


Mein Name ist Denis Rozhkov, ich bin Leiter der Softwareentwicklung bei Gazinformservice, im Produktteam. . Die Gesetze und Firmenrichtlinien stellen bestimmte Anforderungen an die Sicherheit der Datenspeicherung. Niemand möchte, dass Dritte Zugang zu sensiblen Informationen erhalten, deshalb sind für jedes Projekt folgende Aspekte wichtig: Identifizierung und Authentifizierung, Zugriffsmanagement, Sicherstellung der Datenintegrität im System und Erfassung von Sicherheitsereignissen. Deshalb möchte ich einige interessante Punkte zur Sicherheit von Datenbanksystemen vorstellen.
Der Artikel wurde auf der organisiert von . Wenn Sie nicht lesen möchten, können Sie sich Folgendes ansehen:

Der Artikel wird in drei Teile unterteilt:
- Wie man Verbindungen schützt.
- Was ist ein Aktionsaudit und wie erfasst man, was auf der Datenbankseite und bei der Verbindung dazu passiert.
- Wie man die Daten in der Datenbank selbst schützt und welche Technologien dafür existieren.
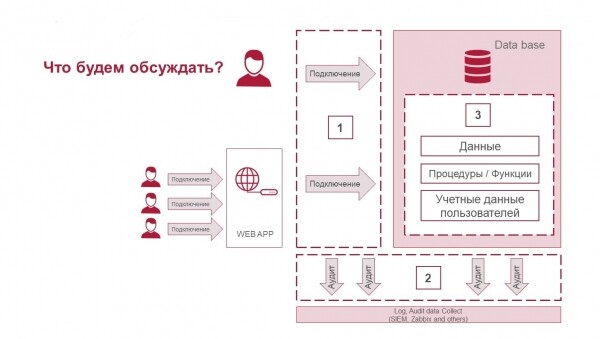
Drei Komponenten der Sicherheit von Datenbanksystemen: Schutz der Verbindungen, Aktionsaudit und Datenschutz.
Schutz der Verbindungen
Die Verbindung zur Datenbank kann sowohl direkt als auch indirekt über Webanwendungen hergestellt werden. In der Regel interagiert ein geschäftlicher Nutzer, also jemand, der mit dem Datenbanksystem arbeitet, nicht direkt mit ihm.
Bevor wir über den Schutz von Verbindungen sprechen, müssen wichtige Fragen beantwortet werden, die Einfluss darauf haben, wie Sicherheitsmaßnahmen gestaltet werden:
- Ist ein Geschäftsnutzer gleichzusetzen mit einem Nutzer des Datenbanksystems?
- Wird der Zugang zu den Daten des Datenbanksystems nur über eine API gewährt, die Sie kontrollieren, oder ist der Zugriff auf die Tabellen direkt möglich?
- Ist das Datenbanksystem in einem separaten, sicheren Segment untergebracht, und wer interagiert mit ihm?
- Wird Pooling/Proxy und eine Zwischenschicht verwendet, die Informationen über den Aufbau der Verbindung und die Nutzer der Datenbank ändern können?
Schauen wir uns nun an, welche Werkzeuge zum Schutz der Verbindungen eingesetzt werden können:
- Verwenden Sie Lösungen der Klasse Database Firewall. Eine zusätzliche Schutzschicht erhöht zumindest die Transparenz bezüglich dessen, was im Datenbanksystem geschieht; im besten Fall können Sie einen zusätzlichen Schutz der Daten gewährleisten.
- Verwenden Sie Passwort-Richtlinien. Ihre Anwendung hängt davon ab, wie Ihre Architektur aufgebaut ist. In jedem Fall ist ein einzelnes Passwort in der Konfigurationsdatei der Webanwendung, die mit der Datenbank verbunden ist, nicht ausreichend für den Schutz. Es gibt eine Vielzahl von Datenbank-Tools, die sicherstellen, dass Benutzer und Passwörter aktualisiert werden.
Weitere Informationen zu den Benutzerbewertungsfunktionen finden Sie , ebenso können Sie mehr über die MS SQL Vulnerability Assessment erfahren .
- Bereichern Sie den Kontext der Sitzung mit den notwendigen Informationen. Wenn die Sitzung undurchsichtig ist und Sie nicht verstehen, wer innerhalb dieser Sitzung in der Datenbank arbeitet, können Sie im Rahmen der ausgeführten Operation zusätzliche Informationen darüber bereitstellen, wer was und warum tut. Diese Informationen sind im Audit sichtbar.
- Konfigurieren Sie SSL, wenn Sie kein Netzwerktrennung zwischen der Datenbank und den Endbenutzern haben, sie nicht in einem eigenen VLAN ist. In solchen Fällen müssen Sie den Kanal zwischen dem Verbraucher und der Datenbank absichern. Schutzwerkzeuge sind unter anderem auch in der Open-Source-Community verfügbar.
Wie wird sich dies auf die Leistung der Datenbank auswirken?
Sehen wir uns am Beispiel von PostgreSQL an, wie SSL die CPU-Last, die Verzögerungen erhöht und die TPS verringert, und ob zu viele Ressourcen verbraucht werden, wenn es aktiviert ist.
Wir belasten PostgreSQL mit pgbench – einem einfachen Programm für Leistungstests. Es führt wiederholt eine Sequenz von Befehlen aus, möglicherweise in parallelen Datenbanksitzungen, und berechnet dann die durchschnittliche Transaktionsgeschwindigkeit.
Test 1 ohne SSL und mit SSL — die Verbindung wird bei jeder Transaktion hergestellt:
pgbench.exe --connect -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres sslmode=require
sslrootcert=rootCA.crt sslcert=client.crt sslkey=client.key"vs
pgbench.exe --connect -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres"Test 2 ohne SSL und mit SSL — alle Transaktionen werden in einer einzigen Verbindung ausgeführt:
pgbench.exe -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres sslmode=require
sslrootcert=rootCA.crt sslcert=client.crt sslkey=client.key"vs
pgbench.exe -c 10 -t 5000 "host=192.168.220.129 dbname=taskdb user=postgres"Weitere Einstellungen:
Scaling-Faktor: 1
Abfragemodus: einfach
Anzahl der Clients: 10
Anzahl der Threads: 1
Anzahl der Transaktionen pro Client: 5000
Tatsächlich verarbeitete Transaktionen: 50000/50000Testergebnisse:
KEIN SSL
SSL
Die Verbindung wird bei jeder Transaktion hergestellt
Durchschnittliche Latenz
171,915 ms
187,695 ms
tps einschließlich Verbindungsaufbau
58.168112
53.278062
tps ohne Verbindungsaufbau
64.084546
58.725846
CPU
24%
28%
Alle Transaktionen werden über eine Verbindung abgewickelt
Durchschnittliche Latenz
6,722 ms
6,342 ms
tps einschließlich der Verbindungsherstellung
1587.657278
1576.792883
tps ohne Verbindungsaufbau
1588.380574
1577.694766
CPU
17%
21%
Bei geringer Belastung ist der Einfluss von SSL mit der Messfehlergrenze vergleichbar. Wenn jedoch eine große Datenmenge übertragen wird, kann die Situation anders sein. Bei einer einzelnen Verbindung pro Transaktion (was selten vorkommt, normalerweise teilen sich mehrere Benutzer eine Verbindung) gibt es viele Verbindungen/Trennungen, und der Einfluss kann etwas größer sein. Das bedeutet, dass es Risiken für die Leistungseinbußen geben kann, jedoch ist der Unterschied nicht so groß, dass man auf den Schutz verzichten sollte.
Beachten Sie, dass es einen deutlichen Unterschied gibt, wenn man die Betriebsmodi vergleicht: Innerhalb einer Sitzung arbeiten Sie oder in unterschiedlichen Sitzungen. Das ist nachvollziehbar: Das Erstellen jeder Verbindung verbraucht Ressourcen.
Wir hatten den Fall, dass wir Zabbix im Trust-Modus verbunden haben, das heißt, wir haben die md5-Prüfung nicht durchgeführt und die Authentifizierung war nicht erforderlich. Später bat der Kunde um die Aktivierung des md5-Authentifizierungsmodus. Dies führte zu einer erheblichen CPU-Belastung, wodurch die Leistung absank. Wir begannen, nach Wegen zur Optimierung zu suchen. Eine mögliche Lösung für das Problem könnte die Implementierung von Netzwerkkontrollen sein, separate VLANs für die Datenbank zu erstellen, Einstellungen hinzuzufügen, um klarzustellen, wer von wo verbindet, und die Authentifizierung zu entfernen. Zudem kann man die Authentifizierungseinstellungen optimieren, um die Kosten bei Aktivierung der Authentifizierung zu senken, aber insgesamt beeinflussen verschiedene Authentifizierungsmethoden die Leistung und es ist wichtig, diese Faktoren bei der Planung der Serverressourcen (Hardware) für die Datenbank zu berücksichtigen.
Fazit: Bei vielen Lösungen können selbst kleine Details bei der Authentifizierung erhebliche Auswirkungen auf das Projekt haben, und es ist ungünstig, wenn dies erst bei der Produktivsetzung offensichtlich wird.
Auditanalyse
Audit kann nicht nur auf die Datenbank beschränkt sein. Der Auditprozess dient dazu, Informationen darüber zu erhalten, was in verschiedenen Segmenten vor sich geht. Dazu gehören auch Datenbankfirewalls und das Betriebssystem, auf dem die DBMS aufgebaut ist.
Bei kommerziellen Enterprise-Datenbanken funktioniert der Auditprozess gut, bei Open-Source-Lösungen jedoch nicht immer. Hier sind die Optionen in PostgreSQL:
- Standardprotokoll – integrierte Protokollierung;
- Erweiterungen: pgaudit – wenn die standardmäßige Protokollierung nicht ausreicht, können separate Einstellungen genutzt werden, um bestimmte Anforderungen zu erfüllen.
Zusatz zu dem Bericht im Video:
Die grundlegende Registrierung von Operatoren kann durch das standardmäßige Protokollierungstool mit log_statement = all sichergestellt werden.
Dies ist geeignet für Monitoring und andere Verwendungszwecke, bietet jedoch nicht das Maß an Detailliertheit, das normalerweise für Audits erforderlich ist.
Es reicht nicht aus, lediglich eine Liste aller mit der Datenbank durchgeführten Operationen zu haben.
Es muss auch die Möglichkeit bestehen, spezifische Aussagen zu finden, die für den Auditor von Interesse sind.
Das standardmäßige Protokollierungstool zeigt an, was der Benutzer angefordert hat, während pgAudit sich auf die Details konzentriert, was passiert ist, als die Datenbank die Anfrage ausgeführt hat.
Zum Beispiel könnte ein Auditor sicherstellen wollen, dass eine bestimmte Tabelle im festgelegten Wartungsfenster erstellt wurde.
Das mag eine einfache Aufgabe für ein grundlegendes Audit und grep erscheinen, aber was, wenn Ihnen etwas wie dieses (bewusst komplizierte) Beispiel präsentiert wird:
DO $$
BEGIN
EXECUTE 'CREATE TABLE import' || 'ant_table (id INT)';
END $$;
Das Standardprotokoll gibt Ihnen Folgendes:
LOG: statement: DO $$
BEGIN
EXECUTE 'CREATE TABLE import' || 'ant_table (id INT)';
END $$;
Es scheint, dass ein gewisses Verständnis des Codes erforderlich sein könnte, um die interessante Tabelle zu finden, insbesondere wenn Tabellen dynamisch erstellt werden.
Das ist nicht ideal, da es besser wäre, einfach nach dem Tabellennamen zu suchen.
Hier kommt pgAudit ins Spiel.
Für denselben Input gibt es folgende Ausgabe im Protokoll:
AUDIT: SESSION,33,1,FUNCTION,DO,,,«DO $$
BEGIN
EXECUTE 'CREATE TABLE import' || 'ant_table (id INT)';
END $$;"
AUDIT: SESSION,33,2,DDL,CREATE TABLE,TABLE,public.important_table,CREATE TABLE important_table (id INT)
Nicht nur der DO-Block wird protokolliert, sondern auch der vollständige TEXT von CREATE TABLE mit dem Operator-Typ, dem Objekt-Typ und dem vollständigen Namen, was die Suche erleichtert.
Bei der Protokollierung von SELECT- und DML-Operatoren kann pgAudit so konfiguriert werden, dass es einen separaten Eintrag für jede Beziehung aufzeichnet, auf die in dem Befehl verwiesen wird.
Es bedarf keiner syntaktischen Analyse, um alle Operatoren zu finden, die eine bestimmte Tabelle betreffen.)».
Wie wird sich dies auf die Leistung der Datenbank auswirken?
Lassen Sie uns Tests mit aktiviertem vollständigen Audit durchführen und sehen, wie sich dies auf die Leistung von PostgreSQL auswirkt. Wir aktivieren das umfangreiche Datenbank-Logging für alle Parameter.
Im Konfigurationsfile ändern wir fast nichts, das Wichtigste ist, den Modus debug5 zu aktivieren, um maximale Informationen zu erhalten.
postgresql.conf
log_destination = 'stderr'
logging_collector = on
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 10MB
log_min_messages = debug5
log_min_error_statement = debug5
log_min_duration_statement = 0
debug_print_parse = on
debug_print_rewritten = on
debug_print_plan = on
debug_pretty_print = on
log_checkpoints = on
log_connections = on
log_disconnections = on
log_duration = on
log_hostname = on
log_lock_waits = on
log_replication_commands = on
log_temp_files = 0
log_timezone = 'Europe/Moscow'
Wir führen drei Lasttests auf einer PostgreSQL-Datenbank mit den Parametern 1 CPU, 2,8 GHz, 2 GB RAM, 40 GB HDD durch, unter Verwendung folgender Befehle:
$ pgbench -p 3389 -U postgres -i -s 150 benchmark
$ pgbench -p 3389 -U postgres -c 50 -j 2 -P 60 -T 600 benchmark
$ pgbench -p 3389 -U postgres -c 150 -j 2 -P 60 -T 600 benchmarkTestresultate:
Ohne Logging
Mit Logging
Gesamtdauer für das Befüllen der Datenbank
43,74 Sek.
53,23 Sek.
RAM
24%
40%
CPU
72%
91%
Test 1 (50 Verbindungen)
Anzahl der Transaktionen in 10 Minuten
74169
32445
Transaktionen/Sekunde
123
54
Durchschnittliche Verzögerung
405 ms
925 ms
Test 2 (150 Verbindungen bei 100 möglichen)
Anzahl der Transaktionen in 10 Minuten
81727
31429
Transaktionen/Sekunde
136
52
Durchschnittliche Verzögerung
550 ms
1432 ms
Über die Größen
Datenbankgröße
2251 MB
2262 MB
Datenbankprotokollgröße
0 MB
4587 MB
Insgesamt: Ein vollständiges Audit ist nicht optimal. Die Datenmenge aus dem Audit wird ähnlich groß sein wie die der Datenbank selbst, oder sogar größer. Ein solches Maß an Protokollierung, das bei der Arbeit mit DBMS entsteht, ist ein gängiges Problem in der Produktionsumgebung.
Sehen wir uns weitere Parameter an:
- Die Geschwindigkeit ändert sich nicht stark: ohne Protokollierung – 43,74 Sek., mit Protokollierung – 53,23 Sek.
- Die Leistung in Bezug auf RAM und CPU wird sinken, da eine Auditdatei erstellt werden muss. Dies ist ebenfalls in der Produktionsumgebung zu beobachten.
Mit steigender Anzahl der Verbindungen werden sich die Werte natürlich etwas verschlechtern.
In Unternehmen mit Audits ist es noch komplizierter:
- es gibt viele Daten;
- das Audit muss nicht nur über syslog in SIEM, sondern auch in Dateien erfolgen: falls mit syslog etwas passiert, sollte eine Datei in der Nähe der Datenbank vorhanden sein, in der die Daten gespeichert werden;
- Für das Audit ist ein separater Speicher erforderlich, um I/O-Verluste bei den Festplatten zu vermeiden, da er viel Platz einnimmt;
- teilweise benötigen IT-Sicherheitsmitarbeiter überall GOST-Standards, sie verlangen eine staatliche Identifikation.
Zugangsbeschränkung zu den Daten
Betrachten wir die Technologien, die zum Schutz von Daten und deren Zugriff in kommerziellen DBMS und Open Source verwendet werden.
Was insgesamt verwendet werden kann:
- Verschlüsselung und Verschleierung von Prozeduren und Funktionen (Wrapping) – das sind spezielle Werkzeuge und Hilfsprogramme, die aus lesbarem Code unlesbaren Code machen. Allerdings kann dieser nachher nicht verändert oder zurückrefaktoriert werden. Dieser Ansatz ist manchmal zumindest auf der DBMS-Seite erforderlich – die Logik der Lizenzbeschränkungen oder der Autorisierung wird genau auf der Ebene von Prozeduren und Funktionen verschlüsselt.
- Einschränkung der Sichtbarkeit von Daten nach Zeilen (RLS) – das bedeutet, dass verschiedene Benutzer eine Tabelle sehen, aber unterschiedliche Zeileninhalte darin, also sind bestimmte Daten für einige Benutzer auf Zeilenebene nicht sichtbar.
- Bearbeitung der angezeigten Daten (Maskierung) – hier sehen Benutzer in einer Spalte der Tabelle entweder Daten oder nur Sternchen, das heißt, für bestimmte Benutzer wird die Information verborgen. Die Technologie bestimmt, was welchem Benutzer je nach Zugriffslevel angezeigt wird.
- Die Zugangskontrolle für Security DBA/Application DBA/DBA bezieht sich hauptsächlich auf die Einschränkung des Zugriffs auf das Datenbankmanagementsystem (DBMS). Das bedeutet, dass Mitarbeiter der IT-Sicherheit von Datenbank- und Anwendungsadministratoren getrennt werden können. Bei Open-Source-Lösungen gibt es nur wenige solche Technologien, während kommerzielle DBMS genügend Alternativen bieten. Diese sind erforderlich, wenn viele Benutzer Zugriff auf die Server haben.
- Einschränkungen beim Zugriff auf Dateien auf der Ebene des Dateisystems. Es können Berechtigungen und Zugriffsprivilegien für Verzeichnisse vergeben werden, sodass jeder Administrator nur Zugriff auf die relevanten Daten erhält.
- Mandatierter Zugriff und Speicherbereinigung — diese Technologien werden selten angewendet.
- End-to-End-Verschlüsselung direkt im DBMS — dies ist eine clientseitige Verschlüsselung mit Schlüsselverwaltung auf der Serverseite.
- Datenverschlüsselung. Zum Beispiel die Spaltenverschlüsselung — wenn Sie einen Mechanismus verwenden, der eine bestimmte Datenbankspalte verschlüsselt.
Wie beeinflusst das die Leistung des DBMS?
Betrachten wir das Beispiel der Spaltenschlüsselung in PostgreSQL. Es gibt das Modul pgcrypto, das es ermöglicht, ausgewählte Felder verschlüsselt zu speichern. Dies ist nützlich, wenn nur bestimmte Daten wertvoll sind. Um die verschlüsselten Felder zu lesen, überträgt der Client den Entschlüsselungsschlüssel, der Server entschlüsselt die Daten und gibt sie an den Client zurück. Ohne den Schlüssel kann niemand etwas mit Ihren Daten anfangen.
Lassen Sie uns einen Test mit pgcrypto durchführen.. Wir erstellen eine Tabelle mit verschlüsselten Daten und eine mit normalen Daten. Im Folgenden die Befehle zur Erstellung der Tabellen, in der ersten Zeile befindet sich der nützliche Befehl zur Erstellung der Extension mit der Registrierung der Datenbank:
CREATE EXTENSION pgcrypto;
CREATE TABLE t1 (id integer, text1 text, text2 text);
CREATE TABLE t2 (id integer, text1 bytea, text2 bytea);
INSERT INTO t1 (id, text1, text2)
VALUES (generate_series(1,10000000), generate_series(1,10000000)::text, generate_series(1,10000000)::text);
INSERT INTO t2 (id, text1, text2) VALUES (
generate_series(1,10000000),
encrypt(cast(generate_series(1,10000000) AS text)::bytea, 'key'::bytea, 'bf'),
encrypt(cast(generate_series(1,10000000) AS text)::bytea, 'key'::bytea, 'bf'));Als nächstes versuchen wir, aus jeder Tabelle Daten auszuwählen und beobachten die Ausführungszeiten.
Abfrage aus der Tabelle ohne Verschlüsselungsfunktion.:
psql -c "timing" -c "select * from t1 limit 1000;" "host=192.168.220.129 dbname=taskdb
user=postgres sslmode=disable" > 1.txtDie Stoppuhr läuft.
id | text1 | text2
——+——-+——-
1 | 1 | 1
2 | 2 | 2
3 | 3 | 3
…
997 | 997 | 997
998 | 998 | 998
999 | 999 | 999
1000 | 1000 | 1000
(1000 Zeilen)
Zeit: 1,386 ms
Abfrage aus der Tabelle mit Verschlüsselungsfunktion:
psql -c "timing" -c "select id, decrypt(text1, 'key'::bytea, 'bf'),
decrypt(text2, 'key'::bytea, 'bf') from t2 limit 1000;"
"host=192.168.220.129 dbname=taskdb user=postgres sslmode=disable" > 2.txtDie Stoppuhr läuft.
id | decrypt | decrypt
——+—————+————
1 | x31 | x31
2 | x32 | x32
3 | x33 | x33
…
999 | x393939 | x393939
1000 | x31303030 | x31303030
(1000 Zeilen)
Zeit: 50,203 ms
Testergebnisse:
Ohne Verschlüsselung
Pgcrypto (decrypt)
Abfrage 1000 Zeilen
1,386 ms
50,203 ms
CPU
15%
35%
RAM
+5%
Die Verschlüsselung hat einen erheblichen Einfluss auf die Leistung. Es ist offensichtlich, dass die Zeit steigt, da die Entschlüsselungsoperationen von verschlüsselten Daten (und die Entschlüsselung ist in der Regel noch in Ihrer Logik eingebettet) erhebliche Ressourcen erfordern. Das bedeutet, dass die Idee, alle Spalten mit Daten zu verschlüsseln, mit einer Verringerung der Leistung verbunden ist.
Die Verschlüsselung ist jedoch keine Allheilmittel, das alle Probleme löst. Die entschlüsselten Daten und der Entschlüsselungsschlüssel befinden sich während des Entschlüsselungs- und Datenübertragungsprozesses auf dem Server. Daher können die Schlüssel von jemandem abgehört werden, der vollen Zugriff auf den Datenbankserver hat, wie beispielsweise ein Systemadministrator.
Wenn für alle Benutzer ein einziger Schlüssel für die gesamte Datenbank verwendet wird (auch wenn dies nicht für alle gilt, sondern nur für eine eingeschränkte Kundengruppe), ist das nicht immer gut und richtig. Daher haben wir mit der Implementierung von End-to-End-Verschlüsselung begonnen. In Datenbanksystemen wurden Optionen für die Verschlüsselung von Daten sowohl auf der Client- als auch auf der Serverseite in Betracht gezogen, und es wurden die sogenannten Key-Vault-Speicher entwickelt — separate Produkte, die das Schlüsselmanagement auf der Datenbankseite gewährleisten.

Sicherheitsmaßnahmen in kommerziellen und Open-Source-Datenbanksystemen
Funktionen
Typ
Passwortrichtlinie
Audit
Schutz des Quellcodes von Verfahren und Funktionen
RLS
Verschlüsselung
Oracle
Kommerziell
+
+
+
+
+
MsSql
Kommerziell
+
+
+
+
+
Kommerziell
+
+
+
+
Erweiterungen
PostgreSQL
Kostenlos
Erweiterungen
Erweiterungen
—
+
Erweiterungen
MongoDb
Kostenlos
—
+
—
—
Nur in MongoDB Enterprise verfügbar
Die Tabelle ist bei weitem nicht vollständig, aber die Situation ist folgende: In kommerziellen Produkten werden Sicherheitsfragen schon lange gelöst, während in Open-Source-Lösungen oft zusätzliche Module für die Sicherheit verwendet werden, und oft fehlen viele Funktionen, sodass manchmal Anpassungen erforderlich sind. Beispielsweise gibt es in PostgreSQL viele verschiedene Erweiterungen, die Passwortrichtlinien implementieren (, , , , ), die jedoch, meiner Meinung nach, keine der Anforderungen des heimischen Unternehmenssegments umfassend abdecken.
Was tun, wenn es nirgendwo das Gewünschte gibt?? Например, хочется использовать определенную СУБД, в которой нет функций, которые требует заказчик.
In diesem Fall können Sie auf Drittanbieter-Lösungen zurückgreifen, die mit verschiedenen DBMS arbeiten, wie zum Beispiel "Krypto DB" oder "Garda DB". Wenn es um Lösungen aus dem heimischen Sektor geht, haben diese meist ein besseres Verständnis für die geltenden Standards als im Open Source-Bereich.
Die zweite Möglichkeit besteht darin, die benötigten Funktionen selbst zu entwickeln und den Datenzugriff sowie die Verschlüsselung auf Anwendungsebene zu implementieren. Allerdings wird es mit den Standards komplizierter. Insgesamt können Sie die Daten nach Bedarf verstecken, sie in der DB ablegen und dann wieder entzippen, genau auf Anwendungsebene. Dabei sollten Sie auch gleich überlegen, wie Sie diese Algorithmen in der Anwendung schützen. Unserer Meinung nach sollten solche Maßnahmen auf der Ebene des DBMS durchgeführt werden, da dies schneller funktionieren wird.
Dieser Vortrag wurde erstmals gehalten auf von Mail.ru Cloud Solutions. Sehen Sie sich ananderer Vorträge an und abonnieren Sie die Veranstaltungshinweise auf Telegram. .
Weitere Lesetipps zu diesem Thema:
- .
- .
Quelle: habr.com
