


Am 9. Januar wurde Pandas 1.0.0rc veröffentlicht. Die vorherige Version der Bibliothek war 0.25.
Die erste Hauptversion enthält viele großartige Neuerungen, darunter verbesserte automatische Zusammenfassungen von DataFrames, mehr Ausgabeformate, neue Datentypen und sogar eine neue Dokumentationswebsite.
Alle Änderungen können eingesehen werden , in diesem Artikel beschränken wir uns jedoch auf eine kurze, weniger technische Übersicht über die wichtigsten Punkte.
Die Bibliothek kann wie gewohnt mit pipinstalliert werden, aber da zum Zeitpunkt des Schreibens Pandas 1.0 noch ein Release Candidate, muss die Version ausdrücklich angegeben werden:
pip install --upgrade pandas==1.0.0rc0Seien Sie vorsichtig: Da es sich um ein Hauptrelease handelt, kann das Update alten Code brechen!
Übrigens wird mit dieser Version die Unterstützung für Python 2 vollständig eingestellt (was ein guter Grund sein kann, — Anm. d. Übers.). Pandas 1.0 erfordert mindestens Python 3.6+, also wenn Sie sich nicht sicher sind, überprüfen Sie, welche Version installiert ist:
$ pip --version
pip 19.3.1 aus /usr/local/lib/python3.7/site-packages/pip (python 3.7)
$ python --version
Python 3.7.5Die Version von Pandas kann am einfachsten so überprüft werden:
>>> import pandas as pd
>>> pd.__version__
1.0.0rc0Verbessertes Autover summarization mit DataFrame.info
Meine Lieblingsneuerung ist die Aktualisierung der Methode DataFrame.info. Die Funktion ist jetzt viel lesbarer, was den Prozess der Datenanalyse erheblich erleichtert:
>>> df = pd.DataFrame({
...: 'A': [1,2,3],
...: 'B': ["goodbye", "cruel", "world"],
...: 'C': [False, True, False]
...:})
>>> df.info()
RangeIndex: 3 Einträge, 0 bis 2
Daten-Spalten (insgesamt 3 Spalten):
# Spalte Nicht-Null Anzahl Datentyp
--- ------ -------------- -----
0 A 3 nicht-null int64
1 B 3 nicht-null object
2 C 3 nicht-null object
dtypes: int64(1), object(2)
Speicherbedarf: 200.0+ BytesAusgabe von Tabellen im Markdown-Format
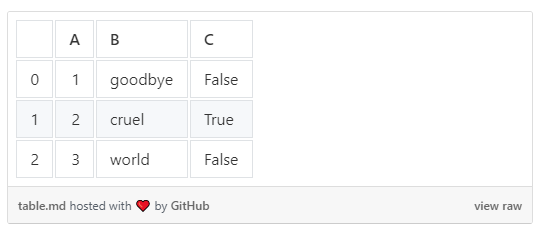
Eine weitere erfreuliche Neuerung ist die Möglichkeit, DataFrames in Markdown-Tabellen zu exportieren mit DataFrame.to_markdown.
>>> df.to_markdown()
| | A | B | C |
|---:|----:|:--------|:------|
| 0 | 1 | goodbye | False |
| 1 | 2 | cruel | True |
| 2 | 3 | world | False |Das vereinfacht die Veröffentlichung von Tabellen auf Websites wie Medium unter Verwendung von GitHub Gists erheblich.
Neue Typen für Strings und boolesche Werte
In der Pandas 1.0-Version wurden auch neue experimentelle Typen hinzugefügt. Ihr API kann sich noch ändern, also nutzen Sie sie mit Vorsicht. Generell empfiehlt Pandas die Verwendung neuer Typen überall dort, wo es sinnvoll ist.
Bisher muss die Konvertierung explizit erfolgen:
>>> B = pd.Series(["goodbye", "cruel", "world"], dtype="string")
>>> C = pd.Series([False, True, False], dtype="bool")
>>> df.B = B, df.C = C
>>> df.info()
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 3 non-null int64
1 B 3 non-null string
2 C 3 non-null bool
dtypes: int64(1), object(1), string(1)
memory usage: 200.0+ bytesBitte beachten Sie, wie die Spalte Dtype neue Typen anzeigt — string und bool.
Die nützlichste Eigenschaft des neuen String-Typs ist die Möglichkeit, nur String-Spalten aus DataFrames auszuwählen. Dies kann die Analyse von Textdaten erheblich vereinfachen:
df.select_dtypes("string")Früher konnten String-Spalten nicht ohne ausdrückliche Nennung der Namen ausgewählt werden.
Mehr über die neuen Typen können Sie lesen .
Vielen Dank fürs Lesen! Die vollständige Liste der Änderungen kann, wie bereits erwähnt, eingesehen werden .
Quelle: habr.com
