


Früher oder später stellt sich bei der Nutzung eines Systems die Frage nach der Sicherheit: das Gewährleisten von Authentifizierung, das Trennen von Rechten, Audits und anderen Aufgaben. Für Kubernetes gibt es bereits , die es ermöglichen, Standards selbst in sehr anspruchsvollen Umgebungen zu erfüllen… Dieses Material befasst sich mit den grundlegenden Aspekten der Sicherheit, die durch die integrierten Mechanismen von K8s realisiert sind. Zuallererst wird es für diejenigen nützlich sein, die sich mit Kubernetes vertrautmachen, - als Ausgangspunkt für die Erforschung von sicherheitsrelevanten Fragen.
Authentifizierung
In Kubernetes gibt es zwei Arten von Benutzern:
- Service Accounts – Konten, die von der Kubernetes API verwaltet werden;
- Benutzer – «normale» Benutzer, die von externen, unabhängigen Diensten verwaltet werden.
Der Hauptunterschied zwischen diesen Typen besteht darin, dass es für Service Accounts in der Kubernetes API spezielle Objekte gibt (die ebenfalls so genannt werden - ServiceAccounts), die an den Namensraum und eine Reihe von Authentifizierungsdaten gebunden sind, die im Cluster in Objekten des Typs Secrets gespeichert sind. Diese Benutzer (Service Accounts) sind hauptsächlich für die Verwaltung der Zugriffsrechte auf die Kubernetes API von Prozessen, die im Kubernetes-Cluster laufen, vorgesehen.
Reguläre Benutzer haben keine Einträge in der Kubernetes-API: Ihre Verwaltung muss durch externe Mechanismen erfolgen. Sie sind für Menschen oder Prozesse gedacht, die außerhalb des Clusters leben.
Jede API-Anfrage ist entweder an ein Service-Konto, an einen Benutzer gebunden oder wird als anonym betrachtet.
Die Authentifizierungsdaten des Benutzers umfassen:
- Benutzername — Benutzernamen (beachten Sie die Groß- und Kleinschreibung!);
- UID — eine maschinenlesbare Benutzeridentifikation, die "konsistenter und einzigartiger als der Benutzername" ist;
- Gruppen — eine Liste der Gruppen, zu denen der Benutzer gehört;
- Zusätzliche Informationen — zusätzliche Felder, die von den Autorisierungsmechanismen verwendet werden können.
Kubernetes kann eine Vielzahl von Authentifizierungsmechanismen nutzen: X509-Zertifikate, Bearer-Tokens, authentifizierende Proxys, HTTP Basic Auth. Mit diesen Mechanismen können viele Autorisierungsschemata implementiert werden: von einer statischen Passwortdatei bis hin zu OpenID OAuth2.
Darüber hinaus können mehrere Autorisierungsschemata gleichzeitig verwendet werden. Standardmäßig kommen im Cluster folgende Mechanismen zum Einsatz:
- Service-Konto-Token — für Service Accounts;
- X509 — für Benutzer.
Die Frage zur Verwaltung von ServiceAccounts geht über den Rahmen dieses Artikels hinaus. Wer sich näher mit diesem Thema befassen möchte, sollte auf die beginnen. Wir werden uns genauer mit der Verwendung von X.509-Zertifikaten befassen.
Zertifikate für Benutzer (X.509)
Der klassische Umgang mit Zertifikaten umfasst:
- die Schlüsselgenerierung:
mkdir -p ~/mynewuser/.certs/ openssl genrsa -out ~/certs/mynewuser.key 2048 - die Erstellung einer Zertifikatsanforderung:
openssl req -new -key ~/certs/mynewuser.key -out ~/certs/mynewuser.csr -subj "/CN=mynewuser/O=company" - die Verarbeitung der Zertifikatsanforderung mit den CA-Schlüsseln des Kubernetes-Clusters zur Erlangung des Benutzerzertifikats (zum Abrufen des Zertifikats muss ein Konto verwendet werden, das Zugriff auf den Schlüssel der Zertifizierungsstelle des Clusters hat, der standardmäßig unter
/etc/kubernetes/pki/ca.key):openssl x509 -req -in ~/certs/mynewuser.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out ~/certs/mynewuser.crt -days 500 - die Erstellung einer Konfigurationsdatei:
- Beschreibung des Clusters (geben Sie die Adresse und den Speicherort der CA-Zertifikatsdatei für die spezifische Clusterinstallation an):
kubectl config set-cluster kubernetes --certificate-authority=/etc/kubernetes/pki/ca.crt --server=https://192.168.100.200:6443 - oder – wie nichtEmpfohlene Option — der Root-Zertifikat muss nicht angegeben werden (in diesem Fall wird kubectl die Richtigkeit des API-Servers im Cluster nicht überprüfen):
kubectl config set-cluster kubernetes --insecure-skip-tls-verify=true --server=https://192.168.100.200:6443 - Benutzer zur Konfigurationsdatei hinzufügen:
kubectl config set-credentials mynewuser --client-certificate=.certs/mynewuser.crt --client-key=.certs/mynewuser.key - Kontext hinzufügen:
kubectl config set-context mynewuser-context --cluster=kubernetes --namespace=target-namespace --user=mynewuser - Standardkontext festlegen:
kubectl config use-context mynewuser-context
- Beschreibung des Clusters (geben Sie die Adresse und den Speicherort der CA-Zertifikatsdatei für die spezifische Clusterinstallation an):
Nach den oben genannten Manipulationen wird in der Datei .kube/config eine Konfiguration in folgender Form erstellt:
apiVersion: v1
clusters:
- cluster:
certificate-authority: /etc/kubernetes/pki/ca.crt
server: https://192.168.100.200:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
namespace: target-namespace
user: mynewuser
name: mynewuser-context
current-context: mynewuser-context
kind: Config
preferences: {}
users:
- name: mynewuser
user:
client-certificate: /home/mynewuser/.certs/mynewuser.crt
client-key: /home/mynewuser/.certs/mynewuser.keyUm den Transfer der Konfiguration zwischen Konten und Servern zu erleichtern, ist es hilfreich, die Werte der folgenden Schlüssel zu bearbeiten:
-
certificate-authority -
client-certificate -
client-key
Dazu können die in ihnen angegebenen Dateien mit base64 codiert und in der Konfiguration eingetragen werden, indem man den Schlüsseln den Suffix -data, also erhält man certificate-authority-data usw.
Zertifikate mit kubeadm
Mit der Veröffentlichung ist die Arbeit mit Zertifikaten dank der Alpha-Version der Unterstützung in . Hier ist beispielsweise, wie die Generierung einer Konfigurationsdatei mit Benutzer-Schlüsseln nun aussehen kann:
kubeadm alpha kubeconfig user --client-name=mynewuser --apiserver-advertise-address 192.168.100.200 NB: Die erforderliche veröffentlichte Adresse kann in der Konfiguration des API-Servers eingesehen werden, die standardmäßig in /etc/kubernetes/manifests/kube-apiserver.yaml.
Die resultierende Konfiguration wird auf stdout ausgegeben. Sie muss in ~/ .kube / config das Benutzerkonto oder in eine Datei, die in der Umgebungsvariable angegeben ist, gespeichert werden. KUBECONFIG.
Tiefer graben
Für Interessierte, die die beschriebenen Themen genauer verstehen möchten:
- über die Arbeit mit Zertifikaten in der offiziellen Kubernetes-Dokumentation;
- , der die Zertifikatsfragen aus praktischer Sicht behandelt.
- zur Authentifizierung in Kubernetes.
Autorisierung
Das standardmäßig autorisierte Benutzerkonto hat keine Berechtigungen für Aktionen im Cluster. Zur Gewährung von Berechtigungen wurde in Kubernetes ein Autorisierungsmechanismus implementiert.
Bis Version 1.6 wurde in Kubernetes ein Autorisierungstyp verwendet, der als ABAC (attributbasierte Zugriffskontrolle) bezeichnet wird. Weitere Informationen dazu finden Sie in . Dieser Ansatz wird derzeit als veraltet (legacy) angesehen, kann jedoch nach wie vor zusammen mit anderen Authentifizierungsmethoden verwendet werden.
Die aktuelle und flexiblere Methode zur Trennung von Zugriffsrechten im Cluster wird genannt: RBAC (). Sie wurde seit der Version . RBAC implementiert ein Berechtigungssystem, bei dem alles, was nicht ausdrücklich erlaubt ist, verboten ist.
Um RBAC zu aktivieren, muss der Kubernetes api-server mit der Option --authorization-mode=RBACgestart werden. Die Parameter werden im Manifest für die Konfiguration des api-servers festgelegt, das standardmäßig unter dem Pfad /etc/kubernetes/manifests/kube-apiserver.yamlzu finden ist, und zwar im Abschnitt command. Allerdings ist RBAC standardmäßig bereits aktiviert, daher ist es wahrscheinlich nicht nötig, sich darüber Sorgen zu machen: Sie können dies anhand des Wertes authorization-mode überprüfen (im bereits erwähnten kube-apiserver.yaml). Übrigens können unter seinen Werten auch andere Authentifizierungstypen sein (node, Webhooks, always allow), deren Untersuchung jedoch außerhalb des Rahmens dieses Materials liegt.
Übrigens haben wir bereits eine recht detaillierte Beschreibung der Prinzipien und Besonderheiten der Arbeit mit RBAC veröffentlicht, sodass ich mich im Folgenden auf eine kurze Übersicht der Grundlagen und Beispiele beschränken werde.
Für die Zugriffsverwaltung in Kubernetes über RBAC werden folgende API-Entitäten verwendet:
-
RolleundClusterRole— Rollen, die zur Beschreibung von Zugriffsrechten dienen: -
Rolleerlaubt es, Berechtigungen innerhalb eines Namensraums zu beschreiben; -
ClusterRole— im Rahmen des Clusters, auch für cluster-spezifische Objekte wie Knoten, non-resource URLs (d.h. nicht mit Kubernetes-Ressourcen verbundene — z.B./version,/logs,/api*); -
RoleBindingundClusterRoleBinding— dient zur BindungRolleundClusterRolean einen Benutzer, eine Benutzergruppe oder ein Servicekonto.
Die Entitäten Role und RoleBinding sind auf den Namensraum beschränkt, d.h. sie müssen innerhalb eines einzigen Namensraums liegen. RoleBinding kann jedoch auf ClusterRole verweisen, was es ermöglicht, eine Sammlung von typischen Berechtigungen zu erstellen und den Zugang darüber zu verwalten.
Rollen beschreiben Berechtigungen mithilfe von Regelsets, die Folgendes enthalten:
- API-Gruppen — siehe für apiGroups und Ausgabe
kubectl api-resources; - Ressourcen (resources:
pod,namespace,deploymentusw.); - Verben (verbs:
set,Aktualisierenusw.). - Ressourcen-Namen (
resourceNames) — für den Fall, dass der Zugriff auf eine bestimmte Ressource und nicht auf alle Ressourcen dieser Art gewährt werden soll.
Eine detailliertere Analyse der Autorisierung in Kubernetes finden Sie auf der Seite . Stattdessen (genauer gesagt — zusätzlich dazu) werde ich Beispiele anführen, die deren Funktion verdeutlichen.
Beispiele für RBAC-Entitäten
Einfach Rolle, die es ermöglicht, eine Liste und den Status von Pods abzurufen und sie im Namensraum zu überwachen ziel-namensraum:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: ziel-namensraum
name: pod-reader
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"] Beispiel ClusterRole, was es ermöglicht, eine Liste und den Status von Pods abzurufen und sie im gesamten Cluster zu überwachen:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
# Die "namespace"-Sektion fehlt, da ClusterRole den gesamten Cluster verwendet
name: secret-reader
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "watch", "list"] Beispiel RoleBinding, wodurch der Benutzer meinneuerbenutzer «Pods» im Namensraum lesen kann mein-namensraum:
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods
namespace: ziel-namensraum
subjects:
- kind: User
name: meinneuerbenutzer # Benutzernamen stets groß-/kleinschreibung beachten!
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role # hier muss “Role” oder “ClusterRole” stehen
name: pod-reader # Name der Rolle im gleichen Namensraum,
# oder Name der ClusterRole, deren Nutzung
# dem Benutzer gestattet werden soll
apiGroup: rbac.authorization.k8s.ioEreignisaudit
Die Architektur von Kubernetes lässt sich schematisch wie folgt darstellen:
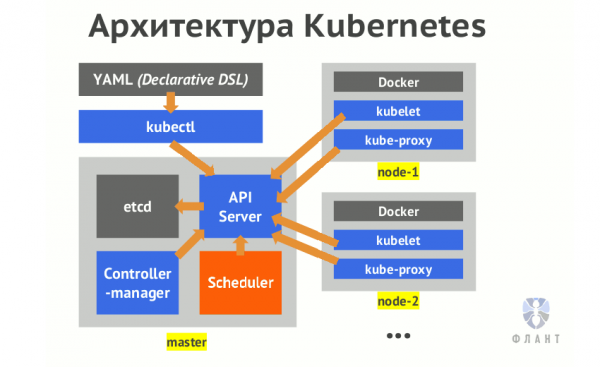
Die Schlüsselkomponente von Kubernetes, die für die Verarbeitung von Anfragen zuständig ist, ist der api-server. Alle Operationen am Cluster laufen darüber. Weitere Informationen zu diesen internen Mechanismen finden Sie im Artikel „».
Das Auditing-System ist eine interessante Funktion in Kubernetes, die standardmäßig deaktiviert ist. Es ermöglicht, alle Anfragen an die Kubernetes-API zu protokollieren. Wie man leicht erraten kann, werden über diese API alle Aktionen zur Kontrolle und Änderung des Clusterzustands durchgeführt. Eine gute Beschreibung ihrer Möglichkeiten findet sich (wie gewohnt) in K8s. Im Folgenden werde ich versuchen, das Thema auf einfachere Weise zu erklären.
Also, Um das Auditing zu aktivieren,, müssen wir dem api-server drei erforderliche Parameter übergeben, zu denen Sie weiter unten mehr erfahren können:
-
--audit-policy-file=/etc/kubernetes/policies/audit-policy.yaml -
--audit-log-path=/var/log/kube-audit/audit.log -
--audit-log-format=json
Neben diesen drei notwendigen Parametern gibt es viele zusätzliche Einstellungen zum Auditing: von der Protokollrotation bis zu Beschreibung von Webhooks. Beispiel für Protokollrotationsparameter:
-
--audit-log-maxbackup=10 -
--audit-log-maxsize=100 -
--audit-log-maxage=7
Auf diese wollen wir jetzt nicht näher eingehen – alle Details finden Sie in der .
Wie bereits erwähnt, werden alle Parameter im Manifest mit der Konfiguration des api-Servers festgelegt (standardmäßig /etc/kubernetes/manifests/kube-apiserver.yaml), im Abschnitt command. Lassen Sie uns zu den 3 erforderlichen Parametern zurückkehren und sie näher betrachten:
-
audit-policy-file— der Pfad zur YAML-Datei mit der Beschreibung der Audit-Policy. Auf deren Inhalt werden wir später zurückkommen, aber ich möchte vorerst anmerken, dass die Datei für den api-Server-Prozess lesbar sein muss. Daher muss sie in den Container eingebunden werden, wofür der folgende Code in die entsprechenden Abschnitte der Konfiguration eingefügt werden kann:volumeMounts: - mountPath: /etc/kubernetes/policies name: policies readOnly: true volumes: - hostPath: path: /etc/kubernetes/policies type: DirectoryOrCreate name: policies -
audit-log-path— der Pfad zur Logdatei. Auch dieser Pfad muss für den api-Server-Prozess zugänglich sein, weshalb wir seine Einbindung ebenfalls beschreiben:volumeMounts: - mountPath: /var/log/kube-audit name: logs readOnly: false volumes: - hostPath: path: /var/log/kube-audit type: DirectoryOrCreate name: logs -
audit-log-format— das Format des Audit-Logs. Standardmäßig ist diesjson, jedoch ist auch ein veraltetes Textformat verfügbar (legacy).
Audit-Policy
Nun zum erwähnten Dokument mit der Beschreibung der Logging-Policy. Das erste Konzept der Audit-Policy ist level, der Logging-Level. Diese können folgende Werte annehmen:
-
None— nicht protokollieren; -
Metadata— Protokollierung von Metadaten der Anfrage: Benutzer, Anfragezeit, Zielressource (Pod, Namespace usw.), Art der Aktion (Verb) usw.; -
Request— Protokollierung von Metadaten und dem Body der Anfrage; -
RequestResponse— Protokollierung von Metadaten, Body der Anfrage und Body der Antwort.
Die letzten beiden Ebenen (Request und RequestResponse) protokollieren keine Anfragen, die keine Ressourcen ansprechen (Zugriffe auf sogenannte Non-Resource-URLs).
Alle Anfragen durchlaufen auch mehrere Phasen:
-
RequestReceived— Phase, in der die Anfrage vom Handler empfangen wurde und noch nicht an den nächsten Handler weitergegeben wurde; -
ResponseStarted— Header der Antwort wurden gesendet, aber bevor der Body der Antwort gesendet wird. Wird für längere Anfragen generiert (z. B.,watch); -
ResponseComplete— Body der Antwort wurde gesendet, es werden keine weiteren Informationen gesendet; -
Panic— Ereignisse werden generiert, wenn eine Ausnahme erkannt wird.
Um Phasen zu überspringen, kann man omitStages.
In der Policy-Datei können wir mehrere Abschnitte mit unterschiedlichen Protokollierungsstufen beschreiben. Es wird die erste passende Regel angewendet, die in der Beschreibung der Policy gefunden wird.
Der kubelet-Demon überwacht Änderungen am Manifest des API-Servers und startet den API-Server-Container bei Entdeckung von Änderungen neu. Es gibt jedoch einen wichtigen Punkt: Änderungen in der Datei policy werden dabei ignoriert.Nach Änderungen in der policy-Datei muss der API-Server manuell neu gestartet werden. Da der API-Server als , das Team kubectl delete führt nicht zu einem Neustart. Stattdessen müssen Sie manuell docker stop auf den kube-mastern durchführen, wo die Auditrichtlinie geändert wurde:
docker stop $(docker ps | grep k8s_kube-apiserver | awk '{print $1}')Bei aktivierter Auditing-Funktion ist es wichtig zu beachten, dass die Last auf dem kube-apiserver erhöht wird.Insbesondere steigt der Speicherverbrauch zur Speicherung des Anfragekontexts. Das Loggen beginnt erst nach dem Senden des Antwort-Headers. Die Last hängt auch von der Konfiguration der Auditrichtlinie ab.
Beispiele für Richtlinien
Lassen Sie uns die Struktur der policy-Dateien an Beispielen erläutern.
Hier ist eine einfache Datei Richtlinie, um alles auf Ebene zu protokollieren Metadata:
apiVersion: audit.k8s.io/v1
kind: Policy
rules:
- level: Metadata In der policy können Benutzer (Benutzer und ServiceAccounts) und Benutzergruppen aufgeführt werden. Beispielsweise können wir auf diese Weise Systembenutzer ignorieren, aber alles andere auf Ebene protokollieren. Request:
apiVersion: audit.k8s.io/v1
kind: Policy
rules:
- level: None
userGroups:
- "system:serviceaccounts"
- "system:nodes"
users:
- "system:anonymous"
- "system:apiserver"
- "system:kube-controller-manager"
- "system:kube-scheduler"
- level: RequestEs besteht auch die Möglichkeit, Ziel-
- Namespaces (
namespaces); - Verben (verbs:
get,Aktualisieren,löschenund andere) zu beschreiben; - Ressourcen (resources, nämlich:
pod,ConfigMapsund Ähnliches) sowie Ressourcen-Gruppen (apiGroups).
Bitte beachten! Ressourcen und Ressourcengruppen (API-Gruppen, d.h. apiGroups) sowie deren in dem Cluster installierte Versionen können mit den folgenden Befehlen abgerufen werden:
kubectl api-resources
kubectl api-versionsDie folgende Audit-Policy dient als Demonstration bewährter Praktiken in :
apiVersion: audit.k8s.io/v1beta1
kind: Policy
# Kein Logging für die Phase RequestReceived
omitStages:
- "RequestReceived"
rules:
# Kein Logging für Ereignisse, die als unbedeutend und nicht gefährlich gelten:
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: "" # dies ist die API-Gruppe mit leerem Namen, zu der
# die grundlegenden Kubernetes-Ressourcen gehören, die "core" genannt werden
resources: ["endpoints", "services"]
- level: None
users: ["system:unsecured"]
namespaces: ["kube-system"]
verbs: ["get"]
resources:
- group: "" # core
resources: ["configmaps"]
- level: None
users: ["kubelet"]
verbs: ["get"]
resources:
- group: "" # core
resources: ["nodes"]
- level: None
userGroups: ["system:nodes"]
verbs: ["get"]
resources:
- group: "" # core
resources: ["nodes"]
- level: None
users:
- system:kube-controller-manager
- system:kube-scheduler
- system:serviceaccount:kube-system:endpoint-controller
verbs: ["get", "update"]
namespaces: ["kube-system"]
resources:
- group: "" # core
resources: ["endpoints"]
- level: None
users: ["system:apiserver"]
verbs: ["get"]
resources:
- group: "" # core
resources: ["namespaces"]
# Kein Logging für Zugriffe auf Read-Only-URLs:
- level: None
nonResourceURLs:
- /healthz*
- /version
- /swagger*
# Kein Logging für Meldungen, die sich auf den Ressourcentyp "Ereignisse" beziehen:
- level: None
resources:
- group: "" # core
resources: ["events"]
# Ressourcen wie Secret, ConfigMap und TokenReview könnten geheime Daten enthalten,
# daher loggen wir nur die Metadaten entsprechender Anfragen
- level: Metadata
resources:
- group: "" # core
resources: ["secrets", "configmaps"]
- group: authentication.k8s.io
resources: ["tokenreviews"]
# Aktionen wie get, list und watch können ressourcenintensiv sein; wir loggen sie nicht
- level: Request
verbs: ["get", "list", "watch"]
resources:
- group: "" # core
- group: "admissionregistration.k8s.io"
- group: "apps"
- group: "authentication.k8s.io"
- group: "authorization.k8s.io"
- group: "autoscaling"
- group: "batch"
- group: "certificates.k8s.io"
- group: "extensions"
- group: "networking.k8s.io"
- group: "policy"
- group: "rbac.authorization.k8s.io"
- group: "settings.k8s.io"
- group: "storage.k8s.io"
# Standard-Logging-Level für grundlegende API-Ressourcen
- level: RequestResponse
resources:
- group: "" # core
- group: "admissionregistration.k8s.io"
- group: "apps"
- group: "authentication.k8s.io"
- group: "authorization.k8s.io"
- group: "autoscaling"
- group: "batch"
- group: "certificates.k8s.io"
- group: "extensions"
- group: "networking.k8s.io"
- group: "policy"
- group: "rbac.authorization.k8s.io"
- group: "settings.k8s.io"
- group: "storage.k8s.io"
# Standard-Logging-Level für alle anderen Anfragen
- level: MetadataEin weiteres gutes Beispiel für die Audit-Policy ist .
Um auf Audit-Ereignisse schnell reagieren zu können, besteht die Möglichkeit, einen Webhook zu beschreiben.Diese Frage wird in , ich lasse sie jedoch außerhalb dieses Artikels.
Ergebnisse
Der Artikel bietet einen Überblick über die Sicherheitsmechanismen in Kubernetes-Clustern, die es ermöglichen, personalisierte Konten für Benutzer zu erstellen, deren Berechtigungen zu trennen und ihr Verhalten zu protokollieren. Ich hoffe, dass er denjenigen hilfreich ist, die sich mit ähnlichen Fragen theoretisch oder bereits praktisch auseinandergesetzt haben. Ich empfehle auch, die Liste weiterer Materialien zum Thema Sicherheit in Kubernetes zu konsultieren, die im Abschnitt „P.S.“ aufgeführt sind - vielleicht finden Sie unter ihnen die für Ihre Probleme relevanten Details.
P.S.
Lesen Sie auch in unserem Blog:
- «»;
- «»;
- «»;
- «»;
- «».
Quelle: habr.com
