

Oft haben Menschen, die in den Bereich Data Science einsteigen, eine etwas unrealistische Vorstellung davon, was sie erwartet. Viele glauben, dass sie nun beeindruckende neuronale Netze erstellen, einen Sprachassistenten wie Iron Man entwickeln oder alle auf den Finanzmärkten schlagen werden.
Aber die Arbeit Data Scientist ist stark datenorientiert, und einer der wichtigsten und zeitaufwendigsten Schritte ist die Datenaufbereitung, bevor sie einem neuronalen Netz zugeführt oder auf bestimmte Weise analysiert werden.
In diesem Artikel wird unser Team beschreiben, wie man Daten einfach und schnell mit einer Schritt-für-Schritt-Anleitung und Code verarbeiten kann. Wir haben versucht, den Code so flexibel zu gestalten, dass er für verschiedene Datensätze anwendbar ist.
Viele Fachleute werden in diesem Artikel vielleicht nichts Außergewöhnliches finden, aber Anfänger können etwas Neues lernen, und jeder, der schon lange davon träumt, ein eigenes Notebook für die schnelle und strukturierte Datenverarbeitung zu erstellen, kann den Code kopieren und anpassen oder
Dataset erhalten. Was nun?
Zunächst müssen wir verstehen, womit wir es zu tun haben, um das Gesamtbild zu erfassen. Dafür verwenden wir Pandas, um verschiedene Datentypen zu identifizieren.
import pandas as pd # Wir importieren pandas
import numpy as np # Wir importieren numpy
df = pd.read_csv("AB_NYC_2019.csv") # Wir lesen den Datensatz ein und speichern ihn in der Variable df
df.head(3) # Wir betrachten die ersten 3 Zeilen, um zu verstehen, wie die Werte aussehen 
df.info() # Wir zeigen Informationen über die Spalten an 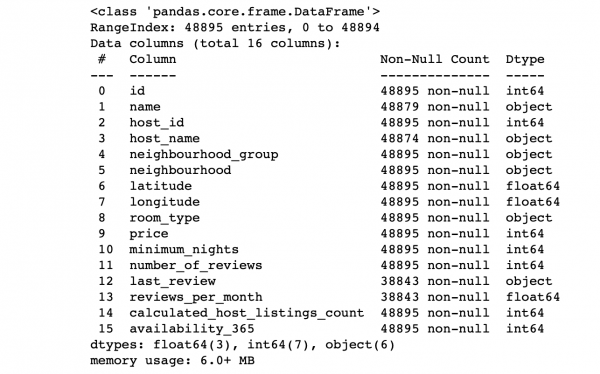
Schauen wir uns die Werte der Spalten an:
- Entspricht die Anzahl der Zeilen jeder Spalte der Gesamtanzahl der Zeilen?
- Was ist die Essenz der Daten in jeder Spalte?
- Welche Spalte möchten wir als Target festlegen, um Vorhersagen dafür zu treffen?
Antworten auf diese Fragen helfen uns, den Datensatz zu analysieren und einen Plan für die nächsten Schritte zu skizzieren.
Für einen tieferen Einblick in die Werte jeder Spalte können wir auch die Funktion pandas describe() nutzen. Der Nachteil dieser Funktion ist jedoch, dass sie keine Informationen über Spalten mit String-Werten liefert. Damit beschäftigen wir uns später.
df.describe() 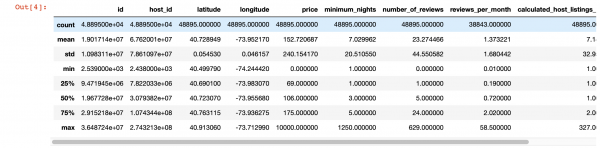
Magische Visualisierung
Lass uns ansehen, wo Werte ganz fehlen:
import seaborn as sns
sns.heatmap(df.isnull(), yticklabels=False, cbar=False, cmap='viridis') 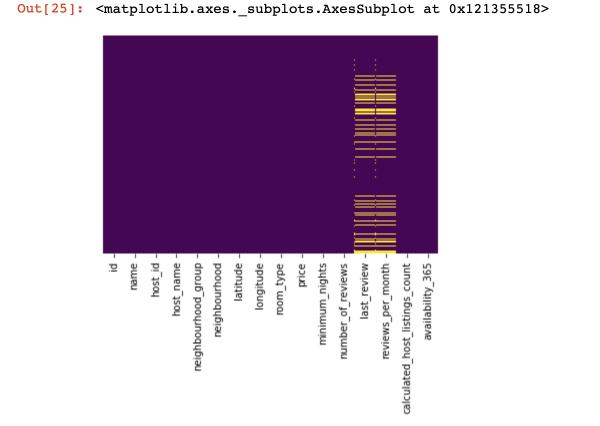
Das war ein kleiner Überblick, jetzt kommen wir zu spannendem Inhalt.
Lassen Sie uns versuchen, Spalten zu finden und wenn möglich zu entfernen, in denen in allen Zeilen nur ein Wert vorhanden ist (die beeinflussen das Ergebnis nicht):
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]] #Dataset neu schreiben, so dass nur Spalten mit mehr als einem einzigartigen Wert erhalten bleiben.Jetzt schützen wir uns und den Erfolg unseres Projekts vor Duplikatzeilen (Zeilen, die die gleiche Information in der gleichen Reihenfolge wie eine bereits bestehende Zeile enthalten):
df.drop_duplicates(inplace=True) #Wir tun dies, wenn wir es für notwendig erachten.
#In einigen Projekten ist es nicht ratsam, solche Daten von Anfang an zu entfernen.Wir teilen das Dataset in zwei Teile: einen mit qualitativen Werten und einen mit quantitativen Werten.
Hier ist eine kurze Klarstellung erforderlich: Wenn die Zeilen mit fehlenden Daten in qualitativen und quantitativen Daten stark unterschiedlich sind, müssen wir entscheiden, auf was wir verzichten – auf alle Zeilen mit fehlenden Daten, nur auf einen Teil davon oder auf bestimmte Spalten. Wenn die Zeilen jedoch korrelieren, haben wir das volle Recht, den Datensatz in zwei Teile zu trennen. Andernfalls müssen wir zuerst die Zeilen klären, in denen die fehlenden Daten in qualitativen und quantitativen Aspekten nicht übereinstimmen, und erst danach den Datensatz teilen.
df_numerical = df.select_dtypes(include = [np.number])
df_categorical = df.select_dtypes(exclude = [np.number])Wir tun dies, um die Verarbeitung dieser beiden unterschiedlichen Datentypen zu erleichtern – anschließend werden wir verstehen, wie sehr uns das das Leben vereinfacht.
Arbeiten mit quantitativen Daten
Das Erste, was wir tun sollten, ist festzustellen, ob es in den quantitativen Daten 'Spion-Spalten' gibt. Wir nennen diese Spalten so, weil sie sich als quantitative Daten ausgeben, aber tatsächlich wie qualitative arbeiten.
Wie identifizieren wir sie? Natürlich hängt alles von der Natur der Daten ab, die Sie analysieren, aber im Allgemeinen können solche Spalten wenige einzigartige Daten haben (ungefähr 3-10 einzigartige Werte).
print(df_numerical.nunique())Nachdem wir uns mit den Spionagespalten entschieden haben, verschieben wir sie von den quantitativen zu den qualitativen Daten:
spy_columns = df_numerical[['Spalte1', 'Spalte2', 'Spalte3']] # wir extrahieren die Spionagespalten und speichern sie in einer separaten DataFrame
df_numerical.drop(labels=['Spalte1', 'Spalte2', 'Spalte3'], axis=1, inplace=True) # wir entfernen diese Spalten aus den quantitativen Daten
df_categorical.insert(1, 'Spalte1', spy_columns['Spalte1']) # wir fügen die erste Spionagespalte zu den qualitativen Daten hinzu
df_categorical.insert(1, 'Spalte2', spy_columns['Spalte2']) # wir fügen die zweite Spionagespalte zu den qualitativen Daten hinzu
df_categorical.insert(1, 'Spalte3', spy_columns['Spalte3']) # wir fügen die dritte Spionagespalte zu den qualitativen Daten hinzuEndlich haben wir die quantitativen von den qualitativen Daten vollständig getrennt und können nun richtig damit arbeiten. Zunächst sollten wir herausfinden, wo wir leere Werte haben (NaN, und in einigen Fällen wird auch 0 als leerer Wert betrachtet).
for i in df_numerical.columns:
print(i, df[i][df[i]==0].count())In diesem Schritt ist es wichtig zu verstehen, in welchen Spalten Nullen fehlende Werte darstellen können: Hängt dies mit der Art und Weise zusammen, wie die Daten gesammelt wurden? Oder könnte es mit den Datenwerten selbst zu tun haben? Diese Fragen sollten in jedem einzelnen Fall beantwortet werden.
Wenn wir also entschieden haben, dass in den Daten dort, wo Nullen stehen, Werte fehlen können, sollten wir die Nullen durch NaN ersetzen, um die spätere Arbeit mit diesen fehlenden Daten zu erleichtern:
df_numerical[["Spalte 1", "Spalte 2"]] = df_numerical[["Spalte 1", "Spalte 2"]].replace(0, nan)Jetzt schauen wir uns an, wo Daten fehlen:
sns.heatmap(df_numerical.isnull(), yticklabels=False, cbar=False, cmap='viridis') # Alternativ kann auch df_numerical.info() verwendet werden 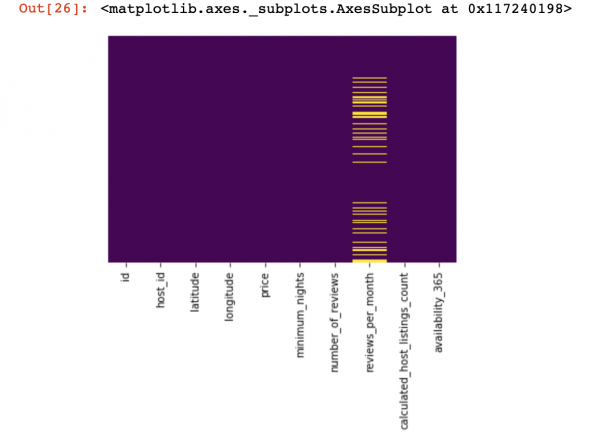
Hier sollten die fehlenden Werte innerhalb der Spalten gelb markiert sein. Und jetzt wird es interessant — wie soll mit diesen Werten verfahren werden? Die Zeilen mit diesen Werten löschen oder die Spalten? Oder die fehlenden Werte durch andere ersetzen?
Hier ist ein grober Plan, der Ihnen helfen kann, zu entscheiden, was grundsätzlich mit fehlenden Werten gemacht werden kann:
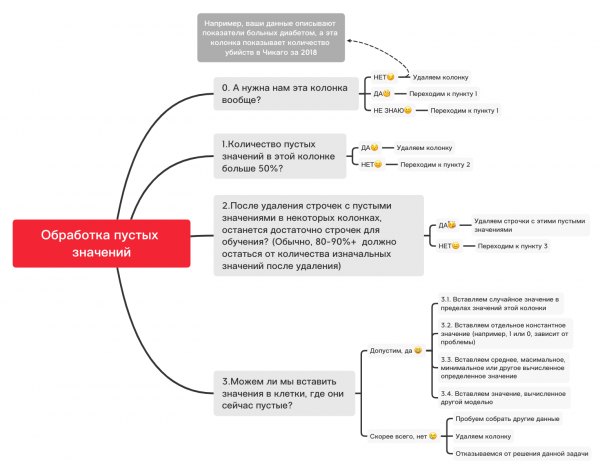
0. Entfernen Sie unnötige Spalten
df_numerical.drop(labels=["Spalte1", "Spalte2"], axis=1, inplace=True)1. Enthält diese Spalte mehr als 50% leere Werte?
print(df_numerical.isnull().sum() / df_numerical.shape[0] * 100)df_numerical.drop(labels=["kolonne1","kolonne2"], axis=1, inplace=True) # Entfernen, wenn eine Spalte mehr als 50 leere Werte hat2. Entfernen von Zeilen mit leeren Werten
df_numerical.dropna(inplace=True) # Entfernt Zeilen mit leeren Werten, wenn danach noch genügend Daten für das Training übrig bleiben3.1. Einfügen eines zufälligen Wertes
import random # Importieren von random
df_numerical["kolonne"].fillna(lambda x: random.choice(df[df[column] != np.nan]["kolonne"]), inplace=True) # Fügen Sie zufällige Werte in leere Zellen der Tabelle ein3.2. Einfügen eines konstanten Wertes
from sklearn.impute import SimpleImputer # Importieren von SimpleImputer, der beim Einfügen von Werten hilft
imputer = SimpleImputer(strategy='constant', fill_value="") # Bestimmten Wert mit SimpleImputer einfügen
df_numerical[["neue_kolonne1", 'neue_kolonne2', 'neue_kolonne3']] = imputer.fit_transform(df_numerical[['kolonne1', 'kolonne2', 'kolonne3']]) # Wenden Sie dies auf unsere Tabelle an
df_numerical.drop(labels=["kolonne1", "kolonne2", "kolonne3"], axis=1, inplace=True) # Entfernen Sie Spalten mit alten Werten3.3. Einfügen des Mittelwerts oder des häufigsten Wertes
from sklearn.impute import SimpleImputer #importieren Sie SimpleImputer, der Ihnen beim Einfügen von Werten hilft
imputer = SimpleImputer(strategy='mean', missing_values = np.nan) #anstatt mean kann auch most_frequent verwendet werden
df_numerical[["neue_spalte1", 'neue_spalte2', 'neue_spalte3']] = imputer.fit_transform(df_numerical[['spalte1', 'spalte2', 'spalte3']]) #Anwendung auf unsere Tabelle
df_numerical.drop(labels = ["spalte1", "spalte2", "spalte3"], axis = 1, inplace = True) #Entfernen der Spalten mit alten Werten3.4. Einfügen eines Wertes, der von einem anderen Modell berechnet wurde
Manchmal lassen sich Werte mit Hilfe von Regressionsmodellen berechnen, wobei Modelle aus der sklearn-Bibliothek oder ähnlichen Bibliotheken verwendet werden. Unser Team wird in naher Zukunft einen separaten Artikel dazu verfassen, wie dies umgesetzt werden kann.
So, während die Erzählung über quantitative Daten unterbrochen wird, gibt es viele andere Aspekte, wie man die Datenvorbereitung und -vorverarbeitung für unterschiedliche Aufgaben am besten angeht. Die grundlegenden Dinge für quantitative Daten wurden in diesem Artikel berücksichtigt, und jetzt ist es an der Zeit, zu den qualitativen Daten zurückzukehren, die wir vor einigen Schritten von den quantitativen getrennt haben. Sie können dieses Notebook nach Belieben anpassen, um es für verschiedene Aufgaben zu optimieren, sodass die Datenvorverarbeitung sehr schnell vonstattengeht!
Qualitative Daten
In der Regel wird für qualitative Daten die Methode des One-Hot-Encoding verwendet, um sie von string (oder Objekt) in Zahlen zu formatieren. Bevor wir zu diesem Punkt übergehen, nutzen wir das Schema und den Code von oben, um uns mit den leeren Werten zu beschäftigen.
df_categorical.nunique()sns.heatmap(df_categorical.isnull(), yticklabels=False, cbar=False, cmap='viridis') 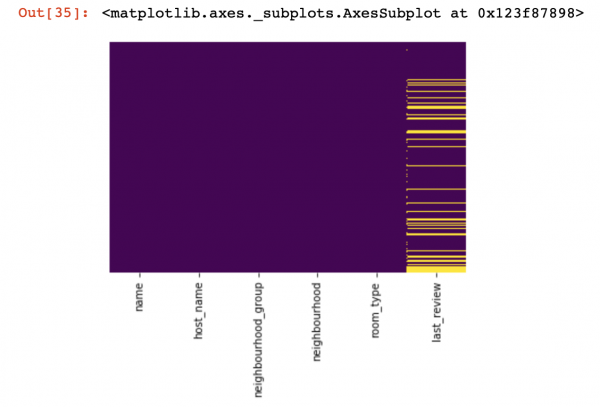
0. Entfernen Sie unnötige Spalten
df_categorical.drop(labels=["kolonne1", "kolonne2"], axis=1, inplace=True)1. Enthält diese Spalte mehr als 50% leere Werte?
print(df_categorical.isnull().sum() / df_numerical.shape[0] * 100)df_categorical.drop(labels=["kolonne1", "kolonne2"], axis=1, inplace=True) # Entfernen, wenn eine Spalte
# mehr als 50% leere Werte hat2. Entfernen von Zeilen mit leeren Werten
df_categorical.dropna(inplace=True)#Entfernen Sie Zeilen mit leeren Werten,
#wenn danach genügend Daten für das Training verbleiben3.1. Einfügen eines zufälligen Wertes
import random
df_categorical["column"].fillna(lambda x: random.choice(df[df[column] != np.nan]["column"]), inplace=True)3.2. Einfügen eines konstanten Wertes
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value="")
df_categorical[["neue_spalte1", 'neue_spalte2', 'neue_spalte3']] = imputer.fit_transform(df_categorical[['spalte1', 'spalte2', 'spalte3']])
df_categorical.drop(labels=["spalte1", "spalte2", "spalte3"], axis=1, inplace=True)Nun haben wir endlich die leeren Werte in den qualitativen Daten behandelt. Jetzt ist es an der Zeit, das One-Hot-Encoding für die Werte durchzuführen, die in Ihrer Datenbank vorhanden sind. Diese Methode wird häufig verwendet, damit Ihr Algorithmus mit den qualitativen Daten trainiert werden kann.
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
res = res.drop([feature_to_encode], axis=1)
return(res)features_to_encode = ["spalte1", "spalte2", "spalte3"]
for feature in features_to_encode:
df_categorical = encode_and_bind(df_categorical, feature))Nun haben wir endlich die qualitativen und quantitativen Daten getrennt verarbeitet – es ist Zeit, sie wieder zusammenzuführen.
new_df = pd.concat([df_numerical, df_categorical], axis=1)Nachdem wir die Datensätze zu einem einzigen vereint haben, können wir die Daten mit Hilfe des MinMaxScaler aus der Bibliothek sklearn transformieren. Dadurch werden unsere Werte in den Bereich von 0 bis 1 gebracht, was das Training des Modells in der Zukunft erleichtert.
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
new_df = min_max_scaler.fit_transform(new_df)Diese Daten sind jetzt für alles bereit – für neuronale Netzwerke, gängige ML-Algorithmen und mehr!
In diesem Artikel haben wir den Umgang mit zeitlichen Datensätzen nicht betrachtet, da hierfür etwas andere Verarbeitungstechniken erforderlich sind, abhängig von Ihrer Aufgabe. Zukünftig wird unser Team diesem Thema einen eigenen Artikel widmen, und wir hoffen, dass er Ihnen etwas Interessantes, Neues und Nützliches bringen kann, genau wie dieser.
Quelle: habr.com
