


Dieser Artikel hilft Ihnen zu verstehen, wie das Lastenmanagement in Kubernetes funktioniert, was beim Skalieren von langfristigen Verbindungen passiert und warum es sinnvoll ist, das Load Balancing auf der Client-Seite in Betracht zu ziehen, wenn Sie HTTP/2, gRPC, RSockets, AMQP oder andere langlebige Protokolle verwenden.
Ein wenig darüber, wie der Traffic in Kubernetes umverteilt wird
Kubernetes bietet zwei praktische Abstraktionen zur Bereitstellung von Anwendungen: Services und Deployments.
Deployments beschreiben, wie und wie viele Kopien Ihrer Anwendung jederzeit ausgeführt werden sollen. Jede Anwendung wird als Pod bereitgestellt und erhält eine IP-Adresse.
Services funktionieren ähnlich wie ein Lastenausgleich. Sie dienen dazu, den Traffic auf mehrere Pods zu verteilen.
Lassen Sie uns sehen, wie das aussieht.
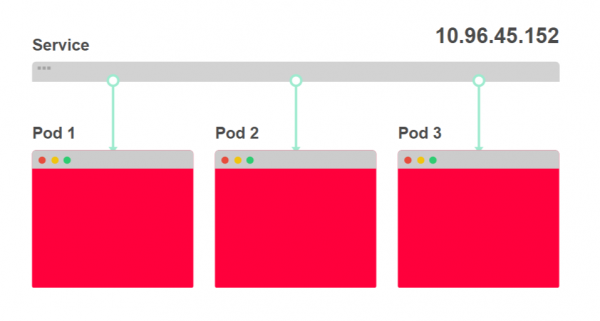
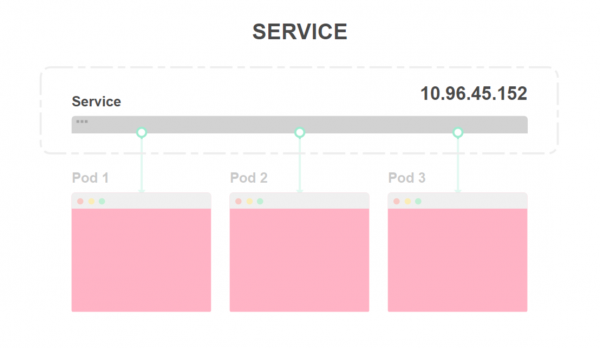
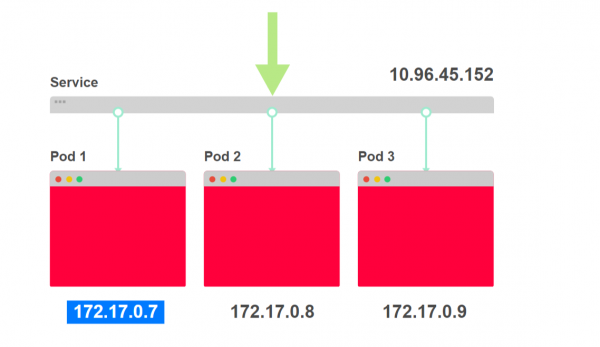
- Im folgenden Diagramm sehen Sie drei Instanzen einer Anwendung und den Lastenverteilungspunkt:

- Der Lastenverteilungspunkt wird als Service bezeichnet und erhält eine IP-Adresse. Jede eingehende Anfrage wird an einen der Pods weitergeleitet:

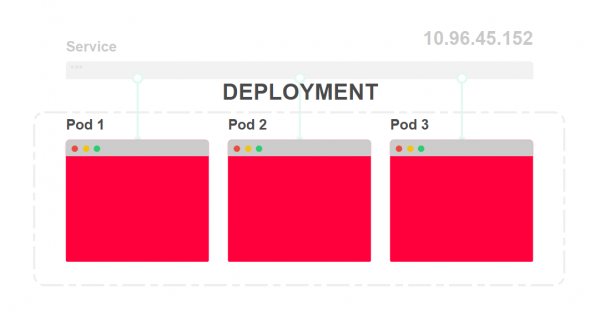
- Das Bereitstellungsszenario legt die Anzahl der Instanzen der Anwendung fest. Sie müssen praktisch nie direkt auf den Pod bereitstellen:

- Jedem Pod wird eine eigene IP-Adresse zugewiesen:

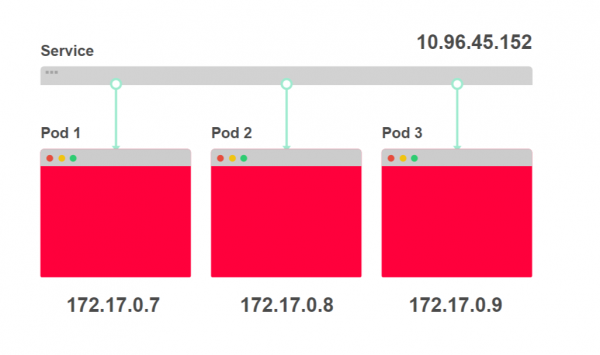
Es ist sinnvoll, Dienste als eine Sammlung von IP-Adressen zu betrachten. Jedes Mal, wenn Sie auf einen Dienst zugreifen, wird eine der IP-Adressen aus der Liste ausgewählt und als Zieladresse verwendet.
So sieht es aus:.
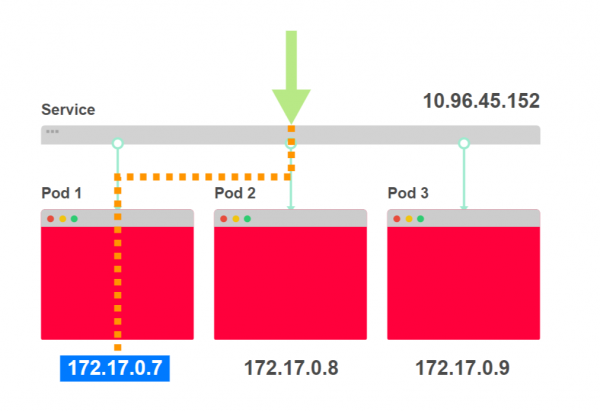
- Eine Anfrage wird über curl 10.96.45.152 an den Dienst gesendet:

- Der Dienst wählt eine der drei Pod-Adressen als Ziel:

- Der Datenverkehr wird an einen bestimmten Pod weitergeleitet:


Wenn Ihre Anwendung aus einem Frontend und einem Backend besteht, haben Sie sowohl einen Dienst als auch ein Deployment für jedes.
Wenn das Frontend eine Anfrage an das Backend sendet, muss es nicht wissen, wie viele Pods das Backend tatsächlich bedient: es können einer, zehn oder hundert sein.
Auch das Frontend weiß nichts über die IP-Adressen der Pods, die das Backend bedienen.
Wenn das Frontend eine Anfrage an das Backend sendet, verwendet es die IP-Adresse des Backend-Dienstes, die sich nicht ändert.
So sieht es aus:.
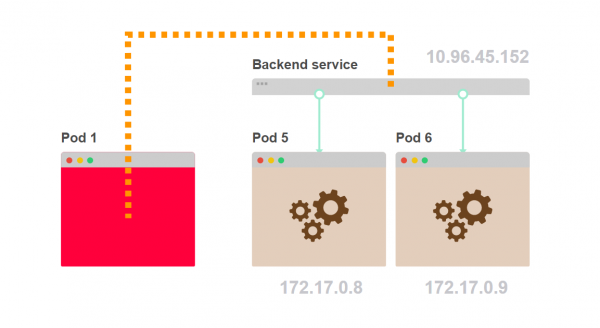
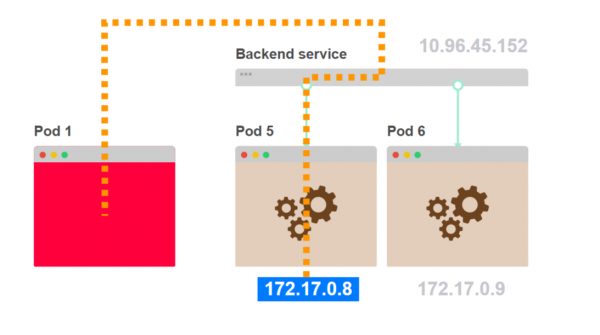
- Pod 1 fragt einen internen Backend-Komponenten. Anstatt einen bestimmten Pod des Backends auszuwählen, fragt er den Service an:

- Der Service wählt einen der Backend-Pods als Zieladresse aus:

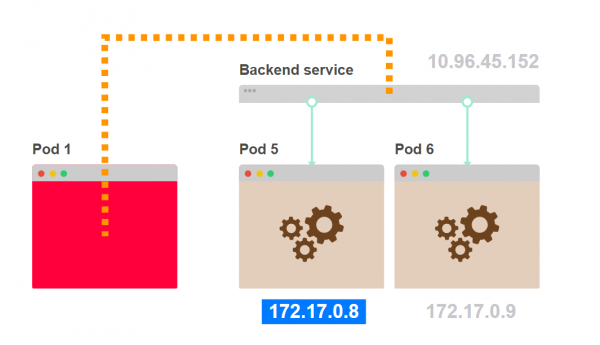
- Der Verkehr geht von Pod 1 zu Pod 5, der vom Service ausgewählt wurde:

- Pod 1 weiß nicht, wie viele Pods wie Pod 5 hinter dem Service verborgen sind:

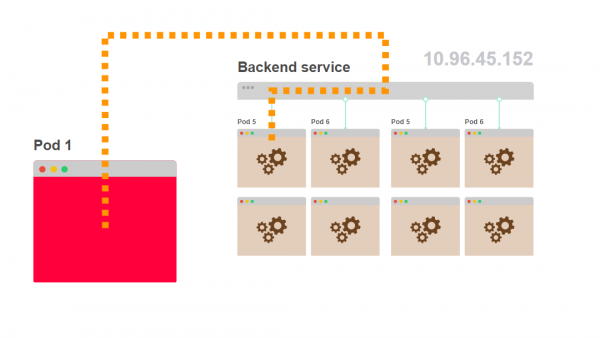
Aber wie genau verteilt der Service die Anfragen? Wird anscheinend Round-Robin-Balancing verwendet? Lassen Sie es uns klären.
Lastverteilung in Kubernetes-Services
Kubernetes-Services existieren nicht. Es gibt keinen Prozess, dem eine IP-Adresse und ein Port zugewiesen sind, der dem Service entspricht.
Sie können dies bestätigen, indem Sie zu einem beliebigen Knoten des Clusters gehen und den Befehl netstat -ntlp ausführen.
Sie werden nicht einmal die IP-Adresse finden, die dem Service zugewiesen ist.
Die IP-Adresse des Services wird in der Steuerungsebene platziert, im Controller, und in einer Datenbank — etcd — gespeichert. Diese Adresse wird auch von einer anderen Komponente — kube-proxy — verwendet.
Kube-proxy erhält eine Liste von IP-Adressen für alle Services und erstellt eine Gruppe von iptables-Regeln auf jedem Knoten des Clusters.
Diese Regeln besagen: 'Wenn wir die IP-Adresse des Services sehen, müssen wir die Zieladresse der Anfrage modifizieren und sie an einen der Pods senden.'
Die IP-Adresse des Dienstes wird nur als Einstiegspunkt verwendet und von keinem Prozess verwaltet, der auf diese IP-Adresse und den Port hört.
Schauen wir uns das an.
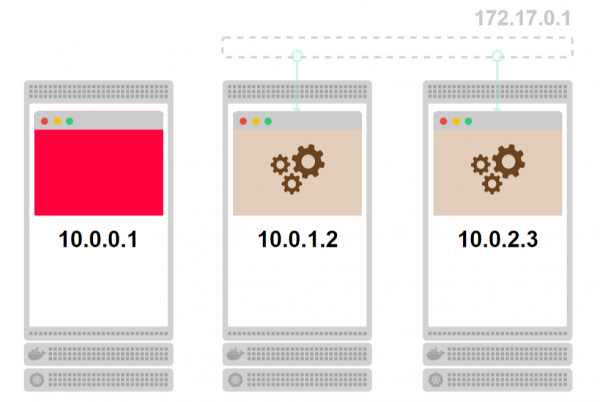
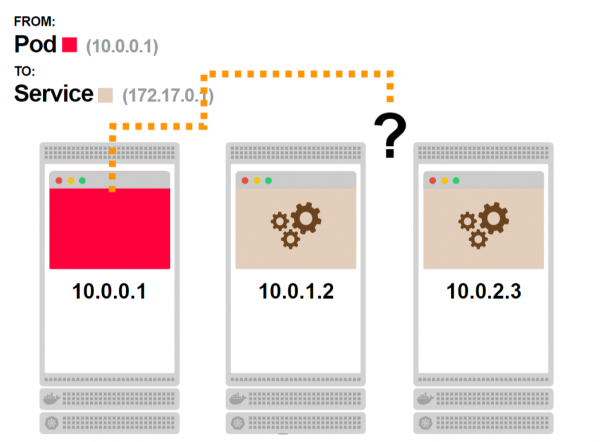
- Betrachten wir einen Cluster aus drei Nodes. Auf jeder Node befinden sich Pods:

- Die verbundenen Pods, die beige gefärbt sind, sind Teil des Dienstes. Da der Dienst nicht als Prozess existiert, wird er grau dargestellt:

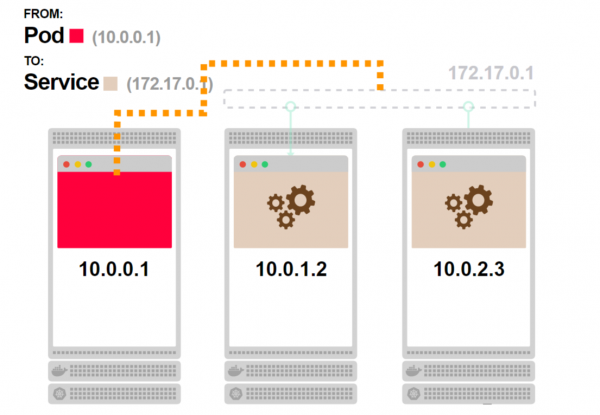
- Der erste Pod fragt den Dienst an und sollte einen der verbundenen Pods erreichen:

- Aber der Dienst existiert nicht, es gibt keinen Prozess. Wie funktioniert das?

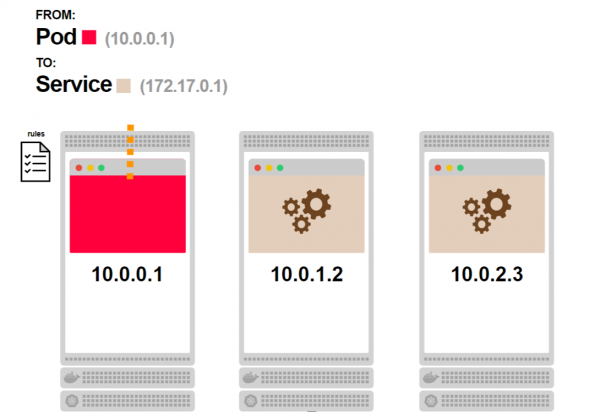
- Bevor die Anfrage die Node verlässt, durchläuft sie die iptables-Regeln:

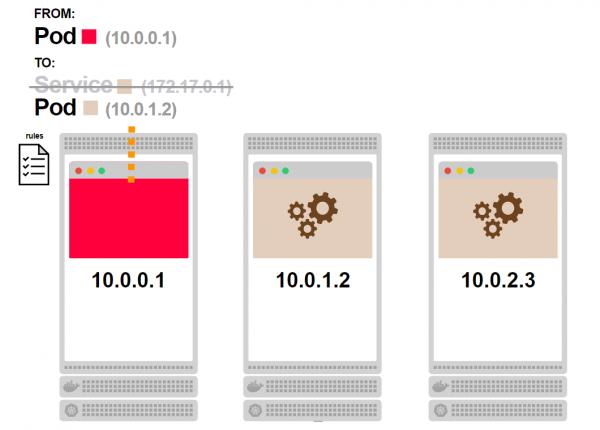
- Die iptables-Regeln wissen, dass der Dienst nicht existiert, und ersetzen seine IP-Adresse durch eine der IP-Adressen der Pods, die mit diesem Dienst verbunden sind:

- Die Anfrage erhält eine gültige IP-Adresse als Zieladresse und wird normal verarbeitet:
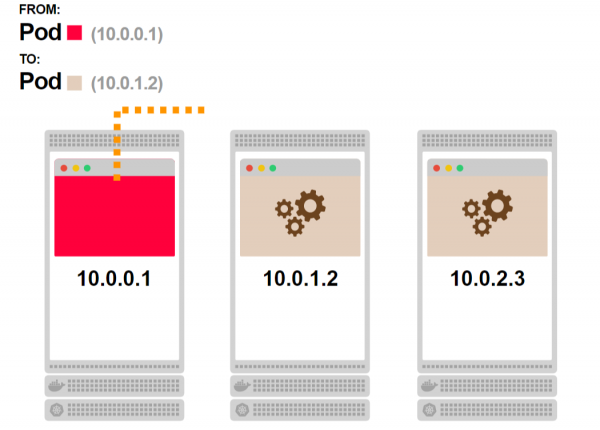
- Je nach Netzwerk-Topologie erreicht die Anfrage letztendlich den Pod:


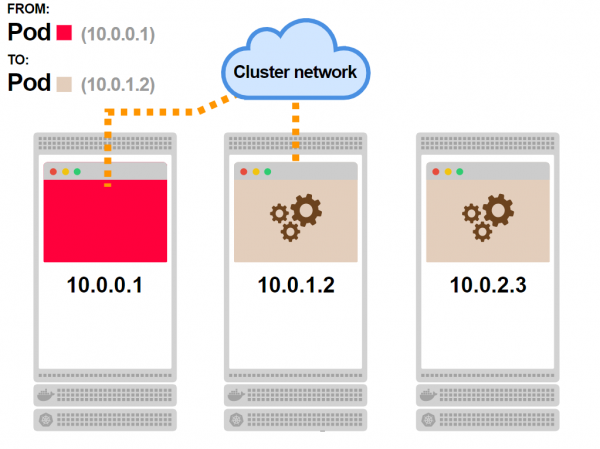
Können iptables Lasten ausbalancieren?
Nein, iptables werden zur Filterung verwendet und wurden nicht für das Lastenbalancieren entworfen.
Es besteht jedoch die Möglichkeit, eine Regelgruppe zu schreiben, die als .
arbeitet, und genau das wird in Kubernetes umgesetzt.
Wenn Sie drei Pods haben, erstellt kube-proxy die folgenden Regeln:
- Wählen Sie den ersten Pod mit einer Wahrscheinlichkeit von 33 %, andernfalls fahren Sie mit der nächsten Regel fort.
- Wählen Sie den zweiten Pod mit einer Wahrscheinlichkeit von 50 %, andernfalls fahren Sie mit der nächsten Regel fort.
- Wählen Sie den dritten Pod.
Dieses System führt dazu, dass jeder Pod mit einer Wahrscheinlichkeit von 33 % ausgewählt wird.
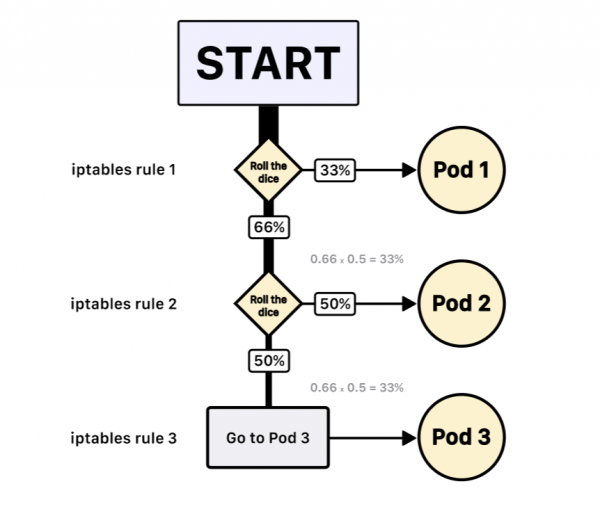
Und es gibt keine Garantie, dass Pod 2 nach Pod 1 als nächstes ausgewählt wird.
Hinweis: iptables verwendet ein statistisches Modul mit zufälliger Verteilung. Daher basiert der Lastenausgleichsalgorithmus auf zufälliger Auswahl.
Jetzt, da Sie verstehen, wie Dienste funktionieren, lassen Sie uns interessantere Szenarien betrachten.
Langfristige Verbindungen in Kubernetes skalieren standardmäßig nicht.
Jede HTTP-Anfrage vom Frontend zum Backend wird von einer separaten TCP-Verbindung bedient, die geöffnet und geschlossen wird.
Wenn das Frontend 100 Anfragen pro Sekunde an das Backend sendet, werden 100 unterschiedliche TCP-Verbindungen geöffnet und geschlossen.
Die Bearbeitungszeit einer Anfrage kann verkürzt und die Last reduziert werden, wenn eine TCP-Verbindung geöffnet und für alle folgenden HTTP-Anfragen verwendet wird.
Das HTTP-Protokoll umfasst eine Funktion, die als HTTP keep-alive oder Verbindungswiederverwendung bezeichnet wird. In diesem Fall wird eine TCP-Verbindung verwendet, um viele HTTP-Anfragen und -Antworten zu senden und zu empfangen:
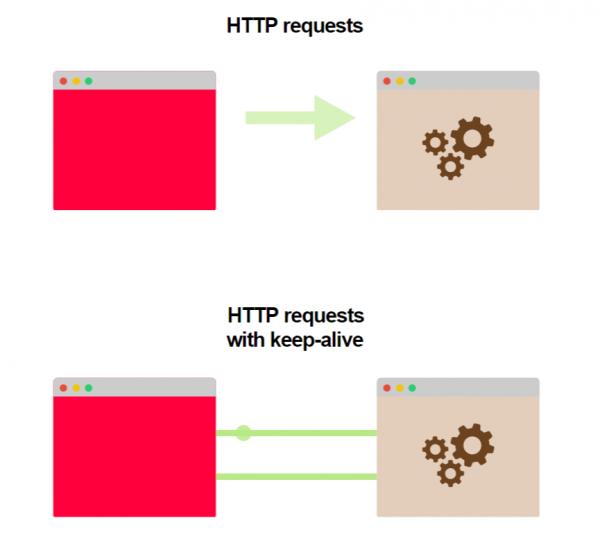
Diese Funktion ist standardmäßig nicht aktiviert: sowohl der Server als auch der Client müssen entsprechend konfiguriert sein.
Die Konfiguration selbst ist einfach und für die meisten Programmiersprachen und Umgebungen zugänglich.
Hier sind einige Links zu Beispielen in verschiedenen Sprachen:
Was passiert, wenn wir keep-alive in einem Kubernetes-Dienst verwenden?
Angenommen, sowohl das Frontend als auch das Backend unterstützen keep-alive.
Wir haben eine Instanz des Frontends und drei Instanzen des Backends. Das Frontend stellt die erste Anfrage und öffnet eine TCP-Verbindung zum Backend. Die Anfrage erreicht den Dienst, und einer der Pods des Backends wird als Zieladresse ausgewählt. Der Pod des Backends sendet eine Antwort, und das Frontend empfängt sie.
Im Unterschied zur normalen Situation, in der die TCP-Verbindung nach Erhalt der Antwort geschlossen wird, bleibt sie jetzt für die nachfolgenden HTTP-Anfragen offen.
Was passiert, wenn das Frontend weitere Anfragen an das Backend sendet?
Für die Weiterleitung dieser Anfragen wird eine offene TCP-Verbindung verwendet, alle Anfragen gelangen ins gleiche Backend-Pod, in das auch die erste Anfrage gelangte.
Sollte iptables den Verkehr nicht umverteilen?
Nicht in diesem Fall.
Wenn eine TCP-Verbindung hergestellt wird, durchläuft sie die iptables-Regeln, die das spezifische Backend-Pod auswählen, an das der Verkehr geleitet wird.
Da alle folgenden Anfragen über die bereits geöffnete TCP-Verbindung laufen, werden die iptables-Regeln nicht mehr aufgerufen.
Lassen Sie uns sehen, wie das aussieht.
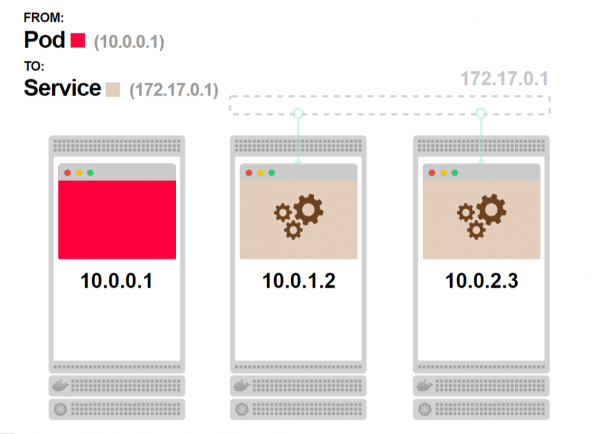
- Das erste Pod sendet eine Anfrage an den Dienst:

- Sie wissen bereits, was als Nächstes passiert. Der Dienst existiert nicht, aber es gibt iptables-Regeln, die die Anfrage bearbeiten:
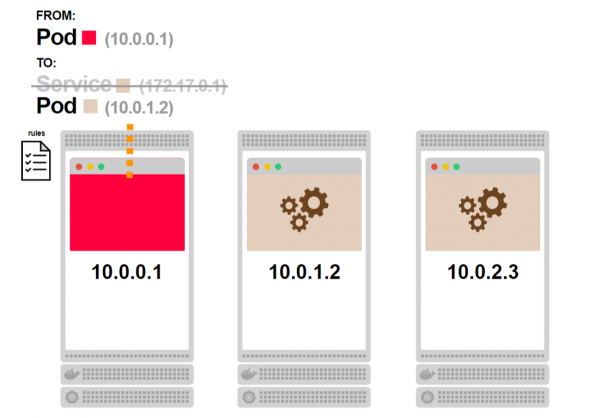
- Ein Pod des Backends wird als Zieladresse ausgewählt:

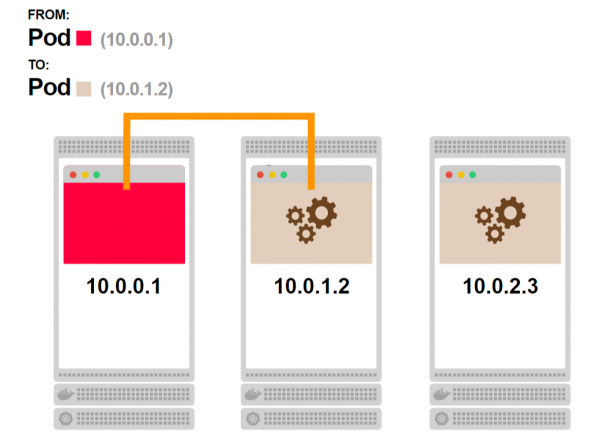
- Die Anfrage erreicht das Pod. In diesem Moment wird eine permanente TCP-Verbindung zwischen den beiden Pods hergestellt:

- Jede folgende Anfrage vom ersten Pod wird über die bereits eingerichtete Verbindung geleitet:

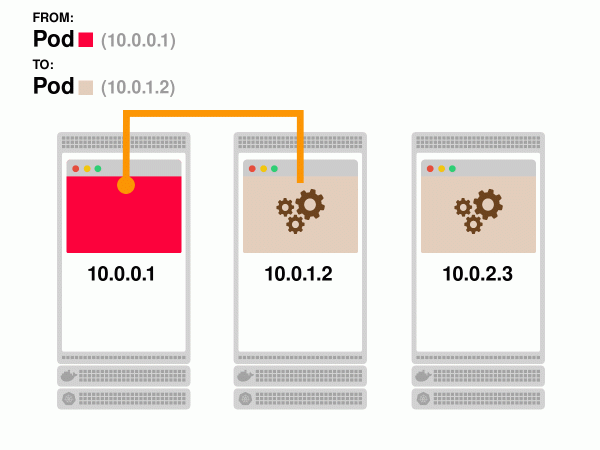
Das Ergebnis ist eine schnellere Antwortzeit und eine höhere Bandbreite, aber Sie haben die Möglichkeit zur Skalierung des Backends verloren.
Selbst wenn Sie zwei Pods im Backend haben, wird der Datenverkehr bei einer ständigen Verbindung immer an einen von ihnen geleitet.
Kann man das beheben?
Da Kubernetes nicht weiß, wie man dauerhafte Verbindungen ausbalanciert, liegt diese Aufgabe bei Ihnen.
Dienste sind eine Gruppe von IP-Adressen und Ports, die als Endpunkte bezeichnet werden.
Ihre Anwendung kann eine Liste von Endpunkten aus dem Dienst abrufen und entscheiden, wie die Anfragen zwischen ihnen verteilt werden. Sie können eine permanente Verbindung zu jedem Pod öffnen und die Anfragen über diese Verbindungen mit Round-Robin ausbalancieren.
Oder komplexere .
Der Client-Code, der für das Balancieren verantwortlich ist, sollte folgender Logik folgen:
- Holen Sie sich die Liste der Endpunkte aus dem Dienst.
- Für jeden Endpunkt eine dauerhafte Verbindung öffnen.
- Wenn eine Anfrage erforderlich ist, eines der offenen Verbindungen verwenden.
- Die Liste der Endpunkte regelmäßig aktualisieren, neue dauerhafte Verbindungen erstellen oder alte schließen, wenn sich die Liste ändert.
So wird es aussehen.
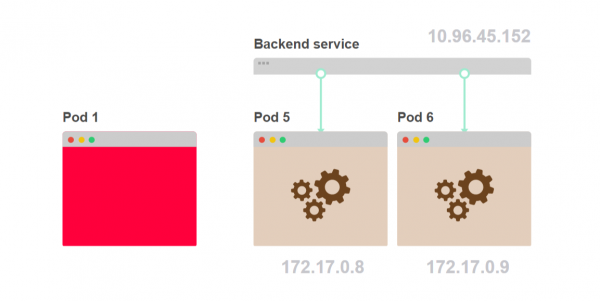
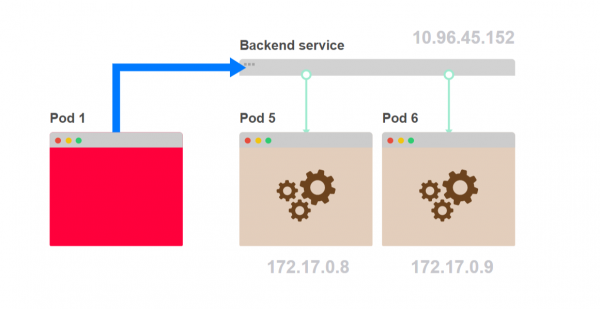
- Anstatt dass der erste Pod die Anfrage an den Dienst sendet, können Sie die Anfragen auf der Client-Seite verwalten:

- Es muss Code geschrieben werden, der abfragt, welche Pods Teil des Dienstes sind:

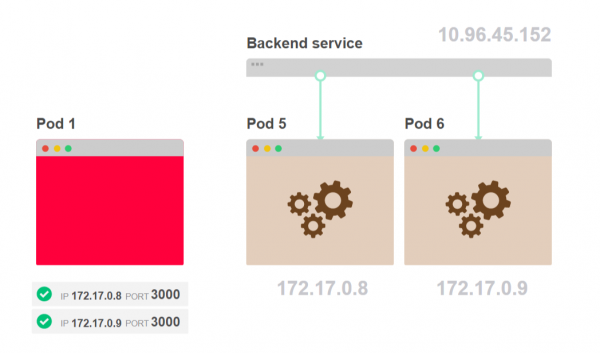
- Sobald Sie die Liste erhalten, speichern Sie sie auf der Client-Seite und verwenden Sie sie zum Herstellen der Verbindung zu den Pods:

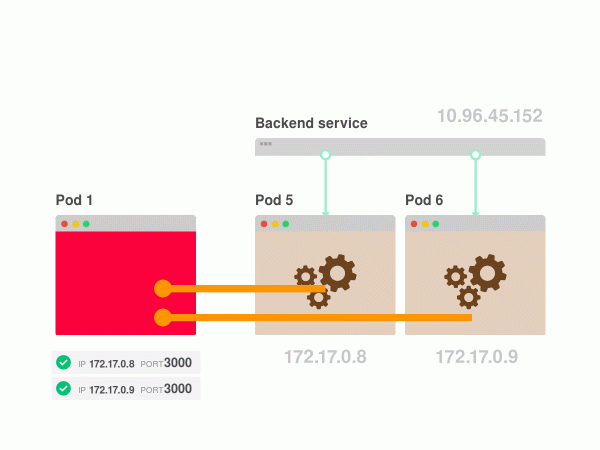
- Sie sind selbst für den Lastverteilungsalgorithmus verantwortlich:
Nun stellt sich die Frage: Betrifft dieses Problem nur HTTP keep-alive?
Lastverteilung auf der Client-Seite
HTTP ist nicht das einzige Protokoll, das permanente TCP-Verbindungen nutzen kann.
Wenn Ihre Anwendung eine Datenbank verwendet, wird die TCP-Verbindung nicht jedes Mal geöffnet, wenn Sie eine Anfrage stellen oder ein Dokument aus der DB abrufen müssen.
Stattdessen wird eine permanente TCP-Verbindung zur Datenbank geöffnet und verwendet.
Wenn Ihre Datenbank in Kubernetes bereitgestellt ist und der Zugriff als Dienst verfügbar ist, werden Sie mit denselben Problemen konfrontiert, die im vorherigen Abschnitt beschrieben wurden.
Eine Datenbank-Replik wird stärker belastet als die anderen. Kube-proxy und Kubernetes helfen nicht, Verbindungen auszubalancieren. Sie müssen sich um das Lastenausgleich von Anfragen an Ihre Datenbank kümmern.
Je nach der Bibliothek, die Sie zur Verbindung mit der Datenbank verwenden, gibt es unterschiedliche Möglichkeiten zur Lösung dieses Problems.
Im Folgenden finden Sie ein Beispiel für den Zugriff auf ein MySQL-Datenbankcluster aus Node.js:
var mysql = require('mysql');
var poolCluster = mysql.createPoolCluster();
var endpoints = /* endpoints aus dem Dienst abrufen */
for (var [index, endpoint] of endpoints) {
poolCluster.add(`mysql-replica-${index}`, endpoint);
}
// Abfragen an die gruppierte MySQL-Datenbank stellenEs gibt viele andere Protokolle, die konstante TCP-Verbindungen verwenden:
- WebSockets und gesicherte WebSockets
- HTTP/2
- gRPC
- RSockets
- AMQP
Sie sollten mit den meisten dieser Protokolle bereits vertraut sein.
Aber wenn diese Protokolle so beliebt sind, warum gibt es dann keine standardisierte Lösung für den Lastenausgleich? Warum muss die Logik des Clients geändert werden? Gibt es eine native Lösung in Kubernetes?
Kube-proxy und iptables wurden entwickelt, um die meisten standardmäßigen Anwendungsfälle beim Deployment in Kubernetes abzudecken. Dies erfolgt zur Vereinfachung.
Wenn Sie einen Webdienst nutzen, der eine REST-API bereitstellt, haben Sie Glück – in diesem Fall werden keine dauerhaften TCP-Verbindungen verwendet, und Sie können jeden Kubernetes-Dienst nutzen.
Sobald Sie jedoch damit beginnen, dauerhafte TCP-Verbindungen zu nutzen, müssen Sie herausfinden, wie Sie die Last gleichmäßig auf die Backends verteilen können. Kubernetes bietet dafür keine sofort einsatzbereiten Lösungen.
Es gibt jedoch natürlich Optionen, die helfen können.
Lastverteilung von langlebigen Verbindungen in Kubernetes
In Kubernetes gibt es vier Arten von Diensten:
- ClusterIP
- NodePort
- LoadBalancer
- Headless
Die ersten drei Dienste arbeiten auf der Basis einer virtuellen IP-Adresse, die kube-proxy verwendet, um iptables-Regeln zu erstellen. Aber die grundlegende Grundlage aller Dienste ist der headless Dienst.
Mit dem headless Dienst ist keine IP-Adresse verknüpft, er bietet lediglich einen Mechanismus zum Abrufen der Liste von IP-Adressen und Ports, die mit den entsprechenden Pods (Endpunkten) verknüpft sind.
Alle Dienste basieren auf dem headless Dienst.
Der ClusterIP-Dienst ist ein headless Dienst mit einigen Ergänzungen:
- Die Verwaltungsschicht weist ihm eine IP-Adresse zu.
- Kube-proxy erstellt die erforderlichen iptables-Regeln.
So können Sie kube-proxy ignorieren und direkt die Endpunktliste verwenden, die aus dem headless Service zur Lastverteilung in Ihrer Anwendung abgerufen wurde.
Aber wie können Sie eine solche Logik auf alle Anwendungen anwenden, die im Cluster bereitgestellt sind?
Wenn Ihre Anwendung bereits bereitgestellt ist, kann diese Aufgabe unmöglich erscheinen. Es gibt jedoch eine alternative Lösung.
Die Service Mesh wird Ihnen helfen.
Sie haben vielleicht bereits festgestellt, dass die Lastverteilungsstrategie auf der Clientseite ganz standardmäßig ist.
Wenn die Anwendung gestartet wird,
- holt sie die Liste der IP-Adressen aus dem Service.
- öffnet und hält einen Pool von Verbindungen aufrecht.
- aktualisiert den Pool regelmäßig, indem sie Endpunkte hinzufügt oder entfernt.
Sobald die Anwendung eine Anfrage stellen möchte,
- wählt sie eine verfügbare Verbindung unter Verwendung einer bestimmten Logik (zum Beispiel Round-Robin).
- führt die Anfrage aus.
Diese Schritte gelten sowohl für WebSocket-Verbindungen als auch für gRPC und AMQP.
Sie können diese Logik in eine eigene Bibliothek auslagern und in Ihren Anwendungen verwenden.
Alternativ können Sie jedoch Service-Meshes wie Istio oder Linkerd verwenden.
Service Mesh ergänzt Ihre Anwendung mit einem Prozess, der:
- Sucht automatisch nach IP-Adressen von Diensten.
- Überprüft Verbindungen wie WebSockets und gRPC.
- Lastet Anfragen unter Verwendung des richtigen Protokolls aus.
Ein Service Mesh hilft, den Datenverkehr innerhalb des Clusters zu verwalten, ist jedoch recht ressourcenintensiv. Alternativen sind die Verwendung von Drittanbieter-Bibliotheken wie Netflix Ribbon oder programmierbaren Proxys wie Envoy.
Was passiert, wenn man die Fragen zur Lastverteilung ignoriert?
Sie können auf Lastverteilung verzichten, ohne dass Ihnen wesentliche Änderungen auffallen. Lassen Sie uns einige Szenarien betrachten.
Wenn Sie mehr Clients als Server haben, ist das nicht so problematisch.
Angenommen, es gibt fünf Clients, die sich mit zwei Servern verbinden. Auch ohne Lastverteilung werden beide Server genutzt:
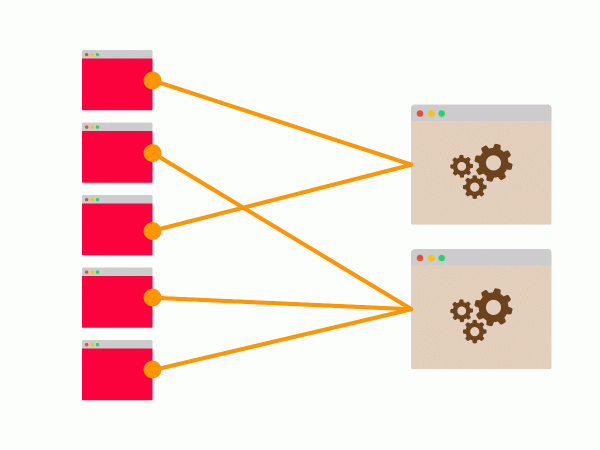
Die Verbindungen können ungleichmäßig verteilt sein: Möglicherweise haben sich vier Clients mit demselben Server verbunden, aber es besteht eine gute Chance, dass beide Server verwendet werden.
Problematischer ist der gegenteilige Szenario.
Wenn Sie weniger Kunden und mehr Server haben, könnten Ihre Ressourcen ungenutzt bleiben, was zu einem potenziellen Engpass führt.
Nehmen wir an, es gibt zwei Kunden und fünf Server. Im besten Fall gibt es zwei dauerhafte Verbindungen zu zwei von fünf Servern.
Die übrigen Server werden inaktiv sein:
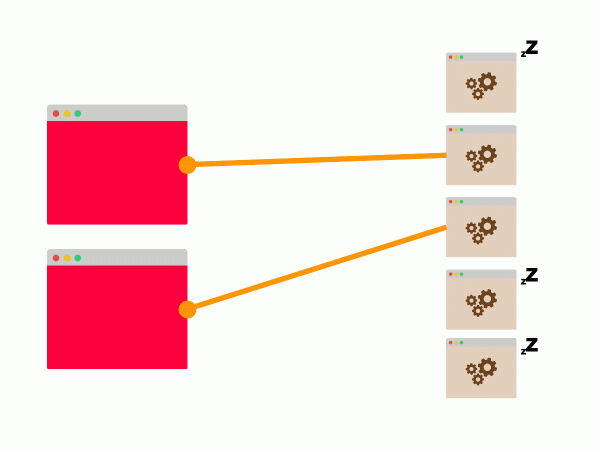
Wenn diese beiden Server nicht in der Lage sind, die Kundenanfragen zu verarbeiten, wird horizontale Skalierung nicht helfen.
Fazit
Kubernetes-Dienste sind für den Einsatz in den meisten Standardszenarien von Webanwendungen konzipiert.
Sobald Sie jedoch mit Anwendungsprotokollen arbeiten, die dauerhafte TCP-Verbindungen verwenden, wie Datenbanken, gRPC oder WebSockets, sind die Dienste nicht mehr geeignet. Kubernetes bietet keine internen Mechanismen zur Lastverteilung für dauerhafte TCP-Verbindungen.
Das bedeutet, dass Sie Anwendungen unter Berücksichtigung der Möglichkeit der Lastverteilung auf der Client-Seite schreiben müssen.
Übersetzung von dem Team vorbereitet .
Weitere Lesetipps zu diesem Thema:
- .
- .
- .
Quelle: habr.com
