

Dmitri Kazakov, Data Analytics Team Lead bei Kolesa Group, teilt Einblicke aus der ersten kasachischen Umfrage unter Datenexperten.

Auf dem Foto: Dmitri Kazakov
Erinnern Sie sich an den beliebten Spruch, dass Big Data am meisten an Teenagersex erinnert – alle reden davon, aber niemand weiß, ob es ihn wirklich gibt. Dasselbe könnte man auch über den Markt für Datenexperten in Kasachstan sagen – das Hype gibt es, aber wer dahintersteckt (und ob überhaupt jemand da ist), war bis jetzt nicht ganz klar – weder für Personalvermittler noch für Manager noch für die Data Scientists selbst.
Wir haben , im Rahmen dessen wir über 300 Fachleute zu ihren Gehältern, Funktionen, Fähigkeiten, Werkzeugen und vielem mehr befragt haben.
Spoiler: ja, sie existieren definitiv, aber es ist nicht so eindeutig.
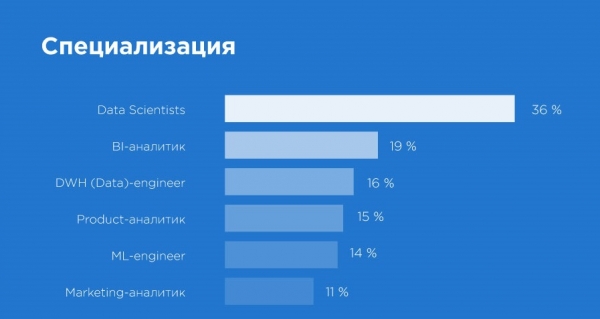
Eine angenehme Einsicht. Zunächst einmal gibt es mehr Datenexperten, als wir erwartet hatten. Es gelang uns, 300 Personen zu befragen, darunter nicht nur Produkt-, Marketing- und BI-Analysten, sondern auch ML- und DWH-Ingenieure, was besonders erfreulich war. In der größten Gruppe fanden sich alle, die sich als Data Scientists bezeichnen – das sind 36 % der Befragten. Ob das den Marktbedürfnissen entspricht, ist schwer zu sagen, da der Markt selbst noch in der Entwicklung ist.
Die Verteilung der Hierarchieebenen ist irritierend – es gibt fast so viele Teamleiter und Führungskräfte wie Junioren. Dafür kann es mehrere Gründe geben. Zum Beispiel die große Anzahl kleiner Teams mit 2-3 Personen, wo der Leiter ein Mittel- oder Senior-Level-Spezialist sein kann.
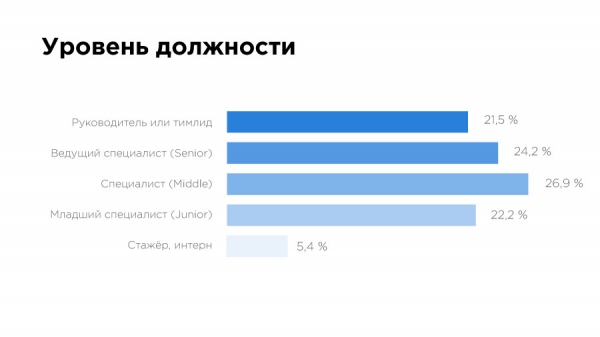
Ein weiterer Grund könnte das derzeitige Chaos auf dem Markt in Bezug auf Standards für die Verteilung von Rollen und Funktionen sein. Manchmal werden Teamleiter einfach als solche ernannt, wenn sie nur ein bis zwei Jahre länger als andere im Unternehmen sind, ohne Bezug zu ihren Fähigkeiten und Kenntnissen. Dies zeigt sich auch in der Verteilung der Funktionen nach Positionen – 38 % der Führungskräfte und Teamleiter sind für die Datenaufbereitung zuständig und weitere 33 % für die grundlegende statistische Analyse.
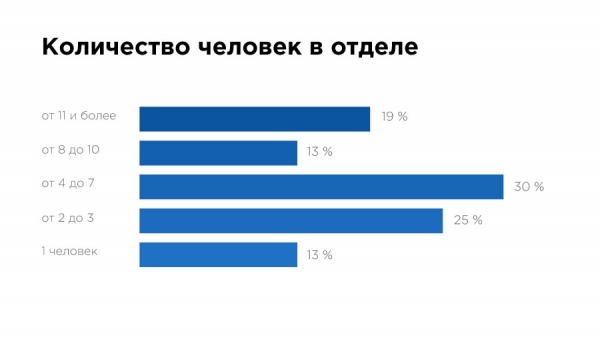
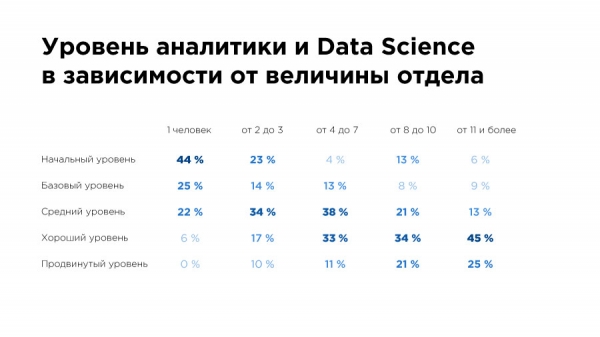
Hier haben wir die Befragten gebeten, den Grad der Analyse in ihren Unternehmen subjektiv zu bewerten. Dabei zeigt sich, dass 10 % der Befragten, die in Analyseabteilungen mit 2-3 Personen arbeiten, glauben, ein "fortgeschrittenes Niveau" erreicht zu haben.
Was bedeutet "fortgeschrittenes Niveau"? Das BI-System funktioniert hervorragend. Es gibt ein DWH und Big Data. Regelmäßig werden A/B-Tests durchgeführt. Es existieren funktionierende ML- und DS-Systeme in Produktion. Entscheidungen werden ausschließlich auf Basis von Daten getroffen. Die Abteilung für Datenverarbeitung und Data Science gehört zu den Schlüsselabteilungen im Unternehmen.
All dies lässt sich mit einer Abteilung von 2-3 Personen kaum erreichen. Ich denke, das Ergebnis dieser Umfrage spiegelt ein gewisses Wachstumsschmerz wider – die Kollegen haben derzeit niemanden, mit dem sie sich vergleichen könnten, um ihr Niveau objektiver einzuschätzen.
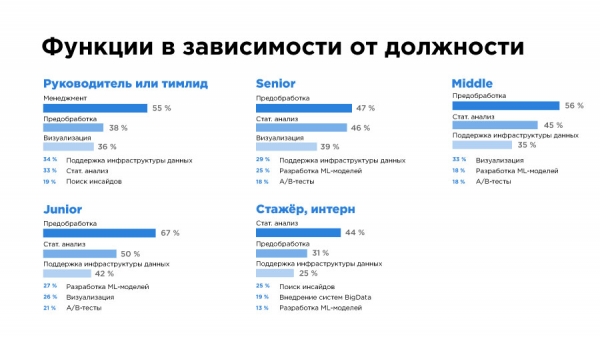

Wie zu erwarten, verbringen Datenexperten die meiste Zeit nicht mit super komplexer Mathematik oder Ingenieurarbeit, sondern mit der Vorverarbeitung, dem Export und der Reinigung von Daten. In jeder Spezialisierung sehen wir die Vorverarbeitung unter den Top 3. Komplexe Aufgaben wie die Entwicklung von ML-Modellen oder die Arbeit mit Big Data tauchen hingegen in den Top 3 nur sehr selten auf – nur bei ML- und DWH-Ingenieuren.
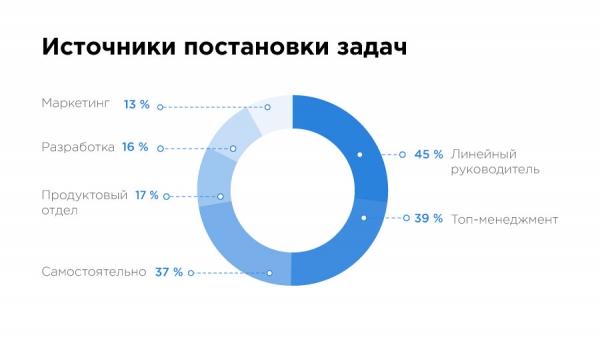
Es gibt auch ein paar traurige Erkenntnisse. 40 % der Aufgaben setzen sich die Spezialisten selbst. In Kasachstan haben bisher nur die führenden Unicorn-Unternehmen die Vorteile der Arbeit mit großen Daten erkannt und gelernt, dies korrekt zu tun. Sie kommunizieren auf dem Markt, dass Big Data und Machine Learning großartig sind, und die zweite Reihe folgt, versteht jedoch oft nicht, wie die Arbeit mit Daten funktioniert. Daher sehen wir, dass die Spezialisten sich selbst Aufgaben geben, während das Unternehmen nicht immer weiß, was es möchte.
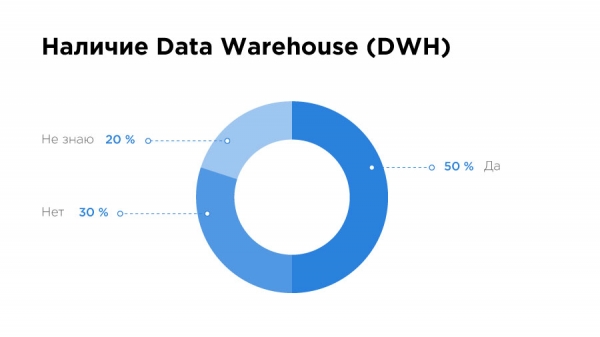
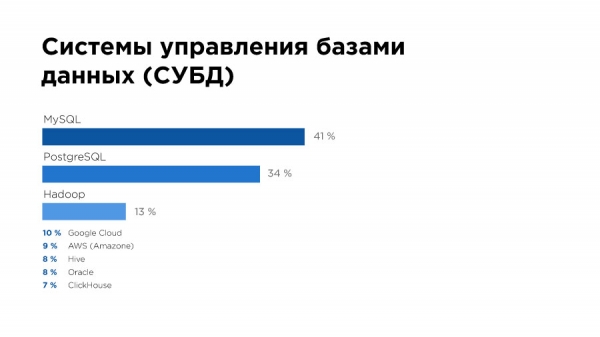
Erstaunlich ist, dass 20 % der Spezialisten überhaupt nicht wissen, ob es in ihrem Unternehmen ein Data Warehouse gibt. Ja, und mit den Systemen Datenbankmanagementsystemen läuft es nicht so gut – 41 % nutzen MySQL, und weitere 34 % PostgreSQL. Was könnte das bedeuten? Sie arbeiten eher mit Small Data.
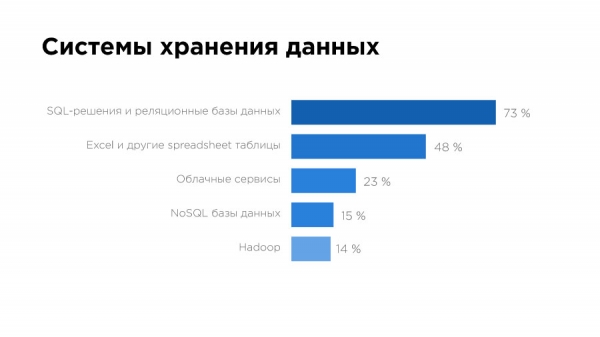
Im Hinblick auf die Speichersysteme sehen wir erneut MySQL und sogar (!) Excel. Das könnte zum Beispiel bedeuten, dass die meisten Unternehmen einfach noch keinen Bedarf an der Arbeit mit großen Daten haben.
Hier ist alles erneut mehrdeutig. Insgesamt waren die Gehälter etwas niedriger als erwartet.
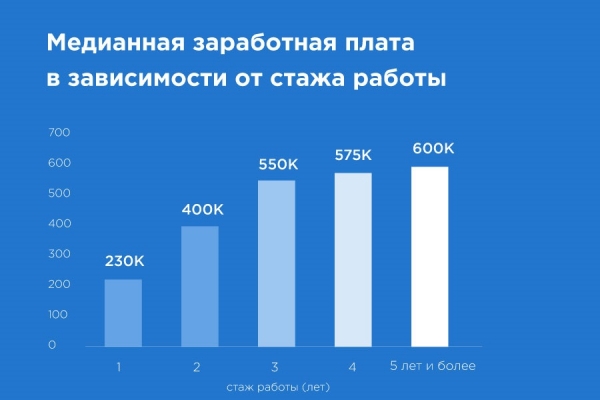
Es fällt mir schwer, mir einen ML-Ingenieur vorzustellen, der bereit ist, für 200.000 Tengue zu arbeiten – wahrscheinlich ist das ein Praktikant. Entweder sind die Fähigkeiten solcher Spezialisten sehr schwach, oder die Unternehmen haben Schwierigkeiten, die Arbeit im Bereich Data Science angemessen zu bewerten. Möglicherweise zeigt dies auch, dass der Markt noch am Anfang seiner Entwicklung steht. Mit der Zeit wird das Gehaltsniveau wahrscheinlich auf ein angemesseneres Niveau steigen.
Quelle: habr.com
