

Hallo, Habr!
Daten sind das wertvollste Gut eines Unternehmens. Dies betont nahezu jedes Unternehmen mit digitalem Fokus. Daran ist schwer zu rütteln: Keine bedeutende IT-Konferenz kommt heute ohne Diskussionen über Ansätze zur Verwaltung, Speicherung und Verarbeitung von Daten aus.
Daten gelangen von außen zu uns, sie bilden sich aber auch innerhalb des Unternehmens. Wenn es um die Daten eines Telekommunikationsunternehmens geht, sind sie für die internen Mitarbeiter eine Goldmine an Informationen über den Kunden, seine Interessen, Gewohnheiten und seinen Standort. Bei einer präzisen Profilierung und Segmentierung werden Werbeangebote am effektivsten. In der Praxis sieht es jedoch nicht immer so rosig aus. Die Daten, die Unternehmen speichern, können hoffnungslos veraltet, überflüssig, redundant oder nur einer kleinen Gruppe von Nutzern bekannt sein.
In einem Wort, Daten müssen effektiv verwaltet werden – nur so können sie zu einem wertvollen Asset für das Geschäft werden, das echte Vorteile und Gewinne bringt. Leider müssen beim Management von Daten viele Herausforderungen überwunden werden. Diese ergeben sich hauptsächlich sowohl aus dem historischen Erbe in Form von "Zoo-Systemen" als auch aus dem Fehlen einheitlicher Prozesse und Ansätze zu ihrer Verwaltung. Aber was bedeutet es, Daten zu "verwalten"?
Genau darüber werden wir unter dem Cut sprechen, sowie darüber, wie uns der Open-Source-Stack dabei geholfen hat.
Das Konzept des strategischen Datenmanagements, Data Governance (DG), ist bereits auf dem russischen Markt bekannt, und die Ziele, die Unternehmen durch dessen Implementierung erreichen, sind klar und deutlich formuliert. Auch unser Unternehmen hat sich das Ziel gesetzt, die Datenmanagement-Konzeption zu implementieren.
Also, womit haben wir begonnen? Zunächst haben wir uns unsere Schlüsselziele definiert:
- Die Verfügbarkeit unserer Daten sicherstellen.
- Die Transparenz des Lebenszyklus der Daten gewährleisten.
- Den Nutzern des Unternehmens konsistente und widerspruchsfreie Daten bereitstellen.
- Den Nutzern des Unternehmens überprüfte Daten zur Verfügung stellen.
Aktuell gibt es auf dem Softwaremarkt eine Vielzahl von Tools im Bereich Data Governance.
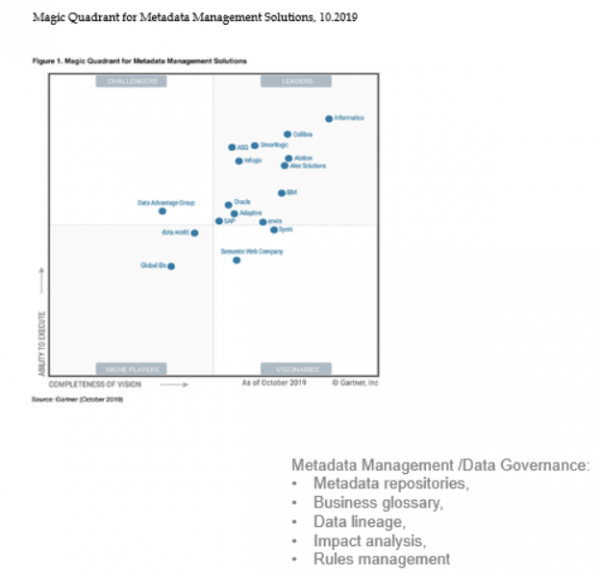
Nach eingehender Analyse und Untersuchung der Lösungen haben wir eine Reihe kritischer Anmerkungen festgehalten:
- Die meisten Anbieter offerieren ein umfassendes Lösungspaket, das für uns überflüssig ist und bereits bestehende Funktionen dupliziert. Zudem ist die Integration in die aktuelle IT-Landschaft ressourcenintensiv und kostspielig.
- Die Funktionalität und das Interface sind für Techniker und nicht für die Endanwender im Geschäft konzipiert.
- Geringe Akzeptanz der Produkte und mangelnde erfolgreiche Implementierungen auf dem russischen Markt.
- Hohe Kosten für die Software und deren zukünftige Wartung.
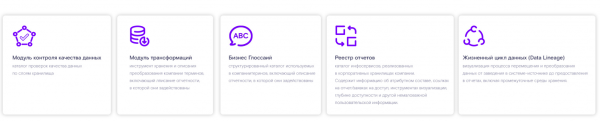
Die genannten Kriterien und Empfehlungen hinsichtlich der Importersatzmaßnahmen für russische Unternehmen haben uns überzeugt, in Richtung einer eigenen Entwicklung auf einem Open-Source-Stack zu gehen. Als Plattform haben wir Django ausgewählt – ein kostenloses und freies Framework, das in Python geschrieben ist. Damit haben wir für uns die Schlüsselmodule identifiziert, die die oben genannten Ziele unterstützen werden:
- Berichteregister.
- Business-Glossar.
- Modul zur Beschreibung technischer Transformationen.
- Modul zur Beschreibung des Lebenszyklus von Daten vom Ursprungsort bis zum BI-Tool.
- Modul zur Qualitätskontrolle von Daten.
Berichtsregister
Laut internen Studien in großen Unternehmen verbringen Mitarbeiter bei der Lösung datenbezogener Aufgaben 40-80 % ihrer Zeit mit der Suche nach Informationen. Daher haben wir uns zum Ziel gesetzt, Informationen über vorhandene Berichte, die zuvor nur für Auftraggeber zugänglich waren, offenzulegen. Damit reduzieren wir die Zeit zur Erstellung neuer Berichte und fördern die Demokratisierung von Daten.
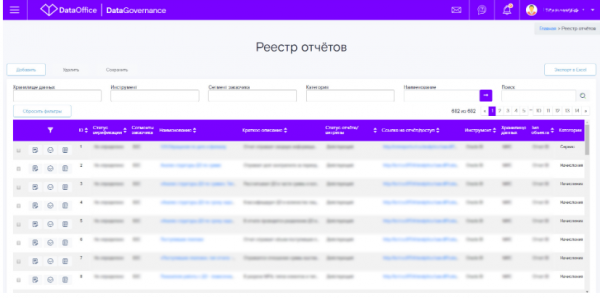
Das Berichtsregister ist zu einem einheitlichen Berichtsfenster für interne Benutzer aus verschiedenen Regionen, Abteilungen und Einheiten geworden. Es konsolidiert Informationen über Informationsservices, die in mehreren Unternehmensdatenbanken erstellt wurden, und davon gibt es bei Rostelekom zahlreiche.
Aber das Register ist nicht nur eine trockene Liste der entwickelten Berichte. Für jeden Bericht stellen wir die für den Benutzer erforderlichen Informationen zur Verfügung, um sich eigenständig damit vertraut zu machen:
- eine kurze Beschreibung des Berichts;
- Tiefe der Datenverfügbarkeit;
- Kundensegment;
- Visualisierungstool;
- Bezeichnung des Unternehmensspeichers;
- geschäftliche Funktionsanforderungen;
- Link zum Bericht;
- Link zur Anfrage für den Zugang;
- Implementierungsstatus.
Die Berichte bieten eine Analyse der Nutzungsebene, und die Berichte landen aufgrund der Log-Analysen hinsichtlich der Anzahl der einzigartigen Benutzer in der Top-Liste. Und das ist noch nicht alles. Neben den allgemeinen Eigenschaften haben wir auch eine detaillierte Beschreibung der attributiven Zusammensetzung der Berichte mit Beispielen von Werten und Berechnungsmethoden eingeplant. Eine solche Detaillierung gibt dem Benutzer sofort eine Antwort, ob der Bericht für ihn nützlich ist oder nicht.
Die Entwicklung dieses Moduls war ein wichtiger Schritt zur Demokratisierung der Daten und hat die Zeit zur Suche der benötigten Informationen erheblich verkürzt. Neben der Verkürzung der Suchzeit ist auch die Anzahl der Anfragen an das Support-Team für Beratungen gesunken. Ein weiteres nützliches Ergebnis, das wir durch die Entwicklung eines einheitlichen Berichtsregisters erreicht haben, ist die Vermeidung der Entwicklung redundanter Berichte für verschiedene organisatorische Einheiten.
Geschäftsglossar
Sie wissen alle, dass selbst innerhalb eines Unternehmens unterschiedliche geschäftliche Sprachen gesprochen werden. Ja, dieselben Begriffe werden verwendet, aber sie bedeuten ganz verschiedene Dinge. Um dieses Problem zu lösen, dient das Geschäfts-Glossar.
Für uns ist das Geschäfts-Glossar nicht nur ein Nachschlagewerk mit Beschreibungen von Begriffen und Berechnungsmethoden. Es ist eine vollständige Entwicklungsumgebung für die Harmonisierung und Genehmigung von Terminologie sowie zum Aufbau von Verbindungen zwischen Begriffen und anderen Informationsressourcen des Unternehmens. Bevor ein Begriff in das Geschäfts-Glossar aufgenommen wird, muss er alle Genehmigungsstufen mit den Fachabteilungen und dem Datenqualitätszentrum durchlaufen. Erst danach steht er zur Nutzung bereit.
Wie bereits erwähnt, besteht die Einzigartigkeit dieses Instruments darin, dass es Verbindungen von der Ebene des Geschäftswortes zu spezifischen Benutzerberichten, in denen es verwendet wird, sowie zur Ebene physischer Datenbankobjekte herstellen kann.
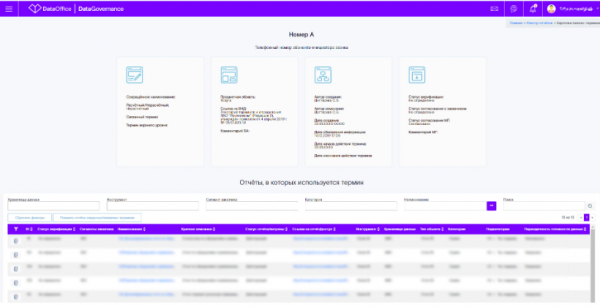
Dies wurde durch die Verwendung von Glossar-Identifikatoren in der detaillierten Beschreibung der Berichte aus dem Register und der Beschreibung physischer Datenbankobjekte möglich.
Im Glossar sind inzwischen über 4000 Begriffe definiert und abgestimmt. Seine Nutzung vereinfacht und beschleunigt die Bearbeitung eingehender Änderungsanfragen in den Informationssystemen des Unternehmens. Wenn der erforderliche KPI bereits in irgendeinem Bericht implementiert ist, sieht der Benutzer sofort eine Auswahl von Berichten, in denen dieser KPI verwendet wird, und kann entscheiden, ob die vorhandene Funktionalität effizient wiederverwendet oder minimal angepasst werden soll, ohne neue Anfragen zur Entwicklung eines neuen Berichts zu initiieren.
Modul zur Beschreibung technischer Transformationen und Data Lineage
Sie fragen sich, was das für Module sind? Es reicht nicht aus, nur das Berichteregister und das Glossar zu implementieren; es ist auch notwendig, alle Geschäftstermine auf das physische Datenmodell zu übertragen. Damit konnten wir den Prozess des Datenlebenszyklus von den Quellsystemen bis zur BI-Visualisierung über alle Schichten des Data Warehouses abschließen. Mit anderen Worten — wir haben Data Lineage aufgebaut.
Wir haben eine Benutzeroberfläche entwickelt, die auf dem zuvor im Unternehmen verwendeten Format zur Beschreibung von Regeln und Logik zur Datenverarbeitung basiert. Über die Benutzeroberfläche wird weiterhin dieselbe Information eingegeben wie zuvor, jedoch ist es nun zwingend erforderlich, den Identifikator des Begriffs aus dem Geschäftsglossar anzugeben. Auf diese Weise stellen wir die Verbindung zwischen den geschäftlichen und physischen Schichten her.
Für wen ist das nötig? Was war mit dem alten Format, das wir mehrere Jahre lang verwendet haben, nicht in Ordnung? Wie sehr haben sich die Arbeitsaufwände zur Erstellung von Anforderungen erhöht? Mit solchen Fragen sahen wir uns während der Implementierung des Tools konfrontiert. Hier sind die Antworten recht einfach – es ist für uns alle notwendig, für das Datenbüro unseres Unternehmens und für unsere Nutzer.
Tatsächlich mussten sich die Mitarbeiter umstellen, was zunächst zu einem geringfügigen Anstieg des Arbeitsaufwands für die Dokumentation führte. Aber dieses Problem haben wir gelöst. Die Praxis, das Identifizieren und Optimieren von Problembereichen hat ihren Teil dazu beigetragen. Unser größtes Ziel haben wir erreicht – die Qualität der entwickelten Anforderungen hat sich verbessert. Pflichtfelder, einheitliche Verzeichnisse, Eingabemasken und integrierte Prüfungen – all dies hat es uns ermöglicht, die Qualität der Transformationsbeschreibungen erheblich zu steigern. Wir haben die Praxis aufgegeben, Skripte in Form von Entwicklungsanforderungen weiterzugeben, und das Wissen, das zuvor nur dem Entwicklungsteam zur Verfügung stand, geteilt. Die erstellte Metadatenbasis reduziert die Zeit für die Durchführung von Regressionstests erheblich und ermöglicht eine schnelle Bewertung der Auswirkungen von Änderungen auf jeder Ebene der IT-Landschaft (Berichte aus Schaufenstern, Aggregate, Quellen).
Aber was haben die normalen Benutzer von den Berichten für Vorteile? Dank der Möglichkeit der Erstellung von Data Lineage erhalten unsere Benutzer, selbst solche, die mit SQL und anderen Programmiersprachen nicht vertraut sind, schnell Informationen über die Quellen und Objekte, auf deren Basis ein bestimmter Bericht erstellt wird.
Modul zur Qualitätskontrolle von Daten
Alles, was wir oben in Bezug auf die Gewährleistung der Transparenz von Daten besprochen haben, ist irrelevant, ohne das Verständnis, dass die Daten, die wir unseren Benutzern bereitstellen, korrekt sind. Eines der wichtigen Module unseres Data Governance-Konzepts ist das Modul zur Qualitätskontrolle von Daten.
In der aktuellen Phase handelt es sich um ein Verzeichnis von Überprüfungen für ausgewählte Entitäten. Das nächste Ziel für die Produktentwicklung ist die Erweiterung der Prüfliste und die Integration mit dem Berichtregister.
Was bringt das und wem nützt es? Für den Endbenutzer wird im Register Informationen über geplante und tatsächliche Fertigstellungstermine der Berichte verfügbar sein, Ergebnisse der durchgeführten Prüfungen mit dynamischen Angaben sowie Daten zu den in den Bericht geladenen Quellen.
Für uns ist das in die Arbeitsabläufe integrierte Modul zur Datenqualität:
- Die umgehende Erfüllung der Erwartungen der Kunden.
- Entscheidungen über die weitere Nutzung von Daten.
- Erhalt eines vorläufigen Sets von Problemfällen in den frühen Phasen der Arbeiten zur Entwicklung regelmäßiger Qualitätskontrollen.
Dies sind definitiv die ersten Schritte zum Aufbau eines umfassenden Datenmanagementprozesses. Wir sind jedoch überzeugt, dass wir unseren Kunden nur durch gezielte Arbeit, aktive Integration von Data Governance-Tools in den Arbeitsprozess, zu Informiertheit, hohem Vertrauen in die Daten, Transparenz bei der Datenerhebung und einer schnelleren Bereitstellung neuer Funktionen verhelfen können.
Das DataOffice-Team
Quelle: habr.com
