

DataHub mit offenem Quellcode: Eine Plattform zur Suche und Entdeckung von Metadaten von LinkedIn
Eine schnelle Suche nach den benötigten Daten ist entscheidend für jedes Unternehmen, das auf eine große Menge an Daten angewiesen ist, um datenbasierte Entscheidungen zu treffen. Dies beeinflusst nicht nur die Produktivität der Datennutzer (einschließlich Analysten, Machine Learning-Entwickler, Datenanalysten und Data Engineers), sondern hat auch direkte Auswirkungen auf die Endprodukte, die auf einer qualitativ hochwertigen Machine Learning (ML)-Pipeline basieren. Darüber hinaus wirft der Trend zur Implementierung oder Erstellung von Machine Learning-Plattformen die Frage auf: Wie gehen Sie mit der internen Entdeckung von Funktionen, Modellen, Metriken, Datensätzen usw. um?
In diesem Artikel erläutern wir, wie wir Datenquellen unter offener Lizenz veröffentlicht haben auf unserer Plattform zur Suche und Entdeckung von Metadaten, seit den Anfängen des Projekts . LinkedIn betreibt eine eigene Version von DataHub, die sich von der Open-Source-Version unterscheidet. Wir beginnen mit einer Erklärung, warum wir zwei separate Entwicklungsumgebungen benötigen, gefolgt von einer Diskussion über die ersten Ansätze zur Verwendung von WhereHows mit Open Source und einem Vergleich unserer internen (Produktions-)Version von DataHub mit der Version auf . Wir werden auch Details zu unserer neuen automatisierten Lösung teilen, um Open-Source-Updates zu senden und zu empfangen, um beide Repositories zu synchronisieren. Schließlich geben wir Anleitungen, wie Sie mit der Open-Source-Version von DataHub beginnen können und diskutieren kurz seine Architektur.

WhereHows ist jetzt DataHub!
Das Metadata-Team von LinkedIn hat zuvor vorgestellt (Nachfolger von WhereHows), die Plattform für die Suche und Entdeckung von Metadaten bei LinkedIn, und teilte die Pläne für deren Einführung. Kurz nach dieser Ankündigung haben wir die Alpha-Version von DataHub veröffentlicht und sie mit der Community geteilt. Seitdem haben wir kontinuierlich zum Repository beigetragen und mit interessierten Nutzern zusammengearbeitet, um die gefragtesten Funktionen hinzuzufügen und Probleme zu lösen. Jetzt freuen wir uns, die offizielle Veröffentlichung anzukündigen. .
Open-Source-Ansätze
WhereHows, das ursprüngliche Portal von LinkedIn zur Daten- und Herkunftssuche, wurde als internes Projekt eröffnet; das Metadatenteam hat es 2016 freigegeben. . Seitdem hat das Team stets zwei unterschiedliche Codebasen unterstützt – eine für den Open Source-Bereich und eine für die interne Nutzung bei LinkedIn, da nicht alle Produktfunktionen, die für die Anwendungsfälle von LinkedIn entwickelt wurden, allgemein auf ein breiteres Publikum anwendbar waren. Zudem hat WhereHows einige interne Abhängigkeiten (Infrastruktur, Bibliotheken usw.), deren Quellcode nicht offengelegt ist. In den folgenden Jahren durchlief WhereHows zahlreiche Iterationen und Entwicklungszyklen, was die Synchronisation der beiden Codebasen zu einer großen Herausforderung machte. Das Metadaten-Team hat über die Jahre hinweg versucht, verschiedene Ansätze zu nutzen, um die interne Entwicklung und die Open Source-Entwicklung zu synchronisieren.
Erster Versuch: „Zuerst Open Source“
Ursprünglich folgten wir dem Modell der "Open-Source-Entwicklung", bei dem die Hauptentwicklung in einem Repository für offener Code stattfindet und die Änderungen für interne Bereitstellungen vorgenommen werden. Das Problem bei diesem Ansatz besteht darin, dass der Code immer zuerst auf GitHub hochgeladen wird, bevor er intern vollständig überprüft wird. Bis die Änderungen aus dem Open-Source-Repository übernommen und eine neue interne Bereitstellung durchgeführt werden, erkennen wir keine produktionsrelevanten Probleme. Im Falle einer fehlerhaften Bereitstellung war es zudem sehr schwierig, den Schuldigen zu identifizieren, da die Änderungen in Gruppen vorgenommen wurden.
Darüber hinaus hat dieses Modell die Produktivität des Teams bei der Entwicklung neuer Funktionen, die schnelle Iterationen erforderten, verringert, da alle Änderungen zunächst im Open-Source-Repository gespeichert und anschließend in das interne Repository übertragen werden mussten. Um die Bearbeitungszeit zu verkürzen, konnten erforderliche Korrekturen oder Änderungen zunächst im internen Repository vorgenommen werden, was jedoch ein enormes Problem darstellte, als es darum ging, diese Änderungen wieder in das Open-Source-Repository zu integrieren, da die beiden Repositories aus der Synchronisierung geraten waren.
Dieses Modell lässt sich viel einfacher für gemeinsame Plattformen, Bibliotheken oder Infrastrukturprojekte umsetzen als für voll funktionsfähige benutzerdefinierte Webanwendungen. Darüber hinaus eignet sich dieses Modell hervorragend für Projekte, die von Tag eins mit Open Source beginnen. WhereHows wurde jedoch als vollständig internes Webanwendungsprojekt entwickelt. Es war wirklich schwierig, sich vollständig von allen internen Abhängigkeiten zu abstrahieren, weshalb wir den internen Fork beibehalten mussten. Allerdings hat die Beibehaltung des internen Forks und die hauptsächliche Entwicklung auf Basis von Open Source nicht ganz funktioniert.
Zweiter Versuch: "Zuerst intern"
** Als zweiten Versuch haben wir das Entwicklungsmodell „zuerst intern“ eingeführt, bei dem die Hauptentwicklung intern im Unternehmen erfolgt und Änderungen regelmäßig im Open-Source-Code vorgenommen werden. Obwohl dieses Modell am besten für unseren Anwendungsfall geeignet ist, gibt es Herausforderungen. Die direkte Übertragung aller Unterschiede in das Open-Source-Repository und der anschließende Versuch, später Konflikte beim Mergen zu lösen, ist eine Möglichkeit, die jedoch viel Zeit in Anspruch nimmt. In den meisten Fällen versuchen die Entwickler, dies bei jeder Codeüberprüfung zu vermeiden. Infolgedessen wird es viel seltener, in Chargen durchgeführt, was die anschließende Lösung von Merge-Konflikten erschwert.
Beim dritten Mal hat es geklappt!
Die beiden oben genannten gescheiterten Versuche führten dazu, dass das WhereHows-Repository auf GitHub für lange Zeit veraltet blieb. Das Team arbeitete weiterhin an der Verbesserung der Funktionen und der Architektur des Produkts, weshalb die interne Version von WhereHows für LinkedIn immer weiter fortschrittlicher wurde als die Open-Source-Version. Sogar ein neuer Name wurde eingeführt - DataHub. Basierend auf den vorherigen Fehlschlägen entschied sich das Team, eine skalierbare, langfristige Lösung zu entwickeln.
Für jedes neue Open-Source-Projekt berät und unterstützt das Entwicklerteam von LinkedIn ein Entwicklungsmodell, bei dem die Module des Projekts vollständig in Open Source entwickelt werden. Versionierte Artefakte werden in einem öffentlichen Repository bereitgestellt und dann über ein internes LinkedIn-Artefakt zurückgeführt mithilfe von . Die Einhaltung dieses Entwicklungsmodells ist nicht nur vorteilhaft für die Nutzer von Open Source, sondern führt auch zur Schaffung einer modulareren, erweiterbaren und integrierbaren Architektur.
Um dieses Niveau für eine reife interne Anwendung wie DataHub zu erreichen, ist jedoch eine erhebliche Menge an Zeit erforderlich. Dies schließt auch die Möglichkeit einer vollständig funktionalen Open-Source-Implementierung aus, bevor alle internen Abhängigkeiten vollständig abstrahiert sind. Deshalb haben wir Tools entwickelt, die uns helfen, schneller und weniger schmerzhaft zu Open-Source-Beiträgen zu gelangen. Diese Lösung ist sowohl für das Metadaten-Team (DataHub-Entwickler) als auch für die Open-Source-Community von Vorteil. In den folgenden Abschnitten wird dieser neue Ansatz erörtert.
Automatisierung der Veröffentlichung mit Open Source
Der neueste Ansatz der Metadaten-Gruppe für DataHub mit Open Source besteht darin, ein Werkzeug zu entwickeln, das automatisch den internen Code und das Open-Source-Repository synchronisiert. Die hochrangigen Funktionen dieses Werkzeugs umfassen:
- Synchronisation von LinkedIn-Code mit / aus Open Source, ähnlich wie bei .
- Generierung des Lizenzkopfes, ähnlich wie bei .
- Automatisierte Erstellung von Commit-Protokollen aus internen Commit-Logs mit Open-Source-Code.
- Verhinderung interner Änderungen, die den Open-Source-Bau stören, durch .
In den folgenden Unterabschnitten werden die oben genannten Funktionen mit interessanten Herausforderungen detailliert behandelt.
Synchronisation des Quellcodes.
Im Gegensatz zur Open-Source-Version von DataHub, die ein einzelnes GitHub-Repository darstellt, ist die LinkedIn-Version von DataHub eine Kombination mehrerer Repositories (unternehmensintern als ). Die DataHub-Oberfläche, die Bibliothek der Metadatenmodelle, der serverseitige Dienst für Metadatenspeicher und die Streaming-Aufgaben befinden sich in verschiedenen Repositories bei LinkedIn. Um die Benutzerfreundlichkeit für Open-Source-Nutzer zu verbessern, haben wir jedoch ein einziges Repository für die Open-Source-Version von DataHub eingerichtet.
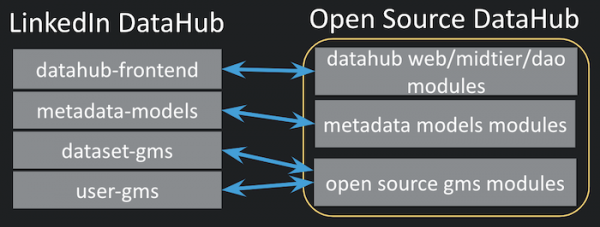
Abbildung 1: Synchronisation zwischen den Repositories LinkedIn DataHub und dem einzelnen Repository DataHub mit Open-Source-Code.
Um die automatisierten Abläufe für den Aufbau, Versand und Abruf zu unterstützen, erstellt unser neues Tool automatisch eine Dateizuordnung, die jeder Quelldatei entspricht. Für das Tool ist jedoch eine anfängliche Konfiguration erforderlich, und die Benutzer müssen eine hochgradige Zuordnung der Module bereitstellen, wie unten dargestellt.
{
"datahub-dao": [
"${datahub-frontend}/datahub-dao"
],
"gms/impl": [
"${dataset-gms}/impl",
"${user-gms}/impl"
],
"metadata-dao": [
"${metadata-models}/metadata-dao"
],
"metadata-builders": [
"${metadata-models}/metadata-builders"
]
}Die Modulzuordnung ist ein einfaches JSON, dessen Schlüssel die Zielmodule im Open-Source-Repository und deren Werte eine Liste der Quelmodule in den LinkedIn-Repositories sind. Jedes Zielmodul im Open-Source-Repository kann von beliebig vielen Quelmodulen gespeist werden. Für die Bezeichnung der internen Repositories in den Quelmodulen wird im Bash-Stil verwendet. Mithilfe der Modulzuordnungsdatei erstellt das Tool eine Dateizuordnung, indem es alle Dateien in den verknüpften Verzeichnissen scannt.
{
"${metadata-models}/metadata-builders/src/main/java/com/linkedin/Foo.java":
"metadata-builders/src/main/java/com/linkedin/Foo.java",
"${metadata-models}/metadata-builders/src/main/java/com/linkedin/Bar.java":
"metadata-builders/src/main/java/com/linkedin/Bar.java",
"${metadata-models}/metadata-builders/build.gradle": null,
}Die Zuordnung von Dateien wird automatisch von den Tools erstellt; sie kann jedoch auch manuell vom Benutzer aktualisiert werden. Diese Zuordnung stellt eine 1:1-Beziehung zwischen der ursprünglichen LinkedIn-Datei und der Datei im Open-Source-Repository dar. Es gibt mehrere Regeln, die mit dieser automatischen Erstellung der Dateizuordnung verbunden sind:
- Bei mehreren Quellmodulen für das Zielmodul im Open Source können Konflikte auftreten, beispielsweise wenn dasselbe , in mehr als einem Quellmodul existiert. Als Konfliktlösungsstrategie verwenden unsere Tools standardmäßig die Option 'Last wins'.
- "null" bedeutet, dass die Quelldatei nicht Teil des Open-Source-Repositories ist.
- Nach jedem Push oder Pull aus dem Open Source wird diese Zuordnung automatisch aktualisiert und ein Snapshot erstellt. Dies ist notwendig, um Hinzufügungen und Löschungen des Quellcodes nach der letzten Aktion zu bestimmen.
Commit-Logs erstellen
Die Logs für Commits im Open Source werden ebenfalls automatisch erstellt, indem die Logs der internen Repositories zusammengeführt werden. Unten finden Sie ein Beispiel für ein Commit-Log, das die Struktur eines von unserem Tool erstellten Logs zeigt. Das Commit gibt eindeutig an, welche Versionen der Quell-Repositories in diesem Commit gebündelt sind und bietet eine Zusammenfassung des Commit-Logs. Überprüfen Sie dieses an einem echten Beispiel eines Commit-Logs, das von unserem Werkzeug erstellt wurde.
metadata-models 29.0.0 -> 30.0.0
Aspektmodell foo hinzugefügt
Fehler bei bar behoben
dataset-gms 2.3.0 -> 2.3.4
REST.li API hinzugefügt, um den Aspekt foo bereitzustellen
MP_VERSION=dataset-gms:2.3.4
MP_VERSION=metadata-models:30.0.0Abhängigkeitsprüfung
LinkedIn hat , die dafür sorgt, dass Änderungen am internen Multiprojekt die Zusammenstellung abhängiger Multiprojekte nicht beeinträchtigen. Das Open-Source-Repository DataHub ist kein Multiprojekt und kann nicht direkt von einem Multiprojekt abhängig sein. Mit einer Multiprojekt-Hülle, die den Quellcode von DataHub extrahiert, können wir jedoch weiterhin dieses Abhängigkeitstest-System nutzen. Somit löst jede Veränderung (die möglicherweise später veröffentlicht wird) in einem der Multiprojekte, die das Open-Source-Repository DataHub speisen, ein Build-Event in der Multiprojekt-Hülle aus. Daher durchläuft jede Änderung, die den Aufbau der Multiprojekt-Hülle verhindert, die Tests nicht, bevor der Quellcode des ursprünglichen Multiprojekts eingegeben wird, und wird zurückgewiesen.
Dies ist ein nützliches Mechanismus, das hilft, jeden internen Commit zu verhindern, der den Build mit öffentlichem Quellcode stört, und ihn während des Commit-Vorgangs zu erkennen. Ohne dies wäre es ziemlich schwierig festzustellen, welcher interne Commit zu einem Fehler im Build des öffentlichen Repositories geführt hat, da wir paketweise interne Änderungen im öffentlichen DataHub-Repository durchführen.
Unterschiede zwischen dem öffentlichen DataHub und unserer Produktionsversion
Bis zu diesem Punkt haben wir unsere Lösung zur Synchronisierung der beiden Versionen der DataHub-Repositories erörtert, jedoch bislang nicht die Gründe benannt, warum wir überhaupt zwei verschiedene Entwicklungsströme benötigen. In diesem Abschnitt werden wir die Unterschiede zwischen der öffentlichen Version von DataHub und der Produktionsversion auf den LinkedIn-Servern auflisten und die Gründe für diese Unterschiede erläutern.
Eine der Quellen für Diskrepanzen ergibt sich daraus, dass unsere Produktionsversion Abhängigkeiten von Code hat, der noch nicht Open Source ist, wie etwa LinkedIn's Offspring (die interne Struktur zur Implementierung von Abhängigkeiten bei LinkedIn). Offspring wird in der internen Codebasis weitläufig verwendet, da es die bevorzugte Methode zur Verwaltung dynamischer Konfigurationen ist. Da es jedoch nicht Open Source ist, mussten wir alternative Open-Source-Lösungen für DataHub finden.
Es gibt auch andere Gründe. Während wir Erweiterungen des Metadatenmodells für die Bedürfnisse von LinkedIn erstellen, sind diese Erweiterungen in der Regel sehr spezifisch für LinkedIn und lassen sich möglicherweise nicht direkt auf andere Umgebungen anwenden. Zum Beispiel haben wir sehr spezifische Tags für Teilnehmeridentifikatoren und andere Arten von Metadatenübereinstimmungen. Daher haben wir diese Erweiterungen derzeit aus dem Open-Source-Metadatenmodell von DataHub ausgeschlossen. Während wir mit der Community interagieren und deren Bedürfnisse verstehen, werden wir an gemeinsamen Versionen dieser Open-Source-Erweiterungen arbeiten, wenn dies notwendig ist.
Die Benutzerfreundlichkeit und die einfachere Anpassung für die Community des Open Source haben auch einige Unterschiede zwischen den beiden Versionen von DataHub inspiriert. Unterschiede in der Streaming-Infrastruktur sind ein gutes Beispiel dafür. Während unsere interne Version eine verwaltete Streaming-Infrastruktur nutzt, haben wir uns entschieden, für die Open-Source-Version die integrierte (standalone) Streaming-Verarbeitung zu verwenden, da dies die Schaffung einer weiteren Infrastrukturschicht vermeidet.
Ein weiteres Beispiel für den Unterschied ist die Verwendung eines einzigen GMS (Generalized Metadata Storage) in der Open-Source-Implementierung anstelle mehrerer GMS. GMA (Generalized Metadata Architecture) ist der interne Architekturbegriff für DataHub, während GMS das Metadatenspeicher im Kontext von GMA bezeichnet. GMA ist eine sehr flexible Architektur, die es Ihnen ermöglicht, jede Datenkonstruktion (z. B. Datensätze, Benutzer usw.) in einem eigenen Metadatenspeicher oder mehrere Datenkonstruktionen in einem einzigen Metadatenspeicher zu speichern, solange das Register, das die Datenstruktur im GMS abbildet, aktualisiert wird. Zur Vereinfachung haben wir ein Exemplar von GMS gewählt, das alle verschiedenen Datenkonstruktionen im Open-Source-DataHub speichert.
Die vollständige Liste der Unterschiede zwischen den beiden Implementierungen finden Sie in der Tabelle unten.
Produktmerkmale
LinkedIn DataHub
Open Source DataHub
Unterstützte Datenkonstrukte
1) Datensätze 2) Benutzer 3) Metriken 4) ML-Funktionen 5) Diagramme 6) Dashboards
1) Datensätze 2) Benutzer
Unterstützte Metadatenquellen für Datensätze
1) 2) Couchbase 3) 4) 5) HDFS 6) Hive 7) Kafka 8) MongoDB 9) MySQL 10) Oracle 11) 12) Presto 12) 13) Teradata 13) Vector 14)
Hive Kafka RDBMS
Pub-sub
Confluent Kafka
Streamverarbeitung
Verwaltet
Eingebettet (Standalone)
Dependency Injection & dynamische Konfiguration
LinkedIn-Nachwuchs
Build-Tooling
Ligradle (Interner Gradle Wrapper von LinkedIn)
CI/CD
CRT (Internes CI/CD von LinkedIn)
und
Metadatenspeicher
Verteilte mehrere GMS: 1) Dataset GMS 2) User GMS 3) Metric GMS 4) Feature GMS 5) Chart/Dashboard GMS
Einzelnes GMS für: 1) Datensätze 2) Benutzer
Mikrodienste in Docker-Containern
vereinfacht die Bereitstellung und Verbreitung von Anwendungen durch . Jedes Element des DataHub-Open-Source-Services, einschließlich Infrastrukturkomponenten wie Kafka, , und , hat sein eigenes Docker-Image. Für die Orchestrierung von Docker-Containern haben wir .
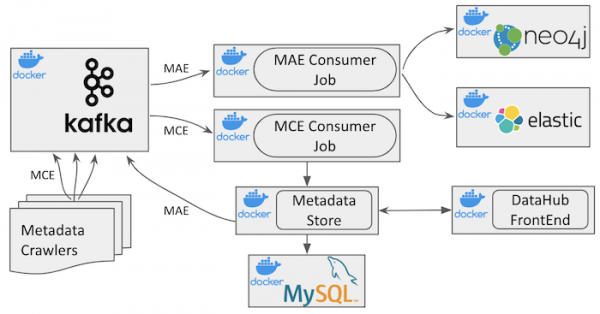
Abbildung 2: Architektur DataHub *Open Source*
Die hochrangige Architektur von DataHub ist in der obigen Abbildung zu sehen. Neben Infrastrukturkomponenten gibt es vier unterschiedliche Docker-Container:
datahub-gms: Metadaten-Speicherdienst
datahub-frontend: Anwendung , die das DataHub-Interface bedient.
datahub-mce-consumer: Anwendung , die den Datenstrom für die Änderung von Metadaten (MCE) verwendet und das Metadatenspeicher aktualisiert.
datahub-mae-consumer: Anwendung , die den Datenstrom für das Audit von Metadaten (MAE) verwendet und eine Suchindex- und Graphdatenbank erstellt.
Die Dokumentation zum Repository mit offenem Quellcode und enthält detailliertere Informationen über die Funktionen der verschiedenen Dienste.
CI/CD in DataHub mit offenem Quellcode
Das DataHub-Repository mit offenem Quellcode nutzt für kontinuierliche Integration und für kontinuierliche Bereitstellung. Beide haben eine gute Integration mit GitHub und sind einfach einzurichten. Für den Großteil der Open-Source-Infrastruktur, die von der Gemeinschaft oder privaten Unternehmen entwickelt wurde (z. B. ), werden Docker-Images erstellt und in Docker Hub bereitgestellt, um die Nutzung durch die Gemeinschaft zu erleichtern. Jedes Docker-Image, das in Docker Hub gefunden wird, kann einfach mit einem einfachen Befehl verwendet werden. .
Bei jedem Commit im Open-Source-Repository von DataHub werden alle Docker-Images automatisch erstellt und mit dem Tag 'latest' in Docker Hub bereitgestellt. Wenn in Docker Hub einige , werden alle Tags im Open-Source-Repository auch mit den entsprechenden Tag-Namen in Docker Hub veröffentlicht.
Die Nutzung von DataHub
ist sehr einfach und besteht aus drei einfachen Schritten:
- Klonen Sie das Open-Source-Repository und starten Sie alle Docker-Container mithilfe von docker-compose mit dem bereitgestellten docker-compose-Skript für einen schnellen Start.
- Laden Sie die im Repository bereitgestellten Beispieldaten mit dem ebenfalls bereitgestellten Command-Line-Tool herunter.
- Durchsuchen Sie DataHub in Ihrem Browser.
Aktiv überwacht ist ebenfalls eingerichtet für schnelle Fragen. Nutzer können auch Issues direkt im GitHub-Repository erstellen. Besonders freuen wir uns immer über Feedback und Vorschläge!
Zukunftspläne
Derzeit ist jede Infrastruktur oder Microservice für DataHub als Open-Source-Container in Docker aufgebaut, und das gesamte System wird verwaltet durch . Angesichts der Beliebtheit und weiten Verbreitung von , möchten wir in naher Zukunft auch eine Kubernetes-basierte Lösung anbieten.
Wir planen außerdem, eine schlüsselfertige Lösung für die Bereitstellung von DataHub in einem öffentlichen Cloud-Dienst wie , oder . Angesichts der jüngsten Ankündigung über die Migration von LinkedIn zu Azure entspricht dies den internen Prioritäten der Metadaten-Gruppe.
Und zuletzt, aber nicht weniger wichtig: Vielen Dank an alle ersten Nutzer von DataHub in der Open-Source-Community, die die Alpha-Versionen von DataHub bewertet und uns geholfen haben, Probleme zu erkennen und die Dokumentation zu verbessern.
Quelle: habr.com
