

Im Herbst 2019 gab es im iOS-Team der Cloud von Mail.ru ein lange erwartetes Ereignis. Die Hauptdatenbank für die persistente Speicherung des Anwendungszustands wurde für die mobile Welt recht exotisch. (LMDB). Im Folgenden wird eine ausführliche Übersicht in vier Teilen angeboten. Zuerst sprechen wir über die Gründe für die Wahl dieses komplexen und schwierigen Hintergrunds. Anschließend betrachten wir die drei Säulen der Architektur von LMDB: die in den Speicher gemappten Dateien, den B+-Baum und den Copy-on-Write-Ansatz zur Umsetzung von Transaktionsfähigkeit und Multi-Versionierung. Zum Schluss folgt der praktische Teil. Darin schauen wir uns an, wie man auf der Grundlage der Low-Level Key-Value-API ein Schema mit mehreren Tabellen, einschließlich der Indextabelle, designen und implementieren kann.
Inhalt
3.1.
3.2.
3.3.
4.1.
4.2.
4.3.
1. Motivation der Implementierung
Im Jahr 2015 begannen wir, die Metriken zu überwachen, wie häufig die Benutzeroberfläche unserer Anwendung laggt. Wir taten dies nicht aus heiterem Himmel. Es häuften sich die Beschwerden, dass die Anwendung manchmal nicht auf die Aktionen der Benutzer reagiert: Tasten drücken sich nicht, Listen scrollen nicht usw. Über die Mechanik der Messungen kann ich bei AvitoTech nichts sagen, daher erwähne ich hier nur die Größenordnung der Zahlen.
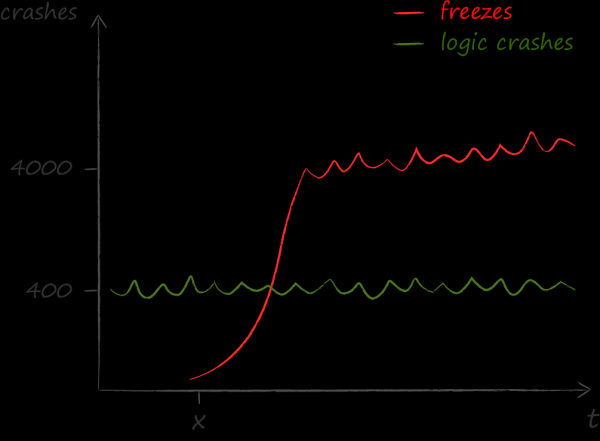
Die Ergebnisse der Messungen waren eine kalte Dusche für uns. Es stellte sich heraus, dass die Probleme, die durch Hänger verursacht werden, viel zahlreicher sind als alle anderen. War bis zu diesem Moment das Hauptmerkmal der Qualität die Absturzfreiheit, so verlagerte sich der Fokus Nachdem wir
ein Dashboard über die Hänger erstellt hatten quantitative und zwei Threads einen Artikel auf Habré . Im Rahmen der aktuellen Erzählung möchte ich die Aspekte der Lösung hervorheben, die die Wahl der Datenbank beeinflusst haben.
Das aktorenbasierte Modell der Systemorganisation geht davon aus, dass die Multithreadigkeit zu ihrem zweiten Wesen wird. Die Objekte des Modells überqueren dabei gerne die Grenzen der Threads, und sie tun dies nicht gelegentlich und irgendwo, sondern praktisch ständig und überall.
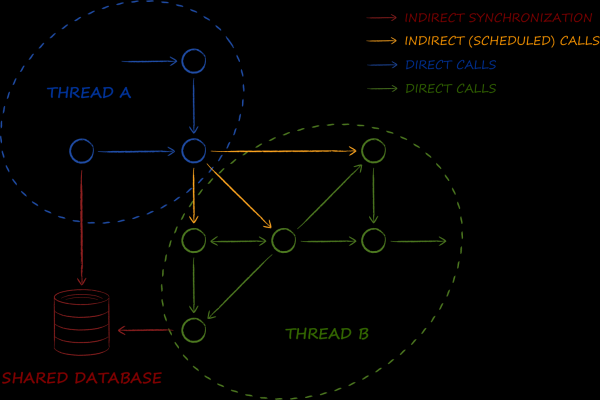
Die Datenbank ist eines der Grundelemente im dargestellten Schema. Ihre Hauptaufgabe besteht darin, das Makromuster zu realisieren. . Während im Unternehmensumfeld mit ihrer Hilfe die Datensynchronisation zwischen Diensten organisiert wird, erfolgt dies im Falle einer aktorenbasierten Architektur — zwischen den Threads. Daher benötigten wir eine Datenbank, deren Verwendung in einer Multithread-Umgebung selbst die minimalsten Schwierigkeiten überwindet. Insbesondere bedeutet dies, dass die daraus gewonnenen Objekte mindestens thread-sicher und idealerweise sogar unveränderlich sein sollten. Wie bekannt ist, können Letztere gleichzeitig von mehreren Threads genutzt werden, ohne dass irgendwelche Sperren erforderlich sind, was sich positiv auf die Leistung auswirkt.
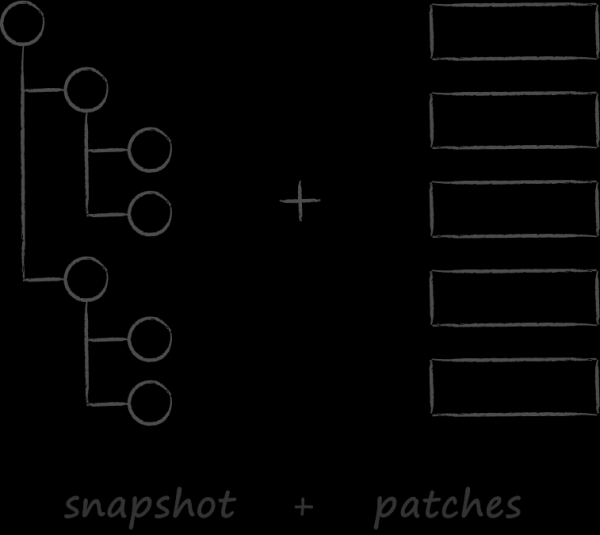 Ein weiterer bedeutender Faktor bei der Auswahl der Datenbank war unser cloudbasiertes API. Es wurde vom Synchronisationsansatz inspiriert, der in git verwendet wird. Genau wie bei git zielen wir auf , was für Cloud-Kunden äußerst sinnvoll erscheint. Es wurde vorausgesetzt, dass sie das vollständige Zustand des Clouds nur einmal herunterladen und danach die Synchronisation in den meisten Fällen durch das Einspielen von Änderungen erfolgt. Leider befindet sich diese Möglichkeit noch immer nur im theoretischen Bereich, und in der Praxis haben die Kunden nicht gelernt, mit Patches zu arbeiten. Das hat mehrere objektive Gründe, die wir der Übersichtlichkeit halber ausklammern möchten. Momentan sind die lehrreichen Erkenntnisse aus der Lektion, was passiert, wenn das API "A" sagt und sein Verbraucher nicht "B" sagt, weitaus interessanter.
Ein weiterer bedeutender Faktor bei der Auswahl der Datenbank war unser cloudbasiertes API. Es wurde vom Synchronisationsansatz inspiriert, der in git verwendet wird. Genau wie bei git zielen wir auf , was für Cloud-Kunden äußerst sinnvoll erscheint. Es wurde vorausgesetzt, dass sie das vollständige Zustand des Clouds nur einmal herunterladen und danach die Synchronisation in den meisten Fällen durch das Einspielen von Änderungen erfolgt. Leider befindet sich diese Möglichkeit noch immer nur im theoretischen Bereich, und in der Praxis haben die Kunden nicht gelernt, mit Patches zu arbeiten. Das hat mehrere objektive Gründe, die wir der Übersichtlichkeit halber ausklammern möchten. Momentan sind die lehrreichen Erkenntnisse aus der Lektion, was passiert, wenn das API "A" sagt und sein Verbraucher nicht "B" sagt, weitaus interessanter.
Stellen Sie sich vor, git vergleicht bei der Ausführung des pull-Befehls anstelle von Patches, die auf einen lokalen Snapshot angewendet werden, den vollständigen Zustand mit dem vollständigen Status auf dem Server. Das gibt Ihnen eine ziemlich genaue Vorstellung davon, wie die Synchronisierung in Cloud-Clients funktioniert. Es ist leicht zu erkennen, dass hierfür zwei DOM-Bäume mit Metainformationen über alle Server- und lokalen Dateien im Speicher allokiert werden müssen. Wenn der Benutzer also 500.000 Dateien in der Cloud speichert, müssen zwei Bäume mit 1 Million Knoten erstellt und zerstört werden. Jeder Knoten ist schließlich ein Aggregat, das eine Grafik von Teilobjekten enthält. In diesem Licht sind die Ergebnisse der Profilerstellung nicht überraschend. Es stellte sich heraus, dass selbst ohne Berücksichtigung der Merging-Algorithmen bereits die Erstellung und anschließende Zerstörung einer großen Anzahl von kleinen Objekten ins Geld geht. Die Situation wird dadurch verschärft, dass die grundlegende Synchronisierungsoperation in viele Benutzer-Szenarien integriert ist. Daher halten wir einen zweiten wichtigen Kriterien für die Auswahl einer Datenbank fest: die Möglichkeit, CRUD-Operationen ohne dynamische Allokation von Objekten durchzuführen.
Andere Anforderungen sind traditioneller, und ihre vollständige Liste sieht folgendermaßen aus:
- Thread-Sicherheit.
- Multiprocessing. Bedingt durch den Wunsch, dieselbe Datenbankinstanz zur Synchronisation des Zustands nicht nur zwischen Threads, sondern auch zwischen der Hauptanwendung und iOS-Erweiterungen zu verwenden.
- Die Möglichkeit, gespeicherte Entitäten als unveränderliche Objekte darzustellen.
- Fehlende dynamische Allokationen im Rahmen von CRUD-Operationen.
- Unterstützung von Transaktionen mit grundlegenden Eigenschaften : Atomarität, Konsistenz, Isolation und Zuverlässigkeit.
- Geschwindigkeit bei den beliebtesten Anwendungsfällen.
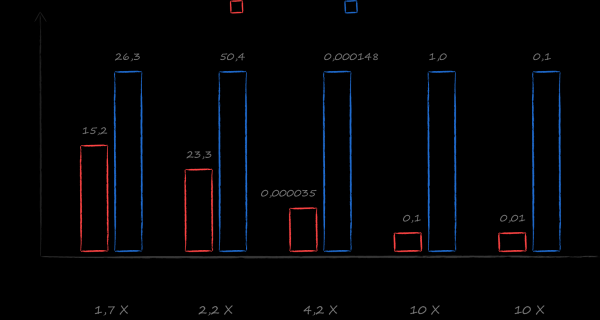
Eine gute Wahl mit diesem Anforderungssatz war und bleibt SQLite. Im Rahmen meiner Erkundung alternativer Optionen stieß ich jedoch auf ein Buch . Unter seiner Leitung wurde ein Benchmark erstellt, der die Geschwindigkeit der verschiedenen Datenbanken in realen Cloud-Szenarien verglichen hat. Das Ergebnis übertraf die kühnsten Erwartungen. Bei den häufigsten Anwendungsfällen - das Abrufen eines Cursors für eine sortierte Liste aller Dateien und der sortierten Liste aller Dateien in einem bestimmten Verzeichnis - war LMDB zehnmal schneller als SQLite. Die Wahl fiel auf LMDB.
2. Positionierung von LMDB
LMDB ist eine sehr kleine Bibliothek (nur 10k Zeilen), die die grundlegendste Ebene von Datenbanken – das Speicherarchiv – implementiert.
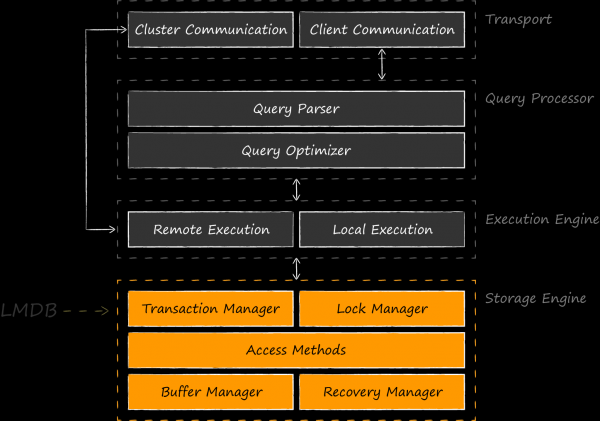
Das gezeigte Schema zeigt, dass es nicht ganz korrekt ist, LMDB mit SQLite zu vergleichen, das auch höhere Ebenen implementiert, ähnlich wie unsinnig ein Vergleich zwischen SQLite und Core Data wäre. Fairer wäre es, gleichwertige Speicher-Engines wie BerkeleyDB, LevelDB, Sophia, RocksDB usw. heranzuziehen. Es gibt sogar Entwicklungen, bei denen LMDB als Komponente des Storage-Engines für SQLite fungiert. Solch ein Experiment wurde erstmals 2012 durchgeführt dem Autor von LMDB . , die so faszinierend waren, dass sein Vorhaben von OSS-Enthusiasten aufgegriffen wurde und seinen Fortgang in Form von . Im Januar 2020 war der Autor dieses Projekts Den Shearer. ihn auf LinuxConfAu.
Die Hauptanwendung von LMDB findet sich als Engine für Anwendungsdatenbanken. Die Bibliothek verdankt ihr Dasein den Entwicklern , die mit BerkeleyDB als Grundlage ihres Projekts sehr unzufrieden waren. Ausgehend von einer bescheidenen Bibliothek , konnte Howard Chu eine der beliebtesten Alternativen unserer Zeit schaffen. Dieser Geschichte sowie dem inneren Aufbau von LMDB widmete er seinen sehr eindrucksvollen Vortrag . Ein gutes Beispiel für die Eroberung des Speichers teilte Leonid Juriev (aka ) von Positive Technologies in seinem Vortrag auf der Highload 2015 . Darin spricht er über LMDB im Kontext einer ähnlichen Aufgabe der Implementierung von ReOpenLDAP, während LevelDB einer vergleichenden Kritik unterzogen wird. Nach der Implementierung entstand bei Positive Technologies sogar ein aktiv entwickelter Fork mit sehr interessanten Funktionen, Optimierungen und .
LMDB wird auch oft als Speicher verwendet. Zum Beispiel hat der Browser Mozilla Firefox für eine Reihe von Bedürfnissen, und ab Version 9 hat Xcode Die Engine zeigte sich auch in der Welt der mobilen Entwicklung. Spuren ihrer Nutzung sind zu finden.
Der Engine hat auch in der Welt der mobilen Entwicklung auf sich aufmerksam gemacht. Spuren seiner Nutzung sind im iOS-Client für Telegram. LinkedIn ging sogar noch weiter und wählte LMDB als Standard-Speicher für das hauseigene Datenbank-Framework Rocket Data, wie in seinem Artikel aus dem Jahr 2016.
LMDB behauptet erfolgreich seinen Platz in der Nische, die BerkeleyDB nach der Übernahme durch Oracle hinterlassen hat. Die Bibliothek wird für ihre Geschwindigkeit und Zuverlässigkeit, selbst im Vergleich zu ähnlichen, geschätzt. Wie bekannt ist, gibt es kein kostenloses Mittagessen, und es ist wichtig, den trade-off zu betonen, mit dem man konfrontiert wird, wenn man zwischen LMDB und SQLite wählt. Das obige Schema zeigt deutlich, wie die höhere Geschwindigkeit erzielt wird. Erstens zahlen wir nicht für zusätzliche Abstraktionsschichten über dem Speicher. Verständlicherweise kann man in einer guten Architektur nicht darauf verzichten, und sie werden letztlich im Anwendungscode erscheinen, jedoch viel dünner. Es werden keine Funktionen vorhanden sein, die von der spezifischen Anwendung nicht benötigt werden, wie etwa die Unterstützung von SQL-Anfragen. Zweitens wird die Möglichkeit geschaffen, die Abbildung der Anwendungsoperationen auf die Anfragen des Speichers optimal umzusetzen. Wenn SQLite Wenn man von den durchschnittlichen Bedürfnissen einer typischen Anwendung ausgeht, sind Sie als Anwendungsentwickler bestens mit den grundlegenden Lastszenarien vertraut. Für eine leistungsfähigere Lösung müssen Sie jedoch höhere Kosten sowohl für die Entwicklung der ursprünglichen Lösung als auch für deren spätere Unterstützung in Kauf nehmen.
3. Drei Säulen von LMDB
Nachdem wir LMDB aus der Vogelperspektive betrachtet haben, ist es an der Zeit, tiefer einzutauchen. Die nächsten drei Abschnitte widmen sich der Analyse der grundlegenden Säulen, auf denen die Architektur des Speichers beruht:
- Speicherabbildungsdateien als Mechanismus zur Arbeit mit der Festplatte und zur Synchronisierung interner Datenstrukturen.
- B+-Baum als Strukturorganisation für die gespeicherten Daten.
- Copy-on-Write als Ansatz zur Gewährleistung der ACID-Eigenschaften von Transaktionen und der Multi-Versionierung.
3.1. Säule Nr. 1. Memory-mapped Dateien
Die im Speicher angezeigten Dateien sind so wichtig, dass sie sogar im Namen des Speichers vorkommen. Fragen zu Cache und Synchronisierung des Zugriffs auf die gespeicherten Informationen liegen vollständig in der Verantwortung des Betriebssystems. LMDB enthält keine internen Caches. Dies ist eine bewusste Entscheidung des Autors, da das Lesen von Daten direkt aus den angezeigten Dateien viele Ecken bei der Implementierung der Engine einsparen kann. Im Folgenden präsentiere ich eine nicht vollständige Liste einiger davon.
- Die Aufrechterhaltung der Datenkonsistenz im Speicher bei Zugriff durch mehrere Prozesse liegt in der Verantwortung des Betriebssystems. Im nächsten Abschnitt wird dieses Mechanismus ausführlich und mit Bildern erläutert.
- Das Fehlen von Caches befreit LMDB vollständig von den Overheadkosten, die mit dynamischen Allokationen verbunden sind. Das Lesen von Daten besteht in der Praxis darin, einen Zeiger auf die richtige Adresse im virtuellen Speicher zu setzen und nicht mehr. Klingt wie eine Fantasie, aber im Quellcode des Speichers sind alle Aufrufe von salloc in der Konfigurationsfunktion des Speichers zusammengefasst.
- Das Fehlen von Caches bedeutet auch das Fehlen von Sperren, die mit deren Zugriffssynchronisation verbunden sind. Leser, deren Zahl beliebig sein kann, stoßen auf ihrem Weg zu den Daten nie auf ein einziges Mutex. Dadurch erreicht die Lesegeschwindigkeit eine perfekte lineare Skalierbarkeit in Bezug auf die Anzahl der CPUs. In LMDB sind nur modifizierende Operationen von Synchronisation betroffen. Zu jedem Zeitpunkt kann nur ein Schreiber aktiv sein.
- Ein Minimum an Cache- und Synchronisationslogik befreit den Code von äußerst komplexen Fehlern, die in einer Multi-Thread-Umgebung auftreten können. Auf der Usenix OSDI 2014 gab es zwei interessante Datenbankstudien: und . Aus diesen Studien lässt sich sowohl die unvergleichliche Zuverlässigkeit von LMDB als auch die nahezu tadellose Implementierung der ACID-Eigenschaften von Transaktionen entnehmen, die in SQLite nicht erreicht werden.
- Der Minimalismus von LMDB ermöglicht es, dass die maschinelle Darstellung ihres Codes vollständig im L1-Cache des Prozessors untergebracht werden kann, was entsprechende Geschwindigkeitsmerkmale zur Folge hat.
Leider ist die Situation in iOS mit den im Speicher abgebildeten Dateien nicht so optimal, wie man es sich wünschen würde. Um über die damit verbundenen Nachteile fundierter sprechen zu können, müssen die allgemeinen Prinzipien der Implementierung dieses Mechanismus in Betriebssystemen erinnert werden.
Allgemeine Informationen zu im Speicher abgebildeten Dateien
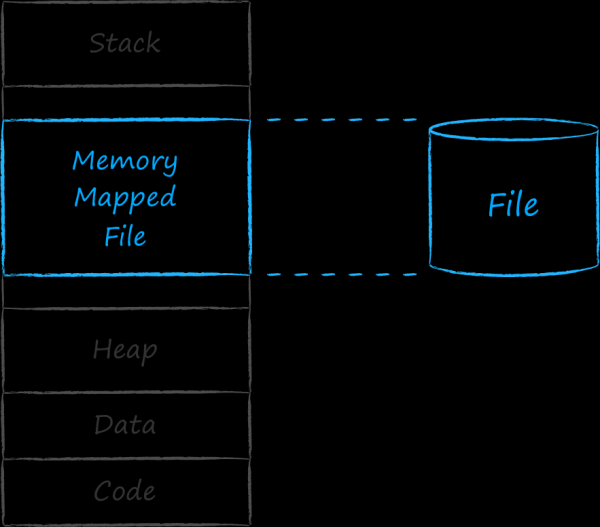 Jede ausführbare Anwendung wird mit einer Entität assoziiert, die als Prozess bezeichnet wird. Jeder Prozess erhält einen kontinuierlichen Adressbereich, in dem er alles Notwendige für seine Funktion unterbringt. In den niedrigsten Adressen befinden sich die Abschnitte mit Code sowie fest codierten Daten und Ressourcen. Darauf folgt ein wachsender Block des dynamischen Adressraums, besser bekannt als Heap. In diesem sind die Adressen von Entitäten, die während der Ausführung des Programms entstehen. Oben befindet sich der Speicherbereich, der vom Stack der Anwendung verwendet wird. Dieser kann wachsen und schrumpfen, was bedeutet, dass seine Größe ebenfalls dynamisch ist. Damit Stack und Heap sich nicht gegenseitig stören, sind sie an verschiedenen Enden des Adressraums angeordnet. Zwischen diesen beiden dynamischen Abschnitten gibt es eine Lücke. Die Adressen in diesem zentralen Bereich nutzt das Betriebssystem zur Zuordnung der unterschiedlichsten Entitäten zum Prozess. Insbesondere kann es einem kontinuierlichen Adressbereich eine Datei auf der Festplatte zuordnen. Eine solche Datei wird als in den Speicher abgebildet bezeichnet.
Jede ausführbare Anwendung wird mit einer Entität assoziiert, die als Prozess bezeichnet wird. Jeder Prozess erhält einen kontinuierlichen Adressbereich, in dem er alles Notwendige für seine Funktion unterbringt. In den niedrigsten Adressen befinden sich die Abschnitte mit Code sowie fest codierten Daten und Ressourcen. Darauf folgt ein wachsender Block des dynamischen Adressraums, besser bekannt als Heap. In diesem sind die Adressen von Entitäten, die während der Ausführung des Programms entstehen. Oben befindet sich der Speicherbereich, der vom Stack der Anwendung verwendet wird. Dieser kann wachsen und schrumpfen, was bedeutet, dass seine Größe ebenfalls dynamisch ist. Damit Stack und Heap sich nicht gegenseitig stören, sind sie an verschiedenen Enden des Adressraums angeordnet. Zwischen diesen beiden dynamischen Abschnitten gibt es eine Lücke. Die Adressen in diesem zentralen Bereich nutzt das Betriebssystem zur Zuordnung der unterschiedlichsten Entitäten zum Prozess. Insbesondere kann es einem kontinuierlichen Adressbereich eine Datei auf der Festplatte zuordnen. Eine solche Datei wird als in den Speicher abgebildet bezeichnet.
Der adressierte Speicherraum für Prozesse ist enorm. Theoretisch ist die Anzahl der Adressen nur durch die Größe des Zeigers begrenzt, was von der Bitbreite des Systems abhängt. Wäre die physische Speichergröße 1:1 zugeordnet, könnte der erste Prozess den gesamten Arbeitsspeicher aufbrauchen und von Multitasking könnte keine Rede sein.
Allerdings wissen wir aus Erfahrung, dass moderne Betriebssysteme gleichzeitig beliebig viele Prozesse ausführen können. Das ist möglich, weil sie nur auf dem Papier Prozessen eine Menge Speicher zuweisen, tatsächlich jedoch nur den Teil in den physischen Hauptspeicher laden, der gerade benötigt wird. Daher wird der mit einem Prozess assoziierte Speicher als virtuell bezeichnet.
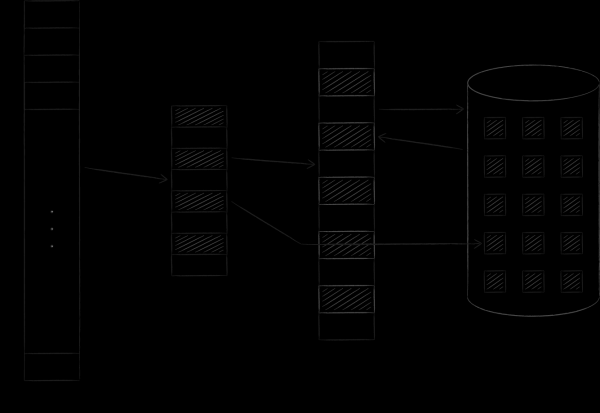
Das Betriebssystem organisiert den virtuellen und physischen Speicher in Form von Seiten bestimmter Größe. Sobald eine virtuelle Speicherseite benötigt wird, lädt das Betriebssystem sie in den physischen Speicher und stellt eine Zuordnung in einer speziellen Tabelle her. Wenn keine freien Slots verfügbar sind, wird eine zuvor geladene Seite auf die Festplatte kopiert, und die angeforderte Seite nimmt ihren Platz ein. Dieses Verfahren, auf das wir bald zurückkommen werden, nennt man Swapping. Die folgende Abbildung veranschaulicht den beschriebenen Prozess. Darauf wurde die Seite A mit der Adresse 0 geladen und auf der Hauptspeicherseite mit der Adresse 4 platziert. Dies wird in der Zuordnungstabelle in Zelle Nummer 0 reflektiert.
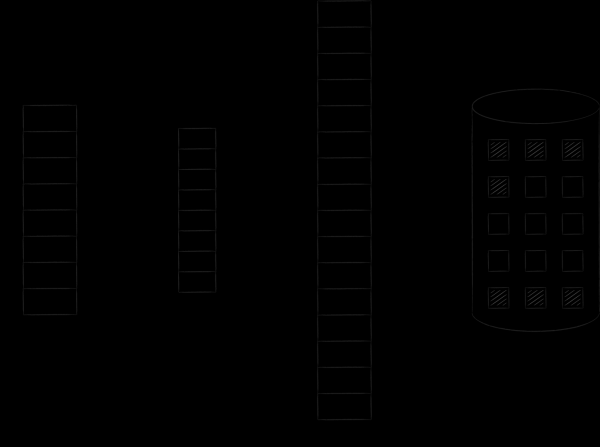
Die im Dateispeicher angezeigte Historie ist genau die gleiche. Logisch gesehen werden sie angeblich kontinuierlich und vollständig im virtuellen Adressraum platziert. Tatsächlich gelangen sie jedoch seitenweise und nur auf Anfrage in den physischen Speicher. Die Änderung solcher Seiten wird mit der Datei auf der Festplatte synchronisiert. So lässt sich eine dateibasierte Ein-/Ausgabe durchführen, indem man einfach mit Bytes im Speicher arbeitet — alle Änderungen werden automatisch vom Betriebssystemkern in die Ausgangsdatei übertragen.
Das folgende Bild zeigt, wie LMDB seinen Zustand synchronisiert, wenn es mit einer Datenbank aus verschiedenen Prozessen arbeitet. Indem wir den virtuellen Speicher verschiedener Prozesse auf dieselbe Datei abbilden, verpflichten wir das Betriebssystem de facto dazu, bestimmte Blöcke ihrer Adressräume transitiv zu synchronisieren, auf die LMDB zugreift.
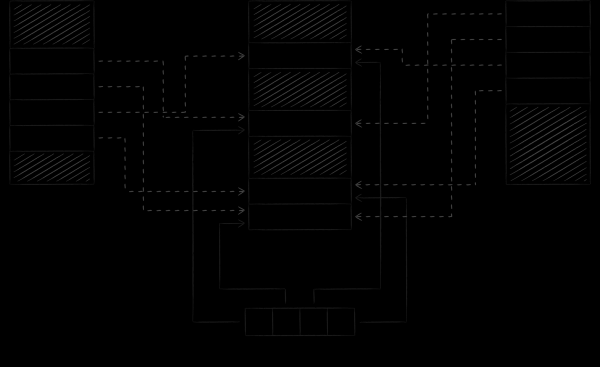
Ein wichtiger Aspekt ist, dass LMDB standardmäßig die Datendatei über den Systemaufruf write ändert, während die Datei selbst im schreibgeschützten Modus angezeigt wird. Dieser Ansatz hat zwei wichtige Folgen.
Die erste Konsequenz ist für alle Betriebssysteme allgemein. Sie besteht darin, einen Schutz gegen unbeabsichtigte Datenbankschäden durch fehlerhaften Code hinzuzufügen. Wie bekannt ist, können die ausführbaren Anweisungen eines Prozesses auf Daten aus jedem Teil seines Adressraums zugreifen. Gleichzeitig bedeutet das Laden einer Datei im Lese- und Schreibmodus, dass jede Anweisung diese Datei zudem auch modifizieren kann. Wenn dies versehentlich geschieht, zum Beispiel indem versucht wird, ein Array-Element mit einem nicht existierenden Index zu überschreiben, könnte dies die Datei, die an diese Adresse gebunden ist, zufällig ändern, was zu einer Beschädigung der Datenbank führt. Wenn die Datei jedoch im Nur-Lese-Modus geladen ist, führt der Versuch, den entsprechenden Adressraum zu ändern, zum Absturz des Programms mit einem Signal. SIGSEGV, und die Datei bleibt intakt.
Die zweite Konsequenz ist spezifisch für iOS. Weder der Autor noch andere Quellen erwähnen dies ausdrücklich, aber ohne sie wäre LMDB für die Nutzung in diesem mobilen Betriebssystem ungeeignet. Der nächsten Abschnitt ist dieser Überlegung gewidmet.
Die Spezifik der in den Speicher abgebildeten Dateien in iOS
Auf der WWDC 2018 gab es einen großartigen Vortrag . Darin wird erläutert, dass alle Seiten, die im physischen Speicher in iOS gespeichert sind, zu einem der 3 Typen gehören: dirty, compressed und clean.

Clean Memory ist die Gesamtheit der Seiten, die schmerzfrei aus dem physischen Speicher ausgelagert werden können. Die darin enthaltenen Daten können bei Bedarf erneut aus ihren ursprünglichen Quellen geladen werden. Read-only memory-mapped Dateien fallen genau in diese Kategorie. iOS hat keine Bedenken, die auf Datei abgebildeten Seiten jederzeit aus dem Speicher auszulagern, da sie garantiert mit der Datei auf der Festplatte synchronisiert sind.
In den Dirty Memory gelangen alle modifizierten Seiten, wo auch immer sie ursprünglich gespeichert waren. Insbesondere werden auch die durch Schreiben in den damit assoziierten virtuellen Speicher geänderten memory-mapped Dateien so klassifiziert. Wenn man LMDB mit dem Flag MDB_WRITEMAP, öffnet, kann man dies nach der Durchführung von Änderungen persönlich überprüfen.
Sobald eine Anwendung zu viel physischen Speicherplatz belegt, unterzieht iOS sie der Kompression von dirty Seiten. Der Gesamtspeicher, der von dirty und komprimierten Seiten belegt wird, wird als der sogenannte memory footprint der Anwendung bezeichnet. Wenn dieser einen bestimmten Schwellenwert erreicht, kommt der Systemdaemon OOM killer und beendet den Prozess zwangsweise. Das ist ein wesentliches Merkmal von iOS im Vergleich zu Desktop-Betriebssystemen. Im Gegensatz zu diesen ist in iOS keine Reduzierung des memory footprint durch das Auslagern von Seiten aus dem physischen Speicher auf die Festplatte vorgesehen. Über die Gründe kann man nur spekulieren. Möglicherweise ist der Prozess des intensiven Verschiebens von Seiten auf die Festplatte und zurück zu energieaufwendig für mobile Geräte, oder iOS spart die Ressourcen beim Überschreiben von Zellen auf SSDs. Vielleicht waren die Designer auch mit der Gesamtleistung des Systems unzufrieden, da alles ständig ausgelagert wird. Wie dem auch sei, der Fakt bleibt bestehen.
Die gute Nachricht, die bereits erwähnt wurde, ist, dass LMDB standardmäßig keinen mmap-Mechanismus zur Aktualisierung von Dateien verwendet. Das bedeutet, dass die angezeigten Daten von iOS als sauberes Gedächtnis klassifiziert werden und somit nicht zum memory footprint beitragen. Dies kann mit einem Xcode-Tool namens VM Tracker überprüft werden. Der Screenshot unten zeigt den Zustand des virtuellen Speichers der iOS-Anwendung Clouds während des Betriebs. Zu Beginn wurden 2 Instanzen von LMDB initialisiert. Der ersten wurde erlaubt, ihre Datei im virtuellen Speicher mit 1 GiB darzustellen, der zweiten mit 512 MiB. Obwohl beide Speicher einen bestimmten Anteil an residentem Speicher beanspruchen, trägt keiner von ihnen zur dirty size bei.
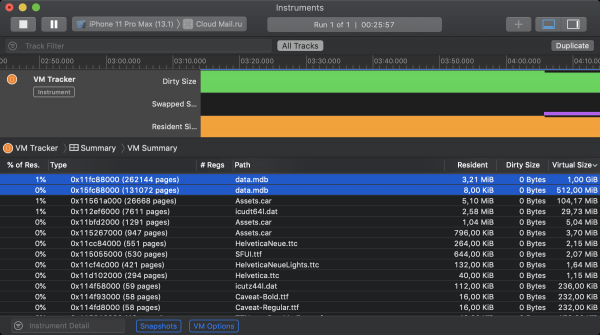
Und nun die schlechten Nachrichten. Dank des Swapping-Mechanismus in 64-Bit-Desktop-Betriebssystemen kann jeder Prozess den gesamten virtuellen Adressraum in Anspruch nehmen, den der freie Speicherplatz auf der Festplatte für sein mögliches Swapping zulässt. Der Austausch von Swapping durch Kompression in iOS verringert das theoretische Maximum radikal. Jetzt müssen alle laufenden Prozesse in den Hauptspeicher (also in den Arbeitsspeicher) passen, und alles, was nicht hineinpasst, wird zwangsläufig beendet. Davon wird im oben genannten erwähnt. als auch in Infolgedessen beschränkt iOS strikt die Größe des Speichers, der über mmap zugewiesen werden kann. Hier ist Es lässt sich beobachten, welche empirischen Grenzen bei den Speichergrößen erreicht wurden, die durch diesen Systemaufruf auf verschiedenen Geräten zugeteilt werden konnten. Bei den modernsten iOS-Smartphones stehen großzügig 2 Gigabyte zur Verfügung, während die Top-Versionen des iPads mit 4 Gigabyte punkten. In der Praxis orientiert man sich jedoch natürlich an den am niedrigsten unterstützten Modellen, wo die Lage recht düster ist. Schlimmer noch, wenn man den Speicherzustand der Anwendung im VM Tracker betrachtet, stellt man fest, dass LMDB nicht die einzige ist, die um memory-mapped Speicher konkurriert. Ein erheblicher Teil wird auch von System-Allocatoren, Ressourcen-Dateien, Bildverarbeitungs-Frameworks und anderen kleineren Prädatoren in Anspruch genommen.
Auf Basis der Experimente in der Cloud sind wir zu folgenden Kompromisswerten für den zugewiesenen LMDB-Speicher gekommen: 384 Megabyte für 32-Bit-Geräte und 768 für 64-Bit-Geräte. Nach Verbrauch dieses Volumens beginnen alle modifizierenden Operationen, mit dem Code zu enden. MDB_MAP_FULL. Solche Fehler beobachten wir in unserer Überwachung, allerdings sind sie so selten, dass sie in diesem Stadium vernachlässigt werden können.
Eine weniger offensichtliche Ursache für übermäßigen Speicherverbrauch durch das Speichersystem können langlebige Transaktionen sein. Um zu verstehen, wie diese beiden Phänomene miteinander verbunden sind, betrachten wir die verbleibenden zwei Säulen von LMDB.
3.2. Säule Nr. 2. B+-Baum
Um Tabellen über ein key-value-Speichersystem zu emulieren, müssen in seiner API folgende Operationen vorhanden sein:
- Einfügen eines neuen Elements.
- Suchen eines Elements mit einem bestimmten Schlüssel.
- Löschen eines Elements.
- Iterieren über Schlüsselbereiche in sortierter Reihenfolge.
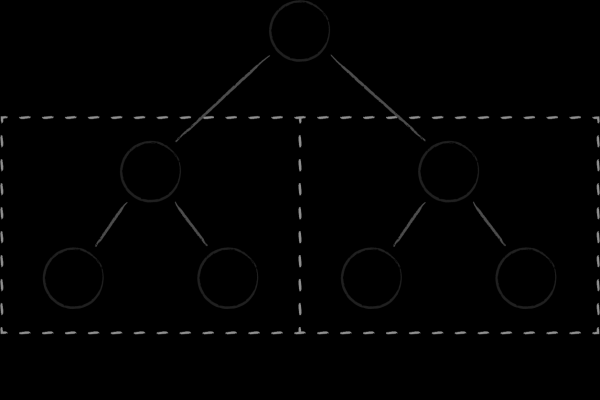 Die einfachste Datenstruktur, mit der man alle vier Operationen leicht implementieren kann, ist der binäre Suchbaum. Jeder Knoten repräsentiert einen Schlüssel, der die gesamte Teilmenge der Kindschlüssel in zwei Teilbäume unterteilt. Links sind die, die kleiner als der Elternknoten sind, und rechts die, die größer sind. Das Erhalten einer sortierten Menge von Schlüsseln wird durch einen der klassischen Baumdurchläufe erreicht.
Die einfachste Datenstruktur, mit der man alle vier Operationen leicht implementieren kann, ist der binäre Suchbaum. Jeder Knoten repräsentiert einen Schlüssel, der die gesamte Teilmenge der Kindschlüssel in zwei Teilbäume unterteilt. Links sind die, die kleiner als der Elternknoten sind, und rechts die, die größer sind. Das Erhalten einer sortierten Menge von Schlüsseln wird durch einen der klassischen Baumdurchläufe erreicht.
Bei binären Bäumen gibt es zwei fundamentale Mängel, die ihre Effizienz als Datenspeicherstruktur beeinträchtigen. Erstens ist der Grad ihrer Balance unvorhersehbar. Es besteht ein beträchtliches Risiko, Bäume zu erhalten, bei denen die Höhe der verschiedenen Äste erheblich variieren kann, was die algorithmische Suchkomplexität im Vergleich zu den Erwartungen erheblich verschlechtert. Zweitens rauben die zahlreichen Querverweise zwischen den Knoten den binären Bäumen die lokale Speicherzuweisung. Nahe Knoten (in Bezug auf ihre Verbindungen) könnten sich auf völlig unterschiedlichen Seiten im virtuellen Speicher befinden. Folglich kann es selbst für eine einfache Durchquerung mehrerer benachbarter Knoten im Baum erforderlich sein, eine vergleichbare Anzahl von Seiten zu besuchen. Dies stellt ein Problem dar, selbst wenn wir über die Effizienz binärer Bäume als In-Memory-Datenstruktur nachdenken, da die ständige Rotation von Seiten im Cache des Prozessors kostspielig ist. Wenn es jedoch um das häufige Abrufen von seitenverknüpften Knoten von der Festplatte geht, wird die Lage geradezu katastrophal. .
 B-Bäume, als Weiterentwicklung der binären Bäume, lösen die im vorherigen Absatz genannten Probleme. Erstens sind sie selbstbalancierend. Zweitens unterteilt jeder Knoten eine Vielzahl von Kinderschlüsseln nicht in 2, sondern in M sortierte Teilmengen, wobei M ziemlich groß sein kann, im Bereich von mehreren Hundert bis hin zu Tausenden.
B-Bäume, als Weiterentwicklung der binären Bäume, lösen die im vorherigen Absatz genannten Probleme. Erstens sind sie selbstbalancierend. Zweitens unterteilt jeder Knoten eine Vielzahl von Kinderschlüsseln nicht in 2, sondern in M sortierte Teilmengen, wobei M ziemlich groß sein kann, im Bereich von mehreren Hundert bis hin zu Tausenden.
Dank dieser Eigenschaften:
- In jedem Knoten befindet sich eine große Anzahl bereits sortierter Schlüssel, wodurch die Bäume sehr flach werden.
- Der Baum erlangt die Eigenschaft der Lokalität im Speicher, da nahe beieinander liegende Schlüssel natürlich nebeneinander in einem oder benachbarten Knoten angeordnet sind.
- Die Anzahl der Übergangsknoten wird während der Suchoperation im Baum verringert.
- Die Anzahl der gelesenen Zielknoten bei Range-Anfragen wird verringert, da in jedem von ihnen bereits eine große Anzahl sortierter Schlüssel vorhanden ist.
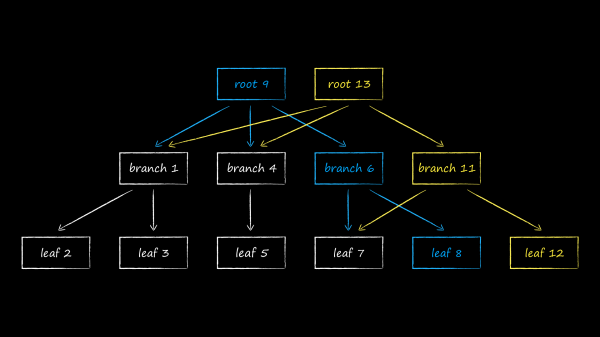
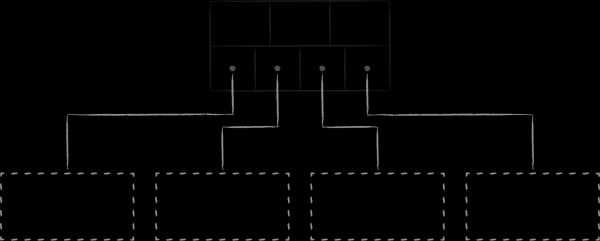
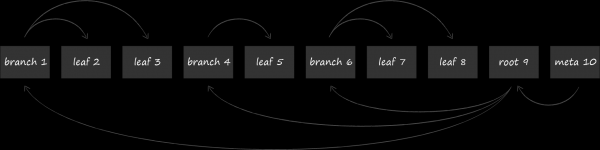
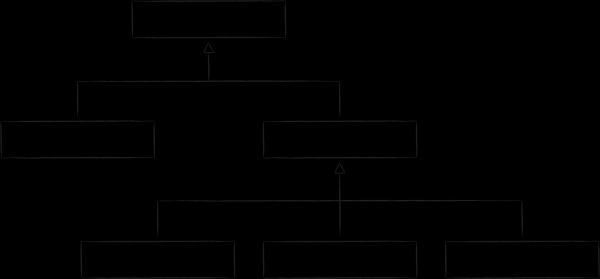
In LMDB wird zur Speicherung der Daten eine der Variationen des B-Baums, das B+-Baum, verwendet. In der obigen Darstellung sind die drei Typen von Knoten abgebildet, die darin vorkommen:
- An der Spitze befindet sich die Wurzel (root). Sie materialisiert nichts anderes als das Datenbankkonzept innerhalb des Speichers. Innerhalb einer einzigen LMDB-Instanz können mehrere Datenbanken erstellt werden, die einen gemeinsam genutzten, gemappten virtuellen Adressraum teilen. Jede von ihnen beginnt mit ihrer eigenen Wurzel.
- Auf der untersten Ebene befinden sich die Blätter (leaf). Diese enthalten ausschließlich die in der Datenbank gespeicherten Schlüssel-Wert-Paare. Dies ist eine Besonderheit der B+-Bäume. Während ein gewöhnlicher B-Baum die Wertteile in den Knoten aller Ebenen speichert, geschieht dies bei der B+-Variante nur auf der untersten Ebene. Sobald dieser Fakt festgehalten ist, werden wir die verwendete Baumunterart in LMDB einfach als B-Baum bezeichnen.
- Zwischen der Wurzel und den Blättern befinden sich 0 oder mehr technische Ebenen mit Navigationsknoten (branch). Ihre Aufgabe ist es, die sortierte Menge von Schlüsseln zwischen den Blättern zu verteilen.
Physische Knoten sind Speichereinheiten mit einer vorab definierten Länge. Ihre Größe ist ein Vielfaches der Seitengröße des Betriebssystems, über das wir zuvor gesprochen haben. Die Struktur des Knotens wird unten dargestellt. Im Header befindet sich die Metainformation, die für dieses Beispiel am offensichtlichsten ist — die Prüfziffer. Danach folgt die Information über die Offsets, an denen die Datenzellen platziert sind. Als Daten können entweder Schlüssel fungieren, wenn wir von Navigationsknoten sprechen, oder vollständige Schlüssel-Wert-Paare im Falle von Blättern. Mehr über die Struktur der Seiten können Sie in der Arbeit nachlesen. .
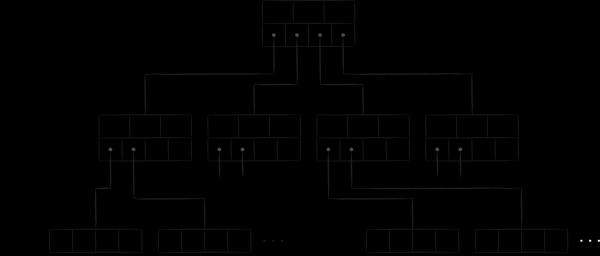
Nachdem wir uns mit dem internen Inhalt der Seitenknoten befasst haben, werden wir den B-Baum LMDB vereinfachend in der folgenden Form darstellen.
Die Seiten mit Knoten werden nacheinander auf der Festplatte angeordnet. Seiten mit höherer Nummer befinden sich näher am Ende der Datei. Die sogenannte Metaseite (meta page) enthält Informationen über die Offsets, mit denen die Wurzeln aller Bäume gefunden werden können. Beim Öffnen der LMDB-Datei scannt das System die Datei seitenweise von Ende zu Anfang auf der Suche nach einer gültigen Metaseite, über die es dann die vorhandenen Datenbanken findet.
Jetzt, da wir ein Verständnis für die logische und physische Struktur der Datenorganisation haben, können wir zum dritten Grundpfeiler von LMDB übergehen. Damit werden alle Änderungen im Speicher transaktional und isoliert voneinander durchgeführt, was der Datenbank insgesamt auch die Eigenschaft der Multi-Versionierung verleiht.
3.3. Grundpfeiler Nr. 3. Copy-on-write
Einige Operationen mit B-Bäumen erfordern eine Reihe von Änderungen an seinen Knoten. Ein Beispiel ist das Hinzufügen eines neuen Schlüssels zu einem Knoten, der bereits seine maximale Kapazität erreicht hat. In diesem Fall muss der Knoten zunächst in zwei Teile geteilt und dann ein Verweis auf den neu abgezweigten Kindknoten in seinem übergeordneten Knoten hinzugefügt werden. Dieser Vorgang ist potenziell sehr gefährlich. Sollte aus irgendeinem Grund (Absturz, Stromausfall usw.) nur ein Teil der Änderungen in der Reihe ausgeführt werden, bleibt der Baum in einem inkonsistenten Zustand.
Eine der traditionellen Lösungen zur Gewährleistung der Fehlertoleranz einer Datenbank besteht darin, neben dem B-Baum eine zusätzliche Datenstruktur hinzuzufügen — das Transaktionsprotokoll, auch bekannt als Write-Ahead Log (WAL). Es handelt sich um eine Datei, in die die vermutete Operation strikt vor der Modifikation des B-Baums geschrieben wird. Wenn während der Selbstdiagnose Datenbeschädigungen festgestellt werden, konsultiert die Datenbank das Protokoll, um sich zu reparieren.
LMDB wählte als Mechanismus zur Gewährleistung der Fehlertoleranz eine andere Methode, die Copy-on-Write genannt wird. Das Prinzip besteht darin, dass anstatt die Daten auf der bestehenden Seite zu aktualisieren, diese zunächst vollständig kopiert wird und alle Modifikationen dann in der Kopie vorgenommen werden.
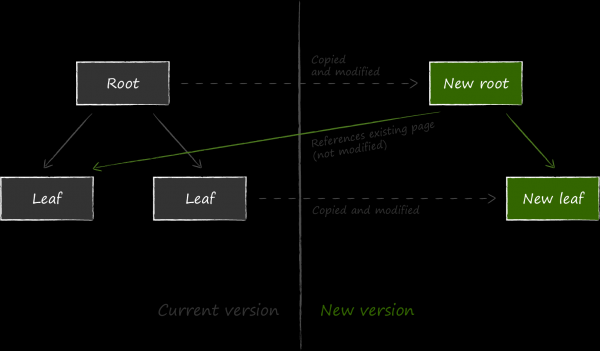
Um die aktualisierten Daten verfügbar zu machen, muss der Verweis auf den aktuell gewordenen Knoten im übergeordneten Knoten geändert werden. Da auch dieser modifiziert werden muss, wird er ebenfalls zuvor kopiert. Dieser Prozess setzt sich rekursiv bis zur Wurzel fort. Zuletzt werden die Daten auf der Metaseite geändert.
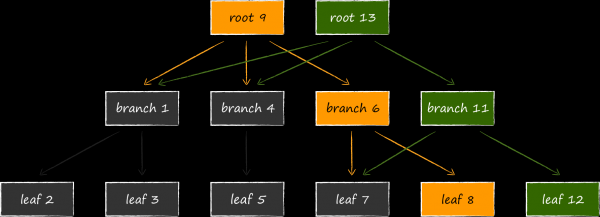
Sollte während des Aktualisierungsprozesses ein unerwarteter Abbruch des Vorgangs auftreten, wird entweder keine neue Metaseite erstellt oder sie wird nicht bis zum Ende auf der Festplatte gespeichert, sodass ihre Prüfziffer inkorrekt ist. In beiden Fällen sind die neuen Seiten nicht zugänglich, während die alten unverändert bleiben. Dies entbindet LMDB von der Notwendigkeit, ein Write-Ahead-Log zur Gewährleistung der Datenkonsistenz zu führen. Die oben beschriebene Datenstruktur auf der Festplatte übernimmt de facto auch diese Funktion. Das Fehlen eines Transaktionsprotokolls in expliziter Form ist eines der Merkmale von LMDB, das eine hohe Lesegeschwindigkeit der Daten gewährleistet.
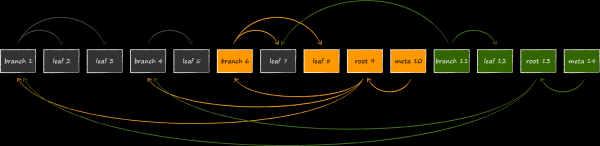
Die resultierende Struktur namens append-only B-tree gewährleistet auf natürliche Weise Transaktionsisolierung und Multiversionität. In LMDB ist jede geöffnete Transaktion mit dem aktuellen Baumwurzel verbunden. Solange die Transaktion nicht abgeschlossen ist, werden die Seiten des entsprechenden Baums niemals geändert oder für neue Datenversionen wiederverwendet. Somit kann man so lange mit genau dem Datensatz arbeiten, der zum Zeitpunkt der Öffnung der Transaktion aktuell war, selbst wenn der Speicher zu diesem Zeitpunkt weiterhin aktiv aktualisiert wird. Darin liegt das Wesen der Multiversionität, die LMDB zur idealen Datenquelle für uns alle macht. UICollectionView. Bei der Öffnung einer Transaktion muss der Speicherbedarf der Anwendung nicht erhöht werden, indem aktuelle Daten hastig in eine in-memory Struktur geladen werden, aus Angst, mit leeren Händen dazustehen. Dieses Merkmal hebt LMDB vorteilhaft von SQLite ab, das mit einer solchen totalen Isolation nicht aufwarten kann. Wenn man im letzteren zwei Transaktionen öffnet und einen bestimmten Datensatz in einer davon löscht, kann dieser Datensatz auch in der übrigen zweiten Transaktion nicht mehr abgerufen werden.
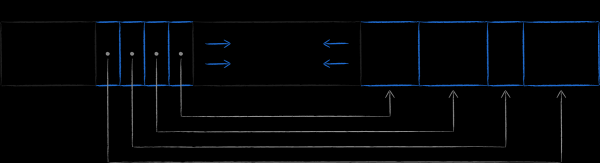
Die Kehrseite der Medaille ist ein potenziell deutlich höherer Verbrauch an virtuellem Speicher. Die Folie zeigt, wie die Struktur der Datenbank aussehen wird, wenn sie gleichzeitig mit 3 geöffneten Lese-Transaktionen, die auf verschiedene Versionen der Datenbank verweisen, verändert wird. Da LMDB keine Knoten, die von den Wurzeln aktueller Transaktionen aus erreichbar sind, erneut verwenden kann, bleibt dem Speicher nichts anderes übrig, als einen vierten Wurzelknoten im Speicher zu platzieren und unter ihm die modifizierbaren Seiten erneut zu klonen.
Hier ist es nützlich, sich an den Abschnitt über speicherabgebildete Dateien zu erinnern. Obwohl zusätzliche Ausgaben für virtuellen Speicher uns nicht allzu sehr belasten sollten, da sie nicht zur Speichernutzung der Anwendung beitragen, wurde jedoch festgestellt, dass iOS sehr sparsam bei deren Zuteilung ist. Wir können nicht einfach, wie auf Servern oder Desktops, einen LMDB-Bereich von 1 Terabyte bereitstellen, ohne diese Eigenheit zu beachten. Wo immer möglich, sollte die Lebensdauer der Transaktionen so kurz wie möglich gehalten werden.
4. Entwurf des Datenschemas über die Key-Value-API
Wir beginnen die Analyse der API mit den grundlegenden Abstraktionen, die LMDB bereitstellt: Umgebung und Datenbanken, Schlüssel und Werte, Transaktionen und Cursors.
Hinweis zu den Code-Listings
Alle Funktionen in der öffentlichen API von LMDB geben das Ergebnis ihrer Arbeit in Form eines Fehlercodes zurück, jedoch wurde die Überprüfung in allen nachfolgenden Listings der Kürze halber weggelassen. Praktisch haben wir für die Interaktion mit dem Speicher unsere eigenen C++-Wrapper , in dem Fehler als C++-Ausnahmen materialisiert werden.
Als schnellste Möglichkeit, LMDB in ein Projekt für iOS oder macOS anzubinden, empfehle ich mein CocoaPod. .
4.1. Grundlegende Abstraktionen
Umgebung (environment)
Struktur MDB_env ist das Container für den internen Zustand von LMDB. Die Funktionsfamilie mit dem Präfix mdb_env ermöglicht es, einige seiner Eigenschaften zu konfigurieren. Im einfachsten Fall sieht die Initialisierung des Engines folgendermaßen aus.
mdb_env_create(env);
mdb_env_set_map_size(*env, 1024 * 1024 * 512)
mdb_env_open(*env, path.UTF8String, MDB_NOTLS, 0664);In der Mail.ru Cloud-App haben wir die Standardwerte nur für zwei Parameter geändert.
Der erste davon ist die Größe des virtuellen Adressraums, auf den die Datenspeicherdatei abgebildet wird. Leider kann der konkrete Wert sogar auf demselben Gerät von Ausführung zu Ausführung erheblich variieren. Um dieser Eigenschaft von iOS Rechnung zu tragen, wird die maximale Speichermenge dynamisch ausgewählt. Ausgehend von einem bestimmten Wert wird sie fortlaufend halbiert, bis die Funktion mdb_env_open ein Ergebnis zurückgibt, das von ENOMEM. In der Theorie gibt es auch den entgegengesetzten Weg – zunächst dem Engine das Minimum an Speicher zuzuweisen und dann bei Auftreten von Fehlern. MDB_MAP_FULL, ihre Größe zu erhöhen. Allerdings ist es viel komplizierter. Der Grund dafür ist, dass die Neuverteilung des Speichers (remap) mit der Funktion mdb_env_set_map_size alle Entitäten (Cursore, Transaktionen, Schlüssel und Werte), die zuvor vom Engine erhalten wurden, ungültig macht. Die Berücksichtigung dieser Wendung im Code würde zu einer erheblichen Komplexität führen. Wenn Ihnen jedoch der virtuelle Speicher sehr wichtig ist, kann dies ein Grund sein, einen weit fortgeschrittenen Fork in Betracht zu ziehen. , der unter den angegebenen Funktionen eine "automatische Anpassung der Datenbankgröße zur Laufzeit" bietet.
Der zweite Parameter, dessen Standardwert uns nicht passte, reguliert die Mechanik der Gewährleistung von Thread-Sicherheit. Leider gibt es zumindest in iOS 10 Probleme mit der Unterstützung von thread local storage. Aus diesem Grund wird im obigen Beispiel das Speicher mit dem Flag MDB_NOTLS. Darüber hinaus war es notwendig, auch C++-Wrapper , um Variablen mit diesem Attribut darin herauszuschneiden.
Datenbanken
Die Datenbank ist eine separate Instanz des B-Baums, über die wir zuvor gesprochen haben. Ihre Eröffnung erfolgt innerhalb einer Transaktion, was zunächst etwas seltsam erscheinen mag.
MDB_txn *txn;
MDB_dbi dbi;
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn);
mdb_dbi_open(txn, NULL, MDB_CREATE, &dbi);
mdb_txn_abort(txn);Tatsächlich ist eine Transaktion in LMDB eine Speichereinheit und keine spezifische Datenbank. Dieses Konzept ermöglicht atomare Operationen auf Entitäten in verschiedenen Datenbanken. Theoretisch eröffnet es die Möglichkeit, Tabellen als verschiedene Datenbanken zu modellieren, doch ich habe zu meiner Zeit einen anderen Weg gewählt, der weiter unten ausführlich beschrieben wird.
Schlüssel und Werte
Struktur MDB_val modelliert das Konzept sowohl als Schlüssel als auch als Wert. Das Speichersystem hat die geringste Vorstellung von deren Semantik. Für es ist etwas das andere — einfach ein Array von Bytes einer bestimmten Größe. Die maximale Größe eines Schlüssels beträgt 512 Bytes.
typedef struct MDB_val {
size_t mv_size;
void *mv_data;
} MDB_val;Mit Hilfe des Comparators sortiert das Speichersystem die Schlüssel aufsteigend. Wenn man ihn nicht durch einen eigenen ersetzt, wird der Standard-Comparator verwendet, der sie byteweise in lexikografischer Reihenfolge sortiert.
Transaktionen
Die Funktionsweise von Transaktionen wird ausführlich in der beschrieben, weshalb ich hier kurz ihre Hauptmerkmale wiederhole:
- Unterstützung aller grundlegenden Eigenschaften : Atomarität, Konsistenz, Isolation und Zuverlässigkeit. Ich möchte nicht unerwähnt lassen, dass es in Bezug auf die Haltbarkeit in macOS und iOS einen Bug gibt, der in MDBX behoben wurde. Weitere Informationen finden Sie in deren .
- Der Ansatz zur Multithread-Verarbeitung wird durch das Schema „ein Schreiber / mehrere Leser“ beschrieben. Schreiber blockieren sich gegenseitig, blockieren jedoch keine Leser. Leser blockieren weder Schreiber noch sich gegenseitig.
- Unterstützung für verschachtelte Transaktionen.
- Unterstützung für Multiversionierung.
Die Multiversionierung in LMDB ist so gut, dass ich sie in Aktion demonstrieren möchte. Aus dem folgenden Code ist ersichtlich, dass jede Transaktion genau mit der Version der Datenbank arbeitet, die zum Zeitpunkt ihrer Öffnung aktuell war, dabei vollständig isoliert von allen nachfolgenden Änderungen. Die Initialisierung des Speichers und das Hinzufügen eines Testeintrags sind nichts Besonderes, daher wurden diese Rituale unter einem Spoiler belassen.
Hinzufügen eines Testeintrags
MDB_env *env;
MDB_dbi dbi;
MDB_txn *txn;
mdb_env_create(&env);
mdb_env_open(env, "./testdb", MDB_NOTLS, 0664);
mdb_txn_begin(env, NULL, 0, &txn);
mdb_dbi_open(txn, NULL, 0, &dbi);
mdb_txn_abort(txn);
char k = 'k';
MDB_val key;
key.mv_size = sizeof(k);
key.mv_data = (void *)&k;
int v = 997;
MDB_val value;
value.mv_size = sizeof(v);
value.mv_data = (void *)&v;
mdb_txn_begin(env, NULL, 0, &txn);
mdb_put(txn, dbi, &key, &value, MDB_NOOVERWRITE);
mdb_txn_commit(txn);MDB_txn *txn1, *txn2, *txn3;
MDB_val val;
// Wir eröffnen 2 Transaktionen, von denen jede auf die
// Version der Datenbank mit einem Datensatz zugreift.
mdb_txn_begin(env, NULL, 0, &txn1); // read-write
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn2); // read-only
// Im Rahmen der ersten Transaktion löschen wir den vorhandenen Datensatz aus der Datenbank.
mdb_del(txn1, dbi, &key, NULL);
// Wir bestätigen die Löschung.
mdb_txn_commit(txn1);
// Wir eröffnen die dritte Transaktion, die auf die
// aktuelle Version der Datenbank zugreift, in der der Datensatz nicht mehr existiert.
mdb_txn_begin(env, NULL, MDB_RDONLY, &txn3);
// Wir stellen sicher, dass der Datensatz mit dem gesuchten Schlüssel nicht mehr existiert.
assert(mdb_get(txn3, dbi, &key, &val) == MDB_NOTFOUND);
// Wir beenden die Transaktion.
mdb_txn_abort(txn3);
// Wir stellen sicher, dass der Datensatz im Rahmen der zweiten Transaktion,
// die zu dem Zeitpunkt geöffnet war, als der Datensatz in der Datenbank existierte,
// immer noch über den Schlüssel gefunden werden kann.
assert(mdb_get(txn2, dbi, &key, &val) == MDB_SUCCESS);
// Wir überprüfen, dass wir mit dem Schlüssel keine beliebigen Müllwerte, sondern valide Daten erhalten.
assert(*(int *)val.mv_data == 997);
// Wir beenden die Transaktion, die mit einer zwar veralteten, aber konsistenten Datenbank arbeitet.
mdb_txn_abort(txn2);Ich empfehle optional, denselben Trick mit SQLite zu versuchen und zu sehen, was dabei herauskommt.
Die Multi-Versionierung bringt sehr angenehme Vorteile für iOS-Entwickler mit sich. Mit dieser Eigenschaft kann die Aktualisierungsgeschwindigkeit der Datenquelle für Bildschirmformulare ganz einfach und unkompliziert entsprechend den Benutzererfahrungen gesteuert werden. Nehmen wir als Beispiel eine Funktion der Mail.ru Cloud-App, wie die automatische Content-Downloads aus der System-Mediagalerie. Bei einer guten Verbindung kann der Kunde mehrere Fotos pro Sekunde auf den Server hochladen. Wenn nach jedem Upload UICollectionView die Mediendaten im Benutzer-Cloud aktualisiert werden, kann man von 60 fps und flüssigem Scrollen während dieses Prozesses vergessen. Um häufige Bildschirmaktualisierungen zu verhindern, muss die Datenänderungsgeschwindigkeit an der Basis begrenzt werden. UICollectionViewDataSource.
Wenn die Datenbank keine Multi-Versionierung unterstützt und nur mit dem aktuellen Zustand arbeitet, ist es erforderlich, eine stabile Zeitaufnahme der Daten zu erstellen, indem sie entweder in einer In-Memory-Datenstruktur oder in einer temporären Tabelle kopiert wird. Jeder dieser Ansätze ist sehr kostspielig. Bei einem In-Memory-Speicher entstehen sowohl Speicher- als auch Zeitkosten, die durch das Speichern konstruierter Objekte und durch überflüssige ORM-Transformationen verursacht werden. Was die temporäre Tabelle betrifft, so ist dies ein noch teurerer Ansatz, der nur in nicht-trivialen Fällen sinnvoll ist.
Die Multi-Versionierung von LMDB löst das Problem der Aufrechterhaltung einer stabilen Datenquelle äußerst elegant. Es reicht aus, einfach eine Transaktion zu eröffnen, und voilà – bis wir sie abschließen, ist unser Datensatz garantiert fixiert. Die Logik der Aktualisierungsgeschwindigkeit liegt nun vollständig in den Händen der Präsentationsschicht, ohne nennenswerte Ressourcenkosten.
Cursors
Cursoren bieten einen Mechanismus zum geordneten Iterieren über Schlüssel-Wert-Paare durch Traversierung eines B-Baums. Ohne sie wäre es unmöglich, Tabellen in einer Datenbank effizient zu modellieren, worauf wir nun übergehen.
4.2. Modellierung von Tabellen
Die Eigenschaft der Ordnung der Schlüssel ermöglicht es, auf der Basis grundlegender Abstraktionen eine hochgradige Struktur wie eine Tabelle zu konstruieren. Lassen Sie uns diesen Prozess am Beispiel der Haupttabelle eines Cloud-Kunden betrachten, in der Informationen über alle Dateien und Ordner des Benutzers zwischengespeichert sind.
Tabellenschema
Ein häufiges Szenario, für das die Struktur der Tabelle mit einem Ordnersystem optimiert sein muss, ist die Abfrage aller Elemente, die sich innerhalb eines bestimmten Verzeichnisses befinden. Ein gutes Datenorganisationsmodell für effiziente Anfragen dieser Art ist . Um sie zu realisieren, müssen die Schlüssel von Dateien und Ordnern über einem Key-Value-Speicher so sortiert werden, dass sie auf der Grundlage ihrer Zugehörigkeit zu dem übergeordneten Verzeichnis gruppiert werden. Außerdem sollten, um den Inhalt des Verzeichnisses in der für Windows-Benutzer gewohnten Art darzustellen (zuerst die Ordner, dann die Dateien, beide alphabetisch sortiert), entsprechende zusätzliche Felder in den Schlüssel aufgenommen werden.
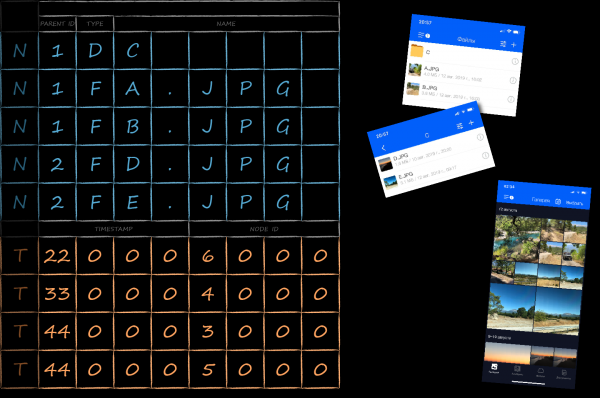
Das Bild unten zeigt, wie die Schlüssel entsprechend der gestellten Aufgabe als Byte-Array dargestellt werden können. Zuerst werden die Bytes mit der ID des übergeordneten Verzeichnisses (rot), danach die mit dem Typ (grün) und zuletzt die mit dem Namen (blau) angeordnet. Durch die Sortierung mit dem Standard-Comparator von LMDB in lexikografischer Reihenfolge werden sie in der gewünschten Weise geordnet. Eine sequenzielle Durchlauf der Schlüssel mit demselben roten Präfix liefert uns die zugehörigen Werte in der Reihenfolge, in der sie im Benutzerinterface ausgegeben werden sollen (rechts), ohne dass zusätzliche Nachbearbeitung erforderlich ist.

Serialisierung von Schlüsseln und Werten
Es gibt viele Methoden zur Serialisierung von Objekten. Da unsere einzige Anforderung die Geschwindigkeit war, haben wir uns für die schnellste verfügbare Methode entschieden — den Speicher-Dump der von einer Instanz einer C-Struktur belegten Speicher. So kann der Schlüssel eines Verzeichniselements durch die folgende Struktur modelliert werden. NodeKey.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameBuffer[256];
} NodeKey;Zur Speicherung NodeKey im Speicher muss der Zeiger auf die Daten auf die Adresse des Beginns der Struktur positioniert werden, und ihre Größe wird durch die Funktion MDB_val sizeof MDB_val serialize(NodeKey * const key) { return MDB_val { .mv_size = sizeof(NodeKey), .mv_data = (void *)key }; }.
MDB_val serialize(NodeKey * const key) {
return MDB_val {
.mv_size = sizeof(NodeKey),
.mv_data = (void *)key
};
}In dem ersten Kapitel über die Auswahlkriterien für Datenbanken erwähnte ich die Minimierung dynamischer Allokationen im Rahmen von CRUD-Operationen als wichtigen Auswahlfaktor. Der Code der Funktion serialize zeigt, wie man im Fall von LMDB das vollständige Vermeiden beim Einfügen neuer Datensätze in die Datenbank erreicht. Das empfangene Byte-Array vom Server wird zuerst in Stapelstrukturen transformiert, und dann werden sie auf triviale Weise in den Speicher gedumpt. Angesichts der Tatsache, dass es innerhalb von LMDB auch keine dynamischen Allokationen gibt, kann man eine fantastische Situation im Maßstab von iOS erhalten – für die Datenverarbeitung auf ihrem gesamten Weg vom Netzwerk bis zur Festplatte nur Stapelspeicher zu verwenden!
Sortierung der Schlüssel mit einem binären Komparator
Die Reihenfolge der Schlüssel wird durch eine spezielle Funktion bestimmt, die als Komparator bezeichnet wird. Da die Engine nichts über die Semantik der enthaltenen Bytes weiß, bleibt dem Standardkomparator nichts anderes übrig, als die Schlüssel in lexikografischer Reihenfolge zu sortieren, indem er byteweise Vergleiche anstellt. Seine Verwendung zur Sortierung von Strukturen ist vergleichbar mit dem Rasieren mit einem Küchenbeil. Trotzdem finde ich diesen Ansatz in einfachen Fällen akzeptabel. Alternativen werden etwas weiter unten beschrieben, und hier möchte ich auf ein paar Stolpersteine hinweisen, die auf diesem Weg liegen.
Das Erste, woran man denken sollte, ist die Speicherung primitiver Datentypen im Speicher. So werden auf allen Apple-Geräten Ganzzahlvariablen im Format . Das bedeutet, dass das am wenigsten signifikante Byte links steht und ganzzahlige Werte nicht durch ihre Byte-Vergleiche sortiert werden können. Zum Beispiel führt der Versuch, dies mit einer Menge von Zahlen von 0 bis 511 zu tun, zu folgendem Ergebnis.
// value (hex dump)
000 (0000)
256 (0001)
001 (0100)
257 (0101)
...
254 (fe00)
510 (fe01)
255 (ff00)
511 (ff01)Um dieses Problem zu lösen, müssen Ganzzahlen im Schlüssel in einem für den Byte-Comparator geeigneten Format gespeichert werden. Die notwendigen Konvertierungen können durch Funktionen aus der Familie hton* durchgeführt werden (insbesondere htons für die zweibyteigen Zahlen aus dem Beispiel).
Das Format der Darstellung von Zeichenfolgen in der Programmierung ist, wie bekannt, whole . Wenn die Semantik von Zeichenfolgen sowie die zur Speicherung im Speicher verwendete Codierung davon ausgeht, dass mehr als ein Byte pro Zeichen erforderlich ist, sollte man besser gleich von der Verwendung des Standard-Comparators Abstand nehmen.
Das Zweite, was man im Kopf behalten sollte, sind die ein Kompilator für Strukturfelder. Dadurch können in der Speicher zwischen den Feldern Bytes mit Müllwerten entstehen, was natürlich die Byte-für-Byte-Sortierung beeinträchtigt. Um diesen Müll zu beseitigen, muss man entweder die Felder in einer streng definierten Reihenfolge deklarieren und die Ausrichtungsregeln im Hinterkopf behalten oder im Strukturdeklaration das Attribut packed.
Die Sortierung von Schlüsseln durch einen externen Comparator
Die Logik zum Vergleichen von Schlüsseln kann für einen binären Comparator zu komplex sein. Einer der vielen Gründe hierfür ist das Vorhandensein technischer Felder innerhalb der Strukturen. Ich werde ihre Entstehung am Beispiel des bereits bekannten Schlüssels für ein Verzeichniselement veranschaulichen.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameBuffer[256];
} NodeKey;Trotz seiner Einfachheit benötigt er in den überwiegenden meisten Fällen zu viel Speicher. Der Puffer für den Namen belegt 256 Byte, obwohl Dateinamen und Ordnernamen im Durchschnitt selten 20-30 Zeichen überschreiten.
Eine der gängigen Techniken zur Optimierung der Speichergröße besteht darin, den Datensatz auf die tatsächliche Größe "zuzuschneiden". Das Grundprinzip besteht darin, dass der Inhalt aller variablen Felder am Ende der Struktur im Puffer gespeichert wird, während deren Längen in separaten Variablen abgelegt werden. Entsprechend diesem Ansatz wird der Schlüssel NodeKey wie folgt transformiert.
typedef struct NodeKey {
EntityId parentId;
uint8_t type;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeKey;Bei der Serialisierung wird nicht die gesamte Struktur als Datengröße angegeben, sondern die Größe aller Felder fester Länge plus die Größe des tatsächlich genutzten Puffers. MDB_val serialize(NodeKey * const key) { return MDB_val { .mv_size = sizeof(NodeKey), .mv_data = (void *)key }; } MDB_val serialize(NodeKey * const key) { return MDB_val { .mv_size = offsetof(NodeKey, nameBuffer) + key->nameLength, .mv_data = (void *)key }; }
Durch das durchgeführte Refactoring haben wir erheblich Platz gespart, der von den Schlüsseln eingenommen wird. Aufgrund des technischen FeldesnameLength , ist der standardmäßige binäre Komparator jedoch nicht mehr geeignet, um die Schlüssel zu vergleichen. Wenn wir ihn nicht durch unseren eigenen ersetzen, wird die Länge des Namens ein höheres Gewicht bei der Sortierung haben als der Name selbst.LMDB ermöglicht es, jeder Datenbank eine eigene Vergleichsfunktion für Schlüssel zuzuweisen. Dies erfolgt durch die Funktion
LMDB ermöglicht es, für jede Datenbank eine eigene Schlüsselsortierfunktion festzulegen. Dies geschieht über eine Funktion mdb_set_compare strikt bis zur Öffnung. Aus offensichtlichen Gründen kann die Datenbank während ihrer gesamten Laufzeit nicht geändert werden. Der Comparator erhält zwei Schlüssel im Binärformat als Eingabe und gibt das Ergebnis des Vergleichs zurück: kleiner (-1), größer (1) oder gleich (0). Der Pseudocode für NodeKey sieht folgendermaßen aus.
int compare(MDB_val * const a, MDB_val * const b) {
NodeKey * const aKey = (NodeKey * const)a->mv_data;
NodeKey * const bKey = (NodeKey * const)b->mv_data;
return // ...
}Solange alle Schlüssel in der Datenbank vom gleichen Typ sind, ist die bedingungslose Umwandlung ihrer Byte-Darstellung in den Typ der Anwendungsschlüsselstruktur zulässig. Hier gibt es jedoch einen wichtigen Punkt, der weiter unten im Abschnitt „Lesen von Einträgen“ behandelt wird.
Serialisierung von Werten
Mit den Schlüsseln der gespeicherten LMDB-Einträge wird äußerst intensiv gearbeitet. Der Vergleich zwischen ihnen erfolgt im Rahmen jeder Anwendung und die Geschwindigkeit des Comparators beeinflusst die Leistung der gesamten Lösung. In einer idealen Welt sollte der Standard-Binär-Comparator für den Vergleich von Schlüsseln ausreichen, aber falls es nötig ist, einen eigenen zu verwenden, sollte der Deserialisierungsprozess der Schlüssel so schnell wie möglich sein.
Die Value-Komponente des Eintrags (Wert) interessiert die Datenbank nicht besonders. Ihre Umwandlung von der Byte-Darstellung in ein Objekt erfolgt nur dann, wenn dies vom Anwendungscode bereits benötigt wird, zum Beispiel für die Anzeige auf dem Bildschirm. Da dies relativ selten geschieht, sind die Anforderungen an die Geschwindigkeit dieses Verfahrens nicht so kritisch, und bei der Implementierung können wir deutlich mehr auf den Komfort achten. Zum Beispiel verwenden wir für die Serialisierung von Metadaten über noch nicht geladene Dateien NSKeyedArchiver.
NSData *data = serialize(object);
MDB_val value = {
.mv_size = data.length,
.mv_data = (void *)data.bytes
};Es gibt jedoch Situationen, in denen die Leistung dennoch wichtig ist. Zum Beispiel verwenden wir beim Speichern von Metainformationen über die Dateistruktur der Benutzer-Cloud immer noch denselben Snapshot des Objektgedächtnisses. Ein besonderes Merkmal der Aufgabe zur Erstellung ihrer serialisierten Darstellung ist die Tatsache, dass die Verzeichniselemente durch eine Klassenhierarchie modelliert werden.
Für die Implementierung in der Programmiersprache C werden spezifische Felder der Nachkommen in separate Strukturen ausgelagert, und ihre Verbindung zur Basisklasse erfolgt über ein union-Feld. Der aktuelle Inhalt des Unions wird über das technische Attribut type festgelegt.
typedef struct NodeValue {
EntityId localId;
EntityType type;
union {
FileInfo file;
DirectoryInfo directory;
} info;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeValue;Hinzufügen und Aktualisieren von Datensätzen
Die serialisierten Schlüssel und Werte können in den Speicher eingefügt werden. Dafür wird die Funktion verwendet mdb_put.
// key и value имеют тип MDB_val
mdb_put(..., &key, &value, MDB_NOOVERWRITE);In der Konfigurationsphase kann der Speicher so eingestellt werden, dass er mehrere Datensätze mit demselben Schlüssel erlaubt oder verbietet. Wenn Duplikate von Schlüsseln verboten sind, kann beim Einfügen eines Datensatzes festgelegt werden, ob das Aktualisieren eines bereits vorhandenen Datensatzes erlaubt ist oder nicht. Wenn das Überschreiben nur aufgrund eines Codesfehlers auftreten kann, kann man sich absichern, indem man ein Flag angibt. NOOVERWRITE.
Lesen von Datensätzen
Zum Lesen von Datensätzen in LMDB ist die Funktion mdb_getvorgesehen. Wenn ein Schlüssel-Wert-Paar zuvor mit bestehenden Strukturen gespeichert wurde, sieht dieser Vorgang folgendermaßen aus:
NodeValue * const readNode(..., NodeKey * const key) {
MDB_val rawKey = serialize(key);
MDB_val rawValue;
mdb_get(..., &rawKey, &rawValue);
return (NodeValue * const)rawValue.mv_data;
}Der bereitgestellte Code zeigt, wie die Serialisierung über den Dump von Strukturen es ermöglicht, dynamische Zuweisungen nicht nur beim Schreiben, sondern auch beim Lesen von Daten zu vermeiden. Das aus der Funktion erhaltene mdb_get Der Zeiger verweist genau auf die Adresse des virtuellen Speichers, an dem die Datenbank die byteweise Darstellung des Objekts speichert. Im Grunde erhalten wir eine Art ORM, das nahezu kostenlos eine sehr hohe Lesegeschwindigkeit bietet. Trotz der Eleganz dieses Ansatzes ist es wichtig, einige damit verbundene Besonderheiten zu beachten.
- Für read-only Transaktionen bleibt der Zeiger auf die Struktur-Werte garantierte gültig, solange die Transaktion nicht geschlossen wird. Wie bereits erwähnt, bleiben die Seiten des B-Baums, auf denen sich das Objekt befindet, aufgrund des Copy-on-Write-Prinzips unverändert, solange mindestens eine Transaktion auf sie verweist. Sobald jedoch die letzte damit verbundene Transaktion abgeschlossen ist, können die Seiten für neue Daten wiederverwendet werden. Wenn Objekte die Transaktion, die sie erzeugt hat, überdauern sollen, müssen sie dennoch kopiert werden.
- Für read-write Transaktionen wird der Zeiger auf die erhaltene Struktur-Werte nur bis zur ersten Modifikationsprozedur (Schreiben oder Löschen von Daten) gültig sein.
- Obwohl die Struktur
NodeValuees ist nicht vollständig, sondern gekürzt (siehe Abschnitt „Sortierung von Schlüsseln mit einem externen Comparator“), über einen Zeiger können direkt auf ihre Felder zugegriffen werden. Wichtig ist, ihn nicht dereferenzieren! - Es darf auf keinen Fall die Struktur über den erhaltenen Zeiger modifiziert werden. Alle Änderungen müssen ausschließlich über die Methode vorgenommen werden
mdb_put. Doch selbst bei aller Willensstärke wird das nicht gelingen, da der Speicherbereich, in dem sich diese Struktur befindet, im read-only-Modus gemappt ist. - Die Remap-Datei in den Adressraum des Prozesses, um beispielsweise die maximale Speichergröße mit der Funktion zu erhöhen
mdb_env_set_map_sizemacht sämtliche Transaktionen und die damit verbundenen Entitäten im Allgemeinen sowie Zeiger auf die gelesenen Objekte im Besonderen ungültig.
Eine weitere Besonderheit ist so tückisch, dass die Offenlegung ihrer Essenz einfach nicht in einen weiteren Punkt passt. In dem Kapitel über B-Bäume habe ich das Schema der Anordnung seiner Seiten im Speicher dargestellt. Daraus folgt, dass die Adresse des Beginns des Puffers mit serialisierten Daten völlig willkürlich sein kann. Aufgrund dessen ist der Zeiger darauf, der in der Struktur erhalten wird, MDB_val und der auf die Struktur verweist, ist im Allgemeinen nicht ausgerichtet. Gleichzeitig erfordern die Architekturen einiger Chips (im Fall von iOS ist es armv7), dass die Adresse von Daten ein Vielfaches der Maschinenwortgröße oder, anders ausgedrückt, der Bit-Breite des Systems (für armv7 sind das 32 Bit) ist. Mit anderen Worten, eine Operation wie *(int *foo)0x800002 wird gleichgesetzt mit einem Fehlerverlauf und führt zu einem Absturz mit dem Fehlerurteil EXC_ARM_DA_ALIGN. Um ein so trauriges Schicksal zu vermeiden, gibt es zwei Möglichkeiten.
Die erste besteht darin, die Daten in eine bereits ausgerichtete Struktur zu kopieren. Zum Beispiel würde sich dies in einem benutzerdefinierten Komparator wie folgt darstellen.
int compare(MDB_val * const a, MDB_val * const b) {
NodeKey aKey, bKey;
memcpy(&aKey, a->mv_data, a->mv_size);
memcpy(&bKey, b->mv_data, b->mv_size);
return // ...
}Ein alternativer Weg besteht darin, den Compiler im Voraus zu informieren, dass die Strukturen mit Schlüssel und Wert möglicherweise nicht ausgerichtet sind, indem das Attribut aligned(1). Auf ARM kann derselbe Effekt auch mit dem Attribut packed erzielt werden. Da dies zudem die Optimierung des belegten Platzes der Struktur begünstigt, erscheint mir dieser Weg bevorzugenswert, auch wenn er die Kosten für den Datenzugriff erhöht.
typedef struct __attribute__((packed)) NodeKey {
uint8_t parentId;
uint8_t type;
uint8_t nameLength;
uint8_t nameBuffer[256];
} NodeKey;Range-Anfragen
Für das Durchlaufen einer Gruppe von Einträgen in LMDB gibt es eine Cursor-Abstraktion. Wie man damit arbeitet, werden wir am Beispiel einer uns bereits bekannten Tabelle mit Cloud-Metadaten erläutern.
Im Rahmen der Anzeige der Dateiliste in einem Verzeichnis müssen alle Schlüssel gefunden werden, die mit seinen untergeordneten Dateien und Ordnern verknüpft sind. In den vorherigen Abschnitten haben wir die Schlüssel so sortiert, NodeKey dass sie zunächst nach der ID des übergeordneten Verzeichnisses geordnet sind. Technisch gesehen reduziert sich die Aufgabe, den Inhalt des Ordners zu erhalten, darauf, den Cursor an das obere Ende der Gruppe von Schlüsseln mit dem gegebenen Prefix zu setzen und danach bis zur unteren Grenze zu iterieren.

Die obere Grenze kann "brutal" durch sequentielle Suche ermittelt werden. Dazu wird der Cursor zu Beginn der gesamten Schlüsselliste in der Datenbank platziert und dann inkrementiert, bis der Schlüssel mit der ID des übergeordneten Verzeichnisses darunter steht. Dieser Ansatz hat zwei offensichtliche Nachteile:
- Die lineare Komplexität der Suche kann, wie bekannt, in Bäumen und insbesondere in B-Bäumen logarithmisch durchgeführt werden.
- Es ist ineffizient, alle Seiten aus der Datei in den Hauptspeicher zu laden, die vor dem gesuchten Element liegen, da dies sehr kostspielig ist.
Glücklicherweise bietet die LMDB-API einen effektiven Ansatz zur initialen Positionierung des Cursors. Dazu muss ein Schlüssel gebildet werden, dessen Wert zweifellos kleiner oder gleich dem Schlüssel am oberen Rand des Intervalls ist. Beispielsweise können wir für die oben gezeigte Liste einen Schlüssel erstellen, bei dem das Feld parentId gleich 2 und alle anderen mit Nullen gefüllt ist. Dieser teilweise ausgefüllte Schlüssel wird der Funktion mdb_cursor_get als Operation übergeben MDB_SET_RANGE.
NodeKey upperBoundSearchKey = {
.parentId = 2,
.type = 0,
.nameLength = 0
};
MDB_val value, key = serialize(upperBoundSearchKey);
MDB_cursor *cursor;
mdb_cursor_open(..., &cursor);
mdb_cursor_get(cursor, &key, &value, MDB_SET_RANGE);Wenn die obere Grenze der Schlüsselgruppe gefunden wurde, iterieren wir weiter, bis wir entweder auf einen Schlüssel mit einem anderen Wert stoßen parentId, oder bis die Schlüssel ganz aufgebraucht sind.
do {
rc = mdb_cursor_get(cursor, &key, &value, MDB_NEXT);
// Verarbeitung...
} while (MDB_NOTFOUND != rc && // Ende der Tabelle überprüfen
IsTargetKey(key)); // Ende der Schlüsselsgruppe überprüfenWas angenehm ist, ist, dass wir beim Iterieren mit mdb_cursor_get nicht nur den Schlüssel, sondern auch den Wert erhalten. Wenn für die Auswahlbedingungen auch Felder aus dem value-Teil der Aufzeichnung überprüft werden müssen, sind sie ohne zusätzliche Schritte gut zugänglich.
4.3. Modellierung von Beziehungen zwischen Tabellen
Bis jetzt haben wir alle Aspekte des Designs und der Arbeit mit einer einseitigen Datenbank betrachtet. Man kann sagen, dass eine Tabelle eine Sammlung von sortierten Aufzeichnungen ist, die aus einheitlichen Schlüssel-Wert-Paaren bestehen. Wenn man den Schlüssel als Rechteck und den zugehörigen Wert als Quader darstellt, erhält man ein visuelles Schema der Datenbank.
![]()
In der Realität gelingt es jedoch selten, so einfach auszukommen. Oft erfordert eine Datenbank erstens mehrere Tabellen und zweitens, dass Abfragen in einer Reihenfolge ausgeführt werden, die nicht dem Primärschlüssel entspricht. Die Erstellung und Verknüpfung dieser Tabellen wird in diesem letzten Abschnitt behandelt.
Indextabellen
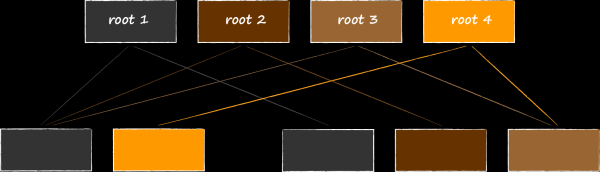
In der Cloud-Anwendung gibt es den Abschnitt „Galerie“. Dort wird der Medieninhalt aus der gesamten Cloud angezeigt, sortiert nach Datum. Für eine optimale Implementierung einer solchen Auswahl sollte neben der Haupttabelle eine weitere mit einem neuen Schlüsseltyp erstellt werden. Darin wird ein Feld mit dem Erstellungsdatum der Datei enthalten sein, welches als primäres Sortierkriterium dient. Da die neuen Schlüssel auf dieselben Daten verweisen wie die Schlüssel in der Haupttabelle, werden sie als Indexschlüssel bezeichnet. In der Abbildung unten sind sie orange hervorgehoben.
Um innerhalb einer Datenbank die Schlüssel verschiedener Tabellen voneinander zu trennen, wurde jedem von ihnen ein zusätzliches technisches Feld tableId hinzugefügt. Indem wir dieses Feld zur Priorität für die Sortierung machen, erreichen wir eine Gruppierung der Schlüssel zunächst nach Tabellen und innerhalb der Tabellen nach eigenen Regeln.
Der Indexschlüssel verweist auf dieselben Daten wie der primäre. Eine direkte Umsetzung dieses Merkmals durch assoziierte Kopien des value-Teils des primären Schlüssels ist aus mehreren Gründen suboptimal:
- Aus der Perspektive des Speicherplatzes, da Metadaten recht umfangreich sein können.
- In Bezug auf die Leistung muss beim Aktualisieren der Metadaten eines Knotens eine Neuschreibung nach zwei Schlüsselwerten erfolgen.
- In Bezug auf die Unterstützung des Codes, denn wenn wir vergessen, die Daten für einen der Schlüssel zu aktualisieren, erhalten wir einen schwer fassbaren Fehler der inkonsistenten Daten im Speicher.
Im Folgenden werden wir erörtern, wie man diese Nachteile beseitigen kann.
Organisation von Beziehungen zwischen Tabellen
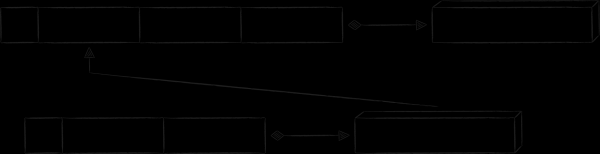
Für die Verbindung der Indextabelle mit der Haupttabelle eignet sich das Muster gut. „Schlüssel als Wert“. Wie der Name schon sagt, ist die value-Teil der Indexpunkte eine Kopie des Wertes des Primärschlüssels. Dieser Ansatz beseitigt alle oben genannten Nachteile, die mit der Speicherung einer Kopie des value-Teils des Primärdatensatzes verbunden sind. Der einzige Nachteil ist, dass für den Zugriff auf den Wert über den Indexschlüssel zwei Anfragen an die Datenbank statt einer erforderlich sind. Schematisch sieht das resultierende Datenbankschema wie folgt aus.
Ein weiteres Muster zur Organisation der Beziehung zwischen Tabellen ist „überschüssiger Schlüssel“. Der Kern besteht darin, im Schlüssel zusätzliche Attribute hinzuzufügen, die nicht für die Sortierung, sondern zur Rekonstruktion des zugehörigen Schlüssels erforderlich sind. In der Mail.ru Cloud-App gibt es echte Beispiele für die Verwendung, aber um ein tieferes Eintauchen in den Kontext spezifischer iOS-Frameworks zu vermeiden, möchte ich ein fiktives, aber verständlicheres Beispiel anführen.
In den Cloud-Mobil-Clients gibt es eine Seite, auf der alle Dateien und Ordner angezeigt werden, für die der Benutzer anderen Personen Zugriff gewährt hat. Da es nur relativ wenige solcher Dateien gibt, es jedoch viele verschiedene Arten von damit verbundenen spezifischen Informationen zur Öffentlichkeit gibt (wer hat Zugriff, mit welchen Rechten usw.), wäre es nicht sinnvoll, den value-Teil des Eintrags in der Haupttabelle damit zu belasten. Wenn man jedoch möchte, dass solche Dateien offline angezeigt werden, muss man sie irgendwo speichern. Eine natürliche Lösung besteht darin, eine separate Tabelle dafür anzulegen. In der folgenden Abbildung hat ihr Schlüssel das Präfix „P“, und der Platzhalter „propname“ kann durch den spezifischeren Wert „public info“ ersetzt werden.
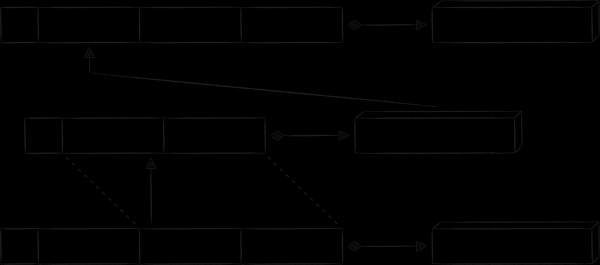
Alle einzigartigen Metadaten, wegen denen die neue Tabelle erstellt wurde, werden im Value-Teil des Eintrags gespeichert. Gleichzeitig möchte man die Daten über Dateien und Ordner, die bereits in der Haupttabelle gespeichert sind, nicht duplizieren. Stattdessen werden überflüssige Daten in den Schlüssel «P» in Form der Felder «Node ID» und «Timestamp» hinzugefügt. Mit diesen kann ein Indexschlüssel konstruiert werden, mit dem der Primärschlüssel und schließlich die Metadaten des Knotens abgerufen werden können.
Fazit
Die Ergebnisse der Implementierung von LMDB bewerten wir positiv. Seitdem ist die Anzahl der Anwendungsabstürze um 30 % gesunken.
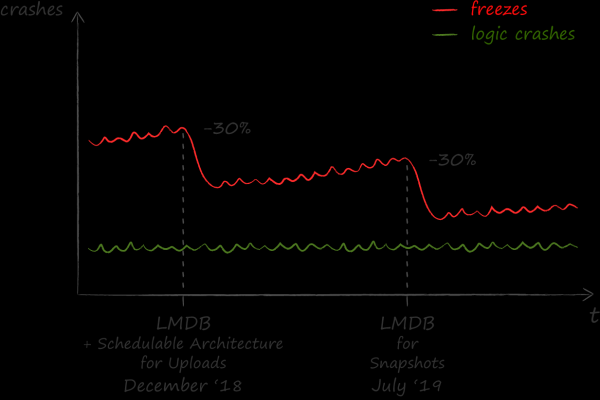
Die Ergebnisse der geleisteten Arbeit fanden auch außerhalb des iOS-Teams Beachtung. Mittlerweile hat auch einer der Hauptabschnitte «Dateien» in der Android-App auf die Nutzung von LMDB umgestellt, und weitere Teile sind in Vorbereitung. Die Programmiersprache C, in der das Key-Value-Speicher implementiert wurde, war eine gute Unterstützung, um zunächst eine plattformübergreifende Anwendungsschicht in C++ darum herum zu erstellen. Für die nahtlose Verbindung der entstandenen C++-Bibliothek mit dem plattformabhängigen Code in Objective-C und Kotlin wurde ein Codegenerator verwendet. von Dropbox, aber das ist eine ganz andere Geschichte.
Quelle: habr.com
