

Im Vorfeld des Starts eines neuen Kurses haben wir eine interessante Materialübersetzung vorbereitet.

Übersicht
Wir werden über ein weit verbreitetes Muster sprechen, bei dem Anwendungen mehrere Datenspeicher nutzen, wobei jeder Speicher für spezifische Zwecke verwendet wird, wie beispielsweise für die Speicherung einer kanonischen Datenform (MySQL usw.), um verbesserte Suchmöglichkeiten (ElasticSearch usw.) zu gewährleisten, zur Zwischenspeicherung (Memcached usw.) und mehr. In der Regel fungiert einer der Datenspeicher als primärer Speicher, während die anderen als abgeleitete Speicher fungieren. Das eigentliche Problem besteht darin, wie diese Datenspeicher synchronisiert werden.
Wir haben eine Reihe verschiedener Muster untersucht, die versucht haben, das Problem der Synchronisation mehrerer Speicher zu lösen, wie z.B. doppelte Schreibvorgänge, verteilte Transaktionen usw. Diese Ansätze haben jedoch wesentliche Einschränkungen hinsichtlich der praktischen Anwendbarkeit, Zuverlässigkeit und Wartung. Neben der Datensynchronisation müssen einige Anwendungen auch Daten anreichern, indem sie externe Dienste aufrufen.
Um diese Probleme zu lösen, wurde Delta entwickelt. Delta stellt letztendlich eine konsistente, ereignisgesteuerte Plattform zur Synchronisierung und Anreicherung von Daten dar.
Bestehende Lösungen
Dual-Write
Um zwei Datenspeicher zu synchronisieren, kann die Dual-Write-Technik verwendet werden, bei der zuerst in einen Speicher geschrieben und anschließend sofort in einen anderen geschrieben wird. Der erste Schreibvorgang kann wiederholt werden, während der zweite abgebrochen werden kann, wenn der erste nach Ausschöpfung der Versuche fehlschlägt. Es besteht jedoch die Möglichkeit, dass die beiden Datenspeicher nicht mehr synchronisiert werden, wenn der Schreibvorgang im zweiten Speicher fehlschlägt. Dieses Problem wird in der Regel durch die Erstellung einer Wiederherstellungsprozedur gelöst, die regelmäßig Daten aus dem ersten Speicher in den zweiten übertragen kann oder dies nur tut, wenn Unterschiede in den Daten festgestellt werden.
Probleme:
Die Durchführung des Wiederherstellungsverfahrens ist eine spezifische Aufgabe, die nicht wiederverwendet werden kann. Darüber hinaus bleiben die Daten zwischen den Speichern bis zur Durchführung des Wiederherstellungsverfahrens unsynchronisiert. Das Problem wird komplizierter, wenn mehr als zwei Datenspeicher verwendet werden. Und schließlich kann das Wiederherstellungsverfahren zusätzliche Belastung auf die ursprüngliche Datenquelle erzeugen.
Änderungsprotokoll-Tabelle
Wenn Änderungen in einer Satz von Tabellen auftreten (z. B. das Einfügen, Aktualisieren und Löschen eines Datensatzes), werden die Änderungsaufzeichnungen als Teil derselben Transaktion in die Protokolltabelle eingefügt. Ein anderer Prozess oder Thread fragt ständig Ereignisse aus der Protokolltabelle ab und speichert sie in einem oder mehreren Datenspeichern, wobei bei Bedarf Ereignisse aus der Protokolltabelle entfernt werden, nachdem die Aufnahme von allen Speichern bestätigt wurde.
Probleme:
Dieses Muster sollte als Bibliothek implementiert werden, idealerweise ohne Änderungen am verwendenden Anwendungscode. In einer polyglotten Umgebung sollte eine solche Bibliothek in jeder erforderlichen Sprache existieren, jedoch ist es ziemlich schwierig, die Konsistenz von Funktionen und Verhalten zwischen den Sprachen sicherzustellen.
Ein weiteres Problem besteht darin, Änderungen an Schema zu erhalten in Systemen, die keine transaktionalen Schemaänderungen unterstützen [1][2], wie beispielsweise MySQL. Daher wird das Muster für die Durchführung von Änderungen (zum Beispiel von Schemaänderungen) und die transaktionale Aufzeichnung in der Änderungsprotokoll-Tabelle nicht immer funktionieren.
Verteilte Transaktionen
Verteilte Transaktionen können verwendet werden, um eine Transaktion zwischen mehreren heterogenen Datenspeichern zu teilen, sodass die Operation entweder in allen verwendeten Speichern festgeschrieben wird oder in keinem von ihnen.
Probleme:
Verteilte Transaktionen stellen eine erhebliche Herausforderung für heterogene Datenspeicher dar. Sie sind naturgemäß auf den kleinsten gemeinsamen Nenner der beteiligten Systeme angewiesen. Beispielsweise blockieren XA-Transaktionen die Ausführung, wenn während des Anwendungsprozesses ein Fehler in der Vorbereitungsphase auftritt. Darüber hinaus bietet XA keine Möglichkeit zur Erkennung von Deadlocks und unterstützt keine optimistischen Verfahren zur Parallelitätskontrolle. Außerdem unterstützen einige Systeme wie ElasticSearch weder XA noch andere heterogene Transaktionsmodelle. Daher bleibt es für Anwendungen eine komplexe Aufgabe, die Atomarität von Aufzeichnungen in verschiedenen Datenspeichertechnologien sicherzustellen [3].
Delta
Delta wurde entwickelt, um die Einschränkungen bestehender Daten-Synchronisierungslösungen zu überwinden, und ermöglicht zudem die Echtzeit-Anreicherung von Daten. Unser Ziel war es, alle diese komplexen Aspekte von den Anwendungsentwicklern zu abstrahieren, damit sie sich vollständig auf die Implementierung der Geschäftslogik konzentrieren können. Im Folgenden werden wir "Movie Search" beschreiben, ein konkretes Anwendungsbeispiel von Delta bei Netflix.
Bei Netflix wird eine Microservice-Architektur umfassend eingesetzt, wobei jeder Microservice in der Regel einen bestimmten Datentyp verarbeitet. Die grundlegenden Informationen zu Filmen werden in einen Microservice mit dem Namen Movie Service ausgelagert, während verwandte Daten wie Informationen über Produzenten, Schauspieler, Anbieter und so weiter von mehreren anderen Microservices verwaltet werden, namentlich Deal Service, Talent Service und Vendor Service.
Geschäftsanwender in Netflix Studios müssen oft Filme nach verschiedenen Kriterien suchen, weshalb es für sie von großer Bedeutung ist, die Möglichkeit zu haben, in allen filmbezogenen Daten zu suchen.
Vor der Einführung von Delta musste das Film-Suchteam Daten aus mehreren Microservices abrufen, bevor es die Filmdaten indizieren konnte. Darüber hinaus musste das Team ein System entwickeln, das den Suchindex regelmäßig aktualisierte, indem es Änderungen von anderen Microservices anforderte, selbst wenn keine Änderungen vorlagen. Dieses System wurde schnell komplex und war schwer zu warten.
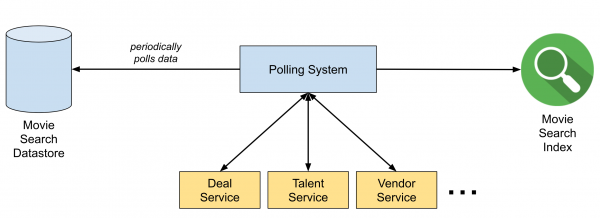
Abbildung 1. Das Polling-System vor Delta
Nach der Einführung von Delta wurde das System auf ein ereignisgesteuertes System vereinfacht, wie im folgenden Bild gezeigt. CDC (Change-Data-Capture)-Ereignisse werden über den Delta-Connector in die Keystone Kafka-Topics gesendet. Die Delta-Anwendung, die mit dem Delta Stream Processing Framework (basierend auf Flink) entwickelt wurde, empfängt CDC-Ereignisse aus dem Topic, bereichert sie durch Aufrufen anderer Mikrodienste und überträgt schließlich die angereicherten Daten in den Suchindex in Elasticsearch. Der gesamte Prozess erfolgt nahezu in Echtzeit, d.h. sobald Änderungen im Datenspeicher festgehalten werden, werden die Suchindizes aktualisiert.
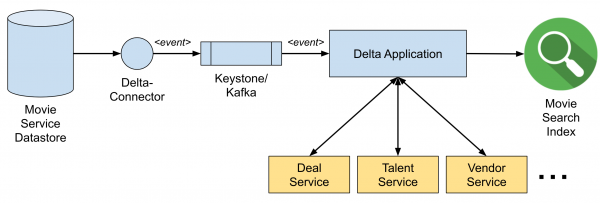
Abbildung 2. Datenpipeline bei der Nutzung von Delta
In den folgenden Abschnitten werden wir die Funktionsweise des Delta-Connectors erläutern, der sich mit dem Speicher verbindet und CDC-Ereignisse auf der Transportschicht veröffentlicht, die eine Echtzeit-Datenübertragungsinfrastruktur darstellt, die CDC-Ereignisse in Kafka-Topics leitet. Schließlich werden wir über die Stream Processing-Struktur von Delta sprechen, die Anwendungsentwickler für die Logik der Verarbeitung und Anreicherung von Daten nutzen können.
CDC (Change-Data-Capture)
Wir haben einen CDC-Service namens Delta-Connector entwickelt, der in der Lage ist, beglichene Änderungen aus dem Datenspeicher in Echtzeit zu erfassen und in einen Stream zu schreiben. Die Echtzeitänderungen stammen aus dem Transaktionsprotokoll und den Speicher-Dumps. Dumps werden verwendet, da Transaktionsprotokolle normalerweise nicht die gesamte Historie der Änderungen speichern. Änderungen werden üblicherweise als Delta-Events serialisiert, sodass sich der Empfänger keine Gedanken darüber machen muss, woher die Änderung stammt.
Der Delta-Connector unterstützt mehrere zusätzliche Funktionen, wie zum Beispiel:
- Die Möglichkeit, in benutzerdefinierte Ausgabekanäle direkt ohne Kafka zu schreiben.
- Die Möglichkeit, manuelle Dumps jederzeit für alle Tabellen, eine bestimmte Tabelle oder für bestimmte Primärschlüssel zu aktivieren.
- Dumps können in Stücken abgerufen werden, sodass es nicht notwendig ist, im Falle eines Fehlers von vorne zu beginnen.
- Es ist keine Sperrung von Tabellen erforderlich, was entscheidend ist, damit der Schreibverkehr in die Datenbank niemals durch unseren Service blockiert wird.
- Hohe Verfügbarkeit dank Backup-Instanzen in den AWS Availability Zones.
Derzeit unterstützen wir MySQL und Postgres, einschließlich der Bereitstellung in AWS RDS und Aurora. Außerdem unterstützen wir Cassandra (Multi-Master). Weitere Informationen zum Delta-Connector finden Sie in diesem .
Kafka und die Transportschicht
Die Transportschicht für Delta-Ereignisse basiert auf dem Messaging-Service der Plattform .
Historisch gesehen wurde die Veröffentlichung von Nachrichten in Netflix so optimiert, dass die Verfügbarkeit im Vordergrund steht und nicht die Langlebigkeit (siehe ). Dies führte in bestimmten Grenzszenarien zu einer potenziellen Inkonsistenz der Broker-Daten. Zum Beispiel unclean leader election führt dazu, dass der Empfänger möglicherweise Ereignisse dupliziert oder verliert.
Mit Delta wollten wir stärkere Garantien für die Langlebigkeit schaffen, um die Lieferung von CDC-Ereignissen an abgeleitete Speicher zu gewährleisten. Dazu haben wir einen speziell gestalteten Kafka-Cluster als First-Class-Objekt eingeführt. Einige Broker-Einstellungen finden Sie in der Tabelle unten:
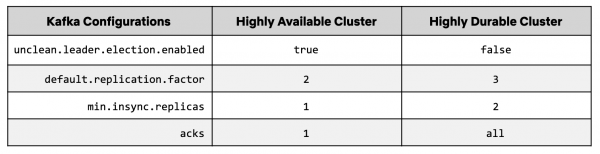
In den Keystone Kafka-Clustern, unclean leader election ist normalerweise aktiviert, um die Verfügbarkeit des Publishers sicherzustellen. Dies kann zu einem Verlust von Nachrichten führen, wenn eine unsynchronisierte Replik als Leader ausgewählt wird. Für ein neues hochverfügbares Kafka-Cluster ist die Einstellung unclean leader election deaktiviert, um den Verlust von Nachrichten zu verhindern.
Außerdem haben wir den Replikationsfaktor von 2 auf 3 und die minimalen in-sync Replikate von 1 auf 2 erhöht. Publisher, die in dieses Cluster schreiben, verlangen Acknowledgments von allen anderen, wodurch sichergestellt wird, dass 2 von 3 Replikaten die aktuellsten vom Publisher gesendeten Nachrichten enthalten.
Wenn eine Broker-Instanz heruntergefahren wird, ersetzt eine neue Instanz die alte. Die neue Broker-Instanz muss jedoch die unsynchronisierten Replikate aufholen, was mehrere Stunden in Anspruch nehmen kann. Um die Wiederherstellungszeit in diesem Szenario zu verkürzen, haben wir begonnen, blockbasierte Datenspeicher (Amazon Elastic Block Store) anstelle der lokalen Broker-Festplatten zu verwenden. Wenn die neue Instanz die beendete Broker-Instanz ersetzt, verbindet sie das EBS-Volume der beendeten Instanz und beginnt, neue Nachrichten aufzuholen. Dieser Prozess verkürzt die Zeit zur Behebung des Rückstands von mehreren Stunden auf mehrere Minuten, da die neue Instanz nicht mehr aus einem leeren Zustand replizieren muss. Insgesamt verringern separate Lebenszyklen von Speicher und Broker erheblich die Auswirkungen des Wechsels des Brokers.
Um die Datenauslieferung weiter zu garantieren, haben wir eine eingesetzt, um jeglichen Nachrichtenverlust unter extremen Bedingungen (z.B. unsynchronisierte Uhren im Partition Leader) zu erkennen.
Stream Processing Framework
Das Verarbeitungsniveau in Delta basiert auf der Netflix SPaaS-Plattform, die die Integration von Apache Flink mit dem Netflix-Ökosystem ermöglicht. Die Plattform bietet eine Benutzeroberfläche, die das Deployment von Flink-Jobs und die Orchestrierung von Flink-Clustern auf unserer Container-Management-Plattform Titus verwaltet. Die Oberfläche steuert auch die Konfigurationen der Jobs und erlaubt es den Nutzern, Änderungen an den Konfigurationen dynamisch vorzunehmen, ohne die Flink-Jobs neu kompilieren zu müssen.
Delta bietet ein Framework zur Datenstreamverarbeitung (stream processing framework) auf Basis von Flink und SPaaS, das verwendet wird, das auf Annotationsbasis DSL (Domain Specific Language) nutzt, um technische Details zu abstrahieren. Um beispielsweise den Schritt zu definieren, mit dem Ereignisse angereichert werden, indem externe Services aufgerufen werden, müssen die Nutzer den folgenden DSL-Code schreiben, und das Framework erstellt darauf basierend ein Modell, das von Flink ausgeführt wird.
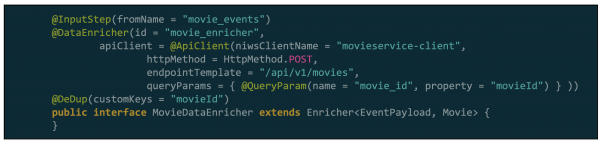
Abbildung 3. Beispiel für die Anreicherung mit DSL in Delta
Das Framework zur Verarbeitung verkürzt nicht nur die Lernkurve, sondern bietet auch grundlegende Funktionen für die Stream-Verarbeitung wie Deduplication, Schematization sowie Flexibilität und Ausfallsicherheit zur Lösung häufiger Betriebsprobleme.
Das Delta Stream Processing Framework besteht aus zwei Hauptmodulen: dem DSL- & API-Modul und dem Runtime-Modul. Das DSL- & API-Modul bietet eine DSL und ein UDF (User-Defined-Function) API, damit Benutzer ihre eigene Verarbeitungslogik (zum Beispiel Filtern oder Transformationen) implementieren können. Das Runtime-Modul stellt eine Implementierung des DSL-Parsers bereit, der eine interne Darstellung der Verarbeitungsschritte in DAG-Modellen erstellt. Die Execution-Komponente interpretiert die DAG-Modelle, um die tatsächlichen Flink-Operatoren zu initialisieren und schließlich die Flink-Anwendung zu starten. Die Architektur des Frameworks ist in der folgenden Abbildung dargestellt.
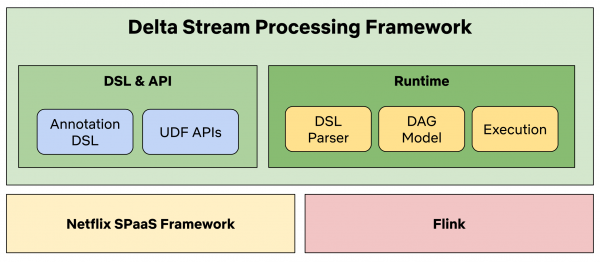
Abbildung 4. Architektur des Delta Stream Processing Frameworks
Dieser Ansatz hat mehrere Vorteile:
- Benutzer können sich auf ihre Geschäftslogik konzentrieren, ohne sich mit den Spezifika von Flink oder der SPaaS-Struktur auseinanderzusetzen.
- Optimierungen können für die Nutzer transparent durchgeführt werden, und Fehler können ohne Änderungen am Benutzer-Code (UDF) behoben werden.
- Die Nutzung von Delta-Anwendungen ist für die Nutzer vereinfacht, da die Plattform von Haus aus Flexibilität und Ausfallsicherheit bietet und zahlreiche detaillierte Metriken sammelt, die für Benachrichtigungen verwendet werden können.
Einsatz in der Produktion
Delta ist seit über einem Jahr in der Produktion und spielt eine Schlüsselrolle in vielen Anwendungen von Netflix Studio. Es hat den Teams geholfen, Anwendungsfälle wie Suchindizierung, Datenspeicherung und ereignisgesteuerte Workflows zu realisieren. Unten ist eine Übersicht über die hochgradige Architektur der Delta-Plattform dargestellt.
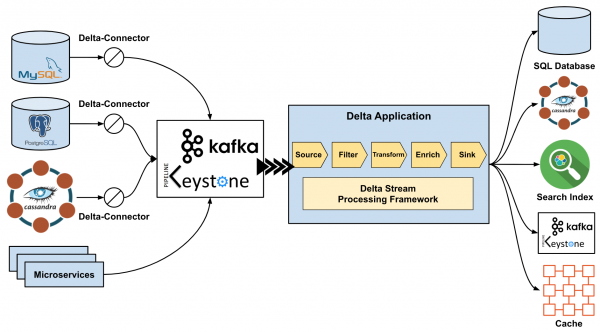
Abbildung 5. Hochgradige Architektur von Delta.
Danksagungen
Wir möchten den folgenden Personen danken, die an der Schaffung und Weiterentwicklung von Delta bei Netflix beteiligt waren: Allen Wang, Charles Zhao, Jaebin Yoon, Josh Snyder, Kasturi Chatterjee, Mark Cho, Olof Johansson, Piyush Goyal, Prashanth Ramdas, Raghuram Onti Srinivasan, Sandeep Gupta, Steven Wu, Tharanga Gamaethige, Yun Wang und Zhenzhong Xu.
Quellen
- Martin Kleppmann, Alastair R. Beresford, Boerge Svingen: Online-Ereignisverarbeitung. Commun. ACM 62(5): 43–49 (2019). DOI:
: „Data Build Tool für Amazon Redshift“.
Quelle: habr.com
