


Hallo zusammen! Ich heiße Oleg Sidorenkov und arbeite als Teamleiter Infrastruktur bei der Firma DomKlick. Wir setzen «Kubik» seit über drei Jahren produktiv ein und haben in dieser Zeit viele interessante Momente damit erlebt. Heute werde ich euch erzählen, wie man mit dem richtigen Ansatz noch mehr Leistung aus einem „vanilla“ Kubernetes für euren Cluster herausholen kann. Bereit, fertig, los!
Ihr wisst alle, dass Kubernetes ein skalierbares Open-Source-System zur Orchestrierung von Containern ist; oder besser gesagt, fünf Binärdateien, die im Hintergrund die Magie entfalten, indem sie den Lebenszyklus eurer Mikrodienste in der Serverumgebung verwalten. Darüber hinaus ist es ein recht flexibles Werkzeug, das wie ein Lego-Bausatz für maximale Anpassung an verschiedene Aufgaben zusammengestellt werden kann.
Und eigentlich ist alles gut: schmeißt Server in den Cluster wie Holz in den Ofen und kennt kein Problem. Aber wenn dir die Umwelt am Herzen liegt, fragst du dich: „Wie kann ich das Feuer im Ofen am Brennen halten und gleichzeitig den Wald schonen?“. Mit anderen Worten, wie findet man Wege zur Verbesserung der Infrastruktur und zur Senkung der Kosten.
1. Achte auf die Ressourcen von Teams und Anwendungen

Eine der grundlegendsten, aber effektivsten Methoden ist die Einführung von Anfragen/Limits. Trennen Sie Anwendungen nach Namespaces und Namespaces nach Entwicklungsteams. Weisen Sie der Anwendung vor dem Deployment Werte für die CPU-Zeit, den Speicher und den ephemeral Speicher zu.
resources:
requests:
memory: 2Gi
cpu: 250m
limits:
memory: 4Gi
cpu: 500mDurch Erfahrung sind wir zu dem Schluss gekommen: Es ist nicht ratsam, die Anfragen von den Limits um mehr als das Doppelte zu erhöhen. Das Volumen des Clusters wird auf der Grundlage der Anfragen berechnet, und wenn Sie den Anwendungen einen Ressourcenunterschied von zum Beispiel 5-10 Mal geben, stellen Sie sich vor, was mit Ihrem Node passiert, wenn es mit Pods gefüllt wird und plötzlich unter hoher Last steht. Nichts Gutes. Mindestens wird es zu Throttling kommen, und maximal müssen Sie sich von dem Worker verabschieden und erleben eine zyklische Belastung der anderen Nodes, nachdem die Pods beginnen zu migrieren.
Darüber hinaus können Sie mithilfe von limitranges Sie können beim Start für den Container Werte für die Ressourcen festlegen — minimal, maximal und standardmäßig:
➜ ~ kubectl describe limitranges --namespace ops
Name: limit-range
Namespace: ops
Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
---- -------- --- --- --------------- ------------- -----------------------
Container cpu 50m 10 100m 100m 2
Container ephemeral-storage 12Mi 8Gi 128Mi 4Gi -
Container memory 64Mi 40Gi 128Mi 128Mi 2Vergessen Sie nicht, die Ressourcen des Namensraums zu begrenzen, damit ein Team nicht alle Ressourcen des Clusters beanspruchen kann:
➜ ~ kubectl describe resourcequotas --namespace ops
Name: resource-quota
Namespace: ops
Resource Used Hard
-------- ---- ----
limits.cpu 77250m 80
limits.memory 124814367488 150Gi
pods 31 45
requests.cpu 53850m 80
requests.memory 75613234944 150Gi
services 26 50
services.loadbalancers 0 0
services.nodeports 0 0Wie aus der Beschreibung ersichtlich resourcequotas, wenn das Team ops Pods bereitstellen möchte, die weitere 10 CPU benötigen, wird der Scheduler dies verhindern und einen Fehler ausgeben:
Error creating: pods "nginx-proxy-9967d8d78-nh4fs" is forbidden: exceeded quota: resource-quota, requested: limits.cpu=5,requests.cpu=5, used: limits.cpu=77250m,requests.cpu=53850m, limited: limits.cpu=10,requests.cpu=10Um ein solches Problem zu lösen, kann man ein Werkzeug schreiben, wie zum Beispiel , das in der Lage ist, den Zustand der Ressourcen der Teams zu speichern und zu committen.
2. Wählen Sie den optimalen Speicher
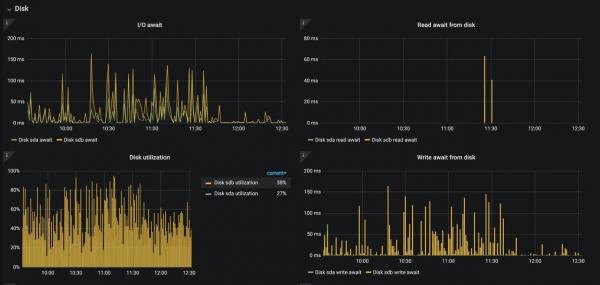
Hier möchte ich das Thema persistenter Volumes und des Disk-Subsystems der Worker-Knoten von Kubernetes ansprechen. Ich hoffe, dass niemand Kub auf HDD im Produktionsbetrieb verwendet, aber manchmal reicht sogar ein gewöhnliches SSD nicht aus. Wir hatten mit dem Problem zu kämpfen, dass die Logs die Festplatte durch Input-Output-Operationen belasteten, und die Lösungsmöglichkeiten sind hier nicht sehr vielfältig:
Entweder hochleistungsfähige SSDs verwenden oder auf NVMe umsteigen (wenn Sie Ihr eigenes Hardware-Setup verwalten).
Das Logging-Level reduzieren.
Eine "intelligente" Lastverteilung für Pods durchführen, die die Festplatte belasten (
podAntiAffinity).
Der Screenshot oben zeigt, was unter dem nginx-ingress-controller mit der Festplatte passiert, wenn das Logging der access_logs aktiviert ist (~12.000 Logs/Sekunde). Ein solcher Zustand kann natürlich zu einer Verschlechterung aller Anwendungen auf diesem Knoten führen.
Was PV betrifft, leider habe ich nicht alle Persistent Volumes. Wählen Sie die beste Option, die zu Ihnen passt. Historisch bedingt benötigen einige wenige Dienste RWX-Volumes, und schon lange verwenden wir dafür NFS-Speicher. Günstig und... ausreichend. Natürlich hatten wir unsere Schwierigkeiten damit – das war kein Zuckerschlecken, aber wir haben gelernt, ihn zu optimieren, und nun haben wir Ruhe. Und wenn möglich, wechseln Sie zu einem Objektspeicher wie S3.
3. Erstellen Sie optimierte Images

Am besten verwenden Sie für Container optimierte Images, damit Kubernetes sie schneller abrufen und effizienter ausführen kann.
Optimiert bedeutet, dass die Images:
nur eine Anwendung enthalten oder nur eine Funktion ausführen;
klein von der Größe her sind, da große Images schlechter über das Netzwerk übertragen werden;
Überwachungsendpunkte für die Verfügbarkeit und Bereitschaft haben, damit Kubernetes im Falle von Ausfällen Maßnahmen ergreifen kann;
containerfreundliche Betriebssysteme (wie Alpine oder CoreOS) verwenden, die widerstandsfähiger gegen Konfigurationsfehler sind;
verwendet mehrstufige Builds, damit Sie nur kompilierte Anwendungen und nicht die dazugehörigen Quellcodes bereitstellen können.
Es gibt viele Werkzeuge und Dienste, die es ermöglichen, Images in Echtzeit zu überprüfen und zu optimieren. Es ist wichtig, sie immer auf dem neuesten Stand und sicher zu halten. Am Ende erhalten Sie:
Reduzierung der Netzwerlast auf dem gesamten Cluster.
Verringerung der Startzeit von Containern.
Kleinere Größe Ihres gesamten Docker-Registrys.
4. Verwenden Sie den DNS-Cache

Wenn es um hohe Lasten geht, ist es ohne Anpassung des DNS-Systems des Clusters recht mühsam. Vor langer Zeit unterstützten die Entwickler von Kubernetes ihre Lösung kube-dns. Dieses System wurde auch bei uns implementiert, aber es wurde nicht wirklich optimiert und lieferte nicht die erforderliche Leistung, obwohl die Aufgabe eigentlich einfach erscheint. Dann kam coredns, auf den wir umgestiegen sind und der uns nicht enttäuschte; schließlich wurde es der standardmäßige DNS-Dienst in K8s. Irgendwann erreichten wir 40.000 rps im DNS-System, und auch dieses System war nicht mehr ausreichend. Aber durch einen glücklichen Zufall kam NodeLocaldns heraus, auch bekannt als node local cache, er auch .
Warum verwenden wir das? Im Linux-Kernel gibt es einen Bug, der bei mehrfachen Anfragen über conntrack NAT über UDP zu einem Rennzustand beim Schreiben in die conntrack-Tabellen führt, wodurch ein Teil des Traffics durch NAT verloren geht (jede Anfrage über den Service ist NAT). Nodelocaldns löst dieses Problem, indem es NAT umgeht und die Verbindung zu den upstream DNS auf TCP aktualisiert sowie lokale DNS-Anfragen an die Upstreams speichert (einschließlich eines kurzen 5-Sekunden-Negativ-Caches).
5. Skalieren Sie Pods automatisch horizontal und vertikal
Können Sie mit Zuversicht sagen, dass all Ihre Microservices bereit für einen zweifachen oder dreifachen Anstieg der Last sind? Wie sollten Sie Ressourcen für Ihre Anwendungen richtig zuweisen? Ein paar Pods über der Arbeitslast aktiv zu halten, kann überflüssig sein, und wenn Sie am Limit bleiben, riskieren Sie Ausfallzeiten durch einen plötzlichen Anstieg des Traffics auf den Service. Die goldene Mitte hilft Ihnen, durch Multiplication, mit solchen Diensten wie und .
VPA ermöglicht es, die Anforderungen/Grenzen Ihrer Container im Pod basierend auf der tatsächlichen Nutzung automatisch zu erhöhen. Wie kann das nützlich sein? Wenn Sie Pods haben, die aus irgendeinem Grund nicht horizontal skaliert werden können (was nicht ganz zuverlässig ist), können Sie versuchen, die Ressourcenänderung dem VPA anzuvertrauen. Sein Merkmal basiert auf einem Empfehlungssystem, das historische und aktuelle Daten vom Metric-Server nutzt. Wenn Sie also nicht automatisch die Anforderungen/Grenzen ändern möchten, können Sie einfach die empfohlenen Ressourcen für Ihre Container verfolgen und die Einstellungen zur Einsparung von CPU und Speicher im Cluster optimieren.
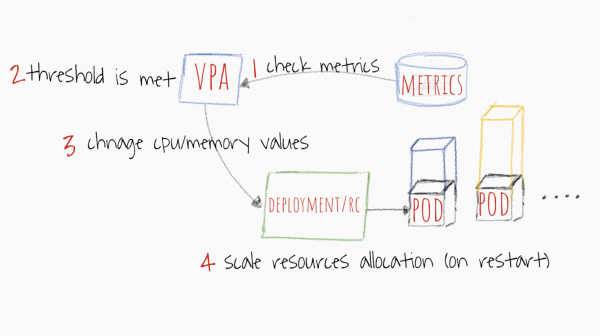 Das Bild wurde von https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231 entnommen.
Das Bild wurde von https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231 entnommen.
Der Scheduler in Kubernetes basiert immer auf den Requests. Welchen Wert Sie auch immer eingeben, der Scheduler sucht eine geeignete Node basierend darauf. Die Limits sind für den Kubelet wichtig, um zu verstehen, wann er throttlen oder ein Pod terminieren soll. Und da der einzige wichtige Parameter die Requests sind, wird der VPA (Vertical Pod Autoscaler) mit ihm arbeiten. Jedes Mal, wenn Sie das vertikale Scaling einer Anwendung festlegen, bestimmen Sie, wie die Requests aussehen sollten. Was geschieht dann mit den Limits? Dieser Parameter wird ebenfalls proportional skaliert.
Beispielsweise sind hier die typischen Einstellungen eines Pods:
resources:
requests:
memory: 250Mi
cpu: 200m
limits:
memory: 500Mi
cpu: 350mDer Empfehlungsmechanismus stellt fest, dass Ihre Anwendung für einen ordnungsgemäßen Betrieb 300m CPU und 500Mi benötigt. Sie erhalten folgende Einstellungen:
resources:
requests:
memory: 500Mi
cpu: 300m
limits:
memory: 1000Mi
cpu: 525mWie bereits erwähnt, handelt es sich um eine proportionale Skalierung basierend auf dem Verhältnis von Requests zu Limits im Manifest:
CPU: 200m → 300m: Verhältnis 1:1,75;
Memory: 250Mi → 500Mi: Verhältnis 1:2.
Was HPA, hier ist der Mechanismus transparenter. Es werden Schwellenwerte für Metriken festgelegt, beispielsweise für die CPU und den Arbeitsspeicher. Wenn der Durchschnittswert aller Replikate den Schwellenwert überschreitet, wird die Anwendung um +1 Pod skaliert, bis der Wert unter den Schwellenwert sinkt oder die maximale Anzahl der Replikate erreicht ist.
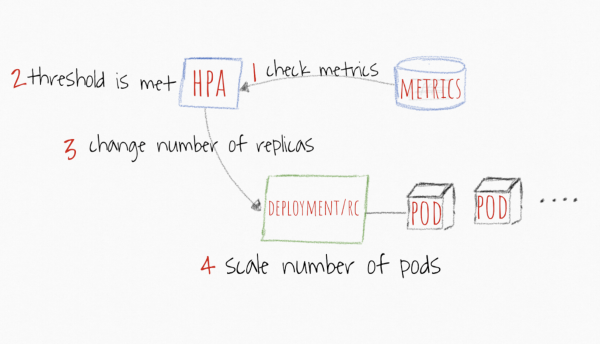 Das Bild wurde von https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231 entnommen.
Das Bild wurde von https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231 entnommen.
Neben den üblichen Metriken wie CPU und Arbeitsspeicher können Sie Schwellenwerte für Ihre benutzerdefinierten Metriken aus Prometheus konfigurieren und mit diesen arbeiten, wenn Sie denken, dass dies die genaueste Definition dafür ist, wann Ihre Anwendung skaliert werden sollte. Sobald die Anwendung unter die festgelegte Metrikgrenze stabilisiert ist, beginnt HPA, Pods auf die minimale Anzahl von Replikaten zu skalieren oder bis die Last den festgelegten Schwellenwert erfüllt.
6. Vergessen Sie nicht die Node Affinity und Pod Affinity

Nicht alle Knoten arbeiten mit der gleichen Hardware, und nicht alle Pods müssen Anwendungen ausführen, die rechenintensiv sind. Kubernetes ermöglicht es, die Spezialisierung von Knoten und Pods über Node Affinity und Pod Affinity.
Wenn Sie Knoten haben, die für rechenintensive Operationen geeignet sind, ist es am effektivsten, die Anwendungen an die entsprechenden Knoten zu binden. Dazu verwenden Sie nodeSelector mit der Knotenmarke.
Angenommen, Sie haben zwei Knoten: einen mit CPUType=HIGHFREQ und vielen schnellen Kernen, und einen anderen mit MemoryType=HIGHMEMORY viele Speicher und höhere Leistung. Am einfachsten ist es, die Bereitstellung des Pods dem Knoten zuzuweisen, der HIGHFREQ, indem Sie im Abschnitt spec einen solchen Selektor hinzufügen:
…
nodeSelector:
CPUType: HIGHFREQEin kostspieligerer und spezifischerer Weg, dies zu tun, ist die Verwendung von nodeAffinity im Feld Affinity Abschnitt spec. Es gibt zwei Optionen:
requiredDuringSchedulingIgnoredDuringExecution: harte Einstellung (der Scheduler wird Pods nur auf bestimmten Knoten bereitstellen (und sonst nirgendwo));preferredDuringSchedulingIgnoredDuringExecution: weiche Einstellung (der Scheduler wird versuchen, auf bestimmten Knoten bereitzustellen, und wenn das nicht funktioniert, wird er versuchen, auf dem nächsten verfügbaren Knoten bereitzustellen).
Sie können eine bestimmte Syntax zur Verwaltung der Knotenmarken angeben, z. B. In, NotIn, Exists, DoesNotExist, Gt oder Lt. Denken Sie jedoch daran, dass komplexe Methoden in langen Listen von Marken die Entscheidungsfindung in kritischen Situationen verlangsamen können. Mit anderen Worten, machen Sie es nicht kompliziert.
Wie bereits erwähnt, ermöglicht Kubernetes die Bindung aktueller Pods. Das heißt, Sie können bestimmte Pods dazu bringen, gemeinsam mit anderen Pods in derselben Verfügbarkeitszone (relevant für Cloud-Umgebungen) oder auf Knoten zu arbeiten.
In podAffinity Felder Affinity Abschnitt spec die gleichen Felder sind verfügbar wie bei nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution und preferredDuringSchedulingIgnoredDuringExecution. Der einzige Unterschied besteht darin, dass matchExpressions Pods an den Knoten bindet, auf dem bereits ein Pod mit diesem Label ausgeführt wird.
Kubernetes bietet außerdem das Feld podAntiAffinity, das im Gegensatz dazu keinen Pod an einen Knoten mit bestimmten Pods bindet.
Bezüglich Ausdrücke nodeAffinity kann derselbe Rat gegeben werden: Streben Sie an, die Regeln einfach und logisch zu halten, und vermeiden Sie es, die Podspezifikationen mit einem komplexen Regelwerk zu überladen. Es ist sehr einfach, eine Regel zu erstellen, die nicht den Bedingungen des Clusters entspricht, was zu einer zusätzlichen Belastung desSchedulers führt und die Gesamtleistung verringert.
7. Taints & Tolerations
Es gibt noch eine weitere Möglichkeit zur Verwaltung desSchedulers. Wenn Sie einen großen Cluster mit Hunderten von Knoten und Tausenden von Mikroservices haben, ist es sehr schwierig, bestimmten Pods das Platzieren auf bestimmten Knoten zu verwehren.
Hierbei hilft der Taint-Mechanismus, der verbotene Regeln definiert. Beispielsweise kann in bestimmten Szenarien bestimmten Knoten das Ausführen von Pods untersagt werden. Um einen Taint auf einem bestimmten Knoten anzuwenden, muss die Option Taint in kubectl verwendet werden. Geben Sie den Schlüssel und den Wert an, und dann den Taint wie NoSchedule oder NoExecute:
$ kubectl taint nodes node10 node-role.kubernetes.io/ingress=true:NoScheduleEs ist auch wichtig zu beachten, dass der Taint-Mechanismus drei grundlegende Effekte unterstützt: NoSchedule, NoExecute und PreferNoSchedule.
NoSchedulebedeutet, dass solange in der Pod-Spezifikation kein entsprechender Eintragtolerationsvorhanden ist, er nicht auf diesem Knoten (in diesem Beispielnode10).PreferNoSchedule— eine vereinfachte VersionNoSchedule) bereitgestellt werden kann. In diesem Fall wird der Scheduler versuchen, Pods ohne entsprechenden Eintrag nicht auf diesen Knoten zu verteilen, aber dies ist keine strikte Einschränkung. Wenn im Cluster keine Ressourcen verfügbar sind, werden die Pods anfangen, auf diesem Knoten bereitzustellen.tolerationsauf den Knoten, aber das ist keine feste Einschränkung. Wenn im Cluster keine Ressourcen verfügbar sind, beginnen die Pods, auf diesem Knoten zu starten.NoExecute— dieser Effekt löst eine sofortige Evakuierung der Pods aus, die keinen entsprechenden Eintrag haben.tolerations.
Interessanterweise kann dieses Verhalten mit dem Toleranzmechanismus aufgehoben werden. Dies ist nützlich, wenn es einen „verbotenen“ Knoten gibt und Sie dort nur Infrastrukturservices unterbringen möchten. Wie macht man das? Erlauben Sie nur diejenigen Pods, für die es eine passende Toleranz gibt.
So wird die Pod-Spezifikation aussehen:
spec:
tolerations:
- key: "node-role.kubernetes.io/ingress"
operator: "Equal"
value: "true"
effect: "NoSchedule"Das bedeutet nicht, dass beim nächsten Redeployment der Pod genau auf diesen Knoten kommt; das ist kein Node Affinity Mechanismus und nodeSelector. Aber durch die Kombination mehrerer Funktionen können Sie eine sehr flexible Konfiguration des Planers erreichen.
8. Konfigurieren Sie die Bereitstellungspriorität der Pods
Das bedeutet nicht, dass alle Pods mit der gleichen Priorität bearbeitet werden müssen. Zum Beispiel könnten Sie möchten, dass einige Pods früher als andere bereitgestellt werden.
Kubernetes bietet verschiedene Möglichkeiten zur Konfiguration der Pod-Priorisierung (Pod Priority and Preemption). Die Konfiguration besteht aus mehreren Teilen: dem Objekt PriorityClass und der Beschreibung des Feldes priorityClassName in der Podspezifikation. Lassen Sie uns ein Beispiel betrachten:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: hoch-prioritär
value: 99999
globalDefault: false
description: "Diese Prioritätsklasse sollte nur für sehr wichtige Pods verwendet werden"Wir erstellen PriorityClass, geben ihm einen Namen, eine Beschreibung und einen Wert. Je höher value, desto höher die Priorität. Der Wert kann jede 32-Bit-Ganzzahl sein, die kleiner oder gleich 1 000 000 000 ist. Höhere Werte sind für kritische System-Pods reserviert, die in der Regel nicht verdrängt werden können. Die Verdrängung erfolgt nur, wenn kein Platz für einen hochprioritären Pod vorhanden ist, sodass einige Pods von einem bestimmten Knoten evakuiert werden. Wenn Ihnen dieser Mechanismus zu restriktiv erscheint, können Sie die Option hinzufügen preemptionPolicy: Never, und dann wird es keine Verdrängung geben, der Pod wird an erster Stelle in der Warteschlange stehen und warten, bis der Scheduler Ressourcen für ihn findet.
Als nächstes erstellen wir einen Pod, in dem wir den Namen angeben priorityClassName:
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
role: myrole
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
priorityClassName: hoch-prioritär
Es können beliebig viele Prioritätsklassen erstellt werden, obwohl es empfohlen wird, damit nicht zu übertreiben (zum Beispiel auf niedrig, mittel und hoch zu beschränken).
So können Sie bei Bedarf die Effizienz der Bereitstellung kritischer Dienste wie dem nginx-ingress-controller, coredns usw. steigern.
9. Optimieren Sie den ETCD-Cluster

ETCD kann als das Gehirn des gesamten Clusters bezeichnet werden. Es ist sehr wichtig, diese Datenbank auf hohem Niveau zu betreiben, da die Geschwindigkeit der Operationen im ‚Kubernetes‘ von ihr abhängt. Eine standardmäßige und gleichzeitig akzeptable Lösung wäre, den ETCD-Cluster auf den Master-Nodes zu halten, um eine minimale Latenz zum kube-apiserver zu gewährleisten. Wenn das nicht möglich ist, platzieren Sie ETCD so nah wie möglich, wobei eine gute Bandbreite zwischen den Teilnehmern erforderlich ist. Achten Sie auch darauf, wie viele Nodes aus ETCD ausfallen können, ohne dem Cluster zu schaden.
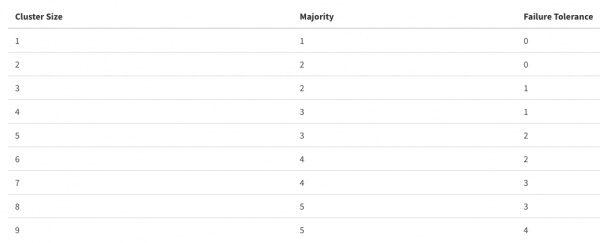
Bitte beachten Sie, dass eine übermäßige Erhöhung der Anzahl der Teilnehmer im Cluster die Fehlertoleranz auf Kosten der Leistung erhöhen kann; alles sollte im angemessenen Maß sein.
Wenn es um die Konfiguration des Dienstes geht, gibt es nur wenige Empfehlungen:
Gute Hardware haben, basierend auf der Größe des Clusters (Sie können lesen ).
Passen Sie einige Parameter an, wenn Sie den Cluster zwischen mehreren Rechenzentren verteilt haben oder wenn Ihr Netzwerk und Ihre Festplatten zu wünschen übrig lassen (lesen Sie mehr darüber) ).
Fazit
In diesem Artikel werden die Punkte beschrieben, die unser Team zu beachten versucht. Es handelt sich nicht um eine Schritt-für-Schritt-Anleitung, sondern um Vorschläge, die zur Optimierung der Betriebskosten des Clusters nützlich sein könnten. Jeder Cluster ist einzigartig, und die Anpassungslösungen können erheblich variieren, daher wäre es interessant, von Ihnen zu hören: Wie überwachen Sie Ihren Kubernetes-Cluster, mit welchen Mitteln verbessern Sie seine Leistung? Teilen Sie Ihre Erfahrungen in den Kommentaren, wir würden gerne davon erfahren.
Quelle: habr.com
