

Hallo! Ich bin Vadim Madison, und ich leite die Entwicklung der System Platform bei Avito. Wir haben bereits mehrfach darüber gesprochen, wie wir von einer monolithischen Architektur zu Mikrodiensten wechseln. Es ist an der Zeit, zu teilen, wie wir unsere Infrastruktur transformiert haben, um das Beste aus Mikrodiensten herauszuholen, ohne uns darin zu verlieren. Wie uns PaaS dabei unterstützt, wie wir den Deployment-Prozess vereinfacht haben und die Erstellung eines Mikrodienstes auf einen Klick reduziert haben – lesen Sie weiter. Nicht alles, was ich hier schreibe, wurde bei Avito vollständig umgesetzt; ein Teil davon ist, wie wir unsere Plattform weiterentwickeln.
(Am Ende dieses Artikels werde ich auch über die Möglichkeit sprechen, an einem dreitägigen Seminar von Mikrodienst-Architektur-Experte Chris Richardson teilzunehmen).

Wie wir zu Mikrodiensten gekommen sind
Avito ist eines der größten Kleinanzeigenportale der Welt, auf dem täglich über 15 Millionen neue Anzeigen veröffentlicht werden. Unser Backend verarbeitet mehr als 20.000 Anfragen pro Sekunde. Derzeit haben wir mehrere Hundert Mikrodienste.
Wir bauen die Mikrodienstarchitektur seit mehreren Jahren auf. Wie genau – unsere Kollegen geben Einblicke in unserem Vortrag auf der RIT++ 2017. Auf dem CodeFest 2017 (siehe. ), Sergey Orlov und Mikhail Prokopchuk haben ausführlich erklärt, warum der Übergang zu Mikrodiensten für uns so wichtig war und welche Rolle Kubernetes dabei spielte. Jetzt tun wir alles, um die mit dieser Architektur verbundenen Skalierungsaufwände zu minimieren.
Ursprünglich haben wir kein Ökosystem geschaffen, das uns umfassend bei der Entwicklung und Einführung von Mikrodiensten unterstützt. Wir haben einfach praktische Open-Source-Lösungen gesammelt, sie bei uns implementiert und den Entwicklern empfohlen, sich damit auseinanderzusetzen. Am Ende mussten sie zu vielen verschiedenen Orten (Dashboards, interne Dienste) gehen, was sie in ihrem Bestreben bestärkte, den alten Weg im Monolithen weiterzugehen. In den nachstehenden Diagrammen ist in Grün dargestellt, was der Entwickler in irgendeiner Weise selbst macht, und in Gelb die Automatisierung.
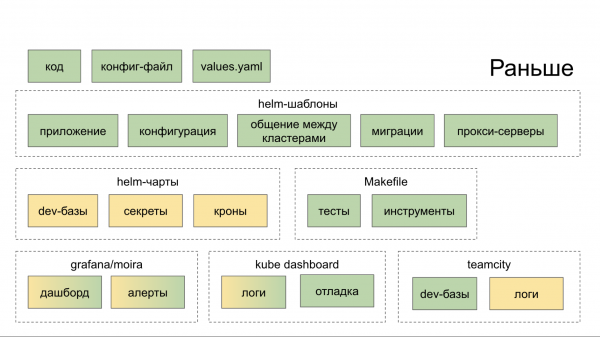
Jetzt kann in der CLI-Utility PaaS mit einem Befehl ein neuer Dienst erstellt und mit zwei weiteren Befehlen eine neue Datenbank hinzugefügt sowie in die Staging-Umgebung deployt werden.
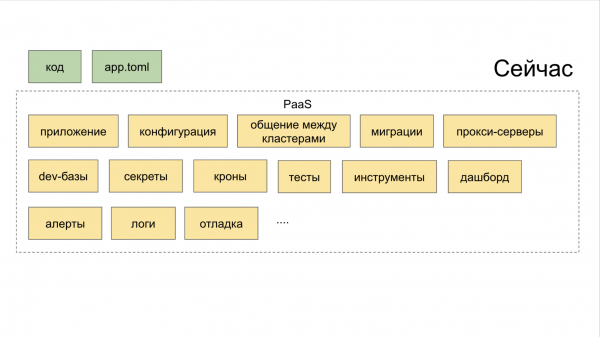
Wie man die Ära der 'Mikrodienstzerstückelung' überwinden kann
Bei einer monolithischen Architektur waren die Entwickler aufgrund der Notwendigkeit, die Konsistenz der Produktänderungen zu gewährleisten, gezwungen, sich damit auseinanderzusetzen, was bei den Nachbarn geschieht. Mit der neuen Architektur sind die Kontexte der Dienste nicht mehr voneinander abhängig.
Darüber hinaus erfordert eine effektive Microservice-Architektur die Etablierung zahlreicher Prozesse, darunter:
• Protokollierung;
• Anfrageverfolgung (Jaeger);
• Fehleraggregation (Sentry);
• Status-, Nachrichten- und Ereignismanagement aus Kubernetes (Event Stream Processing);
• Race Limit / Circuit Breaker (Hystrix kann verwendet werden);
• Überwachung der Service-Verknüpfungen (wir verwenden Netramesh);
• Monitoring (Grafana);
• Build-Prozesse (TeamCity);
• Kommunikation und Benachrichtigung (Slack, E-Mail);
• Aufgabenverfolgung (Jira);
• Dokumentation erstellen.
Um sicherzustellen, dass das System beim Scaling seine Integrität und Effektivität nicht verliert, haben wir die Organisation der Microservices bei Avito neu gedacht.
Wie wir mit Microservices umgehen
Die einheitliche "Partei-Politik" unter den zahlreichen Microservices von Avito wird unterstützt durch:
- Schichtung der Infrastruktur;
- das Konzept Platform as a Service (PaaS);
- Monitoring aller Aktivitäten der Microservices.
Die Ebenen der Infrastrukturabstraktion bestehen aus drei Schichten. Lassen Sie uns von oben nach unten gehen.
A. Obere Ebene – Service Mesh. Zunächst haben wir Istio ausprobiert, aber es stellte sich heraus, dass es zu viele Ressourcen verbraucht, was in unserem Umfang zu kostspielig ist. Daher entwickelte unser leitender Architekt Alexander Lukjantschenko eine eigene Lösung – (verfügbar als Open Source), die wir jetzt in der Produktion verwenden und die im Vergleich zu Istio deutlich weniger Ressourcen benötigt (aber auch nicht alle Funktionen von Istio bietet).
B. Mittlere Ebene – Kubernetes. Darauf stellen wir Mikrodienste bereit und betreiben sie.
C. Untere Ebene – Bare Metal. Wir verwenden keine Clouds und keine Lösungen wie OpenStack, sondern setzen vollständig auf Bare Metal.
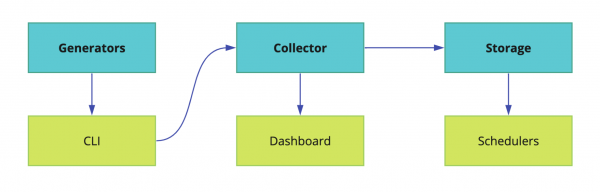
Alle Schichten werden durch PaaS integriert. Diese Plattform besteht wiederum aus drei Teilen.
I. Generatoren, die über ein CLI-Werkzeug gesteuert werden. Dieses Werkzeug hilft den Entwicklern, Mikrodienste richtig und mit minimalem Aufwand zu erstellen.
II. Zusammenfassender Sammler mit Kontrolle aller Werkzeuge über ein gemeinsames Dashboard.
III. Speicher. Es interagiert mit Planern, die automatisch Trigger für bedeutende Aktionen setzen. Dank dieses Systems wird keine Aufgabe übersehen, nur weil jemand vergessen hat, sich eine Aufgabe in Jira zu setzen. Dafür verwenden wir ein internes Tool namens Atlas.
Die Implementierung von Mikrodiensten bei Avito erfolgt ebenfalls nach einem einheitlichen Schema, was die Kontrolle über sie in jeder Phase der Entwicklung und Veröffentlichung vereinfacht.
So funktioniert die Standard-Pipeline zur Entwicklung eines Mikrodienstes
Im Großen und Ganzen sieht die Kette zur Erstellung eines Mikrodienstes folgendermaßen aus:
CLI-Push → Continuous Integration → Bake → Deployment → Künstliche Tests → Canary-Tests → Squeeze Testing → Produktion → Wartung.
Lassen Sie uns diese Schritte genau in dieser Reihenfolge durchgehen.
CLI-Push
• Erstellung des Mikrodienstes.
Wir haben lange daran gearbeitet, jeden Entwickler in der Erstellung von Mikrodiensten zu schulen. Dazu haben wir detaillierte Anleitungen in Confluence geschrieben. Doch die Schemas wurden geändert und ergänzt. Das Ergebnis — ein Flaschenhals entstand am Anfang des Prozesses: Der Start von Mikrodiensten dauerte viel länger als zulässig, und dennoch traten beim Erstellen häufig Probleme auf.
Schließlich haben wir ein einfaches CLI-Tool entwickelt, das die grundlegenden Schritte zur Erstellung eines Mikrodienstes automatisiert. Tatsächlich ersetzt es den ersten git push. Hier ist, was es konkret macht.
— Es erstellt den Dienst basierend auf einer Vorlage — Schritt für Schritt, im Wizard-Modus. Wir haben Vorlagen für die wichtigsten Programmiersprachen im Backend von Avito: PHP, Golang und Python.
— Mit einem Befehl wird die Umgebung für die lokale Entwicklung auf einem bestimmten Rechner eingerichtet — Minikube wird gestartet, Helm-Charts werden automatisch generiert und im lokalen Kubernetes ausgeführt.
— Es verbindet die benötigte Datenbank. Der Entwickler muss keine IP-Adresse, Benutzernamen oder Passwort kennen, um auf die benötigte Datenbank zuzugreifen — sei es lokal, in der Stage oder in der Produktion. Außerdem wird die Datenbank sofort in einer ausfallsicheren Konfiguration mit Load Balancing bereitgestellt.
— Es führt selbst ein Live-Build aus. Angenommen, der Entwickler hat etwas im Mikrodienst über seine IDE geändert. Das Tool erkennt die Änderungen im Dateisystem und erstellt die Anwendung (für Golang) neu und startet sie neu. Für PHP leiten wir einfach das Verzeichnis in den Container und der Live-Reload erfolgt "automatisch".
— Generiert Autotests. In Form von Vorlagen, die jedoch einsatzbereit sind.
• Microservice-Deployment.
Das Bereitstellen eines Microservices war bei uns früher etwas mühsam. Erforderlich waren zwingend:
I. Dockerfile.
II. Konfiguration.
III. Helm-Chart, das an sich schon umfangreich ist und Folgendes umfasst:
— die Charts selbst;
— die Templates;
— spezifische Werte unter Berücksichtigung verschiedener Umgebungen.
Wir haben uns von den Schmerzen beim Überarbeiten der Kubernetes-Manifesten befreit, und jetzt werden sie automatisch generiert. Aber das Wichtigste ist, dass wir das Deployment auf ein Minimum vereinfacht haben. Ab sofort haben wir ein Dockerfile und der gesamte Konfigurationsaufwand wird von den Entwicklern in einer einzigen kurzen Datei, app.toml, festgelegt.

Auch die Bearbeitung der app.toml erfordert jetzt nur eine Minute. Wir legen fest, wie viele Kopien des Dienstes erstellt werden sollen (auf dem Entwicklungsserver, auf Staging, in der Produktion) und geben die Abhängigkeiten an. Beachten Sie die Zeile size = „small“ im Block [engine]. Dies ist das Limit, das dem Dienst über Kubernetes zugewiesen wird.
Auf Basis der Konfiguration werden dann automatisch alle erforderlichen Helm-Charts generiert und die Verbindungen zu den Datenbanken hergestellt.
• Grundlegende Validierung. Diese Überprüfungen sind ebenfalls automatisiert.
Zu beachten ist:
— ob ein Dockerfile vorhanden ist;
— ob eine app.toml vorhanden ist;
— Gibt es eine Dokumentation;
— Sind die Abhängigkeiten in Ordnung;
— Sind die Alert-Regeln festgelegt.
Zum letzten Punkt: Der Serviceinhaber legt selbst fest, welche Produktmetriken überwacht werden sollen.
• Erstellung der Dokumentation.
Bisher ein problematischer Bereich. Es scheint das Offensichtlichste zu sein, ist aber gleichzeitig das am häufigsten „vergessene“ und damit die verwundbarste Stelle in der Kette.
Es ist notwendig, dass eine Dokumentation für jeden Microservice vorhanden ist. Diese enthält folgende Abschnitte.
I. Kurze Beschreibung des Services. Ein paar Sätze darüber, was er tut und wozu er benötigt wird.
II. Link zum Architekturdiagramm. Es ist wichtig, dass man bei einem flüchtigen Blick leicht erkennen kann, ob Sie Redis zum Caching oder als primären Datenspeicher im persistierenden Modus verwenden. Bei Avito ist dies momentan ein Link zu Confluence.
III. Runbook. Ein kurzer Leitfaden zum Starten des Services und zu den Besonderheiten im Umgang damit.
IV. FAQ, in dem es gut wäre, mögliche Probleme vorwegzunehmen, mit denen Ihre Kollegen bei der Arbeit mit dem Service konfrontiert werden könnten.
V. Beschreibung der Endpunkte für die API. Sollten Sie keine Zielpunkte angeben, werden mit hoher Wahrscheinlichkeit Ihre Kollegen für die Kosten aufkommen, deren Mikrodienste mit Ihrem verbunden sind. Aktuell verwenden wir dafür Swagger und unsere Lösung namens brief.
VI. Labels. Oder Marker, die anzeigen, zu welchem Produkt, zu welcher Funktionalität oder zu welcher Abteilung des Unternehmens der Dienst gehört. Sie helfen, schnell zu erkennen, ob Sie Funktionalität entwickeln, die vor einer Woche für denselben Geschäftsbereich von Ihren Kollegen bereitgestellt wurde.
VII. Besitzer oder Besitzer des Dienstes. In den meisten Fällen kann er – oder sie – mittels PaaS automatisch bestimmt werden, aber zur Sicherheit verlangen wir vom Entwickler, diese manuell anzugeben.
Schließlich ist es eine gute Praxis, Dokumentationen ähnlich wie bei Code-Reviews zu überprüfen.
Continuous Integration
- Vorbereitung der Repositories.
- Pipeline in TeamCity erstellen.
- Rechte festlegen.
- Dienstbesitzer suchen. Hier liegt ein hybrides Modell vor – manuelle Markierung und minimale Automatisierung von PaaS. Vollautomatische Modelle führen zu Problemen, wenn Dienste zur Unterstützung an ein anderes Entwicklungsteam übergeben werden oder wenn beispielsweise der Entwickler des Dienstes das Unternehmen verlässt.
- Registrierung des Dienstes in Atlas (siehe oben). Mit all seinen Besitzern und Abhängigkeiten.
- Überprüfung der Migrationen. Wir überprüfen, ob sich darunter potenziell gefährliche Migrationen befinden. Zum Beispiel könnte eine von ihnen ein alter table enthalten oder etwas anderes, das die Kompatibilität des Datenmodells zwischen verschiedenen Versionen des Dienstes beeinträchtigt. In diesem Fall wird die Migration nicht ausgeführt, sondern in eine Warteliste gesetzt – PaaS muss den Dienstbesitzer benachrichtigen, wenn es sicher ist, sie anzuwenden.
Bake
Der nächste Schritt ist das Verpacken der Dienste vor dem Deployment.
- Bau der Anwendung. Klassisch – in ein Docker-Image.
- Generierung von Helm-Charts für den Dienst selbst und die damit verbundenen Ressourcen. Darunter auch für Datenbanken und Cache. Sie werden automatisch gemäß der app.toml-Konfiguration erstellt, die in der CLI-Push-Phase generiert wurde.
- Erstellung von Tickets für Administratoren zur Öffnung von Ports (wenn erforderlich).
- Durchführung von Unit-Tests und Berechnung der Codeabdeckung.. Wenn der Code Coverage unter dem festgelegten Schwellenwert liegt, wird der Service wahrscheinlich nicht in die Bereitstellung (Deployment) übergehen. Liegt der Wert an der Grenze des Zulässigen, erhält der Service einen „pessimistischen“ Koeffizienten: Das bedeutet, dass der Entwickler bei fehlender Verbesserung im Zeitverlauf eine Benachrichtigung erhält, dass es keinen Fortschritt bei den Tests gibt (und etwas unternommen werden sollte).
- Berücksichtigung von Einschränkungen bei Speicher und CPU. Hauptsächlich schreiben wir Mikrodienste in Golang und führen sie in Kubernetes aus. Daraus ergibt sich eine Besonderheit des Golang: Bei der Ausführung werden standardmäßig alle Kerne auf dem Rechner genutzt, es sei denn, die Variable GOMAXPROCS wird ausdrücklich gesetzt. Wenn mehrere solcher Dienste auf einem Rechner gestartet werden, beginnen sie, um Ressourcen zu konkurrieren, was die gegenseitige Beeinträchtigung zur Folge hat. In den Grafiken unten ist zu sehen, wie die Ausführungszeit variieren kann, wenn die Anwendung ohne Wettbewerb und im Ressourcenrennen gestartet wird. (Die Quellcodes der Grafiken befinden sich ).
Ausführungszeit, je weniger, desto besser. Maximum: 643 ms, Minimum: 42 ms. Das Bild ist anklickbar.
Zeit für die Operation, je weniger, desto besser. Maximum: 14091 ns, Minimum: 151 ns. Das Bild ist anklickbar.
Im Vorbereitungsschritt der Assemblierung kann diese Variable entweder direkt festgelegt oder die Bibliothek verwendet werden. von den Jungs bei Uber.
Deployment
• Überprüfung der Konventionen. Bevor Sie beginnen, Assemblierungen des Services in die vorgesehenen Umgebungen zu liefern, müssen Sie Folgendes überprüfen:
— API-Endpunkte.
— Übereinstimmung der Antworten der API-Endpunkte mit dem Schema.
— Format der Protokolle.
— Festlegung der Header bei Anfragen an den Service (momentan erfolgt dies durch netramesh)
— Festlegung eines Eigentümer-Markers beim Versenden von Nachrichten an den Bus (event bus). Dies ist wichtig, um die Kohärenz der Services über den Bus hinweg zu verfolgen. In den Bus können sowohl idempotente Daten gesendet werden, die die Kohärenz der Services nicht erhöhen (was gut ist), als auch Geschäftsdaten, die die Kohärenz der Services stärken (was sehr schlecht ist!). Und in dem Moment, in dem diese Kohärenz ein Problem darstellt, hilft es, zu verstehen, wer den Bus beschreibt und liest, um die Services richtig zu trennen.
Obwohl es bei Avito derzeit nicht viele Konventionen gibt, erweitert sich der Pool. Je mehr solcher Vereinbarungen in einer verständlichen und praktischen Form für das Team vorhanden sind, desto einfacher ist es, die Konsistenz zwischen den Mikrodiensten aufrechtzuerhalten.
Synthesetests
• Testen in einem geschlossenen Kreis. Dafür verwenden wir derzeit die Open-Source-Lösung . Zuerst wird die tatsächliche Auslastung des Dienstes aufgezeichnet, danach wird sie im geschlossenen Kontur emuliert.
• Lasttests. Wir streben danach, alle Dienste auf optimale Leistung zu bringen. Jede Version eines Dienstes sollte einem Lasttest unterzogen werden, um die aktuelle Leistung des Dienstes sowie die Unterschiede zu vorherigen Versionen zu verstehen. Wenn die Performance nach einem Update um die Hälfte sinkt, ist das ein deutliches Signal für die Betreiber: Hier muss sich intensiv mit dem Code beschäftigt werden, um die Situation zu beheben.
Basierend auf den gesammelten Daten arbeiten wir beispielsweise daran, das Auto-Scaling richtig zu implementieren und letztendlich zu verstehen, inwieweit der Dienst skalierbar ist.
Bei Lasttests überprüfen wir, ob der Ressourcenverbrauch den festgelegten Grenzen entspricht. Dabei konzentrieren wir uns insbesondere auf die Extremwerte.
a) Wir betrachten die Gesamtauslastung.
— Zu niedrig — es funktioniert wahrscheinlich etwas gar nicht, wenn die Auslastung plötzlich um mehrere Male sinkt.
— Zu hoch — Optimierung ist erforderlich.
b) Wir betrachten die RPS-Schwelle.
Hier vergleichen wir die Unterschiede zwischen der aktuellen und der vorherigen Version sowie die Gesamtzahl. Wenn ein Service beispielsweise 100 RPS anzeigt, könnte das entweder auf eine schlecht geschriebene Software hinweisen oder Teil seiner Spezifikation sein. In jedem Fall ist das ein Anlass, den Service genau unter die Lupe zu nehmen.
Wenn die RPS jedoch zu hoch sind, könnte dies ein Zeichen für einen Bug sein, und einer der Endpoints erfüllt möglicherweise keine nützliche Funktion mehr, sondern reagiert einfach nur auf einen bestimmten Trigger. return true;
Canary-Tests
Nachdem die synthetischen Tests abgeschlossen sind, testen wir die Funktionalität des Mikroservices mit einer kleinen Anzahl von Nutzern. Wir beginnen vorsichtig, mit einem minimalen Prozentsatz der erwarteten Zielgruppe – weniger als 0,1%. In dieser Phase ist es sehr wichtig, dass im Monitoring die richtigen technischen und produktbezogenen Metriken festgelegt sind, damit sie schnellstmöglich auf Probleme im Service hinweisen. Die minimalen Canary-Testzeiten betragen 5 Minuten, die Hauptzeit 2 Stunden. Für komplexe Services stellen wir die Zeit manuell ein.
Wir analysieren:
— Metriken, die spezifisch für die Sprache sind, insbesondere php-fpm-Worker;
— Fehler in Sentry;
— Antwortstatus;
— Antwortzeiten (Response Time), sowohl exakt als auch durchschnittlich;
— Latenz;
— Behandelte und unbehandelte Ausnahmen;
— Produktmetriken.
Squeeze Testing
Squeeze Testing wird auch als "Pressing"-Test bezeichnet. Diese Methode wurde von Netflix eingeführt. Dabei füllen wir zunächst eine Instanz mit echtem Traffic bis zum Versagen und bestimmen damit ihr Limit. Anschließend fügen wir eine weitere Instanz hinzu und belasten diese Kombination erneut bis zum Maximum; so erkennen wir deren Höchstleistung und die Differenz zum ersten "Squeeze". Dieses Verfahren setzen wir fort, indem wir schrittweise weitere Instanzen hinzuzufügen und die Veränderungen analysieren.
Die Testergebnisse des "Pressing"-Tests fließen ebenfalls in eine zentrale Metrikdatenbank ein, wo wir entweder die Ergebnisse mit künstlicher Last anreichern oder diese vollständig durch "synthetische" Daten ersetzen.
Produktion
• Skalierung. Bei der Einführung eines Dienstes in die Produktion überwachen wir, wie er skaliert. Nur die CPU-Werte zu überwachen, hat sich als ineffektiv erwiesen, basierend auf unseren Erfahrungen. Auto-Scaling funktioniert im Reinen mit einem RPS-Benchmark, allerdings nur für spezifische Dienste, wie zum Beispiel Online-Streaming. Daher konzentrieren wir uns in erster Linie auf die für die Anwendung relevanten Produktmetriken.
Insgesamt analysieren wir bei der Skalierung:
— die CPU- und RAM-Werte,
— die Anzahl der Anfragen in der Warteschlange,
— Antwortzeit,
— Prognose basierend auf gesammelten historischen Daten.
Bei der Skalierung eines Dienstes ist es ebenfalls entscheidend, seine Abhängigkeiten zu überwachen, um zu vermeiden, dass wir den ersten Dienst in der Kette skalieren, während die anderen, auf die er zugreift, unter der Last zusammenbrechen. Um eine für den gesamten Dienstpool akzeptable Last festzulegen, betrachten wir die historischen Daten des „nächsten“ abhängigen Dienstes (unter Berücksichtigung der Kombination aus CPU- und RAM-Werten sowie spezifischen App-Metriken) und vergleichen diese mit den historischen Daten des initiierenden Dienstes und so weiter durch die gesamte „Abhängigkeitskette“ von oben nach unten.
Wartung
Nachdem der Mikrodienst in Betrieb genommen wurde, können wir Trigger darauf setzen.
Hier sind typische Situationen, in denen Trigger ausgelöst werden.
— Potenziell gefährliche Migrationen wurden entdeckt.
— Sicherheitsupdates wurden veröffentlicht.
— Der Dienst wurde seit langem nicht mehr aktualisiert.
— Die Last auf den Dienst hat deutlich nachgelassen oder einige seiner Produktmetriken liegen außerhalb der Norm.
— Der Dienst erfüllt nicht mehr die neuen Anforderungen der Plattform.
Ein Teil der Trigger sorgt für die Stabilität des Betriebs, ein anderer fungiert als Systemwartungsfunktion – zum Beispiel, wenn ein Service lange nicht aktualisiert wurde und sein Basis-Image nicht mehr den Sicherheitsanforderungen entspricht.
Dashboard
Kurz gesagt, das Dashboard ist das Steuerungselement unseres gesamten PaaS.
- Eine zentrale Informationsquelle über den Service, mit Daten zu Testabdeckungen, der Anzahl von Images, Produktionskopien, Versionen usw.
- Ein Werkzeug zur Filterung von Daten nach Services und Labels (Markierungen für Zugehörigkeit zu Business Units, Produktfunktionen usw.).
- Ein Integrationswerkzeug für Infrastruktur-Tools zur Nachverfolgung, Protokollierung und Überwachung.
- Ein zentraler Dokumentationspunkt für die Services.
- Ein zentraler Überblick über alle Ereignisse im Zusammenhang mit den Services.
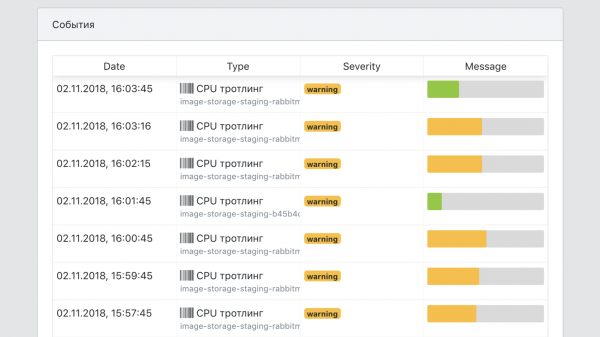
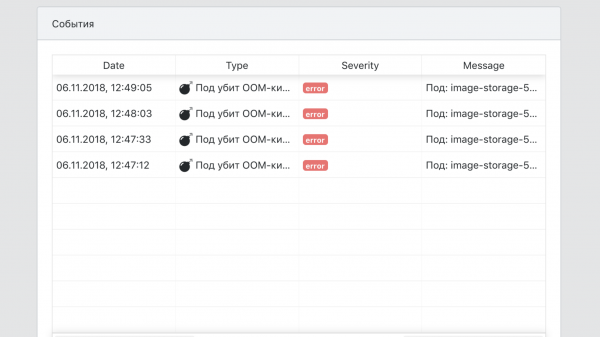
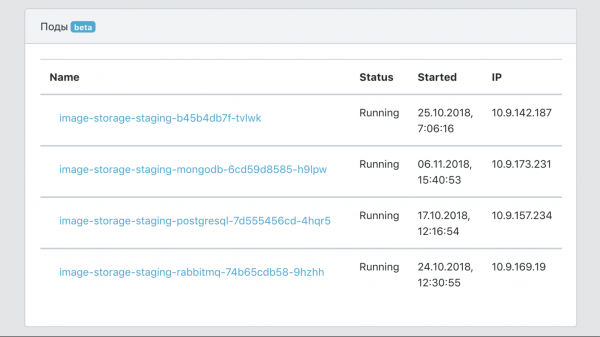
Gesamt
Vor der Einführung von PaaS konnte ein neuer Entwickler mehrere Wochen benötigen, um sich in alle notwendigen Tools für den Einsatz eines Mikrodienstes in der Produktion einzuarbeiten: Kubernetes, Helm, die speziellen internen Aspekte von TeamCity, die Konfiguration der Verbindung zu Datenbanken und Caches in einer ausfallsicheren Weise usw. Jetzt dauert das nur noch ein paar Stunden – das Quickstart lesen und den Service einrichten.
Ich habe zu diesem Thema einen Vortrag auf der HighLoad++ 2018 gehalten, den Sie sich ansehen können. und .
Bonus-Track für diejenigen, die bis zum Ende gelesen haben.
Wir bei Avito organisieren ein internes dreitägiges Training für Entwickler von , einem Experten für Mikrodienste. Wir möchten die Möglichkeit zur Teilnahme an diesem Training an einen der Leser dieses Beitrags verschenken. Das Programm des Trainings wurde veröffentlicht.
Das Training findet vom 5. bis 7. August in Moskau statt. Dies sind Arbeitstage, die vollständig ausgelastet sein werden. Mittagessen und Schulung finden in unserem Büro statt, die Reise und Unterkunft muss der ausgewählte Teilnehmer selbst bezahlen.
Sie können sich für die Teilnahme anmelden. Von Ihnen benötigt werden — eine Antwort auf die Frage, warum genau Sie an dem Training teilnehmen sollten, und Informationen, wie Sie kontaktiert werden können. Bitte antworten Sie auf Englisch, da Chris den Teilnehmer auswählen wird, der an dem Training teilnehmen wird.
Wir werden den Namen des Teilnehmers bis spätestens 19. Juli in einem Update zu diesem Beitrag und in den sozialen Netzwerken von Avito für Entwickler (AvitoTech auf , , ) bekannt geben.
Quelle: habr.com
