auf
Deploymentmit dem Namengo-prom-app. - Der Auslöser-Typ ist —
Prometheus. Die Adresse des Prometheus-Servers wird zusammen mit dem Namen der Metrik, dem Schwellenwert und , die verwendet wird. Die PromQL-Abfrage ist —sum(rate(http_requests[2m])). - Laut
pollingInterval, KEDA fragt das Ziel alle fünfzehn Sekunden bei Prometheus ab. Es wird mindestens ein Pod unterstützt (minReplicaCount), während die maximale Anzahl der Pods nicht überschreitetmaxReplicaCount(in diesem Beispiel — zehn).
Es kann auf minReplicaCount null gesetzt werden. In diesem Fall aktiviert KEDA das Deployment von null auf eins und stellt anschließend HPA für weiteres automatisches Skalieren bereit. Es ist auch das umgekehrte Szenario möglich, also das Skalieren von eins auf null. In unserem Beispiel haben wir null nicht gewählt, da es sich um einen HTTP-Service handelt und nicht um ein System auf Anfrage.
Die Magie des automatischen Skalierens
Der Schwellenwert wird als Auslöser für das Skalieren des Deployments verwendet. In unserem Beispiel gibt die Anfrage PromQL sum(rate (http_requests [2m])) den aggregierten Wert der HTTP-Anfragenrate zurück (Anzahl der Anfragen pro Sekunde), gemessen über die letzten zwei Minuten.
Da der Schwellenwert drei beträgt, wird es einen Pod geben, solange der Wert sum(rate (http_requests [2m])) weniger als drei ist. Wenn der Wert jedoch steigt, wird bei jedem Anstieg um drei ein zusätzlicher Pod hinzugefügt. Wenn zum Beispiel der Wert von 12 auf 14 steigt, beträgt die Anzahl der Pods vier. sum(rate (http_requests [2m])) Jetzt lass uns versuchen, es einzurichten!
Voraussetzung
Alles, was Sie brauchen, ist ein Kubernetes-Cluster und ein konfiguriertes Tool
. In diesem Beispiel wird ein Cluster verwendet kubectl. In diesem Beispiel wird ein Cluster verwendet minikube, aber Sie können auch einen anderen wählen. Zur Installation des Clusters gibt es .
Die neueste Version auf Mac installieren:
curl -Lo minikube
https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
&& chmod +x minikube
sudo mkdir -p /usr/local/bin/
sudo install minikube /usr/local/bin/
Installieren Sie , um auf den Kubernetes-Cluster zuzugreifen.
Die neueste Version auf Mac installieren:
curl -LO
"https://storage.googleapis.com/kubernetes-release/release/$(curl -s
https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/darwin/amd64/kubectl"
chmod +x ./kubectl
sudo mv ./kubectl /usr/local/bin/kubectl
kubectl version
KEDA Installation
Sie können KEDA auf verschiedene Weisen bereitstellen, diese sind aufgelistet in . Ich verwende ein monolithisches YAML:
kubectl apply -f
https://raw.githubusercontent.com/kedacore/keda/master/deploy/KedaScaleController.yaml
KEDA und ihre Komponenten werden im Namensraum kedainstalliert. Der Befehl zur Überprüfung:
kubectl get pods -n keda
Warten Sie, bis der KEDA Operator Pod — in den Running Stategeht. Und danach fortfahren.
Installation von Redis mit Helm
Wenn Sie Helm nicht installiert haben, verwenden Sie diesen . Der Befehl zur Installation auf Mac:
brew install kubernetes-helm
helm init --history-max 200
helm init initialisiert die lokale Befehlszeilenschnittstelle und installiert Tiller im Kubernetes-Cluster.
kubectl get pods -n kube-system | grep tiller
Warten Sie, bis der Tiller Pod den Status Running erreicht.
Hinweis des Übersetzers: Der Autor verwendet Helm@2, der die Installation des Serverkomponenten Tiller erfordert. Derzeit ist Helm@3 aktuell, für den kein Serverteil benötigt wird.
Nachdem Helm installiert ist, genügt ein Befehl, um Redis zu starten:
helm install --name redis-server --set cluster.enabled=false --set
usePassword=false stable/redis
Überprüfen Sie, ob Redis erfolgreich gestartet wurde:
kubectl get pods/redis-server-master-0
Warten Sie, bis der Redis-Pod den Status wechselt. Running.
Anwendungsbereitstellung
Befehl zum Bereitstellen:
kubectl apply -f go-app.yaml
//output
deployment.apps/go-prom-app created
service/go-prom-app-service created
Überprüfen Sie, ob alles gestartet ist:
kubectl get pods -l=app=go-prom-app
Warten Sie, bis Redis in den Status wechselt. Running.
Bereitstellung des Prometheus-Servers
Das Manifest für Prometheus verwendet . Es ermöglicht die dynamische Erkennung von Anwendungspods basierend auf dem Service-Label.
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_run]
regex: go-prom-app-service
action: keep
Zum Bereitstellen:
kubectl apply -f prometheus.yaml
//output
clusterrole.rbac.authorization.k8s.io/prometheus created
serviceaccount/default configured
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
configmap/prom-conf created
deployment.extensions/prometheus-deployment created
service/prometheus-service created
Überprüfen Sie, ob alles gestartet ist:
kubectl get pods -l=app=prometheus-server
Warten Sie, bis der Prometheus-Pod den Status wechselt. Running.
Nutzen Sie kubectl port-forward für den Zugriff auf die Benutzeroberfläche von Prometheus (oder den API-Server) unter .
kubectl port-forward service/prometheus-service 9090
Bereitstellung der KEDA-Autoskalierungs-Konfiguration
Befehl zur Erstellung ScaledObject:
kubectl apply -f keda-prometheus-scaledobject.yaml
Überprüfen Sie die Protokolle des KEDA-Operators:
KEDA_POD_NAME=$(kubectl get pods -n keda
-o=jsonpath='{.items[0].metadata.name}')
kubectl logs $KEDA_POD_NAME -n keda
Das Ergebnis sieht ungefähr so aus:
time="2019-10-15T09:38:28Z" level=info msg="Watching ScaledObject:
default/prometheus-scaledobject"
time="2019-10-15T09:38:28Z" level=info msg="Created HPA with
namespace default and name keda-hpa-go-prom-app"
Überprüfen Sie die Anwendungspods. Es sollte eine Instanz laufen, da minReplicaCount gleich 1:
kubectl get pods -l=app=go-prom-app
Überprüfen Sie, ob das HPA-Ressource erfolgreich erstellt wurde:
kubectl get hpa
Sie sollten etwas sehen wie:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-go-prom-app Deployment/go-prom-app 0/3 (avg) 1 10 1 45s
Überprüfung der Funktionalität: Zugriff auf die Anwendung
Um auf den REST-Endpunkt unserer Anwendung zuzugreifen, führen Sie aus:
kubectl port-forward service/go-prom-app-service 8080
Jetzt können Sie auf die Go-Anwendung zugreifen, indem Sie die Adresse verwenden. Führen Sie dazu den Befehl aus:
curl http://localhost:8080/test
Das Ergebnis sieht ungefähr so aus:
Zugriff am 2019-10-21 11:29:10.560385986 +0000 UTC
m=+406004.817901246
Zugriffszähler 1
Überprüfen Sie in diesem Schritt auch Redis. Sie werden sehen, dass der Schlüssel access_count erhöht auf 1:
kubectl exec -it redis-server-master-0 -- redis-cli get access_count
//output
"1"
Stellen Sie sicher, dass der Metrikwert http_requests der gleiche ist:
curl http://localhost:8080/metrics | grep http_requests
//output
# HELP http_requests Anzahl der HTTP-Anfragen
# TYPE http_requests Zähler
http_requests 1
Lasttest erstellen
Wir verwenden — ein Tool zur Lastgenerierung:
curl -o hey https://storage.googleapis.com/hey-release/hey_darwin_amd64
&& chmod a+x hey
Sie können das Tool auch herunterladen für oder .
Führen Sie es aus:
./hey http://localhost:8080/test
Standardmäßig sendet das Tool 200 Anfragen. Sie können dies mit den Prometheus-Metriken sowie Redis überprüfen.
curl http://localhost:8080/metrics | grep http_requests
//output
# HELP http_requests Anzahl der HTTP-Anfragen
# TYPE http_requests Zähler
http_requests 201
kubectl exec -it redis-server-master-0 -- redis-cli get access_count
//output
201
Bestätigen Sie den Wert der tatsächlichen Metrik (die von der PromQL-Anfrage zurückgegeben wurde):
curl -g
'http://localhost:9090/api/v1/query?query=sum(rate(http_requests[2m]))'
//output
{"status":"success","data":{"resultType":"vector","result":[{"metric":{},"value":[1571734214.228,"1.686057971014493"]}]}}
In diesem Fall ist das tatsächliche Ergebnis gleich 1,686057971014493 und wird im Feld angezeigt value. Das reicht nicht für das Skalieren, da unser festgelegter Schwellenwert 3 beträgt.
Mehr Last!
Beobachten Sie in einem neuen Terminal die Anzahl der Pods der Anwendung:
kubectl get pods -l=app=go-prom-app -w
Lassen Sie uns die Last mit folgendem Befehl erhöhen:
./hey -n 2000 http://localhost:8080/test
Nach einiger Zeit werden Sie sehen, dass HPA das Deployment skaliert und neue Pods startet. Überprüfen Sie HPA, um dies zu bestätigen:
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-go-prom-app Deployment/go-prom-app 1830m/3 (Durchschnitt) 1 10 6 4m22s
Wenn die Last unbeständig ist, wird das Deployment auf einen Punkt reduziert, an dem nur ein Pod läuft. Wenn Sie die tatsächliche Metrik überprüfen möchten (die durch die PromQL-Abfrage zurückgegeben wird), verwenden Sie den folgenden Befehl:
curl -g
'http://localhost:9090/api/v1/query?query=sum(rate(http_requests[2m]))'
Bereinigung
//Delete KEDA
kubectl delete namespace keda
//Delete the app, Prometheus server and KEDA scaled object
kubectl delete -f .
//Delete Redis
helm del --purge redis-server
Fazit
KEDA ermöglicht das automatisierte Skalieren Ihrer Kubernetes-Deployments (bis/von null) basierend auf Daten aus externen Metriken. Zum Beispiel basierend auf Prometheus-Metriken, Warteschlangenlängen in Redis, oder Latenzen von Verbrauchern in Kafka-Themen.
KEDA integriert sich mit einer externen Quelle und stellt deren Metriken über den Metrics Server für den Horizontal Pod Autoscaler bereit.
Viel Erfolg!
Weitere Leseempfehlungen:
- .
- .
- .
Quelle: habr.com
