


Hallo, neulich stieß ich auf eine interessante Aufgabe: einen Speicher für die Sicherung einer großen Anzahl von Blockgeräten einzurichten.
Jede Woche führen wir Backups aller virtuellen Maschinen in unserer Cloud durch. Daher ist es wichtig, mit tausenden von Backups umzugehen und dies so schnell und effizient wie möglich zu tun.
Leider sind die Standardkonfigurationen RAID5, RAID6 in diesem Fall nicht geeignet, da der Wiederherstellungsprozess auf so großen Festplatten wie unseren quälend lange dauern würde und wahrscheinlich niemals abgeschlossen sein würde.
Lassen Sie uns die Alternativen betrachten:
– Entspricht RAID5 und RAID6, jedoch mit anpassbarem Paritätslevel. Hierbei erfolgt die Sicherung nicht blockweise, sondern für jedes Objekt einzeln. Der einfachste Weg, Erasure Coding auszuprobieren, ist die Einrichtung von .
– Dies ist derzeit eine noch nicht veröffentlichte Funktion von ZFS. Im Gegensatz zu RAIDZ verfügt DRAID über einen verteilten Paritätsblock und nutzt beim Wiederherstellungsprozess sofort alle Festplatten im Array, wodurch es besser mit Festplattenausfällen umgeht und schneller nach einem Fehler wiederhergestellt wird.


Wir haben einen Server zur Verfügung: Fujitsu Primergy RX300 S7 mit einem Prozessor Intel Xeon CPU E5-2650L 0 @ 1,80 GHz, neun Speichermodulen Samsung DDR3-1333 8Gb PC3L-10600R ECC Registered (M393B1K70DH0-YH9), Festplattenschrank Supermicro SuperChassis 847E26-RJBOD1, verbunden über Dual LSI SAS2X36 Expander und 45 Festplatten Seagate ST6000NM0115-1YZ110 zum 6 TB jedes.
Bevor wir eine Entscheidung treffen, müssen wir alles ordnungsgemäß testen.
Dafür habe ich verschiedene Konfigurationen vorbereitet und Tests durchgeführt. Ich habe minio verwendet, das als S3-Backend fungiert und es in verschiedenen Modi mit unterschiedlichen Zielen betrieben.
Im Wesentlichen wurde der minio-Anwendungsfall im Erasure Coding gegen Software-RAID mit der gleichen Anzahl von Festplatten und Paritätsfestplatten getestet, also: RAID6, RAIDZ2 und DRAID2.
Zur Information: Wenn Sie minio mit nur einem Ziel ausführen, funktioniert minio im S3-Gateway-Modus und bietet Ihr lokales Dateisystem als S3-Speicher an. Wenn Sie minio hingegen mit mehreren Zielen starten, wird automatisch der Erasure-Coding-Modus aktiviert, der die Daten zwischen Ihren Zielen verteilt und Redundanz bietet.
Standardmäßig teilt MinIO die Zielplatten in Gruppen von 16 Festplatten auf, wobei jede Gruppe über 2 Paritätsplatten verfügt. Das bedeutet, dass gleichzeitig bis zu zwei Festplatten ausfallen können, ohne dass Daten verloren gehen.
Für Leistungstests verwendete ich 16 Festplatten mit jeweils 6 TB und schrieb kleine Objekte mit einer Größe von 1 MB auf sie, was unsere zukünftige Last sehr genau widerspiegelte, da alle modernen Backup-Tools Daten in mehrere Megabyte große Blöcke unterteilen und sie auf diese Weise schreiben.
Für das Benchmarking wurde das Tool s3bench verwendet, das auf einem entfernten Server ausgeführt wird und Zehntausende solcher Objekte in MinIO in Hunderten von Streams sendet. Anschließend wurde versucht, sie auf die gleiche Weise zurückzuziehen.
Die Ergebnisse des Benchmarks sind in der folgenden Tabelle dargestellt:
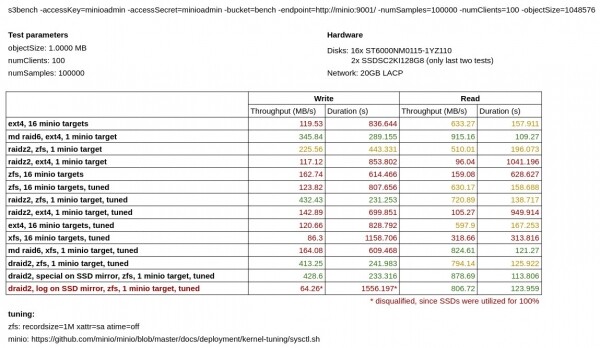
Wie wir sehen, arbeitet MinIO im Modus der eigenen Erasure-Codierung beim Schreiben deutlich schlechter als MinIO, das auf einem Software-RAID6, RAIDZ2 und DRAID2 in derselben Konfiguration läuft.
Separat wurde ich MinIO auf ext4 gegen XFS zu testen. Erstaunlicherweise stellte sich heraus, dass XFS für meine Art der Belastung deutlich langsamer war als ext4.
In der ersten Testreihe zeigte MDADM eine Überlegenheit gegenüber ZFS, aber später , dass die Leistung von ZFS durch die Festlegung der folgenden Optionen verbessert werden kann:
xattr=sa atime=off recordsize=1Mund danach wurden die Tests mit ZFS deutlich besser.
Es lässt sich auch feststellen, dass DRAID im Vergleich zu RAIDZ keinen signifikanten Leistungsgewinn bringt, aber theoretisch viel sicherer sein sollte.
In den letzten beiden Tests habe ich auch versucht, die Metadaten (special) und ZIL (log) auf ein Spiegel-SSD auszulagern. Das Auslagern der Metadaten brachte jedoch keinen nennenswerten Geschwindigkeitsvorteil beim Schreiben, und beim Auslagern des ZIL stießen meine auf eine Wand mit 100 % Auslastung, sodass ich diesen Test als gescheitert betrachte. Ich schließe nicht aus, dass, wenn ich schnellere SSDs gehabt hätte, dies meine Ergebnisse erheblich verbessert hätte, aber leider hatte ich keine.
Letztendlich habe ich mich entschieden, DRAID zu verwenden, und trotz seines Beta-Status ist es die schnellste und effektivste Lösung für unseren Anwendungsfall.
Ich habe ein einfaches DRAID2 in einer Konfiguration mit drei Gruppen und zwei verteilten Spares erstellt:
# zpool status data
pool: data
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
data ONLINE 0 0 0
draid2:3g:2s-0 ONLINE 0 0 0
sdy ONLINE 0 0 0
sdam ONLINE 0 0 0
sdf ONLINE 0 0 0
sdau ONLINE 0 0 0
sdab ONLINE 0 0 0
sdo ONLINE 0 0 0
sdw ONLINE 0 0 0
sdak ONLINE 0 0 0
sdd ONLINE 0 0 0
sdas ONLINE 0 0 0
sdm ONLINE 0 0 0
sdu ONLINE 0 0 0
sdai ONLINE 0 0 0
sdaq ONLINE 0 0 0
sdk ONLINE 0 0 0
sds ONLINE 0 0 0
sdag ONLINE 0 0 0
sdi ONLINE 0 0 0
sdq ONLINE 0 0 0
sdae ONLINE 0 0 0
sdz ONLINE 0 0 0
sdan ONLINE 0 0 0
sdg ONLINE 0 0 0
sdac ONLINE 0 0 0
sdx ONLINE 0 0 0
sdal ONLINE 0 0 0
sde ONLINE 0 0 0
sdat ONLINE 0 0 0
sdaa ONLINE 0 0 0
sdn ONLINE 0 0 0
sdv ONLINE 0 0 0
sdaj ONLINE 0 0 0
sdc ONLINE 0 0 0
sdar ONLINE 0 0 0
sdl ONLINE 0 0 0
sdt ONLINE 0 0 0
sdah ONLINE 0 0 0
sdap ONLINE 0 0 0
sdj ONLINE 0 0 0
sdr ONLINE 0 0 0
sdaf ONLINE 0 0 0
sdao ONLINE 0 0 0
sdh ONLINE 0 0 0
sdp ONLINE 0 0 0
sdad ONLINE 0 0 0
spares
s0-draid2:3g:2s-0 AVAIL
s1-draid2:3g:2s-0 AVAIL
errors: No known data errorsGut, das Speicherproblem ist gelöst, nun zu den Backup-Lösungen. Hier möchte ich drei Lösungen vorstellen, die ich ausprobieren konnte:
— ein Fork , eine spezialisierte Lösung zur Sicherung von Blockgeräten, die eine enge Integration mit Ceph bietet. Sie kann die Unterschiede zwischen Snapshots erfassen und daraus inkrementelle Backups erstellen. Unterstützt eine große Anzahl von Speicherknoten, sowohl lokal als auch S3. Erfordert eine separate Datenbank zur Speicherung der Hash-Tabelle für die Deduplizierung. Nachteile: Ist in Python geschrieben und hat eine etwas unresponsive CLI.
— ein Fork , ein seit langem bekanntes und bewährtes Tool zur Datensicherung, das Daten sichern und gut deduplizieren kann. Es speichert Backups sowohl lokal als auch auf Remote-Servern über SCP. Es kann Blockgeräte backen, wenn es mit dem Flag --special, betrieben wird. Nachteile: Bei der Erstellung eines Backups wird das Repository vollständig gesperrt, weshalb es empfehlenswert ist, für jede virtuelle Maschine ein separates Repository zu erstellen. Das ist im Grunde kein Problem, da sie sehr einfach erstellt werden können.
— ein aktiv wachsendes Projekt, das in Go geschrieben ist, ausreichend schnell und unterstützt eine Vielzahl von Backends zur Speicherung, darunter sowohl lokale Speicher als auch SCP, S3 und vieles mehr. Besonders erwähnenswert ist der speziell entwickelte für Restic, der es ermöglicht, Speicher am schnellsten für die remote Nutzung zu exportieren. Von all den genannten hat mir dieser am besten gefallen. Er kann Backups aus stdin erstellen. Es gibt kaum nennenswerte Nachteile, aber einige Besonderheiten sind zu beachten:
Zunächst habe ich versucht, es im Modus eines gemeinsamen Repositories für alle virtuellen Maschinen (wie Benji) zu verwenden, und es funktionierte sogar ganz gut. Allerdings dauerten die Wiederherstellungsoperationen ziemlich lange, da Restic jedes Mal vor der Wiederherstellung die Metadaten aller Backups lesen möchte. Dieses Problem ließ sich jedoch, wie bei Borg, einfach lösen, indem ich ein separates Repository für jede virtuelle Maschine erstellt habe. Dieser Ansatz erwies sich auch als sehr effektiv für das Backup-Management. Abgeschottete Repositories können ein eigenes Passwort für den Datenzugriff haben, zudem brauchen wir uns keine Sorgen zu machen, dass das globale Repository irgendwie kaputtgeht. Neue Repositories können genauso einfach erstellt werden wie beim Borg-Backup.
In jedem Fall erfolgt die Deduplikation nur relativ zur vorherigen Backup-Version; das vorherige Backup wird nach dem Pfad des angegebenen Backups bestimmt. Wenn Sie also verschiedene Objekte von stdin in ein gemeinsames Repository sichern, vergessen Sie nicht, die Option anzugeben:
--stdin-filename, oder geben Sie jedes Mal explizit die Option an:--parent.
Zweitens dauert die Wiederherstellung in stdout deutlich länger als die Wiederherstellung auf das Dateisystem aufgrund ihrer Parallelität. Zukünftig ist eine engere Unterstützung von Backups für Blockgeräte geplant.
Drittens wird momentan empfohlen, , da Version 0.9.6 einen Fehler mit der langsamen Wiederherstellung großer Dateien hat.
Um die Effizienz des Backups und die Geschwindigkeit des Schreibens / Wiederherstellens aus der Sicherung zu testen, habe ich ein separates Repository erstellt und versucht, ein kleines Image einer virtuellen Maschine (21 GB) zu sichern. Es wurden zwei Backups ohne Änderungen am Original durchgeführt, wobei jede der aufgelisteten Lösungen verwendet wurde, um zu überprüfen, wie viel schneller/langsame die deduplizierten Daten kopiert werden.
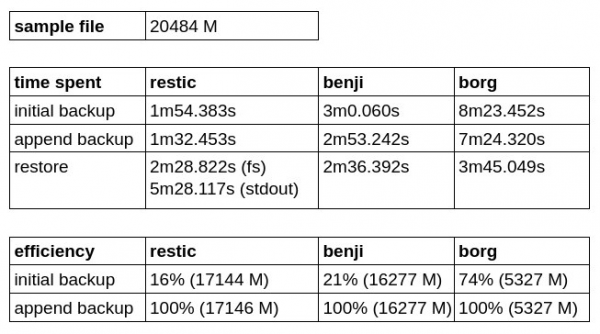
Wie wir feststellen können, hat Borg Backup den besten Effizienzkoeffizienten für das initiale Backup, verliert jedoch sowohl in der Schreib- als auch in der Wiederherstellungsgeschwindigkeit.
Restic stellte sich als schneller als Benji Backup heraus, benötigt jedoch mehr Zeit für die Wiederherstellung in stdout und kann leider bisher nicht direkt auf ein Blockgerät schreiben.
Nach Abwägung aller Vor- und Nachteile habe ich mich entschieden, bei restic mit REST-Server als die bequemste und vielversprechendste Lösung für Backups.
In diesem Screencast sehen Sie, wie der 10-Gigabit-Kanal vollständig ausgelastet wird, während mehrere gleichzeitig laufende Backup-Vorgänge ausgeführt werden. Es ist erwähnenswert, dass die Auslastung der Festplatten dabei nicht über 30 % steigt.
Ich bin mit der gefundenen Lösung mehr als zufrieden!
Quelle: habr.com
