

Kubernetes ist ein hervorragendes Werkzeug zum Starten von Docker-Containern in einer clusterbasierten Produktionsumgebung. Es gibt jedoch Aufgaben, die Kubernetes nicht lösen kann. Bei häufigen Bereitstellungen in der Produktionsumgebung benötigen wir ein vollständig automatisiertes Blue/Green Deployment, um Ausfallzeiten in diesem Prozess zu vermeiden, wobei auch externe HTTP-Anfragen verarbeitet und SSL-Uploads durchgeführt werden müssen. Dies erfordert eine Integration mit einem Lastenausgleichssystem, wie zum Beispiel ha-proxy. Ein weiteres Anliegen ist das halbautomatische Scaling des Kubernetes-Clusters in einer Cloud-Umgebung, wie zum Beispiel das teilweise Reduzieren der Clustergröße während der Nacht.
Obwohl Kubernetes diese Funktionen nicht direkt „out of the box“ bietet, stellt es eine API zur Verfügung, die zur Lösung solcher Aufgaben genutzt werden kann. Werkzeuge für automatisiertes Blue/Green Deployment und das Skalieren von Kubernetes-Clustern wurden im Rahmen des Cloud RTI-Projekts entwickelt, das auf Open-Source basiert.
In diesem Artikel zur Videoentzifferung erfahren Sie, wie Sie Kubernetes zusammen mit anderen Open-Source-Komponenten einrichten, um eine produktionsbereite Umgebung zu schaffen, die ohne Ausfallzeiten im Produktionsbetrieb Code von einem git commit verarbeitet.

Sobald Sie Zugang zu Ihren Anwendungen aus der Außenwelt erhalten haben, können Sie mit der vollständigen Automatisierung beginnen. Das bedeutet, dass Sie die Automatisierung so weit vorantreiben, dass Sie einen git commit ausführen können und sicher sein können, dass dieser git commit in der Produktion endet. Natürlich möchten wir bei der Umsetzung dieser Schritte und beim Deployment keine Ausfallzeiten erleben. Somit beginnt jede Automatisierung in Kubernetes mit der API.

Kubernetes ist nicht das Tool, das man produktiv "out of the box" verwenden kann. Natürlich können Sie es so tun, kubectl verwenden und dergleichen, aber die API ist das Interessanteste und Nützlichste an dieser Plattform. Indem Sie die API als Funktionsset nutzen, können Sie nahezu alles, was Sie in Kubernetes tun möchten, ansteuern. Kubectl selbst verwendet ebenfalls die REST-API.
Es handelt sich um eine REST-API, sodass Sie jede beliebige Sprache und jedes Tool zur Arbeit mit dieser API verwenden können, aber benutzerdefinierte Bibliotheken werden Ihnen das Leben erheblich erleichtern. Mein Team hat zwei solche Bibliotheken geschrieben: eine für Java / OSGi und eine für Go. Letztere wird nicht häufig verwendet, aber diese nützlichen Dinge stehen Ihnen auf jeden Fall zur Verfügung. Sie sind Teil eines teilweise lizenzierten Open-Source-Projekts. Es gibt zahlreiche solcher Bibliotheken für verschiedene Sprachen, sodass Sie die am besten geeigneten auswählen können.
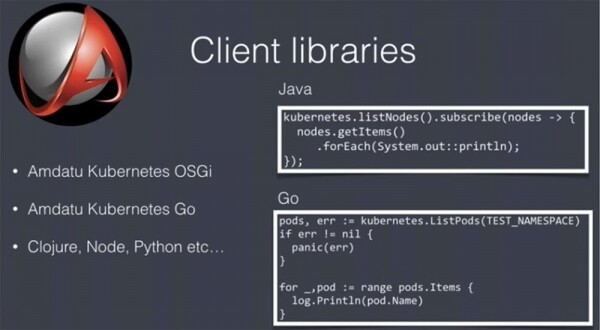
Bevor Sie mit der Automatisierung der Bereitstellung beginnen, ist es entscheidend, sicherzustellen, dass dieser Prozess keine Ausfallzeiten verursacht. Unsere Team führt beispielsweise Produktionsbereitstellungen tagsüber durch, wenn die Nutzung der Anwendungen am höchsten ist. Daher ist es von großer Bedeutung, Verzögerungen in diesem Prozess zu vermeiden. Um Ausfallzeiten zu verhindern, stehen zwei Methoden zur Verfügung: Blue/Green-Bereitstellung oder Rolling Update. Letzteres bedeutet, dass, wenn Sie 5 Replikate Ihrer Anwendung haben, diese nacheinander aktualisiert werden. Diese Methode funktioniert ausgezeichnet, eignet sich jedoch nicht, wenn während der Bereitstellung verschiedene Versionen der Anwendung gleichzeitig laufen. In diesem Fall könnte das Benutzerinterface aktualisiert werden, während das Backend noch mit der alten Version arbeitet, was zu einer Unterbrechung des Anwendungsbetriebs führen würde. Daher gestaltet sich die Programmierung unter diesen Bedingungen als herausfordernd.
Das ist einer der Gründe, warum wir Blue/Green-Deployment bevorzugen, um die Bereitstellung unserer Anwendungen zu automatisieren. Bei dieser Methode müssen Sie sicherstellen, dass zu einem bestimmten Zeitpunkt nur eine Version der Anwendung aktiv ist.
Der Mechanismus des Blue/Green-Deployments funktioniert folgendermaßen: Wir erhalten den Datenverkehr für unsere Anwendungen über HA-Proxy, der ihn an die laufenden Replikate der Anwendung mit derselben Version weiterleitet.
Wenn ein neues Deployment stattfindet, verwenden wir Deployer, dem die neuen Komponenten zur Verfügung gestellt werden, und dieser führt das Deployment der neuen Version durch. Das Deployment einer neuen Version der Anwendung bedeutet, dass ein neuer Satz von Replikaten ''hochgefahren'' wird, nachdem diese Replikate der neuen Version in einem separaten, neuen Pod gestartet werden. Allerdings weiß HA-Proxy noch nichts über diese und leitet vorerst keine Arbeitslast an sie weiter.
Daher ist es zunächst erforderlich, die neuen Versionen mit einem Health-Check zu überprüfen, um sicherzustellen, dass die Replikate bereit sind, die Last zu übernehmen.
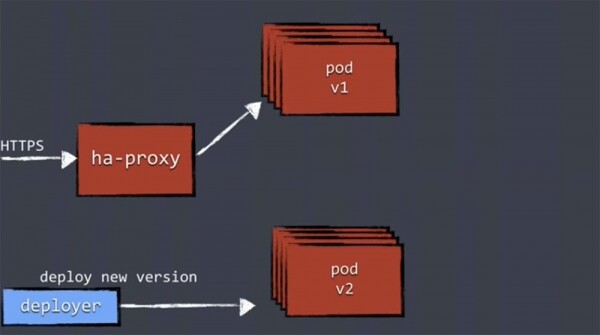
Alle Bereitstellungskomponenten sollten eine Form von Health Check unterstützen. Dies kann ein ganz einfacher HTTP-Check sein, bei dem Sie einen Statuscode von 200 erhalten, oder ein tiefgehenderer Check, bei dem Sie die Verbindung der Replikate zur Datenbank und zu anderen Diensten sowie die Stabilität der Verbindungen in der dynamischen Umgebung überprüfen. Dabei wird sichergestellt, dass alles gestartet wird und korrekt funktioniert. Dieser Prozess kann recht komplex sein.
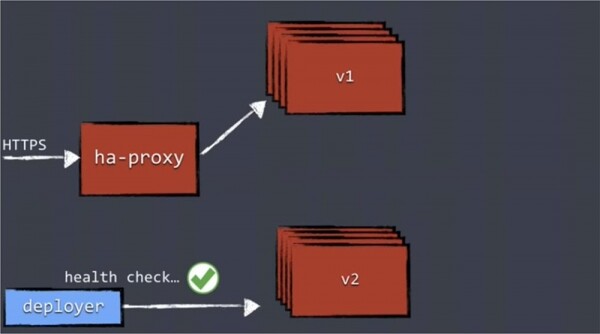
Sobald das System die Funktionsfähigkeit aller aktualisierten Replikate bestätigt hat, wird der Deployer die Konfiguration aktualisieren und das passende confd übergeben, welches ha-proxy neu konfiguriert.
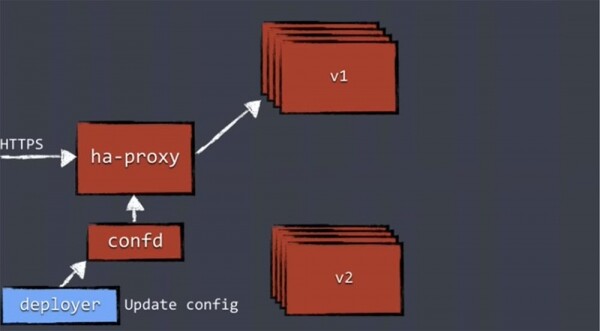
Erst danach wird der Verkehr auf den Pod mit den Replikaten der neuen Version geleitet, während der alte Pod verschwindet.
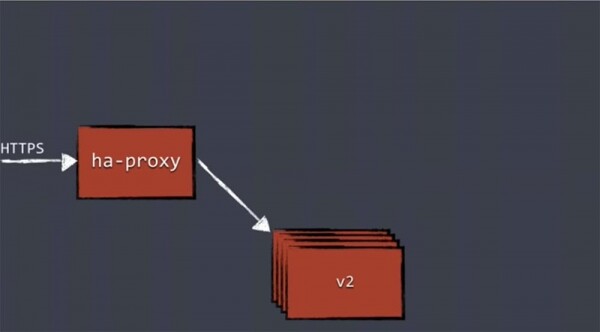
Dieser Mechanismus ist kein spezifisches Merkmal von Kubernetes. Das Konzept des Blue/Green Deployments gibt es schon lange, und es hat immer einen Lastenausgleich verwendet. Zunächst leiten Sie den gesamten Verkehr zur alten Version der Anwendung, und nach dem Update leiten Sie ihn vollständig zur neuen Version um. Dieses Prinzip wird nicht nur in Kubernetes angewandt.
Jetzt präsentiere ich Ihnen eine neue Bereitstellungskomponente – Deployer, die die Funktionsfähigkeit überprüft, den Proxy neu konfiguriert und so weiter. Dies ist ein Konzept, das nicht mit der Außenwelt verbunden ist und innerhalb von Kubernetes existiert. Ich werde Ihnen zeigen, wie Sie Ihr eigenes Deployer-Konzept mit Open-Source-Tools erstellen können.
Das erste, was Deployer tut, ist die Erstellung eines Replication Controllers (RC) unter Verwendung der Kubernetes-API. Diese API erstellt Pods und Services für die weitere Bereitstellung, also einen komplett neuen Cluster für unsere Anwendungen. Sobald der RC sichergestellt hat, dass die Replikate gestartet wurden, führt er einen Health-Check durch. Dafür wird im Deployer der Befehl GET /health verwendet. Dieser Befehl startet die entsprechenden Überprüfungskomponenten und überprüft alle Elemente, die den Betrieb des Clusters gewährleisten.
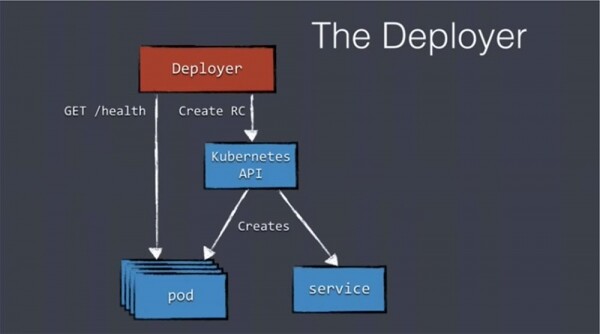
Nachdem alle Pods ihren "Status" gemeldet haben, erstellt Deployer ein neues Konfigurationselement: einen verteilten etcd-Speicher, der innerhalb von Kubernetes verwendet wird, unter anderem zur Speicherung der Konfiguration des Lastenausgleichs. Wir speichern Daten in etcd, und ein kleines Tool namens confd überwacht etcd auf neue Daten.
Wenn es Änderungen in der ursprünglichen Konfiguration entdeckt, wird eine neue Konfigurationsdatei generiert und an den ha-proxy übergeben. In diesem Fall wird der ha-proxy neu gestartet, ohne dass Verbindungen verloren gehen, und leitet die Last an die neuen Services weiter, die die neue Version unserer Anwendungen unterstützen.
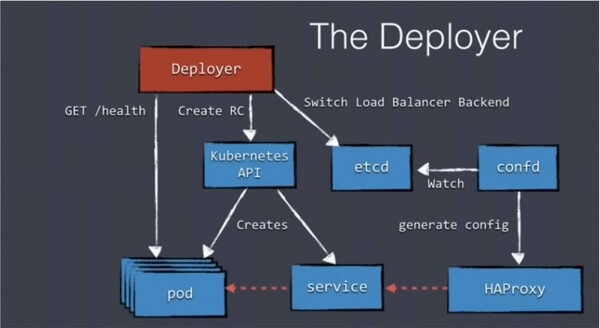
Wie Sie sehen, ist trotz der Vielzahl an Komponenten nichts kompliziert. Sie müssen lediglich mehr Aufmerksamkeit auf die API und etcd richten. Ich möchte Ihnen über den Open-Source-Deploy-Manager berichten, den wir selbst verwenden – den Amdatu Kubernetes Deployer.

Es ist ein Tool zur Orchestrierung von Kubernetes-Bereitstellungen mit Funktionen wie:
- Blue/Green-Deployment;
- Konfiguration eines externen Lastenausgleichs;
- Verwaltung von Bereitstellungsdeskriptoren;
- Verwaltung der tatsächlichen Bereitstellung;
- Health Checks während der Bereitstellung überprüfen;
- Umgebungsvariablen in Pods implementieren.
Dieser Deployer basiert auf der Kubernetes API und bietet ein REST API zur Verwaltung von Deskriptoren und Bereitstellungen sowie ein Websocket API für Live-Logs während der Bereitstellung.
Er speichert die Konfigurationsdaten des Lastenausgleichs in etcd, sodass Sie ha-proxy nicht direkt verwenden müssen, sondern einfach Ihre eigene Konfigurationsdatei für den Lastenausgleich nutzen können. Amdatu Deployer ist in Go geschrieben, wie auch Kubernetes selbst, und unterliegt der Apache-Lizenz.
Vor der Anwendung dieser Version des Deployers habe ich den folgenden Bereitstellungsdeskriptor verwendet, der die benötigten Parameter enthält.

Ein wichtiges Element dieses Codes ist die Aktivierung des Flags „useHealthCheck“. Wir müssen angeben, dass während des Deployments eine Verfügbarkeitsprüfung durchgeführt werden soll. Dieses Parameter kann deaktiviert werden, wenn im Deployment Containern von Drittanbietern verwendet werden, die keiner Überprüfung bedürfen. In diesem Deskriptor sind auch die Anzahl der Replikate und die URL des Frontends angegeben, die für ha-proxy benötigt wird. Am Ende wird das „podspec“-Flag erwähnt, das sich an Kubernetes wendet, um Informationen zur Konfiguration von Ports, Abbildungen usw. abzurufen. Dies ist ein relativ einfacher Deskriptor im JSON-Format.
Ein weiteres Werkzeug, das Teil des Open-Source-Projekts Amdatu ist, ist Deploymentctl. Es bietet eine Benutzeroberfläche (UI) zur Konfiguration von Deployments, speichert die Deployment-Historie und enthält Webhooks für Rückrufe von Drittanbietern und Entwicklern. Sie können die UI auch weglassen, da der Amdatu Deployer selbst eine REST-API ist, aber dieses Interface kann Ihnen das Deployment erheblich erleichtern, ohne dass Sie irgendeine API verwenden müssen. Deploymentctl ist in OSGi/Vertx unter Verwendung von Angular 2 geschrieben.
Ich werde jetzt das oben Gesagte auf dem Bildschirm demonstrieren, indem ich eine vorab aufgezeichnete Sitzung verwende, damit Sie nicht warten müssen. Wir werden eine einfache Anwendung in Go bereitstellen. Keine Sorge, wenn Sie zuvor nichts mit Go zu tun hatten, diese Anwendung ist sehr einfach, sodass alles klar sein sollte.
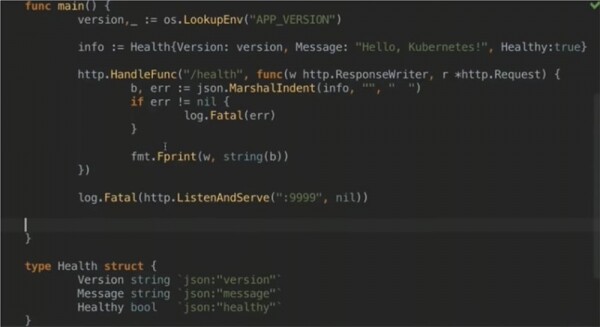
Hier erstellen wir einen HTTP-Server, der nur auf /health antwortet. Diese Anwendung überprüft also nur die Funktionsfähigkeit eines Health Checks und nichts weiter. Wenn der Check besteht, wird die unten gezeigte JSON-Struktur verwendet. Sie enthält die Version der Anwendung, die vom Deployer bereitgestellt wird, und eine Nachricht, die Sie oben in der Datei sehen, sowie einen booleschen Datentyp – ob unsere Anwendung funktionsfähig ist oder nicht.
Mit der letzten Zeile habe ich ein wenig geschummelt, weil ich oben in der Datei einen festen booleschen Wert gesetzt habe, der mir später helfen wird, sogar eine «nicht gesunde» Anwendung bereitzustellen. Darauf werden wir später zurückkommen.
Also, fangen wir an. Zuerst überprüfen wir, ob laufende Pods vorhanden sind, indem wir den Befehl ~ kubectl get pods verwenden, und anhand des fehlenden Frontend-URLs stellen wir sicher, dass derzeit keine Bereitstellungen stattfinden.
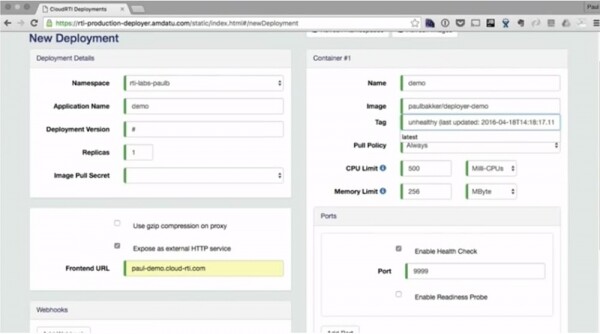
Auf dem Bildschirm sehen Sie jetzt die von mir erwähnte Deploymentctl-Oberfläche, in der die Bereitstellungsparameter festgelegt werden: Namespace, Anwendungsname, Bereitstellungsversion, Anzahl der Replikate, Frontend-URL, Containername, Image, Ressourcengrenzen, Portnummer für den Health-Check usw. Die Ressourcengrenzen sind sehr wichtig, da sie die maximale Ausnutzung der Hardware ermöglichen. Hier können Sie auch das Bereitstellungsprotokoll einsehen.
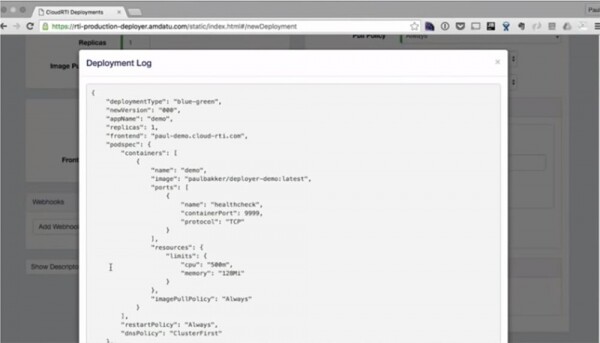
Wenn Sie jetzt den Befehl ~ kubectl get pods erneut ausführen, erkennen Sie, dass das System für 20 Sekunden "stillsteht", während es das ha-proxy neu konfiguriert. Danach wird das Pod gestartet und unsere Replik kann im Bereitstellungsprotokoll gesehen werden.
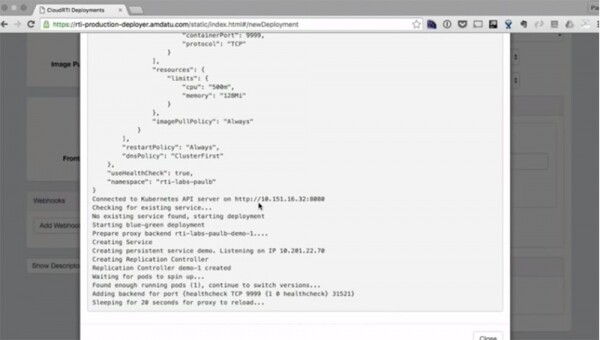
Ich habe die 20-sekündige Wartezeit aus dem Video herausgeschnitten, und jetzt sehen Sie auf dem Bildschirm, dass die erste Version der Anwendung bereitgestellt wurde. All dies wurde ausschließlich über die Benutzeroberfläche durchgeführt.
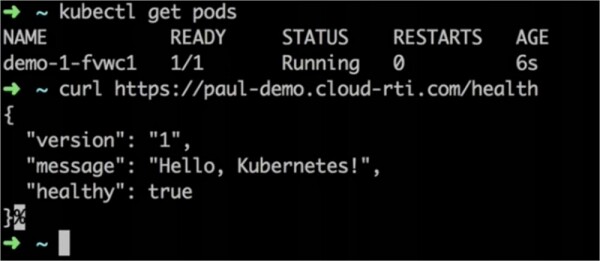
Jetzt versuchen wir die zweite Version. Dazu ändere ich die Nachricht der Anwendung von „Hello, Kubernetes!“ in „Hello, Deployer!“. Das System erstellt dieses Image und speichert es im Docker-Repository, danach klicken wir einfach erneut auf die Schaltfläche „Deploy“ im Fenster Deploymentctl. Gleichzeitig wird das Deployment-Log automatisch gestartet, genau wie beim Deployment der ersten Version der Anwendung.
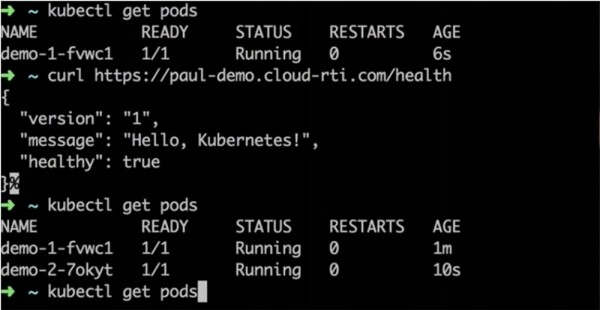
Der Befehl ~ kubectl get pods zeigt, dass derzeit 2 Versionen der Anwendung ausgeführt werden, jedoch zeigt das Frontend, dass immer noch Version 1 aktiv ist.
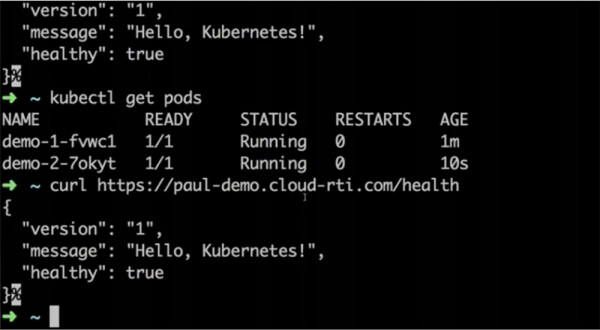
Der Lastenausgleich wartet, bis die Health-Checks durchgeführt wurden, und leitet dann den Datenverkehr zur neuen Version weiter. Nach 20 Sekunden wechseln wir zu curl und sehen, dass jetzt die Version 2 der Anwendung bereitgestellt wurde, während die erste entfernt wurde.
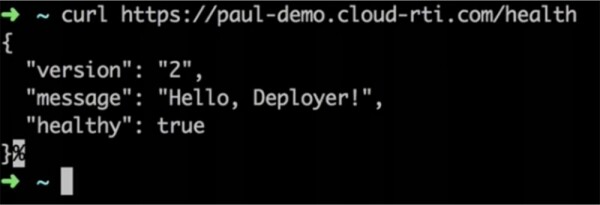
Dies war das Deployment einer "gesunden" Anwendung. Lassen Sie uns sehen, was passiert, wenn ich für die neue Version der Anwendung den Parameter Healthy von true auf false ändere, also versuche, eine ungesunde Anwendung zu deployen, die den Health-Check nicht bestanden hat. Dies kann vorkommen, wenn während der Entwicklung Fehler in der Konfiguration der Anwendung gemacht wurden und sie so in die Produktion geschickt wurde.
Wie Sie sehen, durchläuft das Deployment alle oben genannten Phasen, und ~ kubectl get pods zeigt, dass beide Pods gestartet wurden. Im Gegensatz zum vorherigen Deployment zeigt das Protokoll jedoch den Status 'timeout'. Das bedeutet, dass die neue Version der Anwendung aufgrund eines fehlgeschlagenen Health-Checks nicht bereitgestellt werden kann. Infolgedessen sehen Sie, dass das System zur Verwendung der alten Version der Anwendung zurückgekehrt ist und die neue Version einfach gelöscht wurde.
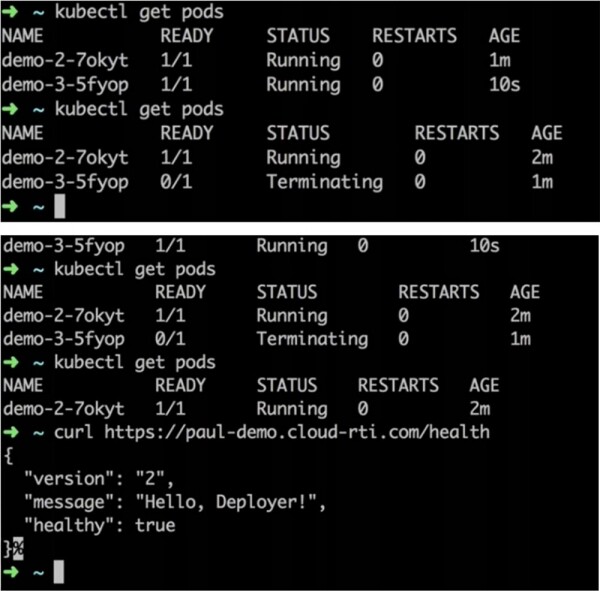
Der Vorteil ist, dass selbst bei einer großen Anzahl gleichzeitiger Anfragen an die Anwendung keine Unterbrechung während des Deployments bemerkbar ist. Wenn Sie diese Anwendung mit dem Gatling-Framework testen, das ihr eine maximale Anzahl an Anfragen sendet, wird keine einzige dieser Anfragen abgelehnt. Das bedeutet, dass unsere Benutzer Aktualisierungen der Version in Echtzeit gar nicht wahrnehmen. Sollte das Deployment fehlschlagen, wird weiterhin die alte Version betrieben, und im Erfolgsfall wechseln die Benutzer zur neuen Version.
Es gibt nur eine Sache, die zu einem Fehlschlag führen kann – wenn der Health Check erfolgreich war, aber die Anwendung zusammenbricht, sobald die Arbeitslast eintrifft, also der Kollaps nach Abschluss der Bereitstellung auftritt. In diesem Fall müssen Sie manuell auf die ältere Version zurücksetzen. Wir haben also betrachtet, wie man Kubernetes mit den dafür vorgesehenen Open-Source-Tools verwendet. Der Bereitstellungsprozess wird erheblich einfacher, wenn Sie diese Tools in Ihre Build/Deploy-Pipelines integrieren. Dabei können Sie sowohl die Benutzeroberfläche zur Auslösung der Bereitstellung verwenden als auch diesen Prozess vollständig automatisieren, indem Sie beispielsweise einen Commit zum Master verwenden.
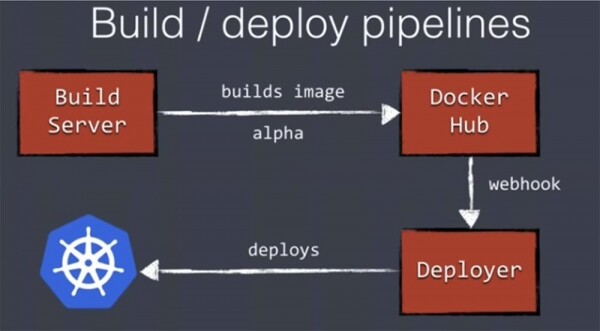
Unser Build-Server erstellt ein Docker-Image und fügt es in den Docker Hub oder ein anderes von Ihnen verwendetes Registry ein. Docker Hub unterstützt Webhooks, sodass wir eine Remote-Bereitstellung über Deployer über den oben gezeigten Weg starten können. So kann die Bereitstellung der Anwendung in eine potenzielle Produktionsumgebung vollständig automatisiert werden.
Kommen wir zum nächsten Thema – der Skalierung von Kubernetes-Clustern. Ich möchte darauf hinweisen, dass das Kommando „kubectl“ für die Skalierung zuständig ist. Damit können Sie ganz einfach die Anzahl der Replikate in Ihrem bestehenden Cluster erhöhen. Allerdings möchten wir in der Praxis meistens die Anzahl der Knoten und nicht der Pods erhöhen.

Dabei kann es während der Arbeitszeiten notwendig sein, die Anzahl zu erhöhen, während es nachts, um die Kosten für Amazon zu senken, nötig sein kann, die Anzahl der laufenden Anwendungsinstanzen zu reduzieren. Das bedeutet nicht, dass es ausreicht, lediglich die Anzahl der Pods zu skalieren, denn selbst wenn einer der Knoten ungenutzt bleibt, müssen Sie weiterhin für diesen Knoten an Amazon zahlen. Das heißt, Sie müssen neben der Skalierung der Pods auch die Anzahl der verwendeten Maschinen skalieren.
Das kann Herausforderungen mit sich bringen, denn unabhängig davon, ob wir Amazon oder einen anderen Cloud-Dienst nutzen, weiß Kubernetes nichts über die Anzahl der verwendeten Maschinen. Es fehlt ein Werkzeug, um das System auf Knotenebene zu skalieren.

Deshalb müssen wir uns sowohl um die Nodes als auch um die Pods kümmern. Wir können die Bereitstellung neuer Nodes problemlos über die AWS API und die Auto Scaling-Gruppe verwalten, um die Anzahl der Arbeitsknoten in Kubernetes zu konfigurieren. Außerdem lässt sich cloud-init oder ein ähnliches Skript verwenden, um die Nodes im Kubernetes-Cluster zu registrieren.
Ein neuer Server startet in der Scaling-Gruppe, registriert sich als Knoten, wird im Master-Registry eingetragen und beginnt zu arbeiten. Danach kann die Anzahl der Replikate erhöht werden, um die neu entstandenen Knoten zu nutzen. Das Verringern der Skalierung erfordert mehr Aufwand, da sichergestellt werden muss, dass dieser Schritt nicht zur Zerstörung bereits laufender Anwendungen führt, nachdem "nicht benötigte" Maschinen abgeschaltet wurden. Um ein solches Szenario zu verhindern, müssen die Knoten in den Status "unschedulable" versetzt werden. Das bedeutet, dass der Standard-Planer beim Planen der DaemonSet-Pods diese Knoten ignorieren wird. Der Planer wird nichts von diesen Servern entfernen, aber auch keine neuen Container dort starten. Der nächste Schritt besteht darin, den Knoten zu drainen, das heißt, die laufenden Pods auf eine andere Maschine oder andere Knoten mit ausreichender Kapazität zu verschieben. Sobald sichergestellt ist, dass auf diesen Knoten keine Container mehr laufen, können sie aus Kubernetes entfernt werden. Danach existieren sie für Kubernetes einfach nicht mehr. Anschließend muss die AWS API genutzt werden, um die nicht benötigten Knoten oder Maschinen abzuschalten.
Sie können Amdatu Scalerd verwenden – ein weiteres Open-Source-Tool zur Skalierung, das dem AWS API ähnlich ist. Es bietet eine CLI zum Hinzufügen oder Entfernen von Knoten im Cluster. Eine interessante Funktion ist die Möglichkeit, den Scheduler über die folgende JSON-Datei anzupassen.
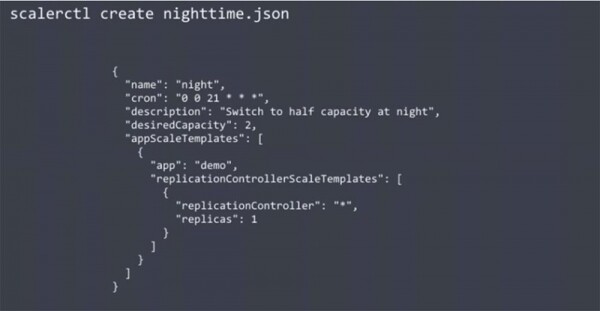
Der dargestellte Code halbiert die Kapazität des Clusters während der Nachtstunden. Er ist so konfiguriert, dass sowohl die Anzahl der vorhandenen Replikate als auch die gewünschte Kapazität des Amazon-Clusters eingestellt werden. Die Verwendung dieses Schedulers reduziert automatisch die Anzahl der Knoten nachts und erhöht sie am Morgen, wodurch Kosten für die Nutzung von Knoten eines Cloud-Dienstes wie Amazon eingespart werden. Diese Funktion ist nicht in Kubernetes integriert, aber die Nutzung von Scalerd ermöglicht es Ihnen, diese Plattform nach Belieben zu skalieren.
Ich möchte Ihre Aufmerksamkeit darauf lenken, dass mir viele Menschen sagen: "Das ist alles gut und schön, aber was ist mit meiner Datenbank, die in der Regel in einem statischen Zustand ist?" Wie kann man so etwas in einer dynamischen Umgebung wie Kubernetes zum Laufen bringen? Meiner Meinung nach sollten Sie das nicht tun und nicht versuchen, ein Datenspeicher in Kubernetes zu organisieren. Technisch ist es möglich, und es gibt Anleitungen dazu im Internet, aber es wird Ihr Leben erheblich komplizierter machen.
Ja, in Kubernetes gibt es das Konzept von persistenten Speichern, und Sie können versuchen, solche Datenspeicher wie Mongo oder MySQL zu betreiben, aber das ist eine ziemlich mühsame Aufgabe. Das liegt daran, dass Datenspeicher nicht vollständig für die Interaktion mit einer dynamischen Umgebung ausgelegt sind. Die meisten Datenbanken erfordern erhebliche Konfigurationen, einschließlich manuellem Cluster-Setup, und mögen kein automatisches Scaling und ähnliche Dinge nicht.
Deshalb sollten Sie sich das Leben nicht unnötig erschweren, indem Sie versuchen, einen Daten-Storage in Kubernetes zu starten. Organisieren Sie deren Betrieb auf herkömmliche Weise mit bewährten Diensten und ermöglichen Sie Kubernetes einfach deren Nutzung.
Zum Abschluss möchte ich Ihnen die Cloud RTI-Plattform auf Basis von Kubernetes vorstellen, an der mein Team arbeitet. Sie bietet eine zentrale Protokollierung, Überwachung von Anwendungen und Clustern und verfügt über viele weitere nützliche Funktionen, die Ihnen von Nutzen sein werden. Verschiedene Open-Source-Tools wie Grafana werden zur Anzeige der Überwachung eingesetzt.

Es stellte sich die Frage, warum man mit Kubernetes einen Lastenausgleichsmechanismus wie ha-proxy verwenden sollte. Eine berechtigte Frage, denn derzeit gibt es zwei Ebenen der Lastenverteilung. Kubernetes-Dienste befinden sich nach wie vor auf virtuellen IP-Adressen. Sie können diese nicht für die Ports externer Hosts verwenden, da sich die Adresse ändern könnte, wenn Amazon sein Cloud-Hosting überlastet. Deshalb platzieren wir ha-proxy vor den Diensten, um eine stabilere Struktur für die kontinuerliche Interaktion des Traffics mit Kubernetes zu schaffen.
Eine weitere interessante Frage ist, wie man Änderungen am Datenbankschema bei einem Blue/Green Deployment handhaben kann. Das Problem ist, dass das Ändern des Datenbankschemas, unabhängig von der Nutzung von Kubernetes, eine komplexe Herausforderung darstellt. Sie müssen sicherstellen, dass die alte und die neue Schema-Version kompatibel sind, bevor Sie die Datenbank aktualisieren und anschließend die Anwendungen selbst aktualisieren können. Man kann ein 'Hot Swapping' der Datenbank durchführen und danach die Anwendungen aktualisieren. Ich kenne Leute, die einen völlig neuen Datenbank-Cluster mit einem neuen Schema eingerichtet haben, was eine mögliche Lösung ist, wenn Sie eine schemalose Datenbank wie Mongo verwenden. Aber so oder so ist das keine einfache Aufgabe. Wenn es keine weiteren Fragen gibt, danke für Ihre Aufmerksamkeit!

Ein wenig Werbung 🙂
Danke, dass Sie bei uns bleiben. Gefallen Ihnen unsere Artikel? Möchten Sie mehr interessante Inhalte sehen? Unterstützen Sie uns, indem Sie eine Bestellung aufgeben oder uns Ihren Freunden empfehlen. , eine einzigartige Alternative zu Einsteiger-Servern, die wir für Sie entwickelt haben: (Verfügbar sind Optionen mit RAID1 und RAID10, bis zu 24 Kerne und bis zu 40GB DDR4).
Dell R730xd im Equinix Tier IV Rechenzentrum in Amsterdam zum halben Preis? Nur bei uns in den Niederlanden! Dell R420 — 2x E5-2430 2.2GHz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — ab 99 $! Lesen Sie darüber
Quelle: habr.com
