


Hallo zusammen! Mein Name ist Dmitry Samsonov und ich arbeite als leitender Systemadministrator bei Odnoklassniki. Wir betreiben über 7 physische Server, 11 Container in unserer Cloud und 200 Anwendungen, die in verschiedenen Konfigurationen 700 unterschiedliche Cluster bilden. Die überwiegende Mehrheit der Server läuft im Cloud-Betrieb. CentOS 7.
Am 14. August 2018 wurden Informationen zur FragmentSmack-Schwachstelle veröffentlicht
() und SegmentSmack (). Hierbei handelt es sich um Schwachstellen mit einem Netzwerk-Angriffsvektor und einem relativ hohen Wert (7.5), die aufgrund von Ressourcenerschöpfung (CPU) einen Denial-of-Service (DoS) drohen. Ein Kernel-Fix für FragmentSmack wurde zu diesem Zeitpunkt nicht vorgeschlagen; außerdem kam er viel später als die Veröffentlichung von Informationen über die Schwachstelle heraus. Um SegmentSmack zu eliminieren, wurde vorgeschlagen, den Kernel zu aktualisieren. Das Update-Paket selbst wurde am selben Tag veröffentlicht, es musste nur noch installiert werden.
Nein, wir sind überhaupt nicht gegen ein Update des Kernels! Allerdings gibt es Nuancen...
Wie wir den Kernel in der Produktion aktualisieren
Im Allgemeinen nichts Kompliziertes:
- Pakete herunterladen;
- Installieren Sie sie auf einer Reihe von Servern (einschließlich Servern, auf denen unsere Cloud gehostet wird);
- Stellen Sie sicher, dass nichts kaputt ist;
- Stellen Sie sicher, dass alle Standard-Kernel-Einstellungen fehlerfrei angewendet werden;
- Warten Sie ein paar Tage;
- Überprüfen Sie die Serverleistung.
- Bereitstellung neuer Server auf den neuen Kernel umstellen;
- Aktualisieren Sie alle Server nach Rechenzentrum (ein Rechenzentrum nach dem anderen, um die Auswirkungen auf Benutzer im Falle von Problemen zu minimieren);
- Starten Sie alle Server neu.
Wiederholen Sie dies für alle Zweige der Kernel, die wir haben. Im Moment ist es:
- Aktie CentOS 7 3.10 - für die meisten regulären Server;
- Vanille 4.19 – für uns , weil wir BFQ, BBR usw. brauchen;
- Elrepo Kernel-ML 5.2 – für , da sich 4.19 früher instabil verhielt, aber die gleichen Funktionen benötigt werden.
Wie Sie vielleicht schon erraten haben, dauert der Neustart Tausender Server am längsten. Da nicht alle Schwachstellen für alle Server kritisch sind, starten wir nur diejenigen neu, die direkt aus dem Internet erreichbar sind. Um die Flexibilität nicht einzuschränken, binden wir in der Cloud von außen erreichbare Container nicht an einzelne Server mit neuem Kernel, sondern starten ausnahmslos alle Hosts neu. Glücklicherweise ist die Vorgehensweise dort einfacher als bei regulären Servern. Beispielsweise können zustandslose Container bei einem Neustart einfach auf einen anderen Server verschoben werden.
Es gibt jedoch noch viel Arbeit und es kann mehrere Wochen dauern, bei Problemen mit der neuen Version sogar mehrere Monate. Angreifer verstehen das sehr gut und brauchen daher einen Plan B.
FragmentSmack/SegmentSmack. Problemumgehung
Glücklicherweise gibt es für einige Schwachstellen einen solchen Plan B, der Workaround genannt wird. In den meisten Fällen handelt es sich dabei um eine Änderung der Kernel-/Anwendungseinstellungen, die die möglichen Auswirkungen minimieren oder die Ausnutzung von Schwachstellen vollständig verhindern kann.
Im Fall von FragmentSmack/SegmentSmack diese Problemumgehung:
«Sie können die Standardwerte von 4 MB und 3 MB in net.ipv4.ipfrag_high_thresh und net.ipv4.ipfrag_low_thresh (und ihren Gegenstücken für IPv6 net.ipv6.ipfrag_high_thresh und net.ipv6.ipfrag_low_thresh) auf 256 kB bzw. 192 kB ändern untere. Tests zeigen je nach Hardware, Einstellungen und Bedingungen einen kleinen bis erheblichen Rückgang der CPU-Auslastung während eines Angriffs. Aufgrund von ipfrag_high_thresh=262144 Bytes kann es jedoch zu gewissen Leistungseinbußen kommen, da jeweils nur zwei 64-KB-Fragmente in die Reassemblierungswarteschlange passen. Beispielsweise besteht die Gefahr, dass Anwendungen, die mit großen UDP-Paketen arbeiten, abstürzen".
Die Parameter selbst wie folgt beschrieben:
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.
ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.
Wir haben keine großen UDPs für Produktionsdienste. Es gibt keinen fragmentierten Datenverkehr im LAN; es gibt fragmentierten Datenverkehr im WAN, aber nicht signifikant. Es gibt keine Anzeichen – Sie können Workaround einführen!
FragmentSmack/SegmentSmack. Erstes Blut
Das erste Problem, auf das wir stießen, war, dass Cloud-Container die neuen Einstellungen manchmal nur teilweise (nur ipfrag_low_thresh) und manchmal überhaupt nicht anwendeten – sie stürzten einfach beim Start ab. Das Problem konnte nicht stabil reproduziert werden (alle Einstellungen wurden problemlos manuell vorgenommen). Auch zu verstehen, warum der Container beim Start abstürzt, ist nicht so einfach: Es wurden keine Fehler gefunden. Eines war sicher: Ein Zurücksetzen der Einstellungen löst das Problem mit Container-Abstürzen.
Warum reicht es nicht aus, Sysctl auf dem Host anzuwenden? Zumindest befindet sich der Container in seinem eigenen dedizierten Netzwerk-Namespace im Container kann vom Host abweichen.
Wie genau werden Sysctl-Einstellungen im Container angewendet? Da unsere Container nicht privilegiert sind, können Sie keine Sysctl-Einstellungen ändern, indem Sie in den Container selbst gehen – Sie haben einfach nicht genügend Rechte. Um Container auszuführen, nutzte unsere Cloud damals Docker (heute ). Die Parameter des neuen Containers wurden über die API an Docker übergeben, inklusive der notwendigen Sysctl-Einstellungen.
Beim Durchsuchen der Versionen stellte sich heraus, dass die Docker-API nicht alle Fehler zurückgab (zumindest in Version 1.10). Als wir versuchten, den Container per „Docker Run“ zu starten, sahen wir endlich etwas:
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.
Der Parameterwert ist ungültig. Aber warum? Und warum ist es nur manchmal nicht gültig? Es stellte sich heraus, dass Docker die Reihenfolge, in der Sysctl-Parameter angewendet werden, nicht garantiert (die neueste getestete Version ist 1.13.1). Daher wurde manchmal versucht, ipfrag_high_thresh auf 256 KB zu setzen, wenn ipfrag_low_thresh noch 3 MB betrug, d. h. die Obergrenze war niedriger als der untere Grenzwert, was zu dem Fehler führte.
Zu diesem Zeitpunkt verwendeten wir bereits unseren eigenen Mechanismus zur Neukonfiguration des Containers nach dem Start (Einfrieren des Containers danach). und Ausführen von Befehlen im Namensraum des Containers über ), und wir haben diesem Teil auch das Schreiben von Sysctl-Parametern hinzugefügt. Das Problem wurde gelöst.
FragmentSmack/SegmentSmack. Erstes Blut 2
Bevor wir Zeit hatten, die Verwendung von Workaround in der Cloud zu verstehen, trafen die ersten seltenen Beschwerden von Benutzern ein. Zu diesem Zeitpunkt waren seit dem Einsatz von Workaround auf den ersten Servern mehrere Wochen vergangen. Die erste Untersuchung ergab, dass Beschwerden gegen einzelne Dienste eingingen, nicht jedoch gegen alle Server dieser Dienste. Das Problem ist erneut äußerst unsicher geworden.
Zunächst haben wir versucht, die Sysctl-Einstellungen zurückzusetzen, aber das hatte keine Wirkung. Auch verschiedene Änderungen an den Server- und Anwendungseinstellungen brachten keinen Erfolg. Ein Neustart half. Neustart für Linux so unnatürlich es auch war, es war ein normaler Zustand für die Arbeit mit Windows Früher funktionierte es. Wir schrieben es einem „Kernel-Fehler“ beim Anwenden neuer Sysctl-Einstellungen zu. Wie naiv von uns…
Drei Wochen später trat das Problem erneut auf. Die Konfiguration dieser Server war recht einfach: Nginx im Proxy/Balancer-Modus. Nicht viel Verkehr. Neuer einleitender Hinweis: Die Zahl der 504-Fehler auf Clients steigt täglich (). Die Grafik zeigt die Anzahl der 504 Fehler pro Tag für diesen Dienst:
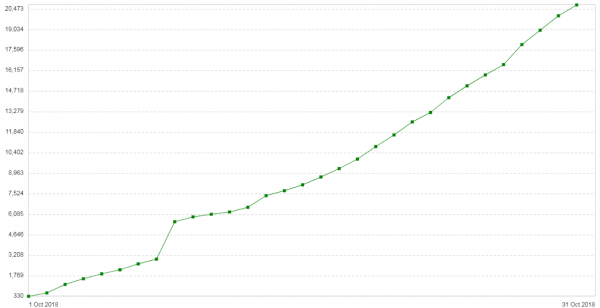
Bei allen Fehlern geht es um dasselbe Backend – also um dasjenige, das sich in der Cloud befindet. Das Speicherverbrauchsdiagramm für Paketfragmente in diesem Backend sah folgendermaßen aus:
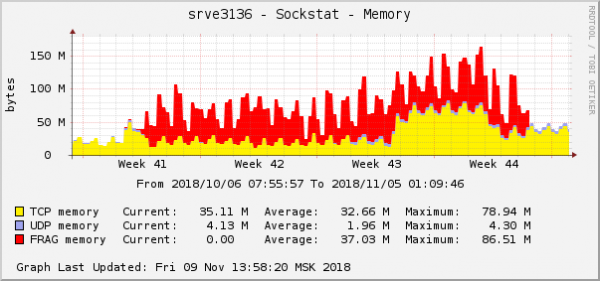
Dies ist eine der offensichtlichsten Erscheinungsformen des Problems in Betriebssystemdiagrammen. In der Cloud wurde gleichzeitig ein weiteres Netzwerkproblem mit den QoS-Einstellungen (Traffic Control) behoben. Auf dem Diagramm des Speicherverbrauchs für Paketfragmente sah es genau gleich aus:
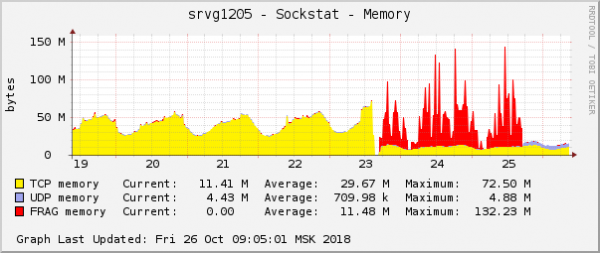
Die Annahme war einfach: Wenn sie in den Diagrammen gleich aussehen, dann haben sie denselben Grund. Darüber hinaus sind Probleme mit diesem Speichertyp äußerst selten.
Der Kern des behobenen Problems bestand darin, dass wir den fq-Paketplaner mit Standardeinstellungen in QoS verwendet haben. Standardmäßig können Sie für eine Verbindung 100 Pakete zur Warteschlange hinzufügen, und einige Verbindungen begannen bei Kanalknappheit, die Warteschlange bis zur Kapazitätsgrenze zu verstopfen. In diesem Fall werden Pakete verworfen. In der tc-Statistik (tc -s qdisc) sieht man das so:
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit
„464545 flow_plimit“ sind die Pakete, die aufgrund der Überschreitung des Warteschlangenlimits einer Verbindung verworfen wurden, und „dropped 464545“ ist die Summe aller verworfenen Pakete dieses Schedulers. Nachdem die Warteschlangenlänge auf 1 erhöht und die Container neu gestartet wurden, trat das Problem nicht mehr auf. Sie können sich zurücklehnen und einen Smoothie trinken.
FragmentSmack/SegmentSmack. Letztes Blut
Zunächst wurde einige Monate nach Bekanntwerden der Kernel-Schwachstellen endlich ein Fix für FragmentSmack veröffentlicht (die Ankündigung im August enthielt lediglich einen Fix für SegmentSmack). Dadurch konnten wir Workaround, das uns erhebliche Probleme bereitet hatte, aufgeben. Wir hatten in der Zwischenzeit bereits einige Server auf den neuen Kernel migriert und mussten nun von vorne beginnen. Warum haben wir den Kernel aktualisiert, ohne auf den FragmentSmack-Fix zu warten? Der Grund ist, dass die Maßnahmen zum Schutz vor diesen Schwachstellen mit der Aktualisierung von Workaround selbst zusammenfielen und sich nahtlos einfügten. CentOS (was sogar noch länger dauert als ein reines Kernel-Update). Außerdem stellt SegmentSmack eine gefährlichere Sicherheitslücke dar, und ein Fix dafür war sofort verfügbar, daher war es ohnehin sinnvoll. Ein reines Kernel-Update hingegen… CentOS Das war uns aufgrund der FragmentSmack-Sicherheitslücke, die während der CentOS Der Fehler in Version 7.5 wurde erst in Version 7.6 behoben, daher mussten wir das Update auf 7.5 stoppen und mit dem Update auf 7.6 von vorne beginnen. Auch das kommt vor.
Zweitens sind seltene Benutzerbeschwerden über Probleme bei uns eingegangen. Jetzt wissen wir bereits mit Sicherheit, dass sie alle mit dem Hochladen von Dateien von Clients auf einige unserer Server zusammenhängen. Darüber hinaus lief nur ein sehr kleiner Teil der gesamten Upload-Masse über diese Server.
Wie wir uns aus der obigen Geschichte erinnern, hat das Zurücksetzen von Sysctl nicht geholfen. Neustart hat geholfen, aber vorübergehend.
Der Verdacht bezüglich Sysctl wurde nicht beseitigt, doch dieses Mal galt es, so viele Informationen wie möglich zu sammeln. Außerdem war es nicht möglich, das Upload-Problem auf dem Client zu reproduzieren, um genauer zu untersuchen, was passierte.
Die Analyse aller verfügbaren Statistiken und Protokolle brachte uns dem Verständnis des Geschehens nicht näher. Es bestand ein akuter Mangel an Fähigkeit, das Problem zu reproduzieren, um einen bestimmten Zusammenhang zu „spüren“. Schließlich gelang es den Entwicklern mithilfe einer speziellen Version der Anwendung, Probleme auf einem Testgerät bei Verbindung über WLAN stabil zu reproduzieren. Dies war ein Durchbruch in der Untersuchung. Der Client stellte eine Verbindung zu Nginx her, das eine Proxy-Verbindung zum Backend herstellte, das unsere Java-Anwendung war.
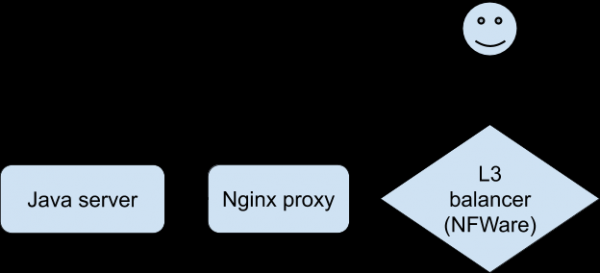
Der Dialog für Probleme sah so aus (behoben auf der Nginx-Proxy-Seite):
- Kunde: Bitte um Informationen zum Herunterladen einer Datei.
- Java-Server: Antwort.
- Kunde: POST mit Datei.
- Java-Server: Fehler.
Gleichzeitig schreibt der Java-Server in das Protokoll, dass 0 Byte Daten vom Client empfangen wurden, und der Nginx-Proxy schreibt, dass die Anfrage mehr als 30 Sekunden gedauert hat (30 Sekunden ist das Timeout der Client-Anwendung). Warum das Timeout und warum 0 Bytes? Aus HTTP-Sicht funktioniert alles wie es sollte, aber der POST mit der Datei scheint aus dem Netzwerk zu verschwinden. Darüber hinaus verschwindet es zwischen dem Client und Nginx. Es ist Zeit, sich mit Tcpdump zu wappnen! Aber zuerst müssen Sie die Netzwerkkonfiguration verstehen. Der Nginx-Proxy befindet sich hinter dem L3-Balancer . Tunneling wird verwendet, um Pakete vom L3-Balancer an den Server zu übermitteln, der seine Header zu den Paketen hinzufügt:
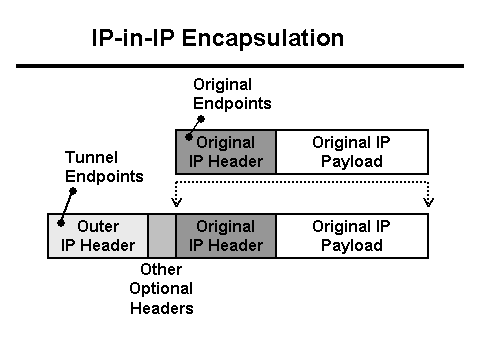
In diesem Fall kommt das Netzwerk in Form von VLAN-getaggtem Datenverkehr zu diesem Server, der den Paketen auch eigene Felder hinzufügt:
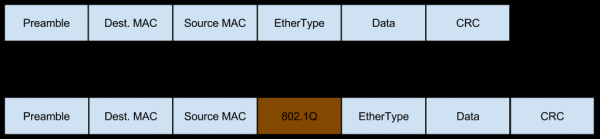
Und dieser Datenverkehr kann auch fragmentiert sein (derselbe kleine Prozentsatz des eingehenden fragmentierten Datenverkehrs, über den wir bei der Bewertung der Risiken durch Workaround gesprochen haben), wodurch sich auch der Inhalt der Header ändert:
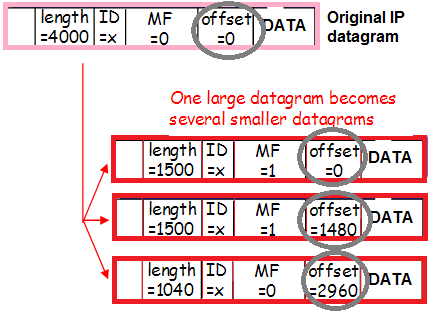
Noch einmal: Pakete werden mit einem Vlan-Tag gekapselt, mit einem Tunnel gekapselt, fragmentiert. Um besser zu verstehen, wie dies geschieht, verfolgen wir die Paketroute vom Client zum Nginx-Proxy.
- Das Paket erreicht den L3-Balancer. Zur korrekten Weiterleitung innerhalb des Rechenzentrums wird das Paket in einem Tunnel gekapselt und an die Netzwerkkarte gesendet.
- Da die Paket- und Tunnelheader nicht in die MTU passen, wird das Paket in Fragmente zerlegt und an das Netzwerk gesendet.
- Der Switch nach dem L3-Balancer fügt beim Empfang eines Pakets ein Vlan-Tag hinzu und sendet es weiter.
- Der Switch vor dem Nginx-Proxy erkennt (anhand der Porteinstellungen), dass der Server ein Vlan-gekapseltes Paket erwartet, und sendet es daher unverändert, ohne das Vlan-Tag zu entfernen.
- Linux Er erhält Bruchstücke einzelner Pakete und klebt diese zu einem großen Paket zusammen.
- Als nächstes erreicht das Paket die VLAN-Schnittstelle, wo die erste Schicht entfernt wird – die VLAN-Kapselung.
- Dann Linux sendet es an die Tunnelschnittstelle, wo eine weitere Schicht entfernt wird - die Tunnelkapselung.
Die Schwierigkeit besteht darin, dies alles als Parameter an tcpdump zu übergeben.
Beginnen wir am Ende: Gibt es saubere (ohne unnötige Header) IP-Pakete von Clients, bei denen die VLAN- und Tunnelkapselung entfernt wurde?
tcpdump host <ip клиента>
Nein, auf dem Server befanden sich keine derartigen Pakete. Das Problem muss also schon früher da sein. Gibt es Pakete, bei denen nur die VLAN-Kapselung entfernt wurde?
tcpdump ip[32:4]=0xx390x2xx
0xx390x2xx ist die Client-IP-Adresse im Hexadezimalformat.
32:4 – Adresse und Länge des Feldes, in das die SCR-IP im Tunnelpaket geschrieben wird.
Die Feldadresse musste mit roher Gewalt ausgewählt werden, da im Internet etwa 40, 44, 50, 54 geschrieben werden, dort aber keine IP-Adresse vorhanden war. Sie können sich auch eines der Pakete im Hexadezimalformat ansehen (den Parameter -xx oder -XX in tcpdump) und die Ihnen bekannte IP-Adresse berechnen.
Gibt es Paketfragmente ohne entfernte VLAN- und Tunnel-Kapselung?
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
Dieser Zauber zeigt uns alle Fragmente, auch das letzte. Wahrscheinlich kann das Gleiche auch nach IP gefiltert werden, aber ich habe es nicht versucht, da es nicht sehr viele solcher Pakete gibt und die benötigten Pakete im allgemeinen Fluss leicht zu finden waren. Hier sind sie:
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0, flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....jEx
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if..MM.*........
14:02:58.471103 In 00:de:ff:1a:94:11 Ethertyp IPv4 (0x0800), Länge 62: (tos 0x0, ttl 63, ID 53652, Offset 1480, Flags [keine], Proto-IPIP (4), Länge 40)
11.11.11.11 > 22.22.22.22: ip-proto-4
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ..........A....
0x0010: 4500 0028 d194 00b9 3f04 faf6 2x76 385x E..(....?....f8}
0x0020: 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .faE...D-,.!...C
0x0030: x978 e91d x9b0 d608 0000 0000 0000 7c31 .x...........|Q
0x0040: 881d c4b6 0000 0000 0000 0000 0000 .............
Dabei handelt es sich um zwei Fragmente eines Pakets (gleiche ID 53652) mit einem Foto (das Wort Exif ist im ersten Paket sichtbar). Aufgrund der Tatsache, dass es Pakete auf dieser Ebene gibt, jedoch nicht in der zusammengeführten Form in den Dumps, liegt das Problem eindeutig bei der Assembly. Endlich gibt es dafür dokumentarische Beweise!
Der Paketdecoder zeigte keine Probleme, die den Build verhindern würden. Habe es hier versucht: . Wenn Sie zunächst versuchen, dort etwas unterzubringen, gefällt dem Decoder das Paketformat nicht. Es stellte sich heraus, dass es zwischen Scmac und Ethertype zwei zusätzliche Oktette gab (die nichts mit Fragmentinformationen zu tun hatten). Nach dem Entfernen begann der Decoder zu arbeiten. Es zeigte sich jedoch keine Probleme.
Was auch immer man sagen mag, außer diesen Sysctl wurde nichts anderes gefunden. Es blieb nur noch, einen Weg zu finden, problematische Server zu identifizieren, um das Ausmaß zu verstehen und über weitere Maßnahmen zu entscheiden. Der gesuchte Zähler wurde schnell genug gefunden:
netstat -s | grep "packet reassembles failed”
Es ist auch in snmpd unter OID=1.3.6.1.2.1.4.31.1.1.16.1 ().
„Die Anzahl der vom IP-Reassembly-Algorithmus erkannten Fehler (aus welchem Grund auch immer: Zeitüberschreitung, Fehler usw.).“
In der Gruppe von Servern, auf denen das Problem untersucht wurde, stieg dieser Zähler auf zwei schneller, auf zwei langsamer und auf zwei weiteren überhaupt nicht. Ein Vergleich der Dynamik dieses Zählers mit der Dynamik von HTTP-Fehlern auf dem Java-Server ergab einen Zusammenhang. Das heißt, der Zähler könnte überwacht werden.
Es ist sehr wichtig, einen zuverlässigen Indikator für Probleme zu haben, damit Sie genau bestimmen können, ob ein Rollback von Sysctl hilfreich ist, da wir aus der vorherigen Geschichte wissen, dass dies nicht sofort aus der Anwendung heraus verstanden werden kann. Dieser Indikator würde es uns ermöglichen, alle Problembereiche in der Produktion zu identifizieren, bevor Benutzer sie entdecken.
Nach dem Rollback von Sysctl wurden die Überwachungsfehler gestoppt, sodass die Ursache der Probleme nachgewiesen wurde und auch die Tatsache, dass das Rollback hilft.
Wir haben die Fragmentierungseinstellungen auf anderen Servern zurückgesetzt, wo die neue Überwachung ins Spiel kam, und irgendwo haben wir sogar noch mehr Speicher für Fragmente zugewiesen als zuvor die Standardeinstellung (das waren UDP-Statistiken, deren teilweiser Verlust vor dem allgemeinen Hintergrund nicht auffiel). .
Die wichtigsten Fragen
Warum sind Pakete auf unserem L3-Balancer fragmentiert? Die meisten Pakete, die von Benutzern an Balancer ankommen, sind SYN und ACK. Die Größe dieser Pakete ist klein. Da der Anteil solcher Pakete jedoch sehr groß ist, ist uns vor diesem Hintergrund das Vorhandensein großer Pakete, die zu fragmentieren begannen, nicht aufgefallen.
Der Grund war ein fehlerhaftes Konfigurationsskript auf Servern mit VLAN-Schnittstellen (damals gab es in der Produktion nur sehr wenige Server mit markiertem Datenverkehr). Advmss ermöglicht es uns, dem Client die Information zu übermitteln, dass Pakete in unsere Richtung kleiner sein sollten, damit sie nach dem Anhängen von Tunnel-Headern nicht fragmentiert werden müssen.
Warum hat das Sysctl-Rollback nicht geholfen, der Neustart jedoch? Durch das Zurücksetzen von Sysctl wurde die für das Zusammenführen von Paketen verfügbare Speichermenge geändert. Gleichzeitig führte offenbar gerade die Tatsache des Speicherüberlaufs für Fragmente zu einer Verlangsamung der Verbindungen, was dazu führte, dass Fragmente lange Zeit in der Warteschlange verzögert wurden. Das heißt, der Prozess verlief in Zyklen.
Durch den Neustart wurde der Speicher gelöscht und alles war wieder in Ordnung.
Konnte auf Workaround verzichtet werden? Ja, aber es besteht ein hohes Risiko, dass Benutzer im Falle eines Angriffs ohne Service bleiben. Natürlich führte der Einsatz von Workaround zu verschiedenen Problemen, einschließlich der Verlangsamung eines der Dienste für die Benutzer, aber dennoch sind wir der Meinung, dass die Maßnahmen gerechtfertigt waren.
Vielen Dank an Andrey Timofeev () für die Unterstützung bei der Durchführung der Ermittlungen sowie Alexey Krenev () – für die gewaltige Aufgabe der Aktualisierung Centos und Serverkerne. In diesem Fall musste der Prozess mehrmals neu gestartet werden, was dazu führte, dass er viele Monate dauerte.
Source: habr.com
