

Der Markt für verteiltes Rechnen und Big Data wächst, wenn man den Quellen Glauben schenken mag, jährlich um 18-19 %. Daher bleibt die Auswahl der Software für diese Zwecke relevant. In diesem Beitrag werden wir zunächst darauf eingehen, warum verteiltes Rechnen nötig ist, dann detaillierter die Auswahl der Software betrachten, die Anwendung von Hadoop mit Cloudera besprechen, und abschließend über die Hardwarewahl und deren verschiedene Auswirkungen auf die Leistung sprechen. , wächst jährlich um 18-19 %. Das heißt, die Wahl der Software für diese Zwecke bleibt relevant. In diesem Beitrag beginnen wir damit, warum verteilte Berechnungen erforderlich sind, werden genauer auf die Auswahl der Software eingehen, erzählen von der Anwendung von Hadoop mit Cloudera und zum Schluss sprechen wir über die Auswahl der Hardware und wie diese auf verschiedene Weise die Leistung beeinflusst.

Warum sind verteilte Rechenverfahren im gewöhnlichen Geschäft nötig? Die Antwort ist gleichzeitig einfach und komplex. Einfach — weil wir in den meisten Fällen relativ unkomplizierte Berechnungen pro Informationseinheit durchführen. Komplex — weil es eine enorme Menge an Informationen gibt. Infolgedessen müssen wir Somit sind die Nutzungsszenarien recht universell: Berechnungen können überall dort angewendet werden, wo eine große Anzahl von Metriken auf einem noch größeren Datensatz berücksichtigt werden muss.
Ein aktuelles Beispiel: die Pizzakette Dodo Pizza. Basierend auf der Analyse der Kundenbestellungen haben Nutzer bei der Auswahl einer Pizza mit beliebigem Belag normalerweise nur sechs Grundsets von Zutaten plus ein paar zufällige Elemente. In Übereinstimmung damit hat die Pizzeria ihre Einkaufsstrategien angepasst. Zudem konnte sie den Kunden besser zusätzliche Produkte empfehlen, die im Bestellprozess angeboten werden, was zu einer Steigerung des Gewinns führte.
Ein weiteres Beispiel: Die Reduzierung des Sortiments um 40 % in bestimmten Filialen von H&M konnte erreicht werden, während das Verkaufsniveau beibehalten wurde. Dies wurde ermöglicht, indem schlecht verkaufte Artikel ausgeschlossen wurden, wobei die Saisonalität berücksichtigt wurde.
Wahl des Werkzeugs
Der Branchenstandard für diese Art von Berechnungen ist Hadoop. Warum? Weil Hadoop ein hervorragendes, gut dokumentiertes Framework ist, das mit einer Vielzahl von Tools und Bibliotheken ausgestattet ist. Sie können große Mengen sowohl strukturierter als auch unstrukturierter Daten einspeisen, während das System selbst diese auf die Rechenressourcen verteilt. Diese Ressourcen können jederzeit erweitert oder deaktiviert werden – das ist die horizontale Skalierbarkeit in Aktion.
Im Jahr 2017 stellte das einflussreiche Beratungsunternehmen Gartner dass Hadoop bald obsolet sein wird. Der Grund ist relativ einfach: Analysten glauben, dass Unternehmen massenhaft in die Cloud migrieren werden, da sie dort nach tatsächlichem Verbrauch von Rechenressourcen bezahlen können. Ein weiterer wichtiger Faktor, der angeblich Hadoop 'begraben' könnte, ist die Geschwindigkeit. Denn Alternativen wie Apache Spark oder Google Cloud DataFlow arbeiten schneller als das zugrunde liegende MapReduce von Hadoop.
Hadoop basiert auf mehreren Kerntechnologien, wobei die herausragendsten die MapReduce-Technologie (ein System zur Verteilung von Daten für Berechnungen zwischen Servern) und das HDFS-Dateisystem sind. Letzteres wurde speziell für die Speicherung von Informationen entwickelt, die über die Knoten eines Clusters verteilt sind: Jeder Block fester Größe kann auf mehreren Knoten platziert werden, und durch Replikation wird die Ausfallsicherheit des Systems gewährleistet. Anstelle einer Dateitabelle kommt ein spezieller Server namens NameNode zum Einsatz.
Das untenstehende Diagramm zeigt die Funktionsweise von MapReduce. Im ersten Schritt werden die Daten nach bestimmten Kriterien aufgeteilt, im zweiten Schritt werden sie auf Berechnungsressourcen verteilt, und im dritten Schritt erfolgt die Berechnung.
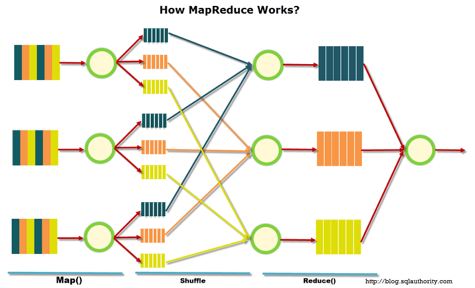
Ursprünglich wurde MapReduce von Google für seine Suchmaschinenbedürfnisse entwickelt. Anschließend wurde MapReduce als Open Source verfügbar gemacht, und Apache übernahm das Projekt. Google hat sich mittlerweile auf andere Lösungen ausgerichtet. Ein interessanter Punkt ist, dass Google derzeit ein Projekt namens Google Cloud Dataflow hat, das als nächster Schritt nach Hadoop positioniert wird, quasi als dessen schnelle Alternative.
Bei genauerer Betrachtung wird deutlich, dass Google Cloud Dataflow auf einer Variante von Apache Beam basiert, wobei Apache Beam ein gut dokumentiertes Framework von Apache Spark enthält. Dies führt dazu, dass die Ausführungsgeschwindigkeit der Lösungen nahezu identisch ist. Zudem funktioniert Apache Spark hervorragend mit dem HDFS-Dateisystem, was eine Bereitstellung auf Hadoop-Servern ermöglicht.
Wenn wir das Volumen der Dokumentation und der verfügbaren Lösungen zu Hadoop und Spark im Vergleich zu Google Cloud Dataflow berücksichtigen, wird die Wahl des Werkzeugs offensichtlich. Darüber hinaus können Ingenieure selbst entscheiden, welchen Code sie – für Hadoop oder Spark – basierend auf der Aufgabe, Erfahrung und Qualifikation ausführen möchten.
Cloud oder lokaler Server
Der Trend zum umfassenden Umstieg in die Cloud hat sogar einen interessanten Begriff wie Hadoop-as-a-Service hervorgebracht. In diesem Szenario ist das Management der angebundenen Server von entscheidender Bedeutung. Denn trotz seiner Popularität ist reines Hadoop leider ein recht komplexes Tool, das viel manuelle Arbeit erfordert. Man muss die Server einzeln konfigurieren, ihre Kennzahlen überwachen und zahlreiche Parameter sorgfältig einstellen. Insgesamt ist es eine anspruchsvolle Aufgabe, bei der die Gefahr besteht, Fehler zu machen oder etwas zu übersehen.
Deshalb erfreuen sich verschiedene Distributionen großer Beliebtheit, die von Anfang an mit benutzerfreundlichen Bereitstellungs- und Verwaltungstools ausgestattet sind. Eine der beliebtesten Distributionen, die Spark unterstützt und vieles vereinfacht, ist Cloudera. Es gibt sowohl eine kostenpflichtige als auch eine kostenlose Version, wobei die letzte alle grundlegenden Funktionen bietet, ohne Einschränkung der Anzahl der Nodes.

Während der Einrichtung wird Cloudera Manager per SSH eine Verbindung zu Ihren Servern herstellen. Ein interessanter Punkt: Es ist besser, während der Installation anzugeben, dass diese so genannte Paketen: speziellen Paketen, in denen alle notwendigen Komponenten enthalten sind, die so konfiguriert sind, dass sie reibungslos zusammenarbeiten. Im Grunde genommen handelt es sich um eine verbesserte Version eines Paketmanagers.
Nach der Installation erhalten wir ein Verwaltungskonsole für den Cluster, auf der Sie die Telemetrie der Cluster, installierte Dienste sehen können. Zudem haben Sie die Möglichkeit, Ressourcen hinzuzufügen/zu entfernen und die Konfiguration des Clusters zu bearbeiten.
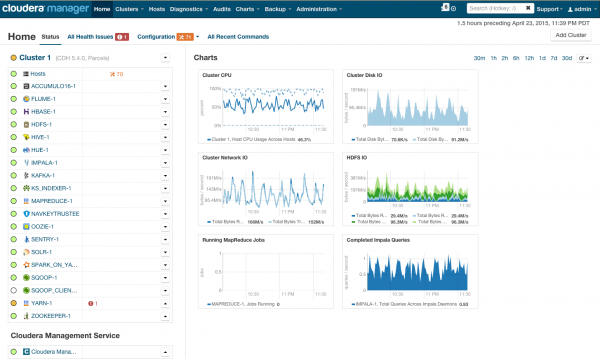
Das Ergebnis ist das Cockpit der Rakete, die Sie in die glorreiche Zukunft von Big Data befördern wird. Aber bevor wir 'Los' sagen, schauen wir uns mal unter die Haube.
Anforderungen an die Hardware
Auf ihrer Website erwähnt Cloudera verschiedene mögliche Konfigurationen. Die allgemeinen Prinzipien, nach denen sie aufgebaut sind, werden in der Abbildung dargestellt:
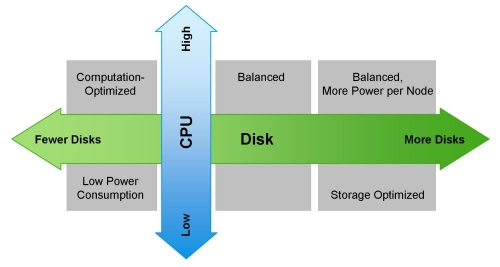
Die optimistische Aussicht kann durch MapReduce getrübt werden. Wenn wir erneut das Diagramm aus dem vorherigen Abschnitt betrachten, wird deutlich, dass ein MapReduce-Job in nahezu allen Fällen auf ein „Flaschenhals“-Problem stoßen kann, wenn Daten von der Festplatte oder aus dem Netzwerk gelesen werden. Dies wird auch im Blog von Cloudera hervorgehoben. Daher ist für schnelle Berechnungen, einschließlich derer, die über Spark durchgeführt werden, der häufig für Echtzeitanalysen genutzt wird, die Geschwindigkeit der Eingabe/Ausgabe von größter Bedeutung. Es ist daher entscheidend, bei der Nutzung von Hadoop auf einen Cluster zu setzen, der über ausgewogene und schnelle Maschinen verfügt, was, gelinde gesagt, nicht immer in der Cloud-Infrastruktur gegeben ist.
Die Balance in der Lastverteilung wird durch den Einsatz von OpenStack-Virtualisierung auf Servern mit leistungsstarken Multi-Core-CPUs erreicht. Den Datenknoten werden eigene Prozessorressourcen und bestimmte Festplatten zugewiesen. In unserer Lösung Atos Codex Data Lake Engine erreichen wir eine umfassende Virtualisierung, wodurch wir sowohl in Bezug auf die Leistung profitieren (der Einfluss der Netzwerk-Infrastruktur wird minimiert) als auch die Gesamtkosten (TCO) gesenkt werden (überflüssige physische Server werden eliminiert).
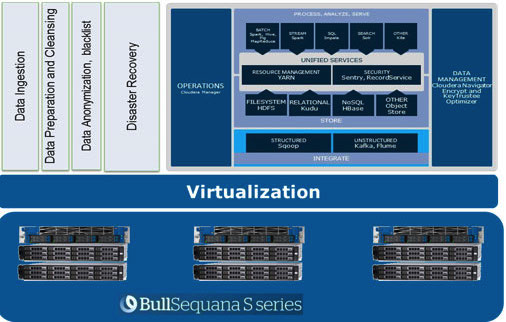
Wenn wir die BullSequana S200 Server verwenden, erhalten wir eine gleichmäßige Auslastung ohne signifikante Engpässe. Die minimale Konfiguration umfasst 3 BullSequana S200 Server, jeder mit zwei JBOD, zusätzlich können optional weitere S200 Server mit jeweils vier Datenknoten hinzugefügt werden. Hier ist ein Beispiel für die Auslastung im TeraGen-Test:
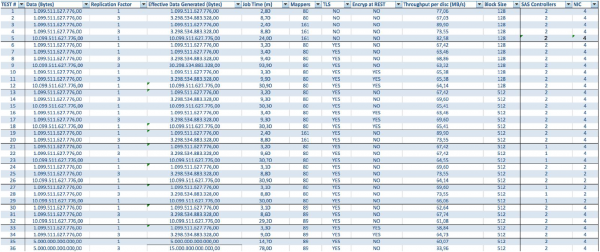
Tests mit verschiedenen Datenmengen und Replikationswerten zeigen ähnliche Ergebnisse hinsichtlich der Lastverteilung zwischen den Clusterknoten. Unten ist ein Diagramm der Festplattendatenzugriffsverteilung aus den Leistungstests dargestellt.
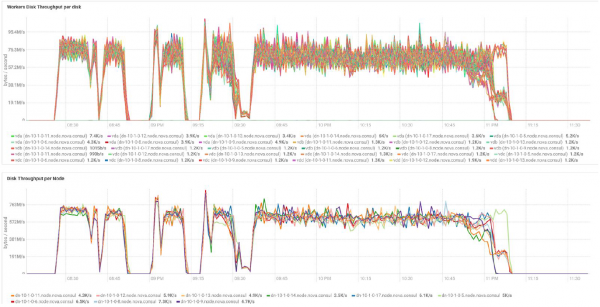
Die Berechnungen wurden auf Basis der minimalen Konfiguration von 3 BullSequana S200 Servern durchgeführt. Sie umfasst 9 Datenknoten und 3 Hauptknoten sowie reservierte virtuelle Maschinen für den Fall eines OpenStack Virtualization-Schutzes. Testergebnis TeraSort: Mit einem Blocksize von 512 MB und einem Replikationsfaktor von drei beträgt die Verschlüsselungszeit 23,1 Minuten.
Wie kann das System erweitert werden? Für den Data Lake Engine sind verschiedene Erweiterungsarten verfügbar:
- Datenübertragungsknoten: für jeweils 40 TB nutzbaren Speicher
- Analytische Knoten mit der Möglichkeit zur Installation eines Grafikprozessors
- Weitere Optionen, abhängig von den Geschäftsbedürfnissen (zum Beispiel, wenn Kafka und ähnliche Technologien benötigt werden)
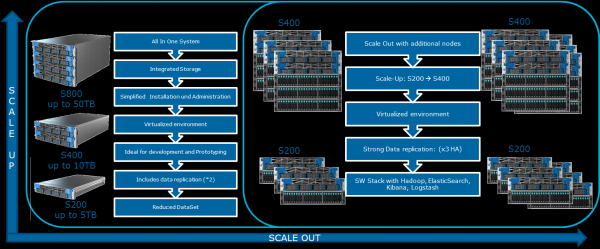
Das Atos Codex Data Lake Engine umfasst sowohl die Server als auch die vorinstallierte Software, einschließlich des lizenzierten Cloudera-Pakets; das Hadoop-System, OpenStack mit virtuellen Maschinen auf Basis von RedHat Enterprise Linux, Datenreplikations- und Backup-Systeme (darunter auch durch die Backup-Node und Cloudera BDR - Backup und Disaster Recovery). Atos Codex Data Lake Engine war die erste Lösung mit Virtualisierung, die zertifiziert wurde. .
Wenn Sie weitere Informationen wünschen, beantworten wir gerne Ihre Fragen in den Kommentaren.
Quelle: habr.com
