


SQL, was könnte einfacher sein? Jeder von uns kann eine einfache Anfrage schreiben – wir geben ein select, listen die benötigten Spalten auf, dann from, den Tabellennamen, ein paar Bedingungen in wo und schon – nützliche Daten sind in unserer Tasche, fast unabhängig davon, welche DBMS gerade im Hintergrund läuft (oder vielleicht ist es sogar ). Dadurch lässt sich die Arbeit mit fast jeder Datenquelle (relational oder nicht) wie gewöhnlicher Code betrachten (mit all den Folgen – Versionskontrolle, Code-Reviews, statische Analyse, automatisierte Tests und so weiter). Das betrifft nicht nur die Daten selbst, die Schemata und Migrationen, sondern das gesamte Leben eines Speichers. In diesem Artikel werden wir über alltägliche Aufgaben und Probleme bei der Arbeit mit verschiedenen Datenbanken im Kontext von „Datenbank als Code“ sprechen.
Und wir beginnen direkt mit . Die ersten Auseinandersetzungen der Art „SQL vs ORM“ wurden bereits in .
Objekt-Relationales Mapping
Befürworter von ORM schätzen traditionell die Geschwindigkeit und Einfachheit der Entwicklung, die Unabhängigkeit von DBMS und die Klarheit des Codes. Für viele von uns sieht der Code zur Arbeit mit der Datenbank (und oft auch die Datenbank selbst)
gewöhnlich etwa so aus…
@Entity
@Table(name = "stock", catalog = "maindb", uniqueConstraints = {
@UniqueConstraint(columnNames = "STOCK_NAME"),
@UniqueConstraint(columnNames = "STOCK_CODE") })
public class Stock implements java.io.Serializable {
@Id
@GeneratedValue(strategy = IDENTITY)
@Column(name = "STOCK_ID", unique = true, nullable = false)
public Integer getStockId() {
return this.stockId;
}
...Das Modell ist mit intelligenten Annotationen ausgestattet, während im Hintergrund ein tüchtiger ORM Unmengen von SQL-Code generiert und ausführt. Es sei erwähnt, dass Entwickler alles daran setzen, sich durch Kilometer von Abstraktionen von ihrer Datenbank abzugrenzen, was auf ein gewisses .
Auf der anderen Seite der Barrikade betonen die Anhänger des reinen "handmade"-SQL die Möglichkeit, die gesamte Leistung ihrer Datenbank ohne zusätzliche Schichten und Abstraktionen auszuschöpfen. Dadurch entstehen "data-centric" Projekte, bei denen speziell geschulte Personen (auch als "Datenbank-Administratoren", "DBAs" oder "Datenbank-Profi" bekannt) die Datenbanken betreuen, während die Entwickler sich darauf beschränken, fertige Views und gespeicherte Prozeduren zu verwenden, ohne sich mit den Einzelheiten zu befassen.
Was wäre, wenn wir das Beste aus beiden Welten kombinieren? So wie es mit dem wunderbaren Werkzeug mit dem lebensbejahenden Namen . Ich werde ein paar Zeilen aus dem allgemeinen Konzept in meiner freien Übersetzung anführen; für detailliertere Informationen können Sie sich damit vertraut machen. .
Clojure ist eine großartige Sprache zur Erstellung von DSLs, aber SQL selbst ist bereits ein außergewöhnlicher DSL, und wir benötigen keinen weiteren. S-Ausdrücke sind wunderbar, tragen hier jedoch nichts Neues bei. Am Ende haben wir nur Klammern um der Klammern willen. Nicht einverstanden? Warten Sie, bis die Abstraktion über der Datenbank undicht wird, und Sie beginnen, mit der Funktion zu kämpfen. (raw-sql)
Was also tun? Lassen Sie uns SQL einfach SQL sein — eine Datei für eine Anfrage:
-- name: users-by-country
select *
from users
where country_code = :country_code… und dann lesen Sie diese Datei, indem Sie sie in eine reguläre Clojure-Funktion umwandeln:
(defqueries "some/where/users_by_country.sql"
{:connection db-spec})
;;; Eine Funktion mit dem Namen `users-by-country` wurde erstellt.
;;; Lassen Sie sie uns verwenden:
(users-by-country {:country_code "GB"})
;=> ({:name "Kris" :country_code "GB" ...} ...)Indem Sie dem Prinzip "SQL getrennt, Clojure getrennt" folgen, erhalten Sie:
- Keine syntaktischen Überraschungen. Ihre Datenbank (wie jede andere auch) entspricht nicht zu 100 % dem SQL-Standard — aber das ist für Yesql nicht wichtig. Sie werden niemals Zeit mit der Suche nach Funktionen mit dem syntaktischen Äquivalent von SQL verschwenden. Sie müssen niemals zur Funktion zurückkehren. (raw-sql "some (‘funky’ :: SYNTAX)")).
- Ausgezeichneter Support für den Editor. Ihr Editor bietet bereits hervorragende Unterstützung für SQL. Indem Sie SQL als SQL speichern, können Sie es einfach verwenden.
- Teamkompatibilität. Ihre DBA können SQL lesen und schreiben, das in Ihrem Clojure-Projekt verwendet wird.
- Einfachere Leistungseinstellungen. Müssen Sie einen Plan für eine problematische Abfrage erstellen? Das ist kein Problem, wenn Ihre Abfrage einfaches SQL ist.
- Wiederverwendung von Abfragen. Ziehen Sie diese SQL-Dateien in andere Projekte, denn es ist einfach das gute alte SQL – teilen Sie es einfach.
Ich finde die Idee wirklich großartig und gleichzeitig sehr einfach, wodurch das Projekt in vielerlei Hinsicht gewachsen ist. in ganz unterschiedlichen Sprachen. Wir werden versuchen, eine ähnliche Philosophie anzuwenden, indem wir SQL-Code von allem anderen deutlich abtrennen, weit über ORM hinaus.
IDE & DB-Manager
Beginnen wir mit einer einfachen, alltäglichen Aufgabe. Oft müssen wir in einer Datenbank nach Objekten suchen, beispielsweise eine Tabelle in einem Schema finden und ihre Struktur untersuchen (welche Spalten, Schlüssel, Indizes, Constraints usw. verwendet werden). Von jeder grafischen IDE oder auch nur einem einfachen DB-Manager erwarten wir in erster Linie genau diese Fähigkeiten. Es sollte schnell gehen, ohne dass wir halbe Stunden warten müssen, bis ein Fenster mit den benötigten Informationen erscheint (insbesondere bei einer langsamen Verbindung zu einer entfernten Datenbank), und die erhaltenen Informationen sollten aktuell und relevant sein, nicht veraltete, zwischengespeicherte Daten. Je komplexer und umfangreicher die Datenbank ist und je mehr Datenbanken es gibt, desto schwieriger wird es, das zu erreichen.
In der Regel lege ich jedoch die Maus beiseite und schreibe einfach den Code. Angenommen, ich möchte herausfinden, welche Tabellen (und mit welchen Eigenschaften) im Schema "HR" vorhanden sind. In den meisten DBMS kann das gewünschte Ergebnis mit einer einfachen Abfrage aus dem information_schema erzielt werden:
select table_name
, ...
from information_schema.tables
where schema = 'HR'Der Inhalt solcher Nachschlagetabellen variiert je nach den Möglichkeiten jeder Datenbank. Beispielsweise können spezifische für MySQL relevante Parameter dieser Tabelle aus demselben Nachschlagewerk abgerufen werden:
select table_name
, storage_engine -- Verwendeter "Engine" ("MyISAM", "InnoDB" etc)
, row_format -- Zeilenformat ("Fixed", "Dynamic" etc)
, ...
from information_schema.tables
where schema = 'HR'Oracle hat kein information_schema, aber es hat , und es treten keine größeren Probleme auf:
select table_name
, pct_free -- Mindestfreier Platz im Datenblock (%)
, pct_used -- Mindestgenutzter Platz im Datenblock (%)
, last_analyzed -- Datum der letzten Statistiksammlung
, ...
from all_tables
where owner = 'HR'Das gilt auch für ClickHouse:
select name
, engine -- Verwendeter "Engine" ("MergeTree", "Dictionary" etc)
, ...
from system.tables
where database = 'HR'Ähnliches lässt sich auch in Cassandra machen (wo es columnfamilies anstelle von Tabellen und keyspaces anstelle von Schemas gibt):
select columnfamily_name
, compaction_strategy_class -- Müllabfuhrstrategie
, gc_grace_seconds -- Lebensdauer von Müll
, ...
from system.schema_columnfamilies
where keyspace_name = 'HR'Für die meisten anderen Datenbanken lassen sich ebenfalls ähnliche Abfragen konstruieren (sogar in Mongo gibt es , die Informationen zu allen Sammlungen im System enthält).
Natürlich kann man auf diese Weise nicht nur Informationen über Tabellen, sondern über beliebige Objekte erhalten. Gelegentlich teilen freundliche Menschen solchen Code für verschiedene Datenbanken, wie beispielsweise in der Reihe von Habr-Artikeln "Funktionen zur Dokumentation von PostgreSQL-Datenbanken" (, , ). Selbstverständlich ist es "nicht gerade angenehm", all diese Anfragen im Kopf zu behalten und ständig einzutippen, daher habe ich in meiner Lieblings-IDE/editor einen vorab vorbereiteten Satz von Snippets für häufig verwendete Abfragen, bei denen ich nur die Objektnamen in die Vorlage einfügen muss.
Infolgedessen ist diese Art der Navigation und Objektsuche viel flexibler, spart viel Zeit und ermöglicht es, genau die Informationen in der Form zu erhalten, die derzeit erforderlich ist (wie beispielsweise in dem Beitrag beschrieben, ).
Operationen mit Objekten
Nachdem wir die benötigten Objekte gefunden und untersucht haben, ist es an der Zeit, etwas Nützliches damit zu tun. Natürlich, ohne die Finger von der Tastatur zu nehmen.
Es ist kein Geheimnis, dass das einfache Löschen einer Tabelle in fast allen Datenbanken gleich aussieht:
drop table hr.personsAber das Erstellen einer Tabelle ist schon interessanter. Praktisch jede DBMS (einschließlich vieler NoSQL-Systeme) beherrscht in irgendeiner Form "create table", und der Hauptteil davon wird sich kaum unterscheiden (Name, Spaltenliste, Datentypen), jedoch können die weiteren Details erheblich variieren und hängen von der internen Struktur und den Möglichkeiten des jeweiligen DBMS ab. Mein Lieblingsbeispiel — in der Dokumentation von Oracle finden sich nur die "nackten" BNF für die Syntax von "create table". Andere DBMS haben bescheidenere Möglichkeiten, aber jede von ihnen bietet ebenfalls viele interessante und einzigartige Funktionen zum Erstellen von Tabellen (, , , ). Es ist unwahrscheinlich, dass irgendein grafischer "Wizard" aus einer beliebigen IDE (insbesondere aus einer universellen) all diese Fähigkeiten vollständig abdecken kann. Selbst wenn es gelingt, wird es ein Anblick sein, der nichts für schwache Nerven ist. Gleichzeitig wird ein richtig und rechtzeitig geschriebener Befehl create table es Ihnen ermöglichen, alle diese Funktionen mühelos zu nutzen und die Speicherung sowie den Zugriff auf Ihre Daten zuverlässig, optimal und so angenehm wie möglich zu gestalten.
In vielen Datenbankmanagementsystemen gibt es spezifische Objekttypen, die in anderen Systemen nicht vorhanden sind. Wir können nicht nur Operationen an Datenbankobjekten durchführen, sondern auch an der Datenbank selbst, wie zum Beispiel einen Prozess 'killen', einen bestimmten Speicherbereich freigeben, das Tracing aktivieren, in den 'Read-Only'-Modus wechseln und vieles mehr.
Jetzt lassen Sie uns ein wenig Zeichnen.
Eine der häufigsten Aufgaben besteht darin, ein Diagramm mit Datenbankobjekten zu erstellen und auf einer ansprechenden Grafik die Objekte sowie die Beziehungen zwischen ihnen darzustellen. So etwas beherrscht praktisch jede grafische IDE, verschiedene 'Command Line'-Tools sowie spezialisierte Grafik-Tools und Modellierungssoftware. Diese zeigen Ihnen alles 'wie sie können', und der Einfluss auf diesen Prozess ist meist nur über einige Parameter in der Konfigurationsdatei oder durch Auswahlmöglichkeiten in der Benutzeroberfläche möglich.
Aber dieses Problem kann viel einfacher, flexibler und eleganter gelöst werden — und natürlich mit Hilfe von Code. Für die Erstellung von Diagrammen jeder Komplexität haben wir mehrere spezialisierte Auszeichnungssprachen (DOT, GraphML usw.), sowie eine Vielzahl von Anwendungen (GraphViz, PlantUML, Mermaid), die diese Anweisungen lesen und in den unterschiedlichsten Formaten visualisieren können. Informationen über Objekte und ihre Beziehungen wissen wir bereits abzurufen.
Hier ist ein kleines Beispiel, wie das aussehen könnte, unter Verwendung von PlantUML und (links der SQL-Befehl, der die benötigte Anweisung für PlantUML generiert, und rechts das Ergebnis):
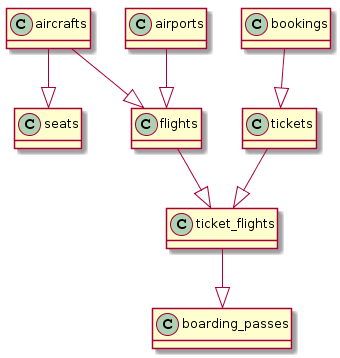
select '@startuml'||chr(10)||'hide methods'||chr(10)||'hide stereotypes' union all
select distinct ccu.table_name || ' --|> ' ||
tc.table_name as val
from table_constraints as tc
join key_column_usage as kcu
on tc.constraint_name = kcu.constraint_name
join constraint_column_usage as ccu
on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and tc.table_name ~ '.*' union all
select '@enduml'Wenn man sich ein wenig anstrengt, kann man auf Basis etwas schaffen, das einer echten ER-Diagramm sehr ähnlich sieht:
Der SQL-Befehl ist ein wenig komplizierter.
-- Kopf
select '@startuml
!define Table(name,desc) class name as "desc" << (T,#FFAAAA) >>
!define primary_key(x) <b>x</b>
!define unique(x) <color:green>x</color>
!define not_null(x) <u>x</u>
hide methods
hide stereotypes'
union all
-- Tabellen
select format('Table(%s, "%s n Informationen über %s") {'||chr(10), table_name, table_name, table_name) ||
(select string_agg(column_name || ' ' || upper(udt_name), chr(10))
from information_schema.columns
where table_schema = 'public'
and table_name = t.table_name) || chr(10) || '}'
from information_schema.tables t
where table_schema = 'public'
union all
-- Beziehungen zwischen Tabellen
select distinct ccu.table_name || ' "1" --> "0..N" ' || tc.table_name || format(' : "Ein %s kann viele %s haben"', ccu.table_name, tc.table_name)
from information_schema.table_constraints as tc
join information_schema.key_column_usage as kcu on tc.constraint_name = kcu.constraint_name
join information_schema.constraint_column_usage as ccu on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and ccu.constraint_schema = 'public'
and tc.table_name ~ '.*'
union all
-- Fußzeile
select '@enduml' 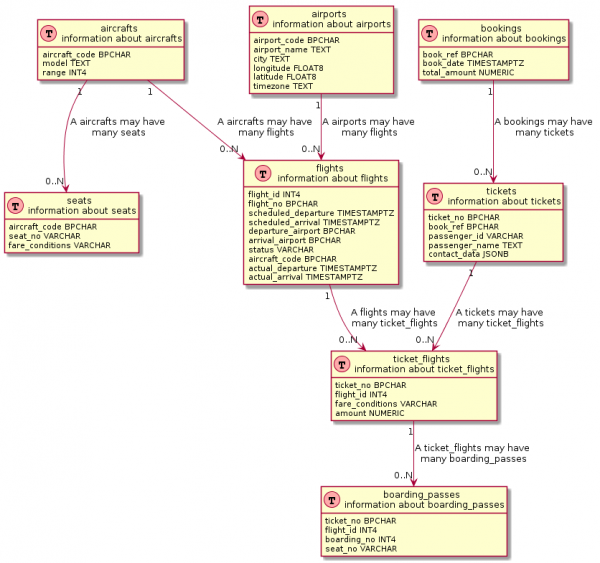
Wenn man genauer hinsieht, verwenden viele Visualisierungstools im Grunde ähnliche Abfragen. Diese Abfragen sind allerdings meistens tief , ganz zu schweigen von jeglicher Modifikation.
Metriken und Überwachung
Kommen wir nun zu einem traditionell komplexen Thema - der Überwachung der Datenbankleistung. Ich erinnere mich an eine kleine wahre Geschichte, die mir "ein Freund von mir" erzählt hat. In einem aktuellen Projekt gab es einen mächtigen DBA, den nur wenige Entwickler persönlich kannten und der auch nur selten gesehen wurde (obwohl es Gerüchte gab, dass er irgendwo im benachbarten Gebäude arbeitete). In der Stunde "X", wenn das Produktionssystem eines großen Einzelhändlers erneut "schlecht funktionierte", schickte er stillschweigend Screenshots von Grafiken aus dem Oracle Enterprise Manager, auf denen er kritische Bereiche mit einem roten Marker zur "Optimierung" markierte (das half, gelinde gesagt, nur wenig). Und so mussten wir mit diesen "Fotos" arbeiten. Dabei hatte niemand Zugang zum wertvollen (in jeder Hinsicht) Enterprise Manager, da das System komplex und teuer war und man befürchtete, dass "die Entwickler vielleicht etwas kaputt machen könnten". Daher fanden die Entwickler auf "empirische" Weise den Ort und die Ursache der Verzögerungen und veröffentlichten einen Patch. Wenn kein beängstigendes Schreiben des DBA kurz darauf wieder eintraf, atmeten alle erleichtert auf und kehrten zu ihren aktuellen Aufgaben zurück (bis zum nächsten Schreiben).
Der Monitoring-Prozess kann jedoch deutlich ansprechender und zugänglicher gestaltet werden, insbesondere die grundlegenden Aspekte, die als Ergänzung zu den Hauptüberwachungssystemen dienen (die zweifellos nützlich und in vielen Fällen unverzichtbar sind). Jede Datenbank (DB) ist bereit, Informationen über ihren aktuellen Zustand und ihre Leistung kostenlos und uneingeschränkt zur Verfügung zu stellen. In der 'blutigen' Oracle-Datenbank kann nahezu jede Leistungsinformation aus den systemischen Ansichten abgerufen werden, angefangen bei Prozessen und Sitzungen bis hin zum Status des Puffer-Caches (zum Beispiel, , Abschnitt 'Monitoring'). In PostgreSQL gibt es ebenfalls eine Vielzahl von systemischen Ansichten zur , insbesondere solche, die im Alltag eines jeden DBA unverzichtbar sind, wie , , . In MySQL gibt es sogar ein separates Schema dafür, . In MongoDB aggregiert der eingebaute Leistungsdaten in einer systemischen Sammlung, .
So kann man, ausgestattet mit einem beliebigen Metrik-Sammler (Telegraf, Metricbeat, Collectd), der in der Lage ist, benutzerdefinierte SQL-Abfragen auszuführen, einem Speicher für diese Metriken (InfluxDB, Elasticsearch, Timescaledb) und einem Visualisierungswerkzeug (Grafana, Kibana), ein relativ einfaches und flexibles Überwachungssystem erhalten, das eng mit anderen allgemeinen Systemmetriken (z. B. von Anwendungsservern, Betriebssystemen usw. erhalten) integriert ist. Wie es beispielsweise in pgwatch2 umgesetzt ist, wo die Kombination InfluxDB + Grafana verwendet wird und eine Reihe von Abfragen an systemische Ansichten, zu denen auch benutzerdefinierte Abfragen hinzugefügt werden können, erfolgt. .
Gesamt
Und das ist nur eine ungefähre Liste dessen, was man mit unserer Datenbank durch gewöhnlichen SQL-Code machen kann. Ich bin sicher, dass es noch viele weitere Anwendungsmöglichkeiten gibt, also hinterlasst eure Kommentare. Über das Automatisieren dieser Prozesse und deren Integration in euren CI/CD-Pipeline werden wir beim nächsten Mal sprechen.
Quelle: habr.com
