

Zu Beginn stand die Technologie, bekannt als BPF. Wir haben sie in , dem alten Artikel dieser Reihe, betrachtet. Im Jahr 2013 wurde durch die Bemühungen von Alexei Starovoitov und Daniel Borkman eine verbesserte Version entwickelt und in den Linux-Kernel integriert, die für moderne 64-Bit-Maschinen optimiert ist. Diese neue Technologie trug kurzfristig den Namen Internal BPF, wurde dann in Extended BPF umbenannt und wird heute einfach als BPF bezeichnet.
Vereinfacht gesagt, ermöglicht BPF die Ausführung beliebigen vom Benutzer bereitgestellten Codes im Linux-Kernel. Diese neue Architektur war so erfolgreich, dass wir noch eine Handvoll Artikel benötigen werden, um all ihre Anwendungen zu beschreiben. (Das Einzige, was die Entwickler, wie Sie weiter unten sehen können, nicht geschafft haben, ist die Erstellung eines anständigen Logos.)
In diesem Artikel wird die Struktur der BPF-VM, die Kernel-Interfaces zur Arbeit mit BPF, die Entwicklungswerkzeuge sowie eine kurze, sehr kurze Übersicht über die vorhandenen Möglichkeiten beschrieben, d.h. alles, was wir benötigen, um die praktischen Anwendungen von BPF näher zu erforschen.
Zusammenfassung des Artikels
Zunächst betrachten wir die BPF-Architektur aus der Vogelperspektive und kennzeichnen die wesentlichen Komponenten.
Nachdem wir nun ein Gesamtbild der Architektur haben, beschreiben wir die Struktur der BPF-VM.
In diesem Abschnitt werfen wir einen genaueren Blick auf den Lebenszyklus von BPF-Objekten – Programmen und Mappings.
Mit dem bisherigen Wissen über das System betrachten wir schließlich, wie man Objekte aus dem Benutzerspeicher mit einem speziellen Systemaufruf erstellt und verwaltet – bpf(2).
Programme mit Systemaufrufen zu schreiben, ist natürlich möglich, aber kompliziert. Für ein realistischeres Szenario wurde von Kernel-Programmierern eine Bibliothek entwickelt, libbpf. Wir werden ein einfaches Gerüst für eine BPF-Anwendung erstellen, das wir in den folgenden Beispielen verwenden werden.
Hier erfahren wir, wie BPF-Programme auf die Kernel-Hilfsfunktionen zugreifen können – ein Werkzeug, das zusammen mit Maps die Möglichkeiten des neuen BPF im Vergleich zum klassischen BPF erheblich erweitert.
Bis zu diesem Punkt werden wir genug wissen, um zu verstehen, wie Programme, die Maps verwenden, erstellt werden können. Und wir werden sogar einen kurzen Blick auf den mächtigen Verifier werfen.
Ein Abschnitt, der beschreibt, wie man die benötigten Werkzeuge und den Kernel für Experimente zusammenstellt.
Am Ende des Artikels finden diejenigen, die bis dorthin gelesen haben, motivierende Worte und eine kurze Beschreibung dessen, was in den nächsten Artikeln zu erwarten ist. Zudem werden wir einige Links zur eigenständigen Vertiefung auflisten für diejenigen, die nicht darauf warten wollen oder können.
Einführung in die BPF-Architektur.
Bevor wir die Architektur von BPF betrachten, möchten wir ein letztes Mal auf , hinweisen, das als Antwort auf die Einführung von RISC-Maschinen entwickelt wurde und das Problem der effizienten Paketfilterung löste. Die Architektur war so erfolgreich, dass sie, geboren in den turbulenten Neunzigern im Berkeley UNIX, auf die meisten bestehenden Betriebssysteme portiert wurde, bis in die verrückten Zwanziger überlebte und weiterhin neue Anwendungen findet.
Das neue BPF wurde als Antwort auf die weitverbreitete Nutzung von 64-Bit-Maschinen, Cloud-Diensten und den gestiegenen Anforderungen an Werkzeuge zur Erstellung von SDN (Osoftware-ddefined nnetworking) entwickelt. Entwickelt von Netzwerktechnikern als verbesserte Alternative zum klassischen BPF fand das neue BPF bereits nach sechs Monaten Anwendung in der herausfordernden Aufgabe der Linux-Systemverfolgung. Und jetzt, sechs Jahre nach seiner Einführung, benötigen wir einen ganzen, nächsten Artikel, nur um die verschiedenen Programmtypen aufzulisten.
VeSyoLe KaRtInKi
Im Wesentlichen ist BPF eine Sandbox-Virtual Machine, die es ermöglicht, "beliebigen" Code im Kernel-Speicher auszuführen, ohne die Sicherheit zu gefährden. BPF-Programme werden im Benutzerspeicher erstellt, ins Kernel geladen und mit einer Ereignisquelle verbunden. Ein Ereignis kann beispielsweise die Zustellung eines Pakets an eine Netzwerkschnittstelle oder die Ausführung einer Kernel-Funktion sein. Im Falle eines Pakets hat das BPF-Programm Zugriff auf die Paketdaten und -metadaten (zum Lesen und möglicherweise auch zum Schreiben, abhängig vom Programmtipo); im Falle der Ausführung einer Kernel-Funktion stehen die Funktionsargumente zur Verfügung, einschließlich Zeigern auf den Kernel-Speicher usw.
Lassen Sie uns diesen Prozess im Detail betrachten. Zunächst wollen wir das erste unterscheidende Merkmal des klassischen BPF erläutern, dessen Programme in Assemblersprache geschrieben wurden. In der neuen Version wurde die Architektur so erweitert, dass Programme in Hochsprachen, insbesondere in C, geschrieben werden können. Zu diesem Zweck wurde ein Backend für llvm entwickelt, das es ermöglicht, Bytecode für die BPF-Architektur zu generieren.

Die BPF-Architektur wurde entwickelt, um auf modernen Maschinen effizient ausgeführt zu werden. Damit dies in der Praxis funktioniert, wird der BPF-B Bytecode nach der Eingabe in den Kernel mithilfe eines als JIT-Compiler bezeichneten Komponenten in nativen Code übersetzt.Just In Time). Wie Sie sich vielleicht erinnern, wurde im klassischen BPF das Programm atomar in den Kernel geladen und mit der Ereignisquelle in einem einzigen Systemaufruf verbunden. In der neuen Architektur geschieht dies in zwei Schritten: Zuerst wird der Code über einen Systemaufruf in den Kernel geladen bpf(2), und dann, zu einem späteren Zeitpunkt, wird das Programm, je nach Art, über verschiedene Mechanismen an die Ereignisquelle angeschlossen (attaches).
Hier könnte der Leser sich fragen: War das so möglich? Wie wird die Sicherheit der Ausführung solchen Codes gewährleistet? Die Sicherheit der Ausführung wird durch den Ladeprozess der BPF-Programme sichergestellt, der als Verifier bezeichnet wird (in Englisch: verifier, und ich werde im Folgenden das englische Wort verwenden):

Der Verifier ist ein statisches Analysewerkzeug, das sicherstellt, dass ein Programm den normalen Betrieb des Kernels nicht stört. Das bedeutet jedoch nicht, dass das Programm nicht in das System eingreifen kann – je nach Typ können BPF-Programme Teile des Kernel-Speichers lesen und überschreiben, Rückgabewerte von Funktionen verändern, Pakete modifizieren, ergänzen, umschreiben und sogar Netzpakete weiterleiten. Der Verifier stellt sicher, dass die Ausführung eines BPF-Programms den Kernel nicht zum Absturz bringt und dass Programme, die gemäß den Regeln Schreibzugriff auf bestimmte Daten haben, wie z. B. die Daten eines ausgehenden Pakets, den Kernel-Speicher nicht außerhalb des Pakets überschreiben können. Wir werden den Verifier im entsprechenden Abschnitt näher betrachten, nachdem wir alle anderen Komponenten von BPF kennengelernt haben.
Was haben wir bis jetzt gelernt? Der Benutzer schreibt ein Programm in C, das über einen Systemaufruf in den Kernel geladen wird. bpf(2), wo sie durch den Verifier überprüft und in nativen Bytecode übersetzt wird. Anschließend verbindet derselbe oder ein anderer Benutzer das Programm mit der Ereignisquelle, und es beginnt, ausgeführt zu werden. Die Trennung von Laden und Verbinden erfolgt aus mehreren Gründen. Erstens ist der Start des Verifiers relativ kostspielig, und beim mehrmaligen Laden desselben Programms vergeuden wir Computerressourcen. Zweitens hängt die Art und Weise, wie das Programm verbunden wird, von seinem Typ ab, und ein „universelles“ Interface, das vor einem Jahr entwickelt wurde, könnte für neue Programmtypen ungeeignet sein. (Auch wenn jetzt, da die Architektur reifer wird, die Idee besteht, dieses Interface auf einer höheren Ebene zu vereinheitlichen. libbpf.)
Aufmerksame Leser könnten bemerken, dass wir mit den Bildern noch nicht fertig sind. Tatsächlich erklärt das oben Gesagte nicht, wie BPF die Situation im Vergleich zu klassischem BPF grundlegend verändert. Zwei Neuerungen, die den Anwendungsbereich erheblich erweitern, sind die Möglichkeit, gemeinsam genutzten Speicher zu verwenden und die Kernel-Hilfsfunktionen (Kernel Helpers). Im BPF wird der gemeinsam genutzte Speicher durch sogenannte Maps realisiert – gemeinsam genutzte Datenstrukturen mit einer spezifischen API. Der Name stammt vermutlich daher, dass der erste Typ von Map eine Hash-Tabelle war. Im weiteren Verlauf kamen Arrays, lokale (per-CPU) Hash-Tabellen und lokale Arrays, Suchbäume, Maps mit Zeigern auf BPF-Programme und vieles mehr hinzu. Uns interessiert hier insbesondere, dass BPF-Programme nun die Fähigkeit besitzen, Zustände zwischen Aufrufen zu speichern und diese mit anderen Programmen sowie dem Benutzerspeicher zu teilen.
Der Zugang zu Maps erfolgt aus Benutzerprozessen heraus über einen Systemaufruf. bpf(2), und aus BPF-Programmen, die im Kernel laufen – mithilfe von Hilfsfunktionen. Darüber hinaus gibt es Hilfsfunktionen nicht nur zur Arbeit mit Maps, sondern auch zum Zugriff auf andere Möglichkeiten des Kernels. Beispielsweise können BPF-Programme Hilfsfunktionen verwenden, um Pakete an andere Schnittstellen umzuleiten, Ereignisse des Perf-Subsystems zu erzeugen, auf Kernelstrukturen zuzugreifen usw.

Insgesamt ermöglicht BPF das Laden beliebigen, d.h. vom Verifier geprüften, Benutzercodes in den Kernelraum. Dieser Code kann den Status zwischen den Aufrufen speichern und Daten mit dem Benutzerraum austauschen sowie auf die für diesen Programmmtyp erlaubten Kernel-Subsysteme zugreifen.
Das ähnelt bereits den Funktionen, die von Kernel-Modulen bereitgestellt werden, wobei BPF einige Vorteile bietet (natürlich können nur ähnliche Anwendungen verglichen werden, wie etwa die Systemverfolgung – es ist nicht möglich, einen beliebigen Treiber mit BPF zu schreiben). Man kann einen niedrigeren Eintrittsbarriere feststellen (einige Werkzeuge, die BPF nutzen, setzen nicht voraus, dass der Benutzer über Kernel-Programmierkenntnisse verfügt, geschweige denn über allgemeine Programmierfähigkeiten), die Sicherheit zur Laufzeit (heben Sie die Hand in den Kommentaren, wenn Sie beim Schreiben oder Testen von Modulen das System nicht destabilisiert haben), Atomarität – beim Neuladen von Modulen gibt es Ausfallzeiten, während das BPF-Subsystem garantiert, dass kein Ereignis verpasst wird (um fair zu sein, gilt dies nicht für alle Arten von BPF-Programmen).
Die Verfügbarkeit solcher Möglichkeiten macht BPF zu einem universellen Werkzeug zur Erweiterung des Kernels, was durch die Praxis belegt wird: Immer mehr Programmtypen werden in BPF integriert, immer mehr große Unternehmen setzen BPF auf produktiven Servern 24×7 ein und immer mehr Startups bauen ihr Geschäft auf Lösungen auf, die auf BPF basieren. BPF findet überall Anwendung: bei der DDoS-Abwehr, dem Aufbau von SDN (zum Beispiel der Implementierung von Netzwerken für Kubernetes), als primäres Werkzeug zur Systemverfolgung und Statistiksammlung, sowie in Intrusion-Detection-Systemen und Sandbox-Systemen usw.
Lassen Sie uns den Überblicksbereich des Artikels beenden und uns die virtuelle Maschine und das BPF-Ökosystem genauer ansehen.
Ausschnitt: Hilfsprogramme
Um die Beispiele aus den folgenden Abschnitten ausführen zu können, benötigen Sie möglicherweise einige Hilfsprogramme, mindestens llvm/clang mit BPF-Unterstützung und bpftool. Im Abschnitt Sie können die Anleitungen zum Kompilieren der Hilfsprogramme sowie Ihres Kernels lesen. Dieser Abschnitt wurde weiter unten platziert, um den Fluss unseres Textes nicht zu stören.
Register und BPF-VM-Befehlssatz
Die Architektur und das BPF-Befehlsystem wurden mit dem Gedanken entwickelt, dass Programme in der Programmiersprache C geschrieben werden und nach dem Laden in den Kernel in nativen Code übersetzt werden. Daher wurde die Anzahl der Register und die Befehlssätze unter Berücksichtigung der mathematischen Schnittmenge der Möglichkeiten moderner Maschinen ausgewählt. Darüber hinaus wurden verschiedenen Einschränkungen auferlegt, beispielsweise war es bis vor kurzem nicht möglich, Schleifen und Unterprogramme zu schreiben, und die Anzahl der Anweisungen war auf 4096 beschränkt (jetzt können privilegierte Programme bis zu einer Million Anweisungen laden).
Im BPF stehen insgesamt elf benutzerzugängliche 64-Bit-Register zur Verfügung. r0—r10 und einen Befehlszähler (program counter). Das Register r10 enthält einen Zeiger auf den Stack (frame pointer) und ist nur schreibgeschützt. Während der Ausführung haben die Programme Zugriff auf einen 512 Byte großen Stack und eine unbegrenzte Menge an gemeinsam genutztem Speicher in Form von Maps.
BPF-Programme dürfen je nach Programmart eine bestimmte Gruppe von Funktionen (Kernel-Helfer) ausführen und seit Kurzem auch reguläre Funktionen. Jede aufgerufene Funktion kann bis zu fünf Argumente annehmen, die in Registern übergeben werden. r1—r5, und der Rückgabewert wird in r0. Es wird garantiert, dass der Inhalt der Register nach der Rückgabe aus der Funktion unverändert bleibt. r6—r9 wird sich nicht ändern.
Für die effiziente Übersetzung von Programmen werden die Register r0—r11 für alle unterstützten Architekturen eindeutig auf die tatsächlichen Register unter Berücksichtigung der ABI-Spezifika der aktuellen Architektur abgebildet. Zum Beispiel werden für x86_64 die Register r1—r5, die zur Übergabe von Funktionsparametern verwendet werden, auf rdi, rsi, rdx, rcx, r8, welche für die Übergabe von Parametern in Funktionen bei x86_64verwendet werden. Zum Beispiel wird der Code links in den folgenden Code rechts übersetzt:
1: (b7) r1 = 1 mov $0x1,%rdi
2: (b7) r2 = 2 mov $0x2,%rsi
3: (b7) r3 = 3 mov $0x3,%rdx
4: (b7) r4 = 4 mov $0x4,%rcx
5: (b7) r5 = 5 mov $0x5,%r8
6: (85) call pc+1 callq 0x0000000000001ee8Das Register r0 wird ebenfalls verwendet, um das Ergebnis der Programmausführung zurückzugeben, und im Register r1 In das Programm wird ein Zeiger auf den Kontext übergeben – je nach Art des Programms kann dies beispielsweise eine Struktur sein (für XDP) oder eine Struktur (für verschiedene Netzwerkprogramme) oder eine Struktur (für verschiedene Typen von Tracing-Programmen) usw.
Wir hatten also eine Gruppe von Registern, Kernel-Helfern, einen Stack, einen Zeiger auf den Kontext und gemeinsamen Speicher in Form von Maps. Es war zwar nicht unbedingt notwendig auf der Reise, aber…
Lassen Sie uns die Beschreibung fortsetzen und das Befehlssystem zur Arbeit mit diesen Objekten vorstellen. Alle () BPF-Anweisungen haben eine feste Größe von 64 Bit. Wenn Sie sich eine Anweisung auf einer 64-Bit Big Endian Maschine ansehen, sehen Sie
![]()
Hier Code — das ist die Kodierung der Anweisung, Dst/Src — das sind die Kodierungen für Empfang und Quelle, jeweils, Off — ein 16-Bit vorzeichenbehafteter Offset, und Imm — das ist eine 32-Bit vorzeichenbehaftete Ganzzahl, die in einigen Anweisungen verwendet wird (analog zur Konstante K aus cBPF). Die Kodierung Code hat einen von zwei Typen:
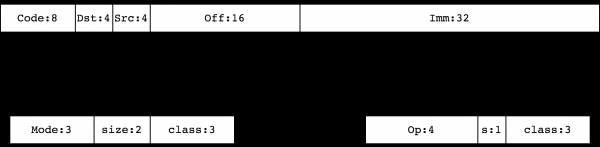
Die Klassen der Anweisungen 0, 1, 2, 3 definieren Anweisungen zur Arbeit mit Speicher. Sie , BPF_LD, BPF_LDX, BPF_ST, BPF_STX, entsprechend. Die Klassen 4, 7 (BPF_ALU, BPF_ALU64) bilden eine Sammlung von ALU-Anweisungen. Die Klassen 5, 6 (BPF_JMP, BPF_JMP32) enthalten Anweisungen zum Übergang.
Der weitere Plan zur Erkundung des BPF-Befehlsystems lautet wie folgt: Anstatt alle Anweisungen und deren Parameter detailliert aufzulisten, werden wir in diesem Abschnitt einige Beispiele durchgehen. Dadurch wird deutlich, wie die Anweisungen tatsächlich aufgebaut sind und wie man manuell jede Binärdatei für BPF disassemblieren kann. Zur Vertiefung des Themas werden wir im weiteren Verlauf auf individuelle Anweisungen in den Abschnitten über den Verifier, den JIT-Compiler, die Übersetzung klassischer BPF sowie bei der Untersuchung von Maps, Funktionsaufrufen usw. stoßen.
Wenn wir über individuelle Anweisungen sprechen, beziehen wir uns auf die Kernel-Dateien und , in denen die numerischen Codes der BPF-Anweisungen definiert sind. Bei der selbstständigen Erkundung der Architektur und/oder der Analyse von Binärdateien können Sie die Semantik in den folgenden, nach Schwierigkeit sortierten Quellen finden: , , und natürlich im Quellcode von Linux – Verifier, JIT und BPF-Interpreter.
Beispiel: BPF im Kopf disassemblieren
Lassen Sie uns ein Beispiel betrachten, in dem wir das Programm readelf-example.c und schauen wir uns das resultierende Binary an. Wir werden den ursprünglichen Inhalt aufdecken readelf-example.c unten, nachdem wir seine Logik aus den Binärcodes wiederhergestellt haben:
$ clang -target bpf -c readelf-example.c -o readelf-example.o -O2
$ llvm-readelf -x .text readelf-example.o
Hexdump des Abschnitts '.text':
0x00000000 b7000000 01000000 15010100 00000000 ................
0x00000010 b7000000 02000000 95000000 00000000 ................Die erste Spalte in der Ausgabe readelf — ist der Einzug und unser Programm besteht somit aus vier Befehlen:
Code Dst Src Off Imm
b7 0 0 0000 01000000
15 0 1 0100 00000000
b7 0 0 0000 02000000
95 0 0 0000 00000000Die Opcode sind gleich b7, 15, b7 und 95. Denken wir daran, dass die drei niedrigsten Bits die Klasse der Anweisung darstellen. In unserem Fall ist das vierte Bit bei allen Anweisungen leer, daher sind die Klassen der Anweisungen gleich, nämlich 7, 5, 7, 5. Klasse 7 ist BPF_ALU64, und 5 ist BPF_JMP. Für beide Klassen ist das Format der Anweisung identisch (siehe oben) und wir können unser Programm so umschreiben (nebenbei die anderen Spalten in menschlicher Form umschreiben):
Op S Klasse Dst Src Off Imm
b 0 ALU64 0 0 0 1
1 0 JMP 0 1 1 0
b 0 ALU64 0 0 0 2
9 0 JMP 0 0 0 0Operation b der Klasse ALU64 — ist . Es weist den Wert des Quellregisters dem Zielregister zu. Wenn das Bit gesetzt ist s (source), der Wert wird aus dem Quellregister genommen, und wenn, wie in unserem Fall, es nicht gesetzt ist, wird der Wert aus dem Feld genommen Imm. Auf diese Weise führen wir in den ersten und dritten Anweisungen die Operation aus r0 = Imm. Darüber hinaus ist die Operation der Klasse JMP — (Sprung, wenn gleich). In unserem Fall, da das Bit O gleich null ist, vergleicht sie den Wert des Quellregisters mit dem Feld Imm. Wenn die Werte übereinstimmen, erfolgt der Sprung zu PC + Off, wobei PC, der bekanntlich die Adresse der nächsten Anweisung enthält. Schließlich ist die Operation der Klasse JMP — . Diese Anweisung beendet das Programm und gibt an den Kernel zurück r0. Fügen wir unserer Tabelle eine neue Spalte hinzu:
Op S Class Dst Src Off Imm Disassm
MOV 0 ALU64 0 0 0 1 r0 = 1
JEQ 0 JMP 0 1 1 0 if (r1 == 0) goto pc+1
MOV 0 ALU64 0 0 0 2 r0 = 2
EXIT 0 JMP 0 0 0 0 exitWir können dies in einer handlicheren Form umschreiben:
r0 = 1
if (r1 == 0) goto END
r0 = 2
END:
exitWenn wir uns erinnern, dass im Register r1 der Programmzeiger auf den Kontext vom Kernel übergeben wird, während im Register r0 der Wert an den Kernel zurückgegeben wird, können wir sehen, dass, wenn der Zeiger auf den Kontext gleich null ist, wir 1 zurückgeben, andernfalls 2. Lassen Sie uns überprüfen, ob wir recht haben, indem wir den Quellcode ansehen:
$ cat readelf-example.c
int foo(void *ctx)
{
return ctx ? 2 : 1;
}Ja, das ist ein sinnloses Programm, aber es wird in nur vier einfache Anweisungen übersetzt.
Beispiel-Ausnahme: 16-Byte-Anweisung
Früher haben wir erwähnt, dass einige Anweisungen mehr als 64 Bit benötigen. Dies gilt beispielsweise für die Anweisung lddw (Code = 0x18 = | | ) — lädt ein Doppelwort aus den Feldern in ein Register. ImmDas Problem ist, dass Imm eine Größe von 32 hat, und ein Doppelwort ist 64 Bit, daher kann man ein 64-Bit-Immidiatwert nicht in einer 64-Bit-Anweisung in ein Register laden. Dafür werden zwei benachbarte Anweisungen verwendet, um den zweiten Teil des 64-Bit-Wertes im Feld zu speichern. Imm. Beispiel:
$ cat x64.c
long foo(void *ctx)
{
return 0x11223344aabbccdd;
}
$ clang -target bpf -c x64.c -o x64.o -O2
$ llvm-readelf -x .text x64.o
Hex-Dump des Abschnitts '.text':
0x00000000 18000000 ddccbbaa 00000000 44332211 ............D3".
0x00000010 95000000 00000000 ........Es gibt insgesamt nur zwei Anweisungen im binären Programm:
Binary Disassm
18000000 ddccbbaa 00000000 44332211 r0 = Imm[0]|Imm[1]
95000000 00000000 exitWir werden die Anweisung noch begegnen lddw, wenn wir über Relokationen und die Arbeit mit Maps sprechen.
Beispiel: Disassemblierung von BPF mit Standardwerkzeugen
Wir haben also gelernt, binäre BPF-Codes zu lesen und sind bereit, jede Anweisung zu analysieren, falls nötig. Allerdings ist es in der Praxis bequemer und schneller, Programme mit Standardwerkzeugen zu disassemblieren, zum Beispiel:
$ llvm-objdump -d x64.o
Disassemblierung des Abschnitts .text:
0000000000000000 :
0: 18 00 00 00 dd cc bb aa 00 00 00 00 44 33 22 11 r0 = 1234605617868164317 ll
2: 95 00 00 00 00 00 00 00 exitLebenszyklus von BPF-Objekten, das bpffs-Dateisystem
(Einige Einzelheiten, die in diesem Abschnitt beschrieben werden, habe ich zum ersten Mal von Alexei Starovoitov bei .)
BPF-Objekte – Programme und Maps – werden aus dem Benutzermodus mit den Befehlen BPF_PROG_LOAD und BPF_MAP_CREATE des Systemaufrufs erstellt, und wir werden im nächsten Abschnitt darüber sprechen, wie genau das geschieht. Dabei werden Datenstrukturen im Kernel erstellt, und für jede von ihnen bpf(2), wir werden im nächsten Abschnitt darüber sprechen, wie genau das geschieht. Dabei werden die Kern-Datenstrukturen erstellt und für jede von ihnen refcount (Referenzzählung) wird auf eins gesetzt, während der Benutzer einen Dateideskriptor erhält, der auf das Objekt verweist. Nach dem Schließen des Deskriptors refcount wird der Zähler des Objekts um eins verringert, und wenn er null erreicht, wird das Objekt zerstört.
Wenn das Programm Maps verwendet, dann refcount Die Anzahl dieser Mappe erhöht sich um eins, nachdem das Programm geladen wurde, d.h. ihre Dateihandles können aus dem Benutzerprozess geschlossen werden, während dies refcount nicht null wird:
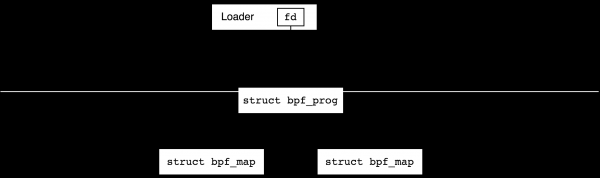
Nach dem erfolgreichen Laden des Programms verbinden wir es normalerweise mit einem Ereignis-Generator. Zum Beispiel können wir es an das Netzwerk-Interface anschließen, um eingehende Pakete zu verarbeiten oder es mit einem Tracepoint im Kernel zu verbinden. In diesem Moment erhöht sich auch der Referenzzähler um eins, und wir können das Dateihandle im Bootprogramm schließen.
Was passiert, wenn wir jetzt den Bootloader abschließen? Das hängt vom Typ des Ereignisgenerators (Hook) ab. Alle Netzwerk-Hooks bestehen weiter nach dem Abschluss des Bootloaders, diese werden als globale Hooks bezeichnet. Programme zur Tracierung hingegen werden nach Beendigung des Prozesses, der sie erstellt hat, freigegeben (und werden daher als lokal bezeichnet, da sie "local to the process" sind). Technisch gesehen haben lokale Hooks stets den entsprechenden Dateideskriptor im Benutzerspeicher und werden beim Schließen des Prozesses geschlossen, globale jedoch nicht. Im nächsten Bild versuche ich mit roten Kreuzen zu verdeutlichen, wie die Beendigung des Bootloader-Programms die Lebensdauer von Objekten in Bezug auf lokale und globale Hooks beeinflusst.
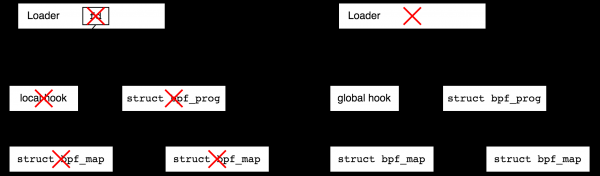
Warum gibt es eine Trennung zwischen lokalen und globalen Hooks? Der Start bestimmter Arten von Netzwerkprogrammen macht auch ohne Userspace Sinn. Stellen Sie sich beispielsweise DDoS-Schutz vor – der Bootloader schreibt Regeln und verbindet ein BPF-Programm mit dem Netzwerkinterface, danach kann der Bootloader beendet werden. Auf der anderen Seite stellen Sie sich ein Debugging-Tool vor, das Sie in zehn Minuten zusammengeschrieben haben – nach dessen Abschluss möchten Sie, dass im System kein Müll zurückbleibt, und lokale Hooks gewährleisten das.
Stellen Sie sich vor, Sie möchten sich mit einem Tracepoint im Kernel verbinden und über viele Jahre Statistiken sammeln. In diesem Fall möchten Sie den Benutzerteil beenden und gelegentlich zur Statistiksammlung zurückkehren. Diese Möglichkeit bietet das BPF-Dateisystem. Es handelt sich um ein Pseudo-Dateisystem, das nur im Speicher existiert und es ermöglicht, Dateien zu erstellen, die auf BPF-Objekte verweisen und somit die Anzahl der Objekte erhöhen. refcount Nachdem der Bootloader die Arbeit beendet hat, bleiben die von ihm erstellten Objekte aktiv.
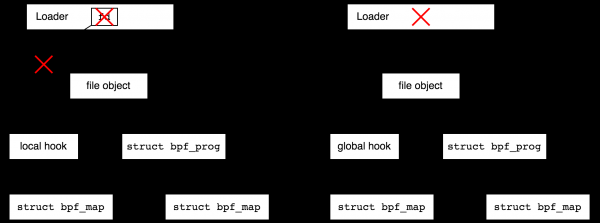
Die Erstellung von Dateien im bpffs, die auf BPF-Objekte verweisen, wird als „Pinning“ bezeichnet (wie in der folgenden Aussage: „Der Prozess kann ein BPF-Programm oder -Karte pinnen“). Die Erstellung von Dateispeicherobjekten für BPF-Objekte ist nicht nur sinnvoll, um die Lebensdauer lokaler Objekte zu verlängern, sondern auch aus praktischen Gründen für globale Objekte – zurück zum Beispiel mit dem globalen DDoS-Schutzprogramm: Wir möchten in der Lage sein, gelegentlich die Statistiken anzusehen.
Das BPF-Dateisystem wird normalerweise in /sys/fs/bpf, kann jedoch auch lokal gemountet werden, beispielsweise so:
$ mkdir bpf-mountpoint
$ sudo mount -t bpf none bpf-mountpointDie Namen im Dateisystem werden mit dem Befehl BPF_OBJ_PIN des BPF-Systemaufrufs erstellt. Zur Veranschaulichung nehmen wir ein beliebiges Programm, kompilieren es, laden es hoch und pinnen es in bpffs. Unser Programm erfüllt keine nützliche Funktion; wir zeigen nur den Code, damit Sie das Beispiel reproduzieren können:
$ cat test.c
__attribute__((section("xdp"), used))
int test(void *ctx)
{
return 0;
}
char _license[] __attribute__((section("license"), used)) = "GPL";Wir kompilieren dieses Programm und erstellen eine lokale Kopie des Dateisystems. bpffs:
$ clang -target bpf -c test.c -o test.o
$ mkdir bpf-mountpoint
$ sudo mount -t bpf none bpf-mountpointLaden wir nun unser Programm mit dem Dienstprogramm hoch bpftool und betrachten die zugehörigen Systemaufrufe bpf(2) (einige irrelevante Zeilen wurden aus dem strace-Auszug entfernt):
$ sudo strace -e bpf bpftool prog load ./test.o bpf-mountpoint/test
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, prog_name="test", ...}, 120) = 3
bpf(BPF_OBJ_PIN, {pathname="bpf-mountpoint/test", bpf_fd=3}, 120) = 0Hier haben wir das Programm mit Hilfe von BPF_PROG_LOAD, einen Dateideskriptor vom Kern erhalten 3 und mit dem Befehl BPF_OBJ_PIN diesen Dateideskriptor als Datei festgelegt "bpf-mountpoint/test". Danach hat der Ladeservice bpftool seine Arbeit beendet, aber unser Programm blieb im Kern aktiv, obwohl wir es nicht mit einem Netzwerkinterface verbunden haben:
$ sudo bpftool prog | tail -3
783: xdp name test tag 5c8ba0cf164cb46c gpl
loaded_at 2020-05-05T13:27:08+0000 uid 0
xlated 24B jited 41B memlock 4096BWir können das Date Objekt einfach mit unlink(2) entfernen, und das entsprechende Programm wird gelöscht:
$ sudo rm ./bpf-mountpoint/test
$ sudo bpftool prog show id 783
Error: get by id (783): No such file or directoryLöschen von Objekten
Wenn wir über das Entfernen von Objekten sprechen, ist es wichtig zu klären, dass, nachdem wir das Programm von dem Hook (Ereignisgenerator) getrennt haben, kein neues Ereignis seine Ausführung auslösen wird. Alle aktuellen Instanzen des Programms werden jedoch ordnungsgemäß beendet.
Einige Arten von BPF-Programmen ermöglichen es, das Programm zur Laufzeit zu ersetzen, d.h. sie bieten Atomarität für die Sequenz. replace = alte Programmdetachierung, neues Programm anhängen. Dabei werden alle aktiven Instanzen der alten Programmversion beendet, während neue Ereignis-Handler bereits aus dem neuen Programm erstellt werden. Hierbei bedeutet "Atomarität", dass kein Ereignis ausgelassen wird.
Anschluss von Programmen an Ereignisquellen
In diesem Artikel werden wir nicht gesondert auf die Verbindung von Programmen zu Ereignisquellen eingehen, da dies im Kontext eines bestimmten Programtyps sinnvoll zu betrachten ist. Siehe unten, wo wir zeigen, wie Programme vom Typ XDP angeschlossen werden.
Objektverwaltung mittels des Systemaufrufs bpf
BPF-Programme
Alle BPF-Objekte werden aus dem Benutzerspeicherraum mithilfe des Systemaufrufs bpf, der folgendes Prototyp hat:
#include <linux/bpf.h>
int bpf(int cmd, union bpf_attr *attr, unsigned int size);Hier ist das Team cmd — es ist einer der Typen von , attr — ein Zeiger auf Parameter für ein bestimmtes Programm und Größe — die Größe des Objekts, auf das verwiesen wird, d.h. normalerweise ist das sizeof(*attr). Im Kernel 5.8 unterstützt der Systemaufruf bpf 34 verschiedene Befehle, und union bpf_attr nimmt 200 Zeilen in Anspruch. Doch das sollte uns nicht abschrecken, denn wir werden die Befehle und Parameter über mehrere Artikel hinweg kennenlernen.
Wir beginnen mit dem Befehl BPF_PROG_LOAD, der BPF-Programme erstellt — er nimmt eine Reihe von BPF-Anweisungen und lädt sie in den Kernel. Zum Zeitpunkt des Ladens wird der Verifier gestartet, gefolgt vom JIT-Compiler, und nach erfolgreicher Ausführung erhält der Benutzer einen Dateideskriptor des Programms zurück. Wir haben gesehen, was als Nächstes mit ihm passiert ist im vorherigen Abschnitt .
Jetzt werden wir ein Benutzerprogramm schreiben, das ein einfaches BPF-Programm lädt, aber zuerst müssen wir entscheiden, welches Programm wir wirklich laden möchten — wir müssen wählen und innerhalb dieses Typs ein Programm schreiben, das die Überprüfung durch den Verifier besteht. Um den Prozess jedoch nicht zu komplizieren, hier ist eine fertige Lösung: Wir nehmen ein Programm des Typs BPF_PROG_TYPE_XDP, die einen Wert zurückgibt XDP_PASS (alle Pakete überspringen). In BPF-Assembly sieht das sehr einfach aus:
r0 = 2
exitNachdem wir festgelegt haben, was was wir laden werden, können wir erklären, wie wir das machen:
#define _GNU_SOURCE
#include <string.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/bpf.h>
static inline __u64 ptr_to_u64(const void *ptr)
{
return (__u64) (unsigned long) ptr;
}
int main(void)
{
struct bpf_insn insns[] = {
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_0,
.imm = XDP_PASS
},
{
.code = BPF_JMP | BPF_EXIT
},
};
union bpf_attr attr = {
.prog_type = BPF_PROG_TYPE_XDP,
.insns = ptr_to_u64(insns),
.insn_cnt = sizeof(insns)/sizeof(insns[0]),
.license = ptr_to_u64("GPL"),
};
strncpy(attr.prog_name, "woo", sizeof(attr.prog_name));
syscall(__NR_bpf, BPF_PROG_LOAD, &attr, sizeof(attr));
for ( ;; )
pause();
}Interessante Ereignisse im Programm beginnen mit der Definition des Arrays insns — unseres BPF-Programms in Maschinenanweisungen. Dabei wird jede Anweisung des BPF-Programms in einer Struktur verpackt . Das erste Element insns entspricht der Anweisung r0 = 2, das zweite — exit.
Ein Abstecher. Im Kernel sind bequemere Makros für das Schreiben von Maschinenanweisungen definiert, und mit der Nutzung der Kernel-Header-Datei tools/include/linux/filter.h könnten wir schreiben
struct bpf_insn insns[] = {
BPF_MOV64_IMM(BPF_REG_0, XDP_PASS),
BPF_EXIT_INSN()
};Da das Schreiben von BPF-Programmen in Maschinenanweisungen nur für das Schreiben von Tests im Kernel und Artikeln über BPF notwendig ist, macht das Fehlen dieser Makros das Leben des Entwicklers tatsächlich nicht komplizierter.
Nach der Definition des BPF-Programms gehen wir zur dessen Lade in den Kernel über. Unser minimalistisches Parameter-Set attr umfasst den Programmtyp, das Set und die Anzahl der Anweisungen, die erforderliche Lizenz sowie den Namen "woo", die wir verwenden, um unser Programm nach dem Laden im System zu finden. Das Programm wird, wie versprochen, mit einem Systemaufruf in das System geladen. bpf.
Am Ende des Programms landen wir in einer Endlosschleife, die eine Nutzlast simuliert. Ohne sie würde das Programm vom Kernel bei der Schließung des Dateihandles, das uns der Systemaufruf zurückgegeben hat, beendet. bpf, und wir werden es nicht im System sehen.
Nun, wir sind bereit für den Test. Lassen Sie uns das Programm unter stracekompilieren und ausführen, um zu überprüfen, ob alles wie gewünscht funktioniert:
$ clang -g -O2 simple-prog.c -o simple-prog
$ sudo strace ./simple-prog
execve("./simple-prog", ["./simple-prog"], 0x7ffc7b553480 /* 13 vars */) = 0
...
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=2, insns=0x7ffe03c4ed50, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(0, 0, 0), prog_flags=0, prog_name="woo", prog_ifindex=0, expected_attach_type=BPF_CGROUP_INET_INGRESS}, 72) = 3
pause(Alles in Ordnung, bpf(2) gab uns Descriptor 3 zurück und wir gingen in die Endlosschleife mit pause(). Lassen Sie uns versuchen, unser Programm im System zu finden. Dazu öffnen wir ein anderes Terminal und verwenden das Dienstprogramm bpftool:
# bpftool prog | grep -A3 woo
390: xdp name woo tag 3b185187f1855c4c gpl
loaded_at 2020-08-31T24:66:44+0000 uid 0
xlated 16B jited 40B memlock 4096B
pids simple-prog(10381)Wir sehen, dass das Programm woo im System geladen ist, dessen globaler ID 390 entspricht und dass der Prozess gerade simple-prog Es gibt einen offenen Dateideskriptor, der auf das Programm verweist (und wenn simple-prog es beendet wird, wird woo es verschwinden). Wie erwartet benötigt das Programm woo 16 Bytes – zwei Befehle – binärer Codes in der BPF-Architektur, aber in nativer Form (x86_64) sind es bereits 40 Bytes. Lassen Sie uns unsere Programm im Original ansehen:
# bpftool prog dump xlated id 390
0: (b7) r0 = 2
1: (95) exitohne Überraschungen. Jetzt betrachten wir den von dem JIT-Compiler generierten Code:
# bpftool prog dump jited id 390
bpf_prog_3b185187f1855c4c_woo:
0: nopl 0x0(%rax,%rax,1)
5: push %rbp
6: mov %rsp,%rbp
9: sub $0x0,%rsp
10: push %rbx
11: push %r13
13: push %r14
15: push %r15
17: pushq $0x0
19: mov $0x2,%eax
1e: pop %rbx
1f: pop %r15
21: pop %r14
23: pop %r13
25: pop %rbx
26: leaveq
27: retqnicht besonders effizient für exit(2), aber um der Fairness willen, unser Programm ist einfach zu rudimentär, und für nicht-triviale Programme sind Prolog und Epilog, die der JIT-Compiler hinzufügt, natürlich notwendig.
Maps
BPF-Programme können strukturierte Speicherbereiche nutzen, die sowohl für andere BPF-Programme als auch für Programme aus dem Benutzerspeicher zugänglich sind. Diese Objekte werden Maps genannt und in diesem Abschnitt zeigen wir, wie man sie mit einem Systemaufruf verwaltet. bpf.
Zunächst sei gesagt, dass die Möglichkeiten von Maps nicht nur den Zugang zu gemeinsamem Speicher umfassen. Es gibt spezialisierte Maps, die beispielsweise Zeiger auf BPF-Programme oder auf Netzwerkschnittstellen enthalten, Maps zur Arbeit mit Perf-Events usw. Darüber werden wir hier nicht reden, um den Leser nicht zu verwirren. Außerdem ignorieren wir Synchronisationsprobleme, da diese für unsere Beispiele nicht wichtig sind. Eine vollständige Liste der verfügbaren Map-Typen finden Sie in , und in diesem Abschnitt nehmen wir als Beispiel den historisch ersten Typ, die Hash-Tabelle BPF_MAP_TYPE_HASH.
Wenn Sie eine Hash-Tabelle erstellen, sagen wir, in C++, würden Sie sagen unordered_map woo, was auf Deutsch bedeutet: „Ich benötige eine Tabelle woo ungerichteter Größe, wobei die Schlüssel den Typ int, und die Werte den Typ longhaben“. Um eine BPF-Hash-Tabelle zu erstellen, müssen wir ungefähr das Gleiche tun, mit der Ausnahme, dass wir die maximale Größe der Tabelle angeben müssen, und anstelle der Typen von Schlüsseln und Werten müssen wir ihre Größen in Bytes angeben. Für die Erstellung von Maps wird der Befehl verwendet BPF_MAP_CREATE des Systemaufrufs erstellt, und wir werden im nächsten Abschnitt darüber sprechen, wie genau das geschieht. Dabei werden Datenstrukturen im Kernel erstellt, und für jede von ihnen bpf. Werfen wir einen Blick auf ein eher minimales Programm, das eine Map erstellt. Nach dem vorherigen Programm zum Laden von BPF-Programmen sollte Ihnen dieses einfach erscheinen:
$ cat simple-map.c
#define _GNU_SOURCE
#include
#include
#include
#include
int main(void)
{
union bpf_attr attr = {
.map_type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(int),
.value_size = sizeof(int),
.max_entries = 4,
};
strncpy(attr.map_name, "woo", sizeof(attr.map_name));
syscall(__NR_bpf, BPF_MAP_CREATE, &attr, sizeof(attr));
for ( ;; )
pause();
}Hier definieren wir eine Reihe von Parametern attr, wobei wir sagen, „ich benötige eine Hash-Tabelle mit Schlüsseln und Werten der Größe sizeof(int), in die ich maximal vier Elemente legen kann“. Beim Erstellen von BPF-Maps können auch andere Parameter angegeben werden, zum Beispiel, wie im Beispiel mit dem Programm haben wir den Objektnamen angegeben als "woo".
Kompilieren und starten wir das Programm:
$ clang -g -O2 simple-map.c -o simple-map
$ sudo strace ./simple-map
execve("./simple-map", ["./simple-map"], 0x7ffd40a27070 /* 14 vars */) = 0
...
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=4, value_size=4, max_entries=4, map_name="woo", ...}, 72) = 3
pause(Hier hat der Systemaufruf bpf(2) uns den Map-Deskriptor Nummer 3 und die Programm wartet wie erwartet auf weitere Anweisungen im Systemaufruf pause(2).
Jetzt senden wir unser Programm in den Hintergrund oder öffnen ein anderes Terminal, um unser Objekt mithilfe des Dienstprogramms zu überprüfen. bpftool (wir können unsere Map an ihrem Namen von anderen unterscheiden):
$ sudo bpftool map
...
114: hash name woo flags 0x0
key 4B value 4B max_entries 4 memlock 4096B
...Die Zahl 114 ist die globale ID unseres Objekts. Jede Anwendung im System kann diese ID verwenden, um eine bereits vorhandene Map mit dem Befehl zu öffnen BPF_MAP_GET_FD_BY_ID des Systemaufrufs erstellt, und wir werden im nächsten Abschnitt darüber sprechen, wie genau das geschieht. Dabei werden Datenstrukturen im Kernel erstellt, und für jede von ihnen bpf.
Jetzt können wir mit unserer Hash-Tabelle experimentieren. Lassen Sie uns ihren Inhalt ansehen:
$ sudo bpftool map dump id 114
Gefunden: 0 ElementeLeer. Lassen Sie uns einen Wert hineinlegen: hash[1] = 1:
$ sudo bpftool map update id 114 key 1 0 0 0 value 1 0 0 0Sehen wir uns die Tabelle noch einmal an:
$ sudo bpftool map dump id 114
key: 01 00 00 00 value: 01 00 00 00
Gefunden: 1 ElementHurra! Es ist uns gelungen, ein Element hinzuzufügen. Beachten Sie, dass wir dafür auf Byte-Ebene arbeiten müssen, da bpftool nicht weiß, welchen Typ die Werte in der Hash-Tabelle haben. (Man kann ihm dieses Wissen über BTF mitteilen, aber dazu später mehr.)
Wie genau liest und fügt bpftool Elemente hinzu? Lassen Sie uns einen Blick unter die Haube werfen:
$ sudo strace -e bpf bpftool map dump id 114
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=NULL, next_key=0x55856ab65280}, 120) = 0
bpf(BPF_MAP_LOOKUP_ELEM, {map_fd=3, key=0x55856ab65280, value=0x55856ab652a0}, 120) = 0
key: 01 00 00 00 value: 01 00 00 00
bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=0x55856ab65280, next_key=0x55856ab65280}, 120) = -1 ENOENTZuerst haben wir die Map über ihre globale ID mit dem Befehl geöffnet. BPF_MAP_GET_FD_BY_ID und bpf(2) Das hat uns den Descriptor 3 zurückgegeben. Weiterhin haben wir mit dem Befehl BPF_MAP_GET_NEXT_KEY den ersten Schlüssel in der Tabelle gefunden, indem wir NULL als Zeiger auf den "vorherigen" Schlüssel übergeben haben. Wenn ein Schlüssel vorhanden ist, können wir BPF_MAP_LOOKUP_ELEM, der den Wert an den Zeiger zurückgibt. valueDer nächste Schritt besteht darin, das nächste Element zu suchen, indem wir den Zeiger auf den aktuellen Schlüssel übergeben, aber unsere Tabelle enthält nur ein Element, und der Befehl BPF_MAP_GET_NEXT_KEY gibt er ENOENT.
Gut, lassen Sie uns den Wert für den Schlüssel 1 ändern. Nehmen wir an, unsere Geschäftslogik erfordert, dass wir hash[1] = 2:
$ sudo strace -e bpf bpftool map update id 114 key 1 0 0 0 value 2 0 0 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=3, key=0x55dcd72be260, value=0x55dcd72be280, flags=BPF_ANY}, 120) = 0Wie erwartet ist das ganz einfach: Der Befehl BPF_MAP_GET_FD_BY_ID öffnet unsere Map über die ID, und der Befehl BPF_MAP_UPDATE_ELEM aktualisiert das Element.
Nachdem wir eine Hash-Tabelle aus einem Programm erstellt haben, können wir deren Inhalt aus einem anderen lesen und schreiben. Beachten Sie, dass, wenn wir dies über die Kommandozeile tun konnten, es auch jedes andere Programm im System tun kann. Neben den oben beschriebenen Befehlen stehen aus dem Benutzerraum zur Arbeit mit Maps auch :
BPF_MAP_LOOKUP_ELEM: den Wert anhand des Schlüssels suchenBPF_MAP_UPDATE_ELEM: den Wert aktualisieren/erstellenBPF_MAP_DELETE_ELEM: den Schlüssel löschenBPF_MAP_GET_NEXT_KEY: den nächsten (oder ersten) Schlüssel findenBPF_MAP_GET_NEXT_ID: ermöglicht das Durchlaufen aller bestehenden Maps, so arbeitetbpftool mapBPF_MAP_GET_FD_BY_ID: ein bestehendes Map anhand seiner globalen ID öffnenBPF_MAP_LOOKUP_AND_DELETE_ELEM: atomar den Objektwert aktualisieren und den alten zurückgebenBPF_MAP_FREEZE: das Map aus dem Userspace unveränderlich machen (diese Operation kann nicht rückgängig gemacht werden)BPF_MAP_LOOKUP_BATCH,BPF_MAP_LOOKUP_AND_DELETE_BATCH,BPF_MAP_UPDATE_BATCH,BPF_MAP_DELETE_BATCH: Batch-Operationen. Zum Beispiel,BPF_MAP_LOOKUP_AND_DELETE_BATCH— dies ist der einzige zuverlässige Weg, um alle Werte aus einem Map zu lesen und auf Null zu setzen
Nicht alle dieser Befehle funktionieren für alle Map-Typen, aber im Allgemeinen sieht die Arbeit mit anderen Typen von Maps aus dem Benutzerraum genauso aus wie die Arbeit mit Hash-Tabellen.
Um Ordnung zu schaffen, lass uns unsere Experimente mit der Hash-Tabelle abschließen. Erinnern Sie sich, dass wir eine Tabelle erstellt haben, die bis zu vier Schlüssel enthalten kann? Fügen wir noch ein paar Elemente hinzu:
$ sudo bpftool map update id 114 key 2 0 0 0 value 1 0 0 0
$ sudo bpftool map update id 114 key 3 0 0 0 value 1 0 0 0
$ sudo bpftool map update id 114 key 4 0 0 0 value 1 0 0 0Bisher alles gut:
$ sudo bpftool map dump id 114
key: 01 00 00 00 value: 01 00 00 00
key: 02 00 00 00 value: 01 00 00 00
key: 04 00 00 00 value: 01 00 00 00
key: 03 00 00 00 value: 01 00 00 00
Gefunden: 4 ElementeLassen Sie uns versuchen, einen weiteren hinzuzufügen:
$ sudo bpftool map update id 114 key 5 0 0 0 value 1 0 0 0
Fehler: Update fehlgeschlagen: Argumentliste zu langWie erwartet, hat es nicht geklappt. Lassen Sie uns den Fehler genauer ansehen:
$ sudo strace -e bpf bpftool map update id 114 key 5 0 0 0 value 1 0 0 0
bpf(BPF_MAP_GET_FD_BY_ID, {map_id=114, next_id=0, open_flags=0}, 120) = 3
bpf(BPF_OBJ_GET_INFO_BY_FD, {info={bpf_fd=3, info_len=80, info=0x7ffe6c626da0}}, 120) = 0
bpf(BPF_MAP_UPDATE_ELEM, {map_fd=3, key=0x56049ded5260, value=0x56049ded5280, flags=BPF_ANY}, 120) = -1 E2BIG (Argumentliste zu lang)
Fehler: Update fehlgeschlagen: Argumentliste zu lang
+++ beendet mit 255 +++Alles gut: wie erwartet versucht der Befehl BPF_MAP_UPDATE_ELEM einen neuen, fünften Schlüssel zu erstellen, schlägt jedoch fehl mit E2BIG.
Wir können also BPF-Programme erstellen und hochladen sowie Maps aus dem Benutzerspeicher verwalten. Jetzt ist es sinnvoll, sich anzusehen, wie wir Maps direkt aus den BPF-Programmen nutzen können. Anstatt auf schwer verständliche Maschinen-Code-Makros einzugehen, ist es an der Zeit zu zeigen, wie BPF-Programme tatsächlich geschrieben und gewartet werden — mit Hilfe von libbpf.
(Für Leser, die unzufrieden sind mit dem Fehlen eines Low-Level-Beispiels: Wir werden Programme ausführlich diskutieren, die Maps und Hilfsfunktionen verwenden, die mit Hilfe von libbpf erstellt wurden, und erklären, was auf der Instruktions- Ebene passiert. Für Leser, die unzufrieden sind mit sehr stark, haben wir an einer passenden Stelle im Artikel hinzugefügt.)
Wir schreiben BPF-Programme mit libbpf
BPF-Programme mit Maschinen-Codes zu schreiben, kann nur eine Zeitlang interessant sein, bevor man desinteressiert wird. In diesem Moment sollte man den Blick auf llvmrichten, das über einen Backend zur Code-Generierung für die BPF-Architektur verfügt, sowie auf die Bibliothek libbpf, die es ermöglicht, den benutzerspezifischen Teil von BPF-Anwendungen zu schreiben und BPF-Programme, die mit Hilfe von erzeugtem Code erstellt wurden, hochzuladen. llvm/clang.
Wie wir in diesem und in den folgenden Artikeln sehen werden, libbpf leistet eine Menge Arbeit, und ohne sie (oder ähnliche Werkzeuge — iproute2, libbcc, libbpf-go, usw.) ist das Leben unmöglich. Eine der herausragenden Funktionen des Projekts libbpf ist BPF CO-RE (Compile Once, Run Everywhere) — ein Projekt, das es ermöglicht, BPF-Programme zu schreiben, die von einem Kernel zum anderen portierbar sind, mit der Möglichkeit, auf verschiedenen APIs zu laufen (zum Beispiel, wenn sich die Kernelstruktur von Version zu Version ändert). Um mit CO-RE arbeiten zu können, muss Ihr Kernel mit BTF-Unterstützung kompiliert sein (wie das funktioniert, erklären wir im Abschnitt ). Um zu überprüfen, ob Ihr Kernel mit BTF kompiliert wurde, schauen Sie einfach nach der folgenden Datei:
$ ls -lh /sys/kernel/btf/vmlinux
-r--r--r-- 1 root root 2.6M 29. Jul 15:30 /sys/kernel/btf/vmlinuxDiese Datei enthält Informationen über alle Datentypen, die im Kernel verwendet werden, und wird in all unseren Beispielen genutzt, die libbpf. Wir werden in der nächsten Artikel ausführlich über CO-RE sprechen, und in diesem Artikel — bauen Sie einfach einen Kernel mit CONFIG_DEBUG_INFO_BTF.
Die Bibliothek libbpf lebt direkt im Verzeichnis tools/lib/bpf des Kernels, und die Entwicklung erfolgt über die Mailingliste bpf@vger.kernel.org. Für Anwendungen, die außerhalb des Kernels laufen, gibt es jedoch ein separates Repository , in dem die Kernel-Bibliothek mehr oder weniger unverändert im Nur-Lese-Zugriff gespiegelt wird.
In diesem Abschnitt schauen wir uns an, wie man ein Projekt erstellt, das libbpf, wir schreiben ein paar (mehr oder weniger sinnlose) Testprogramme und gehen detailliert durch, wie das alles funktioniert. Dadurch können wir in den folgenden Abschnitten einfacher erklären, wie die BPF-Programme mit Maps, Kernel-Helpers, BTF usw. interagieren.
Typischerweise fügen Projekte, die libbpf , das GitHub-Repository als Git-Submodul hinzu. Das werden wir auch tun:
$ mkdir /tmp/libbpf-example
$ cd /tmp/libbpf-example/
$ git init-db
Leeres Git-Repository in /tmp/libbpf-example/.git/ initialisiert.
$ git submodule add https://github.com/libbpf/libbpf.git
Klonen nach '/tmp/libbpf-example/libbpf'...
remote: Objekte werden aufgelistet: 200, abgeschlossen.
remote: Zähle Objekte: 100% (200/200), abgeschlossen.
remote: Objekte werden komprimiert: 100% (103/103), abgeschlossen.
remote: Insgesamt 3354 (Delta 101), wiederverwendet 118 (Delta 79), pack-reused 3154
Empfange Objekte: 100% (3354/3354), 2.05 MiB | 10.22 MiB/s, abgeschlossen.
Löse Deltas auf: 100% (2176/2176), abgeschlossen.Wird sehr einfach kompilieren: libbpf sehr einfach:
$ cd libbpf/src
$ mkdir build
$ OBJDIR=build DESTDIR=root make -s install
$ find root
root
root/usr
root/usr/include
root/usr/include/bpf
root/usr/include/bpf/bpf_tracing.h
root/usr/include/bpf/xsk.h
root/usr/include/bpf/libbpf_common.h
root/usr/include/bpf/bpf_endian.h
root/usr/include/bpf/bpf_helpers.h
root/usr/include/bpf/btf.h
root/usr/include/bpf/bpf_helper_defs.h
root/usr/include/bpf/bpf.h
root/usr/include/bpf/libbpf_util.h
root/usr/include/bpf/libbpf.h
root/usr/include/bpf/bpf_core_read.h
root/usr/lib64
root/usr/lib64/libbpf.so.0.1.0
root/usr/lib64/libbpf.so.0
root/usr/lib64/libbpf.a
root/usr/lib64/libbpf.so
root/usr/lib64/pkgconfig
root/usr/lib64/pkgconfig/libbpf.pcUnser weiterer Plan in diesem Abschnitt ist folgender: Wir werden ein BPF-Programm schreiben, BPF_PROG_TYPE_XDPdas genau dasselbe ist wie im vorherigen Beispiel, jedoch in C, und es mit clangkompilieren und ein Hilfsprogramm schreiben, das es in den Kernel lädt. In den folgenden Abschnitten werden wir sowohl die BPF-Anwendung als auch das Hilfsprogramm erweitern.
Beispiel: Erstellen einer vollständigen Anwendung mit libbpf
Zunächst verwenden wir die Datei /sys/kernel/btf/vmlinux, die zuvor erwähnt wurde, und erstellen ihr Äquivalent in Form einer Header-Datei:
$ bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.hIn dieser Datei werden alle Datenstrukturen gespeichert, die in unserem Kernel vorhanden sind, zum Beispiel wird der Header für IPv4 im Kernel so definiert:
$ grep -A 12 'struct iphdr {' vmlinux.h
struct iphdr {
__u8 ihl: 4;
__u8 version: 4;
__u8 tos;
__be16 tot_len;
__be16 id;
__be16 frag_off;
__u8 ttl;
__u8 protocol;
__sum16 check;
__be32 saddr;
__be32 daddr;
};Jetzt schreiben wir unser BPF-Programm in C:
$ cat xdp-simple.bpf.c
#include "vmlinux.h"
#include
SEC("xdp/simple")
int simple(void *ctx)
{
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";Obwohl unser Programm sehr einfach ist, sollten wir auf viele Details achten. Zuerst ist die erste Header-Datei, die wir einbinden, die vmlinux.h, die wir gerade mit Hilfe von bpftool btf dump generiert haben— jetzt müssen wir kein Paket mit Kernel-Headern installieren, um zu verstehen, wie die Strukturen im Kernel aussehen. Die nächste Header-Datei stammt aus der Bibliothek libbpf. Momentan benötigen wir sie nur, um das Makro SEC, das das Symbol in den entsprechenden Abschnitt der ELF-Objektdatei sendet, zu definieren. Unser Programm befindet sich im Abschnitt xdp/simple, wo wir vor dem Schrägstrich den Typ des BPF-Programms festlegen — dies ist eine Vereinbarung, die in libbpfverwendet wird, und basierend auf dem Abschnittsnamen wird der richtige Typ bei der Ausführung bpf(2)eingesetzt. Das BPF-Programm selbst in C ist sehr einfach und besteht aus einer Zeile return XDP_PASS. Endlich, ein eigener Abschnitt "Lizenz" enthält den Lizenznamen.
Wir können unser Programm mit llvm/clang, Version >= 10.0.0, oder besser, noch höher kompilieren (siehe Abschnitt ):
$ clang --version
clang version 11.0.0 (https://github.com/llvm/llvm-project.git afc287e0abec710398465ee1f86237513f2b5091)
...
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.oZu den interessanten Merkmalen gehört: Wir geben die Zielarchitektur an -target bpf und den Pfad zu den Headers libbpf, die wir kürzlich installiert haben. Vergessen Sie auch nicht -O2, ohne diese Option können Sie später Überraschungen erleben. Schauen wir uns unseren Code an, haben wir das Programm geschrieben, das wir wollten?
$ llvm-objdump --section=xdp/simple --no-show-raw-insn -D xdp-simple.bpf.o
xdp-simple.bpf.o: Dateiformat elf64-bpf
Disassemblierung der Sektion xdp/simple:
0000000000000000 :
0: r0 = 2
1: exitJa, es hat geklappt! Jetzt haben wir eine Binärdatei mit dem Programm, und wir möchten eine Anwendung erstellen, die es in den Kernel lädt. Dafür benötigen wir die Bibliothek libbpf bietet uns zwei Optionen – entweder ein niedrigeres API oder ein höheres API zu verwenden. Wir wählen den zweiten Weg, da wir lernen möchten, wie man BPF-Programme mit minimalem Aufwand schreibt, lädt und anschließt, um sie anschließend zu studieren.
Um zu beginnen, müssen wir mit dem gleichen Tool das 'Skelett' unseres Programms aus seinem Binärformat generieren. bpftool – das Schweizer Taschenmesser der BPF-Welt (was auch wörtlich genommen werden kann, da Daniel Borkman – einer der Schöpfer und Maintainer von BPF – Schweizer ist):
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.hIn der Datei xdp-simple.skel.h enthält den Binärcode unseres Programms und Funktionen zur Verwaltung – zum Laden, Anschließen und Entfernen unseres Objekts. In unserem einfachen Fall mag das übertrieben erscheinen, aber es funktioniert auch, wenn die Objektdatei viele BPF-Programme und Maps enthält, und zum Laden dieses riesigen ELF reicht es aus, nur das Skelett zu generieren und ein oder zwei Funktionen aus der Benutzeranwendung aufzurufen, deren Schreiben wir jetzt angehen werden.
Eigentlich ist unser Loader-Programm trivial:
#include <err.h>
#include <unistd.h>
#include "xdp-simple.skel.h"
int main(int argc, char **argv)
{
struct xdp_simple_bpf *obj;
obj = xdp_simple_bpf__open_and_load();
if (!obj)
err(1, "failed to open and/or load BPF objectn");
pause();
xdp_simple_bpf__destroy(obj);
}Hier struct xdp_simple_bpf wird in der Datei definiert xdp-simple.skel.h und beschreibt unsere Objektdatei:
struct xdp_simple_bpf {
struct bpf_object_skeleton *skeleton;
struct bpf_object *obj;
struct {
struct bpf_program *simple;
} progs;
struct {
struct bpf_link *simple;
} links;
};Wir können hier Spuren einer niedrigstufigen API feststellen: die Struktur struct bpf_program *simple und struct bpf_link *simple. Die erste Struktur beschreibt speziell unser Programm, das im Abschnitt xdp/simple, und die zweite beschreibt, wie das Programm an die Ereignisquelle angeschlossen wird.
Die Funktion xdp_simple_bpf__open_and_load, öffnet das ELF-Objekt, parst es, erstellt alle Strukturen und Unterstrukturen (außer dem Programm befinden sich im ELF auch andere Abschnitte – Daten, schreibgeschützte Daten, Debug-Informationen, Lizenz usw.), und lädt es dann über einen Systemaufruf in den Kernel. bpf, was wir überprüfen können, indem wir das Programm kompilieren und ausführen:
$ clang -O2 -I ./libbpf/src/root/usr/include/ xdp-simple.c -o xdp-simple ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo strace -e bpf ./xdp-simple
...
bpf(BPF_BTF_LOAD, 0x7ffdb8fd9670, 120) = 3
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=2, insns=0xdfd580, license="GPL", log_level=0, log_size=0, log_buf=NULL, kern_version=KERNEL_VERSION(5, 8, 0), prog_flags=0, prog_name="simple", prog_ifindex=0, expected_attach_type=0x25 /* BPF_??? */, ...}, 120) = 4Lassen Sie uns nun unser Programm mithilfe von bpftool. Finden wir ihre ID:
# bpftool p | grep -A4 simple
463: xdp name simple tag 3b185187f1855c4c gpl
loaded_at 2020-08-01T01:59:49+0000 uid 0
xlated 16B jited 40B memlock 4096B
btf_id 185
pids xdp-simple(16498)und dumpen sie (wir verwenden die verkürzte Form des Befehls bpftool prog dump xlated):
# bpftool p d x id 463
int simple(void *ctx):
; return XDP_PASS;
0: (b7) r0 = 2
1: (95) exitEtwas Neues! Das Programm hat Teile unserer Quelldatei in der Sprache C ausgegeben. Dies wurde durch die Bibliothek libbpf, die den Debugging-Bereich im Binärformat gefunden, ihn in ein BTF-Objekt kompiliert und mit BPF_BTF_LOADin den Kernel geladen hat, anschließend das erhaltene Dateihandle beim Laden des Programms mit dem Befehl BPG_PROG_LOAD.
Kernel-Hilfsfunktionen
BPF-Programme können "externe" Funktionen - Kernel-Helfer - aufrufen. Diese Hilfsfunktionen ermöglichen es den BPF-Programmen, auf Kernel-Strukturen zuzugreifen, Maps zu verwalten und mit der "realen Welt" zu interagieren - z.B. Perf-Events zu erstellen, Hardware zu steuern (z.B. Pakete umzuleiten) usw.
Beispiel: bpf_get_smp_processor_id
Im Rahmen des Paradigmas "lernen durch Beispiele" betrachten wir eine der Hilfsfunktionen, bpf_get_smp_processor_id(), in der Datei kernel/bpf/helpers.c. Sie gibt die Nummer des Prozessors zurück, auf dem das aufrufende BPF-Programm ausgeführt wird. Aber uns interessiert nicht so sehr ihre Semantik, sondern dass ihre Implementierung nur eine Zeile umfasst:
BPF_CALL_0(bpf_get_smp_processor_id)
{
return smp_processor_id();
}Die Definitionen von BPF-Hilfsfunktionen ähneln den Definitionen von Systemaufrufen in Linux. Hier wird zum Beispiel eine Funktion definiert, die keine Argumente hat. (Eine Funktion, die beispielsweise drei Argumente annimmt, wird mit einem Makro definiert. BPF_CALL_3. Die maximale Anzahl an Argumenten beträgt fünf.) Dies ist jedoch nur der erste Teil der Definition. Der zweite Teil besteht darin, einen Strukturtyp zu definieren, struct bpf_func_proto, der eine für den Verifier verständliche Beschreibung der Hilfsfunktion enthält:
const struct bpf_func_proto bpf_get_smp_processor_id_proto = {
.func = bpf_get_smp_processor_id,
.gpl_only = false,
.ret_type = RET_INTEGER,
};Registrierung von Hilfsfunktionen
Damit Programme eines bestimmten BPF-Typs diese Funktion nutzen können, müssen sie sie registrieren, zum Beispiel für den Typ BPF_PROG_TYPE_XDP wird im Kernel die Funktion xdp_func_proto, die anhand der ID der Hilfsfunktion bestimmt, ob XDP diese Funktion unterstützt oder nicht. Unsere Funktion ist :
static const struct bpf_func_proto *
xdp_func_proto(enum bpf_func_id func_id, const struct bpf_prog *prog)
{
switch (func_id) {
...
case BPF_FUNC_get_smp_processor_id:
return &bpf_get_smp_processor_id_proto;
...
}
}Neue BPF-Programmtypen werden in der Datei mithilfe des Makros BPF_PROG_TYPE. Sie werden in Anführungszeichen definiert, da dies eine logische Definition ist, während die Definition einer Reihe spezifischer Strukturen in der C-Sprache an anderen Stellen erfolgt. Insbesondere in der Datei kernel/bpf/verifier.c werden alle Definitionen aus der Datei bpf_types.h verwendet, um ein Array von Strukturen zu erstellen bpf_verifier_ops[]:
static const struct bpf_verifier_ops *const bpf_verifier_ops[] = {
#define BPF_PROG_TYPE(_id, _name, prog_ctx_type, kern_ctx_type)
[_id] = & _name ## _verifier_ops,
#include
#undef BPF_PROG_TYPE
};Das heißt, für jeden Typ von BPF-Programmen wird ein Zeiger auf eine Datenstruktur des Typs struct bpf_verifier_ops, der mit dem Wert _name ## _verifier_ops, d.h., xdp_verifier_ops für xdp. Die Struktur xdp_verifier_ops in der Datei net/core/filter.c $ ../..../waf ...
const struct bpf_verifier_ops xdp_verifier_ops = {
.get_func_proto = xdp_func_proto,
.is_valid_access = xdp_is_valid_access,
.convert_ctx_access = xdp_convert_ctx_access,
.gen_prologue = bpf_noop_prologue,
};Hier sehen wir unsere bekannte Funktion xdp_func_proto, die vom Verifier jedes Mal aufgerufen wird, wenn er einen Aufruf einer Funktion innerhalb des BPF-Programms trifft, siehe .
Schauen wir uns an, wie ein hypothetisches BPF-Programm die Funktion bpf_get_smp_processor_idverwendet. Dazu schreiben wir das Programm aus unserem vorherigen Abschnitt wie folgt um:
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
SEC("xdp/simple")
int simple(void *ctx)
{
if (bpf_get_smp_processor_id() != 0)
return XDP_DROP;
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";Das Symbol bpf_get_smp_processor_id in <bpf/bpf_helper_defs.h> der Bibliothek libbpf als
static u32 (*bpf_get_smp_processor_id)(void) = (void *) 8;das heißt, bpf_get_smp_processor_id — dies ist ein Funktionszeiger, dessen Wert 8 beträgt, wobei 8 der Wert ist BPF_FUNC_get_smp_processor_id Typ enum bpf_fun_id, der für uns in der Datei definiert ist vmlinux.h (Datei bpf_helper_defs.h im Kernel von einem Skript generiert wird, daher sind "magische" Zahlen in Ordnung). Diese Funktion akzeptiert keine Argumente und gibt einen Wert des Typs __u32zurück. Wenn wir sie in unserem Programm aufrufen, clang generiert sie die BPF_CALL „richtigen Art“. Lassen Sie uns das Programm kompilieren und den Abschnitt anzeigen xdp/simple:
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.o
$ llvm-objdump -D --section=xdp/simple xdp-simple.bpf.o
xdp-simple.bpf.o: Datei-Format elf64-bpf
Disassembly des Abschnitts xdp/simple:
0000000000000000 <simple>:
0: 85 00 00 00 08 00 00 00 call 8
1: bf 01 00 00 00 00 00 00 r1 = r0
2: 67 01 00 00 20 00 00 00 r1 <<= 32
3: 77 01 00 00 20 00 00 00 r1 >>= 32
4: b7 00 00 00 02 00 00 00 r0 = 2
5: 15 01 01 00 00 00 00 00 if r1 == 0 goto +1 <LBB0_2>
6: b7 00 00 00 01 00 00 00 r0 = 1
0000000000000038 <LBB0_2>:
7: 95 00 00 00 00 00 00 00 exitIn der ersten Zeile sehen wir den Befehl call, Parameter IMM , dessen Wert 8 beträgt, und SRC_REG — null. Laut dem ABI-Übereinkommen, das vom Verifier verwendet wird, geschieht dies durch den Aufruf der Hilfsfunktion Nummer acht. Nach deren Ausführung ist die Logik einfach. Der Rückgabewert aus dem Register r0 wird kopiert in r1 und in den Zeilen 2,3 in den Typ u32 — die obersten 32 Bit werden auf null gesetzt. In den Zeilen 4,5,6,7 geben wir 2 (XDP_PASS) oder 1 (XDP_DROP) zurück, abhängig davon, ob die Hilfsfunktion in Zeile 0 einen null oder einen nicht-null Wert zurückgegeben hat.
Lass uns überprüfen: Wir laden das Programm und sehen uns die Ausgabe an bpftool prog dump xlated:
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.h
$ clang -O2 -g -I ./libbpf/src/root/usr/include/ -o xdp-simple xdp-simple.c ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo ./xdp-simple &
[2] 10914
$ sudo bpftool p | grep simple
523: xdp name simple tag 44c38a10c657e1b0 gpl
pids xdp-simple(10915)
$ sudo bpftool p d x id 523
int simple(void *ctx):
; if (bpf_get_smp_processor_id() != 0)
0: (85) call bpf_get_smp_processor_id#114128
1: (bf) r1 = r0
2: (67) r1 <>= 32
4: (b7) r0 = 2
; }
5: (15) if r1 == 0x0 goto pc+1
6: (b7) r0 = 1
7: (95) exitGut, der Verifier hat den richtigen Kernel-Hilfsdienst gefunden.
Beispiel: Wir übergeben die Argumente und starten schließlich das Programm!
Alle Hilfsfunktionen auf Ausführungsebene haben das Prototyp
u64 fn(u64 r1, u64 r2, u64 r3, u64 r4, u64 r5)Die Parameter werden in Registern an die Hilfsfunktionen übergeben r1—r5, und der Rückgabewert wird im Register zurückgegeben. r0. Funktionen mit mehr als fünf Argumenten sind nicht vorhanden und es wird nicht geplant, diese Unterstützung in Zukunft hinzuzufügen.
Lassen Sie uns den neuen Kernel-Helfer betrachten und wie BPF Parameter übergibt. Schreiben wir xdp-simple.bpf.c wie folgt um (die anderen Zeilen bleiben unverändert):
SEC("xdp/simple")
int simple(void *ctx)
{
bpf_printk("läuft auf CPU %un", bpf_get_smp_processor_id());
return XDP_PASS;
}Unser Programm gibt die CPU-Nummer aus, auf der es läuft. Lassen Sie uns es kompilieren und den Code ansehen:
$ llvm-objdump -D --section=xdp/simple --no-show-raw-insn xdp-simple.bpf.o
0000000000000000 :
0: r1 = 10
1: *(u16 *)(r10 - 8) = r1
2: r1 = 8441246879787806319 ll
4: *(u64 *)(r10 - 16) = r1
5: r1 = 2334956330918245746 ll
7: *(u64 *)(r10 - 24) = r1
8: call 8
9: r1 = r10
10: r1 += -24
11: r2 = 18
12: r3 = r0
13: call 6
14: r0 = 2
15: exitIn den Zeilen 0-7 schreiben wir die Zeile läuft auf CPU %un, und dann in Zeile 8 führen wir das wohlbekannte bpf_get_smp_processor_idaus. In den Zeilen 9-12 bereiten wir die Argumente des Helfers vor, bpf_printk — Register r1, r2, r3. Warum sind es drei und nicht zwei? Weil bpf_printk — das den echten Helfer umschließt, bpf_trace_printk, der die Größe der Formatzeile benötigt.
Lassen Sie uns nun ein paar Zeilen zu xdp-simple.c, damit unser Programm mit dem Interface verbunden wird lo und wirklich gestartet wird!
$ cat xdp-simple.c
#include
#include
#include
#include "xdp-simple.skel.h"
int main(int argc, char **argv)
{
__u32 flags = XDP_FLAGS_SKB_MODE;
struct xdp_simple_bpf *obj;
obj = xdp_simple_bpf__open_and_load();
if (!obj)
err(1, "Fehler beim Öffnen und/oder Laden des BPF-Objektsn");
bpf_set_link_xdp_fd(1, -1, flags);
bpf_set_link_xdp_fd(1, bpf_program__fd(obj->progs.simple), flags);
cleanup:
xdp_simple_bpf__destroy(obj);
}Hier verwenden wir die Funktion bpf_set_link_xdp_fd, die BPF-Programme vom Typ XDP mit Netzwerk-interfaces verbindet. Wir haben die Schnittstellennummer hardcodiert lo, die immer gleich 1 ist. Wir rufen die Funktion zweimal auf, um zuerst das alte Programm zu trennen, falls es bereits verbunden war. Beachten Sie, dass wir nun keinen Aufruf mehr benötigen pause oder eine Endlosschleife: unser Bootprogramm wird beendet, aber das BPF-Programm wird nicht zerstört, da es mit dem Ereignisquellen verbunden ist. Nach dem erfolgreichen Laden und der Verbindung wird das Programm für jedes Netzwerkpaket ausgeführt, das auf lo.
Laden wir das Programm und sehen uns das Interface an lo:
$ sudo ./xdp-simple
$ sudo bpftool p | grep simple
669: xdp name simple tag 4fca62e77ccb43d6 gpl
$ ip l show dev lo
1: lo: mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 669Das Programm, das wir geladen haben, hat die ID 669, und diese ID sehen wir auch am Interface. lo. Lassen Sie uns ein paar Pakete an 127.0.0.1 (Anfrage + Antwort):
$ ping -c1 localhostund jetzt schauen wir uns den Inhalt der Debugging-virtuellen Datei an, /sys/kernel/debug/tracing/trace_pipe, in die bpf_printk Nachrichten geschrieben werden:
# cat /sys/kernel/debug/tracing/trace_pipe
ping-13937 [000] d.s1 442015.377014: bpf_trace_printk: running on CPU0
ping-13937 [000] d.s1 442015.377027: bpf_trace_printk: running on CPU0Zwei Pakete wurden erkannt und lo auf CPU0 verarbeitet — unser erstes vollständiges, sinnloses BPF-Programm hat funktioniert!
Es ist wichtig zu beachten, dass bpf_printk es nicht umsonst in die Debug-Datei schreibt: Das ist kein optimaler Helfer für den Einsatz in der Produktion, aber unser Ziel war es, etwas Einfaches zu zeigen.
Zugriff auf Maps aus BPF-Programmen
Beispiel: Wir verwenden eine Map aus einem BPF-Programm.
In den vorherigen Abschnitten haben wir gelernt, Maps aus dem Benutzerraum zu erstellen und zu verwenden. Nun schauen wir uns den Kernelteil an. Lassen Sie uns, wie üblich, mit einem Beispiel beginnen. Wir schreiben unser Programm um. xdp-simple.bpf.c $ ../..../waf ...
#include "vmlinux.h"
#include <bpf/bpf_helpers.h>
struct {
__uint(type, BPF_MAP_TYPE_ARRAY);
__uint(max_entries, 8);
__type(key, u32);
__type(value, u64);
} woo SEC(".maps");
SEC("xdp/simple")
int simple(void *ctx)
{
u32 key = bpf_get_smp_processor_id();
u32 *val;
val = bpf_map_lookup_elem(&woo, &key);
if (!val)
return XDP_ABORTED;
*val += 1;
return XDP_PASS;
}
char LICENSE[] SEC("license") = "GPL";Am Anfang des Programms haben wir die Definition der Map hinzugefügt, woo: das ist ein Array aus 8 Elementen, in dem Werte des Typs u64 (in C würden wir solch ein Array als u64 woo[8]) definieren. Im Programm "xdp/simple" Wir speichern die aktuelle CPU-Nummer in einer Variablen key und verwenden dann die Hilfsfunktion bpf_map_lookup_element um einen Zeiger auf den entsprechenden Eintrag im Array zu erhalten, den wir um eins erhöhen. Übersetzt auf Deutsch: Wir zählen die Statistik darüber, auf welcher CPU die eingehenden Pakete verarbeitet wurden. Lass uns das Programm starten:
$ clang -O2 -g -c -target bpf -I libbpf/src/root/usr/include xdp-simple.bpf.c -o xdp-simple.bpf.o
$ bpftool gen skeleton xdp-simple.bpf.o > xdp-simple.skel.h
$ clang -O2 -g -I ./libbpf/src/root/usr/include/ -o xdp-simple xdp-simple.c ./libbpf/src/root/usr/lib64/libbpf.a -lelf -lz
$ sudo ./xdp-simpleÜberprüfen wir, ob es verbunden ist lo und senden wir ein paar Pakete:
$ ip l show dev lo
1: lo: mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 108
$ for s in `seq 234`; do sudo ping -f -c 100 127.0.0.1 >/dev/null 2>&1; doneSchauen wir uns jetzt den Inhalt des Arrays an:
$ sudo bpftool map dump name woo
[
{ "key": 0, "value": 0 },
{ "key": 1, "value": 400 },
{ "key": 2, "value": 0 },
{ "key": 3, "value": 0 },
{ "key": 4, "value": 0 },
{ "key": 5, "value": 0 },
{ "key": 6, "value": 0 },
{ "key": 7, "value": 46400 }
]Fast alle Prozesse wurden auf CPU7 verarbeitet. Das ist für uns nicht wichtig, Hauptsache, das Programm funktioniert und wir haben verstanden, wie man auf Maps aus BPF-Programmen zugreift — mit Hilfe von .
Mystischer Zeiger
Wir können also über die BPF-Programmierschnittstelle auf die Map zugreifen, indem wir Aufrufe der Form verwenden
val = bpf_map_lookup_elem(&woo, &key);wobei die Hilfsfunktion wie folgt aussieht
void *bpf_map_lookup_elem(struct bpf_map *map, const void *key)aber wir übergeben einen Zeiger &woo auf eine anonyme Struktur struct { ... }…
Wenn wir uns den Assemblercode des Programms ansehen, werden wir feststellen, dass der Wert &woo tatsächlich nicht definiert ist (Zeile 4):
llvm-objdump -D --section xdp/simple xdp-simple.bpf.o
xdp-simple.bpf.o: Dateiformat elf64-bpf
Disassemblierung der Sektion xdp/simple:
0000000000000000 :
0: 85 00 00 00 08 00 00 00 call 8
1: 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0
2: bf a2 00 00 00 00 00 00 r2 = r10
3: 07 02 00 00 fc ff ff ff r2 += -4
4: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
6: 85 00 00 00 01 00 00 00 call 1
...und in den Relokationen enthalten ist:
$ llvm-readelf -r xdp-simple.bpf.o | head -4
Relokationssektion '.relxdp/simple' bei Offset 0xe18 enthält 1 Einträge:
Offset Info Typ Wert des Symbols Name des Symbols
0000000000000020 0000002700000001 R_BPF_64_64 0000000000000000 wooWenn wir uns jedoch das bereits geladene Programm ansehen, werden wir einen Zeiger auf die richtige Map sehen (Zeile 4):
$ sudo bpftool prog dump x name simple
int simple(void *ctx):
0: (85) call bpf_get_smp_processor_id#114128
1: (63) *(u32 *)(r10 -4) = r0
2: (bf) r2 = r10
3: (07) r2 += -4
4: (18) r1 = map[id:64]
...Daraus können wir schließen, dass zur Zeit des Starts unseres Bootloader-Programms der Link zu &woo durch die Bibliothek auf etwas anderes ersetzt wurde libbpf. Zuerst schauen wir uns die Ausgabe an strace:
$ sudo strace -e bpf ./xdp-simple
...
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_ARRAY, key_size=4, value_size=8, max_entries=8, map_name="woo", ...}, 120) = 4
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, prog_name="simple", ...}, 120) = 5Wir sehen, dass libbpf eine Map erstellt hat woo und dann unser Programm simplegeladen hat. Lassen Sie uns genauer anschauen, wie wir das Programm laden:
- wir rufen
xdp_simple_bpf__open_and_loadaus der Dateixdp-simple.skel.h - auf, die
xdp_simple_bpf__loadaus der Dateixdp-simple.skel.h - auf, die
bpf_object__load_skeletonaus der Dateilibbpf/src/libbpf.c - auf, die
bpf_object__load_xattrvonlibbpf/src/libbpf.c
Die letzte Funktion wird unter anderem bpf_object__create_maps, die neue Maps erstellt oder bestehende öffnet und sie in Dateideskriptoren umwandelt. (Hier sehen wir BPF_MAP_CREATE in der Ausgabe strace.) Dann wird die Funktion bpf_object__relocate aufgerufen, und genau das interessiert uns, da wir uns erinnern, was wir gesehen haben woo in der Relocationstabelle. Wenn wir sie untersuchen, gelangen wir schließlich zur Funktion bpf_program__relocate, die sich :
case RELO_LD64:
insn[0].src_reg = BPF_PSEUDO_MAP_FD;
insn[0].imm = obj->maps[relo->map_idx].fd;
break;Also nehmen wir unseren Befehl
18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 llund ersetzen den Quellregister darin durch BPF_PSEUDO_MAP_FD, und der erste IMM für den Dateideskriptor unserer Map ist, wenn er beispielsweise gleich 0xdeadbeef, dann erhalten wir die Anweisung
18 11 00 00 ef eb ad de 00 00 00 00 00 00 00 00 r1 = 0 llSo wird die Information über Maps an ein bestimmtes geladenes BPF-Programm übergeben. Dabei kann die Map sowohl erstellt werden durch BPF_MAP_CREATE, als auch über die ID geöffnet werden durch BPF_MAP_GET_FD_BY_ID.
Zusammenfassend ergibt sich bei der Verwendung libbpf der folgende Algorithmus:
- während der Kompilierung werden für Verweise auf Maps Einträge in der Relocationstabelle erstellt
libbpföffnet das ELF-Objekt, findet alle verwendeten Maps und erstellt dafür Dateideskriptoren- Dateideskriptoren werden als Teil der Anweisung in den Kernel geladen
LD64
Wie Sie verstehen, ist das noch nicht alles, und wir müssen in den Kernel schauen. Glücklicherweise haben wir einen Anhaltspunkt — wir haben den Wert BPF_PSEUDO_MAP_FD in das Quellregister geschrieben und können ihn durchgrepfen, was uns ins Heilige der Heiligen führt — kernel/bpf/verifier.c, wo eine Funktion mit dem charakteristischen Namen den Dateideskriptor durch die Adresse einer Struktur des Typs struct bpf_map:
static int replace_map_fd_with_map_ptr(struct bpf_verifier_env *env) {
...
f = fdget(insn[0].imm);
map = __bpf_map_get(f);
if (insn->src_reg == BPF_PSEUDO_MAP_FD) {
addr = (unsigned long)map;
}
insn[0].imm = (u32)addr;
insn[1].imm = addr >> 32;(den vollständigen Code finden Sie ). Daher können wir unseren Algorithmus ergänzen:
- Während des Ladens überprüft das Programmverifier die korrekte Nutzung der Map und schreibt die Adresse der entsprechenden Struktur.
struct bpf_map
Beim Laden des ELF-Binaries mit libbpf finden viele weitere Ereignisse statt, aber wir werden dies in anderen Artikeln besprechen.
Laden von Programmen und Maps ohne libbpf
Wie versprochen, hier ein Beispiel für Leser, die wissen möchten, wie man ein Programm erstellt und lädt, das Maps nutzt, ohne Hilfe von libbpf. Dies kann nützlich sein, wenn Sie in einer Umgebung arbeiten, in der Sie Abhängigkeiten nicht kompilieren können, oder wenn Sie jeden Byte sparen möchten, oder wenn Sie ein Programm wie schreiben, das BPF-Binärcode zur Laufzeit generiert.
Um es einfacher zu machen, der Logik zu folgen, werden wir unser Beispiel für diese Zwecke umschreiben xdp-simple. Den vollständigen und etwas erweiterten Code des in diesem Beispiel behandelten Programms finden Sie in diesem .
Die Logik unserer Anwendung ist wie folgt:
- Ein Map des Typs
BPF_MAP_TYPE_ARRAYmithilfe des BefehlsBPF_MAP_CREATE, - Erstellen eines Programms, das diese Map nutzt,
- Das Programm an das Interface anschließen
lo,
was auf Menschen verständlich übersetzt wird als
int main(void)
{
int map_fd, prog_fd;
map_fd = map_create();
if (map_fd < 0)
err(1, "bpf: BPF_MAP_CREATE");
prog_fd = prog_load(map_fd);
if (prog_fd < 0)
err(1, "bpf: BPF_PROG_LOAD");
xdp_attach(1, prog_fd);
}Hier map_create erstellt eine Map auf die gleiche Weise, wie wir es im ersten Beispiel des Systemaufrufs gemacht haben bpf — «Kern, bitte erstelle mir eine neue Map in Form eines Arrays von 8 Elementen vom Typ __u64 und gib mir einen Dateideskriptor zurück»:
static int map_create()
{
union bpf_attr attr;
memset(&attr, 0, sizeof(attr));
attr.map_type = BPF_MAP_TYPE_ARRAY,
attr.key_size = sizeof(__u32),
attr.value_size = sizeof(__u64),
attr.max_entries = 8,
strncpy(attr.map_name, "woo", sizeof(attr.map_name));
return syscall(__NR_bpf, BPF_MAP_CREATE, &attr, sizeof(attr));
}Das Programm wird ebenfalls einfach geladen:
static int prog_load(int map_fd)
{
union bpf_attr attr;
struct bpf_insn insns[] = {
...
};
memset(&attr, 0, sizeof(attr));
attr.prog_type = BPF_PROG_TYPE_XDP;
attr.insns = ptr_to_u64(insns);
attr.insn_cnt = sizeof(insns) / sizeof(insns[0]);
attr.license = ptr_to_u64("GPL");
strncpy(attr.prog_name, "woo", sizeof(attr.prog_name));
return syscall(__NR_bpf, BPF_PROG_LOAD, &attr, sizeof(attr));
}Der schwierigste Teil prog_load — das ist die Definition unseres BPF-Programms in Form eines Arrays von Strukturen struct bpf_insn insns[]. Da wir jedoch ein Programm verwenden, das wir in C haben, können wir ein wenig tricksen:
$ llvm-objdump -D --section xdp/simple xdp-simple.bpf.o
0000000000000000 :
0: 85 00 00 00 08 00 00 00 call 8
1: 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0
2: bf a2 00 00 00 00 00 00 r2 = r10
3: 07 02 00 00 fc ff ff ff r2 += -4
4: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
6: 85 00 00 00 01 00 00 00 call 1
7: b7 01 00 00 00 00 00 00 r1 = 0
8: 15 00 04 00 00 00 00 00 if r0 == 0 goto +4
9: 61 01 00 00 00 00 00 00 r1 = *(u32 *)(r0 + 0)
10: 07 01 00 00 01 00 00 00 r1 += 1
11: 63 10 00 00 00 00 00 00 *(u32 *)(r0 + 0) = r1
12: b7 01 00 00 02 00 00 00 r1 = 2
0000000000000068 :
13: bf 10 00 00 00 00 00 00 r0 = r1
14: 95 00 00 00 00 00 00 00 exitInsgesamt müssen wir 14 Anweisungen in Form von Strukturen wie struct bpf_insn (Tipp: Nehmen Sie das Dump oben, lesen Sie den Abschnitt über Anweisungen erneut durch, öffnen Sie und und versuchen Sie, struct bpf_insn insns[] es selbst zu bestimmen):
struct bpf_insn insns[] = {
/* 85 00 00 00 08 00 00 00 call 8 */
{
.code = BPF_JMP | BPF_CALL,
.imm = 8,
},
/* 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0 */
{
.code = BPF_MEM | BPF_STX,
.off = -4,
.src_reg = BPF_REG_0,
.dst_reg = BPF_REG_10,
},
/* bf a2 00 00 00 00 00 00 r2 = r10 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_X,
.src_reg = BPF_REG_10,
.dst_reg = BPF_REG_2,
},
/* 07 02 00 00 fc ff ff ff r2 += -4 */
{
.code = BPF_ALU64 | BPF_ADD | BPF_K,
.dst_reg = BPF_REG_2,
.imm = -4,
},
/* 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll */
{
.code = BPF_LD | BPF_DW | BPF_IMM,
.src_reg = BPF_PSEUDO_MAP_FD,
.dst_reg = BPF_REG_1,
.imm = map_fd,
},
{ }, /* Platzhalter */
/* 85 00 00 00 01 00 00 00 call 1 */
{
.code = BPF_JMP | BPF_CALL,
.imm = 1,
},
/* b7 01 00 00 00 00 00 00 r1 = 0 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 0,
},
/* 15 00 04 00 00 00 00 00 if r0 == 0 goto +4 <LBB0_2> */
{
.code = BPF_JMP | BPF_JEQ | BPF_K,
.off = 4,
.src_reg = BPF_REG_0,
.imm = 0,
},
/* 61 01 00 00 00 00 00 00 r1 = *(u32 *)(r0 + 0) */
{
.code = BPF_MEM | BPF_LDX,
.off = 0,
.src_reg = BPF_REG_0,
.dst_reg = BPF_REG_1,
},
/* 07 01 00 00 01 00 00 00 r1 += 1 */
{
.code = BPF_ALU64 | BPF_ADD | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 1,
},
/* 63 10 00 00 00 00 00 00 *(u32 *)(r0 + 0) = r1 */
{
.code = BPF_MEM | BPF_STX,
.src_reg = BPF_REG_1,
.dst_reg = BPF_REG_0,
},
/* b7 01 00 00 02 00 00 00 r1 = 2 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_K,
.dst_reg = BPF_REG_1,
.imm = 2,
},
/* <LBB0_2>: bf 10 00 00 00 00 00 00 r0 = r1 */
{
.code = BPF_ALU64 | BPF_MOV | BPF_X,
.src_reg = BPF_REG_1,
.dst_reg = BPF_REG_0,
},
/* 95 00 00 00 00 00 00 00 exit */
{
.code = BPF_JMP | BPF_EXIT
},
};Übung für diejenigen, die dies nicht selbst geschrieben haben – finden Sie map_fd.
In unserem Programm bleibt noch ein unveröffentlichtes Element – xdp_attach. Leider können Programme wie XDP nicht über einen Systemaufruf angeschlossen werden bpf. Die Menschen, die BPF und XDP entwickelt haben, stammen aus der Linux-Netzwerkgemeinschaft, was bedeutet, dass sie die für sie am vertrautesten (aber nicht für normale Menschen) Schnittstelle zur Interaktion mit dem Kernel verwendeten: , siehe auch . Der einfachste Implementierungsweg xdp_attach besteht darin, Code aus libbpf, genauer gesagt, aus der Datei , was wir auch getan haben, indem wir ihn leicht verkürzt haben:
Willkommen in der Welt der Netlink-Sockets
Öffnen Sie den Netlink-Socket vom Typ NETLINK_ROUTE:
int netlink_open(__u32 *nl_pid)
{
struct sockaddr_nl sa;
socklen_t addrlen;
int one = 1, ret;
int sock;
memset(&sa, 0, sizeof(sa));
sa.nl_family = AF_NETLINK;
sock = socket(AF_NETLINK, SOCK_RAW, NETLINK_ROUTE);
if (sock < 0)
err(1, "socket");
if (setsockopt(sock, SOL_NETLINK, NETLINK_EXT_ACK, &one, sizeof(one)) < 0)
warnx("netlink Fehlerberichterstattung nicht unterstützt");
if (bind(sock, (struct sockaddr *)&sa, sizeof(sa)) < 0)
err(1, "bind");
addrlen = sizeof(sa);
if (getsockname(sock, (struct sockaddr *)&sa, &addrlen) < 0)
err(1, "getsockname");
*nl_pid = sa.nl_pid;
return sock;
}Lesen aus einem solchen Socket:
static int bpf_netlink_recv(int sock, __u32 nl_pid, int seq)
{
bool multipart = true;
struct nlmsgerr *errm;
struct nlmsghdr *nh;
char buf[4096];
int len, ret;
while (multipart) {
multipart = false;
len = recv(sock, buf, sizeof(buf), 0);
if (len nlmsg_pid != nl_pid)
errx(1, "falsche pid");
if (nh->nlmsg_seq != seq)
errx(1, "UNGÜLTIGE SEQUENZ");
if (nh->nlmsg_flags & NLM_F_MULTI)
multipart = true;
switch (nh->nlmsg_type) {
case NLMSG_ERROR:
errm = (struct nlmsgerr *)NLMSG_DATA(nh);
if (!errm->error)
continue;
ret = errm->error;
// libbpf_nla_dump_errormsg(nh); zu viele Code zum Kopieren...
goto done;
case NLMSG_DONE:
return 0;
default:
break;
}
}
}
ret = 0;
done:
return ret;
}Schließlich ist hier unsere Funktion, die einen Socket öffnet und eine spezielle Nachricht mit einem Dateideskriptor sendet:
static int xdp_attach(int ifindex, int prog_fd)
{
int sock, seq = 0, ret;
struct nlattr *nla, *nla_xdp;
struct {
struct nlmsghdr nh;
struct ifinfomsg ifinfo;
char attrbuf[64];
} req;
__u32 nl_pid = 0;
sock = netlink_open(&nl_pid);
if (sock nla_type = NLA_F_NESTED | IFLA_XDP;
nla->nla_len = NLA_HDRLEN;
/* add XDP fd */
nla_xdp = (struct nlattr *)((char *)nla + nla->nla_len);
nla_xdp->nla_type = IFLA_XDP_FD;
nla_xdp->nla_len = NLA_HDRLEN + sizeof(int);
memcpy((char *)nla_xdp + NLA_HDRLEN, &prog_fd, sizeof(prog_fd));
nla->nla_len += nla_xdp->nla_len;
/* if user passed in any flags, add those too */
__u32 flags = XDP_FLAGS_SKB_MODE;
nla_xdp = (struct nlattr *)((char *)nla + nla->nla_len);
nla_xdp->nla_type = IFLA_XDP_FLAGS;
nla_xdp->nla_len = NLA_HDRLEN + sizeof(flags);
memcpy((char *)nla_xdp + NLA_HDRLEN, &flags, sizeof(flags));
nla->nla_len += nla_xdp->nla_len;
req.nh.nlmsg_len += NLA_ALIGN(nla->nla_len);
if (send(sock, &req, req.nh.nlmsg_len, 0) < 0)
err(1, "send");
ret = bpf_netlink_recv(sock, nl_pid, seq);
cleanup:
close(sock);
return ret;
}Alles ist also bereit für die Tests:
$ cc nolibbpf.c -o nolibbpf
$ sudo strace -e bpf ./nolibbpf
bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_ARRAY, map_name="woo", ...}, 72) = 3
bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_XDP, insn_cnt=15, prog_name="woo", ...}, 72) = 4
+++ beendet mit 0 +++Lassen Sie uns prüfen, ob unser Programm verbunden ist mit lo:
$ ip l show dev lo
1: lo: mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
prog/xdp id 160Lassen Sie uns Pings senden und das Map ansehen:
$ for s in `seq 234`; do sudo ping -f -c 100 127.0.0.1 >/dev/null 2>&1; done
$ sudo bpftool m dump name woo
key: 00 00 00 00 value: 90 01 00 00 00 00 00 00
key: 01 00 00 00 value: 00 00 00 00 00 00 00 00
key: 02 00 00 00 value: 00 00 00 00 00 00 00 00
key: 03 00 00 00 value: 00 00 00 00 00 00 00 00
key: 04 00 00 00 value: 00 00 00 00 00 00 00 00
key: 05 00 00 00 value: 00 00 00 00 00 00 00 00
key: 06 00 00 00 value: 40 b5 00 00 00 00 00 00
key: 07 00 00 00 value: 00 00 00 00 00 00 00 00
8 Elemente gefundenHurra, alles funktioniert. Übrigens, beachten Sie, dass unser Map wieder in Form von Bytes angezeigt wird. Das liegt daran, dass wir im Gegensatz zu libbpf nicht die Typinformationen (BTF) geladen haben. Aber mehr dazu werden wir beim nächsten Mal sprechen.
Entwicklungswerkzeuge
In diesem Abschnitt werden wir uns mit dem minimalen Werkzeugkasten für die BPF-Entwicklung beschäftigen.
Allgemein gesagt, benötigt man für die Entwicklung von BPF-Programmen nichts Besonderes — BPF funktioniert auf jedem anständigen Distribution-Kernel, und die Programme werden mit Hilfe von clang, der aus dem Paket installiert werden kann. Da sich BPF jedoch in der Entwicklung befindet, ändern sich Kernel und Werkzeuge ständig. Wenn Sie keine BPF-Programme mit den veralteten Methoden von 2019 schreiben möchten, müssen Sie es selbst kompilieren.
llvm/clangpahole- Ihr Kernel
bpftool
(Zur Information: Dieser Abschnitt und alle Beispiele im Artikel liefen auf Debian 10.)
llvm/clang
BPF funktioniert gut mit LLVM und obwohl seit kurzem auch mit gcc BPF-Programme kompiliert werden können, findet die gesamte aktuelle Entwicklung für LLVM statt. Daher werden wir zunächst die aktuelle Version clang aus git sammeln:
$ sudo apt install ninja-build
$ git clone --depth 1 https://github.com/llvm/llvm-project.git
$ mkdir -p llvm-project/llvm/build/install
$ cd llvm-project/llvm/build
$ cmake .. -G "Ninja" -DLLVM_TARGETS_TO_BUILD="BPF;X86"
-DLLVM_ENABLE_PROJECTS="clang"
-DBUILD_SHARED_LIBS=OFF
-DCMAKE_BUILD_TYPE=Release
-DLLVM_BUILD_RUNTIME=OFF
$ time ninja
... viele Zeit später
$Jetzt können wir überprüfen, ob alles richtig kompiliert wurde:
$ ./bin/llc --version
LLVM (http://llvm.org/):
LLVM Version 11.0.0git
Optimierte Build.
Standardziel: x86_64-unknown-linux-gnu
Host-CPU: znver1
Registrierte Ziele:
bpf - BPF (Host-Endianness)
bpfeb - BPF (Big Endian)
bpfel - BPF (Little Endian)
x86 - 32-Bit-X86: Pentium-Pro und höher
x86-64 - 64-Bit-X86: EM64T und AMD64(Die Anleitung zum Kompilieren clang habe ich von .)
Wir werden die gerade zusammengestellten Programme nicht installieren, sondern einfach in PATH, zum Beispiel:
export PATH="`pwd`/bin:$PATH"(Das kann hinzugefügt werden in .bashrc oder in eine separate Datei. Ich füge solche Dinge persönlich in ~/bin/activate-llvm.sh und aktiviere es bei Bedarf mit . activate-llvm.sh.)
Pahole und BTF
Dienstprogramm pahole werden beim Kompilieren des Kernels verwendet, um Debug-Informationen im BTF-Format zu erstellen. In diesem Artikel werden wir nicht im Detail auf die BTF-Technologie eingehen, außer darauf, dass sie praktisch ist und wir sie verwenden möchten. Wenn Sie also beabsichtigen, Ihren Kernel zu kompilieren, stellen Sie bitte zuerst sicher, dass pahole (ohne pahole Sie können den Kernel nicht mit der Option kompilieren CONFIG_DEBUG_INFO_BTF:
$ git clone https://git.kernel.org/pub/scm/devel/pahole/pahole.git
$ cd pahole/
$ sudo apt install cmake
$ mkdir build
$ cd build/
$ cmake -D__LIB=lib ..
$ make
$ sudo make install
$ which pahole
/usr/local/bin/paholeKerne für Experimente mit BPF
Bei der Untersuchung der BPF-Möglichkeiten möchte man möglicherweise seinen eigenen Kernel erstellen. Das ist jedoch nicht zwingend erforderlich, da Sie BPF-Programme auch mit dem standardmäßigen Kernel kompilieren und ausführen können. Ein eigener Kernel ermöglicht es Ihnen jedoch, die neuesten BPF-Funktionen zu nutzen, die in Ihrem Distributionskernel bestenfalls in einigen Monaten verfügbar sind oder, wie bei einigen Debugging-Tools, möglicherweise in absehbarer Zeit überhaupt nicht implementiert werden. Zudem gibt Ihnen ein eigener Kernel das Gefühl, wichtig zu sein, und ermöglicht Ihnen, mit Code zu experimentieren.
Um einen Kernel zu erstellen, benötigen Sie zunächst den Kernel selbst und zweitens die Kernel-Konfigurationsdatei. Für Experimente mit BPF können wir das übliche Kernel oder eines der Entwickler-Kernel verwenden. Historisch gesehen erfolgt die Entwicklung von BPF innerhalb der Linux-Netzwerk-Community, und daher werden alle Änderungen früher oder später von David Miller — dem Maintainer des Netzwerkbereichs von Linux — geprüft. Je nach Art der Änderungen — ob es sich um Bugfixes oder neue Funktionen handelt — gelangen Netzwerkänderungen in eines der beiden Kernels — oder . Änderungen für BPF werden ebenso zwischen und , die dann in net und net-next geschossen werden. Weitere Informationen finden Sie in und . Wählen Sie also den Kernel nach Ihren Vorlieben und Anforderungen an die Stabilität des Systems aus, auf dem Sie testen (*-next Kerne gehören zu den instabilsten in der Liste).
Diese Artikel behandelt nicht, wie Sie mit den Konfigurationsdateien des Kernels umgehen — es wird davon ausgegangen, dass Sie entweder bereits wissen, wie das funktioniert, oder selbstständig. Die folgenden Anweisungen sollten jedoch mehr oder weniger ausreichend sein, um ein funktionierendes System mit BPF-Unterstützung zu erhalten.
Laden Sie eines der oben genannten Kerne herunter:
$ git clone git://git.kernel.org/pub/scm/linux/kernel/git/bpf/bpf-next.git
$ cd bpf-nextErstellen Sie eine minimale funktionierende Kernel-Konfiguration:
$ cp /boot/config-`uname -r` .config
$ make localmodconfigAktivieren Sie die BPF-Optionen in der Datei .config nach Ihrem Belieben (höchstwahrscheinlich ist bereits CONFIG_BPF aktiviert, da es von systemd verwendet wird). Hier ist eine Liste der Optionen aus dem Kernel, der für diesen Artikel verwendet wurde:
CONFIG_CGROUP_BPF=y
CONFIG_BPF=y
CONFIG_BPF_LSM=y
CONFIG_BPF_SYSCALL=y
CONFIG_ARCH_WANT_DEFAULT_BPF_JIT=y
CONFIG_BPF_JIT_ALWAYS_ON=y
CONFIG_BPF_JIT_DEFAULT_ON=y
CONFIG_IPV6_SEG6_BPF=y
# CONFIG_NETFILTER_XT_MATCH_BPF ist nicht gesetzt
# CONFIG_BPFILTER ist nicht gesetzt
CONFIG_NET_CLS_BPF=y
CONFIG_NET_ACT_BPF=y
CONFIG_BPF_JIT=y
CONFIG_BPF_STREAM_PARSER=y
CONFIG_LWTUNNEL_BPF=y
CONFIG_HAVE_EBPF_JIT=y
CONFIG_BPF_EVENTS=y
CONFIG_BPF_KPROBE_OVERRIDE=y
CONFIG_DEBUG_INFO_BTF=yJetzt können wir die Module und den Kernel ganz einfach kompilieren und installieren (übrigens kann der Kernel mit der gerade erstellten clang, hinzufügen CC=clang):
$ make -s -j $(getconf _NPROCESSORS_ONLN)
$ sudo make modules_install
$ sudo make installund mit dem neuen Kernel neu starten (ich benutze dafür kexec aus dem Paket kexec-tools):
v=5.8.0-rc6+ # wenn Sie den aktuellen Kernel neu kompilieren, können Sie v=`uname -r`
sudo kexec -l -t bzImage /boot/vmlinuz-$v --initrd=/boot/initrd.img-$v --reuse-cmdline &&
sudo kexec -ebpftool
Das häufigste Tool in diesem Artikel wird das sein bpftool, das mit dem Linux-Kernel geliefert wird. Es wurde von den BPF-Entwicklern für BPF-Entwickler geschrieben und gewartet und ermöglicht die Handhabung aller Arten von BPF-Objekten – das Laden von Programmen, das Erstellen und Ändern von Maps, das Untersuchen des Lebenszyklus des BPF-Ökosystems usw. Die Dokumentation in Form von Quellcode für die man-Seiten kann gefunden werden oder bereits kompiliert, .
Zum Zeitpunkt des Verfassens des Artikels bpftool wird nur fertig für RHEL, Fedora und Ubuntu bereitgestellt (siehe beispielsweise , der die unvollendete Geschichte der Paketierung behandelt bpftool in Debian). Wenn Sie Ihr Kernelsystem jedoch bereits erstellt haben, ist es ganz einfach, bpftool eine kinderleichte Aufgabe:
$ cd ${linux}/tools/bpf/bpftool
# ... geben Sie die Wege zu dem letzten clang an, wie oben beschrieben
$ make -s
Automatische Erkennung der Systemmerkmale:
... libbfd: [ aktiv ]
... disassembler-four-args: [ aktiv ]
... zlib: [ aktiv ]
... libcap: [ aktiv ]
... clang-bpf-co-re: [ aktiv ]
Automatische Erkennung der Systemmerkmale:
... libelf: [ aktiv ]
... zlib: [ aktiv ]
... bpf: [ aktiv ]
$(hier ${linux} — ist Ihr Verzeichnis mit dem Kernel.) Nach dem Ausführen dieser Befehle bpftool wird es im Verzeichnis ${linux}/tools/bpf/bpftool gespeichert und kann im Pfad angegeben werden (vorzugsweise für den Benutzer root) oder einfach kopiert werden nach /usr/local/sbin.
Das Zusammenstellen bpftool ist am besten mit dem neuesten clang, das wie oben beschrieben erstellt wurde, und um zu überprüfen, ob es korrekt erstellt wurde – können Sie beispielsweise den Befehl verwenden
$ sudo bpftool feature probe kernel
Scanne die Systemkonfiguration...
bpf() syscall für unprivilegierte Benutzer ist aktiviert
JIT-Compiler ist aktiviert
JIT-Compiler-Härtung ist deaktiviert
JIT-Compiler kallsyms-Exporte sind für Root aktiviert
...der Ihnen zeigt, welche BPF-Funktionen in Ihrem Kernel aktiviert sind.
Übrigens kann der vorherige Befehl auch als
# bpftool f p kDies wurde analog zu den Tools im Paket gemacht iproute2, wo wir beispielsweise sagen können ip a s eth0 statt ip addr show dev eth0.
Fazit
BPF ermöglicht es, effizient zu messen und die Funktionalität des Kernels im Fluge zu ändern. Das System ist sehr gelungen und entspricht den besten UNIX-Traditionen: Ein einfaches Mechanismus, das das (Re)Programmieren des Kernels ermöglicht, hat es unzähligen Menschen und Organisationen erlaubt, zu experimentieren. Und obwohl die Experimente, genau wie die Entwicklung der BPF-Infrastruktur, noch lange nicht abgeschlossen sind, hat das System bereits ein stabiles ABI, das es ermöglicht, eine zuverlässige und vor allem effektive Geschäftslogik zu entwickeln.
Ich möchte betonen, dass meiner Meinung nach die Technologie so populär geworden ist, weil man einerseits spielen (Die Architektur einer Maschine kann man mehr oder weniger an einem Abend verstehen), und andererseits – Aufgaben lösen kann, die vorher (schön) nicht möglich waren. Diese beiden Komponenten zusammen bringen die Leute dazu, zu experimentieren, und zu träumen, was zu immer neuen innovativen Lösungen führt.
Dieser Artikel, obwohl nicht besonders kurz, ist lediglich eine Einführung in die Welt von BPF und beschreibt nicht die "fortgeschrittenen" Möglichkeiten sowie wichtige Teile der Architektur. Der weitere Plan sieht folgendermaßen aus: Der nächste Artikel wird einen Überblick über die BPF-Programmarttypen geben (in Kernel 5.8 werden 30 Arten von Programmen unterstützt), dann werden wir schließlich anschauen, wie man echte Anwendungen mit BPF schreibt, anhand von Programmen zur Kernel-Trace, gefolgt von einem tiefergehenden Kurs zur BPF-Architektur. Danach kommen Beispiele für Netzwerk- und Sicherheitsanwendungen von BPF.
Die vorherigen Artikel dieser Reihe
Links
— die BPF-Dokumentation von cilium, genauer gesagt von Daniel Borkman, einem der Schöpfer und Maintainer von BPF. Dies ist eine der ersten ernsthaften Beschreibungen, die sich dadurch auszeichnet, dass Daniel genau weiß, wovon er spricht, und es gibt keine Patzer. Besonders in diesem Dokument wird erläutert, wie man mit BPF-Programmen der Typen XDP und TC mithilfe des bekannten Tools
ipaus dem Paketiproute2.— die Originaldatei mit der Dokumentation zu klassischem und anschließend zum erweiterten BPF. Es ist nützlich zu lesen, wenn Sie in Assembly und technische Details der Architektur eintauchen möchten.
. Wird selten, aber präzise aktualisiert, da Alexei Starovoitov (Autor von eBPF) und Andrii Nakryiko — (Maintainer) dort schreiben.
libbpf).. Ein interessanter Twitter-Thread von Quentin Monnet mit Beispielen und Geheimnissen zur Verwendung von bpftool.
. Eine riesige (und immer noch gepflegte) Liste von Links zur BPF-Dokumentation von Quentin Monnet.
Quelle: habr.com
