

Auswertung des Vortrags von Alexey Lesovsky aus dem Jahr 2015 "Eintauchen in die internen Statistiken von PostgreSQL"
Haftungsausschluss des Autors des Vortrags: Ich möchte darauf hinweisen, dass dieser Vortrag aus November 2015 stammt – seitdem sind mehr als 4 Jahre vergangen und vieles hat sich verändert. Die im Vortrag behandelte Version 9.4 wird nicht mehr unterstützt. In den letzten 4 Jahren wurden 5 neue Versionen veröffentlicht, in denen viele Neuerungen, Verbesserungen und Änderungen in Bezug auf die Statistiken eingeführt wurden, weshalb ein Teil des Materials veraltet und nicht mehr aktuell ist. Während des Reviews habe ich versucht, diese Stellen zu kennzeichnen, um dich, lieber Leser, nicht in die Irre zu führen. Ich habe jedoch beschlossen, diese Abschnitte nicht umzuschreiben, da es zu viele davon gibt und das Ergebnis einen völlig anderen Vortrag darstellen würde.
Das Datenbanksystem PostgreSQL ist ein komplexes Mechanismus, der aus zahlreichen Teilsystemen besteht, deren reibungsloses Zusammenspiel direkt die Leistung der Datenbank beeinflusst. Während des Betriebs werden Statistiken und Informationen über die Funktionsweise der Komponenten gesammelt, was es ermöglicht, die Effizienz von PostgreSQL zu bewerten und Maßnahmen zur Leistungssteigerung zu ergreifen. Diese Informationen sind jedoch umfangreich und werden in einem recht vereinfachten Format dargestellt. Die Verarbeitung und Interpretation dieser Daten kann manchmal eine nicht triviale Aufgabe sein, und die Vielzahl an Werkzeugen und Utilities kann selbst erfahrene DBAs vor Herausforderungen stellen.


Guten Tag! Mein Name ist Alexey. Wie Ilja gesagt hat, werde ich über die Statistiken von PostgreSQL berichten.

Aktivitätsstatistiken von PostgreSQL. PostgreSQL verfügt über zwei Arten von Statistiken. Die Aktivitätsstatistik, über die ich sprechen werde, und die Statistiken des Planers zur Datenverteilung. Ich werde speziell über die Aktivitätsstatistik von PostgreSQL sprechen, die es uns ermöglicht, Rückschlüsse auf die Leistung zu ziehen und diese gegebenenfalls zu verbessern.
Ich werde Ihnen zeigen, wie Sie Statistiken effektiv nutzen können, um verschiedene Probleme zu lösen, die bei Ihnen auftreten oder auftreten könnten.

Was wird nicht im Vortrag behandelt? Der Vortrag wird sich nicht mit der Statistik des Planers befassen, da dies ein separates Thema für einen eigenen Vortrag ist, in dem es darum geht, wie Daten in einer Datenbank gespeichert werden und wie der Abfrageplaner qualitäts- und quantitativ relevante Informationen über diese Daten erhält.
Es wird keine Übersicht über Werkzeuge geben, ich werde kein Produkt mit einem anderen vergleichen. Es wird keine Werbung geben. Lassen Sie uns das beiseitelegen.

Ich möchte Ihnen zeigen, dass die Nutzung von Statistiken nützlich ist. Es ist wichtig. Es ist nicht beängstigend, sie zu verwenden. Wir benötigen lediglich normales SQL und grundlegende SQL-Kenntnisse.
Wir werden auch darüber sprechen, welche Statistiken für die Problemlösung ausgewählt werden sollten.

Wenn wir PostgreSQL betrachten und in der Betriebssystemumgebung den Befehl zur Anzeige der Prozesse ausführen, sehen wir eine "schwarze Box". Wir sehen einige Prozesse, die irgendwo aktiv sind, und anhand der Namen können wir uns ungefähr vorstellen, was sie tun. Aber im Grunde ist es eine schwarze Box, in die wir nicht hineinschauen können.
Wir können die CPU-Auslastung in top, und die Speicherauslastung mit bestimmten Systemtools überprüfen, aber einen Blick in PostgreSQL können wir nicht werfen. Dafür benötigen wir andere Werkzeuge.
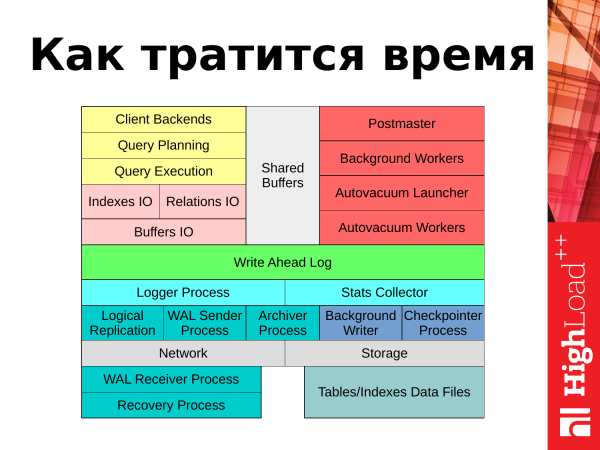
Um fortzufahren, erkläre ich, wo die Zeit investiert wird. Wenn wir PostgreSQL als ein Diagramm betrachten, können wir die Ursprünge der Zeitverwendung identifizieren. Es handelt sich um zwei Aspekte: die Verarbeitung von Clientanfragen durch Anwendungen und die Hintergrundaufgaben, die PostgreSQL zur Aufrechterhaltung seiner Funktionalität erledigt.
Wenn wir von der oberen linken Ecke aus beginnen, können wir nachvollziehen, wie die Kundenanfragen verarbeitet werden. Die Anfrage stammt von einer Anwendung und eröffnet eine Kunden-Sitzung für die weitere Verarbeitung. Die Anfrage wird an den Scheduler weitergegeben. Der Scheduler erstellt einen Ausführungsplan für die Anfrage und leitet ihn zur Ausführung weiter. Dabei kommt es zu einem blockweisen Ein- und Ausgabeprozess, der mit Tabellen und Indizes verbunden ist. Die benötigten Daten werden von den Festplatten in den Speicher in einen speziellen Bereich namens "shared buffers" gelesen. Die Ergebnisse der Anfrage, falls es sich um Updates oder Deletes handelt, werden im Transaktionsjournal im WAL protokolliert. Einige statistische Informationen werden in ein Log oder an einen Statistik-Collector gesendet. Schließlich wird das Ergebnis der Anfrage an den Kunden zurückgegeben, der danach den gesamten Vorgang mit einer neuen Anfrage wiederholen kann.
Wie steht es um unsere Hintergrundaufgaben und -prozesse? Wir haben mehrere Prozesse, die die Funktionsfähigkeit sicherstellen und die Datenbank im normalen Betrieb aufrechterhalten. Diese Prozesse werden ebenfalls im Bericht behandelt: autovacuum, checkpointer, Prozesse, die mit der Replikation verbunden sind, und der background writer. Jeden dieser Prozesse werde ich im Verlauf des Vortrags ansprechen.

Welche Probleme gibt es mit der Statistik?
- Es gibt viele Informationen. PostgreSQL 9.4 bietet 109 Metriken zur Anzeige von Statistikinformationen. Wenn jedoch viele Tabellen, Schemata oder Datenbanken in der Datenbank gespeichert sind, muss jede dieser Metriken mit der entsprechenden Anzahl an Tabellen oder Datenbanken multipliziert werden. Das bedeutet, die Informationen nehmen noch weiter zu. Und es ist sehr einfach, darin zu ertrinken.
- Ein weiteres Problem ist, dass die Statistik in Form von Zählern dargestellt wird. Wenn wir diese Statistik betrachten, sehen wir ständig steigendende Zähler. Und wenn seit dem Zurücksetzen der Statistik viel Zeit vergangen ist, sehen wir Werte in Milliardenhöhe. Diese sagen uns jedoch nichts aus.
- Es gibt keine Historie. Wenn Sie einen Ausfall hatten, der vor 15-30 Minuten aufgetreten ist, können Sie die Statistik nicht nutzen, um zu sehen, was in den letzten 15-30 Minuten passiert ist. Das ist ein Problem.
- Das Fehlen eines in PostgreSQL integrierten Tools stellt ein Problem dar. Die Kernel-Entwickler bieten keine Utility an. Sie haben nichts in dieser Richtung. Sie stellen lediglich die Statistik in der Datenbank zur Verfügung. Nutzen Sie sie, stellen Sie Ihre Anfragen – tun Sie, was Sie wollen.
- Da es kein eingebautes Tool in PostgreSQL gibt, führt das zu einem anderen Problem. Eine Vielzahl von Drittanbieter-Tools ist verfügbar. Jedes Unternehmen mit wenigen technischen Fertigkeiten versucht, sein eigenes Programm zu entwickeln. In der Community gibt es letztlich eine Fülle von Tools, die für die Arbeit mit Statistiken genutzt werden können. Einige Tools bieten bestimmte Funktionen, während andere diese nicht haben oder verschiedene neue Funktionen anbieten. Daraus ergibt sich die Situation, dass man zwei, drei oder vier Tools nutzen muss, die sich überschneiden und unterschiedliche Funktionen besitzen. Das ist sehr unangenehm.

Was folgt daraus? Es ist wichtig, Statistiken direkt abzufragen, um nicht von Programmen abhängig zu sein oder diese selbst zu verbessern: zum Beispiel bestimmte Funktionen hinzuzufügen, um einen eigenen Vorteil zu erhalten.
Und man benötigt grundlegende SQL-Kenntnisse. Um Daten aus Statistiken zu extrahieren, müssen SQL-Abfragen formuliert werden; das bedeutet, dass man wissen muss, wie man Select- und Join-Abfragen erstellt.

Statistiken bieten uns mehrere Dinge. Diese können in Kategorien unterteilt werden.
- Die erste Kategorie umfasst Ereignisse, die in der Datenbank stattfinden. Das sind Ereignisse wie Anfragen, Zugriffe auf Tabellen, Autovacuum, Commits – all diese zählen zu den Ereignissen. Die entsprechenden Zähler werden erhöht, und wir können diese Ereignisse nachverfolgen.
- Die zweite Kategorie bezieht sich auf die Eigenschaften von Objekten, wie Tabellen und Datenbanken. Diese haben spezifische Eigenschaften, wie die Größe der Tabellen. Wir können das Wachstum der Tabellen und Indizes verfolgen und die Veränderungen in der Dynamik beobachten.
- Die dritte Kategorie ist die Zeit, die für ein Ereignis aufgewendet wird. Eine Abfrage ist ein solches Ereignis und hat eine bestimmte Dauer. Hier startet sie und dort endet sie. Das können wir nachvollziehen, ebenso wie die Zeit für das Lesen oder Schreiben von Blöcken von der Festplatte. Solche Dinge werden ebenfalls überwacht.

Die Statistiken stammen aus verschiedenen Quellen:
- Im Shared Memory (gemeinsamem Speicher) gibt es ein Segment zur Unterbringung dieser statischen Daten. Dort befinden sich auch die Zähler, die kontinuierlich inkrementiert werden, wenn verschiedene Ereignisse eintreten oder bestimmte Vorgänge in der Datenbank stattfinden.
- All diese Zähler sind für den Benutzer und sogar für den Administrator nicht zugänglich. Es handelt sich um Low-Level-Elemente. Um auf sie zuzugreifen, stellt PostgreSQL eine Schnittstelle in Form von SQL-Funktionen zur Verfügung. Mit diesen Funktionen können wir Auswahlen (SELECTs) treffen und eine bestimmte Metrik (oder eine Gruppe von Metriken) erhalten.
- Die Verwendung dieser Funktionen ist jedoch nicht immer praktisch, weshalb diese Funktionen die Basis für Ansichten (VIEWs) bilden. Dies sind virtuelle Tabellen, die Statistiken zu einem bestimmten Teilsystem oder einer bestimmten Sammlung von Ereignissen in der Datenbank bereitstellen.
- Diese eingebauten Ansichten (VIEWs) sind die Hauptschnittstelle für den Benutzer zur Arbeit mit Statistiken. Sie sind standardmäßig verfügbar, ohne dass zusätzliche Einstellungen erforderlich sind. Sie können sie sofort nutzen, um Informationen zu sehen und abzurufen. Es gibt auch contrib-Module. Diese sind offiziell. Sie können das Paket postgresql-contrib installieren (z.B. postgresql94-contrib), das erforderliche Modul in der Konfiguration laden, seine Parameter angeben, PostgreSQL neu starten und es verwenden. (Hinweis: Je nach Distribution ist das contrib-Paket in den neuesten Versionen Teil des Hauptpakets.).
- Es gibt auch inoffizielle Contribs, die nicht in der Standardinstallation von PostgreSQL enthalten sind. Diese müssen entweder kompiliert oder als Bibliothek installiert werden. Die Optionen können sehr unterschiedlich sein, abhängig davon, was der Entwickler dieses inoffiziellen Contribs sich überlegt hat.

Diese Folie zeigt alle Ansichten (VIEWs) und einige der Funktionen, die in PostgreSQL 9.4 verfügbar sind. Wie wir sehen, gibt es viele davon. Es kann ziemlich verwirrend werden, wenn man damit zum ersten Mal konfrontiert wird.
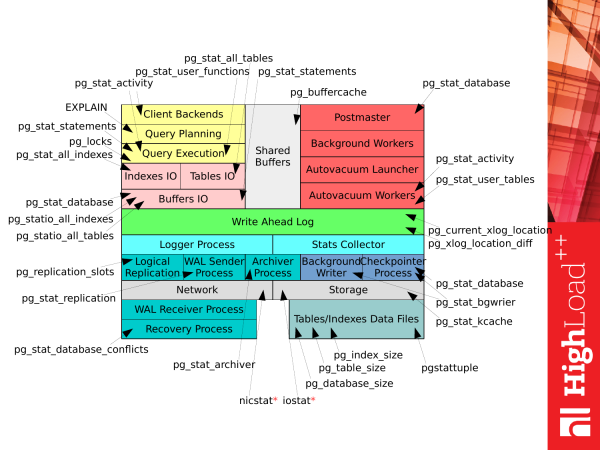
Wenn wir jedoch das vorherige Bild betrachten Wie die Zeit in PostgreSQL genutzt wird und dies mit dieser Liste abgleichen, erhalten wir ein solches Bild. Jede Ansicht (VIEW) oder jede Funktion können wir zu verschiedenen Zwecken verwenden, um entsprechende Statistiken zu erhalten, während PostgreSQL läuft. So können wir bereits einige Informationen über die Funktionsweise des Subsystems gewinnen.
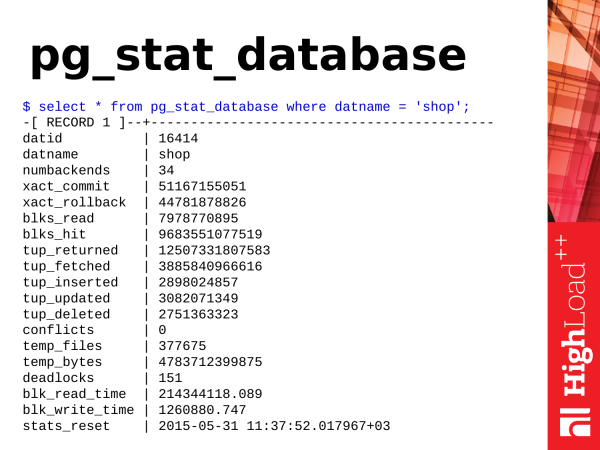
Das erste, was wir betrachten werden, ist pg_stat_database. Wie wir sehen, handelt es sich um eine Ansicht. Sie enthält eine Menge Informationen, die sehr vielfältig sind. Und sie bietet äußerst nützliches Wissen darüber, was in unserer Datenbank passiert.
Was können wir dort Nützliches entnehmen? Lassen Sie uns mit den einfachsten Dingen beginnen.

select
sum(blks_hit)*100/sum(blks_hit+blks_read) as hit_ratio
from pg_stat_database;Eine wichtige Kennzahl, die wir analysieren können, ist der Cache-Hit-Prozentsatz. Der Cache-Hit-Prozentsatz ist eine nützliche Metrik. Sie hilft dabei zu bewerten, wie viel Daten aus dem Cache der Shared Buffers gezogen wird und wie viel von der Festplatte gelesen wird.
Es ist klar, dass je höher unser Cache-Hit-Anteil ist, desto besser. Wir bewerten diese Metrik als Prozentsatz. Beispielsweise ist es positiv, wenn unser Cache-Hit-Anteil über 90 % liegt. Wenn er unter 90 % fällt, bedeutet das, dass der Speicher nicht ausreicht, um die heißen Daten im Speicher zu halten. Um auf diese Daten zuzugreifen, muss PostgreSQL auf die Festplatte zugreifen, was langsamer ist, als wenn die Daten im Speicher gelesen werden. In diesem Fall sollten wir über eine Erhöhung des Speichers nachdenken: entweder die Shared Buffers vergrößern oder den Arbeitsspeicher (RAM) erweitern.
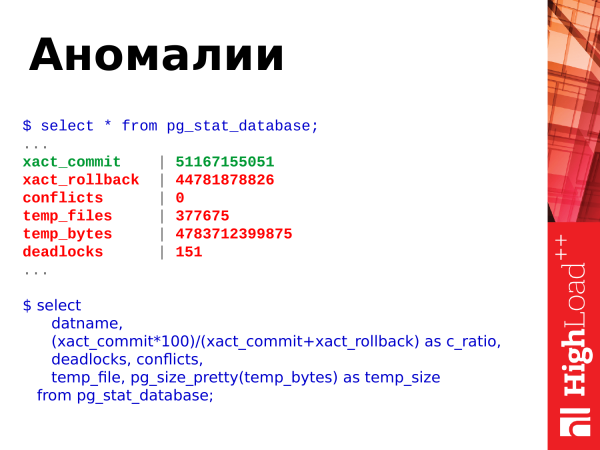
select
datname,
(xact_commit*100)/(xact_commit+xact_rollback) as c_ratio,
deadlocks, conflicts,
temp_file, pg_size_pretty(temp_bytes) as temp_size
from pg_stat_database;Was können wir noch aus dieser Ansicht entnehmen? Wir können die Anomalien in der Datenbank betrachten. Was wird hier angezeigt? Es gibt Commits, Rollbacks, die Erstellung temporärer Dateien, deren Größe, Deadlocks und Konflikte.
Wir können diese Anfrage nutzen. Diese SQL-Abfrage ist ziemlich einfach. Und wir können uns diese Daten ansehen.
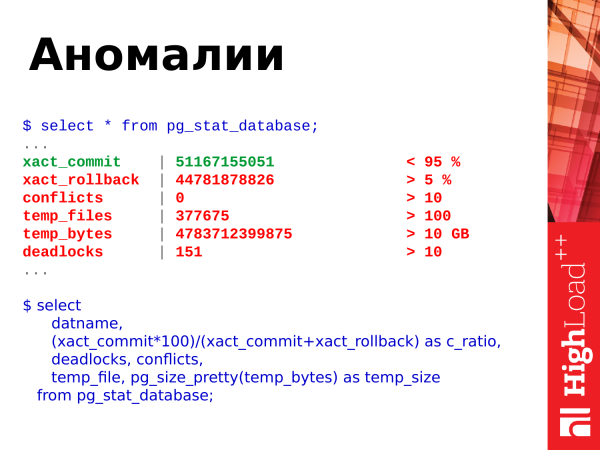
Hier sind sofort die Grenzwerte. Wir betrachten das Verhältnis von Commits zu Rollbacks. Commits sind erfolgreiche Bestätigungen von Transaktionen. Rollbacks sind Rücksetzungen, d. h. die Transaktion hat eine bestimmte Arbeit verrichtet, die Datenbank beansprucht, etwas berechnet, und dann gab es einen Fehler, wodurch die Ergebnisse der Transaktion verworfen werden. Eine stetig steigende Anzahl von Rollbacks ist schlecht. Wir sollten versuchen, sie zu vermeiden und den Code anzupassen, um solch Situationen zu verhindern.
Konflikte (conflicts) sind mit der Replikation verbunden und sollten ebenfalls vermieden werden. Wenn Sie Anfragen haben, die auf der Replik ausgeführt werden und Konflikte auftreten, müssen diese Konflikte analysiert werden. Schauen Sie, was passiert. Details finden Sie in den Logs. Beheben Sie Konfliktsituationen, damit die Anfragen der Anwendung fehlerfrei arbeiten.
Deadlocks – das ist auch eine ungünstige Situation. Wenn Anfragen um Ressourcen kämpfen, kann eine Anfrage eine Sperre für eine Ressource übernehmen, während eine zweite Anfrage eine Sperre für eine andere Ressource übernimmt, und dann beide Anfragen auf die Ressourcen des jeweils anderen zugreifen und auf die Freigabe der Sperre warten. Auch das ist problematisch. Diese Situationen müssen durch das Neuschreiben von Anwendungen und die Serialisierung des Zugriffs auf Ressourcen gelöst werden. Wenn Sie feststellen, dass Ihre Deadlocks ständig zunehmen, sollten Sie die Details in den Logs überprüfen, die aufgetretenen Situationen analysieren und herausfinden, wo das Problem liegt.
Temp files (temporäre Dateien) – das ist ebenfalls ungünstig. Wenn einer Benutzeranfrage der Speicher für die Unterbringung temporärer Daten im Arbeitsspeicher fehlt, wird eine Datei auf der Festplatte erstellt. Alle Operationen, die im temporären Speicher erfolgen könnten, müssen dann auf der Festplatte ausgeführt werden. Das ist langsam. Das erhöht die Ausführungszeit der Anfrage. Und der Kunde, der die Anfrage an PostgreSQL gesendet hat, erhält die Antwort etwas später. Wenn alle diese Operationen im Speicher stattfinden, antwortet Postgres viel schneller und der Kunde muss weniger warten.
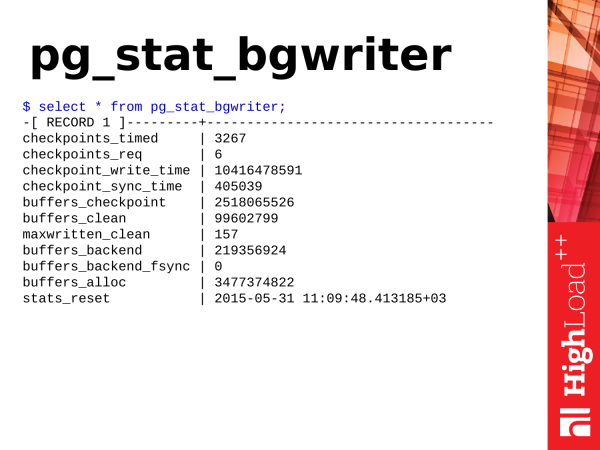
Pg_stat_bgwriter – diese Ansicht beschreibt die Arbeit von zwei Hintergrundsystemen in PostgreSQL: dies ist der Checkpointer und der Hintergrundschreiber.

Zunächst betrachten wir die sogenannten Kontrollpunkte, Checkpoints. Was sind Checkpoints? Ein Checkpoint ist eine Position im Transaktionsprotokoll, die besagt, dass alle im Protokoll festgehaltenen Datenänderungen erfolgreich mit den Daten auf der Festplatte synchronisiert wurden. Je nach Arbeitslast und Einstellungen kann der Prozess zeitaufwendig sein und besteht hauptsächlich darin, schmutzige Seiten im gemeinsamen Puffer mit Datendateien auf der Festplatte zu synchronisieren. Warum ist das notwendig? Wenn PostgreSQL ständig auf die Festplatte zugreifen und Daten bei jedem Zugriff lesen und schreiben würde, wäre das sehr langsam. Daher hat PostgreSQL einen bestimmten Speicherbereich, dessen Größe von den Konfigurationsparametern abhängt. Postgres speichert in diesem Speicher operative Daten für eine spätere Verarbeitung oder Ausgabe auf Anfragen. Bei Änderungen an den Daten geschieht eine Modifikation. Dadurch haben wir zwei Versionen der Daten: eine im Speicher und eine auf der Festplatte. Diese Daten müssen regelmäßig synchronisiert werden. Die in Speicheränderungen müssen auf die Festplatte übertragen werden. Dafür sind Checkpoints erforderlich.
Checkpoint durchläuft die gemeinsamen Buffers, markiert die schmutzigen Seiten, die für den Checkpoint benötigt werden. Danach startet er einen zweiten Durchlauf durch die gemeinsamen Buffers. Die Seiten, die für den Checkpoint markiert sind, werden dann synchronisiert. Auf diese Weise erfolgt die Datensynchronisation mit der Festplatte.
Es gibt zwei Arten von Kontrollpunkten. Ein Checkpoint wird nach Zeitintervall ausgeführt. Dieser Checkpoint ist nützlich und gut – checkpoint_timed. Und es gibt Checkpoints auf Anfrage – checkpoint required. Ein solcher Kontrollpunkt tritt auf, wenn wir eine sehr große Datenmenge schreiben. Wir haben eine Menge Transaktionsprotokolle gespeichert. Und PostgreSQL denkt, dass es alles so schnell wie möglich synchronisieren muss, einen Kontrollpunkt erstellen und weitermachen kann.
Und wenn Sie die Statistik pg_stat_bgwriter angeschaut haben und gesehen haben, dass Sie checkpoint_req deutlich mehr als checkpoint_timed haben, ist das schlecht. Warum ist das schlecht? Das bedeutet, dass sich PostgreSQL in einer ständigen Stresssituation befindet, in der es Daten auf die Festplatte schreiben muss. Ein Checkpoint mit einer kürzeren Timeout-Dauer ist weniger belastend und erfolgt gemäß einem internen Zeitplan, sodass er zeitlich gestreckt wird. PostgreSQL bietet die Möglichkeit, Arbeitspausen einzulegen, wodurch das Speichersystem nicht überlastet wird. Dies ist für PostgreSQL vorteilhaft. Anfragen, die während des Checkpoints ausgeführt werden, sind nicht von der Belastung betroffen, die durch ein ausgelastetes Speichersystem entsteht.
Für die Anpassung von Checkpoints gibt es drei Parameter:
checkpoint_segments.checkpoint_timeout.checkpoint_completion_target.
Diese Parameter ermöglichen die Regelung der Arbeit der Checkpoints. Ich möchte jedoch nicht länger auf sie eingehen. Ihr Einfluss ist ein separates Thema.
Achtung: Die in diesem Bericht behandelte Version 9.4 ist bereits veraltet. In den aktuellen Versionen von PostgreSQL wurde der Parameter checkpoint_segments durch die Parameter min_wal_size und max_wal_size.

Die nächste Subsystem ist der Hintergrundschreiber — der Hintergrundschreiber. Was macht er? Er arbeitet kontinuierlich in einer Endlosschleife. Er scannt die Seiten im Shared Buffer und schreibt die dreckigen Seiten, die er findet, auf die Festplatte. So hilft er dem Checkpointer, weniger Arbeit während der Ausführung der Checkpoints zu leisten.
Wofür wird es noch benötigt? Es stellt den Bedarf an freien Seiten in den Shared Buffers sicher, falls diese plötzlich (in großer Menge und gleichzeitig) für die Datenablage benötigt werden. Nehmen wir an, es tritt eine Situation auf, in der für die Ausführung einer Anfrage freie Seiten benötigt werden und sie bereits in den Shared Buffers vorhanden sind. PostgreSQL backend nimmt sie einfach und verwendet sie, ohne selbst etwas säubern zu müssen. Wenn jedoch keine freien Seiten vorhanden sind, stoppt das Backend die Arbeit und beginnt mit der Suche nach Seiten, um sie auf die Festplatte zu schreiben und für seine Bedürfnisse zu verwenden – was sich negativ auf die Zeit der gerade ausgeführten Anfrage auswirkt. Wenn Sie sehen, dass Ihr Parameter maxwritten_clean hoch ist, bedeutet dies, dass der Background Writer seine Arbeit nicht bewältigt, und die Parameter müssen erhöht werden bgwriter_lru_maxpages, damit er in einem Zyklus mehr Arbeit verrichten und mehr Seiten säubern kann.
Ein weiterer sehr nützlicher Indikator ist buffers_backend_fsync. Backends führen kein fsync durch, weil das langsam ist. Sie übertragen fsync an den Checkpointer weiter oben im IO-Stack. Der Checkpointer hat seine eigene Warteschlange, und er verarbeitet fsync regelmäßig und synchronisiert die Seiten im Speicher mit den Dateien auf der Festplatte. Wenn die Warteschlange beim Checkpointer groß und voll ist, muss der Backend selbst ein fsync durchführen, was die Leistung des Backends verlangsamt., d. h. der Kunde erhält eine Antwort später, als er könnte. Wenn Sie sehen, dass dieser Wert größer als Null ist, ist das bereits ein Problem und Sie sollten die Einstellungen des Background Writers überprüfen und auch die Leistung des Speichersystems bewerten.
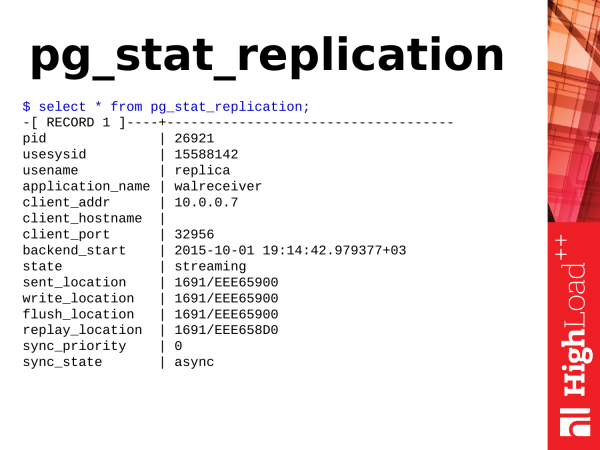
Achtung: _Der folgende Text beschreibt statistische Ansichten, die mit der Replikation verbunden sind. Die meisten Namen von Ansichten und Funktionen wurden in Postgres 10 umbenannt. Der Zweck der Umbenennungen bestand darin, xlog findet man wal und location findet man lsn in den Namen von Funktionen/Ausgaben usw. Ein spezifisches Beispiel ist die Funktion pg_xlog_location_diff() die in pg_wal_lsn_diff()._
umbenannt wurde. Hier haben wir auch viel. Aber wir benötigen nur die Punkte, die mit der Location verbunden sind.
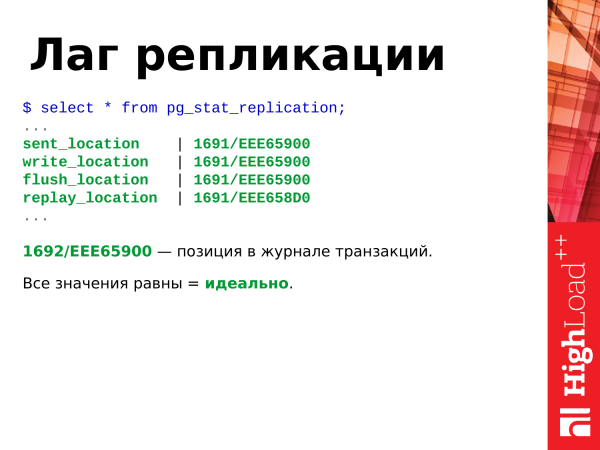
Wenn wir sehen, dass alle Werte gleich sind, ist das ideal, und die Replikation hinkt nicht hinter dem Master hinterher.
Diese hexadezimale Position ist die Position im Transaktionsprotokoll. Sie erhöht sich ständig, wenn in der Datenbank Aktivitäten stattfinden: Inserts, Deletes usw.
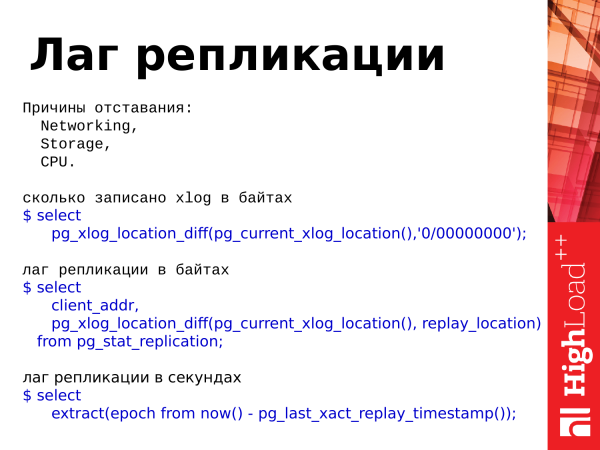
wie viel xlog in Bytes geschrieben wurde
$ select
pg_xlog_location_diff(pg_current_xlog_location(),'0/00000000');
Replikationsverzögerung in Bytes
$ select
client_addr,
pg_xlog_location_diff(pg_current_xlog_location(), replay_location)
from pg_stat_replication;
Replikationsverzögerung in Sekunden
$ select
extract(epoch from now() - pg_last_xact_replay_timestamp());Wenn diese Werte unterschiedlich sind, gibt es eine Verzögerung. Eine Verzögerung bezieht sich darauf, dass der Replikat hinter dem Master zurückbleibt, das heißt, die Daten stimmen zwischen den Servern nicht überein.
Es gibt drei Gründe für eine Verzögerung:
- Das Speicher-Subsystem kann die Synchronisierung der Dateien nicht bewältigen.
- Es können Netzwerkfehler oder Netzwerküberlastungen vorliegen, wodurch die Daten nicht rechtzeitig zum Replikat gelangen und es nicht in der Lage ist, sie wiederzugeben.
- Und der Prozessor. Der Prozessor ist ein sehr seltener Fall. Ich habe so etwas vielleicht zwei oder drei Mal gesehen, aber das kann auch vorkommen.
Und hier sind drei Abfragen, die uns helfen, die Statistiken zu nutzen. Wir können einschätzen, wie viel in unserem Transaktionsprotokoll geschrieben wurde. Es gibt eine Funktion pg_xlog_location_diff mit der wir die Replikationsverzögerung in Bytes und Sekunden bewerten können. Außerdem verwenden wir für dies den Wert aus dieser Ansicht (VIEWs).
Hinweis: _Anstelle der pg_xlog_locationdiff() Funktion kann man auch den Subtraktionsoperator verwenden und einen Standort von einem anderen abziehen. Praktisch.
Es gibt einen Punkt bezüglich des Lags in Sekunden. Wenn auf dem Master keine Aktivität stattfindet, die Transaktion etwa 15 Minuten zurückliegt und es keine Aktivität gibt, werden wir beim Blick auf den Lag auf der Replik einen Lag von 15 Minuten sehen. Das sollte man im Hinterkopf behalten. Es kann verwirrend sein, wenn man diesen Lag betrachtet.
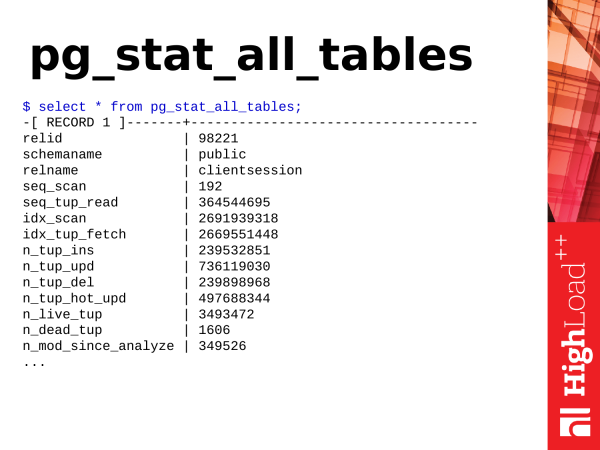
Pg_stat_all_tables ist eine weiteres nützliches Ansicht. Es zeigt Statistiken zu den Tabellen an. Wenn wir Tabellen in der Datenbank haben, bei denen es eine gewisse Aktivität, einige Aktionen gibt, können wir diese Informationen aus dieser Ansicht erhalten.

select
relname,
pg_size_pretty(pg_relation_size(relname::regclass)) as size,
seq_scan, seq_tup_read,
seq_scan / seq_tup_read as seq_tup_avg
from pg_stat_user_tables
where seq_tup_read > 0 order by 3,4 desc limit 5;Das erste, was wir betrachten können, sind die sequenziellen Scans der Tabelle. Die Zahl nach diesen Durchläufen ist noch nicht unbedingt schlecht und zeigt nicht, dass wir sofort etwas unternehmen müssen.
Es gibt jedoch eine zweite Metrik – seq_tup_read. Dies ist die Anzahl der Zeilen, die als Ergebnis einer sequenziellen Abfrage zurückgegeben wurden. Wenn die durchschnittliche Zahl 1.000, 10.000, 50.000 oder 100.000 überschreitet, ist das ein Hinweis darauf, dass möglicherweise ein Index aufgebaut werden sollte, um die Zugriffe indiziert zu gestalten, oder dass die Anfragen, die solche sequenziellen Scans verwenden, optimiert werden müssen, um dies zu vermeiden.
Ein einfaches Beispiel: Angenommen, eine Anfrage mit einem großen OFFSET und LIMIT steht an. Zum Beispiel, wenn 100.000 Zeilen in einer Tabelle gescannt werden und danach 50.000 benötigte Zeilen entnommen werden, während die vorher gescannten Zeilen verworfen werden. Das ist auch ein schlechter Fall, und solche Anfragen sollten optimiert werden. Hier ist ein einfacher SQL-Befehl, mit dem man dies überprüfen und die erhaltenen Zahlen bewerten kann.

select
relname,
pg_size_pretty(pg_total_relation_size(relname::regclass)) as
full_size,
pg_size_pretty(pg_relation_size(relname::regclass)) as
table_size,
pg_size_pretty(pg_total_relation_size(relname::regclass) -
pg_relation_size(relname::regclass)) as index_size
from pg_stat_user_tables
order by pg_total_relation_size(relname::regclass) desc limit 10;Die Größen der Tabellen können auch mit dieser Tabelle und zusätzlichen Funktionen abgerufen werden. pg_total_relation_size(), pg_relation_size().
Im Allgemeinen gibt es Metakommandos. dt und di, die in PSQL verwendet werden können und auch die Größen von Tabellen und Indizes anzeigen.
Die Verwendung von Funktionen ermöglicht es uns jedoch, die Größen von Tabellen unter Berücksichtigung von Indizes oder ohne Berücksichtigung von Indizes zu betrachten und bereits Schätzungen auf der Grundlage des Wachstums der Datenbank vorzunehmen, d. h. wie sie wächst, mit welcher Intensität, und bereits Schlussfolgerungen über die Optimierung der Größen zu ziehen.
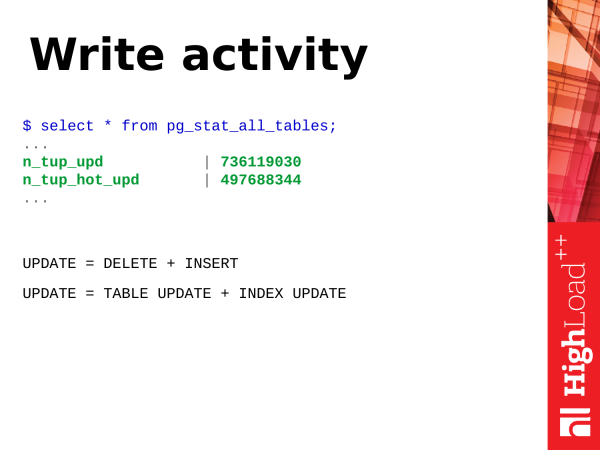
Schreibaktivität. Was ist eine Schreiboperation? Lassen Sie uns die Operation betrachten. UPDATE – die Operation zur Aktualisierung von Zeilen in einer Tabelle. Im Grunde genommen ist ein Update zwei (oder sogar mehr) Vorgänge. Es handelt sich um das Einfügen einer neuen Version der Zeile und die Kennzeichnung der alten Version der Zeile als veraltet. Später wird der Autovacuum-Prozess diese veralteten Versionen der Zeilen bereinigen und diesen Platz als wiederverwendbar markieren.
Darüber hinaus ist ein Update nicht nur die Aktualisierung der Tabelle. Es kommt auch zur Aktualisierung der Indizes. Wenn Ihre Tabelle viele Indizes enthält, müssen bei einem Update alle Indizes, in denen die Felder beteiligt sind, die in der Anfrage aktualisiert werden, ebenfalls aktualisiert werden. In diesen Indizes werden auch veraltete Versionen der Zeilen vorhanden sein, die bereinigt werden müssen.

Wählen Sie
s.relname,
pg_size_pretty(pg_relation_size(relid)),
coalesce(n_tup_ins,0) + 2 * coalesce(n_tup_upd,0) -
coalesce(n_tup_hot_upd,0) + coalesce(n_tup_del,0) AS total_writes,
(coalesce(n_tup_hot_upd,0)::float * 100 / (CASE WHEN n_tup_upd > 0
THEN n_tup_upd ELSE 1 END)::float)::numeric(10,2) AS hot_rate,
(select v[1] FROM regexp_matches(reloptions::text,E'fillfactor=(\d+)') as
r(v) LIMIT 1) AS fillfactor
FROM pg_stat_all_tables s
JOIN pg_class c ON c.oid=relid
ORDER BY total_writes DESC LIMIT 50;Aufgrund ihres Designs sind UPDATE-Operationen jedoch oft sehr ressourcenintensiv. Aber es gibt Möglichkeiten zur Optimierung. Es gibt Hot Updates. Diese wurden in PostgreSQL Version 8.3 eingeführt. Was genau ist das? Es handelt sich um einen leichten Update-Vorgang, der keine Neukonfiguration von Indizes erfordert. Das bedeutet, dass wir einen Datensatz aktualisiert haben, aber nur der Datensatz auf der Seitenablage (die zur Tabelle gehört) aktualisiert wurde, während die Indizes nach wie vor auf denselben Datensatz auf der Seite verweisen. Die Logik hier ist interessant: Wenn der Vacuum-Prozess kommt, wird er diese Ketten hot neu aufbauen, und alles funktioniert weiterhin ohne die Aktualisierung der Indizes, was zu einem geringeren Ressourcenverbrauch führt.
Wenn Sie also n_tup_hot_upd hohe Werte aufweisen, ist das sehr vorteilhaft. Das bedeutet, dass die leichten Updates überwiegen, was für unsere Ressourcen kostengünstiger ist und alles gut läuft.

ALTER TABLE table_name SET (fillfactor = 70);Wie erhöhen wir das Volumen von Hot Updates?Wir können den Fillfactor verwenden.. Es bestimmt die Größe des reservierten freien Raums beim Füllen einer Seite in der Tabelle mit INSERTs. Wenn Daten in die Tabelle eingefügt werden, füllen sie die Seite vollständig aus, ohne freien Raum zu lassen. Dann wird eine neue Seite zugewiesen. Die Daten werden erneut ausgefüllt. Dieses Verhalten ist standardmäßig, fillfactor = 100%.
Wir können den fillfactor auf 70% setzen. Das bedeutet, dass beim Einfügen neuer Daten eine neue Seite zugewiesen wird, aber nur 70% der Seite ausgefüllt werden. 30% bleiben für Reserven. Wenn später ein Update durchgeführt werden muss, wird es mit hoher Wahrscheinlichkeit auf derselben Seite geschehen, und die neue Version der Zeile wird auf dieser Seite untergebracht. So wird ein hot_update durchgeführt. Dies erleichtert das Schreiben in den Tabellen.

select c.relname,
current_setting('autovacuum_vacuum_threshold') as av_base_thresh,
current_setting('autovacuum_vacuum_scale_factor') as av_scale_factor,
(current_setting('autovacuum_vacuum_threshold')::int +
(current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples))
as av_thresh,
s.n_dead_tup
from pg_stat_user_tables s join pg_class c ON s.relname = c.relname
where s.n_dead_tup > (current_setting('autovacuum_vacuum_threshold')::int
+ (current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples));Die Warteschlange des Autovakuums. Das Autovakuum ist ein Subsystem, für das es in PostgreSQL nur sehr wenig Statistiken gibt. In den Tabellen von pg_stat_activity können wir nur sehen, wie viele Vakuumvorgänge derzeit laufen. Es ist jedoch sehr schwierig zu verstehen, wie viele Tabellen sich momentan in der Warteschlange befinden.
Hinweis: Seit Version Postgres 10 hat sich die Situation bezüglich der Nachverfolgung des Autovakuums erheblich verbessert — es gibt jetzt die Ansicht pg_stat_progressvacuum, die die Überwachung des Autovakuums erheblich vereinfacht.
Wir können eine vereinfachte Abfrage wie diese verwenden, um zu sehen, wann ein Vakuum durchgeführt werden sollte. Aber wann und wie sollte das Vakuum gestartet werden? Hier sind die veralteten Versionszeilen, von denen ich vorher sprach. Ein Update fand statt, eine neue Versionszeile wurde eingefügt. Eine veraltete Versionszeile ist entstanden. In der Tabelle pg_stat_user_tables gibt es einen Parameter n_dead_tup. Dieser zeigt die Anzahl der "toten" Zeilen an. Sobald die Anzahl der toten Zeilen einen bestimmten Schwellenwert überschreitet, wird das Autovakuum für die Tabelle aktiviert.
Wie wird dieser Schwellenwert berechnet? Es handelt sich um ein spezifisches Prozentverhältnis der Gesamtzahl der Zeilen in der Tabelle. Es gibt einen Parameter autovacuum_vacuum_scale_factor. Dies bestimmt das prozentuale Verhältnis. Angenommen, 10 % + ein zusätzlicher Grundwert von 50 Zeilen. Was passiert dann? Wenn die Anzahl der toten Zeilen mehr als "10 % + 50" von allen Zeilen in der Tabelle beträgt, setzen wir die Tabelle auf Autovacuum.

select c.relname,
current_setting('autovacuum_vacuum_threshold') as av_base_thresh,
current_setting('autovacuum_vacuum_scale_factor') as av_scale_factor,
(current_setting('autovacuum_vacuum_threshold')::int +
(current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples))
as av_thresh,
s.n_dead_tup
from pg_stat_user_tables s join pg_class c ON s.relname = c.relname
where s.n_dead_tup > (current_setting('autovacuum_vacuum_threshold')::int
+ (current_setting('autovacuum_vacuum_scale_factor')::float * c.reltuples));Es gibt jedoch einen Punkt. Die Grundschwellenwerte für die Parameter av_base_thresh und av_scale_factor können individuell festgelegt werden. Daher ist der Schwellenwert nicht global, sondern individuell für die Tabelle. Um die Berechnung vorzunehmen, müssen daher Tricks und Kniffe angewendet werden. Wenn Sie interessiert sind, können Sie die Erfahrungen unserer Kollegen von Avito einsehen (der Link auf der Folie ist ungültig und im Text aktualisiert).
Sie haben einen geschrieben, der diese Aspekte berücksichtigt. Es handelt sich um zwei Seiten Inhalt. Aber er berechnet korrekt und ermöglicht eine recht effiziente Einschätzung, wo wir viel Vacuum für die Tabellen benötigen und wo weniger.
Was können wir damit tun? Wenn wir eine große Warteschlange haben und Autovacuum nicht ausreicht, können wir die Anzahl der Vacuum-Worker erhöhen oder einfach das Vacuum aggressiver gestalten,damit es früher getriggert wird und die Tabelle in kleinen Portionen bearbeitet wird. So wird die Warteschlange geringer. — Es ist wichtig, die Belastung der Festplatten im Auge zu behalten, da Vakuum nicht kostenlos ist. Mit dem Aufkommen von SSDs/NVMe-Geräten ist das Problem jedoch weniger auffällig geworden.
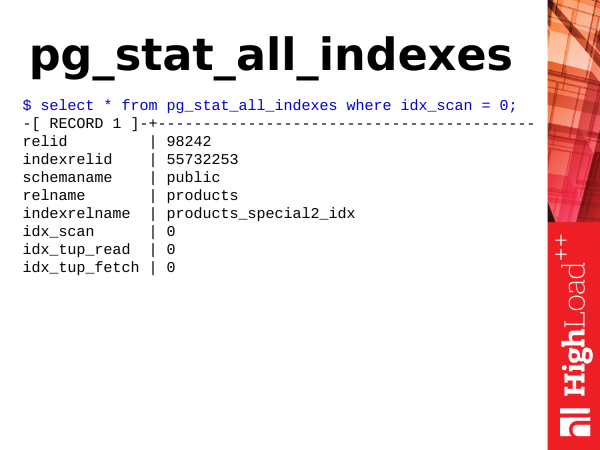
Pg_stat_all_indexes liefert Statistiken zu Indizes. Diese sind gering. Damit können wir Informationen über die Nutzung von Indizes abrufen und beispielsweise feststellen, welche Indizes überflüssig sind.
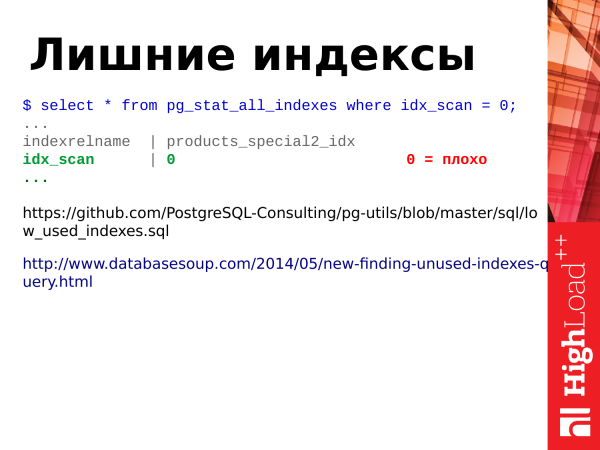
Wie bereits erwähnt, update bedeutet nicht nur, dass Tabellen aktualisiert werden, sondern auch, dass Indizes aktualisiert werden. Daher müssen, wenn wir viele Indizes auf einer Tabelle haben, bei der Aktualisierung von Zeilen auch die Indizes der indizierten Felder aktualisiert werden, und wenn es ungenutzte Indizes gibt, für die keine Indizes-Scans erfolgen, stellen sie eine Belastung dar, und wir müssen sie loswerden. Dafür benötigen wir das Feld idx_scan. Wir schauen einfach auf die Anzahl der Index-Scans. Wenn Indizes über einen relativ langen Zeitraum (mindestens 2-3 Wochen) null Scans aufweisen, sind das höchstwahrscheinlich schlechte Indizes, und wir müssen sie loswerden.
Hinweis: Bei der Suche nach ungenutzten Indizes in einem Streaming-Replikationscluster müssen alle Knoten des Clusters überprüft werden, da die Statistik nicht global ist. Wenn ein Index am Master nicht verwendet wird, könnte er in den Replikaten (wenn dort Last vorhanden ist) genutzt werden.
Zwei Links:
Dies sind fortgeschrittenere Beispiele für Abfragen, um ungenutzte Indizes zu finden.
Der zweite Link führt zu einer recht interessanten Abfrage. Dort ist eine sehr komplexe Logik eingebaut. Ich empfehle, sich damit vertraut zu machen.
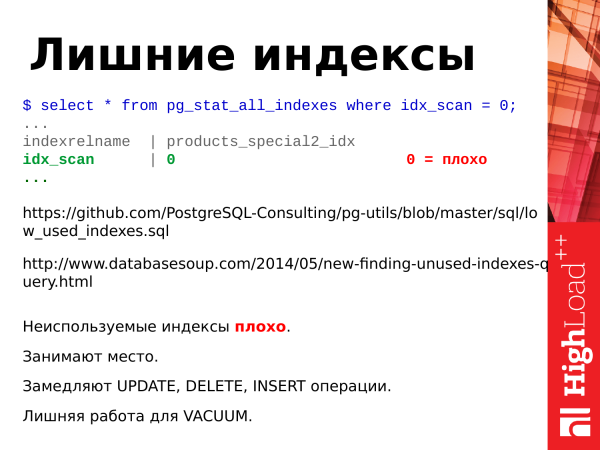
Was könnte man sonst noch zu Indizes zusammenfassen?
Ungenutzte Indizes sind schädlich.
Sie nehmen Platz weg.
Sie verlangsamen Aktualisierungsoperationen.
Zusätzliche Arbeit für das Vakuum.
Wenn wir ungenutzte Indizes entfernen, verbessern wir die Datenbank insgesamt.
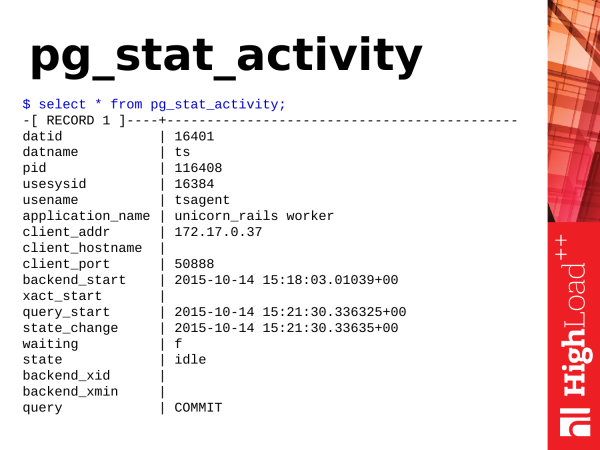
Die nächste Ansicht ist pg_stat_activity. Dies entspricht dem Dienstprogramm ps, nur in PostgreSQL. Wenn psSie Prozesse im Betriebssystem mit 'ps' betrachten, dann pg_stat_activity zeigt es Ihnen die Aktivität innerhalb von PostgreSQL.
Was können wir dort Nützliches entnehmen?

select
count(*)*100/(select current_setting('max_connections')::int)
from pg_stat_activity;Wir können die allgemeine Aktivität in der Datenbank überprüfen. Wir können ein neues Deployment durchführen. Bei uns ist alles eskaliert, neue Verbindungen werden nicht akzeptiert, es treten Fehler in der Anwendung auf.

select
client_addr, usename, datname, count(*)
from pg_stat_activity group by 1,2,3 order by 4 desc;Wir können eine solche Abfrage durchführen und den Gesamtprozentsatz der Verbindungen im Verhältnis zur maximalen Verbindungsgrenze anzeigen sowie sehen, wer die meisten Verbindungen hat. In diesem speziellen Fall sehen wir, dass der Benutzer cron_role 508 Verbindungen geöffnet hat. Da ist etwas passiert, das müssen wir untersuchen. Es ist durchaus möglich, dass dies eine anomal hohe Anzahl an Verbindungen ist.
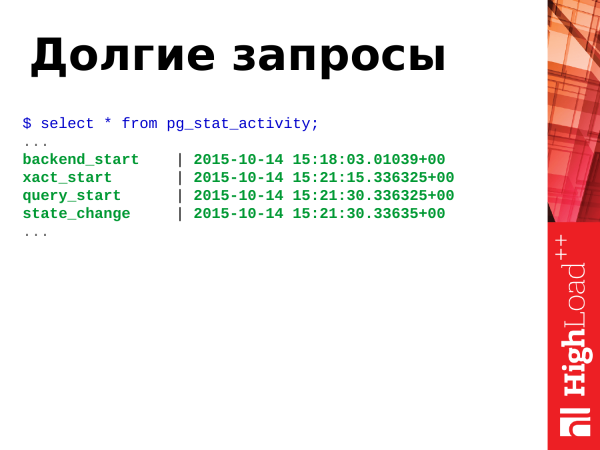
Wenn wir eine OLTP-Last haben, sollten die Abfragen schnell, sehr schnell durchgeführt werden, ohne lange Abfragen. Wenn jedoch lange Abfragen auftreten, ist das kurzfristig nicht schlimm, aber langfristig schädigen lange Abfragen die Datenbank. Sie erhöhen den Bloat-Effekt der Tabellen, wenn Fragmentierung auftritt. Sowohl von Bloat als auch von langen Abfragen sollten wir uns befreien.

select
client_addr, usename, datname,
clock_timestamp() - xact_start as xact_age,
clock_timestamp() - query_start as query_age,
query
from pg_stat_activity order by xact_start, query_start;Bitte beachten Sie: Mit dieser Abfrage können wir langwierige Anfragen und Transaktionen identifizieren. Wir verwenden die Funktion clock_timestamp() um die Laufzeit zu bestimmen. Die gefundenen langwierigen Anfragen können wir speichern, ausführen explain, die Pläne ansehen und sie irgendwie optimieren. Aktuelle langwierige Anfragen beenden wir und arbeiten weiter.
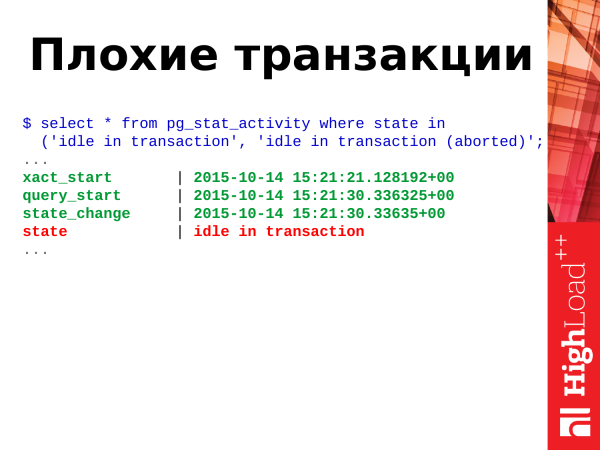
select * from pg_stat_activity where state in
('idle in transaction', 'idle in transaction (aborted)';Schlechte Transaktionen sind Transaktionen im Zustand 'idle in transaction' und 'idle in transaction (aborted)'.
Was bedeutet das? Transaktionen können mehrere Zustände haben, und jeden dieser Zustände können sie jederzeit annehmen. Zur Bestimmung der Zustände gibt es das Feld state in dieser Ansicht. Und wir verwenden es zur Bestimmung des Zustands.

select * from pg_stat_activity where state in
('idle in transaction', 'idle in transaction (aborted)';Und wie bereits erwähnt, können diese beiden Zustände Idle in Transaction und Idle in Transaction (aborted) – das ist schlecht. Was bedeutet das? Es tritt auf, wenn eine Anwendung eine Transaktion eröffnet, einige Aktionen durchführt und dann ihrer Wege geht. Die Transaktion bleibt offen. Sie bleibt hängen, es passiert nichts, sie blockiert eine Verbindung, führt zu Sperren auf geänderte Zeilen und kann potenziell den Bloat anderer Tabellen erhöhen, aufgrund der Architektur des transaktionalen Engines von PostgreSQL. Solche Transaktionen sollten ebenfalls beendet werden, da sie insgesamt schädlich sind, ganz gleich, wie man es betrachtet.
Wenn Sie sehen, dass Sie mehr als 5-10-20 davon in Ihrer Datenbank haben, sollten Sie sich bereits Sorgen machen und anfangen, etwas dagegen zu unternehmen.
Hier verwenden wir auch für die Berechnungszeit clock_timestamp(). Transaktionen werden beendet, Anwendungen werden optimiert.
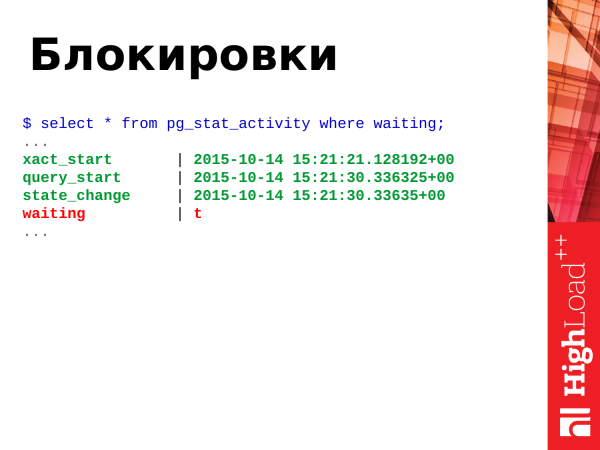
Wie ich bereits oben erwähnt habe, entstehen Blockierungen, wenn zwei oder mehr Transaktionen um eine oder mehrere Ressourcen konkurrieren. Dafür haben wir das Feld waiting mit einem booleschen Wert true oder false.
True – das bedeutet, dass der Prozess im Wartemodus ist, es muss etwas unternommen werden. Wenn der Prozess im Wartemodus ist, bedeutet das, dass der Client, der diesen Prozess initiiert hat, ebenfalls wartet. Der Client in seinem Browser sitzt ebenfalls und wartet.
Achtung: _Ab Version PostgreSQL 9.6 ist das Feld waiting wurde entfernt und durch zwei informativere Felder ersetzt wait_event_type und wait_event._
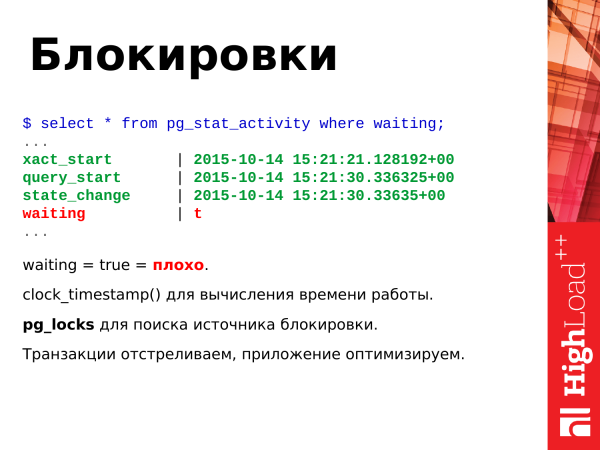
Was tun? Wenn Sie über einen langen Zeitraum true sehen, sollte man solche Anfragen vermeiden. Wir blockieren einfach solche Transaktionen. An die Entwickler schreiben wir, dass eine Optimierung notwendig ist, um keine Ressourcenkonflikte zu verursachen. Danach optimieren die Entwickler die Anwendung, um solche Situationen zu vermeiden.
Der letzte, aber potenziell nicht kritische Fall ist das Auftreten von Deadlocks. Zwei Transaktionen haben zwei Ressourcen aktualisiert und greifen dann wieder auf diese Ressourcen zu, aber von den entgegengesetzten Seiten. In diesem Fall beendet PostgreSQL die Transaktion, damit die andere weiterarbeiten kann. Dies ist eine Sackgasse, die sich nicht von selbst löst. Daher sieht sich PostgreSQL gezwungen, drastische Maßnahmen zu ergreifen.

Hier sind zwei Abfragen, mit denen man Deadlocks überwachen kann. Wir verwenden die Sicht pg_locks, die es ermöglicht, schwere Blockaden zu überwachen.
Der erste Link ist der Text der Abfrage selbst. Er ist ziemlich lang.
Der zweite Link ist ein Artikel über Locks. Es ist nützlich, ihn zu lesen, er ist sehr interessant.
Also, was sehen wir? Wir sehen zwei Abfragen. Die Transaktion mit ALTER TABLE – ist eine blockierende Transaktion. Sie wurde gestartet, aber nicht abgeschlossen und die Anwendung, die diese Transaktion ausgelöst hat, beschäftigt sich irgendwo anders. Die zweite Anfrage – Update. Sie wartet, bis ALTER TABLE abgeschlossen ist, um ihre Arbeit fortzusetzen.
So können wir herausfinden, wer wen blockiert, und können dieses Problem weiter untersuchen.
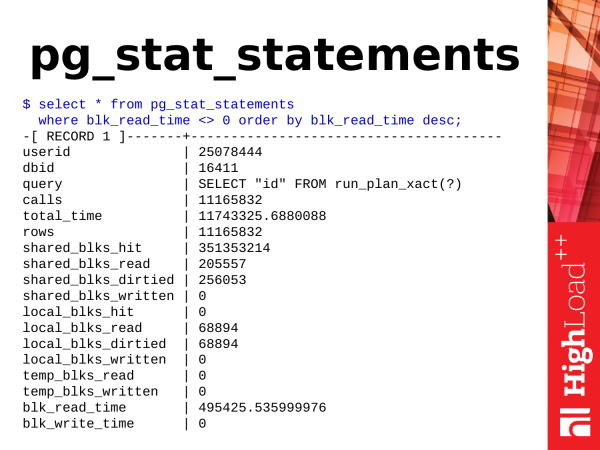
Das nächste Modul – das pg_stat_statements. Wie bereits erwähnt, handelt es sich um ein Modul. Um es zu nutzen, müssen wir seine Bibliothek in die Konfiguration laden, PostgreSQL neu starten, das Modul (mit einem Befehl) installieren und dann haben wir eine neue Ansicht.

Durchschnittliche Abfragezeit in Millisekunden
$ select (sum(total_time) / sum(calls))::numeric(6,3)
from pg_stat_statements;
Die aktivsten Schreibabfragen (in shared_buffers)
$ select query, shared_blks_dirtied
from pg_stat_statements
where shared_blks_dirtied > 0 order by 2 desc;Was können wir daraus entnehmen? Wenn wir über einfache Dinge sprechen, können wir die durchschnittliche Ausführungszeit der Abfrage nehmen. Wenn die Zeit steigt, bedeutet das, dass PostgreSQL langsam antwortet und wir etwas unternehmen müssen.
Wir können die aktivsten schreibenden Transaktionen in der Datenbank betrachten, die Daten in shared buffers ändern. Schauen wir, wer dort Daten aktualisiert oder löscht.
Wir können verschiedene Statistiken zu diesen Anfragen einfach einsehen.

Wir pg_stat_statements werden verwendet, um Berichte zu erstellen. Einmal täglich setzen wir die Statistiken zurück und sammeln sie. Vor dem nächsten Zurücksetzen der Statistiken erstellen wir einen Bericht. Hier ist der Link zum Bericht. Sie können ihn sich ansehen.

Was tun wir? Wir zählen die Gesamtstatistik für alle Anfragen. Dann berechnen wir den individuellen Beitrag jeder Anfrage zu dieser Gesamtstatistik.
Was können wir einsehen? Wir können die Gesamtverarbeitungszeit aller Anfragen eines bestimmten Typs im Vergleich zu allen anderen Anfragen betrachten. Wir können die Nutzung der CPU- und I/O-Ressourcen gegenüber dem Gesamtbild analysieren. Und dann diese Anfragen optimieren. Wir erstellen ein Ranking der Anfragen basierend auf diesem Bericht und erhalten bereits Denkanstöße zur Optimierung.

Was bleibt uns verborgen? Es gibt noch einige Darstellungen, die ich nicht behandelt habe, weil die Zeit begrenzt ist.
Es gibt pgstattuple ist ebenfalls ein zusätzliches Modul aus dem Standardpaket contribs. Es ermöglicht die Einschätzung Bloat Tabellen, d.h. die Fragmentierung der Tabellen. Wenn die Fragmentierung stark ist, sollte man sie beseitigen und verschiedene Werkzeuge einsetzen. Und die Funktion pgstattuple arbeitet lange. Je mehr Tabellen vorhanden sind, desto länger wird sie arbeiten.

Der nächste Beitrag ist pg_buffercache. Er ermöglicht die Inspektion der Shared Buffers: wie intensiv und für welche Tabellen die Seiten des Puffers genutzt werden. Und er erlaubt einen Blick in die Shared Buffers und zur Bewertung der Vorgänge dort.
Das nächste Modul – das pgfincore. Er ermöglicht niedriglevelige Operationen mit Tabellen über den Systemaufruf mincore(), d.h. er erlaubt es, eine Tabelle in die Shared Buffers zu laden oder sie dort herauszuladen. Darüber hinaus ermöglicht er die Inspektion des Seiten-Caches des Betriebssystems, d.h. in welchem Umfang unsere Tabelle im Page Cache und in den Shared Buffers belegt ist und hilft, die Belastung der Tabelle zu bewerten.
Das nächste Modul ist pg_stat_kcache. Es verwendet ebenfalls den Systemaufruf getrusage(). Es führt diesen vor und nach der Ausführung der Abfrage aus. In den gewonnenen Statistiken können wir beurteilen, wie viel Zeit die Abfrage für die Durchführung von Datenträger-I/O, d.h. Operationen mit dem Dateisystem, benötigt hat, und wir betrachten die CPU-Nutzung. Allerdings ist das Modul noch relativ neu (hüstel-hüstel) und benötigt für seine Funktion PostgreSQL 9.4 sowie pg_stat_statements, auf das ich zuvor eingegangen bin.

Der Umgang mit Statistiken ist nützlich. Sie benötigen keine Drittanbieter-Software. Sie können selbst einen Blick darauf werfen, etwas tun, eine Abfrage ausführen.
Es ist einfach, Statistiken zu nutzen; es ist ganz normales SQL. Sie erstellen eine Abfrage, formulieren sie, senden sie und schauen sich die Ergebnisse an.
Statistiken helfen dabei, Fragen zu beantworten. Wenn Fragen auftauchen, ziehen Sie die Statistiken hinzu - betrachten Sie sie, ziehen Sie Rückschlüsse und analysieren Sie die Ergebnisse.
Und experimentieren Sie. Es gibt viele Abfragen und viele Daten. Sie können immer eine bereits bestehende Abfrage optimieren. Sie können Ihre eigene Version einer Abfrage erstellen, die besser zu Ihnen passt als das Original, und diese verwenden.

Links
Nützliche Links, die in dem Artikel erwähnt wurden, basierend auf dem Material aus dem Bericht.
Der Autor schreibt weiter
(eng)
Der Statistik-Sammler
Funktionen der Systemadministration
Beitragsmodule
SQL-Utilities und SQL-Codebeispiele
Vielen Dank für Ihre Aufmerksamkeit!
Quelle: habr.com
