

Heute gibt es 100.500 Kurse im Bereich Data Science, und es ist bekannt, dass man mit Data Science-Kursen am meisten Geld verdienen kann (warum graben, wenn man Schaufeln verkaufen kann?). Der Hauptnachteil dieser Kurse ist, dass sie nichts mit der echten Arbeit zu tun haben: Niemand wird Ihnen klare, verarbeitete Daten im benötigten Format zur Verfügung stellen. Und wenn Sie die Kurse abgeschlossen haben und beginnen, an einer echten Aufgabe zu arbeiten, tauchen viele Nuancen auf.
Daher starten wir eine Serie von Beiträgen mit dem Titel «Was bei Data Science schiefgehen kann», basierend auf realen Ereignissen, die mir, meinen Freunden und Kollegen widerfahren sind. Wir werden typische Data Science-Aufgaben an realen Beispielen analysieren: wie es tatsächlich abläuft. Heute beginnen wir mit dem Thema Datensammlung.
Das erste, worüber die Menschen stolpern, wenn sie beginnen, mit echten Daten zu arbeiten, ist tatsächlich die Sammlung der relevanten Daten. Die zentrale Botschaft dieses Artikels lautet:
Wir unterschätzen systematisch die Zeit, Ressourcen und Anstrengungen für die Sammlung, Reinigung und Vorbereitung von Daten.
Und vor allem werden wir besprechen, was zu tun ist, um dies zu vermeiden.
Schätzungen zufolge nehmen Datenbereinigung, -transformation, Datenverarbeitung, Merkmalsengineering usw. 80-90 % der Zeit in Anspruch, während die Analyse nur 10-20 % in Anspruch nimmt, obwohl nahezu das gesamte Lernmaterial ausschließlich auf die Analyse fokussiert ist.
Lassen Sie uns ein typisches Beispiel für eine einfache Analyseaufgabe in drei Varianten durchgehen und sehen, welche "erschwerenden Faktoren" auftreten können.
Als Beispiel werden wir erneut ähnliche Variationen der Aufgabe zur Datensammlung und zum Vergleich von Gemeinschaften betrachten für:
- Zwei Subreddits von Reddit
- Zwei Sektionen von Habr
- Zwei Gruppen von Odnoklassniki
Ein hypothetischer Ansatz in der Theorie
Öffnen Sie die Website und lesen Sie die Beispiele. Falls alles klar ist, planen Sie mehrere Stunden zum Lesen, mehrere Stunden für den Code zu den Beispielen und zur Fehlersuche. Fügen Sie mehrere Stunden für die Sammlung hinzu. Planen Sie einige zusätzliche Stunden ein (verdoppeln Sie die Zeit und addieren Sie N Stunden).
Der Schlüsselpunkt: Die zeitliche Schätzung basiert auf Annahmen und Vermutungen darüber, wie viel Zeit es in Anspruch nehmen wird.
Beginnen Sie die Analyse der Zeit mit der Bewertung der folgenden Parameter für die hypothetische Aufgabe, die oben beschrieben wurde:
- Wie groß sind die Daten und wie viel davon muss physisch gesammelt werden (*siehe unten*).
- Wie lange dauert das Zusammenstellen eines Datensatzes und wie lange muss man warten, bevor man den zweiten sammeln kann?
- Code zur Zustandsbewahrung implementieren und einen Neustart initiieren, wenn (und nicht wenn) alles abstürzt.
- Klärung, ob eine Autorisierung notwendig ist und Zeit für den Zugriff über die API einplanen.
- Die Anzahl der Fehler als Funktion der Datenkomplexität festlegen – bewerten anhand der spezifischen Aufgabe: Struktur, wie viele Umwandlungen, was und wie wir extrahieren.
- Netzwerkfehler und Probleme mit dem unkonventionellen Verhalten des Projekts einplanen.
- Bewerten, ob die erforderlichen Funktionen in der Dokumentation vorhanden sind, und falls nicht, wie viel Zeit für die Implementierung einer Lösung benötigt wird.
Das Wichtigste für die zeitliche Einschätzung ist, dass Sie tatsächlich Zeit und Mühe für eine ‚Probebohrung‘ investieren müssen – nur dann wird Ihre Planung adäquat sein. Daher, egal wie sehr man Sie drängt zu sagen: ‚Wie viel Zeit benötigt man für die Datensammlung?‘ – nehmen Sie sich die Zeit für eine vorläufige Analyse und begründen Sie, dass die Zeit je nach realen Parametern der Aufgabe variieren wird.
Und jetzt zeigen wir konkrete Beispiele, wo solche Parameter sich ändern werden.
Der Schlüsselpunkt: Die Bewertung basiert auf der Analyse der Schlüsselfaktoren, die das Volumen und die Komplexität der Arbeit beeinflussen.
Eine bewertung, die auf Vermutungen basiert, ist ein guter Ansatz, wenn die funktionalen Elemente relativ klein sind und nicht viele Faktoren vorhanden sind, die die Struktur der Aufgabe erheblich beeinflussen können. Im Fall mancher Data-Science-Aufgaben jedoch gibt es äußerst viele solcher Faktoren, wodurch dieser Ansatz unzureichend wird.
Vergleich von Reddit-Communities
Lassen Sie uns mit dem einfachsten Fall beginnen (wie sich herausstellen wird). Um ehrlich zu sein, handelt es sich hier um einen nahezu idealen Fall. Lassen Sie uns unsere Checklist zur Komplexität überprüfen:
- Es gibt eine saubere, verständliche und dokumentierte API.
- Ein Token wird extrem einfach und vor allem automatisch generiert.
- Es gibt — mit einer Vielzahl von Beispielen.
- Eine Community, die sich mit der Analyse und Sammlung von Daten auf Reddit beschäftigt (bis hin zu YouTube-Videos, die erklären, wie man den Python-Wrapper verwendet) .
- Die Methoden, die wir benötigen, existieren wahrscheinlich in der API. Darüber hinaus sieht der Code kompakt und sauber aus; hier ist ein Beispiel einer Funktion, die Kommentare zu einem Beitrag sammelt.
def get_comments(submission_id):
reddit = Reddit(check_for_updates=False, user_agent=AGENT)
submission = reddit.submission(id=submission_id)
more_comments = submission.comments.replace_more()
if more_comments:
skipped_comments = sum(x.count for x in more_comments)
logger.debug('Über %d MoreComments übersprungen (%d Kommentare)',
len(more_comments), skipped_comments)
return submission.comments.list()
Entnommen aus Sammlungen nützlicher Dienste zur Einbettung.
Obwohl wir hier den besten Fall haben, sollten wir dennoch mehrere wichtige Faktoren aus der realen Welt berücksichtigen:
- API-Limits – wir sind gezwungen, Daten in Chargen abzurufen (Pausen zwischen den Anfragen usw.).
- Sammlungszeit – für eine vollständige Analyse und den Vergleich muss man beträchtliche Zeit einplanen, damit der Crawler durch die Subreddit navigieren kann.
- Der Bot muss auf dem Server laufen – Sie können ihn nicht einfach auf einem Laptop starten, in einen Rucksack stecken und sich auf den Weg machen. Deshalb habe ich alles auf einem VPS gestartet. Mit dem Aktionscode habrahabr10 können Sie zusätzlich 10% sparen.
- Physische Unzugänglichkeit bestimmter Daten (sie sind nur für Admins sichtbar oder sind zu kompliziert zu sammeln) – das muss berücksichtigt werden, nicht alle Daten können grundsätzlich in angemessener Zeit gesammelt werden.
- Netzwerkfehler: Die Arbeit mit dem Netzwerk ist problematisch.
- Das sind echte, lebendige Daten – sie sind nie sauber.
Natürlich müssen die genannten Aspekte in die Entwicklung einfließen. Die konkreten Stunden/ Tage hängen von der Erfahrung in der Entwicklung oder bei ähnlichen Aufgaben ab. Dennoch sehen wir, dass es sich hier um eine rein ingenieurtechnische Aufgabe handelt, die keine zusätzlichen Maßnahmen zur Lösung erfordert — man kann alles sehr gut bewerten, aufschlüsseln und umsetzen.
Vergleich der Abschnitte von Habra
Kommen wir zu einem interessanteren und nicht-trivialen Fall, dem Vergleich von Strömen und/oder Abschnitten von Habra.
Überprüfen wir unsere Checkliste zur Komplexität — hier wird es notwendig sein, jeden Punkt etwas genauer zu betrachten und zu experimentieren.
- Zuerst denken Sie, dass es eine API gibt, aber die gibt es nicht. Ja, Habra hat eine API, aber die ist nur für Benutzer nicht zugänglich (oder funktioniert vielleicht überhaupt nicht).
- Dann fangen Sie einfach an, HTML zu parsen — "import requests", was kann schon schiefgehen?
- Und wie parsieren wir überhaupt? Der einfachste und am häufigsten verwendete Ansatz besteht darin, über die IDs zu iterieren; dies ist jedoch nicht der effektivste und man muss unterschiedliche Fälle bearbeiten — hier ist beispielsweise die Dichte der realen IDs unter allen existierenden.

Entnommen aus des Artikels gehen. - Rohdaten, die in HTML über das Netzwerk gewickelt sind, sind problematisch. Zum Beispiel möchten Sie die Bewertung eines Artikels sammeln und speichern: Sie extrahieren den Score aus dem HTML und entscheiden, ihn als Zahl für weitere Verarbeitung zu speichern.
1) int(score) wirft einen Fehler: da es auf Habr ein Minus gibt, wie zum Beispiel in der Zeile "–5" – dies ist ein kurzer Gedankenstrich und kein Minuszeichen (überraschend, oder?), weshalb ich irgendwann den Parser mit einem solchen schrecklichen Fix zum Leben erwecken musste.
try: score_txt = post.find(class_="score").text.replace(u"–","-").replace(u"+","+") score = int(score_txt) if check_date(date): post_score += scoreEs gibt keine Daten, Plus oder Minus (wie wir oben in der Funktion check_date sehen können — so war es tatsächlich).
2) Unescaped Sonderzeichen — sie kommen, man muss darauf vorbereitet sein.
3) Die Struktur ändert sich je nach Art des Beitrags.
4) Alte Beiträge können eine **seltsame Struktur** haben.
- Im Wesentlichen muss die Fehlerbehandlung und alles, was passieren kann oder nicht, behandelt werden, und man kann nicht sicher vorhersagen, was schiefgehen wird und wie die Struktur sein könnte und was wo wegfallen könnte — man muss es einfach versuchen und die Fehler berücksichtigen, die der Parser wirft.
- Dann versteht man, dass man in mehreren Threads parsen muss, andernfalls dauert das Parsen in einem einzigen Thread über 30 Stunden (das ist die reine Ausführungszeit eines bereits laufenden Einzel-Thread-Parsers, der schläft und nicht unter irgendwelche Sperren fällt). In dem Artikel führte das irgendwann zu einem solchen Schema:
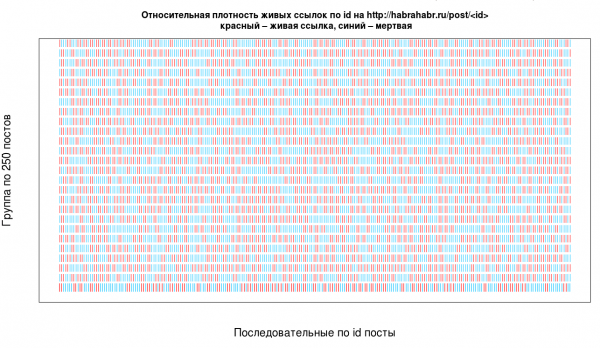
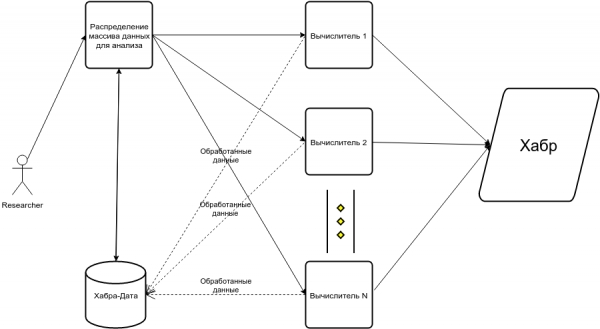
Zusammenfassung des Schwierigkeits-Checklists:
- Arbeiten mit dem Netzwerk und HTML-Parsen mit Iterationen und ID-Durchläufen.
- Dokumente mit heterogener Struktur.
- Viele Stellen, an denen der Code leicht abstürzen kann.
- Es ist notwendig, || Code zu schreiben.
- Fehlende benötigte Dokumentation, Code-Beispiele und/oder eine Community.
Die geschätzte Zeit für diese Aufgabe wird 3-5 Mal höher sein als das Sammeln von Daten von Reddit.
Vergleich von Gruppen in Odnoklassniki
Kommen wir zum technisch interessantesten Fall aus den beschriebenen. Er war für mich interessant, weil er auf den ersten Blick recht trivial aussieht, sich aber als ganz anders erweist – sobald man mit einem Stock darauf zeigt.
Wir beginnen mit unserer Schwierigkeits-Checkliste und merken an, dass viele von ihnen viel komplizierter sein werden, als sie zunächst erscheinen:
- Die API ist vorhanden, aber es fehlen fast vollständig die benötigten Funktionen.
- Für bestimmte Funktionen muss man per E-Mail um Zugriff bitten, das heißt, die Gewährung des Zugriffs erfolgt nicht sofort.
- Die Dokumentation ist schrecklich (um es mal zu sagen, dort vermischen sich überall russische und englische Begriffe, und das absolut inkonsistent — manchmal muss man einfach raten, was von einem an welcher Stelle gewünscht wird) und darüber hinaus ist sie designtechnisch nicht geeignet, um Daten zu erhalten, zum Beispiel .
- Es erfordert eine Sitzung in der Dokumentation, wird jedoch in der Praxis nicht verwendet — und es gibt keine Möglichkeit, die Feinheiten der API-Modi herauszufinden, außer durch Herumprobieren und Hoffen, dass etwas funktioniert.
- Beispiele und eine Community fehlen, der einzige Anhaltspunkt für die Informationsbeschaffung ist ein kleiner in Python (mit wenigen Anwendungsbeispielen).
- Die vielversprechendste Option scheint Selenium zu sein, da viele benötigte Daten unzugänglich sind.
1) Das bedeutet, die Authentifizierung erfolgt über einen fiktiven Benutzer (und die Registrierung erfolgt manuell).2) Mit Selenium gibt es jedoch keine Garantie für eine korrekte und wiederholbare Funktion (definitiv im Fall von ok.ru).
3) Die Website ok.ru enthält JavaScript-Fehler und verhält sich manchmal seltsam und inkonsistent.
4) Es muss Pagination, das Nachladen von Elementen usw. behandelt werden...
5) API-Fehler, die vom Wrapper zurückgegeben werden, müssen workaroundmäßig bearbeitet werden, zum Beispiel so (ein Stück experimenteller Code):
def get_comments(args, context, discussions): pause = 1 if args.extract_comments: all_comments = set() #makes sense to keep track of already processed discussions for discussion in tqdm(discussions): try: comments = get_comments_from_discussion_via_api(context, discussion) except odnoklassniki.api.OdnoklassnikiError as e: if "NOT_FOUND" in str(e): comments = set() else: print(e) bp() pass all_comments |= comments time.sleep(pause) return all_commentsMein liebstes Fehler war:
OdnoklassnikiError("Error(code: 'None', description: 'HTTP error', method: 'discussions.getComments', params: …)")6) Letztendlich scheint die Kombination aus Selenium + API die vernünftigste Lösung zu sein.
- Es ist notwendig, den Zustand zu speichern und das System neu zu starten, sowie viele Fehler zu behandeln, einschließlich inkonsistentem Verhalten der Website — und zwar solche Fehler, die ziemlich schwer vorstellbar sind (es sei denn, Sie schreiben professionell Parser, natürlich).
Die geschätzte Zeit für diese Aufgabe wird 3- bis 5-mal höher sein als beim Sammeln von Informationen von Habra. Während wir bei Habra einen direkten Ansatz mit HTML-Parsen verwenden, können wir bei OK an kritischen Stellen mit der API arbeiten.
Fazit
Egal, wie sehr man von Ihnen eine "Vorort"-Zeitschätzung verlangt (wir haben schließlich heute Planung!), ist es praktisch nie möglich, die Ausführungszeit qualitativ zu schätzen, ohne die Parameter der Aufgabe zu analysieren.
Wenn wir etwas philosophischer sprechen, dann passen die Schätzstrategien im Agile-Bereich gut zu ingenieurtechnischen Aufgaben, aber bei experimentelleren und, in gewissem Sinne, "kreativen" und forschungsorientierten Aufgaben, also weniger vorhersehbaren, entstehen Schwierigkeiten, ähnlich wie in den Beispielen, die wir hier behandelt haben.
Natürlich ist die Datensammlung ein sehr anschauliches Beispiel – in der Regel scheint diese Aufgabe unglaublich einfach und technisch unproblematisch zu sein, und genau in den Details versteckt sich hier häufig der Teufel. Und gerade bei dieser Aufgabe kann man das gesamte Spektrum möglicher Varianten aufzeigen, was schiefgehen kann und wie sehr sich die Arbeit in die Länge ziehen kann.
Wenn man die Eigenschaften der Aufgabe flüchtig betrachtet, wirken Reddit und OK ähnlich: Es gibt eine API und einen Python-Wrapper, aber im Grunde genommen ist der Unterschied enorm. Betrachtet man diese Parameter, scheint das Parsen von Habr komplizierter zu sein als bei OK – in der Praxis ist das genau umgekehrt, und das lässt sich leicht herausfinden, indem man einfache Experimente zur Analyse der Aufgabendetails durchführt.
Nach meiner Erfahrung ist der effektivste Ansatz eine grobe Zeitabschätzung, die Sie für die grundlegende Analyse, erste einfache Experimente und das Lesen der Dokumentation benötigen. Diese Schritte ermöglichen es Ihnen, eine präzise Schätzung für die gesamte Arbeit abzugeben. In den Begriffen der beliebten Agile-Methodik bitte ich, ein Ticket für die „Schätzung der Aufgabenparameter“ zu erstellen, auf dessen Basis ich beurteilen kann, was im Rahmen eines „Sprints“ machbar ist und eine genauere Schätzung für jede Aufgabe abgeben kann.
Deshalb scheint das überzeugendste Argument zu sein, das einem 'nicht-technischen' Spezialisten aufzeigt, wie sehr die Zeit- und Ressourcenaufwände je nach noch zu schätzenden Parametern variieren können.
Quelle: habr.com
