

Wie man Geschäftsanforderungen in spezifische Datenstrukturen umwandelt am Beispiel der Planung einer Datenbank von Grund auf für einen Messenger.
- Teil 1: das Gerüst der Datenbank entwerfen

Unsere Datenbank wird nicht so groß und verteilt sein wie die von oder , sondern eher bescheiden, aber dennoch gut – funktional, schnell und auf einem Server Platz finden. PostgreSQL – damit wir einen separaten Instanz des Dienstes irgendwo anders bereitstellen können, zum Beispiel.
Deshalb werden wir keine Fragen zu Sharding, Replikation und geo-distribuierten Systemen behandeln, sondern uns auf die strukturellen Lösungen innerhalb der Datenbank konzentrieren.
Schritt 1: Ein wenig geschäftsspezifische Informationen
Wir werden unseren Nachrichtenaustausch nicht abstrakt entwerfen, sondern in die Umgebung integrieren. Das heißt, die Menschen kommunizieren nicht einfach, sondern interagieren im Kontext der Lösung spezifischer Geschäftsprobleme.
Welche Aufgaben hat ein Unternehmen?... Schauen wir uns das am Beispiel von Vasily, dem Leiter der Entwicklungsabteilung, an.
- "Nikolai, der Patch für diese Aufgabe wird bereits heute benötigt!"
Das bedeutet, dass die Kommunikation im Kontext von etwas stattfinden kann. des Dokuments. - "Koya, lass uns heute Abend Dota spielen?"
Das bedeutet, dass sogar bei einem Paar von Gesprächspartnern gleichzeitig über verschiedene Themen kommuniziert werden kann.. - „Peter, Nikolai, schaut euch im Anhang die Preisliste für den neuen Server an.”
So kann eine Nachricht mehrere Empfänger haben.. Dabei kann die Nachricht angehängte Dateien enthalten.. - „Semen, du solltest auch einen Blick darauf werfen.”
Und es sollte möglich sein, einen neuen Teilnehmer in die bereits bestehende Korrespondenz einzuladen..
Lassen Sie uns vorerst bei dieser Liste der „offensichtlichen” Bedürfnisse bleiben.
Ohne das Verständnis der spezifischen Anforderungen und der ihnen auferlegten Einschränkungen ist es praktisch unmöglich, eine effektive Datenbankschema für deren Lösung zu entwerfen.
Schritt 2: Minimales logisches Schema
Vorläufig ähnelt alles sehr der E-Mail-Korrespondenz — einem traditionellen Geschäftsführungstool. Ja, „algorithmisch” ähneln sich viele Geschäftsaufgaben, daher werden auch die Werkzeuge zu ihrer Lösung strukturell ähnlich sein.
Lassen Sie uns das bereits erhaltene logische Schema der Entitätenbeziehungen festhalten. Zur Vereinfachung des Verständnisses unserer Modell nutzen wir die einfachste Form der Darstellung ohne komplizierte UML- oder IDEF-Notation.
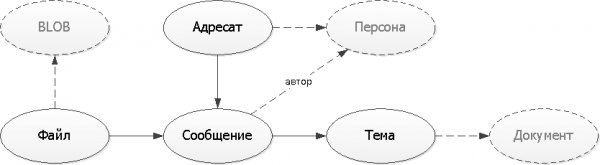
In unserem Beispiel sind die Persona, das Dokument und das binäre „Körper“ der Datei „externe“ Entitäten, die unabhängig von unserem Dienst existieren. Daher betrachten wir sie künftig einfach als Links „irgendwo“ über UUID.
Zeichnen Sie Schemen so einfach wie möglich — Die meisten derjenigen, die Sie sie zeigen werden, sind keine Experten im Lesen von UML/IDEF. Aber zeichnen Sie unbedingt.
Schritt 3: Skizzieren Sie die Struktur der Tabellen
Über die Namen von Tabellen und FeldernZu 'russischen' Bezeichnungen für Felder und Tabellen kann man unterschiedlich stehen, aber das ist Geschmackssache. Da keine ausländischen Entwickler haben und PostgreSQL uns erlaubt, auch mit Hieroglyphen zu benennen, wenn sie in Anführungszeichen stehen, bevorzugen wir es, Objekte eindeutig verständlich zu benennen, um Missverständnisse zu vermeiden.
Da viele Menschen gleichzeitig Nachrichten schreiben, können einige von ihnen dies im Offline-Modus, ist die einfachste Option — UUIDs als Identifikatoren zu verwenden nicht nur für externe Entitäten, sondern auch für alle Objekte innerhalb unseres Dienstes. Zudem können sie sogar auf der Client-Seite generiert werden — das hilft uns, den Versand von Nachrichten bei kurzfristiger Nichtverfügbarkeit der DB aufrechtzuerhalten, und die Wahrscheinlichkeit einer Kollision ist äußerst niedrig.
Die Rohstruktur der Tabellen in unserer Datenbank wird folgendermaßen aussehen:
Tabellen : RU
ERSTELLE TABELLE "Thema"(
"Thema"
uuid
PRIMARY KEY
, "Dokument"
uuid
, "Titel"
text
);
ERSTELLE TABELLE "Nachricht"(
"Nachricht"
uuid
PRIMARY KEY
, "Thema"
uuid
, "Autor"
uuid
, "DatumUhrzeit"
timestamp
, "Text"
text
);
ERSTELLE TABELLE "Empfänger"(
"Nachricht"
uuid
, "Person"
uuid
, PRIMARY KEY("Nachricht", "Person")
);
ERSTELLE TABELLE "Datei"(
"Datei"
uuid
PRIMARY KEY
, "Nachricht"
uuid
, "BLOB"
uuid
, "Name"
text
);Tabellen : EN
ERSTELLE TABELLE thema(
thema
uuid
PRIMARY KEY
, dokument
uuid
, titel
text
);
ERSTELLE TABELLE nachricht(
nachricht
uuid
PRIMARY KEY
, thema
uuid
, autor
uuid
, dt
timestamp
, text
text
);
ERSTELLE TABELLE nachricht_empfänger(
nachricht
uuid
, person
uuid
, PRIMARY KEY(nachricht, person)
);
ERSTELLE TABELLE nachricht_datei(
datei
uuid
PRIMARY KEY
, nachricht
uuid
, inhalt
uuid
, dateiname
text
);Am einfachsten beginnt man bei der Beschreibung des Formats, indem man die Beziehungsgrafik "enthüllt". von Tabellen, die nicht referenzieren sich selbst auf niemanden.
Schritt 4: Offensichtliche Bedürfnisse klären
So, wir haben eine Datenbank entworfen, in die man ausgezeichnet schreiben und irgendwie lesen kann.
Lassen Sie uns in die Lage des Nutzers unseres Services versetzen — was würden wir mit dessen Hilfe tun wollen?
- Neueste Nachrichten
Das chronologisch sortiert nach verschiedenen Kriterien eine Übersicht meiner Nachrichten. Wo ich einer der Adressaten bin, wo ich der Autor bin, wo man mir geschrieben hat, aber ich nicht geantwortet habe, wo mir nicht geantwortet wurde, … - Teilnehmer der Konversation
Wer nimmt eigentlich an diesem langen, langen Chat teil?
Unsere Struktur ermöglicht es, beide Aufgaben ‚insgesamt‘ zu lösen, aber schnell – nein. Das Problem ist, dass für die Sortierung im Rahmen der ersten Aufgabe es unmöglich ist, einen Index zu erstellen, der für jeden der Teilnehmer geeignet ist (und man muss alle Aufzeichnungen abrufen), und zur Lösung der zweiten Aufgabe ist es notwendig alle Nachrichten zum Thema zu extrahieren.
Unvorhergesehene Benutzeraufgaben können ein fettes Kreuz für die Leistung setzen..
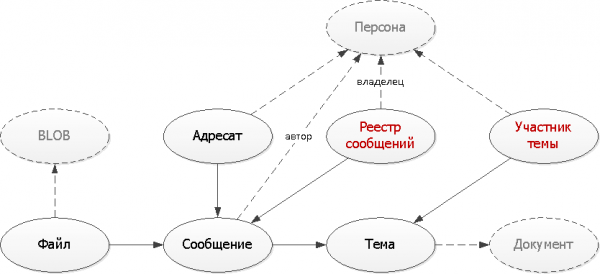
Schritt 5: Sinnvolle Denormalisierung
Beide unsere Probleme können durch zusätzliche Tabellen gelöst werden, in die wir einen Teil der Daten duplizieren, die erforderlich sind, um geeignete Indizes für unsere Aufgaben zu erstellen.
Tabellen : RU
CREATE TABLE "Nachrichtenregister"(
"Eigentümer"
uuid
, "RegistryTyp"
smallint
, "DatumUhrzeit"
timestamp
, "Nachricht"
uuid
, PRIMARY KEY("Eigentümer", "RegistryTyp", "Nachricht")
);
CREATE INDEX ON "Nachrichtenregister"("Eigentümer", "RegistryTyp", "DatumUhrzeit" DESC);
CREATE TABLE "ThemenTeilnehmer"(
"Thema"
uuid
, "Person"
uuid
, PRIMARY KEY("Thema", "Person")
);Tabellen : EN
CREATE TABLE message_registry(
owner
uuid
, registry
smallint
, dt
timestamp
, message
uuid
, PRIMARY KEY(owner, registry, message)
);
CREATE INDEX ON message_registry(owner, registry, dt DESC);
CREATE TABLE theme_participant(
theme
uuid
, person
uuid
, PRIMARY KEY(theme, person)
);Hier haben wir zwei typische Ansätze angewendet, die beim Erstellen von Hilfstabellen verwendet werden:
- Multiplikation von Datensätzen
Wir erstellen aus einem ursprünglichen Nachrichtendatensatz mehrere Folgedatensätze in verschiedene Arten von Registern für unterschiedliche Eigentümer — sowohl für den Absender als auch für den Empfänger. So wird jedes Register nun auf einen Index gelegt — denn im typischen Fall möchten wir nur die erste Seite sehen. - Eindeutigkeit der Datensätze
Bei jedem Versenden einer Nachricht innerhalb eines bestimmten Themas genügt es zu überprüfen, ob ein solcher Datensatz bereits existiert. Wenn nicht — fügen wir ihn in unser „Wörterbuch“ ein.
Im nächsten Teil des Artikels wird es um in die Struktur unserer Datenbank.
Quelle: habr.com
