


Wie erkennt ein Backend-Entwickler, dass eine SQL-Abfrage in der Produktionsumgebung gut funktionieren wird? In großen oder schnell wachsenden Unternehmen haben nicht alle Mitarbeiter Zugang zur Produktivumgebung. Und selbst mit Zugang lassen sich viele Abfragen nicht schmerzlos testen, und das Erstellen einer Kopie der Datenbank dauert oft Stunden. Um diese Probleme zu lösen, haben wir einen künstlichen DBA – Joe – erschaffen. Er wurde bereits erfolgreich in mehreren Unternehmen implementiert und hilft mehreren Dutzend Entwicklern.
Video:

Hallo zusammen! Mein Name ist Anatoli Stansler. Ich arbeite bei . Wir sind darauf spezialisiert, den Entwicklungsprozess zu beschleunigen, indem wir Verzögerungen im Zusammenhang mit der Arbeit von Postgres für Entwickler, DBAs und QA beseitigen.
Wir haben großartige Kunden, und heute wird ein Teil des Vortrags den Fällen gewidmet, die wir in der Zusammenarbeit mit ihnen erlebt haben. Ich werde darüber berichten, wie wir ihnen geholfen haben, ernsthafte Probleme zu lösen.

Wenn wir Entwicklungen durchführen und komplexe migrationslastige Prozesse gestalten, stellen wir uns die Frage: „Wird diese Migration erfolgreich sein?“. Wir nutzen Reviews, wir greifen auf das Wissen erfahrener Kollegen und DBA-Experten zurück. Und sie können uns sagen – ob sie erfolgreich sein wird oder nicht.
Es wäre jedoch besser, wenn wir dies selbst an vollständigen Kopien testen könnten. Heute werden wir darüber sprechen, welche Ansätze es derzeit für das Testen gibt und wie man dies am besten durchführt und mit welchen Tools. Auch werden wir die Vor- und Nachteile dieser Ansätze erörtern und was wir hier verbessern können.
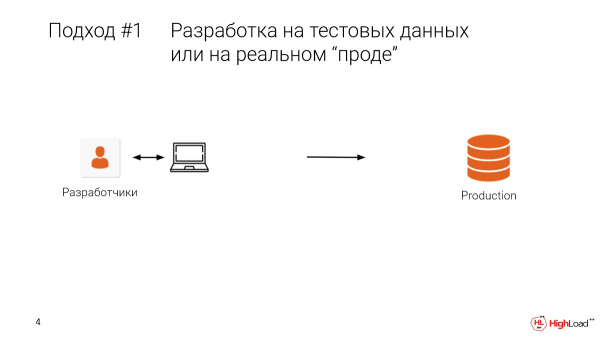
Wer hat jemals direkt in der Produktionsumgebung Indizes erstellt oder Änderungen vorgenommen? Ganz schön viele. Und wer hat dadurch Datenverluste oder Ausfallzeiten erlebt? Dann kennt ihr diesen Schmerz. Gott sei Dank gibt es Backups.

Der erste Ansatz ist das Testen in der Produktionsumgebung. Das bedeutet, dass der Entwickler von seinem lokalen Rechner aus arbeitet, Testdaten hat und eine eingeschränkte Auswahl hat. Dann gehen wir live und haben genau diese Situation.

Es tut weh und kostet viel. Wahrscheinlich sollte man das besser nicht so machen.
Wie kann man es besser machen?
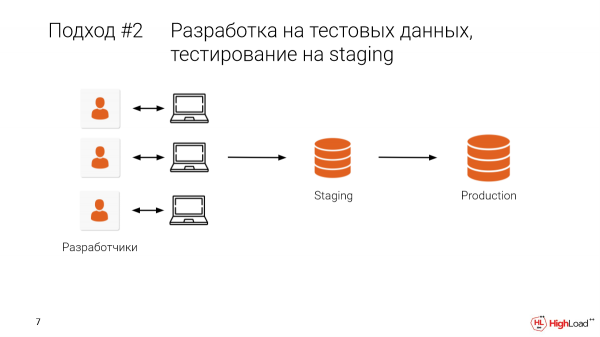
Lassen Sie uns eine Staging-Umgebung einrichten und einen Teil der Produktionsumgebung dort hervorheben. Oder im besten Fall nehmen wir die echte Produktionsumgebung, alle Daten. Und nachdem wir lokal entwickelt haben, sollten wir zusätzlich in der Staging-Umgebung prüfen.
Das wird es uns ermöglichen, einige Fehler zu vermeiden, d.h. sie nicht in die Produktionsumgebung zu bringen.
Welche Probleme gibt es?
- Das Problem ist, dass wir dieses Staging mit unseren Kollegen teilen. Und es passiert sehr oft, dass man eine Änderung vornimmt und plötzlich sind alle Daten weg, die Arbeit ist umsonst. Das Staging hatte mehrere Terabyte. Und man muss lange warten, bis es wieder hochgefahren wird. Wir entscheiden uns, das morgen zu überarbeiten. Damit steht unsere Entwicklung still.
- Und natürlich arbeiten dort viele Kollegen, viele Teams. Man muss die Änderungen manuell abstimmen. Das ist unpraktisch.

Es sei gesagt, dass wir nur einen Versuch haben, einen Schuss, wenn wir Änderungen an der Datenbank vornehmen, die Daten anfassen oder die Struktur ändern wollen. Wenn etwas schiefgeht, wenn es einen Fehler bei der Migration gibt, können wir nicht einfach zurückrollen.
Das ist besser als der vorherige Ansatz, aber es besteht immer noch eine hohe Wahrscheinlichkeit, dass ein Fehler in die Produktion gelangt.
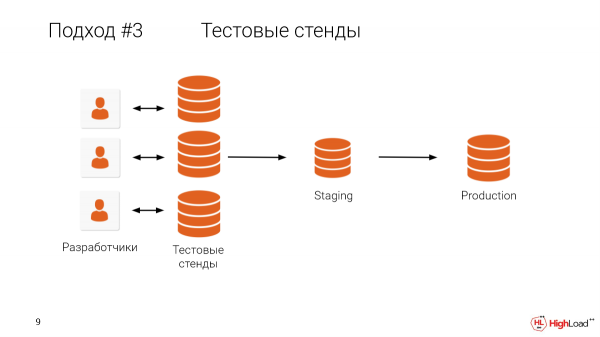
Was hindert uns daran, jedem Entwickler eine Testumgebung, eine vollwertige Kopie, zur Verfügung zu stellen? Ich denke, es ist klar, was uns dabei hindert.
Wer hat eine Datenbank von mehr als einem Terabyte? Mehr als die Hälfte des Raumes.
Und es ist klar, dass es sehr teuer ist, Maschinen für jeden Entwickler zu betreiben, wenn man eine so große Produktion hat, und es dauert dazu auch noch lange.
Wir haben Kunden, die erkannt haben, wie wichtig es ist, alle Änderungen auf vollständigen Kopien zu testen. Aber ihre Datenbank ist kleiner als ein Terabyte, und sie verfügen nicht über die Ressourcen, um für jeden Entwickler eine Testumgebung zu erstellen. Daher müssen sie Dumps lokal auf ihren Rechner herunterladen und auf diese Weise testen. Das kostet viel Zeit.

Selbst wenn Sie dies innerhalb der Infrastruktur tun, ist es bereits sehr gut, ein Terabyte Daten mit einer Geschwindigkeit von einer Stunde herunterzuladen. Aber sie verwenden logische Dumps; sie laden lokal aus der Cloud herunter. Für sie beträgt die Geschwindigkeit etwa 200 Gigabyte pro Stunde. Und man benötigt auch Zeit, um aus dem logischen Dump zu entpacken, Indizes anzuwenden usw.
Aber sie verwenden diesen Ansatz, weil er es ermöglicht, die Produktion zuverlässig zu halten.
Was können wir hier tun? Lassen Sie uns die Testumgebungen kostengünstig gestalten und jedem Entwickler seine eigene Testumgebung zur Verfügung stellen.
Und das ist möglich.
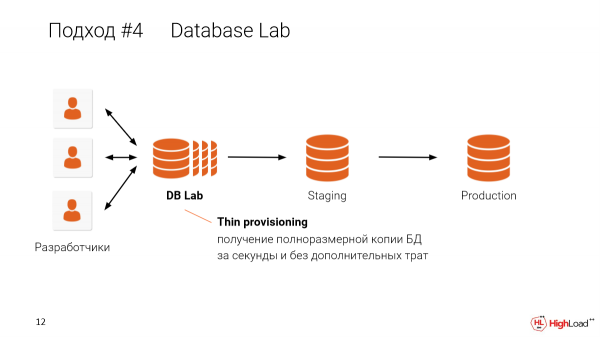
Und mit diesem Ansatz, bei dem wir dünne Klone für jeden Entwickler erstellen, können wir das auf einer Maschine teilen. Wenn Sie beispielsweise eine vier Terabyte große Datenbank haben und diese zehn Entwicklern zur Verfügung stellen möchten, müssen Sie nicht zehnmal vier Terabyte große Datenbanken haben. Eine Maschine reicht aus, um dünne isolierte Kopien für jeden Entwickler zu erstellen.

Ein konkretes Beispiel:
DB – 4,5 Terabyte.
Wir können unabhängige Kopien in 30 Sekunden erhalten.
Sie müssen nicht auf eine Testumgebung warten und von deren Größe abhängig sein. Sie können sie in Sekundenschnelle erhalten. Es werden vollständig isolierte Umgebungen erstellt, die jedoch die Daten untereinander teilen.
Das ist genial. Hier sprechen wir von Magie und parallelen Universen.

In unserem Fall funktioniert das mit dem OpenZFS-System.

OpenZFS ist ein Copy-on-Write-Dateisystem, das von Haus aus Snapshots und Klone unterstützt. Es ist zuverlässig und skalierbar. Die Verwaltung ist extrem einfach. Es kann in nur zwei Befehlen bereitgestellt werden.
Es gibt andere Optionen:
LVM,
Storage-Systeme (z.B. Pure Storage).
Die Database Lab, von der ich spreche, ist modular. Sie kann bei Verwendung solcher Varianten implementiert werden. Bisher haben wir uns jedoch auf OpenZFS konzentriert, da es speziell mit LVM Probleme gab.
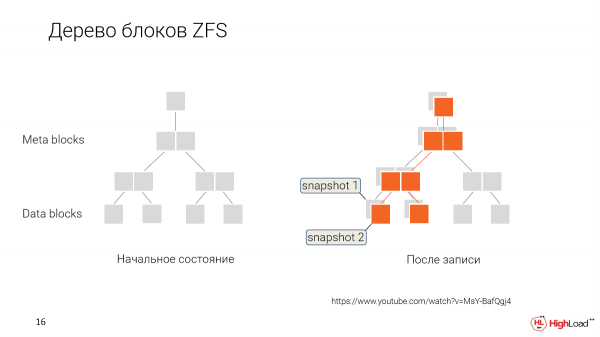
Wie funktioniert das? Anstatt die Daten jedes Mal neu zu schreiben, wenn wir sie ändern, speichern wir sie, indem wir einfach kennzeichnen, dass diese neuen Daten zu einem neuen Zeitpunkt, zu einem neuen Snapshot gehören.
Und später, wenn wir zurückrollen oder einen neuen Klon von einer älteren Version erstellen möchten, sagen wir einfach: „Okay, geben Sie uns diese Datenblöcke, die so gekennzeichnet sind.“
Dieser Benutzer wird mit diesem Datensatz arbeiten. Er wird ihn schrittweise ändern und eigene Snapshots machen.
Und es wird eine Verzweigung geben. Jeder Entwickler hat in unserem Fall die Möglichkeit, seinen eigenen Klon zu haben, den er bearbeitet, während die gemeinsamen Daten zwischen allen geteilt werden.
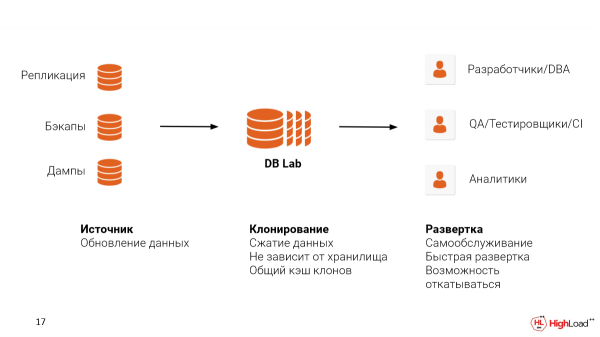
Um ein solches System bei sich zu implementieren, müssen zwei Probleme gelöst werden:
Die erste Quelle ist der Datenort, von dem Sie sie abrufen werden. Sie können eine Replikation mit der Produktionsumgebung einrichten. Sie können auch bereits vorhandene Backups nutzen, hoffe ich. WAL-E, WAL-G oder Barman. Selbst wenn Sie eine Cloud-Lösung wie RDS oder Cloud SQL verwenden, können Sie logische Dumps benutzen. Dennoch empfehlen wir Ihnen, Backups zu verwenden, da Sie auf diese Weise auch die physische Struktur der Dateien beibehalten, was Ihnen erlaubt, näher an den Metriken zu sein, die Sie in der Produktion sehen würden, um die bestehenden Probleme zu identifizieren.
Die zweite Quelle ist der Ort, an dem Sie das Database Lab hosten möchten. Das kann Cloud-basiert sein oder vor Ort. Es ist wichtig zu erwähnen, dass ZFS die Datenkompression unterstützt. Und das macht es ziemlich gut.
Stellen Sie sich vor, dass jeder solcher Klon, abhängig von den Operationen, die wir mit der Datenbank durchführen, einen gewissen Entwicklungsplatz einnehmen wird. Auch für diesen Entwicklungsplatz wird Platz benötigt. Aber da wir eine Datenbank von 4,5 Terabyte genommen haben, wird ZFS sie auf 3,5 Terabyte komprimieren. Je nach den Einstellungen kann dies variieren. Und es bleibt noch Platz für die Entwicklung.
Ein solches System kann für verschiedene Anwendungsfälle genutzt werden.
Das sind Entwickler, DBA zur Überprüfung von Abfragen zur Optimierung.
Dies kann im QA-Testing verwendet werden, um eine bestimmte Migration zu überprüfen, bevor wir sie in die Produktion bringen. Außerdem können wir spezielle Umgebungen für QA mit echten Daten bereitstellen, in denen sie neue Funktionen testen können. Das dauert Sekunden, statt Stunden oder sogar Tage in anderen Fällen, wenn keine dünnen Duplikate verwendet werden.
Und noch ein separater Fall. Wenn im Unternehmen kein Analysesystem eingerichtet ist, können wir ein dünnes Duplikat der Produktdatenbank erstellen und es für langwierige Abfragen oder spezielle Indizes nutzen, die in der Analyse verwendet werden können.

Mit diesem Ansatz:
Geringe Fehlerwahrscheinlichkeit in der Produktion, da wir alle Änderungen mit vollständigen Daten getestet haben.
Wir entwickeln eine Testkultur, da man nun nicht mehr stundenlang auf seine eigene Testumgebung warten muss.
Und es gibt keine Barrieren, kein Warten zwischen den Tests. Man kann wirklich loslegen und überprüfen. Und so wird es besser, da wir die Entwicklung beschleunigen.
Es wird weniger Refactoring geben. Weniger Bugs gelangen in die Produktion. Wir refaktorisieren sie später weniger.
Wir können irreversible Änderungen vornehmen. Das gibt es in den Standardansätzen nicht.
- Das ist vorteilhaft, weil wir die Ressourcen der Teststände teilen.
Das ist schon gut, aber was könnte man noch beschleunigen?

Dank eines solchen Systems können wir die Einstiegshürde für solche Tests erheblich senken.
Derzeit gibt es einen Teufelskreis, in dem der Entwickler, um Zugang zu realen Daten zu erhalten, zum Experten werden muss. Ihm muss dieser Zugang anvertraut werden.
Aber wie soll man wachsen, wenn das nicht der Fall ist? Und was, wenn dir nur ein sehr kleiner Satz an Testdaten zur Verfügung steht? Dann wird es unmöglich sein, echte Erfahrungen zu sammeln.
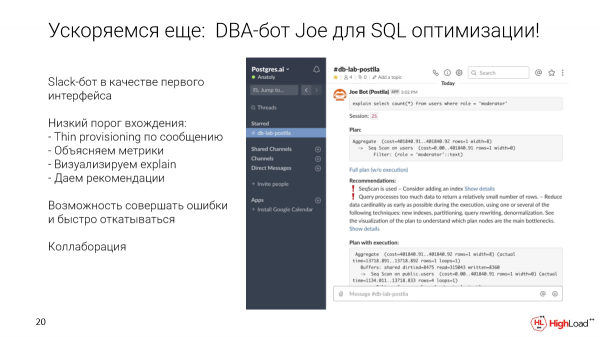
Wie kommt man aus diesem Kreis heraus? Als erste Benutzeroberfläche, die für Entwickler jeder Erfahrungsstufe bequem ist, haben wir einen Slack-Bot gewählt. Aber es könnte jede andere Benutzeroberfläche sein.
Was ermöglicht es? Eine spezifische Anfrage kann genommen und in einen speziellen Kanal für die Datenbank gesendet werden. Wir erstellen automatisch in wenigen Sekunden eine schlanke Kopie. Wir führen diese Anfrage aus. Wir sammeln Metriken und Empfehlungen. Wir zeigen die Visualisierung an. Und diese Kopie bleibt dann, um die Anfrage zu optimieren, Indizes hinzuzufügen usw.
Slack bietet uns ebenfalls Möglichkeiten zur Zusammenarbeit direkt aus der Box. Da es sich einfach um einen Kanal handelt, kann man dort in einem Thread für eine bestimmte Anfrage mit den Kollegen und den DBAs im Unternehmen diskutieren und sie direkt anpingen.

Natürlich gibt es auch Probleme. Da wir im realen Umfeld arbeiten und einen Server verwenden, auf dem viele Klone gleichzeitig gehostet werden, müssen wir die verfügbare Menge an Speicher und CPU-Leistung für die Klone begrenzen.
Um jedoch diese Tests glaubwürdig zu gestalten, müssen wir dieses Problem irgendwie lösen.
Es ist klar, dass identische Daten ein wichtiger Punkt sind. Aber die haben wir bereits. Wir möchten eine einheitliche Konfiguration erreichen. Und wir können eine praktisch identische Konfiguration bereitstellen.
Es wäre großartig, die gleiche Hardware wie in der Produktion zu haben, aber sie kann abweichen.
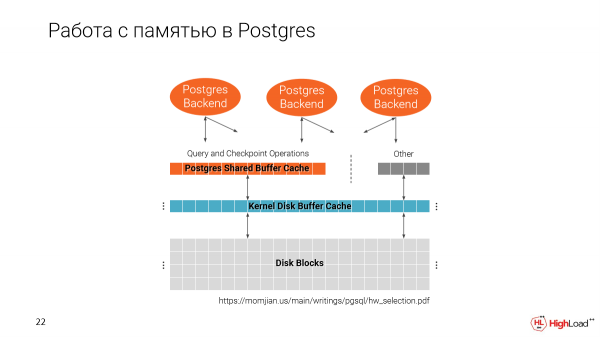
Lassen Sie uns daran erinnern, wie Postgres mit Speicher arbeitet. Wir haben zwei Caches. Einen von der Dateisystem und einen eigenen Postgres, also den Shared Buffer Cache.
Es ist wichtig zu beachten, dass der Shared Buffer Cache beim Start von Postgres entsprechend der Größe, die Sie in der Konfiguration festlegen, zugewiesen wird.
Der zweite Cache nutzt den gesamten verfügbaren Speicher.
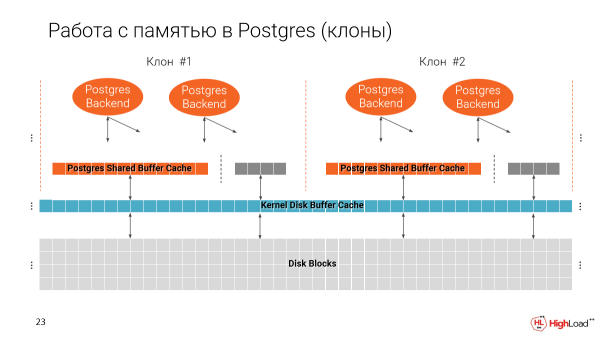
Und wenn wir mehrere Klone auf einer Maschine erstellen, füllen wir allmählich den Speicher. Optimal wären 25 % des gesamten verfügbaren Speichers auf der Maschine für den Shared Buffer Cache.
Das bedeutet, wenn wir diesen Parameter nicht ändern, können wir auf einer Maschine nur 4 Instanzen, das heißt 4 solcher dünnen Klone, starten. Und das ist natürlich schlecht, denn wir möchten viel mehr davon haben.
Andererseits wird der Buffer Cache zur Ausführung von Abfragen, für Indizes verwendet, das heißt der Plan hängt von der Größe unserer Caches ab. Wenn wir einfach diesen Parameter verringern, können sich unsere Pläne erheblich ändern.
Wenn wir zum Beispiel in der Produktion einen großen Cache haben, wird Postgres bevorzugen, den Index zu verwenden. Wenn nicht, wird SeqScan verwendet. Und was wäre der Sinn, wenn unsere Pläne nicht übereinstimmen würden?
Hier kommen wir zu der Erkenntnis, dass der Plan in Postgres nicht von der spezifischen Größe des im Shared Buffer definierten Caches abhängt, sondern von effective_cache_size.

Effective_cache_size ist das geschätzte Cache-Volumen, das uns zur Verfügung steht, d. h. die Summe aus Buffer Cache und dem Cache des Dateisystems. Dies wird über die Konfiguration festgelegt. Dieser Speicher wird jedoch nicht zugewiesen.
Durch diesen Parameter können wir Postgres quasi täuschen, indem wir behaupten, dass uns tatsächlich viele Daten zur Verfügung stehen, auch wenn wir diese Daten nicht haben. Auf diese Weise werden die Pläne vollständig mit der Produktionsumgebung übereinstimmen.
Das kann jedoch die Timing-Werte beeinflussen. Wir optimieren die Anfragen nach Timing, aber wichtig ist, dass das Timing von vielen Faktoren abhängt:
Es hängt von der aktuellen Last in der Produktion ab.
Es hängt von den Eigenschaften der Maschine ab.
Und dies ist ein indirekter Parameter, aber tatsächlich können wir speziell nach der Menge der Daten optimieren, die diese Anfrage lesen wird, um ein Ergebnis zu erzielen.
Wenn wir möchten, dass das Timing dem in der Produktion ähnelt, müssen wir die am besten geeignete Hardware auswählen und möglicherweise sogar mehr, damit alle Klone Platz finden. Das ist jedoch ein Kompromiss, d. h. Sie erhalten die gleichen Pläne, sehen, wie viele Daten eine bestimmte Anfrage liest, und können entscheiden – ob diese Anfrage gut (oder die Migration) oder schlecht ist und noch optimiert werden muss.
Lassen Sie uns konkret untersuchen, wie die Optimierung mit Joe abläuft.
Nehmen wir eine Anfrage aus einem echten System. In diesem Fall beträgt die Datenbankgröße 1 Terabyte. Wir möchten die Anzahl der frischen Beiträge zählen, die mehr als 10 Likes erhalten haben.
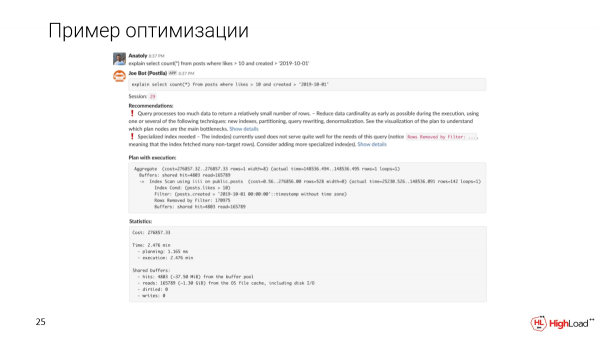
Wir schreiben eine Nachricht in den Kanal, ein Klon wurde für uns hochgefahren. Wir werden sehen, dass eine solche Anfrage in 2,5 Minuten bearbeitet wird. Das ist das erste, was uns auffällt.
Bei Joe werden automatische Empfehlungen basierend auf dem Plan und den Metriken angezeigt.
Wir werden feststellen, dass die Anfrage zu viele Daten verarbeitet, um eine relativ geringe Anzahl von Zeilen zu erhalten. Es wird ein spezieller Index benötigt, da wir festgestellt haben, dass in der Anfrage zu viele gefilterte Zeilen vorhanden sind.
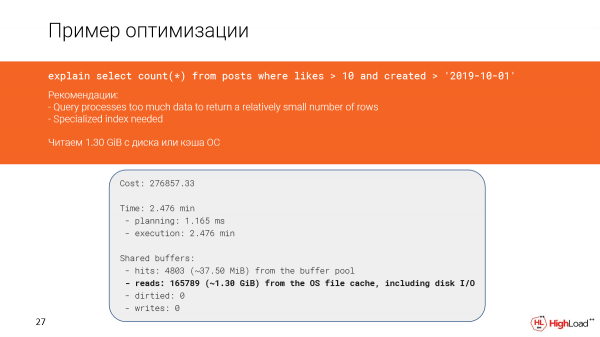
Lassen Sie uns genauer anschauen, was passiert ist. Tatsächlich sehen wir, dass wir fast anderthalb Gigabyte Daten aus dem Dateicache oder sogar von der Festplatte gelesen haben. Das ist nicht ideal, da wir nur 142 Zeilen abgerufen haben.
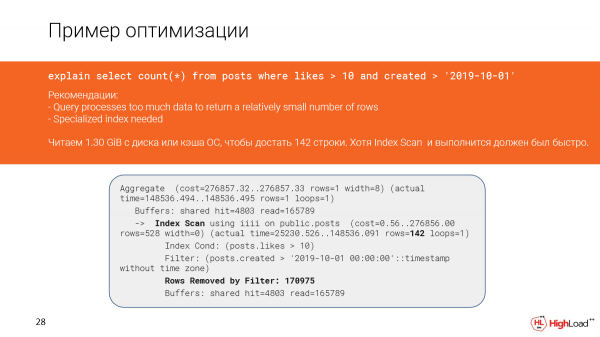
Es schien, als hätten wir hier einen Index-Scan, der schnell sein sollte, aber da wir zu viele Zeilen gefiltert haben (wir mussten sie zählen), hat die Abfrage langsam funktioniert.
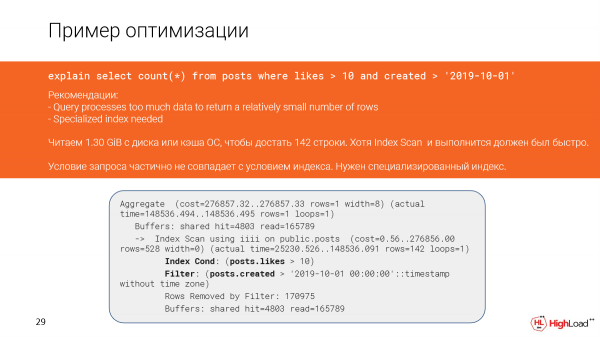
Dies geschah im Plan, weil die Bedingungen in der Abfrage und die Bedingungen im Index teilweise nicht übereinstimmen.
Lassen Sie uns versuchen, den Index präziser zu gestalten und sehen, wie sich die Ausführung der Abfrage danach verändert.
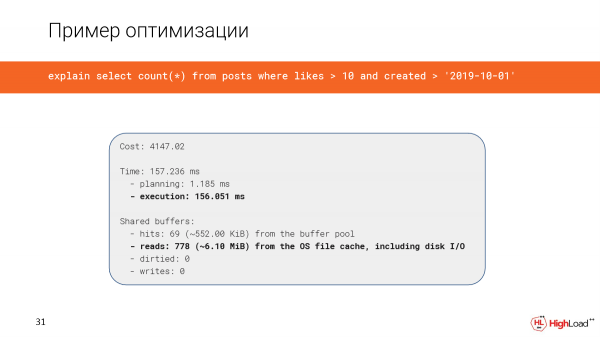
Die Erstellung des Index hat viel Zeit in Anspruch genommen, aber jetzt überprüfen wir die Abfrage und sehen, dass die Zeit anstelle von 2,5 Minuten nur noch 156 Millisekunden beträgt, was recht gut ist. Und wir lesen nur 6 Megabyte Daten.
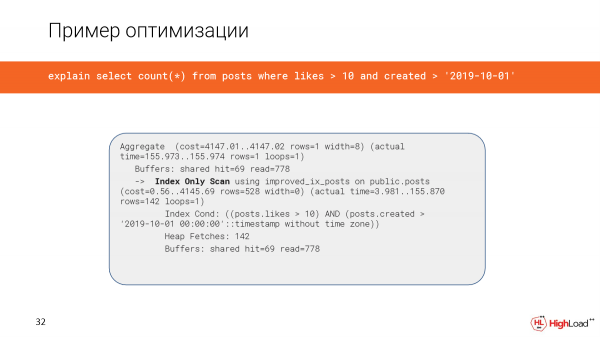
Jetzt verwenden wir einen Index-Only-Scan.
Eine weitere wichtige Geschichte ist, dass wir den Plan in einer verständlicheren Weise präsentieren möchten. Wir haben eine Visualisierung mit Flame Graphs implementiert.
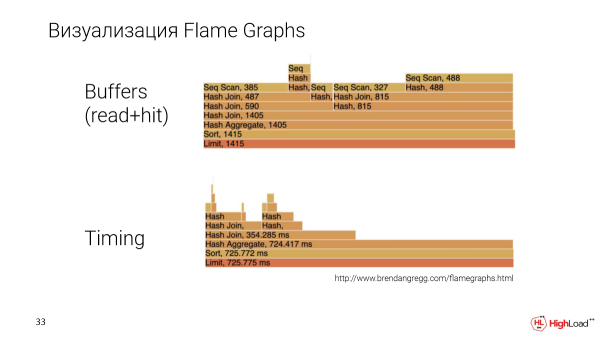
Dies ist eine andere, anspruchsvollere Anfrage. Und Flame Graphs erstellen wir basierend auf zwei Parametern: der Menge an Daten, die ein bestimmter Knoten verarbeitet hat, und dem Timing, d. h. der Ausführungszeit des Knotens.
Hier können wir die spezifischen Knoten miteinander vergleichen. Es wird deutlich, welcher Knoten mehr oder weniger benötigt, was normalerweise schwierig ist mit anderen Visualisierungsmethoden.
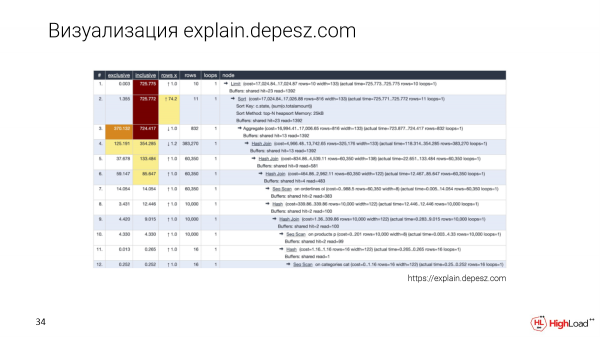
Natürlich kennen alle explain.depesz.com. Ein gutes Merkmal dieser Visualisierung ist, dass wir den Textplan speichern und einige wichtige Parameter in eine Tabelle auslagern, um diese sortieren zu können.
Und auch Entwickler, die sich in dieses Thema noch nicht vertieft haben, nutzen explain.depesz.com, da sie damit leichter verstehen können, welche Metriken wichtig sind und welche nicht.
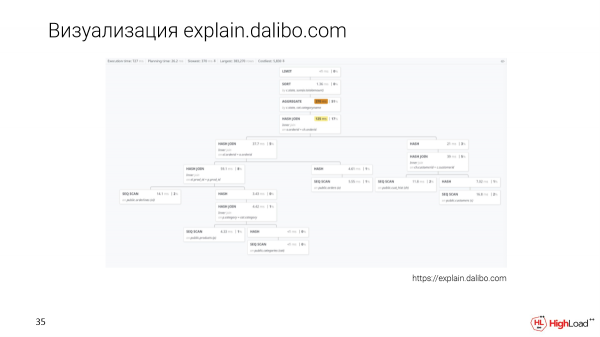
Es gibt einen neuen Ansatz zur Visualisierung – explain.dalibo.com. Sie machen eine baumartige Visualisierung, aber hier ist es sehr schwierig, die Knoten miteinander zu vergleichen. Man kann die Struktur gut erkennen, aber wenn die Anfrage groß ist, muss man hin und her scrollen, was auch eine Option ist.
Kollaboration
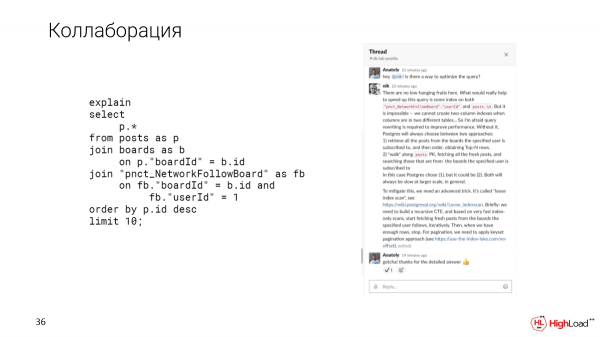
Und wie ich bereits sagte, bietet uns Slack die Möglichkeit zur Zusammenarbeit. Zum Beispiel, wenn wir auf eine komplexe Anfrage stoßen, die unklar ist, wie sie optimiert werden kann, können wir diese Frage im Thread in Slack mit unseren Kollegen klären.

Wir sind der Meinung, dass es wichtig ist, mit vollständigen Daten zu testen. Dazu haben wir das Tool Update Database Lab entwickelt, das als Open Source verfügbar ist. Sie können auch den Bot Joe verwenden. Sie können ihn jetzt gleich mitnehmen und bei sich implementieren. Alle Anleitungen sind dort verfügbar.
Es ist auch wichtig zu erwähnen, dass die Lösung an sich nicht revolutionär ist, denn es gibt Delphix, aber dies ist eine Unternehmenslösung. Sie ist vollständig proprietär und sehr teuer. Wir sind spezialisiert auf Postgres. Das sind alles Open-Source-Produkte. Schließen Sie sich uns an!
Damit beende ich. Vielen Dank!
Fragen
Hallo! Vielen Dank für den Vortrag! Sehr interessant, besonders für mich, weil ich vor einiger Zeit eine ähnliche Aufgabe gelöst habe. Daher habe ich eine ganze Reihe von Fragen. Ich hoffe, ich kann zumindest einige davon stellen.
Wie berechnen Sie den Speicherplatz für diese Umgebung? Die Technologie impliziert, dass unter bestimmten Umständen Ihre Klone auf die maximale Größe anwachsen können. Grob gesagt, wenn Sie eine zehn Terabyte große Datenbank und 10 Klone haben, ist es leicht, sich eine Situation vorzustellen, in der jeder Klon 10 einzigartige Daten beinhaltet. Wie berechnen Sie diesen Speicherplatz, d. h. die Delta, von der Sie gesprochen haben, in der diese Klone leben werden?
Gute Frage. Hier ist es wichtig, die spezifischen Klone im Auge zu behalten. Und wenn irgendeine klonbezogene Änderung zu groß ist und der Klon zu wachsen beginnt, können wir zunächst eine Warnung an den Benutzer ausgeben oder diesen Klon sofort stoppen, um eine Fehlersituation zu vermeiden.
Ja, ich habe eine ergänzende Frage. Wie gewährleisten Sie den Lebenszyklus dieser Module? Das ist bei uns ein Problem und eine ganz eigene Geschichte. Wie funktioniert das?
Jeder Klon hat eine gewisse TTL. Im Grunde haben wir eine feste TTL.
Welche, wenn ich fragen darf?
1 Stunde, d. h. im Leerlauf – 1 Stunde. Wenn es nicht verwendet wird, löschen wir es. Aber hier gibt es keine Überraschung, da wir Klone in wenigen Sekunden hochfahren können. Und wenn wir es erneut benötigen, dann – bitte.
Ich bin auch an der Auswahl der Technologien interessiert, denn wir verwenden beispielsweise aus verschiedenen Gründen parallel mehrere Methoden. Warum gerade ZFS? Warum haben Sie nicht LVM verwendet? Sie erwähnten, dass es Probleme mit LVM gab. Welche Probleme waren das? Meiner Meinung nach ist die Variante mit SAN in Bezug auf die Leistung am optimalsten.
Was ist das Hauptproblem mit ZFS? Dass du es auf einem Host betreiben musst, d. h. alle Instanzen leben innerhalb eines Betriebssystems. Bei SAN kannst du jedoch unterschiedliche Hardware anschließen. Engpässe entstehen nur bei den Blöcken, die am SAN hängen. Und ich finde die Frage der Technologieauswahl interessant. Warum nicht LVM?
Speziell über LVM können wir beim Meetup sprechen. Zu den Speicherlösungen – das ist einfach zu teuer. Das ZFS-System können wir überall implementieren. Sie können es auf Ihrem eigenen Rechner installieren. Sie können einfach das Repository herunterladen und es einrichten. ZFS lässt sich praktisch überall installieren, wenn wir von Linux sprechen. Das heißt, wir erhalten eine sehr flexible Lösung. Und ZFS bietet von Haus aus schon sehr viel. Man kann beliebig viele Daten dort laden, eine große Anzahl von Festplatten anschließen und es gibt Snapshots. Und wie schon erwähnt, es lässt sich einfach verwalten. Das heißt, es scheint sehr benutzerfreundlich zu sein. Es ist erprobt und hat viele Jahre Erfahrung. Es gibt eine sehr große Community, die wächst. ZFS ist eine sehr zuverlässige Lösung.
Nikolai Samokhvalov: Darf ich noch einen Kommentar abgeben? Ich heiße Nikolai und arbeite zusammen mit Anatolij. Ich stimme zu, dass Speicherlösungen großartig sind. Einige unserer Kunden haben Pure Storage usw.
Anatolij hat richtig festgestellt, dass wir auf Modularität setzen. In Zukunft könnte man eine Schnittstelle umsetzen – Snapshot erstellen, Klon erstellen, Klon löschen. Das ist alles ganz einfach. Und Speicherlösungen sind großartig, wenn sie vorhanden sind.
Aber ZFS steht allen zur Verfügung. Genug von DelPhix, die haben 300 Kunden. Davon sind 50 Kunden aus den Fortune 100, also richten sie sich an NASA und Co. Es ist an der Zeit, diese Technologie für alle zugänglich zu machen. Deshalb haben wir einen Open-Source-Kern. Es gibt einen Teil der Benutzeroberfläche, der nicht Open Source ist. Das ist die Plattform, die wir zeigen werden. Aber wir wollen, dass es für jeden zugänglich ist. Wir wollen eine Revolution erzeugen, damit alle Tester aufhören, auf Laptops zu spekulieren. Wir sollten SELECT schreiben und sofort sehen, dass es langsam ist. Genug gewartet, bis der DBA darüber spricht. Das ist das Hauptziel. Und ich glaube, dass wir das erreichen werden. Und dieses Tool machen wir für alle zugänglich. Daher ZFS, weil es überall verfügbar sein wird. Danke an die Community für die Problemlösung und dass es die Open-Source-Lizenz gibt und so weiter.
Hallo! Vielen Dank für den Vortrag! Ich heiße Maxim. Wir haben die gleichen Probleme gelöst. Wir haben sie bei uns gelöst. Wie teilen Sie die Ressourcen zwischen diesen Klonen? Jeder Klon kann zu jedem Zeitpunkt das seine tun: der eine testet das eine, der andere ein anderes, einer baut einen Index auf, ein anderer führt einen schweren Job aus. Und wenn man die CPU noch aufteilen kann, wie machen Sie das mit dem I/O? Das ist die erste Frage.
Und die zweite Frage zu den unterschiedlichen Ständen. Angenommen, ich habe hier ZFS und alles ist großartig, aber der Kunde hat im Produktionsbetrieb nicht ZFS, sondern ext4, zum Beispiel. Wie ist in diesem Fall der Verlauf?
Das sind sehr gute Fragen. Ich habe dieses Problem angesprochen, dass wir die Ressourcen teilen. Die Lösung besteht darin, sich Folgendes vorzustellen: Sie testen auf Staging. Es kann auch gleichzeitig so sein, dass jemand eine bestimmte Last erzeugt und jemand anderes eine andere. Und letztendlich sehen Sie unklare Metriken. Man kann ein ähnliches Problem im Produktionsbetrieb feststellen. Wenn Sie eine Anfrage überprüfen möchten und sehen, dass es ein Problem gibt – sie wird langsam bearbeitet, liegt das Problem nicht an der Anfrage selbst, sondern daran, dass es eine parallele Last gibt.
Darum ist es hier wichtig, sich darauf zu konzentrieren, was der Plan sein wird, welche Schritte wir unternehmen werden und wie viele Daten wir dafür sammeln werden. Dass unsere Festplatten zum Beispiel durch etwas belastet werden, wird sich direkt auf die Timing auswirken. Aber wir können an der Menge der Daten abschätzen, wie belastend diese Anfrage ist. Es ist nicht so wichtig, dass gleichzeitig noch eine andere Ausführung erfolgt.
Ich habe zwei Fragen. Das ist eine wirklich coole Sache. Gab es Fälle, in denen die Daten im Produktionsumfeld kritisch wichtig waren, zum Beispiel Kreditkartennummern? Gibt es bereits etwas Fertiges oder ist das eine eigene Aufgabe? Und die zweite Frage – gibt es so etwas für MySQL?
Zu den Daten. Wir werden Obfuskation durchführen, solange wir das nicht tun. Aber wenn Sie Joe genau bereitstellen und keinen Zugriff für die Entwickler gewähren, dann gibt es keinen Zugriff auf die Daten. Warum? Weil Joe keine Daten anzeigt. Er zeigt nur Metriken, Pläne und alles. Das wurde absichtlich so gemacht, da es eine der Anforderungen unseres Kunden war. Sie wollten die Möglichkeit zur Optimierung haben, aber nicht jedem den Zugriff gewähren.
Zu MySQL. Dieses System kann für alles verwendet werden, was den Zustand auf der Festplatte speichert. Und da wir uns mit Postgres beschäftigen, konzentrieren wir uns zunächst darauf, die gesamte Automatisierung für Postgres vollständig zu implementieren. Wir möchten die Datenwiederherstellung aus Backups automatisieren. Wir konfigurieren Postgres richtig. Wir wissen, wie wir sicherstellen können, dass die Pläne übereinstimmen usw.
Da das System jedoch erweiterbar ist, kann es auch für MySQL genutzt werden. Es gibt ähnliche Beispiele. Eine solche Lösung gibt es bei Yandex, aber sie veröffentlichen sie nirgendwo. Sie nutzen sie intern in Yandex.Metrica. Dort geht es tatsächlich um MySQL. Aber die Technologie ist dieselbe: ZFS.
Danke für den Vortrag! Ich habe auch ein paar Fragen. Sie haben erwähnt, dass Klonen für Analysen verwendet werden kann, um dort zusätzliche Indizes zu erstellen. Können Sie bitte etwas genauer erklären, wie das funktioniert?
Und gleich die zweite Frage zur Gleichheit der Stände und der Pläne. Der Plan hängt auch von den Statistiken ab, die Postgres sammelt. Wie gehen Sie mit diesem Problem um?
Für spezifische Fallanalysen haben wir noch keine Erfahrung, aber die Möglichkeit besteht. Wenn wir von Indizes sprechen, stellen Sie sich vor, dass eine Abfrage über eine Tabelle mit hundert Millionen Datensätzen und über eine Spalte durchgeführt wird, die normalerweise in der Produktion nicht indiziert ist. Und wir möchten einige Daten berechnen. Wenn man diese Abfrage in der Produktion laufen lässt, besteht die Möglichkeit, dass es dort zu Verzögerungen kommt, da die Abfrage dort eine Minute lange benötigt.
Okay, lass uns einen schlanken Klon erstellen, den man für ein paar Minuten problemlos anhalten kann. Um die Analytik komfortabler zu gestalten, fügen wir Indizes für die Spalten hinzu, die uns interessieren.
Wird der Index jedes Mal erstellt?
Es ist möglich, die Daten zu ändern, Snapshots zu erstellen und dann von diesem Snapshot wiederherzustellen, um neue Abfragen durchzuführen. Das heißt, wir können neue Klone mit bereits gesetzten Indizes erstellen.
Was die Statistik betrifft, so wird die Statistik identisch sein, wenn wir aus einem Backup wiederherstellen oder eine Replikation durchführen. Denn wir übertragen die gesamte physische Struktur der Daten, das heißt, die Daten mit allen Statistikmetriken werden ebenfalls mitgebracht.
Hier gibt es ein anderes Problem. Wenn Sie eine Cloud-Lösung verwenden, sind nur logische Dumps verfügbar, da Google und Amazon keine physische Kopie bereitstellen. Das wird ein Problem sein.
Vielen Dank für den Vortrag. Es gab zwei gute Fragen zu MySQL und zur Ressourcenteilung. Im Grunde genommen geht es jedoch darum, dass dies kein spezifisches DBMS-Thema ist, sondern ein allgemeines Thema der Dateisysteme. Entsprechend sollten auch die Fragen zur Ressourcenteilung dort gelöst werden, nicht am Ende mit dem Hinweis, dass es sich um Postgres handelt, sondern im Dateisystem. Server, in instance.
Meine Frage handelt von etwas anderem. Sie ist eher auf die Mehrschichtigkeit von Datenbanken ausgerichtet, in denen sich mehrere Schichten befinden. Beispielsweise haben wir ein Update für ein zehn Terabyte großes Abbild konfiguriert, in dem die Replikation läuft. Wir nutzen diese Lösung speziell für Datenbanken. Die Replikation findet statt; es erfolgt ein Datenupdate. Parallel arbeiten 100 Mitarbeiter, die ständig diese verschiedenen Schnappschüsse ausführen. Was tun? Wie kann man sicherstellen, dass es keine Konflikte gibt, wenn sie etwas auslösen und das Dateisystem dann ersetzt wird, sodass diese Schnappschüsse durcheinander geraten?
Sie werden nicht durcheinandergeraten, denn so funktioniert ZFS. Wir können Änderungen des Dateisystems in einem separaten Thread halten, die durch die Replikation kommen. Und alte Versionen der Daten können Klone halten, die die Entwickler benutzen. Und das funktioniert bei uns, damit ist alles in Ordnung.
Das bedeutet, dass das Update als zusätzliche Schicht erfolgt und alle neuen Snapshots bereits auf dieser Schicht basieren, nicht wahr?
Von den vorherigen Schichten, die aus den vorherigen Replikationen stammen.
Die vorherigen Schichten fallen weg, aber sie werden auf die alte Schicht verweisen, während die neuen Images von der letzten Schicht genommen werden, die im Update erhalten wurde?
Im Allgemeinen, ja.
Dann werden wir folglich viele Schichten haben. Und im Laufe der Zeit müssen sie komprimiert werden?
Ja, genau. Es gibt ein bestimmtes Fenster. Wir speichern wöchentliche Snapshots. Das hängt davon ab, welche Ressourcen Sie haben. Wenn Sie die Möglichkeit haben, viele Daten zu speichern, können Sie Snapshots über einen langen Zeitraum aufbewahren. Sie werden nicht automatisch gelöscht. Es wird keine Datenbeschädigung geben. Wenn die Snapshots veraltet sind, wie wir denken, d.h. es hängt von der Unternehmenspolitik ab, können wir sie einfach löschen und Platz freigeben.
Hallo, vielen Dank für den Bericht! Zum Thema Joe: Sie haben gesagt, dass der Kunde nicht wollte, dass jeder Zugang zu den Daten hat. Streng genommen kann eine Person, die das Ergebnis von Explain Analyze hat, die Daten einsehen.
Das ist richtig. Zum Beispiel könnten wir schreiben: „SELECT FROM WHERE email = jemand“. Das heißt, wir sehen die Daten selbst nicht, aber wir können einige indirekte Hinweise betrachten. Das muss man verstehen. Auf der anderen Seite ist alles sichtbar. Wir haben ein Log-Audit, wir haben die Kontrolle anderer Kollegen, die auch sehen, was die Entwickler tun. Und wenn jemand versucht, so zu handeln, wird die Sicherheitsabteilung zu ihnen kommen und dieses Thema behandeln.
Guten Tag! Vielen Dank für den Vortrag! Ich habe eine kurze Frage. Wenn Slack im Unternehmen nicht verwendet wird, gibt es dann aktuell eine Verbindung dazu oder können die Entwickler Instanzen bereitstellen, um eine Testanwendung mit den Datenbanken zu verbinden?
Derzeit gibt es eine Verbindung zu Slack, das heißt, es gibt keinen anderen Messenger, aber wir möchten sehr gerne Unterstützung für andere Messenger einführen. Was können Sie tun? Sie können DB Lab ohne Joe bei sich bereitstellen, mit dem REST API oder unserer Plattform arbeiten, Klone erstellen und sich über PSQL verbinden. Aber das ist möglich, wenn Sie bereit sind, Ihren Entwicklern Zugang zu den Daten zu geben, denn dann gibt es keine Trennung mehr.
Diese Zwischenschicht benötige ich nicht, ich brauche diese Möglichkeit.
Dann – ja, das lässt sich umsetzen.
Quelle: habr.com
