

Hallo!
Mein Name ist Michail, ich bin der IT-Direktor bei «Sportmaster». Ich möchte eine Geschichte darüber teilen, wie wir die Herausforderungen während der Pandemie gemeistert haben.
In den ersten Tagen der neuen Realität kam der gewohnte Offline-Verkauf von «Sportmaster» zum Erliegen, und die Belastung unseres Online-Kanals, insbesondere im Hinblick auf die Lieferung an die Kundenadresse, stieg um das Zehnfache. Innerhalb weniger Wochen haben wir unser riesiges Offline-Geschäft in ein Online-Geschäft transformiert und unseren Service an die Bedürfnisse unserer Kunden angepasst.
Im Grunde genommen wurde das, was ursprünglich unsere Nebentätigkeit war, zum Hauptgeschäft. Die Bedeutung jeder Online-Bestellung stieg extrem an. Jeder Rubel, den ein Kunde in das Unternehmen brachte, musste gesichert werden.
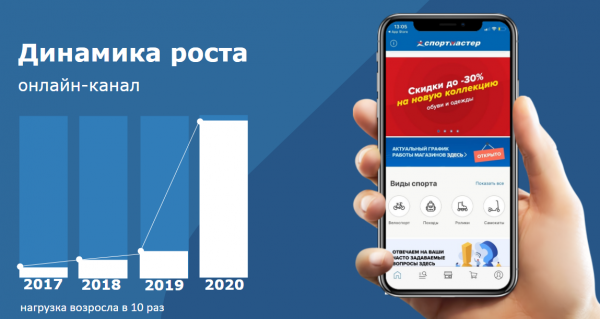
Um schnell auf die Anfragen der Kunden reagieren zu können, haben wir ein zusätzliches Kontaktzentrum in der Unternehmenszentrale eröffnet, das jetzt rund 285.000 Anrufe pro Woche entgegennehmen kann. Gleichzeitig haben wir 270 Filialen auf ein neues, kontaktloses und sicheres Betriebsformat umgestellt, was es den Kunden ermöglichte, Bestellungen zu erhalten, während die Mitarbeiter ihre Arbeitsplätze behalten konnten.
Während des Transformationsprozesses standen wir vor zwei wesentlichen Herausforderungen. Erstens gab es eine spürbare Zunahme der Belastung für unsere Online-Ressourcen (wie wir damit umgegangen sind, wird Sergej erzählen). Zweitens ist der Fluss seltener (vor COVID) Operationen exponentiell gestiegen, was ein großes Maß an schneller Automatisierung erforderte. Um dieses Problem zu lösen, mussten wir umgehend Ressourcen von Bereichen abziehen, die zuvor unsere Hauptschwerpunkte waren. Wie wir das gemeistert haben, wird Elena berichten.
Betrieb von Online-Diensten
Sergej Kolesnikow, verantwortlich für den Betrieb des Online-Shops und der Mikrodienste
Seit der Schließung unserer Einzelhandelsgeschäfte für Besucher verzeichnen wir einen Anstieg von Metriken wie der Anzahl der Nutzer, der Bestellungen, die über unsere App aufgegeben werden, und der Anfragen an die Anwendungen.
 Anzahl der Bestellungen vom 18. bis 31. März
Anzahl der Bestellungen vom 18. bis 31. März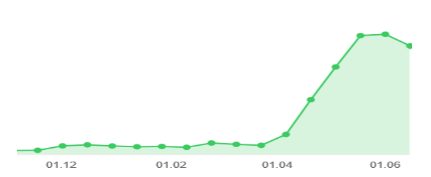 Anzahl der Anfragen an die Mikrodienste für Online-Zahlungen
Anzahl der Anfragen an die Mikrodienste für Online-Zahlungen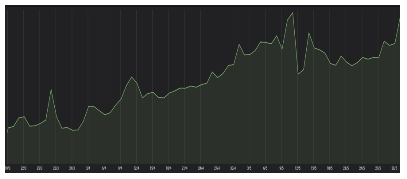 Anzahl der auf der Website getätigten Bestellungen
Anzahl der auf der Website getätigten Bestellungen
Im ersten Diagramm sehen wir, dass das Wachstum etwa das 14-fache betrug, im zweiten das 4-fache. Besonders aussagekräftig erachten wir dabei die Metrik der Antwortzeiten unserer Anwendungen.
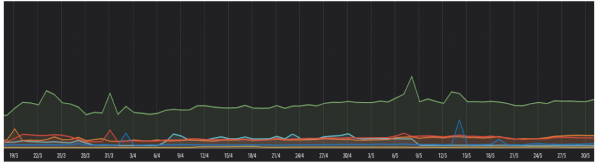
In diesem Diagramm sehen wir die Reaktionen von Frontend und Anwendungen, und wir haben festgestellt, dass wir kein signifikantes Wachstum bemerkt haben.
Das liegt in erster Linie daran, dass wir Ende 2019 mit den Vorbereitungsarbeiten begonnen haben. Derzeit sind unsere Dienste reserviert und die Ausfallsicherheit ist auf Ebene der physischen Server, der Virtualisierungssysteme, der Container und der Dienste in diesen gewährleistet. Gleichzeitig ermöglichen unsere Serverressourcen Mehrfachbelastungen.
Das Hauptinstrument, das uns in dieser ganzen Geschichte geholfen hat, ist unser Überwachungssystem. Allerdings hatten wir vor nicht allzu langer Zeit kein einheitliches System, das es uns ermöglicht hätte, Metriken auf allen Ebenen zu sammeln, vom physischen Equipment und Hardware bis hin zu Geschäftsmetriken.
Formal gab es in der Firma Monitoring, aber in der Regel war es verstreut und lag in der Verantwortung spezifischer Abteilungen. Tatsächlich hatten wir fast nie ein gemeinsames Verständnis dafür, was genau passiert ist, wenn ein Vorfall auftrat; es gab keine Information, und oft führte das zu einer endlosen Suche nach der Problemursache und deren Behebung.
Irgendwann dachten wir, dass es genug ist — wir benötigten ein einheitliches System, um das gesamte Bild zu sehen. Die Haupttechnologien, die in unserem Stack enthalten sind, sind Zabbix als Alert-Center und zur Speicherung von Metriken, Prometheus zur Erfassung und Speicherung von Anwendungsmetriken, die ELK-Stack für das Logging und die Speicherung der Daten des gesamten Monitoring-Systems sowie Grafana zur Visualisierung, Swagger, Docker und andere nützliche und Ihnen vertraute Tools.
Dabei nutzen wir nicht nur die am Markt verfügbaren Technologien, sondern entwickeln auch eigene Lösungen. Zum Beispiel erstellen wir Services zur Integration von Systemen miteinander, also eine Art API zur Erfassung von Metriken. Zudem arbeiten wir an eigenen Monitoring-Systemen — auf der Ebene der Geschäftsmetriken verwenden wir UI-Tests. Außerdem haben wir einen Bot in Telegram zur Benachrichtigung der Teams.
Darüber hinaus bemühen wir uns, das Monitoring-System für die Teams zugänglich zu machen, damit sie ihre Metriken eigenständig speichern und verwalten können, einschließlich der Möglichkeit, Alerts für spezifische Metriken einzurichten, die nicht von breiterer Anwendung sind.
Innerhalb des gesamten Systems streben wir proaktive und möglichst schnelle Lokalisierungen von Vorfällen an. Zudem ist die Anzahl unserer Mikrodienste und Systeme in letzter Zeit erheblich gewachsen, was auch die Zahl der Integrationen erhöht. Im Rahmen der Optimierung des Diagnosprozesses von Vorfällen auf Integrationsniveau entwickeln wir ein System, das es ermöglicht, systemübergreifende Prüfungen durchzuführen und Ergebnisse zu liefern, wodurch wir die grundlegenden Probleme im Zusammenhang mit Importen und dem Zusammenspiel der Systeme identifizieren können.
Natürlich gibt es noch viel Raum für Wachstum und Entwicklung in Bezug auf das Betriebsmanagement der Systeme, und wir arbeiten aktiv daran. Weitere Informationen zu unserem Überwachungssystem finden Sie hier. .
Technische Tests
Serguei Orlow, leitet das Kompetenzzentrum für Web- und mobile Entwicklung
Seit der Schließung physischer Geschäfte sehen wir uns in der Entwicklung mit verschiedenen Herausforderungen konfrontiert. An erster Stelle steht der Anstieg der Last. Es ist klar, dass, wenn keine entsprechenden Maßnahmen ergriffen werden, das System unter hoher Last mit einem unglücklichen Knall in eine Kürbisform verwandelt werden kann, entweder durch einen vollständigen Leistungsabfall oder möglicherweise sogar durch einen kompletten Ausfall.
Der zweite Aspekt, der etwas weniger offensichtlich ist, besteht darin, dass das System unter hoher Last sehr schnell angepasst werden musste, um sich an die Veränderungen der Geschäftsprozesse anzupassen. Manchmal mehrfach am Tag. Viele Unternehmen haben die Regel, dass bei großen Marketingaktivitäten keine Änderungen am System vorgenommen werden sollen. Überhaupt keine, solange es läuft.
Bei uns gab es im Grunde genommen einen unendlichen Black Friday, während wir gleichzeitig das System ändern mussten. Und jeder Fehler, jedes Problem, jeder Ausfall im System hätte dem Geschäft sehr teuer zu stehen kommen können.
Um es vorweg zu nehmen: Wir haben es geschafft, diese Herausforderungen zu meistern. Alle Systeme hielten der Last stand, ließen sich leicht skalieren, und es gab keine größeren technischen Ausfälle.
Es gibt vier Säulen, auf denen die Fähigkeit des Systems basiert, hohe sprungartige Lasten zu bewältigen. Die erste ist das Monitoring, das Sie weiter oben gelesen haben. Ohne ein gut etabliertes Monitoring-System ist es nahezu unmöglich, Engpässe im System zu identifizieren. Ein gutes Monitoring-System ist wie bequeme Freizeitkleidung — es sollte angenehm und auf Sie abgestimmt sein.
Der zweite Aspekt ist das Testing. Wir nehmen diesen Punkt sehr ernst: Wir schreiben klassische Unit-Tests, Integrationstests, Lasttests und viele andere für jedes System. Zudem erstellen wir eine Teststrategie und bemühen uns, das Testlevel so weit zu steigern, dass manuelle Prüfungen nicht mehr notwendig sind.
Der dritte Schlüssel ist der CI/CD-Pipeline. Die Prozesse für den Build, das Testen und das Deployment von Anwendungen sollten so weit wie möglich automatisiert sein, ohne manuelle Eingriffe. Das Thema CI/CD-Pipeline ist ziemlich umfangreich, und ich werde es nur am Rande behandeln. Es genügt zu erwähnen, dass wir eine Checkliste für die CI/CD-Pipeline haben, die von jedem Produktteam mit Hilfe von Kompetenzzentren durchgegangen wird.
 Hier ist die Checkliste
Hier ist die Checkliste
Auf diese Weise werden viele Ziele erreicht. Dazu gehören die Versionierung von APIs und Feature-Toggles, um eine Flut von Releases zu vermeiden, und das Erreichen von Testabdeckungen in einem Umfang, der es ermöglicht, dass das Testen vollständig automatisiert ist und die Deployments nahtlos erfolgen.
Der vierte Schlüssel sind die Architekturprinzipien und technischen Entscheidungen. Man kann viel und lange über Architektur sprechen, aber ich möchte ein paar Prinzipien hervorheben, auf die ich gerne aufmerksam machen möchte.
Zunächst einmal sollten spezialisierte Werkzeuge für bestimmte Aufgaben ausgewählt werden. Ja, das klingt offensichtlich, und es ist klar, dass man Nägel mit einem Hammer einschlagen sollte und spezielle Schraubendreher benötigt, um Armbanduhren zu zerlegen. In unserem Zeitalter streben viele Werkzeuge jedoch nach Universalität, um den größtmöglichen Benutzerkreis abzudecken: Datenbanken, Caches, Frameworks und mehr. Wenn wir zum Beispiel die Datenbank MongoDB betrachten, arbeitet sie mit Multidokumenten-Transaktionen, während die Datenbank Oracle mit JSON arbeitet. Man könnte also denken, dass alles für alles verwendet werden kann. Doch wenn wir für Leistung eintreten, müssen wir die Stärken und Schwächen jedes Werkzeugs klar verstehen und die für unsere spezifischen Aufgaben wichtigen Tools auswählen.
Zweitens muss jede Erhöhung der Komplexität bei der Systemgestaltung gerechtfertigt sein. Wir müssen dies ständig im Hinterkopf behalten; das Prinzip des niedrigen Kopplungsgrades ist allgemein bekannt. Ich denke, dass es sowohl auf der Ebene eines bestimmten Dienstes, auf der Ebene des gesamten Systems als auch auf der Ebene der architektonischen Landschaft angewendet werden sollte. Ebenso ist die Fähigkeit zur horizontalen Skalierung jeder Systemkomponente unter Last wichtig. Wenn man diese Fähigkeit hat, wird das Skalieren kein Problem darstellen.
Wenn es um technische Lösungen geht, haben wir die Produktteams gebeten, ein frisches Set von Empfehlungen, Ideen und Lösungen vorzubereiten, die sie im Rahmen der Vorbereitung auf die nächste Lastwelle umgesetzt haben.
Caches
Die Wahl zwischen lokalen und verteilten Caches sollte bewusst getroffen werden. Manchmal ist es sinnvoll, beide innerhalb eines Systems zu verwenden. Zum Beispiel haben wir Systeme, in denen ein Teil der Daten im Wesentlichen ein Schaufenster-Cache ist, das heißt, die Quelle der Aktualisierungen liegt außerhalb des Systems, und das System ändert diese Daten nicht. Für diesen Ansatz verwenden wir den lokalen Caffeine Cache.
Es gibt Daten, die das System aktiv während des Betriebs ändert. Hier setzen wir einen verteilten Cache mit Hazelcast ein. Dieser Ansatz ermöglicht es uns, die Vorteile eines verteilten Caches dort zu nutzen, wo sie wirklich gebraucht werden, und die Betriebskosten für die Datenzirkulation im Hazelcast-Cluster zu minimieren, wo wir darauf verzichten können. Über Caches haben wir viel geschrieben. und .
Darüber hinaus hat der Wechsel des Serialisierers zu Kryo in Hazelcast uns einen guten Leistungsschub gegeben. Der Übergang von ReplicatedMap zu IMap + Near Cache in Hazelcast hat es uns ermöglicht, die Datenbewegungen im Cluster zu minimieren.
Ein kleiner Tipp: Bei der massenhaften Invalidierung des Caches kann manchmal die Taktik des Aufwärmens eines zweiten Caches mit anschließendem Wechsel darauf anwendbar sein. Auf den ersten Blick scheint dieser Ansatz zu einem doppelten Speicherverbrauch zu führen, aber in der Praxis, in den Systemen, in denen dies praktiziert wurde, wurde der Speicherverbrauch verringert.
Reaktiver Stack
Wir setzen den reaktiven Stack bereits in einer Vielzahl von Systemen ein. In unserem Fall handelt es sich um Webflux oder Kotlin mit Koroutinen. Besonders gut eignet sich der reaktive Stack dort, wo wir langsame Input-Output-Operationen erwarten. Zum Beispiel bei dem Aufruf langsamer Dienste, der Arbeit mit dem Dateisystem oder Speichersystemen.
Das wichtigste Prinzip ist, blockierende Aufrufe zu vermeiden. Unter der Haube der reaktiven Frameworks läuft eine begrenzte Anzahl aktiver Service-Threads. Wenn wir uns nicht vorsichtig verhalten und einen direkten blockierenden Aufruf tätigen, wie etwa einen Aufruf des JDBC-Treibers, wird das System einfach stehenbleiben.
Versuchen Sie, Fehler in eigene Runtime-Exceptions zu verwandeln. Der ursprüngliche Ausführungsfluss des Programms wechselt zu den reaktiven Frameworks, die Ausführung des Codes wird nichtlinear. Daher ist es sehr schwierig, Probleme anhand von Stack-Traces zu diagnostizieren. Eine Lösung besteht darin, verständliche, objektive Runtime-Exceptions für jeden Fehler zu erstellen.
Elasticsearch
Bei der Nutzung von Elasticsearch sollten Sie keine ungenutzten Daten auswählen. Dies ist im Grunde genommen ein sehr einfacher Rat, aber meistens wird genau das vergessen. Wenn Sie mehr als 10.000 Datensätze auf einmal auswählen müssen, sollten Sie Scroll verwenden. Im Vergleich dazu ähnelt es ein wenig einem Cursor in einer relationalen Datenbank.
Verwenden Sie Postfilter nicht ohne Notwendigkeit. Bei großen Datenmengen in der Hauptabfrage belastet dieser Vorgang die Datenbank erheblich.
Nutzen Sie Bulk-Operationen, wo immer dies anwendbar ist.
API
Planen Sie bei der Gestaltung der API Anforderungen zur Minimierung der übertragenen Daten ein. Dies ist besonders relevant in Verbindung mit dem Frontend: Genau an dieser Schnittstelle verlassen wir die Kanäle unserer Rechenzentren und arbeiten bereits über den Kanal, der uns mit dem Kunden verbindet. Wenn es dort die geringsten Probleme gibt, führt ein zu hoher Datenverkehr zu einem negativen Nutzererlebnis.
Und schließlich, geben Sie nicht einfach einen Haufen Daten aus, sondern gehen Sie klar und präzise an den Vertrag zwischen Verbrauchern und Anbietern heran.
Organisatorische Transformation
Eroshkina Elena, stellvertretende IT-Direktorin
Als die Quarantäne eintrat und die Notwendigkeit bestand, die Entwicklung online schnell voranzutreiben und Omnikanal-Services zu implementieren, waren wir bereits in einem Prozess der organisatorischen Transformation.
Ein Teil unserer Struktur wurde umgestellt, um nach den Prinzipien und Praktiken des Produktansatzes zu arbeiten. Es bildeten sich Teams, die nun für den Betrieb und die Weiterentwicklung jedes Produkts verantwortlich sind. Die Mitarbeiter in diesen Teams sind zu 100% involviert und gestalten ihre Arbeit nach Scrum oder Kanban, je nachdem, was für sie bevorzugt ist. Sie richten das Bereitstellungssystem ein, implementieren technische Praktiken, Qualitätsmanagement-Systeme und vieles mehr.
Durch einen glücklichen Zufall befanden sich die meisten dieser Produktteams in den Bereichen Online- und Omnikanal-Services. Das ermöglichte es uns, innerhalb kürzester Zeit (ernsthaft, in nur zwei Tagen) in den Remote-Arbeitsmodus zu wechseln, ohne an Effektivität zu verlieren. Der etablierte Prozess ermöglichte eine schnelle Anpassung an die neuen Arbeitsbedingungen und hielt ein ziemlich hohes Tempo bei der Lieferung neuer Funktionalitäten aufrecht.
Darüber hinaus mussten wir die Teams verstärken, die an der Spitze des Online-Geschäfts stehen. Zu diesem Zeitpunkt wurde klar, dass wir dies nur durch interne Ressourcen erreichen können. In etwa zwei Wochen haben rund 50 Personen ihren Arbeitsbereich gewechselt und sich in die Arbeit an einem neuen Produkt eingearbeitet.
Es bedurfte keiner besonderen Managementanstrengungen, da wir neben der Organisation des eigenen Prozesses, der technischen Weiterentwicklung des Produkts und der Qualitätssicherung unsere Teams in der Selbstorganisation schulen — sie sind in der Lage, ihren eigenen Produktionsprozess ohne administrative Ressourcen zu steuern.
Die Managementressourcen konnten wir genau dort bündeln, wo es zu diesem Zeitpunkt notwendig war - bei der Koordination mit dem Geschäft: Was ist momentan wichtig für unseren Kunden, welche Funktionalitäten müssen prioritär umgesetzt werden, was muss getan werden, um unsere Kapazität für die Lieferung und Bearbeitung von Bestellungen zu erhöhen. All dies und ein klares Rollenmodell ermöglichten es uns während dieses Zeitraums, unsere Produktionsströme zur Schaffung von Wert mit dem zu belasten, was wirklich wichtig und notwendig ist.
Offensichtlich kann man bei Remote-Arbeit und einem hohen Veränderungstempo, bei dem die Geschäftszahlen von jedem Mitwirken abhängen, nicht nur auf interne Gefühle setzen wie: "Läuft bei uns alles gut? Sieht nicht schlecht aus." Notwendige objektive Kennzahlen des Produktionsprozesses. Solche haben wir, sie stehen jedem zur Verfügung, der sich für die Kennzahlen der Produktteams interessiert. Vor allem dem Team selbst, dem Geschäft, den Schnittstellen und dem Management.
Alle zwei Wochen findet ein Statusmeeting mit jedem Team statt, in dem innerhalb von 10 Minuten Metriken analysiert, Engpässe im Produktionsprozess identifiziert und gemeinsame Lösungen erarbeitet werden: Was kann getan werden, um diese Engpässe zu beseitigen? Hier können auch sofort Unterstützung von der Führung angefordert werden, falls ein identifiziertes Problem außerhalb des Einflussbereichs der Teams liegt oder auf die Expertise von Kollegen zurückgegriffen werden muss, die möglicherweise bereits mit einem ähnlichen Problem konfrontiert waren.
Dennoch verstehen wir, dass wir noch viel lernen und in unsere tägliche Arbeit integrieren müssen, um eine drastische Beschleunigung zu erreichen (genau dieses Ziel haben wir uns gesetzt). Momentan setzen wir unseren produktorientierten Ansatz in weiteren Teams und neuen Produkten um. Dafür mussten wir ein für uns neues Format der Online-Schule für Methodologen erlernen.
Methodologen, also Menschen, die Teams helfen, Prozesse aufzubauen, Kommunikationskanäle zu etablieren und die Effizienz der Arbeit zu steigern, sind im Grunde genommen Veränderungsagenten. Momentan arbeiten die Absolventen unseres ersten Jahrgangs mit Teams zusammen und helfen ihnen, erfolgreich zu werden.
Ich denke, dass die aktuelle Situation uns Möglichkeiten und Perspektiven eröffnet, die wir vielleicht selbst noch nicht vollständig erkennen. Aber die Erfahrungen und das Wissen, die wir gerade jetzt erwerben, bestätigen, dass wir den richtigen Entwicklungsweg gewählt haben. Wir werden in Zukunft diese neuen Möglichkeiten nicht verpassen und in der Lage sein, genauso effektiv auf die Herausforderungen zu reagieren, die "Sportmaster" bevorstehen werden.
Fazit
In dieser schwierigen Zeit haben wir die Hauptprinzipien formuliert, auf denen die Softwareentwicklung basiert, die meiner Meinung nach für jedes Unternehmen, das sich damit beschäftigt, relevant sein werden.
Menschen. Das ist der Kern, auf dem alles basiert. Die Mitarbeiter müssen Freude an der Arbeit haben, die Ziele des Unternehmens und die Ziele der Produkte, an denen sie arbeiten, verstehen. Und natürlich sollten sie sich auch beruflich weiterentwickeln können.
Technologie. Es ist notwendig, dass das Unternehmen reif an den Umgang mit seinem Technologie-Stack herangeht und dort Kompetenzen aufbaut, wo es wirklich notwendig ist. Das klingt sehr einfach und offensichtlich. Und wird sehr oft ignoriert.
Prozesse. Es ist wichtig, die Arbeit der Produktteams und Kompetenzzentren richtig zu organisieren und die Zusammenarbeit mit dem Geschäft herzustellen, um als Partner zu arbeiten.
So haben wir im Großen und Ganzen überlebt. Der zentrale Gedanke der Gegenwart wurde erneut bestätigt, als er laut auf die Stirn klopfte.
Selbst wenn du ein riesiges Offline-Geschäft mit zahlreichen Filialen und vielen Städten bist, entwickle deinen Online-Bereich. Das ist nicht nur ein zusätzlicher Verkaufsweg oder eine schöne Anwendung, über die man auch etwas kaufen kann (auch weil die Konkurrenz ebenfalls schöne Anwendungen hat). Es ist kein Reservesystem für den Notfall, das hilft, einen Sturm zu überstehen.
Es ist eine absolute Notwendigkeit. Darauf sollten nicht nur deine technischen Ressourcen und Infrastruktur vorbereitet sein, sondern auch die Menschen und die Prozesse. Denn es ist schnell möglich, Speicherplatz, Kapazitäten und neue Instanzen in ein paar Stunden zu beschaffen. Aber die Menschen und Prozesse müssen darauf im Voraus vorbereitet werden.
Quelle: habr.com
