

Wir haben die Struktur unserer PostgreSQL-Datenbank für die Speicherung von Korrespondenz erfolgreich entworfen. Ein Jahr ist vergangen, und die Benutzer fügen aktiv Inhalte hinzu; mittlerweile sind bereits Millionen von Einträgen, und… es beginnt alles, ein wenig langsam zu werden.
- Teil 2: „live“ partitionieren

Das Problem ist, dass Mit der Zunahme der Tabellenmenge steigt auch die „Tiefe“ der Indizes – wenn auch logarithmisch. Doch im Laufe der Zeit führt dies dazu, dass der Server für denselben Lese-/Schreibvorgang weit mehr Daten-Seiten verarbeiten muss, als zu Beginn.
Hier kommt das Partitionieren.
ins Spiel. Ich möchte erwähnen, dass es nicht um Sharding geht, also um die Verteilung von Daten auf verschiedene Datenbanken oder Server. Denn selbst wenn Sie die Daten auf mehrere Server aufteilen, werden Sie das Problem der „aufgeblähten“ Indizes im Laufe der Zeit nicht los. Es ist klar, dass, wenn Sie es sich leisten können, jeden Tag einen neuen Server in Betrieb zu nehmen, Ihre Probleme nicht mehr nur im Bereich einer bestimmten Datenbank liegen werden.
Wir werden keine speziellen Skripte für die Implementierung des Partitionierens „in der Hardware“ betrachten, sondern vielmehr den Ansatz – was und wie man in „Stücke“ schneiden sollte und welche Folgen dieser Wunsch haben kann.
Konzept
Lassen Sie uns unser Ziel noch einmal festlegen: Wir möchten sicherstellen, dass die Anzahl der lesbaren PostgreSQL-Daten bei jeder Lese-/Schreiboperation sowohl heute als auch morgen und in einem Jahr ungefähr gleich bleibt.
Für alle chronologisch angesammelten Daten (Nachrichten, Dokumente, Protokolle, Archive, …) ist das natürliche Selektionskriterium für den Partitionierungsschlüssel das Datum/Uhrzeit des Ereignisses. In unserem Fall ist ein solches Ereignis der Zeitpunkt des Versendens der Nachricht.
Es ist anzumerken, dass Benutzer nahezu immer nur mit den „letzten“ solchen Daten arbeiten — sie lesen die neuesten Nachrichten, analysieren die letzten Protokolle,… Nein, natürlich können sie auch weiter zurückscrollen, aber das tun sie sehr selten.
Aus diesen Einschränkungen wird deutlich, dass die optimale Lösung für Nachrichten „tägliche“ Partitionen sind — denn fast immer wird unser Benutzer die Daten lesen, die ihm „heute“ oder „gestern“ zugekommen sind.
Wenn wir den Tag über fast nur in eine Partition schreiben und lesen, ermöglicht uns das außerdem eine effizientere Nutzung von Speicher und Festplatte. — da alle Indizes des Abschnitts problemlos in den Arbeitsspeicher passen, im Gegensatz zu den "großen und dicken" in der gesamten Tabelle.
Schritt für Schritt
Insgesamt klingt alles, was bisher gesagt wurde, wie ein durchgehender Gewinn. Und er ist erreichbar, aber dafür müssen wir uns anstrengen — denn die Entscheidung, eine der Entitäten zu sektionieren, führt zur Notwendigkeit, auch die damit verbundenen.
Nachricht, ihre Eigenschaften und Projektionen
Da wir beschlossen haben, die Nachrichten nach Daten zu schneiden, macht es auch Sinn, die abhängigen Entitäten-Eigenschaften (Anhänge, Empfängerliste) ebenfalls zu teilen, und auch nach dem Datum der Nachricht.
Da eine unserer typischen Aufgaben darin besteht, die Register der Nachrichten zu durchsuchen (ungelesen, eingehend, alle), ist es auch logisch, sie in die Sektionierung nach den Nachrichten zu involvieren.
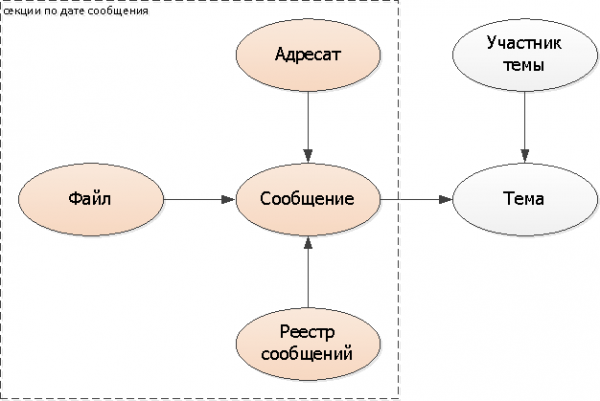
Wir fügen den Sektionierungsschlüssel (das Datum der Nachricht) in alle Tabellen ein: Empfänger, Datei, Register. In die Nachricht selbst kann man ihn nicht hinzufügen, sondern das bestehende Datum nutzen.
Themen
Da das Thema mehrere Nachrichten betrifft, kann es in demselben Modell nicht „geteilt“ werden; wir müssen uns auf etwas anderes stützen. In unserem Fall eignet sich perfekt Datum der ersten Nachricht im Chatverlauf — also der Zeitpunkt der Erstellung des Themas.
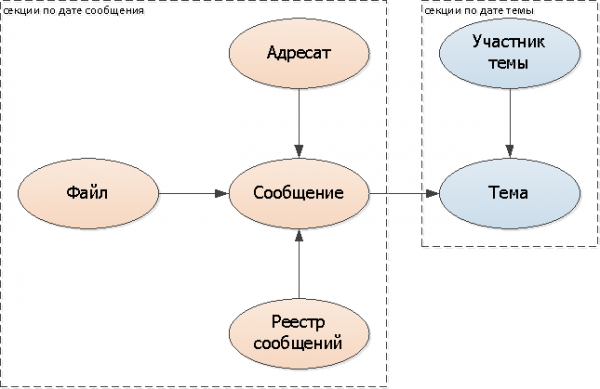
Fügen wir den Sektionierungskey (Datum des Themas) in alle Tabellen ein: Thema, Teilnehmer.
Nun haben wir jedoch gleich zwei Probleme:
- In welcher Sektion sollen wir nach Nachrichten zum Thema suchen?
- In welcher Sektion suchen wir das Thema aus der Nachricht?
Natürlich könnten wir weiterhin in allen Sektionen suchen, aber das wäre sehr frustrierend und würde all unsere Gewinne zunichte machen. Daher, um genau zu wissen, wo wir suchen sollen, erstellen wir logische Links/Referenzen auf die Sektionen:
- In der Nachricht fügen wir hinzu ein Feld mit dem Datum des Themas
- Zum Thema fügen wir hinzu eine Sammlung von Nachrichten-Daten dieser Unterhaltung (entweder in einer separaten Tabelle oder als Array von Daten)
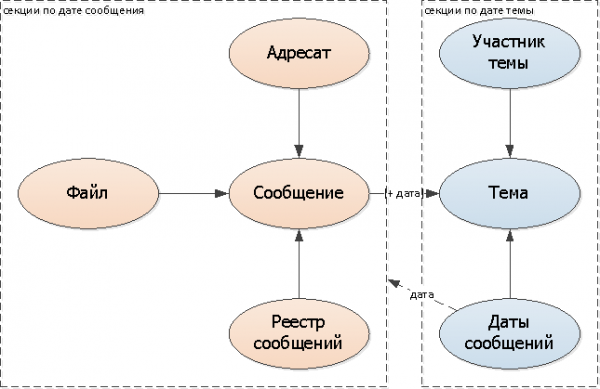
Da es nur wenige Änderungen der Nachrichten-Daten für jede einzelne Unterhaltung geben wird (da fast alle Nachrichten innerhalb von 1-2 benachbarten Tagen fallen), werde ich mich genau auf diese Variante konzentrieren.
Zusammenfassend hat sich die Struktur unserer Datenbank unter Berücksichtigung der Sektionierung wie folgt entwickelt:
Tabellen: RU, bei Abneigung gegen Kyrillisch in den Tabellennamen/Feldern besser nicht schauen
-- Abschnitte nach Datum der Nachricht
CREATE TABLE "Nachricht_YYYYMMDD"(
"Nachricht"
uuid
PRIMARY KEY
, "Thema"
uuid
, "DatumThema"
date
, "Autor"
uuid
, "DatumUhrzeit" -- verwenden wir als Datum
timestamp
, "Text"
text
);
CREATE TABLE "Adressat_YYYYMMDD"(
"DatumNachricht"
date
, "Nachricht"
uuid
, "Person"
uuid
, PRIMARY KEY("Nachricht", "Person")
);
CREATE TABLE "Datei_YYYYMMDD"(
"DatumNachricht"
date
, "Datei"
uuid
PRIMARY KEY
, "Nachricht"
uuid
, "BLOB"
uuid
, "Name"
text
);
CREATE TABLE "RegisterNachrichten_YYYYMMDD"(
"DatumNachricht"
date
, "Besitzer"
uuid
, "TypRegister"
smallint
, "DatumUhrzeit"
timestamp
, "Nachricht"
uuid
, PRIMARY KEY("Besitzer", "TypRegister", "Nachricht")
);
CREATE INDEX ON "RegisterNachrichten_YYYYMMDD"("Besitzer", "TypRegister", "DatumUhrzeit" DESC);
-- Abschnitte nach Datum des Themas
CREATE TABLE "Thema_YYYYMMDD"(
"DatumThema"
date
, "Thema"
uuid
PRIMARY KEY
, "Dokument"
uuid
, "Titel"
text
);
CREATE TABLE "TeilnehmerThema_YYYYMMDD"(
"DatumThema"
date
, "Thema"
uuid
, "Person"
uuid
, PRIMARY KEY("Thema", "Person")
);
CREATE TABLE "DatenNachrichtenThema_YYYYMMDD"(
"DatumThema"
date
, "Thema"
uuid
PRIMARY KEY
, "Datum"
date
);
Wir sparen ein paar Cent
Nun, was ist, wenn wir nicht Basierend auf der Verteilung der Feldwerte (durch Trigger und Vererbung oder PARTITION BY) sowie manuell auf Anwendungsebene kann man feststellen, dass der Wert des Partitionierungsschlüssels bereits im Namen der Tabelle selbst gespeichert ist.
Wenn Sie also so sehr über das Volumen der gespeicherten Daten besorgt sind, dann können Sie auf diese „überflüssigen“ Felder verzichten und gezielt auf bestimmte Tabellen zugreifen. Allerdings müssen in diesem Fall alle Abfragen über mehrere Partitionen auf die Anwendungsebene verlagert werden.
Quelle: habr.com
