


Auf welchen Prinzipien basiert das ideale Datenlager?
Fokus auf geschäftlichem Nutzen und Analytik ohne Boilerplate-Code. Management von DWH wie einer Codebasis: Versionierung, Überprüfung, automatisierte Tests und CI. Modularität, Erweiterbarkeit, Open Source und Community. Benutzerfreundliche Dokumentation und Visualisierung von Abhängigkeiten (Data Lineage).
Mehr dazu und zur Rolle von DBT im Ökosystem Big Data & Analytics – willkommen unter dem Artikel.
Hallo zusammen
Hier ist Artemij Kozyr. Seit über 5 Jahren arbeite ich mit Datenlagern, baue ETL/ELT auf und beschäftige mich mit Datenanalyse und -visualisierung. Momentan arbeite ich bei , unterrichte an OTUS im Kurs , und heute möchte ich einen Artikel mit Ihnen teilen, den ich im Vorfeld des Starts eines neuen Kurses.
Überblick
Das DBT-Framework dreht sich um das T im Akronym ELT (Extract – Transform – Load).
Mit der Einführung leistungsfähiger und skalierbarer analytischer Datenbanken wie BigQuery, Redshift, Snowflake hat es keinen Sinn mehr, Transformationen außerhalb des Datenlagers durchzuführen.
DBT lädt keine Daten aus Quellen herunter, bietet jedoch enorme Möglichkeiten zur Arbeit mit bereits im Speicher (in Internal oder External Storage) geladenen Daten.
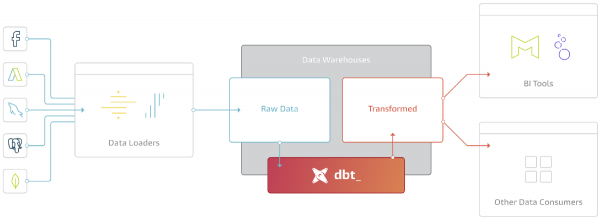
Die Hauptfunktion von DBT besteht darin, Code zu nehmen, ihn in SQL zu kompilieren und die Befehle in der richtigen Reihenfolge im Speicher auszuführen.
Die Struktur eines DBT-Projekts
Ein Projekt besteht aus Verzeichnissen und Dateien von insgesamt 2 Typen:
- Modell (.sql) – die Einheit der Transformation, ausgedrückt durch eine SELECT-Abfrage.
- Konfigurationsdatei (.yml) – Parameter, Einstellungen, Tests, Dokumentation.
Auf einer grundlegenden Ebene erfolgt die Arbeit wie folgt:
- Der Benutzer bereitet den Code der Modelle in einer beliebigen bevorzugten IDE vor.
- Durch den Aufruf der CLI wird der Modellstart initiiert, DBT kompiliert den Modellcode in SQL.
- Der kompilierte SQL-Code wird im Speicher in der festgelegten Reihenfolge (Graph) ausgeführt.
So könnte der Start aus der CLI aussehen:
Alles ist SELECT.
Dies ist das Killer-Feature des Data Build Tool-Frameworks. Mit anderen Worten, DBT abstrahiert den gesamten Code, der mit der Materialisierung Ihrer Abfragen im Speicher zusammenhängt (Variationen aus den Befehlen CREATE, INSERT, UPDATE, DELETE, ALTER, GRANT, ...).
Jedes Modell beinhaltet das Schreiben einer einzelnen SELECT-Abfrage, die den resultierenden Datensatz definiert.
Die Logik der Transformationen kann dabei mehrstufig sein und Daten aus mehreren anderen Modellen konsolidieren. Ein Beispielmodell, das eine Bestellübersicht erstellt (f_orders):
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
mit bestellungen als (
select * from {{ ref('stg_orders') }}
),
bestellzahlungen als (
select * from {{ ref('order_payments') }}
),
final als (
select
bestellungen.order_id,
bestellungen.customer_id,
bestellungen.order_date,
bestellungen.status,
{% for payment_method in payment_methods -%}
bestellzahlungen.{{payment_method}}_amount,
{% endfor -%}
bestellzahlungen.total_amount as amount
from bestellungen
left join bestellzahlungen using (order_id)
)
select * from final
Was können wir hier Interessantes sehen?
Zunächst: CTEs (Common Table Expressions) wurden verwendet — um den Code zu organisieren und verständlich zu machen, der viele Transformationen und Geschäftslogik enthält.
Zweitens: Der Modellcode ist eine Mischung aus SQL und der (Template-Sprache).
Im Beispiel wird eine Schleife verwendet, für um die Summe für jede Zahlungsmethode zu berechnen, die im Ausdruck setangegeben ist. Außerdem wird die Funktion ref verwendet — um innerhalb des Codes auf andere Modelle zu verweisen:
- Während der Kompilierung ref wird sie in einen Zielverweis auf eine Tabelle oder Sicht im Speicher umgewandelt.
- ref ermöglicht den Aufbau eines Abhängigkeitsdiagramms für Modelle
Genau fügt DBT nahezu unbegrenzte Möglichkeiten hinzu. Die am häufigsten verwendeten sind:
- If / else-Anweisungen — Verzweigungsoperatoren
- For-Schleifen — Schleifen
- Variablen — Variablen
- Makro — Erstellung von Makros
Materialisierung: Tabelle, Ansicht, inkrementell
Materialisierungsstrategie — Ansatz, bei dem der resultierende Datensatz des Modells im Speicher gespeichert wird.
Im Grundsatz bedeutet dies:
- Tabelle — physische Tabelle im Speicher
- Ansicht — eine virtuelle Tabelle im Speicher
Es gibt auch komplexere Materialisierungsstrategien:
- Inkrementell — inkrementelles Laden (großer Faktentabellen); neue Zeilen werden hinzugefügt, geänderte werden aktualisiert, gelöschte werden entfernt
- Ephemeral — Modell wird nicht direkt materialisiert, sondern dient als CTE in anderen Modellen
- Andere Strategien, die Sie selbst hinzufügen können
Zusätzlich zu den Materialisierungsstrategien eröffnen sich Möglichkeiten zur Optimierung für bestimmte Speicher, zum Beispiel:
- Snowflake: Transiente Tabellen, Zusammenführungsverhalten, Tabellenclustering, Berechtigungen kopieren, Sichere Ansichten
- Redshift: Distkey, Sortkey (interleaved, compound), Late Binding Views
- BigQuery: Tabellenpartitionierung & Clustering, Zusammenführungsverhalten, KMS-Verschlüsselung, Labels & Tags
- Spark: Dateiformat (parquet, csv, json, orc, delta), partition_by, clustered_by, buckets, inkrementelle Strategie
Derzeit werden folgende Speichersysteme unterstützt:
- Postgres
- Redshift
- BigQuery
- Snowflake
- Presto (teilweise)
- Spark (teilweise)
- Microsoft SQL Server (Community-Adapter)
Lassen Sie uns unser Modell verbessern:
- Gestalten wir dessen Inhalt inkrementell
- Fügen wir Segmentierungs- und Sortierungsschlüssel für Redshift hinzu
-- Modellkonfiguration:
-- Inkrementelles Füllen, eindeutiger Schlüssel für die Aktualisierung von Datensätzen (unique_key)
-- Segmentierungsschlüssel (dist), Sortierungsschlüssel (sort)
{{
config(
materialized='incremental',
unique_key='order_id',
dist="customer_id",
sort="order_date"
)
}}
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
with orders as (
select * from {{ ref('stg_orders') }}
where 1=1
{% if is_incremental() -%}
-- Dieser Filter wird nur bei inkrementaler Ausführung angewendet
and order_date >= (select max(order_date) from {{ this }})
{%- endif %}
),
order_payments as (
select * from {{ ref('order_payments') }}
),
final as (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
order_payments.{{payment_method}}_amount,
{% endfor -%}
order_payments.total_amount as amount
from orders
left join order_payments using (order_id)
)
select * from final
Abhängigkeiten der Modelle
Auch bekannt als Abhängigkeitsbaum oder DAG (Directed Acyclic Graph – gerichteter azyklischer Graph).
DBT erstellt den Graphen basierend auf der Konfiguration aller Modelle des Projekts, genauer gesagt, auf den ref()-Verweisen innerhalb der Modelle zu anderen Modellen. Das Vorhandensein eines Graphen ermöglicht es, folgende Dinge zu tun:
- Modelle in der korrekten Reihenfolge auszuführen
- Parallelisierung der Erstellung von Dashboards
- Einen beliebigen Teilgraphen auszuführen
Beispiel einer Graphvisualisierung:
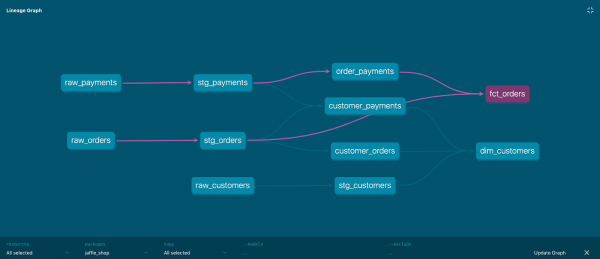
Jeder Knoten des Graphen ist ein Modell, die Kanten des Graphen werden durch den Ausdruck ref definiert.
Datenqualität und Dokumentation
Neben der Erstellung der Modelle ermöglicht es DBT, eine Reihe von Annahmen (Assertions) über den resultierenden Datensatz zu testen, wie zum Beispiel:
- Nicht-Null
- Eindeutig
- Referenzintegrität – die Integrität von Referenzen (zum Beispiel, dass customer_id in der Tabelle orders der id in der Tabelle customers entspricht)
- Übereinstimmung mit einer Liste zulässiger Werte
Es ist möglich, eigene Tests (benutzerdefinierte Daten-Tests) hinzuzufügen, wie z.B. die Abweichung der Einnahmen im Vergleich zu den Werten vor einem Tag, einer Woche oder einem Monat. Jede Annahme, die in Form einer SQL-Abfrage formuliert wurde, kann zu einem Test werden.
So lassen sich unerwünschte Abweichungen und Datenfehler in den Displays des Speichers erfassen.
Was die Dokumentation betrifft, bietet DBT Mechanismen zum Hinzufügen, Versionieren und Verbreiten von Metadaten und Kommentaren auf Modellebene und sogar für Attribute.
So sieht das Hinzufügen von Tests und Dokumentation auf Ebene der Konfigurationsdatei aus:
- name: fct_orders
description: Diese Tabelle enthält grundlegende Informationen zu Bestellungen sowie einige abgeleitete Fakten basierend auf Zahlungen
columns:
- name: order_id
tests:
- unique # Überprüfung auf Eindeutigkeit der Werte
- not_null # Überprüfung auf Vorhandensein von Null
description: Dies ist ein eindeutiger Identifizierer für eine Bestellung
- name: customer_id
description: Fremdschlüssel zur Kundentabelle
tests:
- not_null
- relationships: # Überprüfung der referenziellen Integrität
to: ref('dim_customers')
field: customer_id
- name: order_date
description: Datum (UTC), an dem die Bestellung aufgegeben wurde
- name: status
description: '{{ doc("orders_status") }}'
tests:
- accepted_values: # Überprüfung auf zulässige Werte
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
So sieht diese Dokumentation bereits auf der generierten Webseite aus:
Makros und Module
Das Ziel von DBT ist nicht nur, eine Sammlung von SQL-Skripten bereitzustellen, sondern den Nutzern leistungsstarke und vielseitige Werkzeuge zur Verfügung zu stellen, um ihre eigenen Transformationen zu erstellen und diese Module zu verbreiten.
Makros sind Sets von Konstruktionen und Ausdrücken, die als Funktionen innerhalb von Modellen aufgerufen werden können. Sie ermöglichen die Wiederverwendung von SQL zwischen Modellen und Projekten gemäß dem Ingenieurprinzip DRY (Don’t Repeat Yourself).
Beispiel für ein Makro:
{% macro rename_category(column_name) %}
case
when {{ column_name }} ilike '%osx%' then 'osx'
when {{ column_name }} ilike '%android%' then 'android'
when {{ column_name }} ilike '%ios%' then 'ios'
else 'other'
end as renamed_product
{% endmacro %}
Und seine Verwendung:
{% set column_name = 'product' %}
select
product,
{{ rename_category(column_name) }} -- Aufruf des Makros
from my_table
DBT wird mit einem Paketmanager (packages) geliefert, der es Nutzern ermöglicht, einzelne Module und Makros zu veröffentlichen und wiederzuverwenden.
Das bedeutet die Möglichkeit, Bibliotheken wie folgende zu laden und zu verwenden:
- : Arbeiten mit Datum/Uhrzeit, Surrogate Keys, Schema-Tests, Pivot/Unpivot und mehr
- Vorgefertigte Vorlagen für Services wie und
- Bibliotheken für spezifische Data Warehouses, wie zum Beispiel
- — Modul zur Protokollierung der DBT-Arbeiten
Die vollständige Liste der Pakete finden Sie auf .
Noch mehr Möglichkeiten
Hier werde ich einige weitere interessante Funktionen und Implementierungen beschreiben, die ich und das Team verwenden, um ein Data Warehouse in .
Trennung der Ausführungsumgebungen DEV — TEST — PROD
Sogar innerhalb eines DWH-Clusters (in verschiedenen Schemata). Zum Beispiel mit dem folgenden Ausdruck:
with source as (
select * from {{ source('salesforce', 'users') }}
where 1=1
{%- if target.name in ['dev', 'test', 'ci'] -%}
where timestamp >= dateadd(day, -3, current_date)
{%- endif -%}
)
Dieser Code sagt wörtlich: für die Umgebungen dev, test, ci hole nur die Daten der letzten 3 Tage und nicht mehr. Das heißt, die Ausführung in diesen Umgebungen wird viel schneller und benötigt weniger Ressourcen. Bei der Ausführung in der prod Umgebung wird die Filterbedingung ignoriert.
Materialisierung mit alternativer Spaltenkodierung
Redshift ist ein spaltenbasiertes DBMS, das es ermöglicht, Kompressionsalgorithmen für jede einzelne Spalte festzulegen. Die Auswahl optimaler Algorithmen kann den Speicherplatz auf der Festplatte um 20–50 % reduzieren.
Makro führt den Befehl ANALYZE COMPRESSION aus, erstellt eine neue Tabelle mit empfohlenen Kodierungsmethoden für Spalten, unter Verwendung der angegebenen Segmentierungsschlüssel (dist_key) und Sortierschlüssel (sort_key), überträgt die Daten dorthin und entfernt bei Bedarf die alte Kopie.
Makrosignatur:
{{ compress_table(schema, table,
drop_backup=False,
comprows=none|Integer,
sort_style=none|compound|interleaved,
sort_keys=none|List,
dist_style=none|all|even,
dist_key=none|String) }}
Protokollierung von Modellstarts
An jedes Modell kann ein Hook (hooks) angehängt werden, der vor dem Start oder direkt nach Abschluss der Modellerstellung ausgeführt wird:
pre-hook: "{{ logging.log_model_start_event() }}"
post-hook: "{{ logging.log_model_end_event() }}"
Das Protokollierungsmodul ermöglicht die Aufnahme aller erforderlichen Metadaten in eine separate Tabelle, die anschließend für Audits und zur Analyse von Engpässen (bottlenecks) verwendet werden kann.
So sieht das Dashboard mit den Protokolldaten in Looker aus:
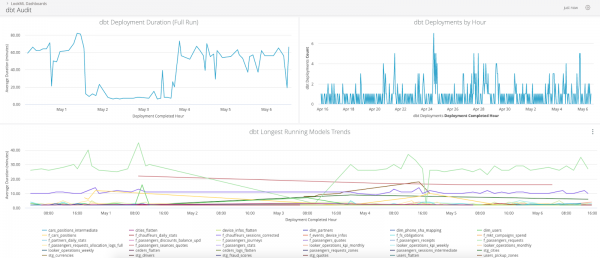
Automatisierung des Speicherservices
Wenn Sie Erweiterungen der Funktionalität des verwendeten Speichers nutzen, wie beispielsweise UDFs (User Defined Functions), lässt sich die Versionierung dieser Funktionen, die Verwaltung von Zugriffsrechten sowie die automatisierte Bereitstellung neuer Versionen sehr bequem in DBT durchführen.
Wir verwenden UDFs in Python zur Berechnung von Hash-Werten, E-Mail-Domains und zur Dekodierung von Bitmasken.
Beispiel eines Makros, das UDFs in jeder Ausführungsumgebung (dev, test, prod) erstellt:
{% macro create_udf() -%}
{% set sql %}
CREATE OR REPLACE FUNCTION {{ target.schema }}.f_sha256(mes "varchar")
RETURNS varchar
LANGUAGE plpythonu
STABLE
AS $$
import hashlib
return hashlib.sha256(mes).hexdigest()
$$
;
{% endset %}
{% set table = run_query(sql) %}
{%- endmacro %}
Bei Wheely nutzen wir Amazon Redshift, das auf PostgreSQL basiert. Für Redshift ist es wichtig, regelmäßig Statistiken zu den Tabellen zu sammeln und Speicherplatz freizugeben – dafür sind die Befehle ANALYZE und VACUUM zuständig.
Zu diesem Zweck werden jede Nacht die Befehle aus dem Makro redshift_maintenance ausgeführt:
{% macro redshift_maintenance() %}
{% set vacuumable_tables=run_query(vacuumable_tables_sql) %}
{% for row in vacuumable_tables %}
{% set message_prefix=loop.index ~ " von " ~ loop.length %}
{%- set relation_to_vacuum = adapter.get_relation(
database=row['table_database'],
schema=row['table_schema'],
identifier=row['table_name']
) -%}
{% do run_query("commit") %}
{% if relation_to_vacuum %}
{% set start=modules.datetime.datetime.now() %}
{{ dbt_utils.log_info(message_prefix ~ " Vakuumieren " ~ relation_to_vacuum) }}
{% do run_query("VACUUM " ~ relation_to_vacuum ~ " BOOST") %}
{{ dbt_utils.log_info(message_prefix ~ " Analysieren " ~ relation_to_vacuum) }}
{% do run_query("ANALYZE " ~ relation_to_vacuum) %}
{% set end=modules.datetime.datetime.now() %}
{% set total_seconds = (end - start).total_seconds() | round(2) %}
{{ dbt_utils.log_info(message_prefix ~ " Fertig " ~ relation_to_vacuum ~ " in " ~ total_seconds ~ "s") }}
{% else %}
{{ dbt_utils.log_info(message_prefix ~ ' Überspringe Relation "' ~ row.values() | join ('"."') ~ '" da sie nicht existiert') }}
{% endif %}
{% endfor %}
{% endmacro %}
DBT Cloud
Es besteht die Möglichkeit, DBT als Managed Service zu nutzen. Inklusive:
- Web IDE zur Entwicklung von Projekten und Modellen
- Jobkonfiguration und Zeitplanung
- Einfacher und bequemer Zugriff auf Logs
- Webseite mit Dokumentation Ihres Projekts
- Anbindung von CI (Continuous Integration)
Fazit
Das Arbeiten mit und der Genuss von DWH wird so angenehm und bereichernd wie das Trinken eines Smoothies. DBT besteht aus Jinja, benutzerdefinierten Erweiterungen (Modulen), einem Compiler, einem Executor und einem Paketmanager. Wenn Sie diese Elemente zusammenbringen, erhalten Sie eine voll funktionsfähige Arbeitsumgebung für Ihr Data Warehouse. Heute gibt es kaum einen besseren Weg, Transformationen innerhalb eines DWH zu verwalten.

Die Überzeugungen, denen die Entwickler von DBT gefolgt sind, lauten:
- Code, nicht GUI, ist die beste Abstraktion zur Darstellung komplexer analytischer Logik.
- Die Arbeit mit Daten sollte die besten Praktiken der Softwareentwicklung adaptieren.
- Die wichtigste Infrastruktur für die Datenbearbeitung sollte von der Benutzergemeinschaft als Open Source Software kontrolliert werden.
- Nicht nur Analysewerkzeuge, sondern auch Code wird zunehmend Teil der Open Source Gemeinschaft.
Diese grundlegenden Überzeugungen haben ein Produkt hervorgebracht, das heute in über 850 Unternehmen eingesetzt wird und die Grundlage für viele interessante Erweiterungen bildet, die in Zukunft entwickelt werden.
Für Interessierte gibt es eine Aufzeichnung des offenen Kurses, den ich vor einigen Monaten im Rahmen eines offenen Unterrichts bei OTUS gehalten habe — .
Neben DBT und Data Warehousing bieten ich und meine Kollegen im Rahmen des Data Engineering Kurses bei OTUS Unterricht zu einer Reihe weiterer aktueller und relevanter Themen an:
- Architektonische Konzepte großer Datenanwendungen
- Praxis mit Spark und Spark Streaming
- Erforschung von Methoden und Werkzeugen zum Laden von Datenquellen
- Aufbau analytischer Data Marts in DWH
- NoSQL-Konzepte: HBase, Cassandra, ElasticSearch
- Prinzipien der Überwachung und Orchestrierung
- Abschlussprojekt: alle Fähigkeiten unter mentorieller Unterstützung zusammenführen
Links:
- — Offizielle Dokumentation
- — Überblicksartikel eines der DBT-Autoren
- — YouTube, Aufzeichnung des offenen Unterrichts bei OTUS
- — Nächster offener Kurs am 15. Mai 2020
- — OTUS
- — Ein Blick auf die Zukunft der Datenarbeit und Analytik
- — Die Evolution der Analytik und den Einfluss von Open Source
- — Prinzipien des CI-Aufbaus mit DBT
- — Praxis, Schritt-für-Schritt-Anleitungen zur Selbstarbeit
- — Github, Code des Lernprojekts
Quelle: habr.com
